

이 Python을 활용한 데이터 분석 가이드에서는 다음을 살펴보게 됩니다:
- 데이터 분석에 파이썬을 사용하는 이유
- 파이썬 데이터 분석에 흔히 사용되는 라이브러리
- 파이썬으로 데이터 분석을 수행하는 단계별 튜토리얼
- 데이터 분석 시 따라야 할 절차
자, 시작해 보겠습니다!
데이터 분석에 파이썬을 사용하는 이유
데이터 분석은 주로 두 가지 주요 프로그래밍 언어로 수행됩니다:
특히, 데이터 분석에 파이썬을 사용해야 하는 주요 이유는 다음과 같습니다:
- 낮은 학습 곡선: 파이썬은 간단하고 가독성 높은 구문으로 초보자부터 전문가까지 모두 접근하기 쉽습니다.
- 다용도성: Python은 CSV, Excel, JSON, SQL 데이터베이스, Parquet 등 다양한 데이터 유형과 형식을 처리할 수 있습니다. 또한 간단한 데이터 정리부터 복잡한 머신러닝 및 딥러닝 애플리케이션에 이르기까지 다양한 작업에 적합합니다.
- 확장성: 파이썬은 확장성이 뛰어나 소규모 데이터셋부터 대규모 데이터 처리 작업까지 모두 처리할 수 있습니다. 예를 들어, Dask 및 PySpark와 같은 라이브러리를 사용하면 빅데이터를 손쉽게 다룰 수 있습니다.
- 커뮤니티 지원: 파이썬은 생태계에 기여하는 대규모의 활발한 개발자 및 데이터 과학자 커뮤니티를 보유하고 있습니다.
- 머신 러닝 및 AI 통합: Python은 머신 러닝과 AI를 위한 주요 언어로, TensorFlow, PyTorch, Keras와 같은 라이브러리가 고급 분석 및 예측 모델링을 지원합니다.
- 재현성과 협업: Jupyter Notebooks는 데이터 분석 스니펫을 공유하고 재현하는 데 도움을 주며, 이는 데이터 과학에서의 협업에 중요합니다.
- 다양한 목적에 맞는 독특한 환경: 파이썬은 동일한 환경을 다양한 목적으로 활용할 수 있는 가능성을 제공합니다. 예를 들어, 웹에서 데이터를 스크래핑한 후 분석하는 데 동일한 Jupyter Notebook을 사용할 수 있습니다. 같은 환경에서 머신러닝 모델을 활용한 예측 작업도 수행할 수 있습니다.
Python을 활용한 데이터 분석을 위한 주요 라이브러리
파이썬은 광범위한 라이브러리 생태계 덕분에 분석 분야에서도 널리 사용됩니다. 파이썬 데이터 분석에 가장 흔히 사용되는 라이브러리는 다음과 같습니다:
- NumPy: 수치 계산 및 다차원 배열 처리를 위한 라이브러리입니다.
- Pandas: 데이터 조작 및 분석, 특히 표 형식 데이터 처리용.
- Matplotlib 및 Seaborn: 데이터 시각화 및 통찰력 있는 플롯 생성.
- SciPy: 과학적 계산 및 고급 통계 분석을 위한 라이브러리.
- Plotly: 애니메이션 플롯 생성용.
다음 가이드 섹션에서 실제 동작을 확인해 보세요!
파이썬을 활용한 데이터 분석: 완벽한 예시
이제 데이터 분석에 Python을 사용해야 하는 이유와 해당 작업을 지원하는 일반적인 라이브러리를 알게 되었습니다. 단계별 튜토리얼을 따라 Python으로 데이터 분석을 수행하는 방법을 배워보세요.
이 섹션에서는 Bright Data의 무료 데이터 세트에서 가져온 Airbnb 부동산 정보를 분석할 것입니다.
필요 사항
이 가이드를 따라 하려면 컴퓨터에 Python 3.6 이상이 설치되어 있어야 합니다.
1단계: 환경 설정 및 종속성 설치
프로젝트의 메인 폴더를 data_analysis/라고 가정합니다 . 이 단계가 끝나면 폴더 구조는 다음과 같아집니다:
data_analysis/
├── analysis.ipynb
└── venv/여기서:
analysis.ipynb: 모든 Python 데이터 분석 코드가 포함된 Jupyter Notebook입니다.venv/에는Python 가상 환경이 포함됩니다.
venv/ 가상 환경 디렉터리는 다음과 같이 생성할 수 있습니다:
python -m venv venvWindows에서 활성화하려면 다음을 실행하세요:
venvScriptsactivatemacOS/Linux에서는 다음과 같이 실행합니다:
source venv/bin/activate활성화된 가상 환경에서 필요한 모든 라이브러리를 설치하세요:
pip install pandas jupyter matplotlib seaborn numpy분석용 .ipynb 파일을 생성하려면 먼저 data_analysis/ 폴더로 이동해야 합니다:
cd data_analysis그런 다음 다음 명령어로 새 Jupyter Notebook을 초기화합니다:
jupyter notebook이제 브라우저에서 http://locahost:8888 로 Jupyter Notebook 앱에 접근할 수 있습니다.
“새로 만들기 > Python 3 (ipykernel)” 옵션을 클릭하여 새 파일을 생성합니다:
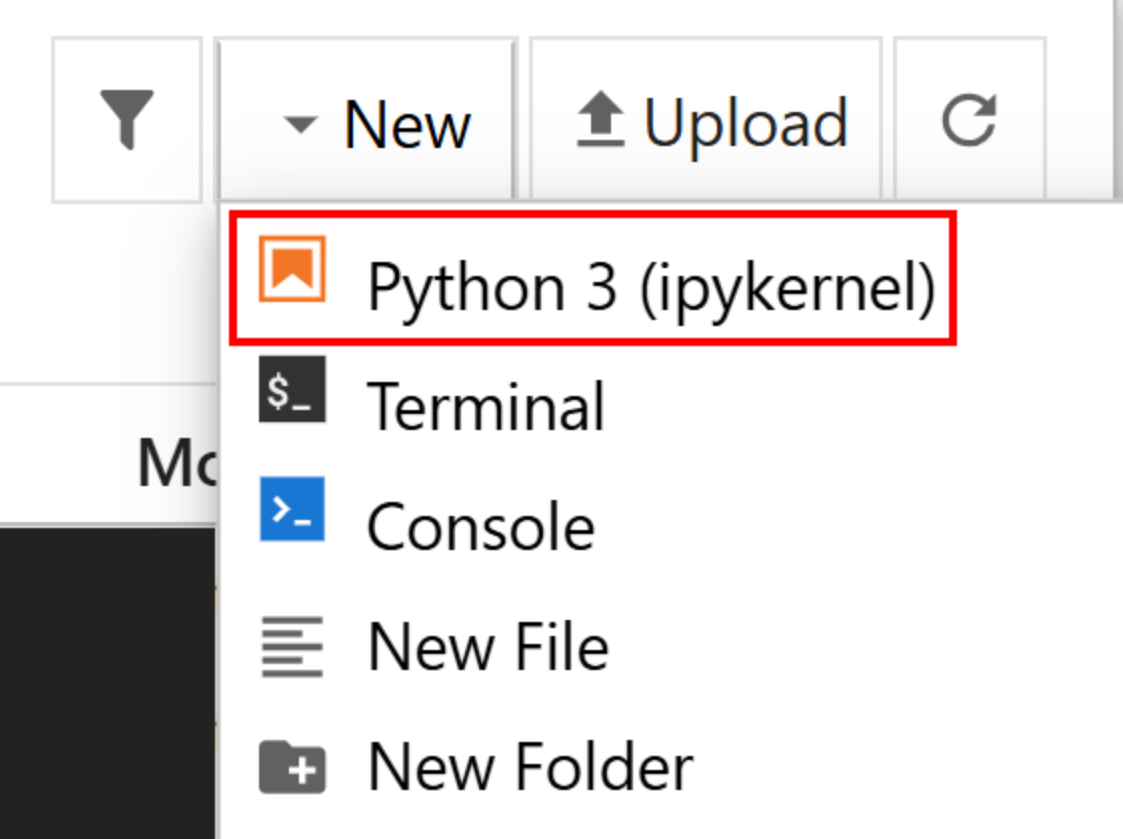
기본적으로 새 파일명은 untitled.ipynb입니다. 대시보드에서 다음과 같이 이름을 변경할 수 있습니다:
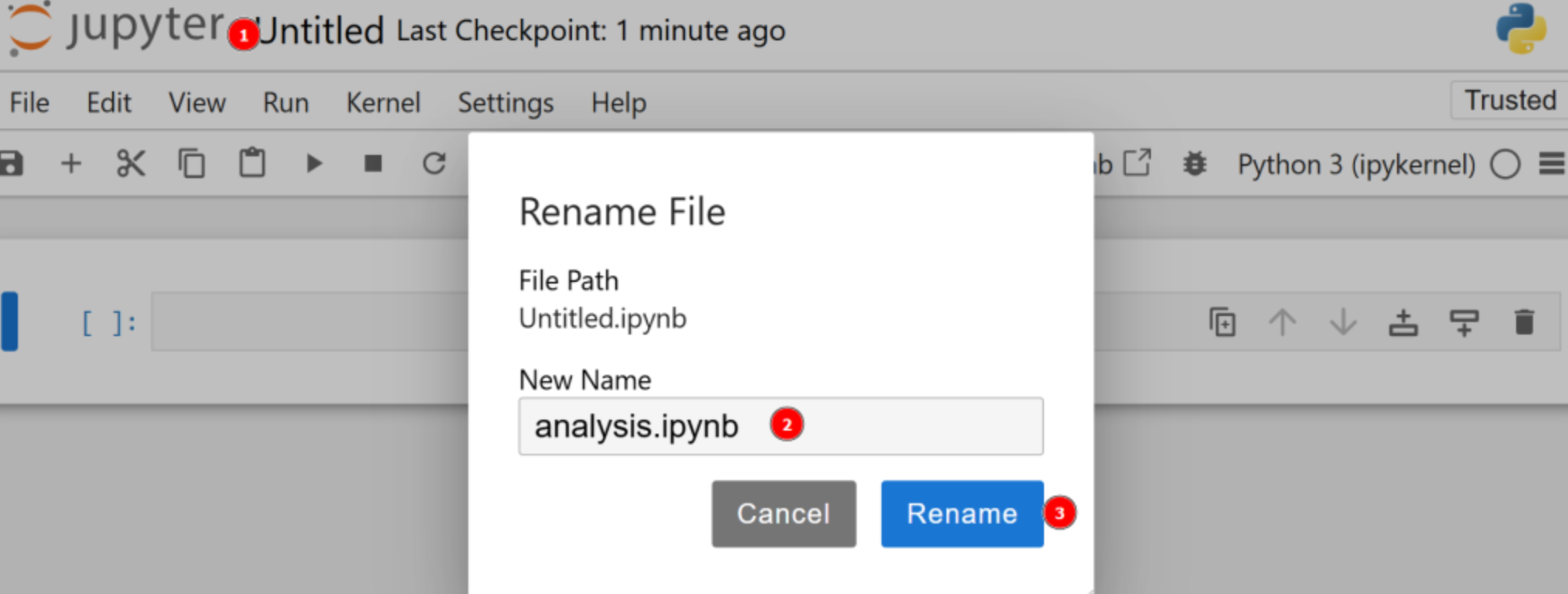
좋습니다! 이제 Python으로 데이터 분석을 위한 모든 준비가 완료되었습니다.
2단계: 데이터 다운로드 및 열기
이 튜토리얼에 사용된 데이터셋은 Bright Data의 데이터셋 마켓플레이스에서 가져왔습니다. 다운로드하려면 플랫폼에 무료로 가입하고 사용자 대시보드로 이동하세요. 그런 다음 “웹 데이터셋 > 데이터셋” 경로를 따라 데이터셋 마켓플레이스로 이동하세요:
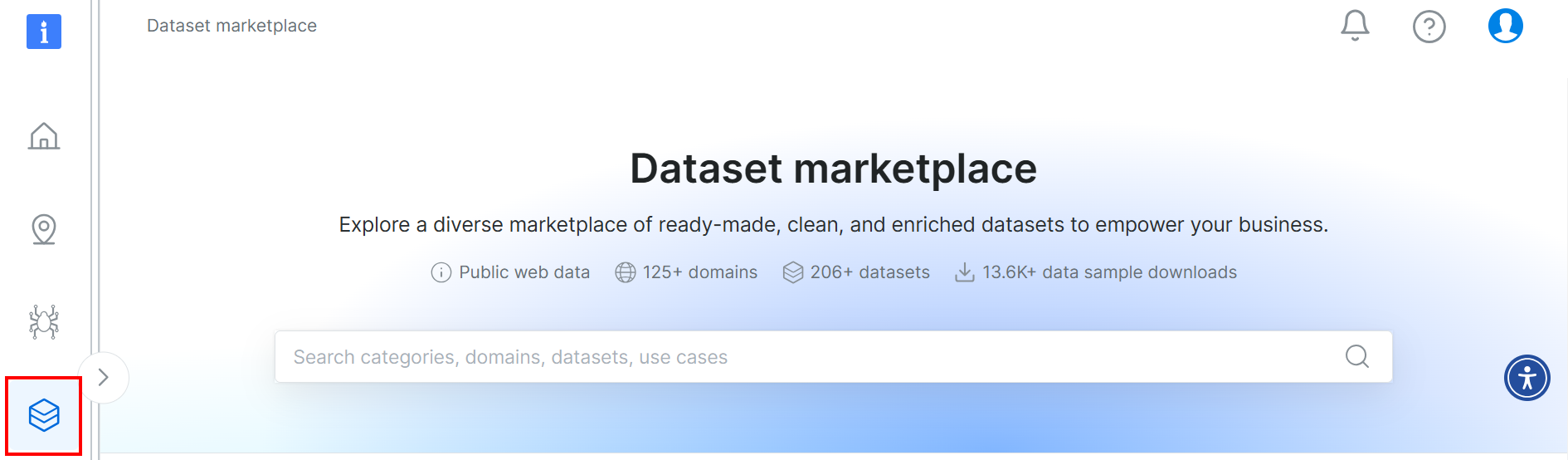
아래로 스크롤하여 “Airbnb Properties Information” 카드를 검색하세요:
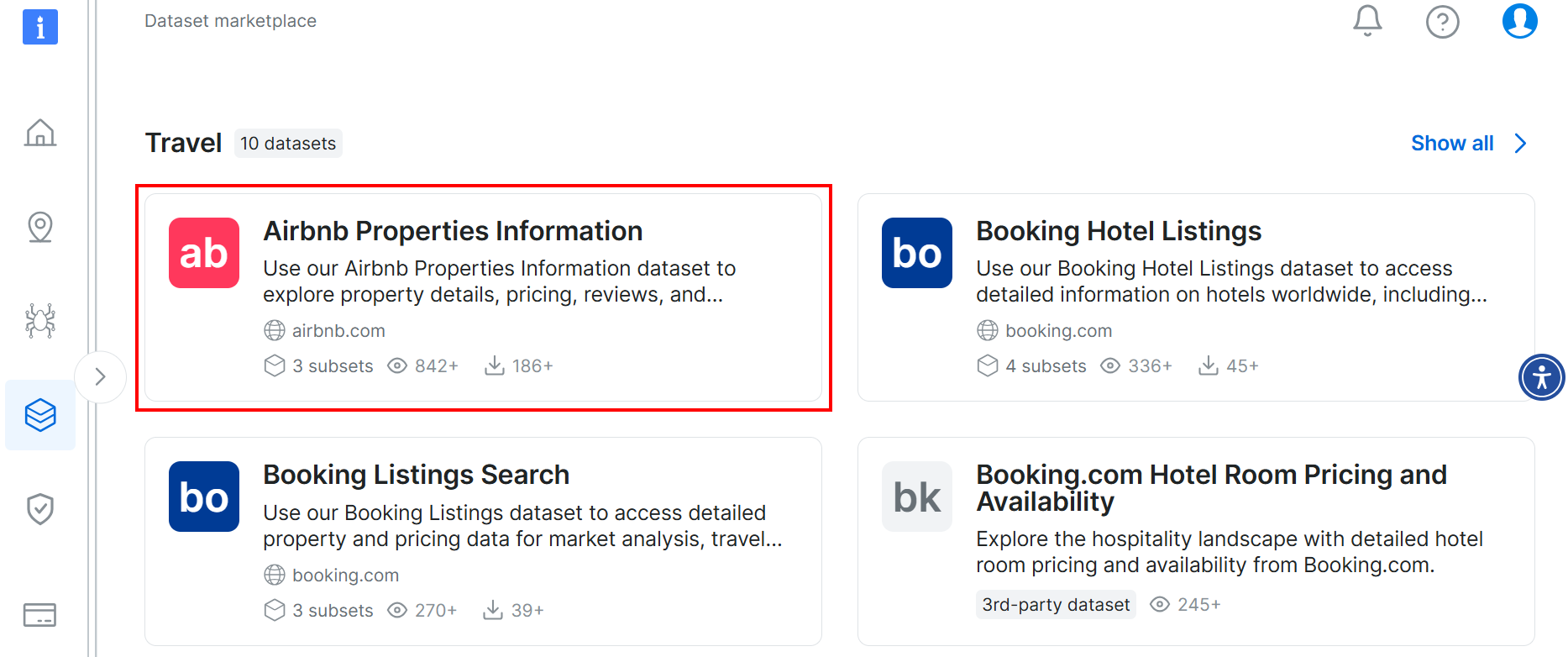
데이터셋을 다운로드하려면 “샘플 다운로드 > CSV로 다운로드” 옵션을 클릭하세요:
이제 다운로드한 파일 이름을 airbnb.csv 등으로 변경할 수 있습니다. Jupyter Notebook에서 CSV 파일을 열려면 새 셀에 다음을 작성하세요:
import pandas as pd
# CSV 열기
data = pd.read_csv("airbnb.csv")
# 상위 행 표시
data.head()이 코드 조각에서:
read_csv()메서드는 CSV 파일을 pandas 데이터셋으로 엽니다.head()메서드는 데이터셋의 첫 5개 행을 표시합니다.
예상 결과는 다음과 같습니다:
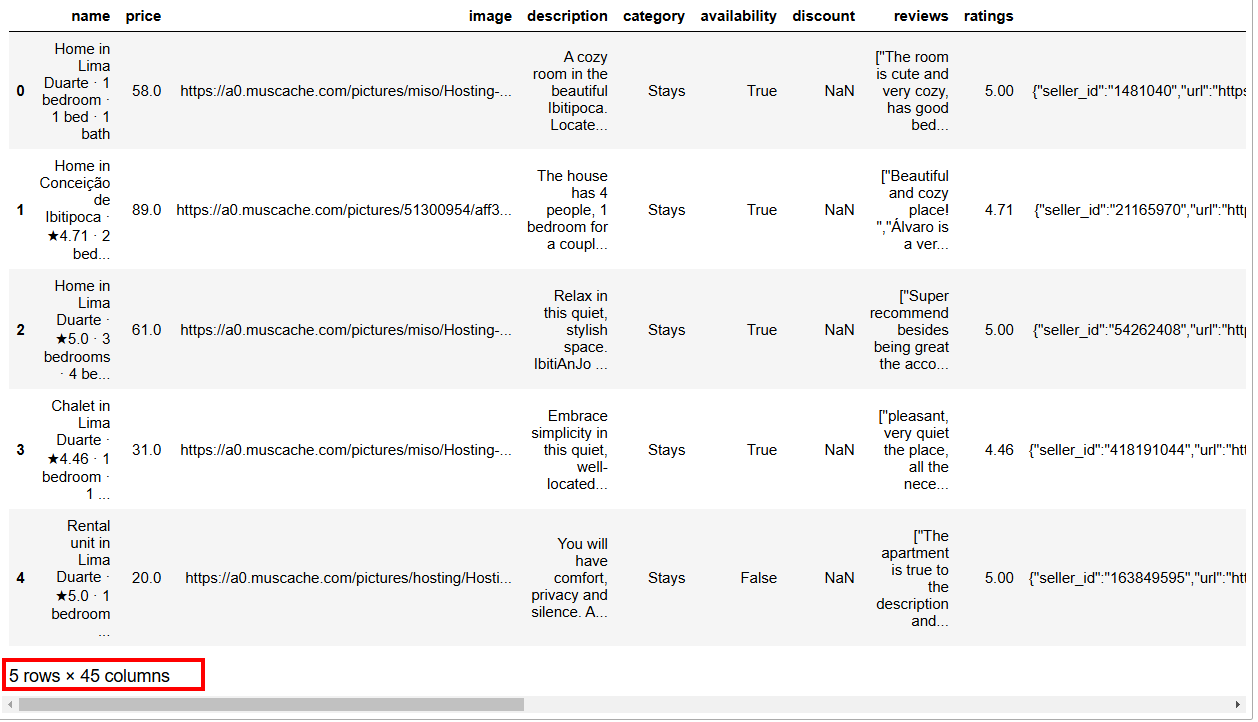
보시다시피 이 데이터셋은 45개의 열을 가지고 있습니다. 모든 열을 보려면 막대를 오른쪽으로 이동해야 합니다. 그러나 이 경우 열 수가 많아 막대만 오른쪽으로 스크롤해도 일부 열이 숨겨져 모든 열을 볼 수 없습니다.
모든 열을 실제로 확인하려면 별도의 셀에 다음을 입력하세요:
# 모든 열 표시
pd.set_option("display.max_columns", None)
# 데이터 프레임 표시
print(data)3단계: NaN처리
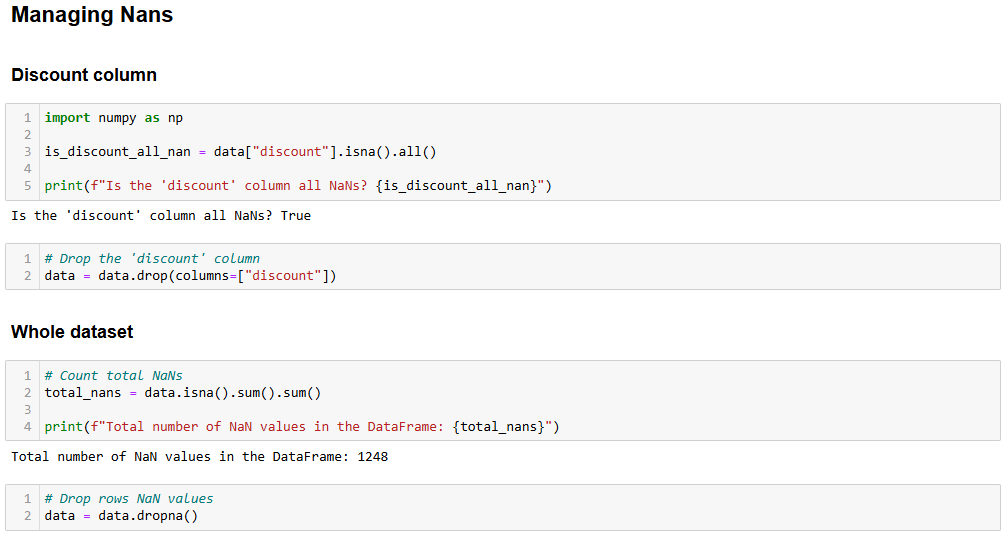
컴퓨팅에서 NaN은 “Not a Number(숫자가 아님)”을 의미합니다. Python으로 데이터 분석을 수행할 때 빈 값이 있는 데이터셋, 숫자가 있어야 할 위치에 문자열이 있는 경우, 또는 이미 NaN으로 표시된 셀(예: 위 이미지의 할인 열 참조)을 접할 수 있습니다.
데이터 분석이 목표이므로 NaN을적절히 처리해야 합니다. 주로 세 가지 방법이 있습니다:
NaN이포함된 모든 행을 삭제합니다.- 해당 열의
NaN값을 같은 열의 다른 숫자들로 계산한 평균값으로 대체합니다. - 원본 데이터셋을 보강할 새로운 데이터를 찾는다.
간단함을 위해 첫 번째 접근법을 따르겠습니다.
먼저 할인(discount) 열의 모든 값이 NaN인지확인해야 합니다. 그렇다면 해당 열 전체를 삭제할 수 있습니다. 이를 확인하려면 새 셀에 다음을 작성하세요:
import numpy as np
is_discount_all_nan = data["discount"].isna().all()
print(f"할인 열이 모두 NaN인가요? {is_discount_all_nan}")이 코드 조각에서 isna().all() 메서드는 데이터셋에서 data["discount"]로 필터링된 할인 열의 NaN값을 분석합니다.
결과는 True로, 이는 discount 열의 모든 값이 NaN이므로해당 열을 삭제할 수 있음을 의미합니다. 이를 위해 다음을 작성하세요:
data = data.drop(columns=["discount"])원본 데이터셋은 할인 열이 제거된 새 데이터셋으로 덮어씌워졌습니다.
이제 전체 데이터셋을 분석하여 행에 다른 NaN이 있는지 확인할 수 있습니다:
total_nans = data.isna().sum().sum()
print(f"데이터 프레임 내 NaN 값 총 개수: {total_nans}")다음과 같은 결과를 얻을 수 있습니다:
데이터 프레임 내 NaN 값 총 개수: 1248이는 데이터 프레임에 1248개의 다른 NaN이존재함을 의미합니다. 하나 이상의 NaN을 포함하는 행을 제거하려면 다음을 입력하세요:
data = data.dropna()이제 데이터 데이터 프레임에는 NaN이없으며, 결과가 왜곡될 염려 없이 Python 데이터 분석을 수행할 준비가 되었습니다.
이 과정이 제대로 진행되었는지 확인하려면 다음을 작성하세요:
print(data.isna().sum().sum())예상 결과는 0입니다.
4단계: 데이터 탐색
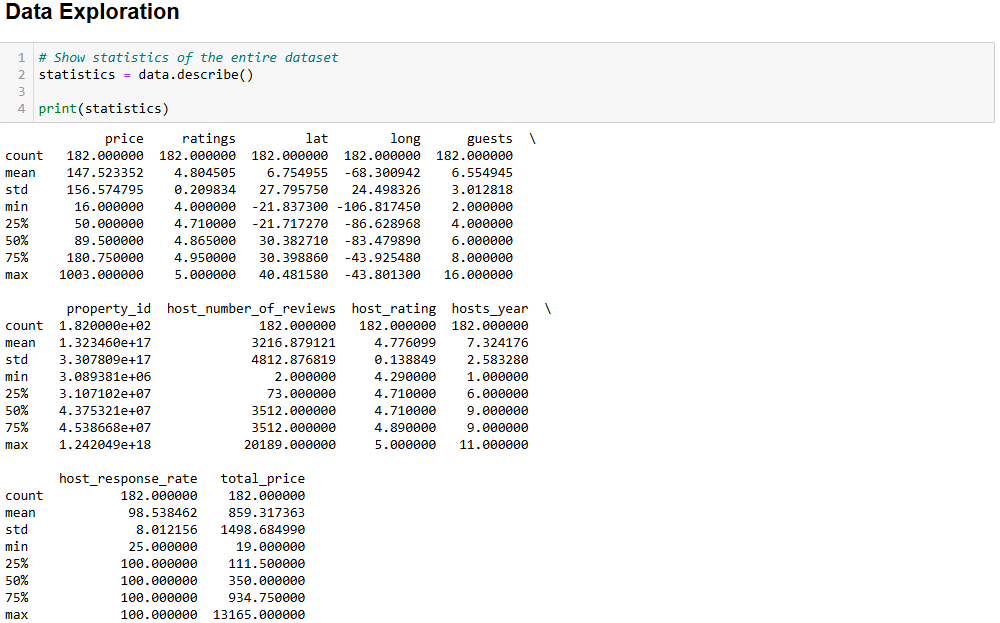
에어비앤비 데이터를 시각화하기 전에 데이터에 익숙해져야 합니다. 좋은 방법은 다음과 같이 데이터셋의 통계 정보를 시각화하는 것부터 시작하는 것입니다:
# 전체 데이터셋 통계 표시
statistics = data.describe()
# 통계 출력
print(statistics)예상 결과는 다음과 같습니다:
가격 평점 위도 경도 게스트 수
182.000000 182.000000 182.000000 182.000000 182.000000
mean 147.523352 4.804505 6.754955 -68.300942 6.554945
표준편차 156.574795 0.209834 27.795750 24.498326 3.012818
min 16.000000 4.000000 -21.837300 -106.817450 2.000000
25% 50.000000 4.710000 -21.717270 -86.628968 4.000000
50% 89.500000 4.865000 30.382710 -83.479890 6.000000
75% 180.750000 4.950000 30.398860 -43.925480 8.000000
최대 1003.000000 5.000000 40.481580 -43.801300 16.000000
property_id host_number_of_reviews host_rating hosts_year
count 1.820000e+02 182.000000 182.000000 182.000000
mean 1.323460e+17 3216.879121 4.776099 7.324176
std 3.307809e+17 4812.876819 0.138849 2.583280
min 3.089381e+06 2.000000 4.290000 1.000000
25% 3.107102e+07 73.000000 4.710000 6.000000
50% 4.375321e+07 3512.000000 4.710000 9.000000
75% 4.538668e+07 3512.000000 4.890000 9.000000
최대 1.242049e+18 20189.000000 5.000000 11.000000
호스트 응답률 총 가격
개수 182.000000 182.000000
평균 98.538462 859.317363
표준편차 8.012156 1498.684990
min 25.000000 19.000000
25% 100.000000 111.500000
50% 100.000000 350.000000
75% 100.000000 934.750000
max 100.000000 13165.000000 describe() 메서드는 수치형 값을 가진 열과 관련된 통계를 보고합니다. 이는 데이터를 이해하기 위한 첫 번째 방법입니다. 예를 들어, host_rating 열은 다음과 같은 흥미로운 통계를 보고합니다:
- 데이터셋에는 총 182개의 리뷰가 있습니다(
count값). - 최대 평점은 5점, 최소 평점은 4.29점, 평균 평점은 4.77점입니다.
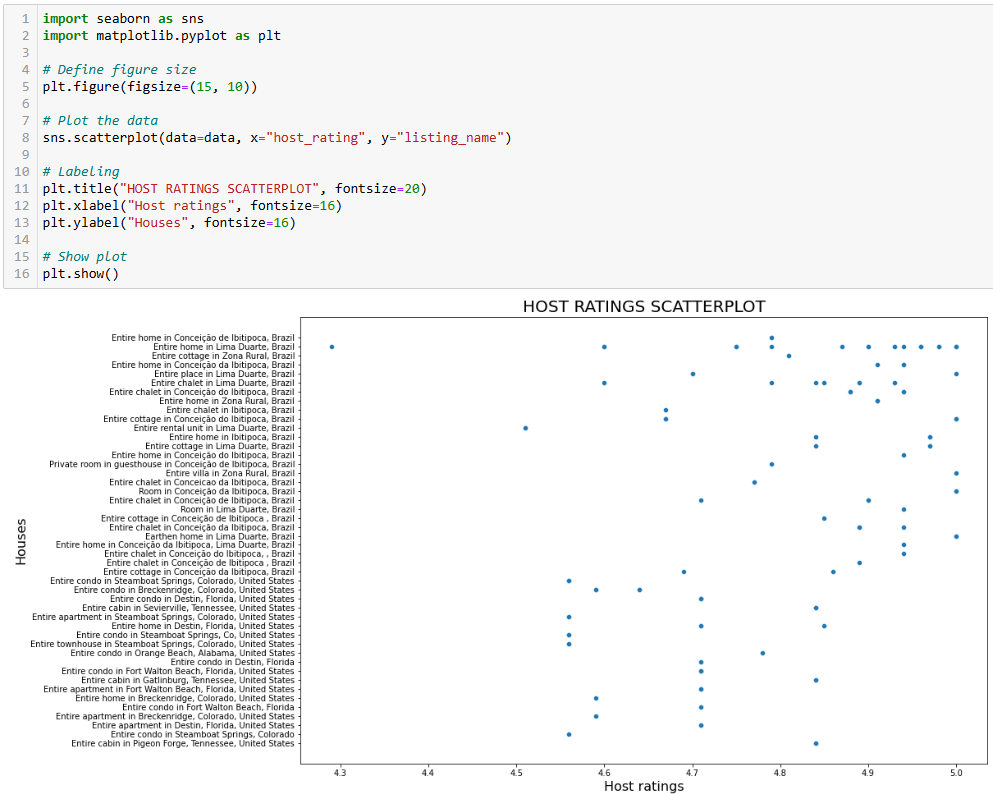
그러나 위 통계만으로는 충분하지 않을 수 있습니다. 따라서 host_rating 열의 산점도를 시각화하여 추후 조사할 만한 흥미로운 패턴이 있는지 확인해 보세요. seaborn을 사용해 산점도를 생성하는 방법은 다음과 같습니다:
import seaborn as sns
import matplotlib.pyplot as plt
# 그림 크기 정의
plt.figure(figsize=(15, 10))
# 데이터 플롯
sns.scatterplot(data=data, x="host_rating", y="listing_name")
# 레이블 지정
plt.title("호스트 평점 산점도", fontsize=20)
plt.xlabel("호스트 평점", fontsize=16)
plt.ylabel("숙소", fontsize=16)
# 플롯 표시
plt.show()위의 코드 조각은 다음을 수행합니다:
figure()메서드를 사용하여 이미지 크기(인치 단위)를 정의합니다.- seaborn의
scatterplot()메서드를 사용하여 산점도를 생성합니다. 구성 옵션:data=data:데이터데이터프레임을 사용해야 함을 의미합니다.x="host_rating": 수평축에 호스트 평점 값을 표시합니다.y="listing_name": 세로축에 부동산 리스팅 이름을 표시합니다.
예상 결과는 다음과 같습니다:
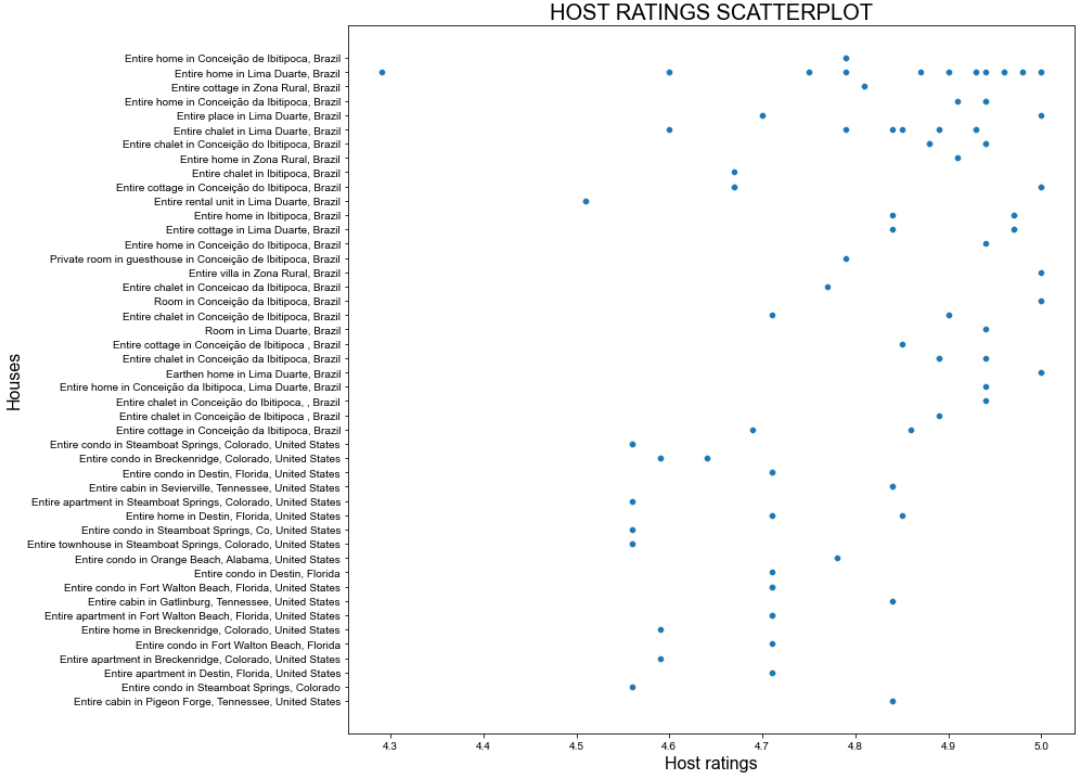
훌륭한 플롯이지만 더 개선할 수 있습니다!
5단계: 데이터 변환 및 시각화
이전 산점도는 호스트 평점에 특별한 패턴이 없음을 보여줍니다. 그러나 대부분의 평점은 4.7점 이상입니다.
휴가를 계획 중이고 최고의 숙소에 머물고 싶다고 상상해 보세요. 스스로에게 던질 수 있는 질문은 “평점 4.8점 이상인 숙소에 머무는 데 비용이 얼마나 들까?”일 것입니다.
이 질문에 답하려면 먼저 데이터를 변환해야 합니다!
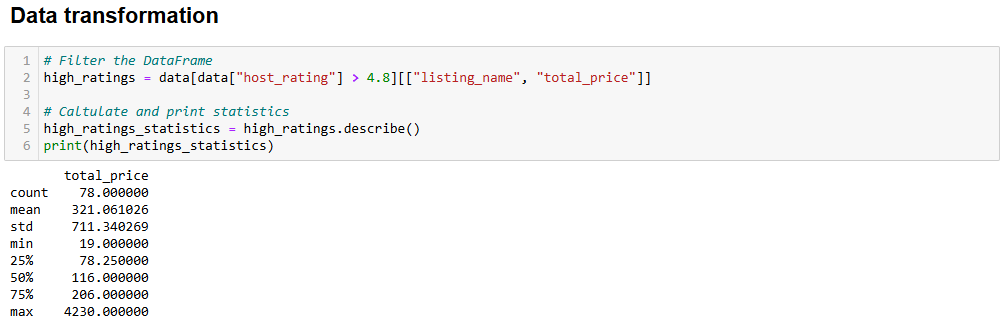
평가가 4.8 이상인 새 데이터프레임을 생성하는 변환을 수행할 수 있습니다. 이 데이터프레임에는 아파트 이름을 나열한 listing_name 열과 가격을 나타낸 total_price 열이 포함됩니다.
해당 하위 집합을 추출하고 통계 정보를 표시하려면 다음을 실행하세요:
# 데이터프레임 필터링
high_ratings = data[data["host_rating"] > 4.8][["listing_name", "total_price"]]
# 통계 계산 및 출력
high_ratings_statistics = high_ratings.describe()
print(high_ratings_statistics)위 코드 조각은 다음과 같이 high_ratings라는 새 데이터프레임을 생성합니다:
data["host_rating"] > 4.8은데이터셋의host_ratings열에서 4.8보다 큰 값을 필터링합니다.[["listing_name", "total_price"]]는high_ratings데이터 프레임에서listing_name과total_price열만 선택합니다.
예상 출력 결과는 다음과 같습니다:
총가격
개수 78.000000
평균 321.061026
표준편차 711.340269
최소값 19.000000
25% 78.250000
50% 116.000000
75% 206.000000
max 4230.000000통계에 따르면 선택된 아파트의 평균 총 가격은 $321이며, 최소 $19에서 최대 $4230까지 분포합니다. 이에 대한 추가 분석이 필요합니다!
이전과 동일한 코드 조각을 사용하여 평점이 높은 주택의 가격 산점도를 시각화하세요. 차트에 사용되는 변수를 다음과 같이 변경하기만 하면 됩니다:
# 그림 크기 정의
plt.figure(figsize=(12, 8))
# 데이터 플롯
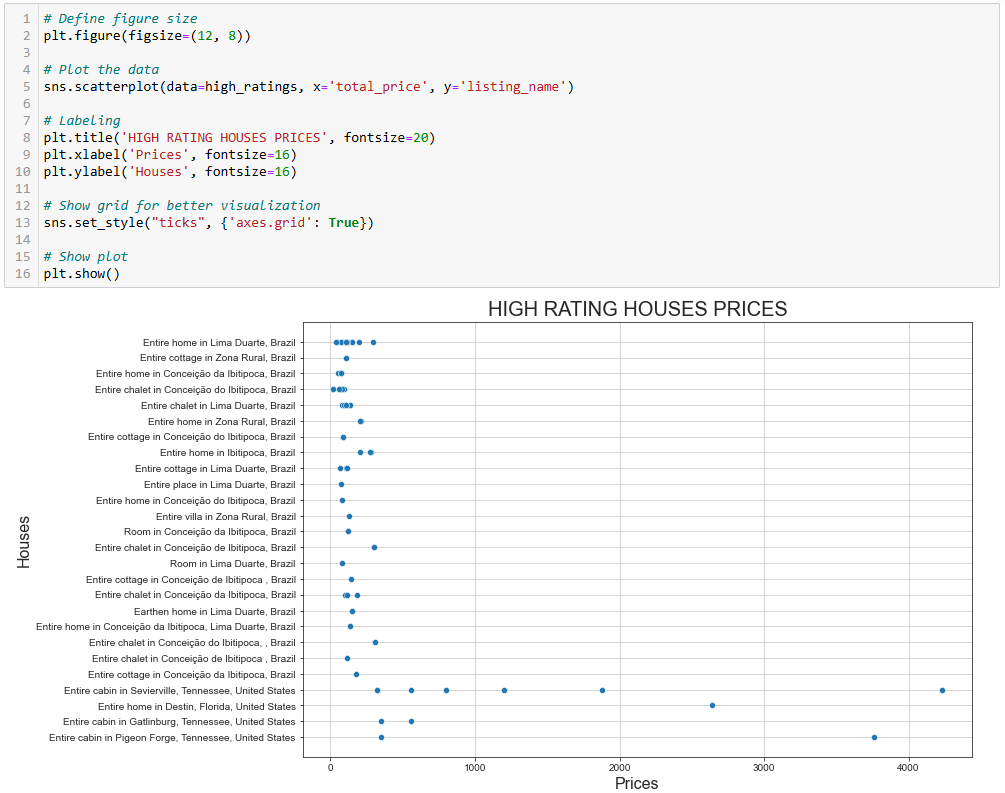
sns.scatterplot(data=high_ratings, x='total_price', y='listing_name')
# 레이블링
plt.title('HIGH RATING HOUSES PRICES', fontsize=20)
plt.xlabel('가격', fontsize=16)
plt.ylabel('주택 수', fontsize=16)
# 시각화 개선을 위한 그리드 표시
sns.set_style("ticks", {'axes.grid': True})
# 플롯 표시
plt.show()그리고 결과 플롯은 다음과 같습니다:
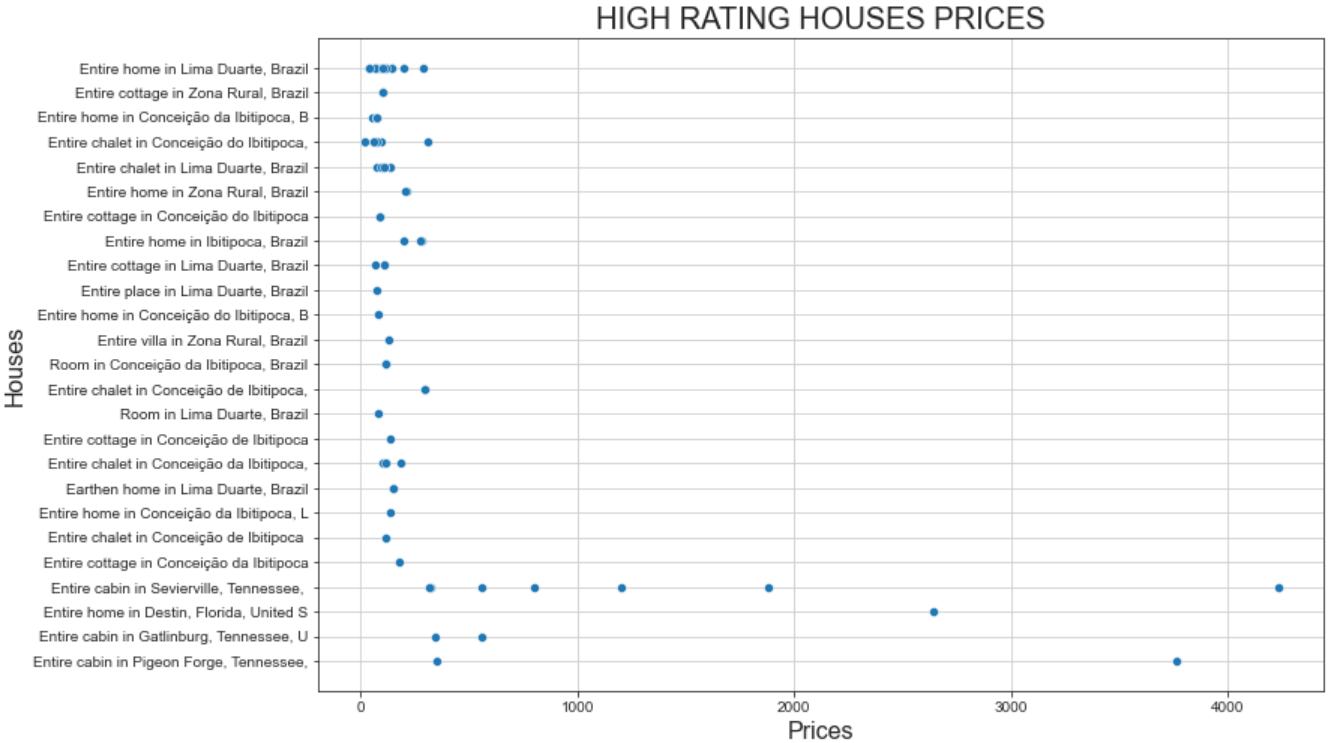
이 플롯은 두 가지 흥미로운 사실을 보여줍니다:
- 가격은 대부분 500달러 미만입니다.
- “세비어빌의 전체 캐빈”과 “피전빌의 전체 캐빈”은 가격이 $1000를 훨씬 초과합니다.
가격 범위를 시각화하는 더 나은 방법은 박스 플롯을 표시하는 것입니다. 방법은 다음과 같습니다:
# 그림 크기 정의
plt.figure(figsize=(15, 10))
# 박스 플롯 그리기
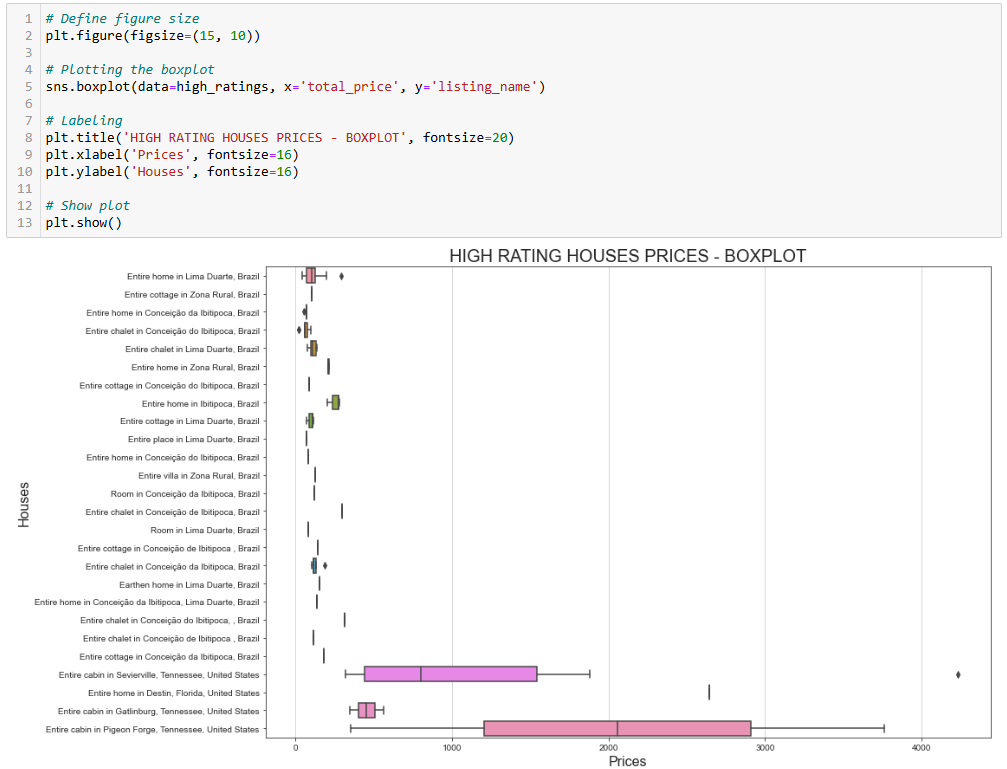
sns.boxplot(data=high_ratings, x='total_price', y='listing_name')
# 레이블 지정
plt.title('고평가 주택 가격 - 박스 플롯', fontsize=20)
plt.xlabel('가격', fontsize=16)
plt.ylabel('주택', fontsize=16)
# 플롯 표시
plt.show()이번에 생성된 차트는 다음과 같습니다:
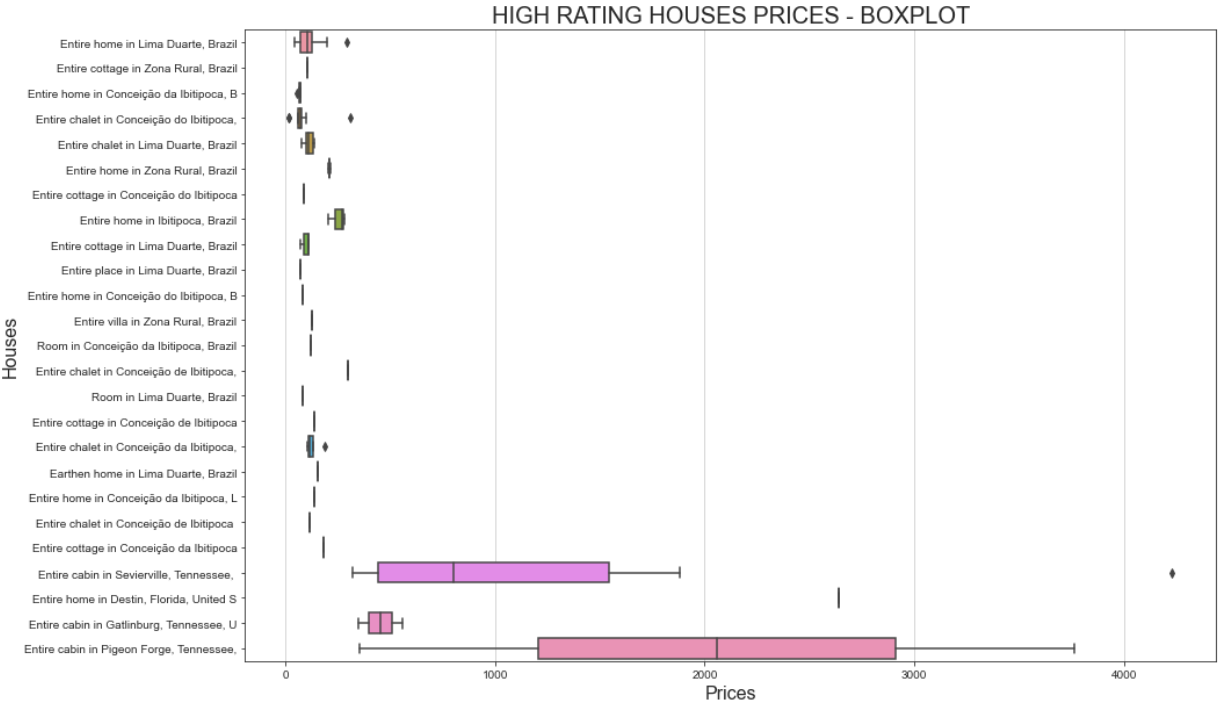
동일한 주택이 왜 다른 가격을 가질 수 있는지 궁금하다면, 사용자 평점을 기준으로 필터링했음을 기억해야 합니다. 이는 서로 다른 사용자가 다른 금액을 지불하고 다른 평점을 남겼음을 의미합니다.
또한 “세비어빌의 전체 캐빈”의 경우 1,000달러 미만부터 4,000달러 이상까지 가격 변동이 큰 것은 숙박 기간과 관련이 있을 수 있습니다. 자세히 보면 원본 데이터셋에는 숙박 기간 정보를 담은 travel_details 열이 포함되어 있습니다. 이처럼 가격 범위가 넓다는 것은 일부 사용자가 장기간 숙소를 임대했음을 시사할 수 있습니다. Python을 활용한 심층 분석을 통해 이에 대한 더 많은 통찰력을 얻을 수 있을 것입니다!
6단계: 상관 행렬을 통한 추가 조사
파이썬 데이터 분석은 보유한 데이터 내에서 질문을 던지고 답을 찾는 과정입니다. 이러한 질문을 촉발하는 효과적인 방법 중 하나는 상관 행렬을 시각화하는 것입니다.
상관 행렬은 서로 다른 변수 간의 상관 계수를 보여주는 표입니다. 가장 널리 사용되는 상관 계수는 피어슨 상관계수(PCC)로, 두 변수 간의 선형 상관관계를 측정합니다. 그 값은 -1에서 +1 사이이며, 이는 다음과 같은 의미를 가집니다:
- +1: 한 변수의 값이 증가하면 다른 변수도 선형적으로 증가합니다.
- -1: 한 변수의 값이 증가하면 다른 변수의 값이 선형적으로 감소합니다.
- 0: 두 변수 간의 선형 관계에 대해 아무것도 말할 수 없음(비선형 분석이 필요함).
통계학에서 선형 상관관계의 값은 다음과 같이 정의됩니다:
- 0.1-0.5: 낮은 상관관계.
- 0.6-1: 높은 상관관계.
- 0: 상관관계 없음.
데이터 데이터 프레임의 상관 행렬을 표시하려면 다음을 입력하세요:
# 이미지 크기 설정
plt.figure(figsize=(12, 10))
# 레이블링
plt.title('상관 행렬', fontsize=20)
plt.xticks(fontsize=16) # x축 글자 크기
plt.yticks(fontsize=16) # y축 글자 크기
# 마스크 적용
mask = np.triu(np.ones_like(numeric_data.corr()))
dataplot = sns.heatmap(numeric_data.corr(), annot=True, fmt='.2f', mask=mask, annot_kws={"size": 12})
# 상관 행렬 생성 전에 이 코드 추가
numeric_data = data.select_dtypes(include=['float64', 'int64'])
# 상관 행렬
dataplot = sns.heatmap(data.corr(), annot=True, fmt='.2f', mask=mask, annot_kws={"size": 12})위 코드 조각은 다음과 같은 작업을 수행합니다:
np.triu()메서드는 행렬을 대각화하는 데 사용됩니다. 이는 행렬을 사각형이 아닌 삼각형 형태로 표시하여 시각화를 개선하기 위한 것입니다.sns.heatmap()메서드는 히트맵을 생성합니다. 이 역시 시각화 개선을 위한 것입니다. 내부에서data.corr()메서드는데이터프레임data의각 열에 대해 피어슨 상관계수를 실제로 계산합니다.
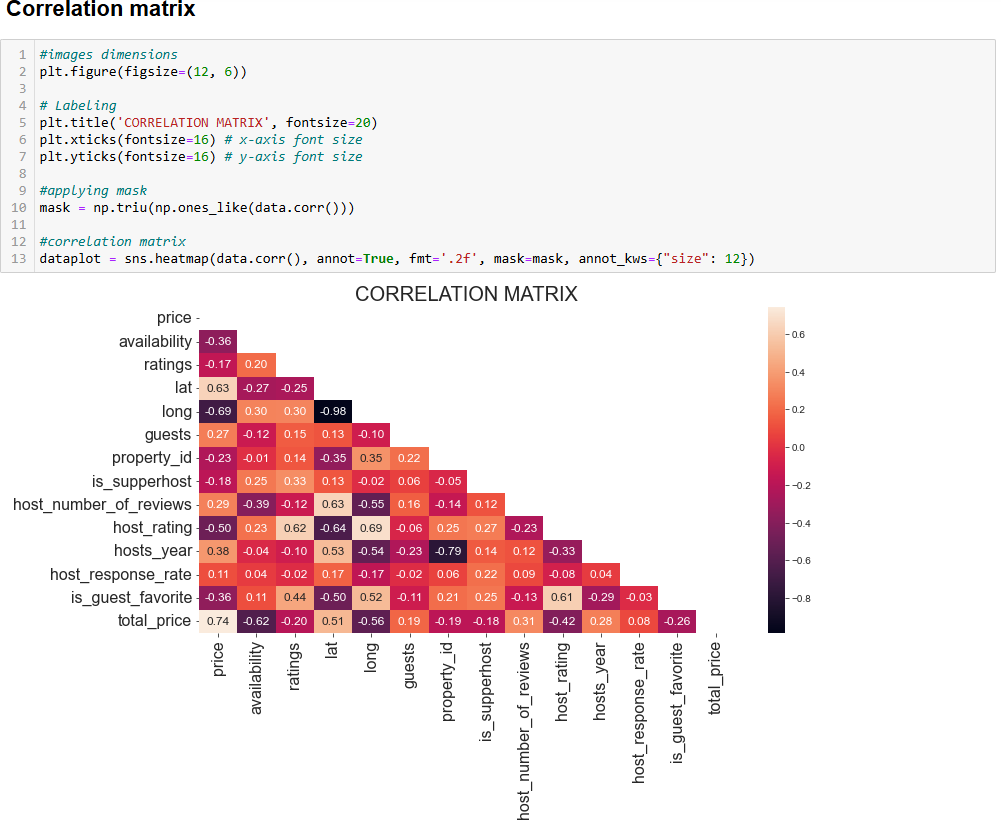
아래는 얻게 될 결과입니다:
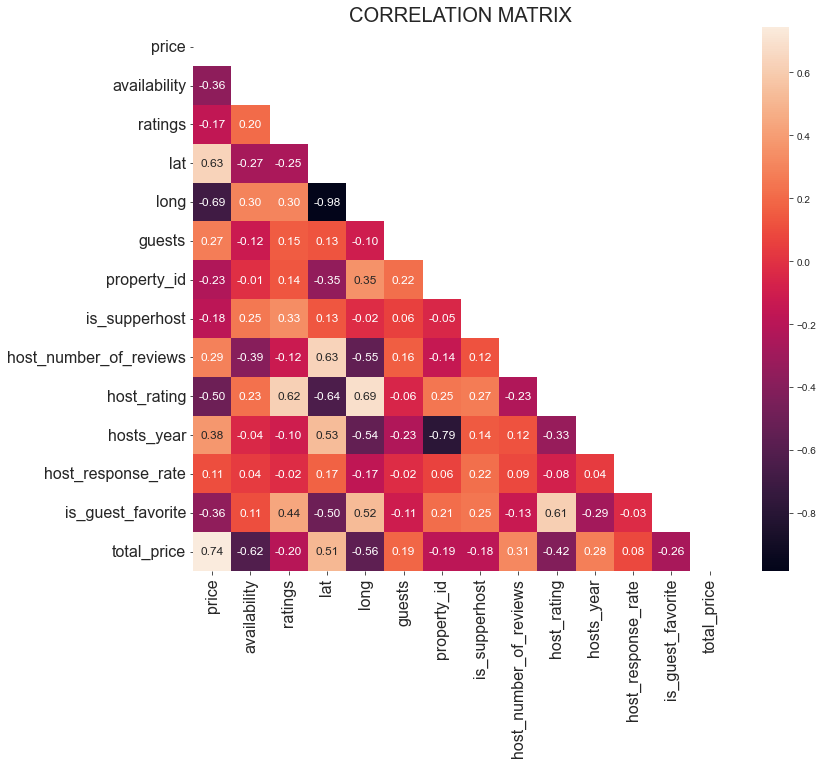
상관 행렬을 해석할 때 핵심은 높은 상관관계를 보이는 변수를 찾는 것입니다. 이는 새로운 심층 분석의 출발점이 되기 때문입니다. 예를 들어:
lat및long변수 간 상관관계는 -0.98입니다. 이는 지구의 특정 위치를 정의할 때 위도와 경도가 강하게 연관되므로 예상된 결과입니다.host_rating과long변수는 -0.69의 상관관계를 보입니다. 이는 흥미로운 결과로, 호스트 평점이 경도 변수와 매우 높은 상관관계가 있음을 의미합니다. 따라서 세계 특정 지역에 위치한 주택들은 높은 호스트 평점을 받는 것으로 보입니다.위도(lat)와경도(long) 변수는 각각가격(price)과 0.63, -0.69의 상관관계를 보입니다. 이는 일일 가격이 위치에 크게 영향을 받는다는 것을 충분히 시사합니다.
분석 시 상관관계가 없는 변수도 찾아보아야 합니다. 예를 들어, is_supperhost 변수와 가격 간의 계수는 -0.18로, 슈퍼호스트가 반드시 가장 높은 가격을 책정하는 것은 아님을 의미합니다.
주요 개념을 이해하셨으니, 이제 여러분이 직접 데이터를 탐색하고 분석해 보세요!
7단계: 종합하기
파이썬을 활용한 데이터 분석 최종 Jupyter Notebook은 다음과 같습니다:
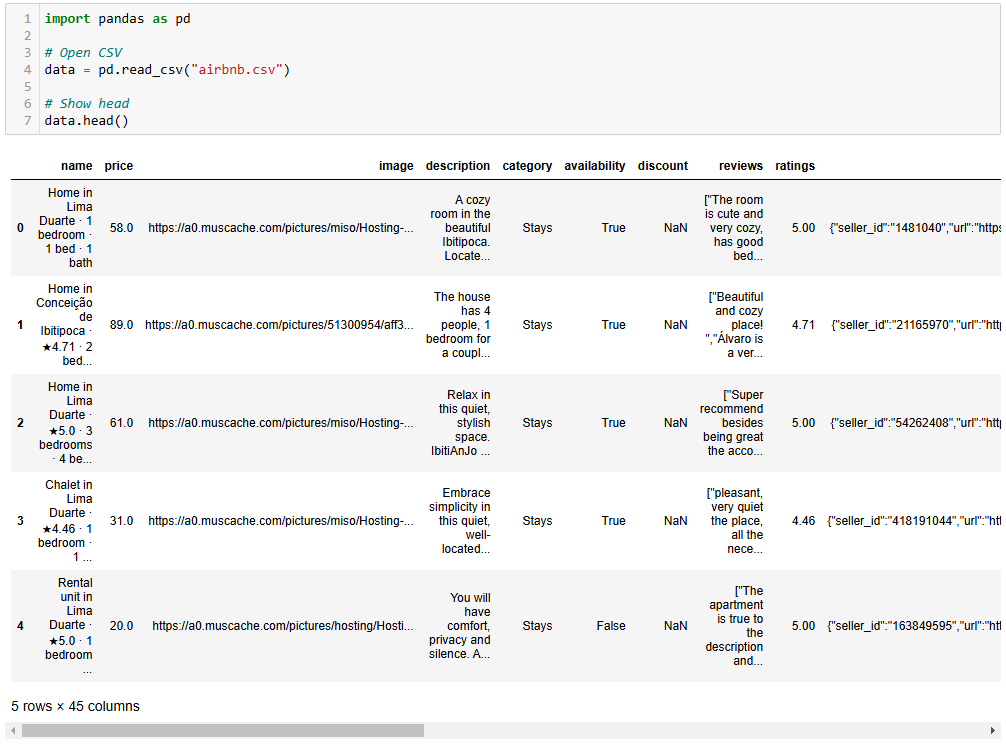
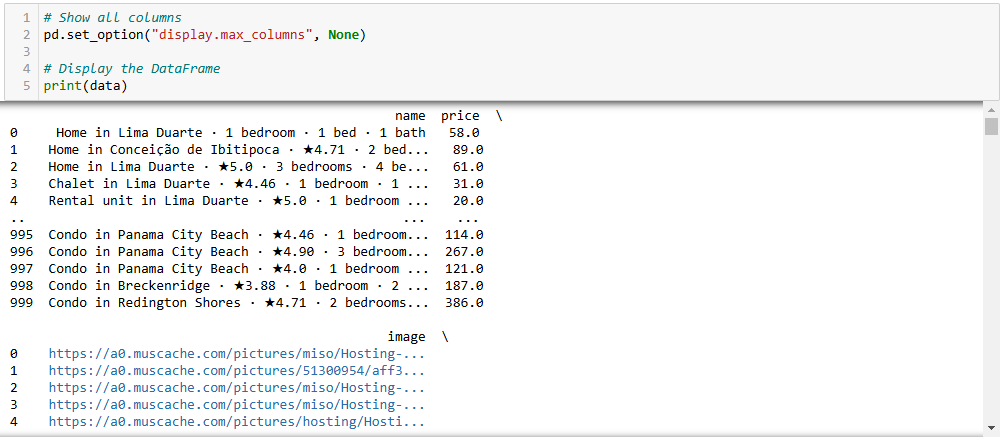
각 셀마다 출력 결과가 표시되는 것을 확인하세요.
파이썬을 활용한 데이터 분석의 과정
위 섹션에서는 Python을 활용한 데이터 분석 과정을 안내했습니다. 기회 중심의 단계별 접근법처럼 보일 수 있지만, 실제로는 다음과 같은 모범 사례를 기반으로 구성되었습니다:
- 데이터 수집: 필요한 데이터가 데이터베이스에 있다면 정말 운이 좋은 것입니다! 그렇지 않다면웹 스크래핑과 같은 일반적인 데이터 소싱 방법을 사용하여 데이터를 수집해야 합니다.
- 데이터 정리:
NaN처리, 데이터 집계, 초기 데이터셋에 대한 첫 번째 필터 적용. - 데이터 탐색: 데이터 탐색(때로는 데이터 발견이라고도함)은 파이썬을 활용한 데이터 분석에서 가장 중요한 부분입니다. 데이터의 구조나 특정 패턴을 파악하는 데 도움이 되는 기본적인 플롯을 생성해야 합니다.
- 데이터 조작: 분석 대상 데이터의 핵심 개념을 파악한 후에는 이를 조작해야 합니다. 이 단계에서는 데이터셋을 필터링하고, 종종 두 개 이상의 데이터셋을 하나로 결합해야 합니다(SQL에서 테이블 조인을 수행하는 것과 유사합니다).
- 데이터 시각화: 이 단계는 최종 단계로, 조작된 데이터셋에 대해 여러 플롯을 생성하여 데이터를 시각적으로 제시합니다.
결론
이 파이썬 데이터 분석 가이드에서는 데이터 분석에 파이썬을 사용해야 하는 이유와 해당 목적에 활용할 수 있는 일반적인 라이브러리를 알아보았습니다. 또한 단계별 튜토리얼을 통해 파이썬으로 데이터 분석을 수행할 때 따라야 할 과정을 학습했습니다.
Jupyter Notebook이 데이터의 하위 집합을 생성하고, 이를 시각화하며, 강력한 통찰력을 발견하는 데 도움이 된다는 점을 확인했습니다. 이 모든 작업을 동일한 환경에서 체계적으로 유지하면서 수행할 수 있습니다. 그렇다면 바로 사용할 수 있는 데이터셋은 어디서 찾을 수 있을까요? Bright Data가 해결해 드립니다!
Bright Data는 포춘 500대 기업을 비롯한 20,000여 고객사가 이용하는 대규모, 고속, 안정적인 프록시 네트워크를 운영합니다. 이 네트워크를 통해 웹에서 윤리적으로 데이터를 수집하여 방대한 데이터셋 마켓플레이스에 제공합니다. 여기에는 다음이 포함됩니다:
- 비즈니스 데이터셋: LinkedIn, CrunchBase, Owler, Indeed 등 주요 출처의 데이터.
- 이커머스 데이터셋: Amazon, Walmart, Target, Zara, Zalando, Asos 등 다양한 플랫폼의 데이터.
- 부동산 데이터셋: 질로우(Zillow), MLS 등 웹사이트의 데이터.
- 소셜 미디어 데이터셋: Facebook, Instagram, YouTube, Reddit 등에서 수집한 데이터.
- 금융 데이터셋: 야후 파이낸스, 마켓워치, 인베스토피디아 등에서 수집한 데이터.
지금 바로 무료 Bright Data 계정을 생성하고 당사의 데이터 세트를 살펴보세요.





