이 가이드에서는 다음을 배울 수 있습니다:
- Jupyter Notebooks란 무엇인가
- 웹 스크래핑에 Jupyter Notebook을 사용해야 하는 이유
- 단계별 튜토리얼에서 활용하는 방법
- 온라인 데이터 스크래핑을 위한 Jupyter Notebook 활용 사례
자, 시작해 보겠습니다!
Jupyter Notebooks란 무엇인가?
Jupyter의 맥락에서노트북은“컴퓨터 코드, 평문 설명, 데이터, 차트, 그래프 및 그림, 상호작용 컨트롤을 결합한 공유 가능한 문서”입니다.
노트북은 코드 프로토타이핑 및 설명, 데이터 탐색 및 시각화, 아이디어 공유를 위한 대화형 환경을 제공합니다. 특히Jupyter Notebook App으로생성된 노트북을 Jupyter Notebooks라고 합니다.
Jupyter Notebook App은 웹 브라우저를 통해노트북 문서를편집하고 실행할 수 있는 서버-클라이언트 애플리케이션입니다. 로컬 데스크톱에서 실행하거나 원격 서버에 설치할 수 있습니다.
Jupyter Notebook은 소위 “커널”을 제공하는데, 이는 노트북 문서에 포함된 코드를 실행하는 “계산 엔진”입니다. 구체적으로ipython커널은 Python 코드를 실행합니다(다른 언어의 커널도 존재함):
Jupyter Notebook 앱은 로컬 파일 표시, 기존 노트북 문서 열기, 문서 커널 관리 등 일반적인 작업을 지원하는 대시보드를 제공합니다:
웹 스크래핑에 Jupyter Notebook을 사용해야 하는 이유는 무엇인가요?
Jupyter Notebook은 데이터 분석 및 연구 개발 목적으로 특별히 설계되었으며, 다음과 같은 특성으로 인해 웹 스크래핑에 유용합니다:
- 대화형 개발: 셀이라고 하는 작고 관리하기 쉬운 단위로 코드를 작성하고 실행합니다. 각 셀은 다른 셀과 독립적으로 작동할 수 있습니다. 이는 테스트와 디버깅을 단순화합니다.
- 구성: 셀 내에서 마크다운을 사용하여 코드를 문서화하고, 논리를 설명하며, 메모나 지침을 추가할 수 있습니다.
- 데이터 분석 도구와의 통합: 스크래핑 후, Jupyter Notebooks가
pandas,matplotlib,seaborn등의 라이브러리와 통합되어 Python에서 데이터를 즉시 정리, 처리 및 분석할 수 있습니다. - 재현성 및 공유: Jupyter Notebook은
.ipynb파일(표준 형식)로 다른 사람과 쉽게 공유하거나ReST, 마크다운 등 다른 형식으로 변환할 수 있습니다.
장단점
데이터 스크래핑에 Jupyter Notebook을 사용할 때의 장단점은 다음과 같습니다:
👍장점:
- 단계별 디버깅: 각 셀이 독립적으로 실행되므로 데이터 추출 코드를 여러 셀로 분할하여 실행할 수 있습니다. 이를 통해 셀 단위로 코드를 실행하고 오류를 포착함으로써 작은 코드 조각을 디버깅할 수 있습니다.
- 문서화: 셀 내 마크다운을 활용하여 스크래핑 코드의 작동 방식과 선택한 논리를 설명하는 문서 파일을 생성할 수 있습니다.
- 유연성: Jupyter Notebooks에서는 웹 스크래핑, 데이터 정리, 분석을 단일 환경에서 결합할 수 있습니다. 이를 통해 스크래핑 스크립트를 IDE에 작성하고 데이터를 다른 곳에서 분석하는 등 서로 다른 환경 간 전환이 가능합니다.
👎단점:
- 대규모 프로젝트에 부적합: Jupyter Notebook은 문서가 길어지는 경향이 있어 대규모 데이터 스크래핑 프로젝트에는 적합하지 않습니다.
- 성능 한계: 대규모 데이터셋 작업이나 긴 스크립트 실행 시 노트북이 느려지거나 응답이 중단될 수 있습니다.웹 스크래핑 속도 향상 방법에 대해 자세히 알아보세요.
- 자동화에 적합하지 않음: 스크레이퍼를 일정대로 실행하거나 대규모 시스템의 일부로 배포해야 하는 경우 Jupyter Notebooks는 최선의 선택이 아닙니다. 이는 셀의 대화형 수동 실행을 주로 위해 설계되었기 때문입니다.
웹 스크래핑을 위한 Jupyter Notebook 사용법: 단계별 튜토리얼
이제 웹 스크래핑에 Jupyter Notebooks를 사용해야 하는 이유를 알게 되었습니다. 따라서 실제 스크래핑 시나리오에서 이를 활용하는 방법을 살펴볼 준비가 되었습니다!
필수 조건
이 튜토리얼을 따라 하려면 시스템이 다음 요구 사항을 충족해야 합니다:
- Python 3.6 이상: 3.6보다 높은 버전의 Python이면 됩니다. 특히,
pip를통해 종속성을 설치할 예정인데, pip는 3.4보다 높은 Python 버전과 함께 이미 설치되어 있습니다.
1단계: 환경 설정 및 종속성 설치
프로젝트의 메인 폴더를 scraper/라고 가정합니다 . 이 단계가 끝나면 폴더 구조는 다음과 같아집니다:
scraper/
├── analysis.ipynb
└── venv/
여기서:
analysis.ipynb: 모든 코드가 포함된 Jupyter Notebook 파일입니다.venv/에는가상 환경이 포함됩니다.
venv/ 가상 환경 디렉터리는 다음과 같이 생성할 수 있습니다:
python -m venv venv
활성화하려면 Windows에서 다음을 실행하세요:
venvScriptsactivate
macOS/Linux에서는 다음과 같이 실행합니다:
source venv/bin/activate
활성화된 가상 환경에서 이 튜토리얼에 필요한 모든 라이브러리를 설치하세요:
pip install requests beautifulsoup4 pandas jupyter seaborn
이 라이브러리들은 다음과 같은 용도로 사용됩니다:
requests: HTTP 요청 수행.beautifulsoup4: HTML 및 XML 문서 파싱을 위한 라이브러리입니다.pandas: 강력한 데이터 조작 및 분석 라이브러리로, CSV 파일이나 테이블과 같은 구조화된 데이터 작업에 이상적입니다.jupyter: Python 코드 실행 및 공유를 위한 웹 기반 대화형 개발 환경으로, 분석 및 시각화에 탁월합니다.seaborn:Matplotlib 기반의 Python 데이터 시각화 라이브러리입니다.
분석용 analysis.ipynb 파일을 생성하려면 먼저 scraper/ 폴더로 이동해야 합니다:
cd scraper
그런 다음 다음 명령어로 새로운 Jupyter Notebook을 초기화합니다:
jupyter notebook
이제 로컬호스트 8888을 통해 Jupyter Notebook 앱에 접속할 수 있습니다.
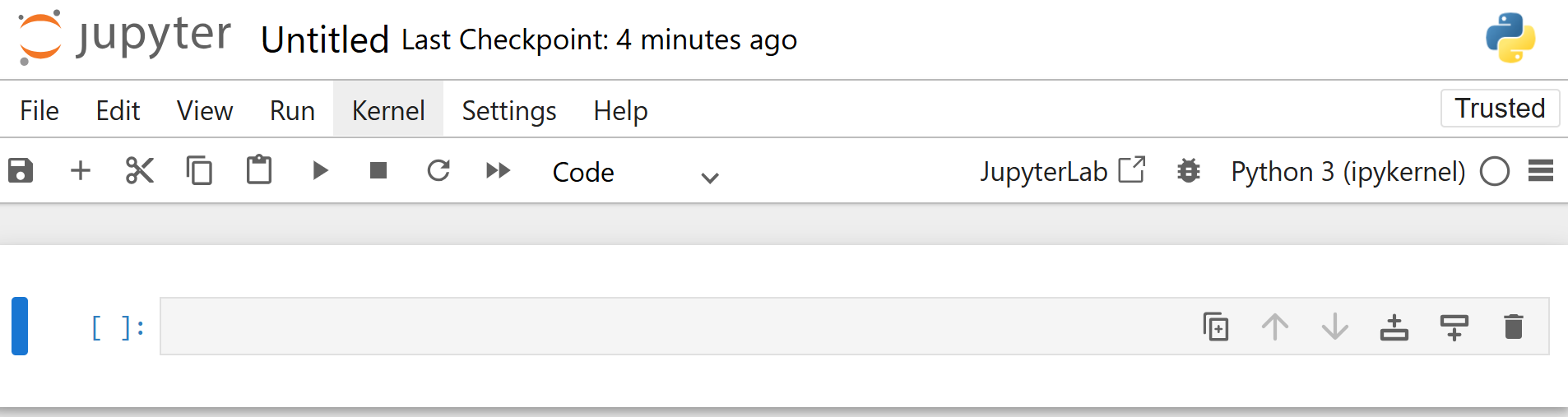
“새로 만들기 > Python 3” 옵션을 클릭하여 새 파일을 생성합니다:
새 파일은 자동으로untitled.ipynb로 저장됩니다. 대시보드에서 이름을 변경할 수 있습니다:
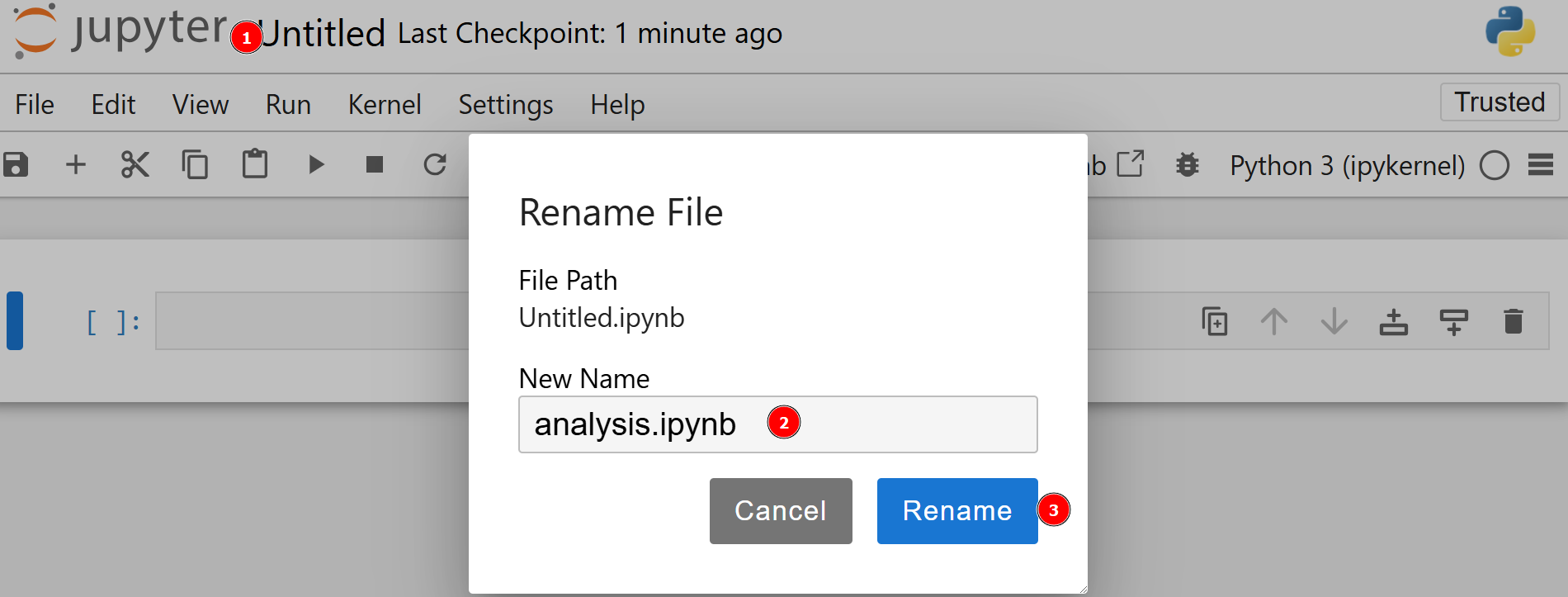
잘하셨습니다! 이제 Jupyter Notebook으로 웹 스크래핑을 위한 모든 설정이 완료되었습니다.
2단계: 대상 페이지 정의
이 튜토리얼에서는worldometer 웹사이트의 데이터를 스크래핑합니다. 특히, 대상 페이지는 다음과 같은 표 형식의 데이터를 제공하는미국연간이산화탄소 배출량관련 페이지입니다:
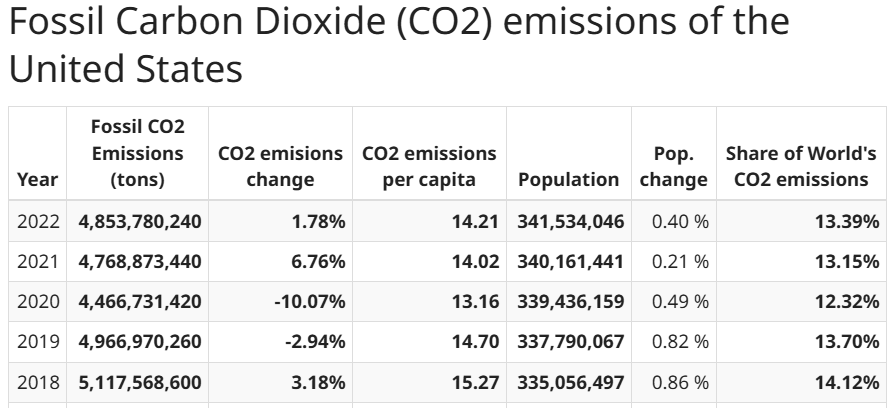
3단계: 데이터 추출
대상 페이지의 데이터를 가져와 다음과 같이 CSV 파일로 저장할 수 있습니다:
import requests
from bs4 import BeautifulSoup
import csv
# 웹사이트 URL
url = "https://www.worldometers.info/co2-emissions/us-co2-emissions/"
# 웹사이트에 GET 요청 전송
response = requests.get(url)
response.raise_for_status()
# HTML 콘텐츠 파싱
soup = BeautifulSoup(response.text, "html.parser")
# 테이블 위치 파악
table = soup.find("table")
# 테이블 헤더 추출
headers = [header.text.strip() for header in table.find_all("th")]
# 테이블 행 추출
rows = []
for row in table.find_all("tr")[1:]: # 헤더 행 건너뛰기
cells = row.find_all("td")
row_data = [cell.text.strip() for cell in cells]
rows.append(row_data)
# 데이터를 CSV 파일에 저장
csv_file = "emissions.csv"
with open(csv_file, mode="w", newline="", encoding="utf-8") as file:
writer = csv.writer(file)
writer.writerow(headers) # 헤더 기록
writer.writerows(rows) # 행 기록
print(f"데이터가 {csv_file}에 저장되었습니다")
이 코드의 동작은 다음과 같습니다:
therequests라이브러리를 사용하여requests.get()메서드로 대상 페이지에 GET 요청을 전송하고,response.raise_for_status()메서드로 요청 오류를 확인합니다.BeautifulSoup() 클래스를인스턴스화하고soup.find()메서드로테이블선택자를 찾아 HTML 콘텐츠를파싱합니다. 특히 이 메서드는 데이터를 포함하는 테이블을 찾는 데 유용합니다. 이 구문에 익숙하지 않다면BeautifulSoup 웹 스크래핑 가이드를 참고하세요.- 리스트 이해를 사용하여 테이블 헤더를 추출합니다.
- 헤더 행을 건너뛰면서 테이블의 모든 데이터를 가져오기 위해
for루프를 사용합니다. - 마지막으로 새 CSV 파일을 열고 추출한 모든 데이터를 여기에 추가합니다.
이 코드를 셀에 붙여넣고 SHIFT+ENTER를 눌러 실행할 수 있습니다.
셀을 실행하는 또 다른 방법은 셀을 선택한 후 대시보드의 “실행” 버튼을 누르는 것입니다:
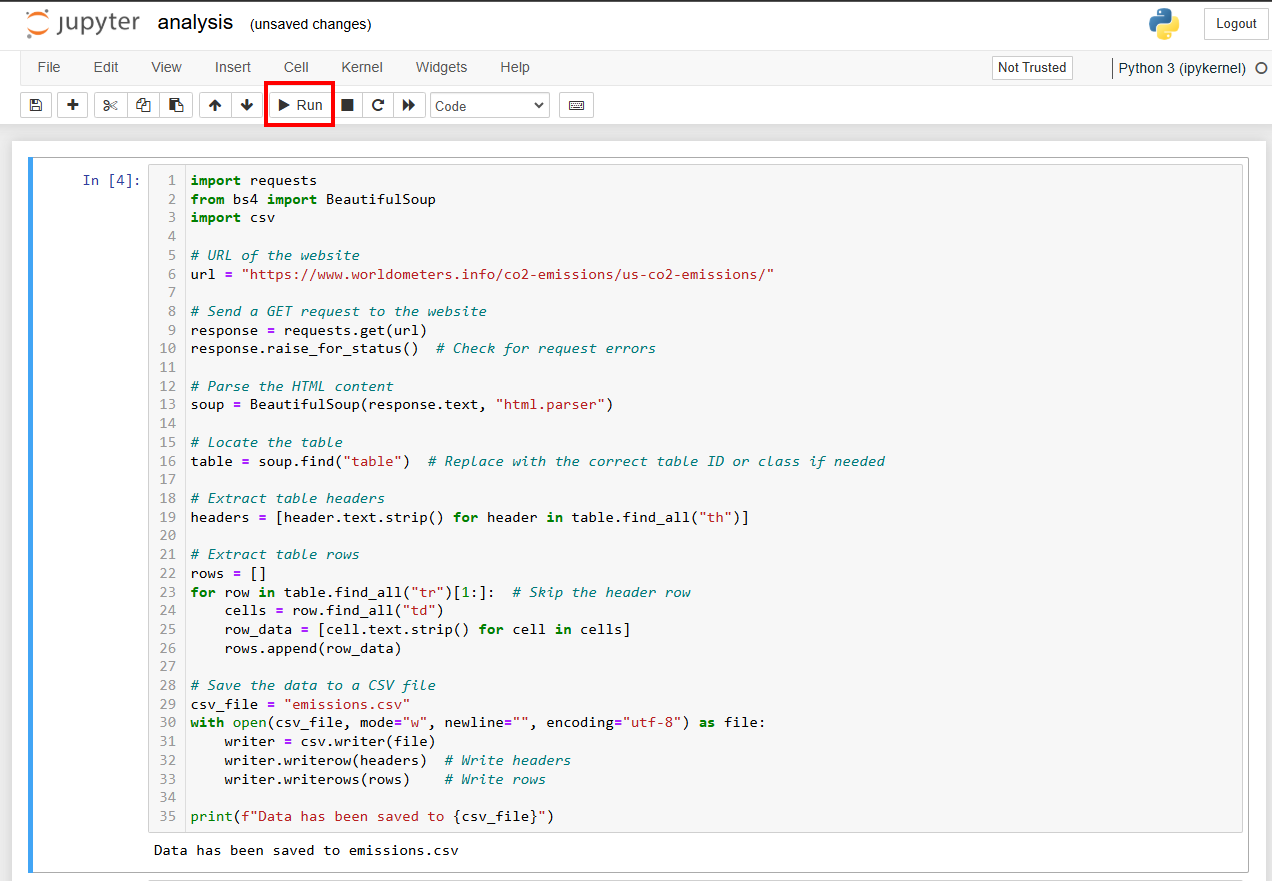
놀랍게도, “데이터가 emissions.csv에 저장되었습니다”라는 메시지가 성공적인 데이터 추출 작업을 알려줍니다.
4단계: 데이터 정확성 확인
이제 데이터를 CSV 파일에 저장했습니다. CSV 파일을 열고 모든 것이 잘 진행되었는지 확인하세요. 때로는 변환 문제로 인해 문제가 발생할 수 있습니다. 이를 위해 새 셀에 다음 코드를 입력할 수 있습니다:
import pandas as pd
# CSV 파일을 pandas DataFrame으로 로드
csv_file = "emissions.csv"
df = pd.read_csv(csv_file)
# DataFrame 출력
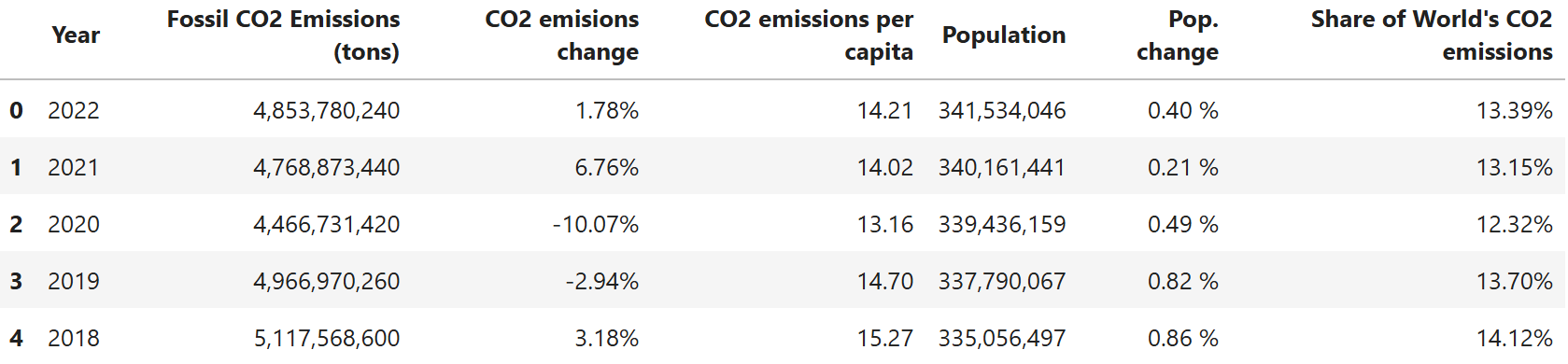
df.head()
이 코드는 다음을 수행합니다:
pandas의pd.read_csv()메서드를 사용하여 CSV 파일을 데이터프레임으로 엽니다.df.head()메서드로 데이터프레임의 첫 5개 행을 출력합니다.
예상 결과는 다음과 같습니다:
훌륭합니다! 이제 추출한 데이터를 시각화하기만 하면 됩니다.
5단계: 데이터 시각화
이제 원하는 데이터 분석을 수행할 수 있습니다. 예를 들어, seaborn을 사용하여 연도별 이산화탄소 배출량 추세를 보여주는 선 그래프를 만들 수 있습니다. 다음과 같이 실행하세요:
import seaborn as sns
import matplotlib.pyplot as plt
# CSV 파일을 pandas DataFrame으로 로드
csv_file = "emissions.csv"
df = pd.read_csv(csv_file)
# 불필요한 공백 제거로 열 이름 정리
df.columns = df.columns.str.strip().str.replace(' ', ' ')
# '화석 연료 CO2 배출량 (톤)' 열을 숫자형으로 변환
df['Fossil CO2 Emissions (tons)'] = df['Fossil CO2 Emissions (tons)'].str.replace(',', '').astype(float)(float)
# '연도' 열이 숫자형인지 확인
df['Year'] = pd.to_numeric(df['Year'], errors='coerce')
df = df.sort_values(by='Year')
# 라인 플롯 생성
plt.figure(figsize=(10, 6))
sns.lineplot(data=df, x='연도', y='화석 연료 CO2 배출량 (톤)', marker='o')
# 레이블과 제목 추가
plt.title('연도별 화석 연료 CO2 배출량 추이', fontsize=16)
plt.xlabel('연도', fontsize=12)
plt.ylabel('화석 연료 CO2 배출량 (톤)', fontsize=12)
plt.grid(True)
plt.show()
이 코드의 기능은 다음과 같습니다:
pandas를사용하여:- CSV 파일을 엽니다.
df.columns.str.strip().str.replace(' ', ' ')메서드로 불필요한 공백을 제거하여 열 이름을 정리합니다(이 작업을 수행하지 않으면 본 예제에서 코드 오류가 발생합니다).- “Fossil CO2 Emissions (tons)” 열에 접근하고
df['Fossil CO2 Emissions (tons)'].str.replace(',', '').astype(float)메서드로 데이터를 숫자로 변환합니다. - “Years” 열에 접근하여
pd.to_numeric()메서드로 값을 숫자로 변환하고,df.sort_values()메서드로 값을 오름차순으로 정렬합니다.
- 실제 플롯을 생성하기 위해
matplotlib및seaborn(matplotlib을기반으로 구축되어seaborn을설치하면 함께 설치됨) 라이브러리를 사용합니다.
예상 결과는 다음과 같습니다:
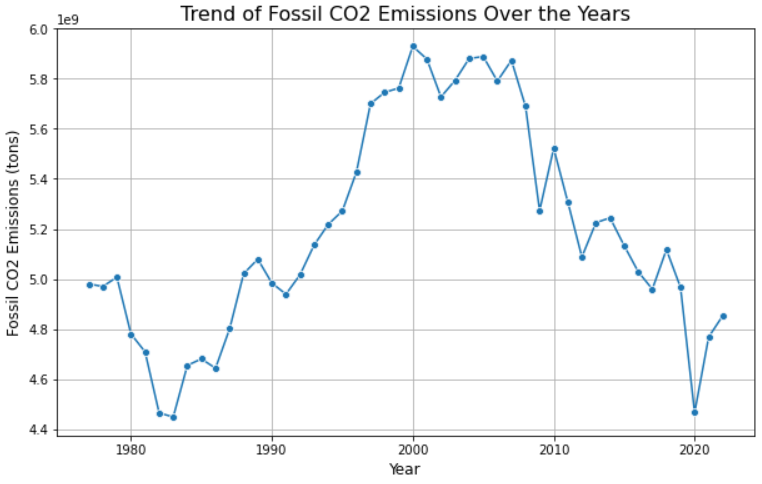
와! Jupyter Notebook 스크래핑이 이렇게 강력하군요.
6단계: 모든 것을 통합하기
최종 Jupyter Notebook 웹 스크래핑 문서는 다음과 같습니다:
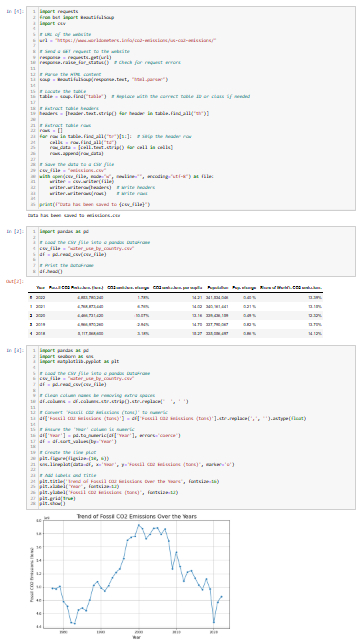
각기 다른 블록이 존재하며, 각각의 출력 결과를 확인할 수 있습니다.
Jupyter Notebook 웹 스크래핑 활용 사례
웹 스크래핑 시 Jupyter Notebook 활용 사례를 살펴볼 시간입니다!
튜토리얼
Jupyter Notebook의 각 셀은 독립적으로 실행될 수 있다는 점을 잊지 마세요. 마크다운(Markdown) 지원이 추가되면서 이 라이브러리는 단계별 튜토리얼을 만드는 데 탁월한 도구가 되었습니다.
예를 들어, 코드가 포함된 셀과 그 뒤에 있는 논리와 추론을 설명하는 셀을 번갈아 가며 사용할 수 있습니다. 웹 스크래핑의 경우, Jupyter Notebooks는 특히 유용합니다. 이들을 사용하여 주니어 개발자를 위한 튜토리얼을 만들고, 프로세스의 각 단계를 안내할 수 있습니다.
과학 및 연구(R&D)
Jupyter Notebook은 상호작용적 특성과 협업을 위한 손쉬운 내보내기 기능 덕분에 연구 및 R&D 목적에 이상적입니다. 특히 웹 스크래핑에 적합합니다. 예를 들어, 여러 번의 시행착오가 필요한 웹사이트를 스크래핑할 때 모든 테스트를 단일 Notebook에 보관하고 Markdown을 사용하여 성공한 테스트를 강조 표시할 수 있습니다.
데이터 탐색
Jupyter 라이브러리는 데이터 탐색 및 분석을 위해 특별히 설계되었습니다. 이는머신 러닝을 위한 웹 스크래핑에도 완벽한 도구입니다.
이 사용 사례는 위에서 코딩한 예제에 직접 적용됩니다. 웹사이트에서 데이터를 가져온 후 동일한 코딩 환경 내에서 즉시 분석할 수 있습니다.
결론
이 글에서는 Jupyter Notebook이 데이터 추출 및 분석을 위한 대화형 유연한 환경을 제공함으로써 웹 스크래핑에 강력한 도구가 될 수 있음을 알아보았습니다. 그러나 웹 스크래핑 작업의 확장이나 작업 자동화 측면에서는 Jupyter Notebook이 가장 효율적인 솔루션이 아닐 수 있습니다.
이때 저희 웹 스크레이퍼가 해결책이 됩니다. API 기반 솔루션을 찾는 개발자이든, 코딩 없이 해결하려는 사용자이든, 저희 웹 스크레이퍼는 데이터 수집 작업을 단순화하고 향상시키도록 설계되었습니다. 100개 이상의 도메인을 위한 전용 엔드포인트, 대량 요청 처리, 자동 IP 로테이션, CAPTCHA 해결 등의 기능을 통해 구조화된 데이터를 손쉽게 대규모로 추출할 수 있습니다. 지금 바로 무료 Bright Data 계정을 생성하여 저희 스크레이핑 솔루션을 체험하고 프록시를 테스트해 보세요!