

이 튜토리얼에서는 다음 내용을 살펴봅니다:
- 고객 식별을 위한 완전한 단계별 워크플로우.
- Bright Data의 Filter API를 사용하여 필요에 맞게 특별히 조정된 Crunchbase 데이터셋을 생성하는 방법.
- Bright Data API와 AI를 활용한 데이터 보강 및 분석을 통해 고객 발굴에 이 데이터셋을 활용하는 방법.
바로 시작해 보겠습니다!
신규 고객 식별 워크플로우 소개
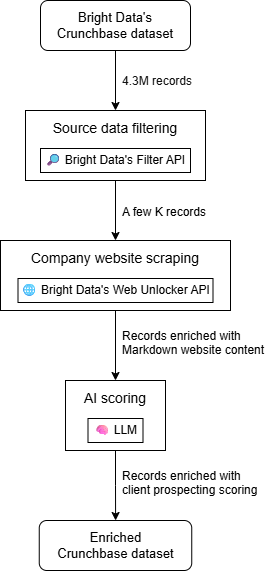
큰 그림에서 보면, AI 기반 고객 발굴 워크플로우는 세 가지 주요 단계로 구성됩니다:
- 소스 데이터 필터링: Crunchbase 데이터셋에서 시작하여 고유한 필요에 맞게 필터링합니다.
- 기업 웹사이트 스크래핑: 데이터셋의 각 기업 홈페이지 콘텐츠를 가져옵니다.
- AI 점수화: AI를 활용하여 웹사이트 콘텐츠(및 기업 레코드의 기타 필드)를 기반으로 각 기업을 평가하고, 제품 또는 서비스에 맞춘 고객 발굴 점수를 생성합니다.
결과물은 보강된 데이터셋으로, 각 Crunchbase 기업 레코드에 고객 발굴 점수 및 기타 추가 정보가 담긴 열이 포함됩니다. 결과 데이터셋을 필터링하거나 점수 기준으로 정렬하여 어느 기업에 먼저 연락할지 결정할 수 있습니다.
각 단계와 구현 방법에 대해 자세히 알아보세요!
1. 소스 데이터 필터링
이 워크플로우의 이상적인 소스는 기업 정보가 담긴 데이터셋입니다. Bright Data는 최고의 기업 데이터 제공업체로, LinkedIn, Crunchbase, Indeed 등 다양한 플랫폼을 포괄하는 풍부한 데이터셋을 제공합니다.
고객 발굴을 위해서는 Crunchbase가 특히 유용합니다. CB Rank, Heat Score 등 업계 내 기업의 영향력을 빠르게 평가할 수 있는 특화된 필드를 제공하기 때문입니다.
Bright Data는 430만 개 이상의 레코드를 포함한 Crunchbase 데이터셋을 제공합니다. 이처럼 방대한 데이터셋을 직접 다루는 것은 어려울 수 있으므로, Filter API를 사용하여 특정 기준에 맞는 기업만 추려낼 수 있습니다. 예를 들어, 특정 직원 수 범위 내에 있고, 현재 운영 중이며, 기타 관련 조건을 충족하는 기업만 가져올 수 있습니다.
2. 기업 웹사이트 스크래핑
필터링된 Crunchbase 데이터셋의 데이터 필드는 분명 흥미롭습니다. 하지만 그것만으로는 정확한 고객 식별에 충분하지 않은 경우가 많습니다. 기업을 제대로 평가하려면 해당 기업의 웹사이트를 분석하는 것이 가장 좋은 방법 중 하나입니다. 이를 통해 기업이 무엇을 하는지, 그리고 귀사의 서비스가 도움이 될 수 있는지 파악할 수 있습니다.
각 기업 웹사이트의 콘텐츠를 프로그래밍 방식으로 가져오는 것은 쉽지 않습니다. 모든 사이트는 구조가 다르고, IP 차단, 지역 제한, CAPTCHA 등 봇 방지 조치로 보호될 수 있습니다. 일부 사이트는 JavaScript 렌더링도 필요합니다.
이러한 문제를 일관되게 처리하고 LLM 분석에 최적화된 형식으로 웹사이트 콘텐츠를 얻으려면, Bright Data의 Web Unlocker API를 활용하는 것이 최선입니다. 이 엔드포인트를 통해 아무리 보호된 웹사이트라도 스크래핑할 수 있습니다.
3. AI 점수화
마지막으로, 각 기업의 웹사이트 콘텐츠로 보강된 필터링된 Crunchbase 데이터셋을 확보하면, 각 레코드를 AI에 입력합니다. 귀사의 서비스/제품에 대한 설명을 제공하고, AI가 각 기업이 귀사의 제품과 얼마나 잘 맞는지 점수를 매기도록 요청합니다.
Bright Data의 Filter API를 통해 필요에 맞게 특별히 조정된 Crunchbase 데이터셋 가져오기
AI 기반 고객 발굴 워크플로우의 첫 단계로 소스 데이터를 가져오겠습니다. 이는 발굴 가설과 관련된 기준에 맞는 기업들이 담긴 필터링된 Crunchbase 데이터셋입니다.
이 초기 단계를 통해 중요한 데이터만 다루게 되어, 훨씬 큰 데이터셋을 처리하는 것보다 시간과 비용을 절약할 수 있습니다. 곧 보시겠지만, 이 부분에서 Bright Data의 고급 필터링 기능이 특히 Filter API를 통해 빛을 발합니다.
아래 지침에 따라 맞춤형 Crunchbase 데이터셋을 가져오세요!
사전 준비
이 섹션을 따라하려면 다음이 필요합니다:
- API 키가 설정된 Bright Data 계정.
requests가 설치된 로컬 Python 환경.- Bright Data 데이터셋과 스냅샷 생성 방식에 대한 기본 이해.
Bright Data API 키를 구성하려면 공식 가이드를 참고하세요.
Step #1: Crunchbase 데이터셋 필터링
Bright Data 계정에 로그인하여 시작하세요. 제어판에서 “Web Datasets” 페이지로 이동하여 “Dataset Marketplace” 탭을 선택합니다. “Dataset Marketplace” 페이지에서 “crunchbase”를 검색하고 “Crunchbase companies information” 데이터셋을 선택합니다: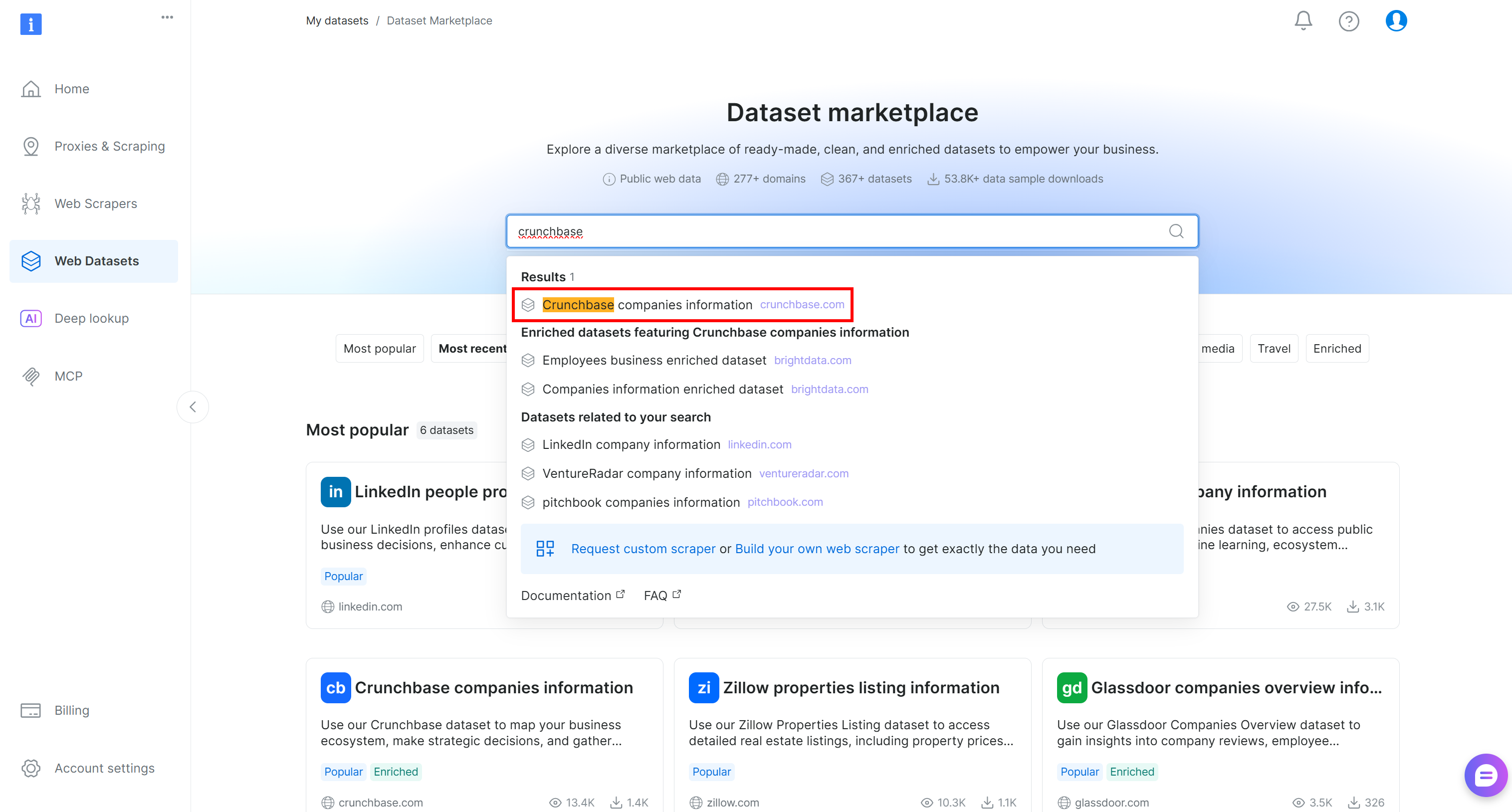
“Crunchbase companies information” 데이터셋 페이지로 이동됩니다. 거기서 왼쪽의 “Filters” 버튼을 눌러 제어판에서 직접 데이터 필터링을 적용할 수 있습니다: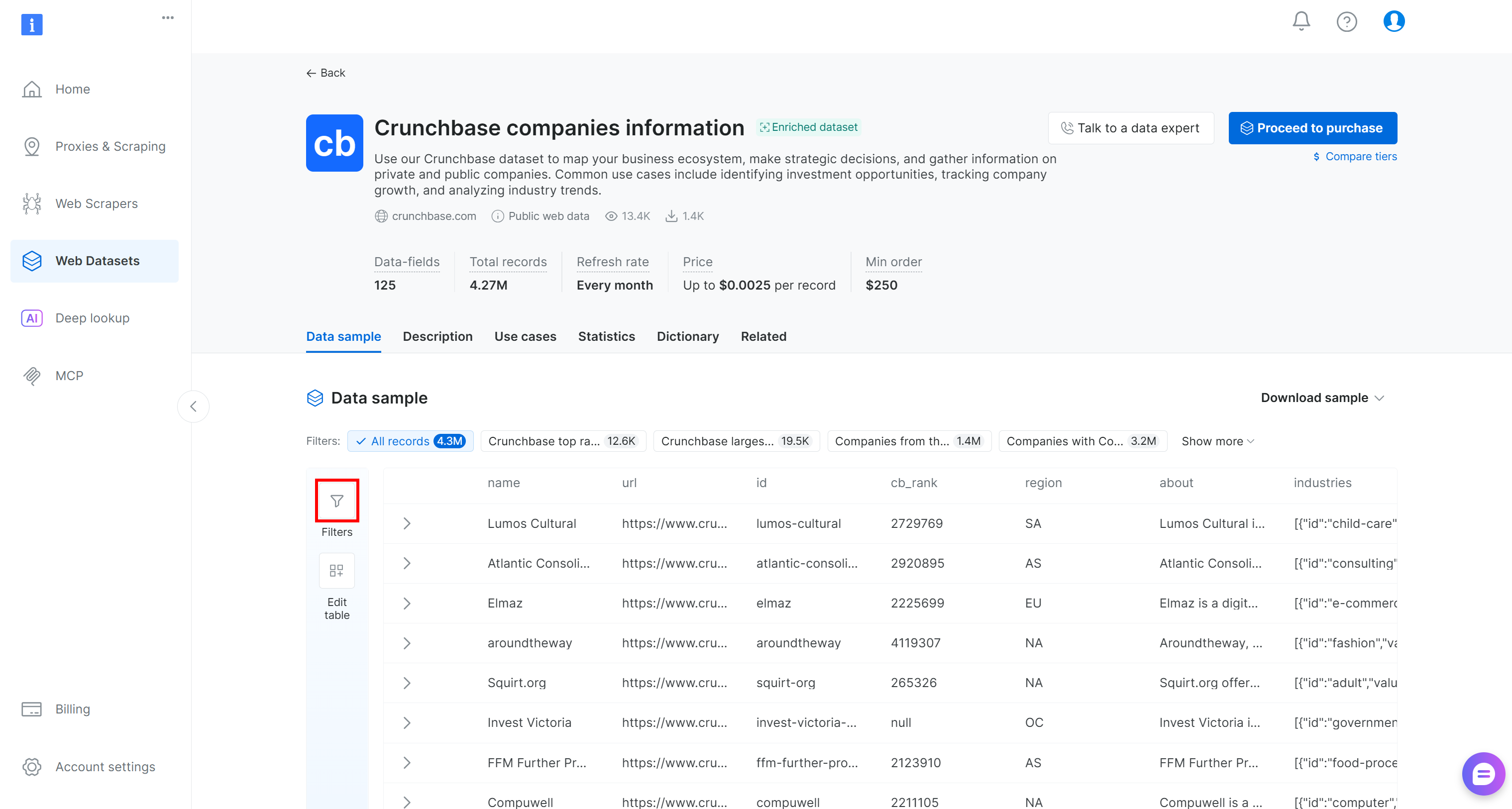
구체적으로, 125개 이상의 데이터 필드 각각에 하나 이상의 필터를 추가할 수 있습니다. 필터를 적용하여 430만 개의 전체 기업 목록에서 잠재적 우수 고객을 더 쉽게 식별하세요.
예를 들어, 다음 조건을 충족하는 기업을 찾고 싶다고 가정해 보겠습니다:
- 북미 또는 유럽에 위치한 기업.
- 현재 운영 중인 기업.
- AI 업계에서 활동하는 기업.
- CB Rank가 10,000 이하인 기업.
- 직원 수가 250명 미만인 기업.
website필드가 채워진 기업.- heat score가 60 이하인 기업.
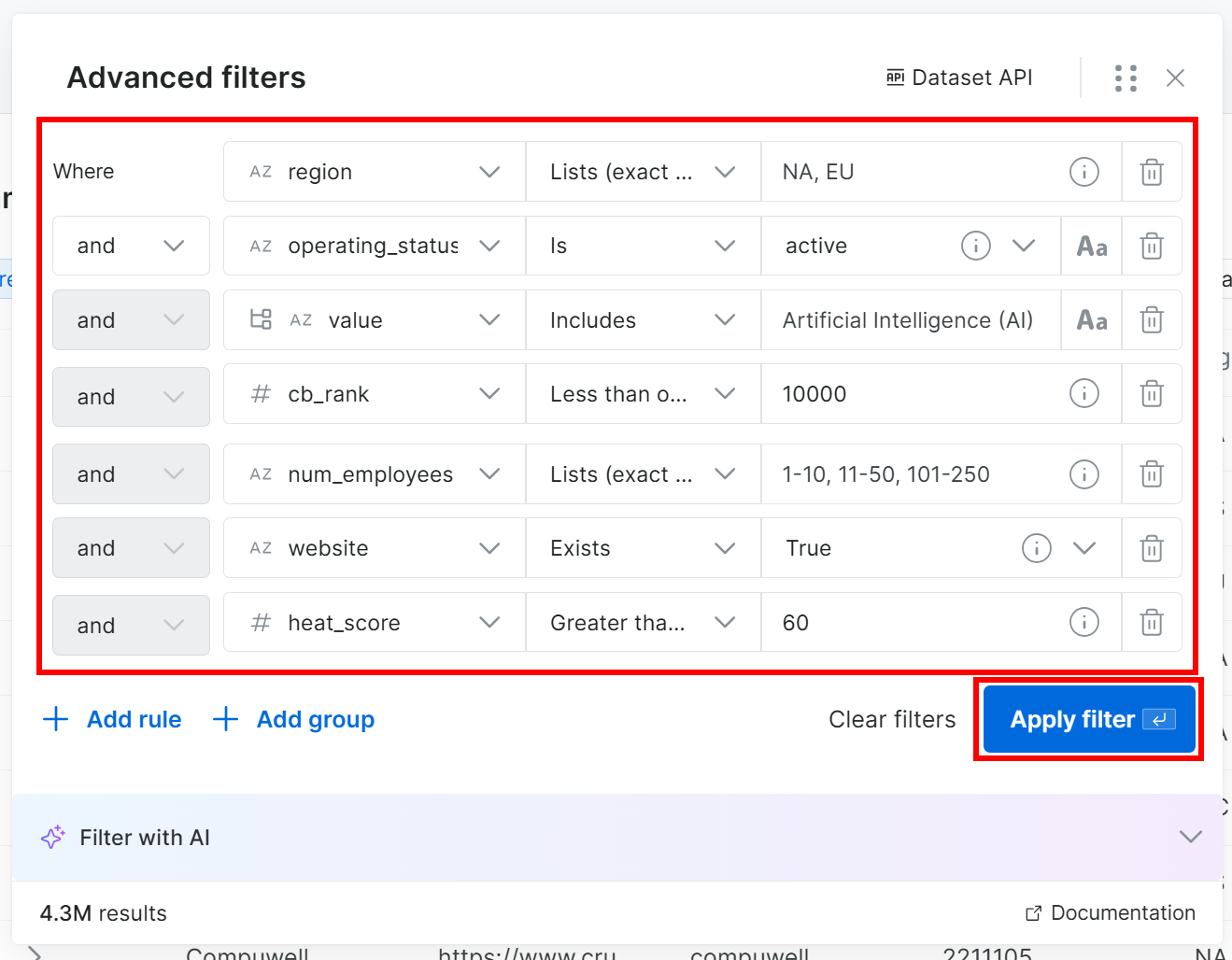
참고: 필터를 수동으로 추가하지 않으려면 “Filter with AI” 버튼을 클릭하고 원하는 데이터를 일반 영어 프롬프트로 설명하세요.
“Apply Filter” 버튼을 누르고 잠시 기다립니다. 필터링에는 다소 시간이 걸릴 수 있습니다. Bright Data는 필터가 기대에 맞는지 확인할 수 있도록 처음 30개 레코드의 미리보기를 보여줍니다.
필터링된 데이터셋의 총 레코드 수도 확인할 수 있습니다:
이 예시에서는 430만 개의 레코드에서 발굴을 위한 잠재 고객 1,300개를 얻었습니다. 이것이 바로 Bright Data의 필터링 기능의 강점으로, 방대한 초기 데이터셋에서 필요한 데이터를 정확하게 추출할 수 있습니다. 멋지지 않나요!
Step #2: Filter API 호출
이제 두 가지 옵션이 있습니다: “Proceed to purchase”를 클릭하여 데이터셋을 직접 다운로드하거나, Filter API를 사용하여 프로그래밍 방식으로 생성하는 것입니다. Filter API(Bright Data의 Dataset API의 일부)를 호출하면 반복성과 더 많은 제어가 가능하므로, 해당 방법을 사용하겠습니다.
필터 모달에서 “Dataset API” 버튼을 클릭합니다. 그러면 선택한 필터가 적용된 해당 데이터셋에서 Filter API를 호출하는 데 필요한 코드가 표시됩니다. “Python” 옵션을 선택하여 Python 스니펫을 가져옵니다: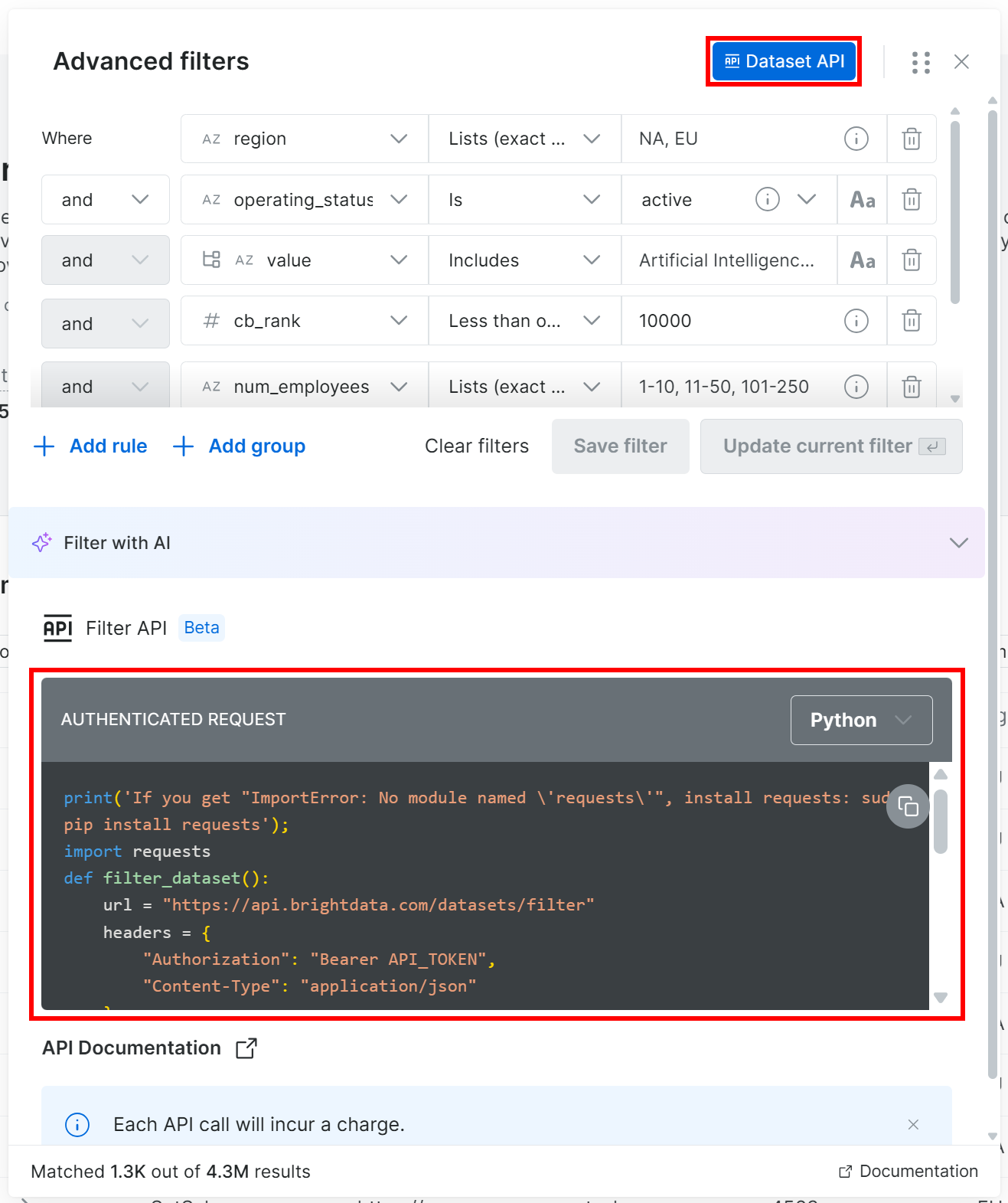
다음과 같은 Python 스니펫을 얻게 됩니다:
print('If you get "ImportError: No module named 'requests'", install requests: sudo pip install requests');
import requests
def filter_dataset():
url = "https://api.brightdata.com/datasets/filter"
headers = {
"Authorization": "Bearer API_TOKEN",
"Content-Type": "application/json"
}
payload = {
"dataset_id": "gd_l1vijqt9jfj7olije",
"filter": {"operator":"and","filters":[{"name":"region","value":["NA","EU"],"operator":"in"},{"name":"operating_status","value":"active","operator":"="},{"name":"industries:value","value":"Artificial Intelligence (AI)","operator":"includes"},{"name":"cb_rank","value":10000,"operator":"<="},{"name":"num_employees","value":["1-10","11-50","101-250"],"operator":"in"},{"name":"website","operator":"is_not_null"},{"name":"heat_score","value":60,"operator":">="}]}
}
response = requests.post(url, headers=headers, json=payload)
if response.ok:
print("Request succeeded:", response.json())
else:
print("Request failed:", response.text)
filter_dataset()API_TOKEN 자리 표시자를 Bright Data API 키로 교체하고, 스크립트를 로컬에 저장한 후 Python 환경에서 실행합니다.
모든 것이 올바르게 작동하면 다음과 같은 출력이 표시됩니다:
Request succeeded: {'snapshot_id': 'snap_XXXXXXXXXXXXXXXXXXX'}이는 새 데이터셋 스냅샷 생성 작업이 시작되었음을 의미합니다.
이 시점에서 다음 중 하나를 선택할 수 있습니다:
- Dataset API를 통해 상태를 확인하고 다운로드하거나,
- 제어판에서 수동으로 다운로드합니다(다음 단계에서 진행할 방법입니다!)
Step #3: 필터링된 데이터 가져오기
스냅샷 생성 작업이 완료되면 스냅샷이 준비되었다는 이메일 알림을 받게 됩니다: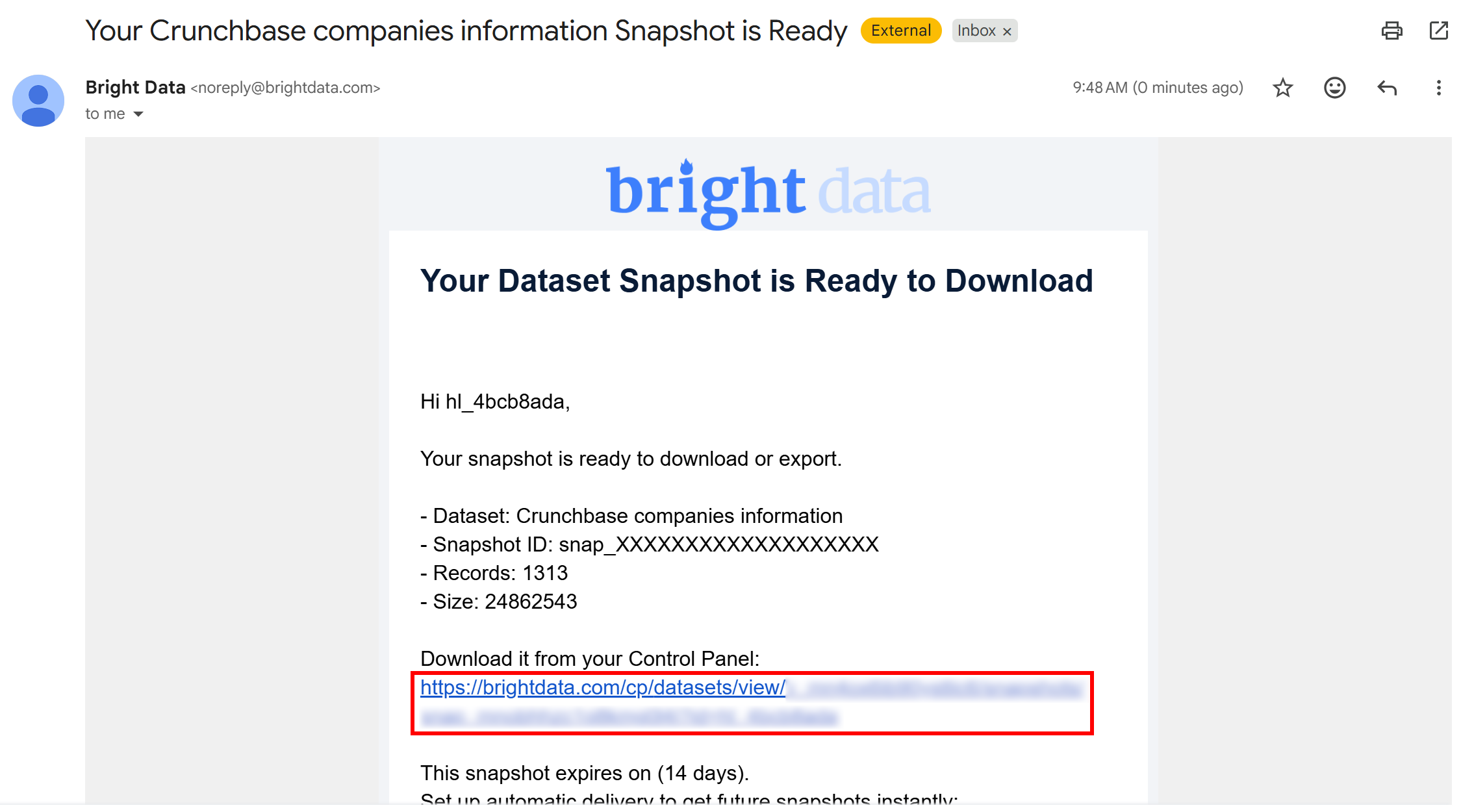
이메일의 URL을 클릭하면 Bright Data 제어판의 스냅샷 페이지로 이동합니다: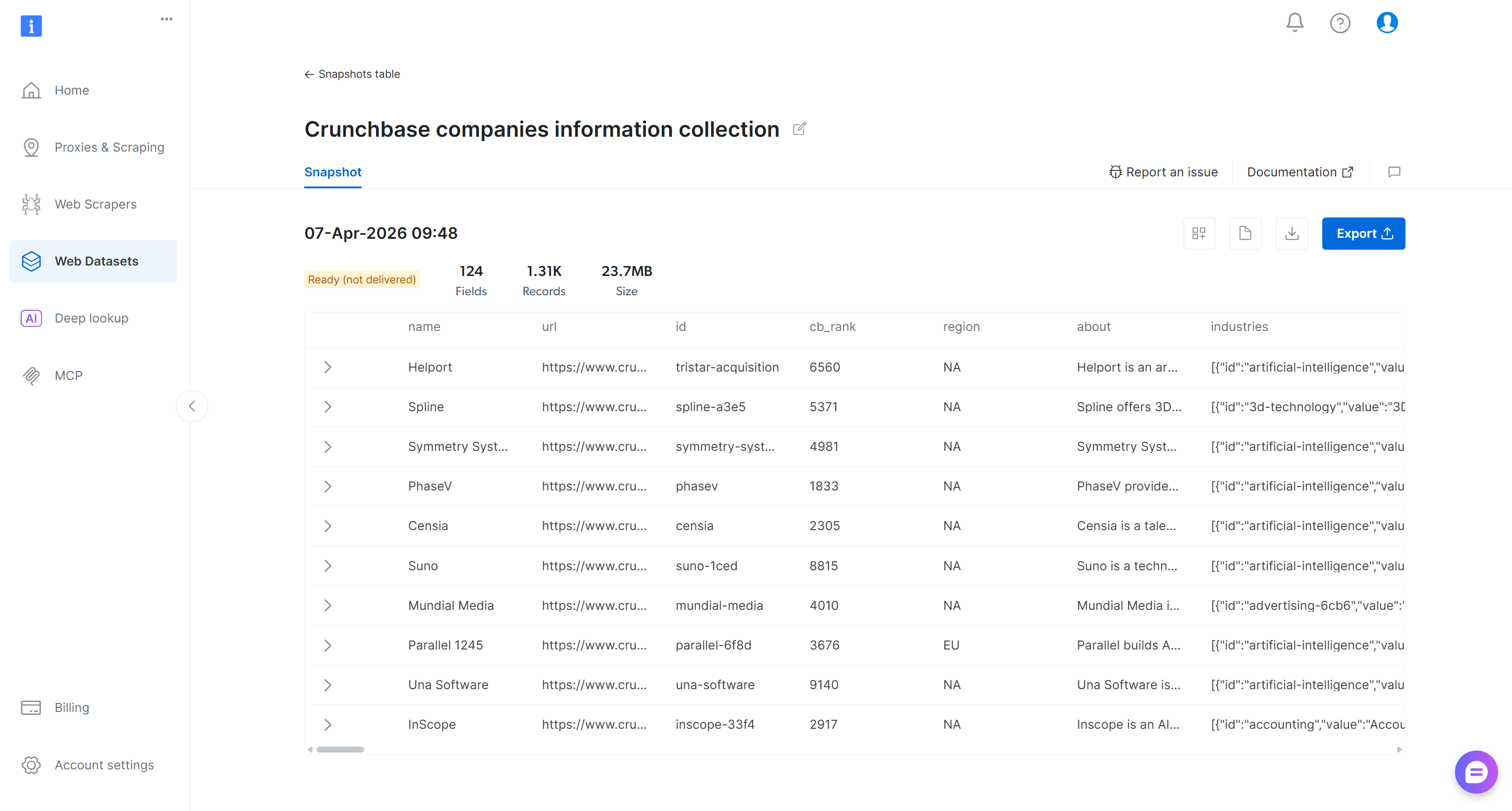
여기서 필터링된 데이터셋을 탐색하고, 다운로드하고, 추가 세부 정보에 접근할 수 있습니다. 예를 들어, 레코드 수와 총 비용 등의 인사이트가 담긴 보고서를 다운로드할 수 있습니다. 이 경우 보고서는 $3.29를 지출하여 1,313개의 레코드를 가져왔음을 보여줍니다(참고: 가격은 1,000레코드당 $2.50입니다):

스냅샷을 가져오려면 “Download” 아이콘을 클릭하고 “CSV” 옵션을 선택합니다: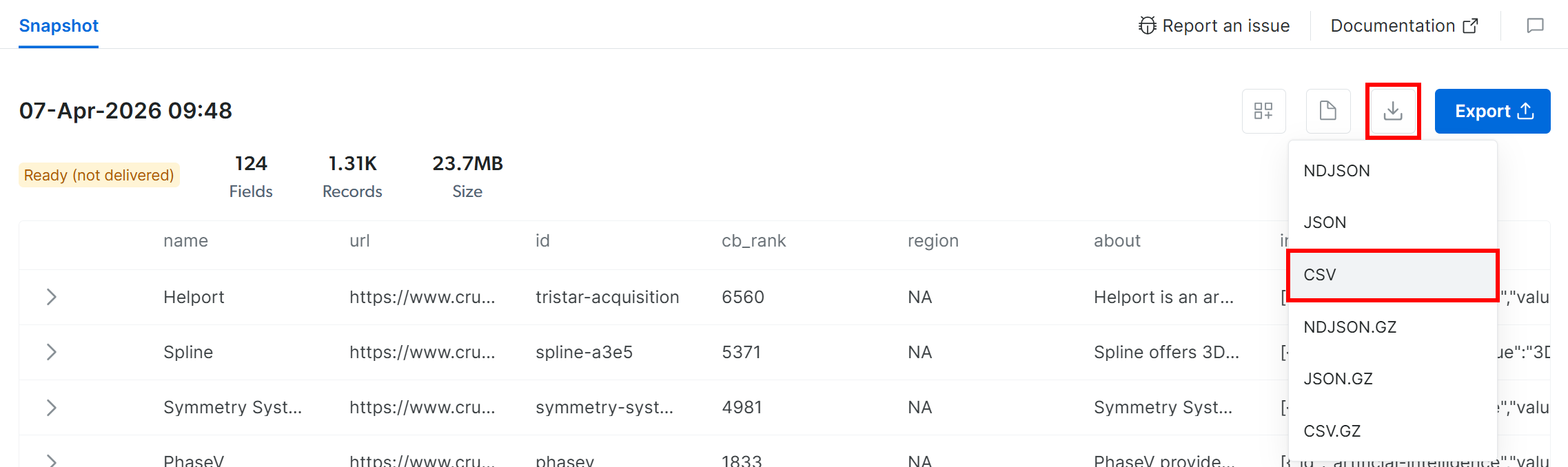
브라우저가 필터링된 Crunchbase 데이터가 담긴 snap_XXXXXXXXXXXXXXXXXXX.csv 파일을 다운로드합니다. 완벽합니다!
Step #4: 필터링된 데이터셋 탐색
snap_XXXXXXXXXXXXXXXXXXX.csv 파일을 열면 다음과 같은 내용을 볼 수 있습니다:
다운로드된 데이터셋에는 지정된 필터와 일치하는 1,313개의 Crunchbase 기업 항목(각각 133개 열 포함)이 포함되어 있습니다.
임무 완료! 이제 AI 기반 데이터 변환 및 보강을 통한 고객 발굴을 수행할 소스 데이터를 확보했습니다.
참고: 진행하기 전에 데이터셋을 검토하고 이 문서를 지원하는 “Crunchbase Data Analysis for Client Prospecting” Kaggle 노트북에서 보여주는 것처럼 콘텐츠를 더욱 좁히기 위한 추가 필터링 단계를 적용하는 것을 고려하세요.
맞춤형 Crunchbase 데이터셋을 시작점으로 AI를 활용하여 신규 고객 발굴하기
필터링된 Crunchbase 데이터셋은 데이터 처리 및 보강 워크플로우의 소스로 활용됩니다. 각 행에 대해 이 프로세스는 다음을 수행합니다:
- Web Unlocker API를 사용하여 기업 웹사이트를 방문하고 Markdown 형식으로 콘텐츠를 가져옵니다.
- 기업 콘텐츠를 AI 모델에 전달하여 기업이 무엇을 하는지 파악하고, 귀사 비즈니스에 얼마나 좋은 잠재 고객인지를 나타내는 점수를 제공하도록 요청합니다.
구현 방법을 살펴보겠습니다!
사전 준비
이 섹션을 따라하려면 이전 사전 준비 조건을 충족하는지 확인하고, 추가로 다음이 필요합니다:
- Bright Data 계정에 설정된 Web Unlocker API 존(예:
web_unlocker). - Web Unlocker API 작동 방식 및 지원 기능에 대한 지식.
- OpenAI API 키.
Web Unlocker 존을 생성하려면 Bright Data 문서의 “Create Your First Unlocker API” 가이드를 참고하세요. 아래에서는 Web Unlocker 존 이름이 web_unlocker라고 가정합니다.
간결함을 위해 이미 로컬 Jupyter Notebook 환경이 준비되어 있다고 가정합니다.
Step #1: 소스 필터링된 데이터셋을 노트북에 업로드
Jupyter Notebook을 실행하고 새 노트북을 만듭니다(예: client_prospecting.ipynb로 이름 지정). 그런 다음 snap_XXXXXXXXXXXXXXXXXXX.csv 파일을 업로드합니다:
이 파일은 AI 기반 고객 발굴 워크플로우의 소스 데이터로 사용됩니다. 잘 했습니다!
Step #2: 필요한 라이브러리 설치
데이터 보강 로직에 들어가기 전에, 이 워크플로우에 필요한 의존성을 설치합니다. 다음 내용이 담긴 셀을 추가합니다:
!pip install pandas requests pydantic openai다음 라이브러리가 설치됩니다:
pandas: Crunchbase 데이터가 담긴 소스 CSV를 로드하고 DataFrame으로 작업하기 위해.requests: 기업 홈페이지 다운로드를 위해 Bright Data Web Unlocker API에 연결하기 위해.pydantic: OpenAI 작업의 구조화된 출력을 정의하기 위해.openai: OpenAI 모델과 상호작용하여 고객 발굴을 위한 홈페이지 순위를 매기기 위해.
“▶” 버튼을 눌러 셀을 실행하여 이 라이브러리를 설치합니다. 이제 노트북에 필터링된 Crunchbase 데이터셋을 시작으로 AI 기반 고객 발굴에 필요한 모든 의존성이 포함되었습니다.
Step #3: 초기 셀 설정
코드 전반에 가져오기, 시크릿, 상수가 분산되는 것을 방지하기 위해 다음과 같이 노트북의 첫 번째 셀에 모두 배치합니다:
import os
import pandas as pd
import requests
import datetime
import concurrent.futures
from typing import Optional
from pydantic import BaseModel, Field
from openai import OpenAI
# Secrets to connect to third-party services (replace them with the actual values)
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"
OPENAI_API_KEY="<YOUR_OPENAI_API_KEY>"
# Define the required constants
SOURCE_CSV_PATH = "snap_XXXXXXXXXXXXXXXXXXX.csv"
ENRICHED_CSV_PATH = "crunchbase_analyzed_companies.csv"
# Initialize the OpenAI client
openai_client = OpenAI(api_key=OPENAI_API_KEY)다음을 확인하세요:
<YOUR_BRIGHT_DATA_API_KEY>를 Bright Data API 키로 교체합니다.<YOUR_OPENAI_API_KEY>를 OpenAI API 키로 교체합니다.- 필요에 따라 소스 파일(
SOURCE_CSV_PATH)과 보강된 파일 경로(ENRICHED_CSV_PATH)의 이름을 업데이트합니다.
ENRICHED_CSV_PATH는 보강된 데이터가 저장될 출력 파일 경로를 정의한다는 점을 기억하세요.
이 설정으로 시작하는 데 필요한 모든 구성 요소가 갖춰졌습니다.
Step #4: 데이터셋 로드
새 셀에 소스 데이터셋을 DataFrame으로 로드하고 주요 정보를 표시하는 로직을 추가합니다:
# Load the CSV file containing the filtered Crunchbase dataset
df = pd.read_csv(SOURCE_CSV_PATH, keep_default_na=False)
# Print the basic info about the dataset
df.info()
# Print the first rows
df.head()참고: keep_default_na=False 옵션이 필요합니다. 그렇지 않으면 "NA"가 포함된 region 열이 pandas에 의해 기본적으로 NaN으로 해석됩니다.
셀을 실행하면 다음과 같은 출력이 표시됩니다: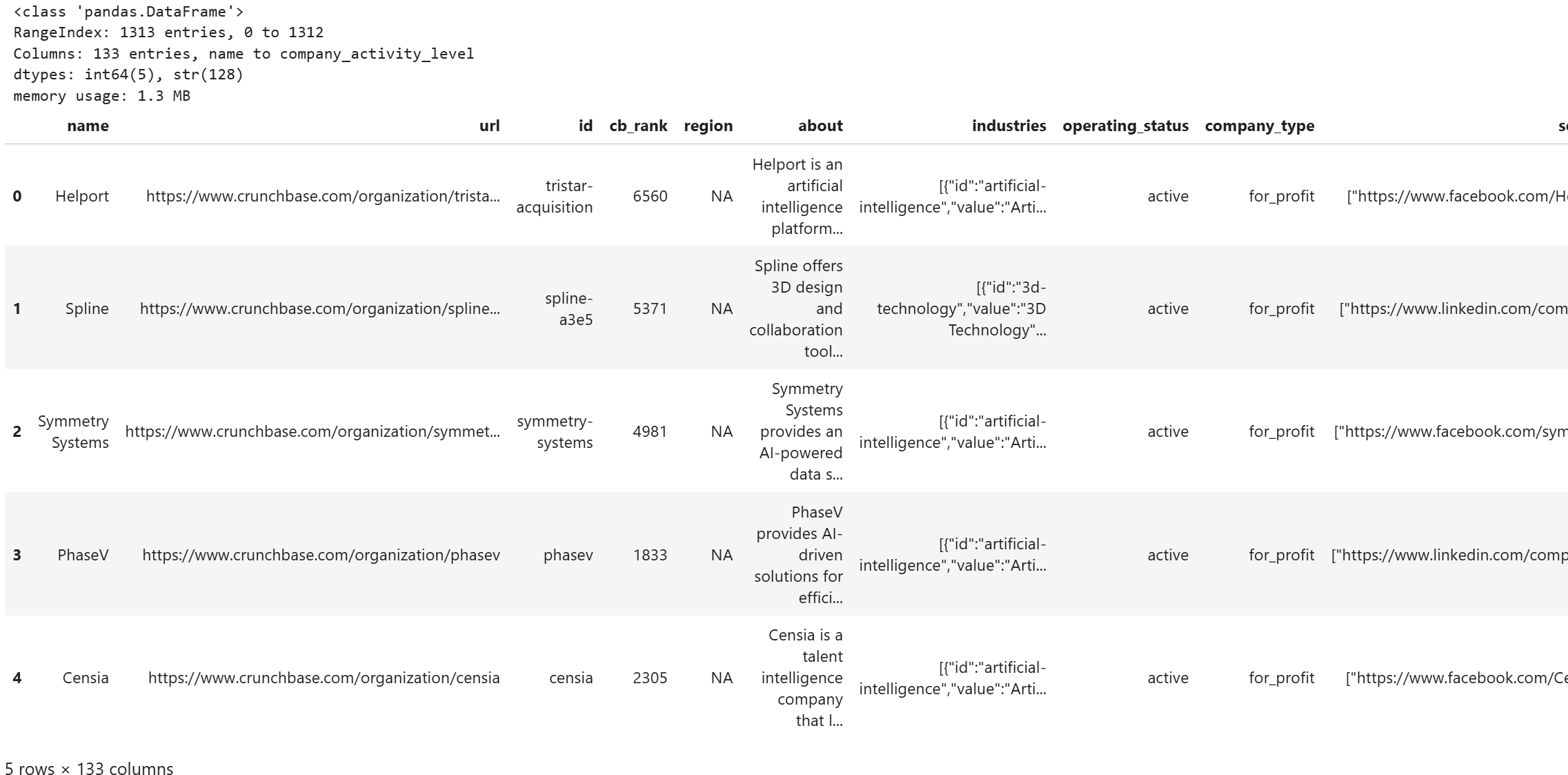
DataFrame이 필터링된 Crunchbase 데이터셋에서 133개 열을 가진 1,313개의 항목을 모두 저장하고 있음을 확인할 수 있습니다. 훌륭합니다!
Step #5: 웹사이트 스크래핑을 위한 함수 정의
이제 Web Unlocker API를 호출하여 기업 웹사이트를 스크래핑하는 함수를 정의합니다:
def fetch_website(url, zone = "web_unlocker"):
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json"
}
data = {
"zone": zone,
"url": url,
"format": "raw", # Get the response directly in the body
"data_format": "markdown" # Get the webpage in Markdown format (ideal for LLM ingestion)
}
api_url = "https://api.brightdata.com/request"
try:
response = requests.post(api_url, json=data, headers=headers)
# Raise an error if the response is 4xx/5xx
response.raise_for_status()
return response.text
except requests.RequestException as e:
print(f"Error fetching '{url}' via Web Unlocker API: {e}")
return NoneWeb Unlocker API 작동 방식에 익숙하지 않다면 공식 문서를 참고하세요.
fetch_website() 함수는 제공된 URL에서 Bright Data Web Unlocker API 존("web_unlocker"을 자신의 존 이름으로 교체)을 호출합니다. data_format: "markdown" 매개변수 덕분에 응답은 AI 준비가 된 웹사이트의 Markdown 버전이 됩니다. 해당 데이터 형식은 LLM 수집에 완벽합니다. 곧 바로 활용하게 될 것입니다.
이 함수는 각 기업 항목에 적용되어 홈페이지의 Markdown 버전으로 보강됩니다. 다음 단계에서 방법을 확인하세요!
Step #6: 모든 기업 홈페이지를 병렬로 가져오기
Web Unlocker API는 Bright Data의 다른 API 기반 제품과 마찬가지로 4억 개 이상의 주거용 IP를 보유한 엔터프라이즈급 인프라를 기반으로 합니다. 덕분에 속도 제한이나 확장 문제에 대한 걱정 없이 무제한 동시성으로 API를 호출할 수 있습니다.
데이터셋에 수천 개의 기업이 포함되어 있으므로, 여러 웹사이트를 동시에 스크래핑하는 것이 합리적입니다. 다음 셀이 정확히 그 작업을 수행합니다:
batch_size = 5
total = len(df)
defprocess_row_for_scraping(idx):
url = df.at[idx, "website"]
# Skip the row if the "website" field is missing
if pd.isna(url):
return None
# Retrieve the website homepage in Markdown
markdown = fetch_website(url)
timestamp = datetime.datetime.now(datetime.UTC)
return idx, markdown, timestamp
for start in range(0, total, batch_size):
# Get the current batch
end = min(start + batch_size, total)
batch_indices = df.index[start:end]
print(f"Processing Crunchbase records {start} to {end-1}")
# Fetching website homepages in parallel for the batch
with concurrent.futures.ThreadPoolExecutor(max_workers=batch_size) as executor:
results = list(executor.map(process_row_for_scraping, batch_indices))
# Update the DataFrame with the results
for r in results:
# Skip
if r is None:
continue
idx, markdown, timestamp = r
df.at[idx, "website_markdown"] = markdown
df.at[idx, "website_markdown_fetching_timestamp"] = timestamp
# Save the updated CSV after each batch
df.to_csv(ENRICHED_CSV_PATH, index=False)
print(f"Batch {start}-{end-1} saved to disk.")이 스니펫은 Crunchbase 데이터셋을 처리하여 각 기업 항목을 AI 기반 분석에 준비된 웹사이트의 Markdown 버전으로 보강합니다. 한 번에 5개 행씩 배치로 처리하며, 웹사이트를 병렬로 가져와 I/O 바운드 작업을 가속화합니다.
process_row() 함수는 각 기업을 처리합니다: Web Unlocker API를 사용하여 홈페이지를 가져오고 타임스탬프를 기록합니다. 누락된 URL을 건너뛰면 효율성이 높아지고 불필요한 API 호출을 방지할 수 있습니다. 또한 기업 웹사이트는 자주 변경될 수 있으므로 타임스탬프를 추적하는 것이 중요합니다. 따라서 마지막으로 스크래핑된 시간을 알아두는 것이 좋습니다.
배치는 스레드 풀로 처리되어 여러 요청이 동시에 실행될 수 있습니다. 각 배치 후에 DataFrame이 업데이트되고 디스크에 저장됩니다. 증분 저장은 프로세스가 중단될 경우 데이터 손실을 방지하고 처음부터 다시 시작하지 않고 재개할 수 있게 해주므로 매우 중요합니다.
Pro tip: 첫 번째 실행 시 전체 데이터셋을 처리하기 전에 워크플로우가 예상대로 작동하는지 확인하기 위해 행 수를 5 또는 10으로 제한하세요.
실행 후 아래 이미지와 같은 출력 메시지가 표시됩니다:
노트북의 디렉토리에 crunchbase_analyzed_companies.csv 파일이 나타납니다. 여기에는 원본 Crunchbase 데이터와 두 개의 새로운 열이 포함됩니다:
website_markdown: 각 기업 홈페이지의 AI 준비 Markdown 버전.website_markdown_fetching_timestamp: 각 페이지가 가져와진 정확한 시간.
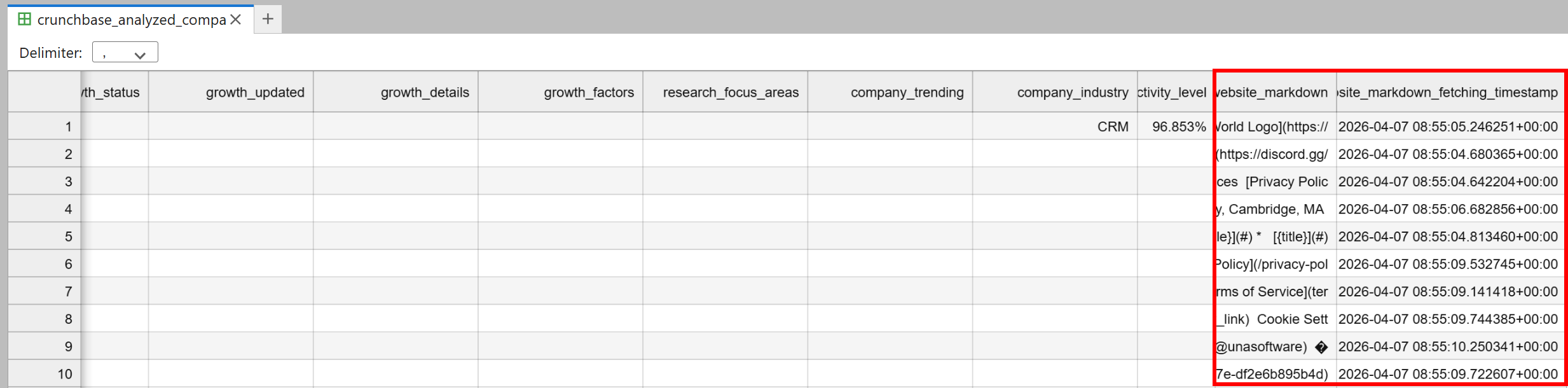
훌륭합니다! 이 데이터셋은 이제 AI 기반 분석 및 고객 발굴을 위한 준비가 되었습니다.
Step #7: AI 고객 발굴을 위한 함수 지정
다음 단계는 AI에게 고객 발굴을 수행하도록 지시하는 함수를 추가하는 것입니다. 아이디어는 귀사가 하는 일을 설명하고 AI가 각 Crunchbase 기업 항목을 평가하여 다음을 생성하도록 하는 것입니다:
- 이 기업이 얼마나 강력한 잠재 고객이 될 수 있는지를 나타내는 점수.
- 점수 뒤의 추론을 설명하는 짧은 코멘트(숫자만으로는 전체 그림을 보여주지 못할 수 있으므로 유용합니다).
- 웹사이트 콘텐츠를 기반으로 한 기업 핵심 비즈니스에 대한 짧은 설명(적합성 여부를 이해하는 데 도움이 됩니다).
참고: 다음 프롬프트는 기업 웹사이트만을 입력으로 사용하지만, 더 고급스럽고 세밀한 분석을 위해 전체 레코드를 전달할 수도 있습니다.
다음 셀로 프로세스를 구현합니다:
# Define the structured output schema
class AIProspectingResult(BaseModel):
ai_client_prospecting_score: float
ai_client_prospecting_comment: str
ai_core_business: str
def analyze_website(markdown):
# Ask the AI to perform the client prospecting task
system_prompt = (
"You are a business intelligence analyst specialized in identifying potential clients "
"for a cybersecurity firm. We are a specialized cybersecurity firm providing adversarial testing "
"for AI-powered ecosystems. Our mission is to proactively identify vulnerabilities by attempting to 'break' "
"AI models through sophisticated attack simulations. Following our assessment, we deliver a comprehensive "
"Vulnerability & Patch Report, detailing specific weaknesses discovered and providing actionable technical "
"strategies to remediate these risks and fortify the system's integrity.nn"
"Analyze the provided website content and produce a structured JSON with:n"
"- `ai_client_prospecting_score`: 0-10 float indicating how good a potential client this company could be.n"
"- `ai_client_prospecting_comment`: short comment (<=30 words) explaining the score.n"
"- `ai_core_business`: short description (<= 50 words) of what the company does based on the website.n"
)
user_prompt = f"WEBSITE CONTENT:n{markdown}"
try:
response = openai_client.responses.parse(
model="gpt-5.4-mini",
input=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
],
text_format=AIProspectingResult,
)
# Return the parsed result
return response.output_parsed
except Exception as e:
print("Error analyzing website with AI:", e)
return None선택한 OpenAI 모델(이 경우 GPT-5.4 Mini)이 구조화된 출력으로 응답하도록 하기 위해 responses.parse() 메서드를 호출합니다. 이 메서드는 Pydantic 데이터 모델을 받아 생성된 응답이 해당 형식을 따르도록 보장합니다. 자세한 내용은 ChatGPT를 활용한 웹 스크래핑 가이드에서 실제 사용 예를 확인하세요.
훌륭합니다! 다음 단계는 각 기업 레코드에 대해 이 함수를 병렬로 호출하는 것입니다.
Step #8: 모든 기업을 병렬로 발굴하기
이전과 마찬가지로 AI가 여러 항목을 병렬로 처리하도록 셀을 추가합니다:
batch_size = 5
total = len(df)
def process_row(idx):
markdown = df.at[idx, "website_markdown"]
# Skip rows with missing markdown
if pd.isna(markdown):
return None
# Call the AI prospecting function
result = analyze_website(markdown)
if result is None:
return None
return idx, result.ai_client_prospecting_score, result.ai_client_prospecting_comment, result.ai_core_business
for start in range(0, total, batch_size):
end = min(start + batch_size, total)
batch_indices = df.index[start:end]
print(f"Processing AI prospecting for records {start} to {end-1}")
# Run AI analysis in parallel
with concurrent.futures.ThreadPoolExecutor(max_workers=batch_size) as executor:
results = list(executor.map(process_row, batch_indices))
# Update the DataFrame with the results (if the array is not full of None values)
for r in results:
if r is None:
continue # Skip
idx, score, comment, core_business = r
df.at[idx, "ai_client_prospecting_score"] = score
df.at[idx, "ai_client_prospecting_comment"] = comment
df.at[idx, "ai_core_business"] = core_business
# Save CSV after each batch
df.to_csv(ENRICHED_CSV_PATH, index=False)
print(f"Batch {start}-{end-1} saved to disk.")실행하면 다음과 같은 메시지가 출력됩니다:
좋습니다! Crunchbase 데이터셋이 이제 Bright Data 추출 및 AI 기반 분석으로 고객 발굴을 위해 보강되었습니다.
결과를 탐색할 시간입니다!
Step #9: 보강된 데이터 분석
마지막 셀에서 보강된 데이터를 표시하는 로직을 추가합니다:
relevant_columns = [
"name",
"cb_rank",
"region",
"ai_client_prospecting_score",
"ai_client_prospecting_comment",
"ai_core_business"
]
pd.set_option("display.max_columns", None) # Show all columns
pd.set_option("display.max_colwidth", None) # Do not truncate text
# Print only the relevant fields
df[relevant_columns].head(10)결과 데이터셋에는 다음이 포함됩니다:
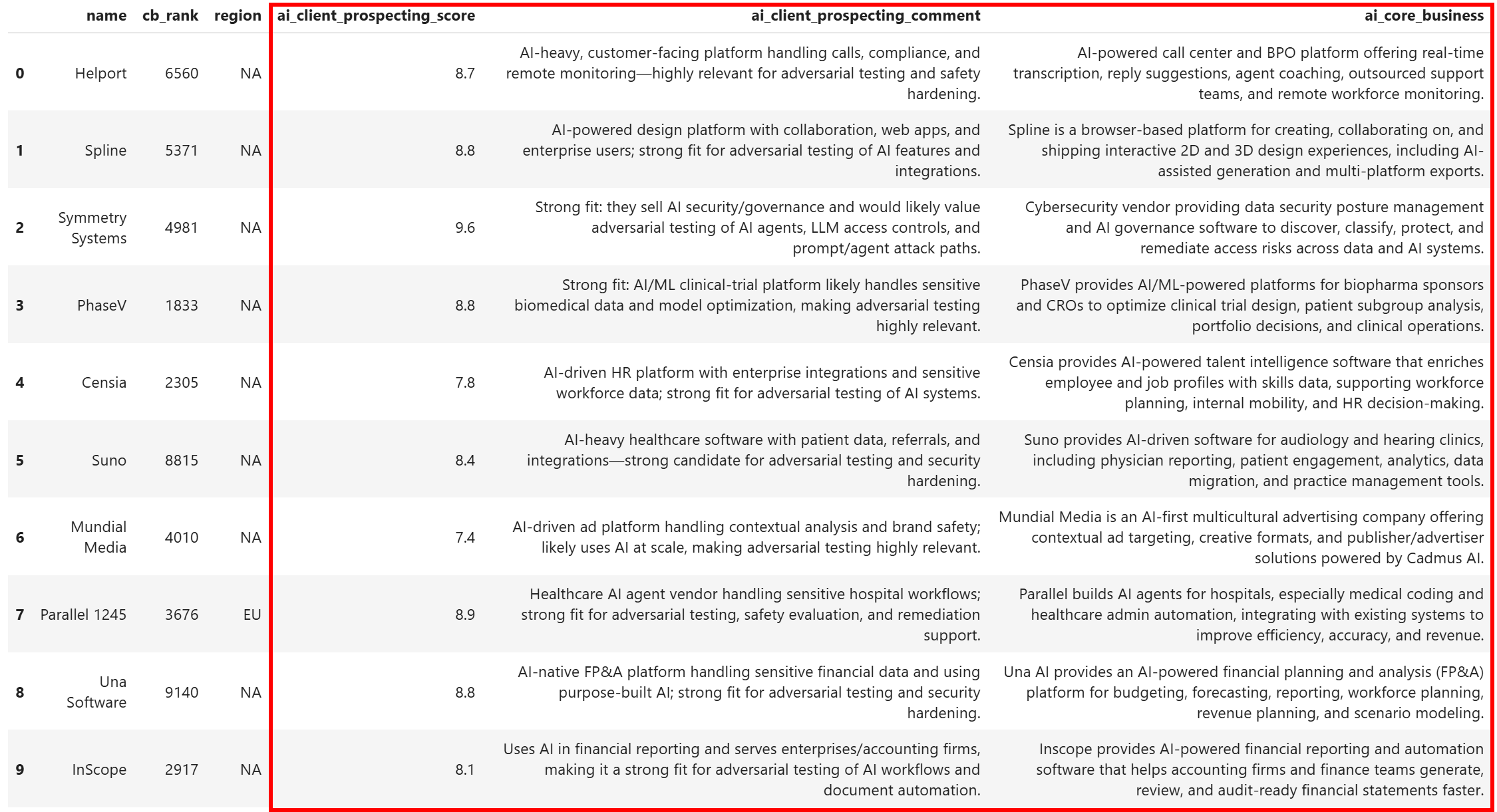
각 기업이 명확한 발굴 점수, 점수를 설명하는 짧은 코멘트, 기업이 하는 일에 대한 간결한 설명으로 보강된 것을 확인할 수 있습니다. 이는 다음 없이는 불가능했을 것입니다:
- Bright Data의 Filter API: 타겟팅된 필터링된 Crunchbase 데이터셋을 가져오기 위해.
- Web Unlocker API: 차단 없이 모든 기업 웹사이트를 안정적으로 스크래핑하기 위해.
이제 추가 데이터 분석을 적용하여 먼저 연락할 최적의 후보를 선택할 수 있습니다.
결론
이 글에서는 Bright Data의 데이터셋과 Bright Data API 및 AI를 활용하여 완전하고 프로덕션 준비가 된 자동화된 고객 발굴 워크플로우를 구축하는 방법을 배웠습니다. 이 워크플로우는:
- 430만 개 이상의 레코드가 담긴 Crunchbase 데이터셋으로 시작합니다.
- Bright Data의 Filter API를 사용하여 특정 기준에 맞는 기업만 포함하도록 프로그래밍 방식으로 필터링합니다.
- Web Unlocker API를 사용하여 각 기업의 웹사이트 콘텐츠를 가져옵니다.
- 해당 콘텐츠를 AI에 전달하여 프로그래밍 방식으로 점수를 매기고, 각 기업이 얼마나 좋은 잠재 고객인지 평가합니다.
결과는 보강된 데이터셋으로, 각 기업에 귀사의 제품이나 서비스를 위해 연락하는 것이 합리적인지를 나타내는 점수와 간단한 코멘트가 포함됩니다. Bright Data 마켓플레이스의 고품질 데이터, 고급 필터링 기능, AI 보강 덕분에 신규 고객 발굴이 그 어느 때보다 쉬워졌습니다!
지금 무료 Bright Data 계정을 만들고 AI 준비 웹 도구로 실험을 시작하세요!




