

이 가이드에서는 다음을 확인하실 수 있습니다:
- ChatGPT가 AI 기반 웹 스크래핑에 이상적인 선택인 이유.
- Python에서 ChatGPT를 활용해 웹사이트를 스크래핑하는 방법.
- 이 접근법의 주요 한계점과 해결 방법.
자, 시작해 보겠습니다!
웹 스크래핑에 ChatGPT를 사용해야 하는 이유
ChatGPT(더 정확하게는 GPT 모델)는 웹 스크래핑에 접근하는 강력한 새로운 방법을 제시합니다.
원시 HTML에서 데이터를 추출하기 위해 복잡한 파싱 로직을 작성하는 대신, 모델이 이 과정을 처리하도록 할 수 있습니다. OpenAI의 API는 데이터 파싱을 위한 전용 엔드포인트까지 제공하여 GPT 모델이 웹 스크래핑 작업에 특히 적합하게 만듭니다.
가장 큰 장점은 수동 데이터 파싱 로직을 작성할 필요가 없다는 점입니다. 취약한 CSS 선택자나 XPath 표현식을 다룰 필요가 없습니다. 데이터 추출을 위한 탄탄한 프롬프트만 있으면 됩니다. 몇 줄의 코드만으로 AI가 HTML 페이지에서 구조화된 데이터를 추출하도록 지시할 수 있습니다.
종합적으로 이 AI 기반 접근 방식은 웹 스크래핑을 더 빠르고 유연하며 유지 관리하기 훨씬 쉽게 만듭니다. 자세한 내용은 웹 스크래핑에 AI를 활용하는 방법 가이드를 참조하세요.
스크래핑 시나리오
ChatGPT가 기존 스크레이퍼를 개선하거나 대체할 수 있는 실용적인 시나리오는 다음과 같습니다:
- 동적 레이아웃의 전자상거래 사이트: 페이지 구조가 달라져도 제품 세부 정보(가격, 설명, 이미지)를 자동 추출합니다. 아마존 같은 사이트에서 가격 모니터링 및/또는 데이터 수집, Shopify 기반 스토어 스크래핑에 적합합니다.
- 콘텐츠 집계: 여러 출처의 블로그 게시물, 리뷰 또는 뉴스 기사를 스크래핑하고 GPT를 사용하여 출력을 요약하거나 표준화합니다.
- AI 지원 웹 크롤링: GPT와 크롤러를 결합하여 단순히 페이지를 가져오는 것뿐만 아니라 방문할 가치가 있는 링크를 판단하거나 스크래핑 우선순위가 높은 콘텐츠를 결정합니다.
- 소셜 미디어 및 빠르게 변화하는 플랫폼: 자주 업데이트되는 콘텐츠나 파싱이 어려운 UI를 가진 플랫폼에서 관련 정보를 추출합니다.
지원되는 워크플로
ChatGPT 스크래핑이 특히 뛰어난 몇 가지 고급 워크플로는 다음과 같습니다:
- 검색 강화 생성(RAG): 스크랩한 웹 데이터를 ChatGPT 컨텍스트에 직접 추가하여 더 스마트하고 정확하며 컨텍스트를 인식하는 답변을 생성합니다. SERP 데이터로 구동되는 RAG 챗봇 구축 가이드를 참조하세요.
- 실시간 데이터 강화: 스크래핑된 제품, 가격 또는 트렌드 데이터를 실시간으로 수집하여 내부 도구, 대시보드 또는 AI 에이전트를 최적화합니다.
- 시장 조사를 위한 신속한 프로토타이핑: 맞춤형 스크래핑 봇을 수동으로 구축할 필요 없이 ChatGPT를 활용해 여러 플랫폼에서 데이터를 신속하게 수집하세요.
Python에서 ChatGPT로 웹 스크래핑 수행 방법
이 가이드 섹션에서는 ChatGPT 스크래핑 스크립트 구축 방법을 살펴봅니다. 대상은 “웹 스크래핑 학습용 전자상거래 테스트 사이트”의 특정 제품 페이지입니다:
이 페이지는 테스트에 이상적인 대상입니다. 전자상거래 제품 페이지는 구조가 자주 달라지기 때문입니다. 제품에 따라 다양한 유형의 데이터를 표시합니다. 이러한 변동성이 전자상거래 웹 스크래핑을 매우 어렵게 만드는 요인이며, AI가 진정한 차이를 만들 수 있는 부분입니다.
스크레이퍼는 ChatGPT(GPT 모델)를 활용하여 수동 파싱 로직을 작성하지 않고도 페이지에서 이러한 제품 세부 정보를 추출할 것입니다:
- SKU
- 이름
- 이미지
- 가격
- 설명
- 사이즈
- 색상
- 카테고리
참고: 다음 예시는 단순성을 위해 Python으로 작성되었으며 OpenAI Python SDK가 널리 사용되기 때문입니다. 그러나 JavaScript OpenAI SDK나 기타 지원되는 언어를 사용해도 동일한 결과를 얻을 수 있습니다. 또한 Python 웹 스크래핑 가이드를 참고하시길 권장합니다.
ChatGPT를 사용하여 웹 데이터를 스크래핑하는 방법을 배우려면 아래 단계를 따르세요!
필수 조건
시작하기 전에 다음 사항을 확인하세요:
- 컴퓨터에 Python 3.8 이상 설치.
- GPT 모델에 접근하기 위한 OpenAI API 키.
OpenAI API 키를 획득하려면 공식 가이드를 따르세요.
1단계: Python 프로젝트 생성
터미널에서 다음 명령어를 실행하여 웹 스크래핑 프로젝트용 새 폴더를 생성하세요:
mkdir chatgpt-scraper이 chatgpt-scraper 디렉터리는 ChatGPT를 이용한 웹 스크래핑 프로젝트 폴더 역할을 합니다.
폴더로 이동하여 내부에서 Python 가상 환경을 생성하세요:
cd chatgpt-scraper
python -m venv venv선호하는 Python IDE로 프로젝트 폴더를 엽니다. Python 확장 프로그램이 설치된 Visual Studio Code 또는 PyCharm Community Edition이 모두 훌륭한 선택입니다.
프로젝트 폴더 내에 scraper.py 파일을 생성합니다:
chatgpt-scraper
├─── venv/
└─── scraper.py # <------------현재 scraper.py는 빈 Python 스크립트입니다. 곧 ChatGPT를 통한 LLM 웹 스크래핑 로직이 여기에 포함될 것입니다.
다음으로 터미널에서 가상 환경을 활성화하세요. Linux 또는 macOS에서는 다음 명령을 실행합니다:
source venv/bin/activateWindows에서는 다음과 같이 실행하세요:
venv/Scripts/activate잘하셨습니다! 이제 ChatGPT를 활용한 웹 스크래핑을 위한 Python 환경이 설정되었습니다.
참고: 다음 단계에서는 필요한 모든 종속성을 하나씩 설치하는 방법을 안내해 드립니다. 한 번에 모두 설치하려면 다음 명령어를 실행하세요:
pip install requests openai markdownify beautifulsoup42단계: Python에서 OpenAI 구성
웹 스크래핑을 위해 ChatGPT(즉, GPT 모델)에 연결하려면 OpenAI Python SDK를 사용해야 합니다. 활성화된 가상 환경에서 openai 패키지를 통해 라이브러리를 설치하세요:
pip install openai그런 다음 코드에서 OpenAI 클라이언트를 임포트하세요:
from openai import OpenAI웹 스크래핑을 위해 ChatGPT에 연결하려면 클라이언트 인스턴스를 생성하세요:
client = OpenAI()기본적으로 OpenAI() 생성자는 OPENAI_API_KEY 환경 변수에서 API 키를 찾습니다. 이는 인증을 안전하게 구성하는 권장 방법입니다.
개발 또는 테스트 목적으로는 코드에 키를 직접 추가할 수도 있습니다:
python
OPENAI_API_KEY = "<YOUR_OPENAI_API_KEY>"
client = OpenAI(api_key=OPENAI_API_KEY)<YOUR_OPENAI_API_KEY> 자리 표시자를 실제 OpenAI API 키로 대체하세요.
완벽합니다! 이제 OpenAI 설정이 완료되었으며, 웹 스크래핑을 위해 ChatGPT를 사용할 준비가 되었습니다.
3단계: 대상 페이지의 HTML 가져오기
웹 페이지에서 데이터를 스크래핑하려면 먼저 해당 페이지의 HTML을 가져와야 합니다. Requests와 같은 널리 사용되는 Python HTTP 클라이언트를 사용하여 대상 웹 서버에 GET 요청을 보내면 됩니다.
활성화된 가상 환경에서 Requests를 설치하려면 다음 명령어를 실행하세요:
pip install requests다음으로 scraper.py 파일에서 라이브러리를 임포트하세요:
import requestsget() 메서드를 사용하여 대상 URL에 GET 요청을 전송합니다:
url = "https://www.scrapingcourse.com/ecommerce/product/mach-street-sweatshirt"
response = requests.get(url)대상 서버는 해당 웹 페이지와 연관된 HTML 문서를 응답으로 반환합니다.
response.content를 출력하면 페이지의 전체 HTML 문서를 볼 수 있습니다:
<!DOCTYPE html>
<html lang="en-US">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<link rel="profile" href="https://gmpg.org/xfn/11" />
<link rel="pingback" href="https://www.scrapingcourse.com/ecommerce/xmlrpc.php" />
<!-- 생략... -->
<title>Mach Street 스웨트셔츠 – 웹 스크래핑 학습용 전자상거래 테스트 사이트</title>
<!-- 생략... -->
</head>
<body>
<!-- 생략... -->
</body>
</html>이제 대상 페이지의 HTML을 확보했습니다. ChatGPT를 활용하여 이를 파싱하고 구조화된 데이터를 추출하세요!
단계 #4: 페이지 HTML을 마크다운으로 변환하기 [선택 사항]
참고: 이 단계는 기술적으로 필수 사항은 아니지만 상당한 시간과 비용을 절약할 수 있습니다. 따라서 구현할 가치가 있습니다.
ChatGPT 스크래핑을 시작하기 전에, 다른 AI 웹 스크래핑 도구들이 원시 HTML을 어떻게 처리하는지 살펴보세요. 많은 도구들이 LLM에 전달하기 전에 HTML을 마크다운으로 변환한다는 것을 알 수 있을 것입니다.
왜 그럴까요? Kaggle 벤치마크에서 두 가지 주요 이유를 확인할 수 있습니다:
- 비용 효율성: 마크다운은 HTML보다 토큰 사용량이 적어 API 사용량을 줄이고 비용을 절감합니다.
- 더 빠른 처리: 토큰 수가 적으면 컴퓨팅 오버헤드도 낮아져 응답 속도가 빨라집니다.
자세한 내용은 AI 에이전트가 HTML보다 마크다운을 선호하는 이유에 대한 가이드를 참고하세요.
HTML-to-Markdown 최적화를 적용해 볼 시간입니다!
대상 웹페이지를 시크릿 모드(새 세션 보장)로 열고, 페이지 아무 곳이나 마우스 오른쪽 버튼으로 클릭하세요. “검사”를 선택해 브라우저 개발자 도구를 엽니다. DOM을 살펴보면 모든 관련 제품 정보가 CSS 선택자 #main:을 가진 요소 안에 있음을 확인할 수 있습니다:
첫 번째 접근법으로 전체 페이지의 원시 HTML을 ChatGPT에 전송해 데이터 파싱을 시도할 수 있습니다. 그러나 이 경우 헤더, 푸터, 네비게이션 요소 등 관련 없는 콘텐츠가 대량 포함됩니다. 이는 불필요한 잡음을 유발하고 환각(hallucinations) 발생 가능성을 높입니다.
대신 #main 요소 내 콘텐츠만 활용해야 합니다. 이렇게 하면 LLM에 페이지의 가장 관련성 높은 부분만 전송되어 부정확한 결과 발생 위험을 줄일 수 있습니다. 따라서 HTML을 마크다운으로 변환하지 않더라도, 주요 HTML 요소로 입력 범위를 제한하는 것이 LLM 작업 시 권장되는 방법입니다.
#main 요소만 고려하려면 Beautiful Soup 같은 Python HTML 파싱 라이브러리가 필요합니다. 활성화된 Python 가상 환경에서 다음 명령어로 설치하세요:
pip install beautifulsoup4API 사용법에 익숙하지 않다면 Beautiful Soup 웹 스크래핑 튜토리얼을 참고하세요.
그런 다음 scraper.py에서 다음과 같이 임포트하세요:
from bs4 import BeautifulSoupBeautiful Soup을 사용하여:
- Requests로 가져온 원시 HTML을 파싱합니다.
#main요소를 선택합니다.- 해당 HTML 콘텐츠를 가져옵니다.
다음 코드 조각으로 이를 달성합니다:
# Beautiful Soup로 페이지 HTML 파싱
soup = BeautifulSoup(response.content, "html.parser")
# #main 요소 선택 및 외부 HTML 가져오기
main_element = soup.select_one("#main")
main_html = str(main_element)main_html을 출력하면 다음과 같이 표시됩니다:
<main id="main" class="site-main" role="main" data-testid="main-content" data-content="main-area">
<div class="woocommerce-notices-wrapper"
id="notices-wrapper"
data-testid="notices-wrapper"
data-sorting="notices">
</div>
<div id="product-267"
class="product type-product post-267 status-publish first outofstock
product_cat-hoodies-sweatshirts has-post-thumbnail
shipping-taxable purchasable product-type-variable">
<!-- 생략... -->
</div>
</main>이제 공식 OpenAI 토큰화 도구를 사용하여 선택한 HTML 문자열이 몇 개의 토큰에 해당하는지 확인하세요:
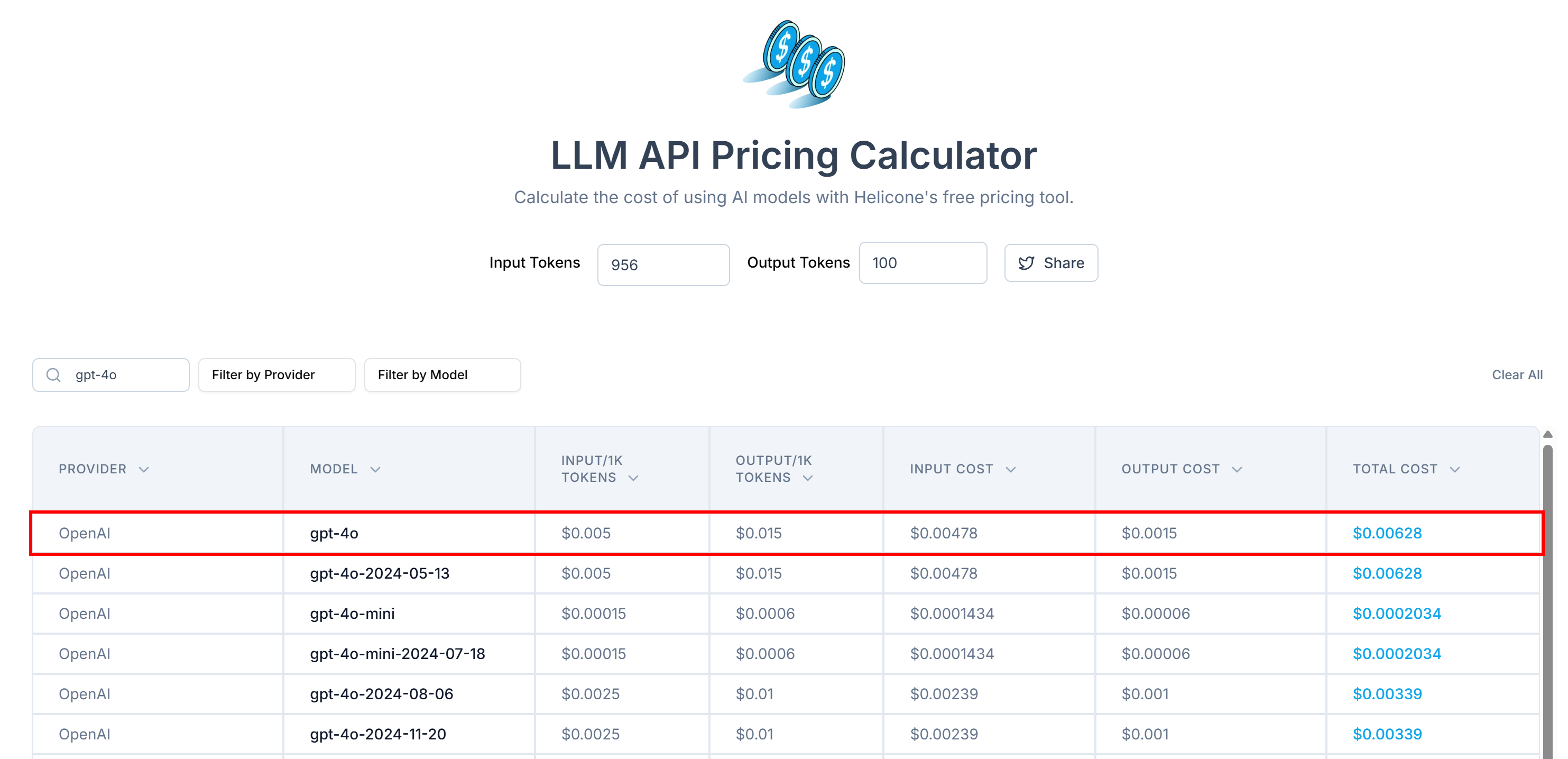
다음으로 LLM API Pricing Calculator 같은 도구를 사용해 이 토큰들을 OpenAI에 전송하는 비용을 추정해 보세요:
보시다시피 이 접근법은 20,000개 이상의 토큰을 발생시키며, 이는 요청당 약 0.10달러에 해당합니다. 처음에는 많지 않아 보일 수 있지만, 수천 개의 페이지를 포함하는 대규모 웹 스크래핑 프로젝트에서는 비용이 빠르게 누적될 수 있습니다.
토큰 소비를 줄이려면 markdownify 같은 패키지를 사용해 추출한 HTML을 마크다운으로 변환하세요. ChatGPT 스크래핑 프로젝트에 설치하려면 다음 명령어를 실행하세요:
pip install markdownifyscraper.py 파일에서 markdownify를 반드시 임포트하세요:
from markdownify import markdownify그런 다음 다음 코드 줄로 #main 의 HTML을 마크다운으로 변환하세요:
main_markdown = markdownify(main_html)온라인에 있는 다양한 HTML-to-Markdown 변환기 중 하나를 사용해 출력을 시뮬레이션할 수 있습니다. 변환 과정은 다음과 유사한 결과를 생성합니다:
두 텍스트 영역 끝부분 근처의 “size” 요소를 살펴보면, 입력된 HTML (#main )보다 마크다운 버전이 훨씬 더 간결함을 알 수 있습니다. 그러나 자세히 살펴보면 스크래핑에 필요한 모든 핵심 데이터가 그대로 보존되어 있음을 확인할 수 있습니다.
OpenAI 토큰라이저를 다시 사용해 새로운 마크다운 입력값이 소비하는 토큰 수를 확인해 보세요:
이 간단한 방법으로 21,504개의 토큰을 956개로 줄였습니다. 이는 95% 이상의 토큰 감소율입니다!
이는 요청당 OpenAI API 비용의 대폭적인 절감으로 이어집니다:
요청당 비용이 약 0.10달러에서 약 0.006달러로 떨어졌습니다!
단계 #5: 데이터 파싱을 위해 ChatGPT 사용
OpenAI SDK는 구조화된 데이터 추출을 위한parse()라는 특수 메서드를 제공합니다. 이 메서드는 다음을 인수로 받습니다:
- 파싱에 사용할 모델(예:
"gpt-4o"). - Pydantic 모델로 정의된 출력 형식.
- 표준 완성 입력 (시스템 및 사용자 메시지).
parse() 메서드는 지정된 Pydantic 클래스의 인스턴스를 반환하거나, 모델이 유효한 응답을 생성하지 못할 경우 None을 반환합니다.
추출하려는 제품 데이터 구조를 나타내는 Product 클래스를 정의하는 것으로 시작합니다:
class Product(BaseModel):
sku: Optional[str] = None
name: Optional[str] = None
images: Optional[List[str]] = None
price: Optional[str] = None
description: Optional[str] = None
sizes: Optional[List[str]] = None
colors: Optional[List[str]] = None
category: Optional[str] = None이 Pydantic 클래스는 페이지에서 발견되는 예상 제품 구조를 매핑합니다. 모든 필드는 선택 사항으로 표시되어 있으며, 이는 다음과 같은 이유로 중요합니다:
- 모든 상품 페이지에 모든 데이터 필드가 존재하지 않을 수 있습니다.
- 필수 필드가 페이지에 누락된 경우, 구조를 완성하기 위해 잠재적으로 허구적인 데이터로 모델을 채우도록 강요하지 않습니다.
scrape.py에 다음 두 가지 임포트 문 추가를 잊지 마세요:
from pydantic import BaseModel
from typing import List, Optional그런 다음 스크래핑 작업을 다음과 같이 정의하세요:
input = [
{
"role": "system",
"content": (
"You are a scraping agent that extracts structured product data in the specified format."
),
},
{
"role": "user",
"content": (
f"""
주어진 콘텐츠에서 제품 데이터를 추출하세요.
콘텐츠:n
{main_markdown}
"""
),
},
]위의 프롬프트는 ChatGPT가 Product 클래스에서 정의된 형식을 사용하여 main_markdown 콘텐츠에서 구조화된 데이터를 추출하도록 지시합니다.
팁: 코드에 통합하기 전에 ChatGPT에서 프롬프트를 테스트하고 개선하여 예상하는 구조를 반환하는지 확인하세요.
이제 설정된 매개변수로 parse() 메서드를 호출하세요:
response = client.responses.parse(
model="gpt-4o",
input=input,
text_format=Product,
)이제 다음과 같이 파싱된 객체에 접근할 수 있습니다:
product = response.output_parsedproduct는 Product 클래스의 인스턴스가 됩니다(데이터 파싱 과정이 실패하면 None).
훌륭합니다! 방금 GPT 모델을 활용해 웹페이지에서 구조화된 제품 데이터를 추출했습니다.
6단계: 스크랩된 데이터 내보내기
이 시점에서 스크랩된 데이터는 Product 클래스의 인스턴스인 Python 객체에 저장됩니다. 파싱이 실패한 경우 이 객체는 None일 수도 있습니다.
해당 객체를 JSON 파일로 내보내려면 다음 코드를 사용하세요:
if product is not None:
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product.model_dump(), json_file, indent=4)
else:
print("추출된 제품이 None입니다!")이렇게 하면 구조화된 JSON 형식으로 스크랩된 데이터가 포함된 product.json 파일이 생성됩니다.
Python 표준 라이브러리에서 json을 임포트합니다:
import json잘하셨습니다! 이제 ChatGPT 기반 웹 스크래퍼가 완성되었습니다.
7단계: 모든 것을 통합하기
다음은 ChatGPT를 활용한 웹 스크래핑 스크립트인 scraper.py의 전체 코드입니다:
from openai import OpenAI
import requests
from bs4 import BeautifulSoup
from markdownify import markdownify
from pydantic import BaseModel
from typing import List, Optional
import json
# 스크래핑할 객체의 구조를 나타내는 Pydantic 클래스
class Product(BaseModel):
sku: Optional[str] = None
name: Optional[str] = None
images: Optional[List[str]] = None
price: Optional[str] = None
description: Optional[str] = None
sizes: Optional[List[str]] = None
colors: Optional[List[str]] = None
category: Optional[str] = None
# OpenAI API 키
OPENAI_API_KEY = "<YOUR_OPENAI_API_KEY>"
# OpenAI SDK 클라이언트 초기화
client = OpenAI(api_key=OPENAI_API_KEY) # 실제 운영 환경에서는 envs에서 OpenAI 키를 읽어옴
# 대상 페이지의 HTML 콘텐츠 가져오기
url = "https://www.scrapingcourse.com/ecommerce/product/mach-street-sweatshirt/"
response = requests.get(url)
# Beautiful Soup로 페이지 HTML 파싱
soup = BeautifulSoup(response.content, "html.parser")
# #main 요소 선택, HTML 추출 및 마크다운 변환
main_element = soup.select_one("#main")
main_html = str(main_element)
main_markdown = markdownify(main_html)
# 스크래핑 작업의 입력 정의
input = [
{
"role": "system",
"content": (
"You are a scraping agent that extracts structured product data in the specified format."
),
},
{
"role": "user",
"content": (
f"""
주어진 콘텐츠에서 제품 데이터를 추출하세요.
콘텐츠:n
{main_markdown}
"""
),
},
]
# OpenAI로 스크래핑 파싱 요청 수행
response = client.responses.parse(
model="gpt-4o",
input=input,
text_format=Product,)
# 파싱된 제품 데이터 가져오기
product = response.output_parsed
# OpenAI가 원하는 콘텐츠를 반환한 경우
if product is not None:
# 스크랩된 데이터를 JSON으로 내보내기
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product.model_dump(), json_file, indent=4)
else:
print("추출된 제품이 None입니다!")다음 명령어로 스크립트를 실행하세요:
python scraper.py스크레이퍼는 잠시 시간이 걸린 후 프로젝트 폴더에 product.json 파일을 생성합니다. 파일을 열면 다음과 같은 내용을 확인할 수 있습니다:
{
"sku": "MH10",
"name": "Mach Street Sweatshirt",
"images": [
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh10-blue_main.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh10-blue_alt1.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh10-blue_back.jpg"
],
"price": "$62.00",
"description": "거친 거리부터 아스팔트 트랙까지, Mach Street 스웨트셔츠는 마모와 바람, 비에도 견딥니다. 성능과 스타일리시한 편안함이 조화된 이 제품은 습기 흡수 기능의 LumaTech® 소재로 제작되어 당신의 활동적인 라이프스타일에 꼭 맞는 일상의 필수품이 될 것입니다.\nu2022 네이비 헤더 크루넥 스웨트셔츠. nu2022 LumaTech® 흡습 발한 원단. nu2022 항균, 냄새 방지 기능. nu2022 지퍼 핸드 포켓. nu2022 마찰 방지 플랫록 솔기. nu2022 리브 니트 커프스와 밑단.",
"sizes": [
"XS",
"S",
"M",
"L",
"XL"
],
"colors": [
"Black",
"Blue",
"Red"
],
"category": "후디 & 스웨트셔츠"
}자, 이제 완성되었습니다! ChatGPT 스크레이퍼가 HTML 페이지의 비정형 데이터를 깔끔하게 정리된 JSON 파일로 변환했습니다.
다음 단계
ChatGPT 스크레이퍼를 개선하려면 다음 사항을 고려하세요:
- 재사용 가능하게 만들기: 스크립트를 리팩토링하여 대상 URL과 모델 이름을 명령줄 인수로 받아들이도록합니다. 이렇게 하면 스크래핑 로직에 유연성이 추가됩니다.
- API 키 보안 강화: OpenAI API 키를 스크립트에 하드코딩하지 말고
.env파일에 저장한 후python-dotenv를사용해 안전하게 불러오세요. 또는OPENAI_API_KEY라는글로벌 환경 변수로 설정하세요. 두 방법 모두 민감한 자격 증명을 코드베이스에서 분리해 보안을 강화합니다.
다른 AI 스크래핑 도구에서 OpenAI 모델을 통합하려면 다음 가이드를 참조하세요:
이 AI 기반 스크래핑 접근법의 가장 큰 한계 극복하기
주요 병목 현상은 requests 모듈이 생성하는 HTTP 요청입니다. 위 예제가 작동하는 이유는 대상 사이트가 웹 스크래핑을 허용하기 때문입니다(대상 사이트 이름이 “웹 스크래핑 학습용 전자상거래 테스트 사이트”임을 기억하세요). 실제 환경에서는 상황이 다릅니다. 대부분의 사이트는 자동화된 요청을 차단할 수 있는 스크래핑 방지 조치로 콘텐츠를 보호합니다.
이 경우 스크립트는 다음과 같은 403 Forbidden 오류(또는 유사한 오류)로 실패합니다:
requests.exceptions.HTTPError: 403 Client Error: Forbidden for url: <YOUR_TARGET_URL>또한 여기서 소개한 스크래핑 방법은 자바스크립트에 크게 의존하는 웹사이트에서는 작동하지 않습니다. 동적 사이트를 대상으로 한다면 requests만으로는 부족하며, Playwright나 Selenium 같은 브라우저 자동화 솔루션이 필요합니다. 따라서 강력한 반봇 보호 기능이 없더라도 많은 사이트가 ChatGPT 스크레이퍼를 무력화시킬 수 있습니다.
이러한 문제를 극복하는 최선의 방법은 전용 웹 언락킹 API를 사용하는 것입니다!
Bright Data의 Web Unlocker API는 모든 HTTP 클라이언트에서 호출 가능한 강력한 스크래핑 엔드포인트입니다. 이 API는 모든 URL의 완전히 잠금 해제된 HTML을 반환하므로, 자동으로 스크래핑 차단 기능을 우회해 줍니다.
이것이 가능한 이유는 다음과 같은 지원 덕분입니다:
- 1억 5천만 개 이상의 IP로 구성된 프록시 네트워크.
- 지문 위조 기술.
- CAPTCHA 해결 기능.
- 기타 다양한 고급 기능.
더욱 뛰어난 점은 Web Unlocker가 원시 HTML 대신 AI 최적화 마크다운을 반환할 수 있다는 것입니다. 이를 통해 HTML-to-Markdown 변환 단계(단계 #5)를 완전히 건너뛸 수 있습니다. 이렇게 하면 몇 줄의 코드만으로 어떤 웹사이트든 효과적인 AI 기반 스크래퍼를 구축할 수 있습니다.
시작하려면 공식 Web Unlocker 문서를 따라 API 키를 발급받으세요. 그런 다음 “단계 #4″와 “단계 #5″의 코드를 다음 줄로 대체하세요:
WEB_UNLOCKER_API_KEY = "<YOUR_WEB_UNLOCKER_API_KEY>"
# Web Unlocker 인증 헤더 설정
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {WEB_UNLOCKER_API_KEY}"
}
# 요청 페이로드 정의
payload = {
"zone": "unblocker",
"url": "https://www.scrapingcourse.com/ecommerce/product/ajax-full-zip-sweatshirt/", # 대상 URL로 교체
"format": "raw",
"data_format": "markdown" # 마크다운 형식으로 응답 받기"
}
# 대상 페이지의 잠금 해제된 HTML 가져오기
response = requests.post("https://api.brightdata.com/request", json=payload, headers=headers)이렇게 간단하게, 더 이상 차단도 제한도 없습니다. 이제 ChatGPT와 Web Unlocker로 구동되는 완전한 기능의 AI 웹 스크레이퍼를 갖게 되었습니다.
더 복잡한 스크래핑 시나리오에서 OpenAI SDK와 Web Unlocker가 함께 작동하는 모습을 확인하세요.
결론
이 튜토리얼에서는 ChatGPT(GPT 모델)를 Requests 및 기타 도구와 결합하여 AI 기반 웹 스크레이퍼를 구축하는 방법을 배웠습니다. 가장 큰 과제 중 하나인 차단 문제는 Bright Data의 Web Unlocker API를 사용하여 해결했습니다.
앞서 논의한 바와 같이, ChatGPT와 Web Unlocker API를 통합하면 사용자 정의 파싱 코드를 작성하지 않고도 모든 사이트에서 프롬프트 준비가 완료된 데이터를 추출할 수 있습니다. 이는 Bright Data의 AI 제품 및 서비스가 다루는 수많은 시나리오 중 하나에 불과합니다.
지금 바로 Bright Data에 무료로 가입하여 스크래핑 솔루션을 직접 체험해 보세요!


