

기존 웹 스크래핑은 특정 웹사이트 레이아웃에 맞춰 복잡하고 시간이 많이 소요되는 코드를 작성하는 경우가 많으며, 사이트 변경 시 쉽게 깨질 수 있습니다. ScrapeGraphAI는 대규모 언어 모델(LLM)을 활용하여 정보를 추출하고 인간처럼 해석하므로 레이아웃 대신 데이터에 집중할 수 있습니다. ScrapeGraphAI에 LLM을 통합하면 데이터 추출이 향상되고 콘텐츠 수집이 자동화되며 실시간 분석이 가능해집니다.
이 글에서는 ScrapeGraphAI를 활용한 웹 스크래핑 방법을 소개합니다. 그에 앞서 시간과 비용을 절약해 줄 Bright Data의 솔루션을 먼저 소개합니다.
Bright Data의 웹 스크래핑 솔루션
Bright Data는 효율적이고 확장 가능하며 규정 준수된 데이터 추출을 위해 최적화된 포괄적인 웹 스크래핑 솔루션 제품군을 제공합니다:
- 웹 스크레이퍼 API
- 즉시 사용 가능한 데이터셋
- 맞춤형 데이터셋
이러한 솔루션은 빠르고 정확하며 확장 가능한 데이터 수집을 가능하게 하여 소규모 애플리케이션부터 기업 수준의 요구 사항에 이르기까지 모든 범위의 프로젝트에 적합합니다.
ScrapeGraphAI를 활용한 LLM 웹 스크래핑 구현
이 튜토리얼을 시작하기 전에 다음 전제 조건이 필요합니다:
- Python 3.x 설치.
- OpenAI 계정. 이 튜토리얼은 ScrapeGraphAI로 데이터를 스크래핑하기 위해 OpenAI LLM을 사용합니다. Anthropic, Google 또는 Llama, Mistral AI와 같은 오픈 소스 모델을 사용할 수도 있지만, 이 튜토리얼에서는 인기와 설정 용이성 때문에 GPT-4를 사용합니다.
Python으로 웹 스크래핑을 처음 접하신다면, 시작하기 위해 이 웹 스크래핑 튜토리얼을 참고하세요.
환경 설정
가장 먼저 가상 환경을 생성해야 합니다. 터미널을 열고 프로젝트 디렉터리로 이동하세요:
python -m venv venv
그런 다음 가상 환경을 활성화하세요. macOS 및 Linux에서는 다음 명령어로 가능합니다:
source venv/bin/activate
Windows에서는 다음 명령어를 사용하세요:
venvScriptsactivate
가상 환경을 활성화한 후에는 ScrapeGraphAI와 그 종속성을 설치해야 합니다:
pip install scrapegraphai
playwright install
playwright install 명령어는 Chromium, Firefox, WebKit에 필요한 브라우저를 설정합니다.
환경 변수를 안전하게 관리하려면 python-dotenv를 설치하세요:
pip install python-dotenv
API 키와 같은 민감한 정보를 보호하는 것이 중요합니다. 환경 변수를 코드 파일과 분리하여 .env 파일에 저장하는 것이 권장됩니다.
프로젝트 디렉터리에 .env라는 새 파일을 생성하고 OpenAI 키를 지정하는 다음 줄을 추가하세요:
OPENAI_API_KEY="your-openai-api-key"
이 파일은 Git과 같은 버전 관리 시스템에 커밋해서는 안 됩니다. 이를 방지하려면 .gitignore 파일에 .env를 추가하세요.
ScrapeGraphAI로 데이터 스크래핑하기
이 튜토리얼에서는 웹 스크래핑 기법 연습을 위한 데모 웹사이트인 Books to Scrape에서 제품 데이터를 스크래핑하는 것으로 시작합니다. 이 웹사이트는 온라인 서점을 모방하여 다양한 장르의 책을 가격, 평점, 재고 상태와 함께 제공합니다:
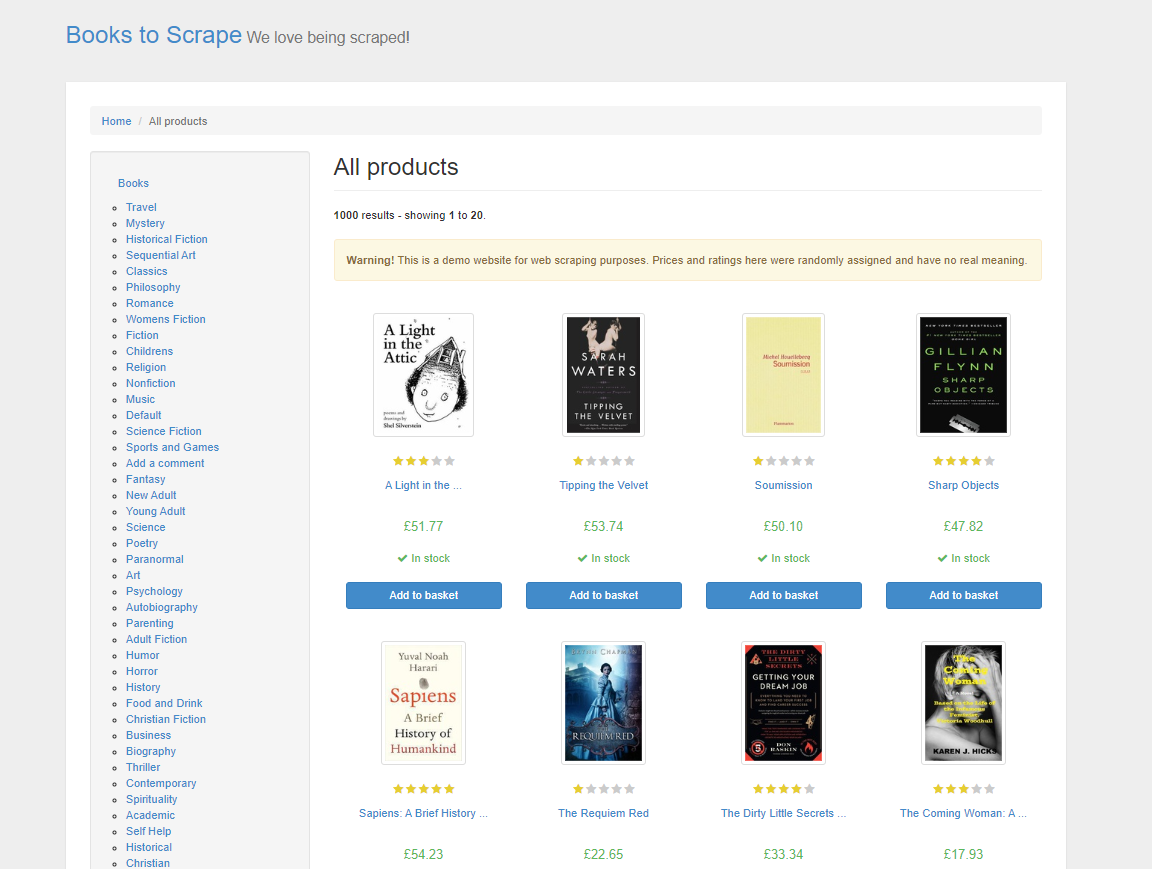
기존 HTML 웹 스크래핑에서는 페이지의 HTML을 분석하고, 원하는 데이터를 찾기 위해 요소와 태그를 수동으로 검사해야 합니다. 이 과정은 시간이 많이 소요되며 웹 구조에 대한 탄탄한 이해가 필요합니다. ScrapeGraphAI를 사용하면 프롬프트를 통해 원하는 데이터만 지정하면 LLM이 이를 추출할 만큼 지능적입니다.
ScrapeGraphAI는 다양한 스크래핑 요구에 맞춰 여러 유형의 그래프를 제공합니다. 이 그래프들은 스크래핑 프로세스의 구조와 목표를 정의합니다. 주요 그래프 유형을 간략히 소개합니다:
- SmartScraperGraph는 프롬프트와 URL 또는 로컬 파일을 제공하는 단일 페이지 스크레이퍼입니다. LLM을 활용하여 지정한 정보를 추출합니다.
- SearchGraph는 프롬프트에 기반해 검색 엔진 결과에서 정보를 추출하는 다중 페이지 스크레이퍼입니다.
- SpeechGraph는 SmartScraperGraph에 텍스트 음성 변환 기능을 추가하여 추출된 콘텐츠의 오디오 파일을 생성합니다.
- ScriptCreatorGraph는 프롬프트와 URL을 입력받아 결과를 생성하는 대신, 지정된 URL을 스크래핑할 수 있는 Python 스크립트를 출력합니다.
이러한 그래프가 정확한 요구 사항에 부합하지 않는 경우, ScrapeGraphAI를 사용하면 서로 다른 노드를 결합하고 특정 요구 사항에 맞게 스크래핑 프로세스를 조정하여 사용자 지정 그래프를 만들 수도 있습니다.
적합한 그래프 유형 선택과 더불어, 특히 프롬프트 및 모델 선택과 관련하여 스크레이퍼를 적절히 구성해야 합니다. 프롬프트는 LLM이 정확히 어떤 데이터를 추출해야 하는지 이해하도록 안내하므로 명확하고 명시적이어야 합니다. 또한 올바른 LLM 모델 선택은 스크레이퍼가 웹사이트 콘텐츠를 얼마나 잘 처리하고 해석하는지를 결정합니다. 지리적 제한 콘텐츠를 더 원활하게 스크래핑하기 위한 프록시 설정이나 프로세스의 효율성과 속도를 유지하기 위한 헤드리스 모드 설정 등 다른 옵션도 구성할 수 있습니다. 적절한 구성은 궁극적으로 스크래핑된 데이터의 정확성과 관련성을 결정합니다.
스크레이퍼 코드 작성
스크레이퍼 코드를 작성하려면 app. py라는 새 파일을 생성하고 다음 코드 줄을 추가하세요:
from dotenv import load_dotenv
import os
from scrapegraphai.graphs import SmartScraperGraph
# .env 파일에서 환경 변수 로드
load_dotenv()
# OpenAI API 키 접근
OPENAI_API_KEY = os.getenv('OPENAI_API_KEY')
# ScrapeGraphAI 구성
graph_config = {
"llm": {
"api_key": OPENAI_API_KEY,
"model": "openai/gpt-4o-mini",
}
}
# 프롬프트 및 소스 정의
prompt = "이 페이지의 모든 책 제목, 가격 및 재고 상태를 추출하세요."
source = "http://books.toscrape.com/"
# 스크레이퍼 그래프 생성
smart_scraper_graph = SmartScraperGraph(
prompt=prompt,
source=source,
config=graph_config)
# 스크레이퍼 실행
result = smart_scraper_graph.run()
# 결과 출력
print(result)
이 코드는 환경 변수 처리를 위한 os 및 dotenv와 같은 필수 모듈과 스크래핑에 사용되는 ScrapeGraphAI의 SmartScraperGraph 클래스를 임포트합니다. 그런 다음 dotenv를 통해 환경 변수를 로드하여 API 키와 같은 민감한 데이터를 안전하게 유지합니다. 다음으로, 스크래핑에 사용할 모델과 API 키를 지정하는 LLM 구성을 생성합니다. 이 구성은 사이트 URL 및 스크래핑 프롬프트와 함께 SmartScraperGraph를 정의하는 데 사용되며, run() 메서드를 통해 실행되어 지정된 데이터를 수집하는 프로세스를 시작합니다.
이 코드를 실행하려면 터미널을 열고 python app.py를 실행하세요. 출력 결과는 다음과 같아야 합니다:
{
"books": [
{
"title": "A Light in the Attic",
"price": "£51.77",
"availability": "In stock"
},
{
"title": "Tipping the Velvet",
"price": "£53.74",
"availability": "In stock"
}, ...
]
}
참고: 코드 실행 시 문제가 발생하면 ScrapeGraphAI의 기본 종속성인
grpcio패키지를 수동으로 설치해야 할 수 있습니다. 다음 명령어로 설치할 수 있습니다:
pip install grpcio
ScrapeGraphAI는 웹 스크래핑의 데이터 추출 부분을 쉽게 만들어 주지만, CAPTCHA나 IP 차단과 같은 일반적인 문제들은 여전히 존재하며 이를 처리하는 방법을 알아야 합니다.
브라우징 행동을 모방하려면 코드에 시간 지연을 구현할 수 있습니다. 탐지를 피하기 위해 회전 프록시를 활용할 수도 있습니다. 또한 Bright Data의 CAPTCHA 솔버나 Anti Captcha 같은 CAPTCHA 해결 서비스를 스크레이퍼에 통합하여 CAPTCHA를 자동으로 해결할 수 있습니다.
참고: 항상 웹사이트의 이용 약관을 준수해야 합니다. 개인적 용도의 스크래핑은 허용되는 경우가 많지만, 데이터를 재배포할 경우 법적 문제가 발생할 수 있습니다.
ScrapeGraphAI에서 프록시 사용하기
ScrapeGraphAI는 IP 차단 회피 및 지역 제한 콘텐츠 접근을 위해 프록시 서비스를 설정할 수 있습니다. 무료 프록시 서비스를 사용하거나 사용자 지정 프록시 서버를 구성할 수 있습니다.
무료 프록시 서비스를 사용하려면 graph_config에 다음을 추가하세요:
graph_config = {
"llm": {
"api_key": OPENAI_API_KEY,
"model": "openai/gpt-4o-mini",
},
"loader_kwargs": {
"proxy": {
"server": "broker",
"criteria": {
"anonymous": True,
"secure": True,
"countryset": {"US"},
"timeout": 10.0,
"max_tries": 3
},
},
}
}
이 구성은 ScrapeGraphAI가 사용자의 기준에 맞는 무료 프록시 서비스를 사용하도록 지시합니다.
Bright Data와 같은 제공업체의 맞춤형 프록시 서버를 사용하려면, 서버 URL, 사용자 이름, 비밀번호를 삽입하여 graph_config를 다음과 같이 수정하세요:
graph_config = {
"llm": {
"api_key": OPENAI_API_KEY,
"model": "openai/gpt-4o-mini",
},
"loader_kwargs": {
"proxy": {
"server": "http://your_proxy_server:port",
"username": "your_username",
"password": "your_password",
},
}
}
사용자 지정 프록시 서버를 사용하면 특히 대규모 웹 스크래핑에 여러 이점이 있습니다. 프록시 위치를 제어할 수 있어 지역 제한 콘텐츠를 스크래핑할 수 있습니다. 또한 무료 프록시에 비해 사용자 지정 프록시는 더 안정적이고 안전하여 IP 차단 또는 속도 제한을 받을 가능성이 줄어듭니다.
데이터 정리 및 전처리
데이터를 스크래핑한 후에는, 특히 AI 모델에 입력할 계획이라면 데이터를 정리하고 전처리해야 합니다. 깨끗한 데이터는 모델이 정확하고 일관된 정보로부터 학습하도록 보장하며, 이는 모델의 성능과 신뢰성에 직접적인 영향을 미칩니다. 데이터 정리는 일반적으로 누락된 값 처리, 데이터 유형 수정, 텍스트 정규화, 중복 제거 등을 포함합니다.
pandas를 사용하여 이전에 스크래핑한 데이터를 정리하는 예시는 다음과 같습니다:
import pandas as pd
# 결과를 DataFrame으로 변환
df = pd.DataFrame(result["books"])
# 통화 기호 제거 및 가격을 부동 소수점으로 변환
df['price'] = df['price'].str.replace('£', '').astype(float)
# 재고 상태 텍스트 표준화
df['availability'] = df['availability'].str.strip().str.lower()
# 누락된 값 처리
df.dropna(inplace=True)
# 정리된 데이터 미리보기
print(df.head())
이 코드는 책 가격에서 통화 기호를 제거하고, 재고 상태를 소문자로 변환하여 표준화하며, 누락된 값을 처리하여 데이터를 정리합니다.
코드를 실행하기 전에 데이터 조작을 위한 pandas 라이브러리를 설치해야 합니다:
pip install pandas
코드를 실행하려면 터미널을 열고 python app.py를 실행하세요. 출력 결과는 다음과 같아야 합니다:
title price availability
0 A Light in the Attic 51.77 in stock
1 Tipping the Velvet 53.74 in stock
2 Soumission 50.10 in stock
3 Sharp Objects 47.82 in stock
4 Sapiens: A Brief History of Humankind 54.23 in stock
이는 스크랩한 데이터를 정리하는 방법의 예시일 뿐입니다. 정리 과정은 데이터와 훈련 중인 LLM 사용 사례에 따라 달라집니다. 데이터를 정리하면 언어 모델이 구조화되고 의미 있는 입력을 받도록 보장할 수 있습니다. AI 프로젝트에 데이터를 활용하는 방법에 대해 더 알고 싶다면 ‘데이터 포 AI’를 참고하세요.
이 튜토리얼의 모든 코드는 이 GitHub 저장소에서 확인할 수 있습니다.
결론
ScrapeGraphAI는 웹 스크래핑에 적응형 접근 방식을 제공하기 위해 LLM을 활용하여 웹사이트 구조 변화에 대응하고 데이터를 지능적으로 추출합니다. 그러나 웹 스크래핑을 확장하는 데에는 IP 차단, CAPTCHA 해결, 법적 규정 준수 유지와 같은 과제가 따릅니다.
이러한 과제를 극복하기 위해 Bright Data는 AI 및 머신러닝 프로젝트에 맞춤화된 포괄적인 웹 스크래핑 솔루션 제품군을 제공합니다. 여기에는 Bright Data 웹 스크래퍼 API, 프록시 서비스, 서버리스 스크래핑이 포함됩니다. 또한 Bright Data는 100개 이상의 인기 웹사이트에서 수집한 데이터로 구성된 즉시 사용 가능한 데이터셋도 제공합니다.
지금 바로 무료 체험을 시작하세요!





