

이 가이드에서는 다음을 배우게 됩니다:
- Dify란 무엇이며 왜 사용해야 하는지.
- 올인원 스크래핑 플러그인과 통합해야 하는 이유.
- Bright Data 스크래핑 플러그인과 Dify 통합의 이점.
- Dify 스크래핑 워크플로우를 생성하는 단계별 튜토리얼.
자, 시작해 보겠습니다!
Dify: 로우코드 AI 개발의 힘
Dify는 오픈 소스 LLM 앱 개발 플랫폼입니다. AI 기반 애플리케이션 제작을 간소화하는 LLM-ops 솔루션으로 작동합니다.
더 구체적으로, 개발자가 다음과 같은 기능을 제공하여 즉시 사용 가능한 에이전트형 AI 애플리케이션을 구축하고 출시할 수 있도록 지원합니다:
- 시각적 워크플로 빌더: 드래그 앤 드롭 인터페이스로 다단계 AI 프로세스를 설계합니다. 반복적인 코드 작업에 매몰되지 않고 다양한 모델, 도구 및 로직을 연결할 수 있습니다.
- 모델 독립성: OpenAI의 GPT 시리즈와 같은 독점 모델부터 다양한 오픈소스 대안까지 광범위한 LLM과 통합됩니다. 이를 통해 사용 사례에 가장 적합한 모델을 유연하게 선택할 수 있습니다.
- 백엔드 서비스(BaaS): 호스팅, 확장성 관리, 백엔드 인프라 운영의 복잡성을 처리합니다. 이를 통해 기반 인프라 관리 대신 AI 기능 활용에 집중할 수 있습니다.
- 확장성: 타사 제공업체의 플러그인과 맞춤형 도구를 통해 기능을 손쉽게 확장할 수 있습니다. 이를 통해 Dify는 다양한 사용 사례에 유연하게 대응할 수 있습니다.
Dify에서 전용 스크래핑 플러그인의 필요성
대규모 웹 스크래핑은 많은 어려움을 안고 있습니다. 웹사이트들은 단순한 데이터 수집 시도를 쉽게 차단할 수 있는 봇 방지 조치를 사용합니다. 결과적으로 이러한 장애물을 극복하기 위한 시스템을 구축하고 유지하는 것은 복잡하고 많은 자원을 소모합니다.
바로 이 부분에서 Bright Data Dify 플러그인이 역할을 합니다. 이 플러그인은 프록시 로테이션과 IP 관리부터 CAPTCHA 해결 및 데이터 파싱에 이르기까지 모든 기본적인 복잡성을 처리합니다. 즉, Dify 에이전트가 일관되고 고품질의 웹 데이터를 수신하도록 보장합니다.
구체적으로 Bright Data 플러그인은 다음과 같은 도구를 제공합니다:
- 구조화된 데이터 피드: 전자상거래 제품 페이지나 부동산 목록 등 50개 이상의 플랫폼에서 구조화되고 체계화된 데이터를 제공합니다.
- 마크다운 형식으로 스크래핑: 광고, 네비게이션 바 등 불필요한 요소를 제거하여 깔끔한 마크다운 형식의 텍스트를 제공합니다.
- 검색 엔진 도구: Google, Bing, Yandex 등 다양한 검색 엔진에서 직접 쿼리를 수행합니다. 특정 키워드의 검색 순위 모니터링, 경쟁사 콘텐츠 탐색, SERP RAG 워크플로우에 활용할 수 있습니다.
Dify와 Bright Data 플러그인 통합의 이점
Dify의 AI 오케스트레이션 기능과 Bright Data의 스크래핑 기능을 결합하면 다음과 같은 기능을 활용할 수 있습니다:
- 실시간 데이터 접근: 오래된 데이터에 의존하지 않고 AI 에이전트가 최신 정보를 위해 실시간 웹을 쿼리할 수 있습니다. 이는 AI 애플리케이션이 가능한 최신 데이터로 운영되도록 보장합니다.
- 복잡한 연구 및 분석 자동화: Dify 워크플로 내에서 LLM에 데이터를 직접 공급함으로써 수시간의 수작업이 필요한 작업을 자동화할 수 있습니다. 예를 들어, 전자상거래 사이트에서 경쟁사 제품 목록을 모니터링하는 RAG 워크플로를 구축할 수 있습니다.
- 기술적 복잡성 간소화: 웹 스크래핑은 사이트들이 정교한 차단 기술을 사용하기 때문에 쉽지 않습니다. Bright Data 플러그인은 이러한 차단을 대신 회피합니다. Dify는 이러한 기능을 활용할 수 있는 간편한 인터페이스를 제공합니다.
- 다양한 사용 사례를 위한 다용도성: 이 플러그인은 구조화된 데이터 추출, 마크다운 정리용 페이지 스크래핑, 검색 엔진 쿼리 실행 등 다양한 도구를 제공합니다. 이로 인해 Dify와 Bright Data의 통합은 여러 사용 사례에 유연하게 적용될 수 있습니다.
제품 요약화를 위한 Dify와 Bright Data 통합: 단계별 튜토리얼
Dify와 Bright Data의 통합 사용법을 단계별로 안내하는 튜토리얼을 시작해 보겠습니다.
만들게 될 워크플로의 목표는 아마존 제품을 입력으로 주고 요약본을 받는 것입니다. 사용할 제품은 아마존의 Apple AirTag입니다:
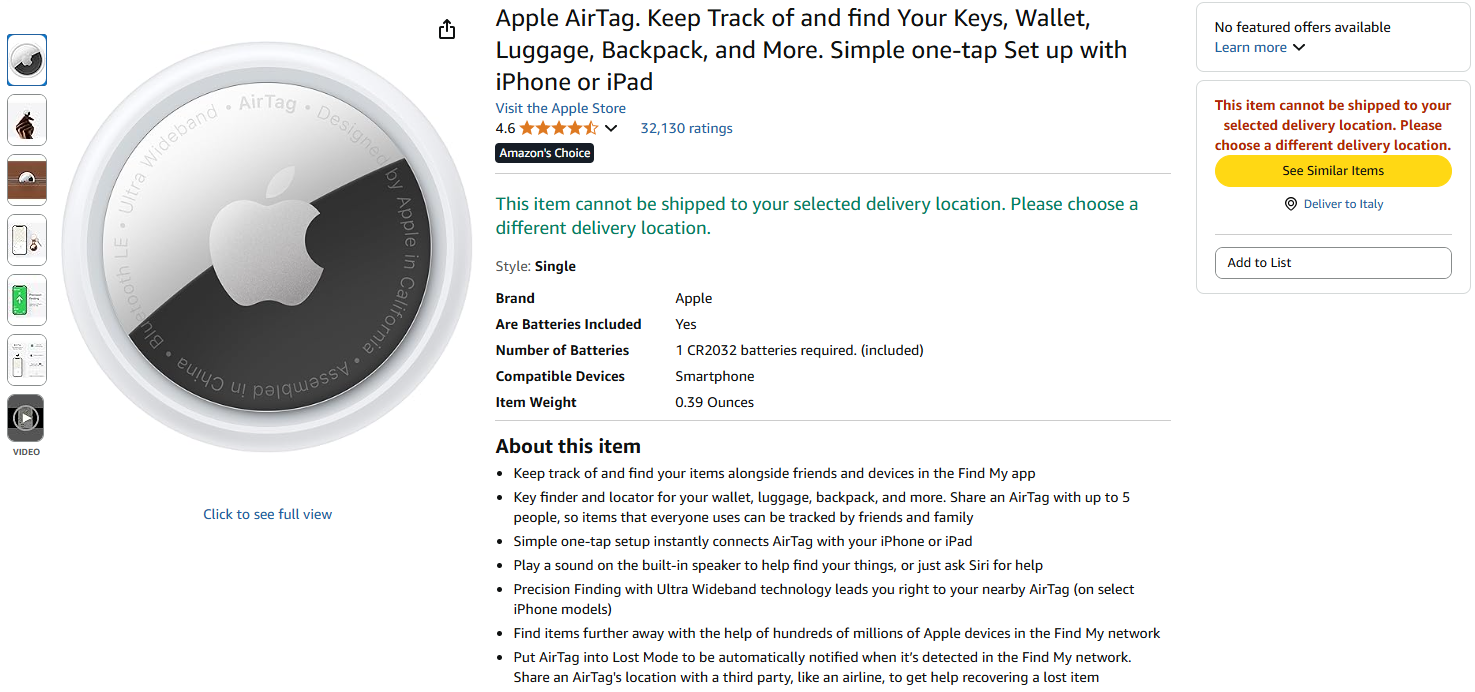
AI 스크래핑 목표를 달성하기 위해 서로 다른 노드를 연결하여 4단계 워크플로를 구축합니다. 각 노드는 특정 역할을 수행합니다:
- 입력 변수(아마존 제품 페이지 URL)를 정의하는 “시작” 노드.
- “구조화된 데이터 피드(Structured Data Feeds)” 노드는 해당 URL을 가져와 콘텐츠를 스크래핑하고 아마존 페이지의 모든 구조화된 데이터를 추출합니다.
- 스크래핑된 데이터를 처리하는 “LLM” 노드. 특정 프롬프트를 통해 제품 요약문을 생성하도록 지시합니다.
- LLM이 생성한 요약 텍스트를 표시하는 “종료” 노드.
이 전체 4단계 AI 스크래핑 프로세스는 완전히 시각적으로 구현됩니다. 간단한 흐름으로 노드들을 연결하기만 하면 되며, 단 한 줄의 코드도 작성할 필요가 없습니다.
지침을 따라 Dify에서 Bright Data 기반의 코드 없는 웹 스크래핑 AI 워크플로를 구축하세요!
필요 사항
Dify와 Bright Data를 통합하는 이 튜토리얼을 재현하려면 다음이 필요합니다:
- Dify 계정 (무료 계정으로도 충분합니다).
- Bright Data API 키.
아직 준비되지 않았다면 위 링크를 따라 안내에 따라 모든 설정을 완료하세요.
필수 조건
LLM 노드를 사용하려면 먼저 Dify에서 LLM 통합을 설정해야 합니다. 설정하려면 프로필 이미지를 클릭하고 “설정” 옵션을 선택하세요:
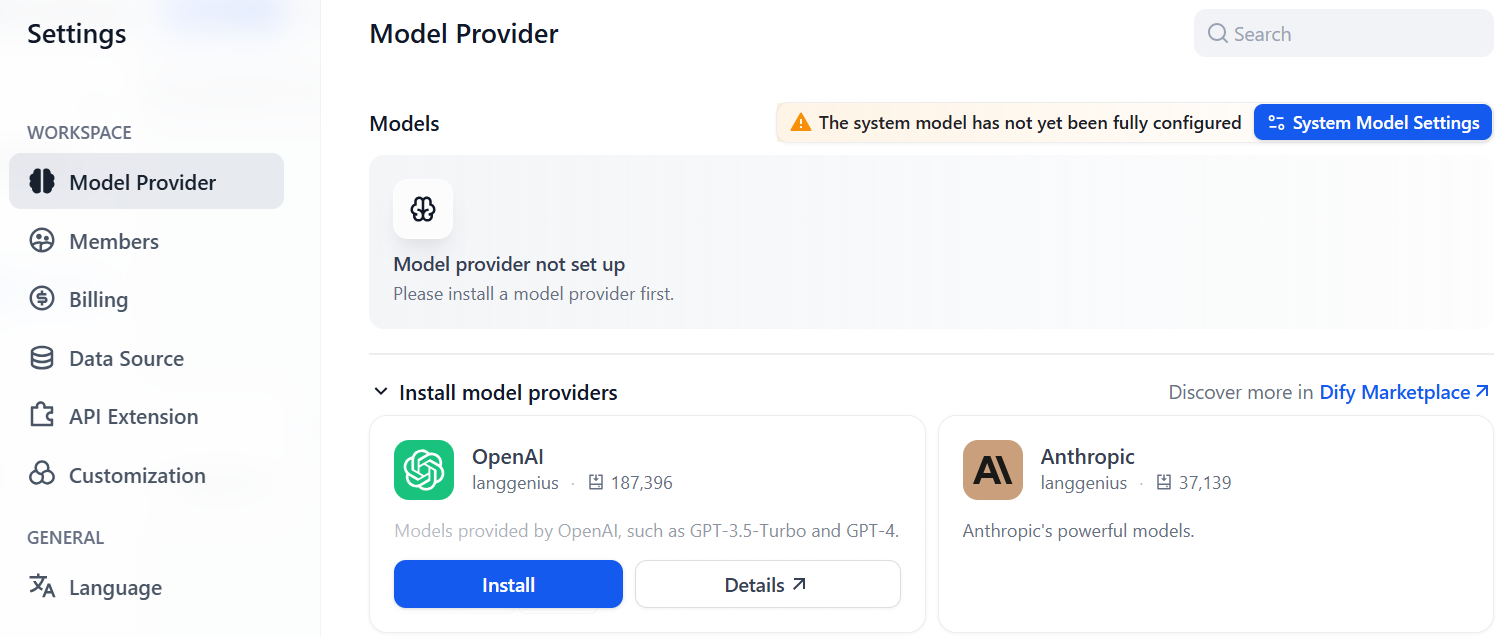
모델을 선택할 수 있는 페이지(“모델 제공자” 탭)로 이동합니다. 예를 들어 OpenAI 제공자 플러그인을 설치할 수 있습니다:
잘하셨습니다! 이제 Dify 웹 스크래핑 워크플로를 시작할 준비가 되었습니다.
1단계: Bright Data 플러그인 다운로드 및 통합
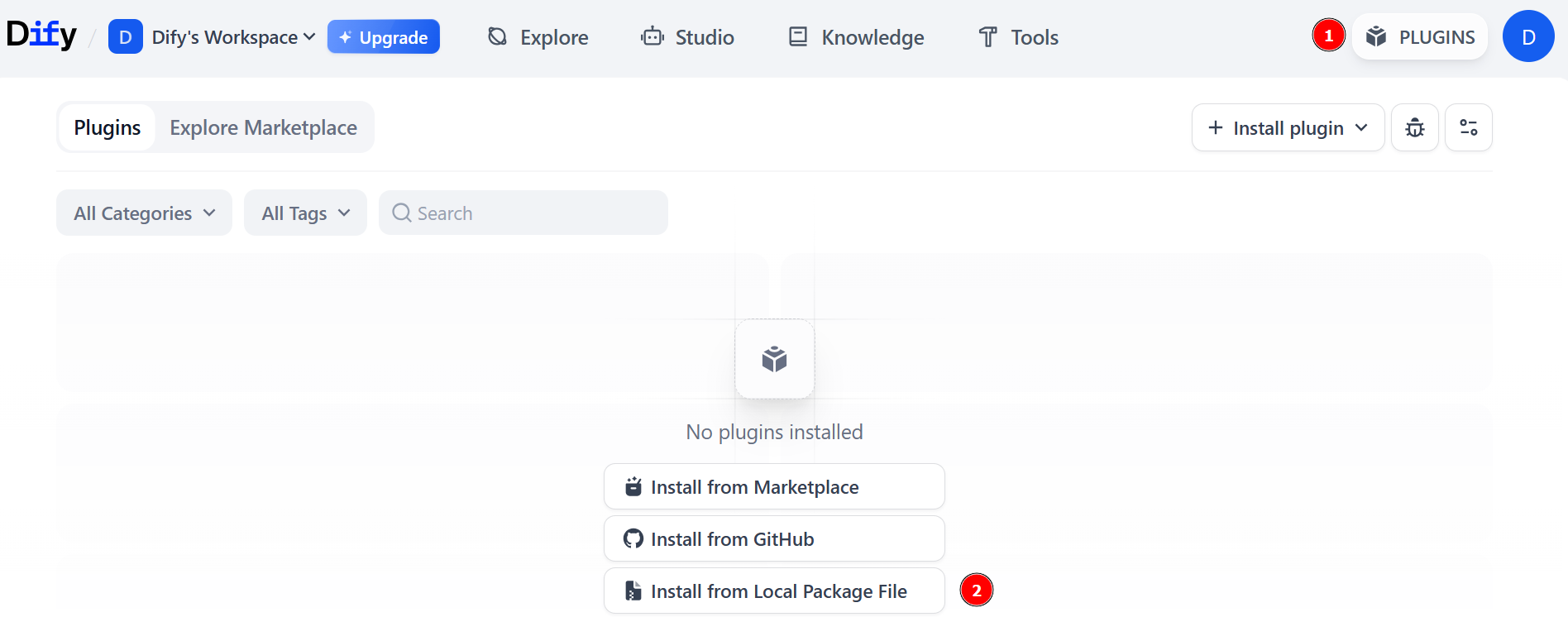
공식 Dify 저장소에서 최신 Bright Data 플러그인 패키지를 다운로드하세요. 그런 다음 “PLUGINS”를 누르고 “Install from Local Package File” 옵션을 선택하세요:
앞서 다운로드한 로컬 파일을 선택하고 “설치” 버튼을 클릭하세요:
잘하셨습니다! Bright Data 통합 패키지가 Dify에 로드 및 설치되었습니다.
2단계: 새 Dify 애플리케이션 생성
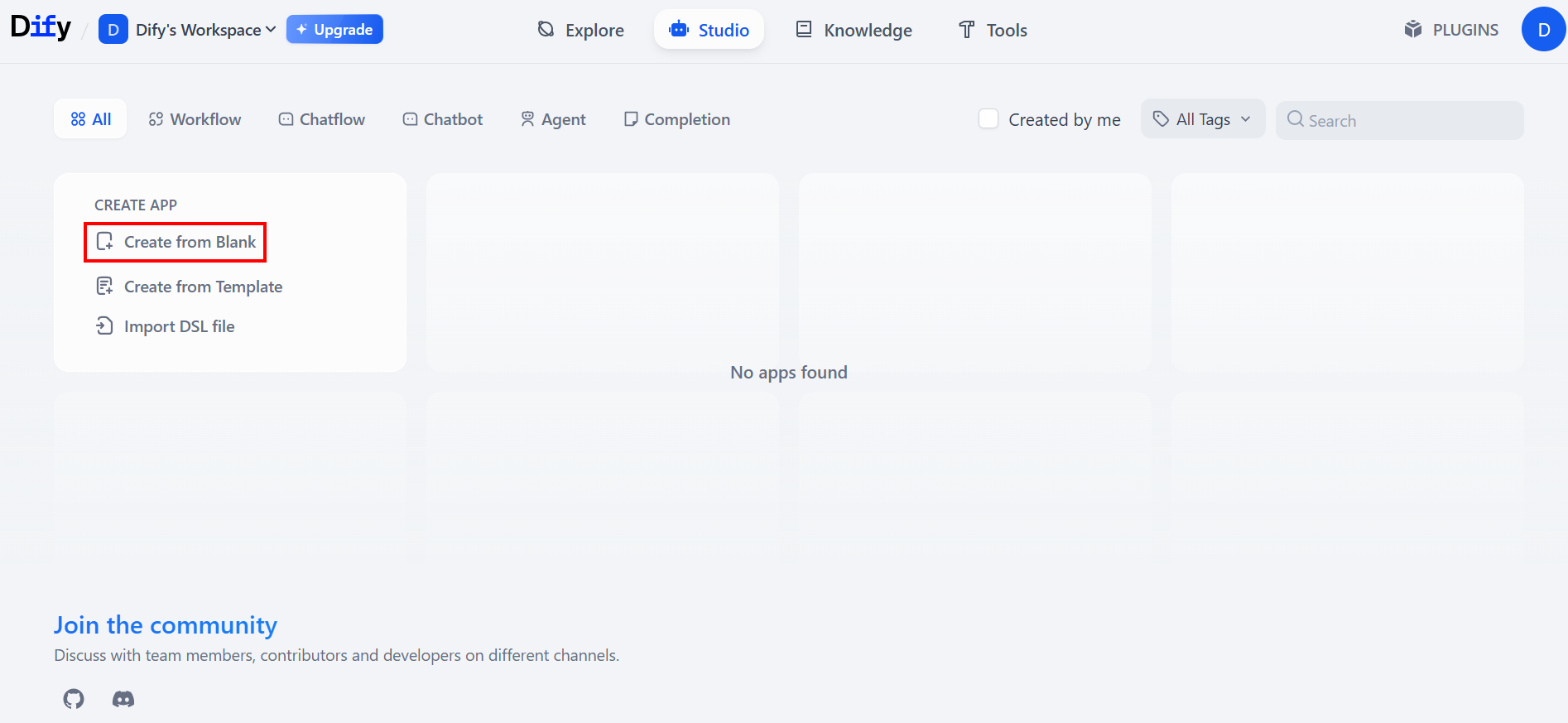
Dify 작업 공간 홈페이지에서 아래와 같이 “Create from Blank”를 선택하여 새 애플리케이션을 처음부터 생성하세요:
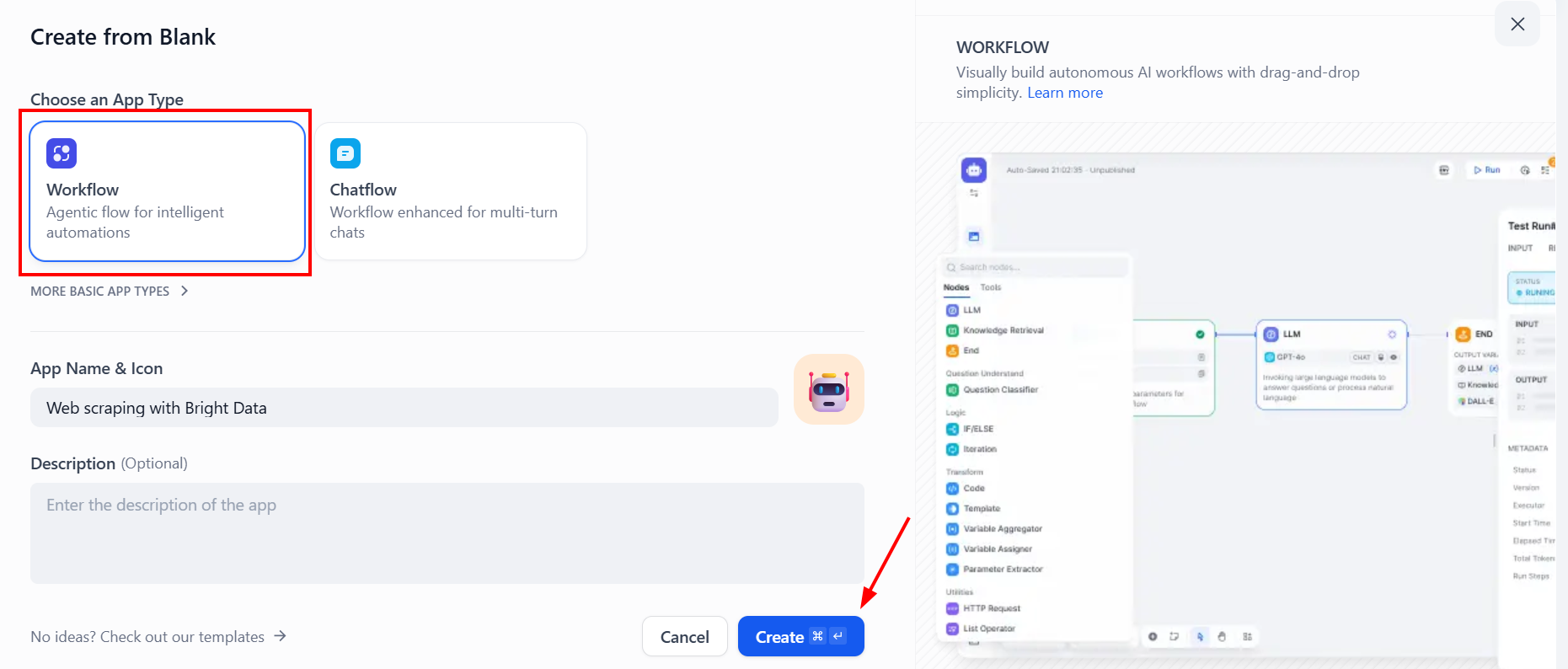
다음으로 “워크플로우” 유형을 선택하고 “생성”을 클릭하세요:
아래는 새로 생성된 빈 워크플로의 모습입니다:

훌륭합니다! 방금 새로운 Dify 워크플로우를 생성했습니다. 이제 웹 스크래핑에 필요한 노드를 추가할 차례입니다.
3단계: 웹 스크래핑용 노드 구성
이제 Bright Data를 통해 Dify 웹 스크래핑 워크플로우에 노드를 추가하고 필요한 매개변수를 설정할 수 있습니다.
먼저 “시작” 노드를 클릭한 후 “입력 필드”를 선택하세요:
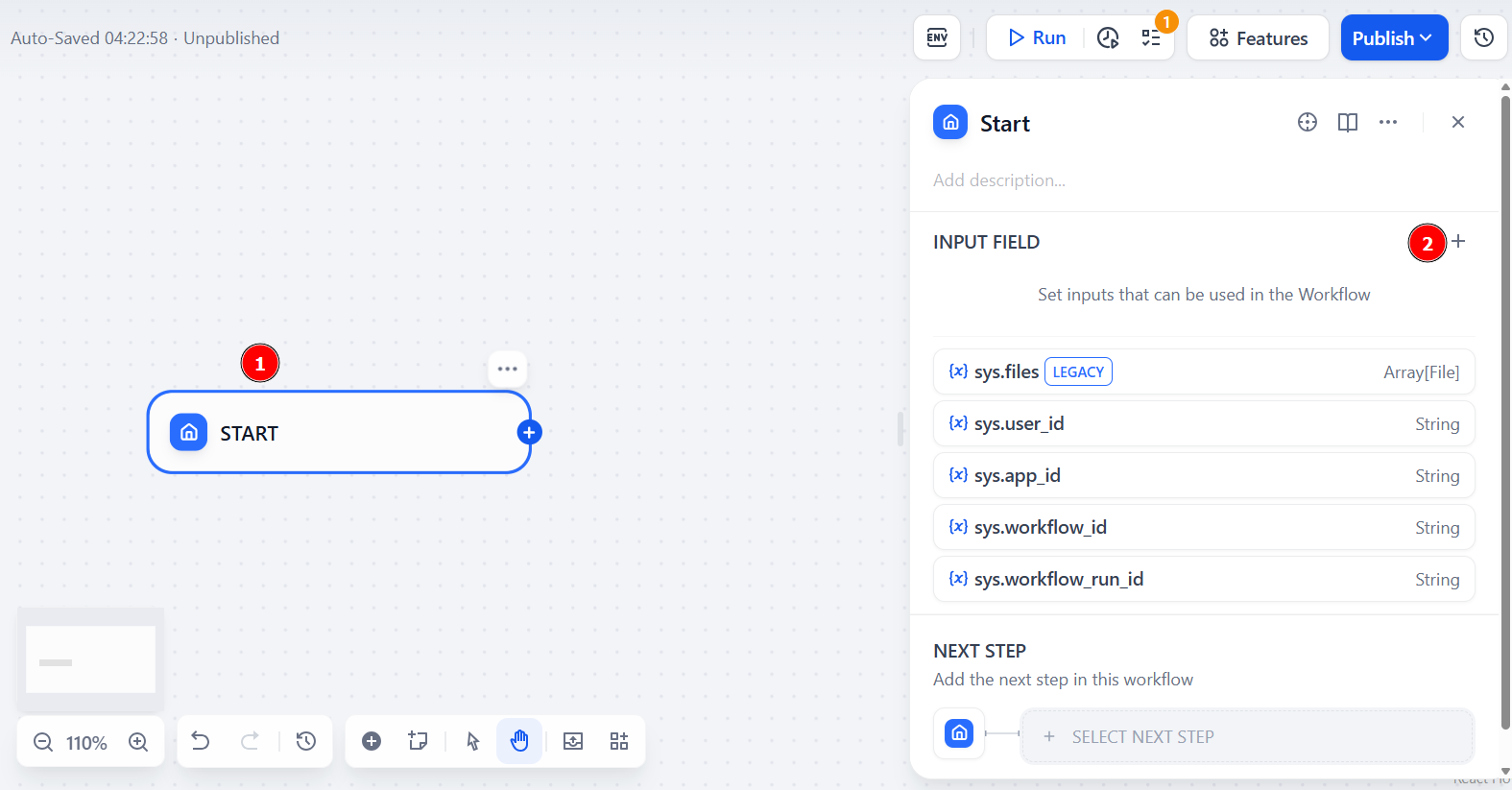
유형으로 “단락(Paragraph)”을 선택하고 “변수 이름(Variable Name)” 필드에 이름을 지정하세요. 예를 들어 product_url. “최대 길이(Max length)” 값을 최소 200으로 변경하세요. 이는 스크래핑할 대상 페이지의 URL을 나타냅니다. 워크플로를 실행하려면 여기에 입력을 전달해야 합니다.
“저장” 버튼을 클릭하여 확인합니다:
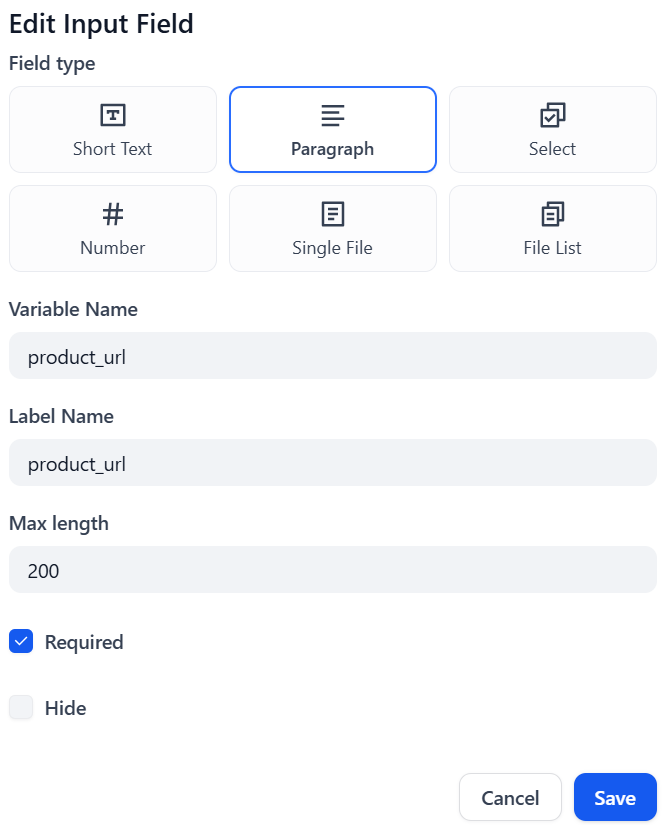
완료! “시작” 노드가 올바르게 설정되었습니다.
“시작” 노드의 “+”를 클릭하여 계속합니다. “도구” > “Bright Data 웹 스크레이퍼” > “구조화된 데이터 피드”를 선택하세요:
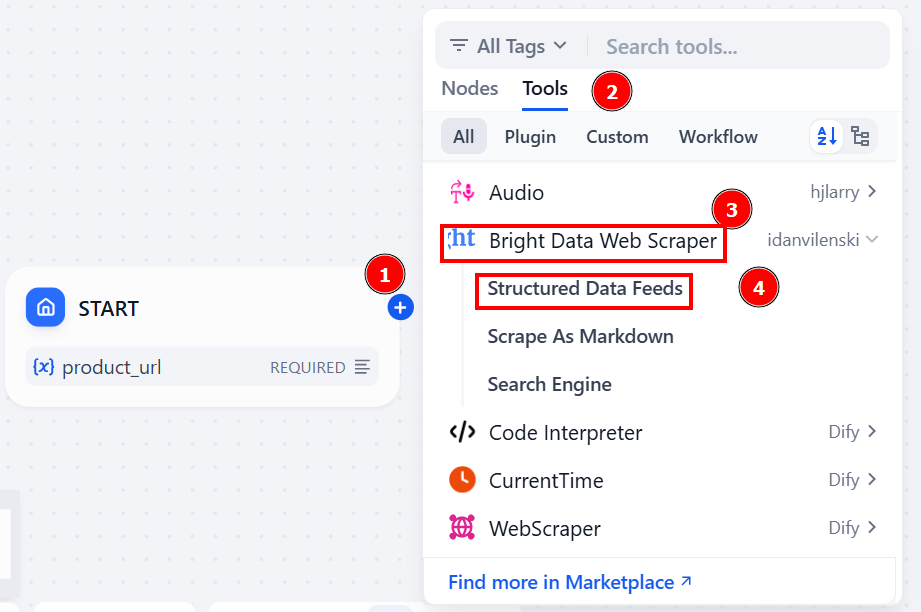
Bright Data 노드는 Dify 워크플로우와 [Bright Data AI 인프라](
/ai)를 연결하는 다리 역할을 합니다. 이를 통해 AI 스크래핑 에이전트가 웹에서 필요한 정보를 추출할 수 있게 됩니다.
“구조화된 데이터 피드” 도구를 선택하면 복잡한 아마존 제품 페이지를 예측 가능한 데이터 필드를 가진 구조화된 JSON 출력으로 변환합니다.
이제 “Authorize”를 클릭하여 Bright Data API 토큰을 입력하세요:
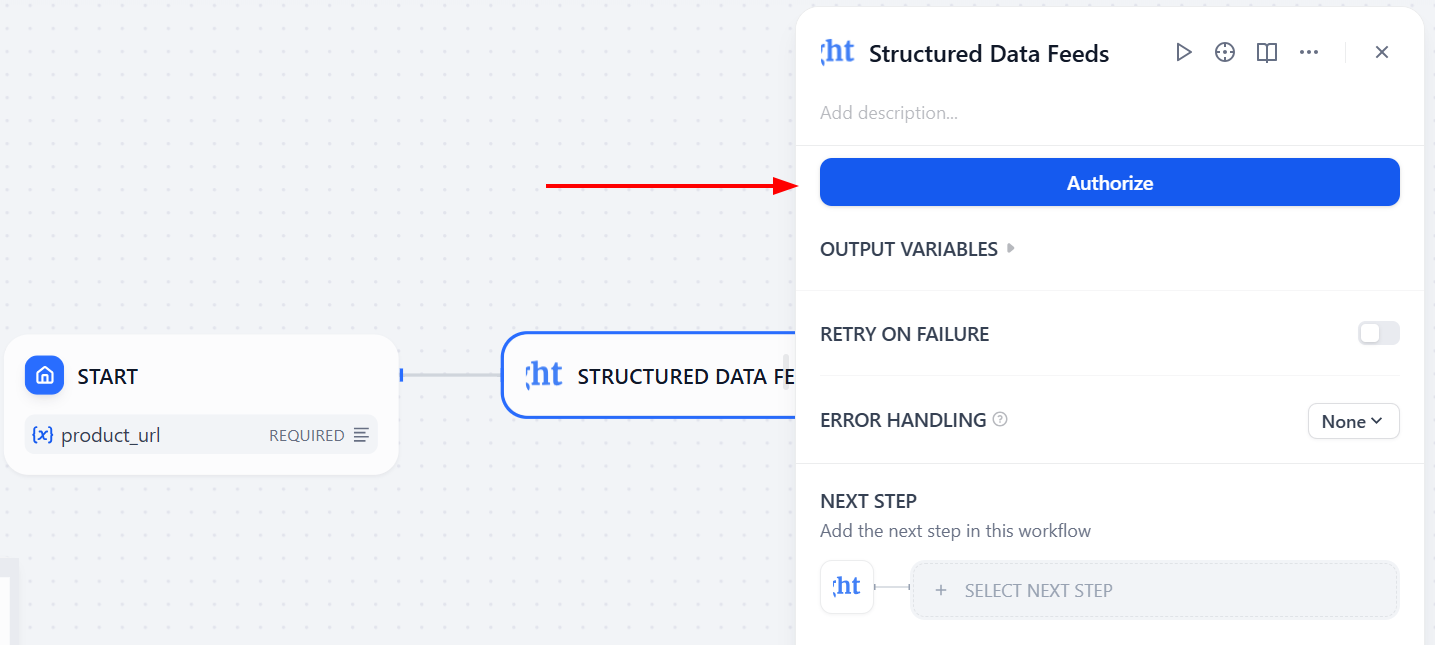
입력 변수로 product_url을 선택하세요. 이렇게 하면 “시작” 노드가 실제 제품 URL 값을 Bright Data 노드의 입력값으로 전달합니다.
이를 위해 “대상 URL” 필드에 “/”를 입력하면 사용 가능한 변수 목록이 표시됩니다. 또한 “데이터 요청 설명” 필드에 설명을 추가하세요:
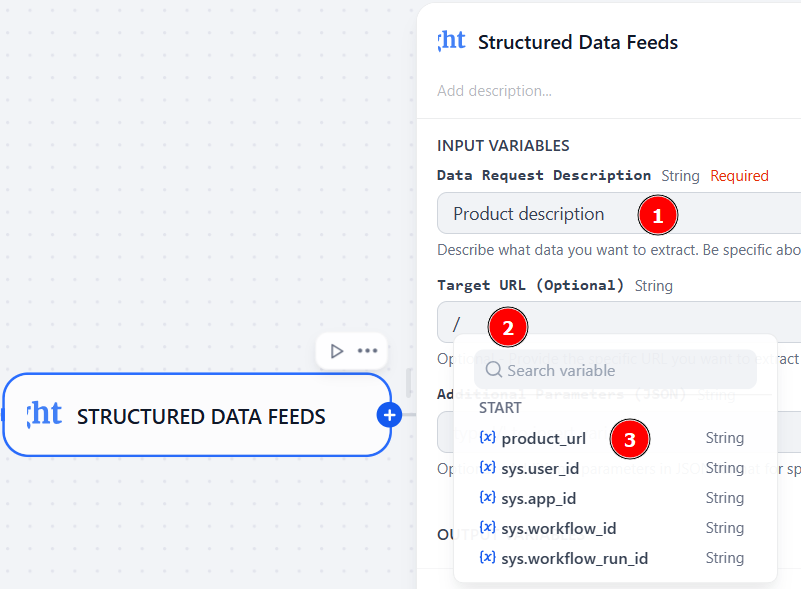
잘하셨습니다! Bright Data 노드 설정이 완료되었습니다. 다음 노드로 진행하세요.
“+”을 클릭하여 LLM 노드를 추가하세요:
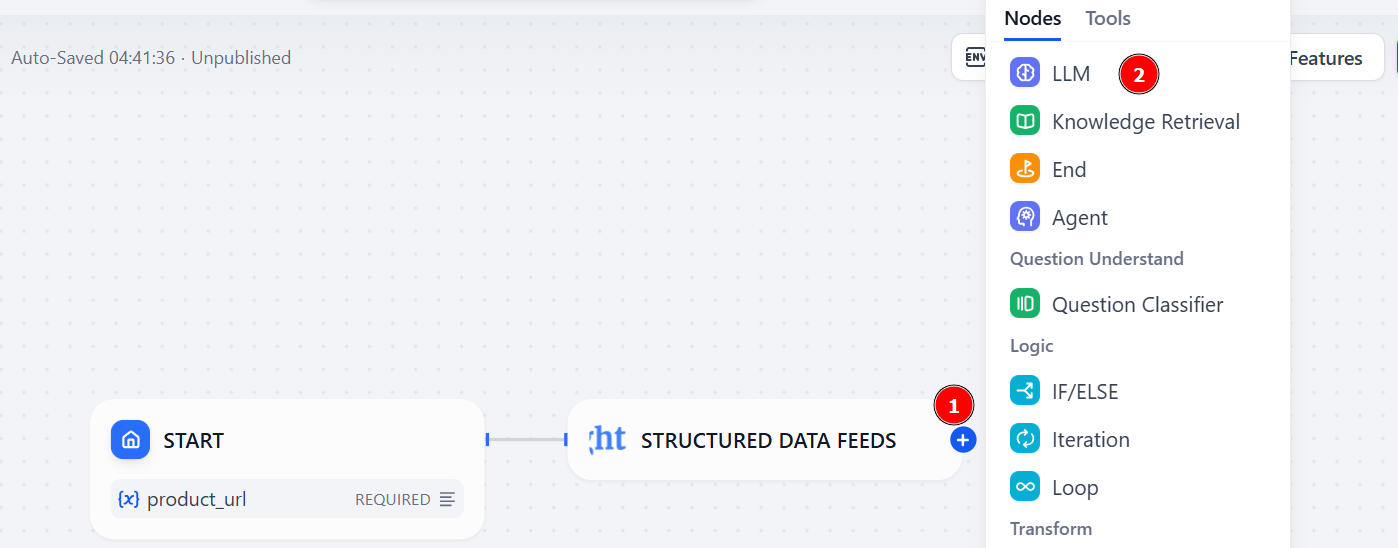
“모델” 섹션에서 “모델 구성”을 선택하고 목록에서 LLM 모델을 선택하세요:
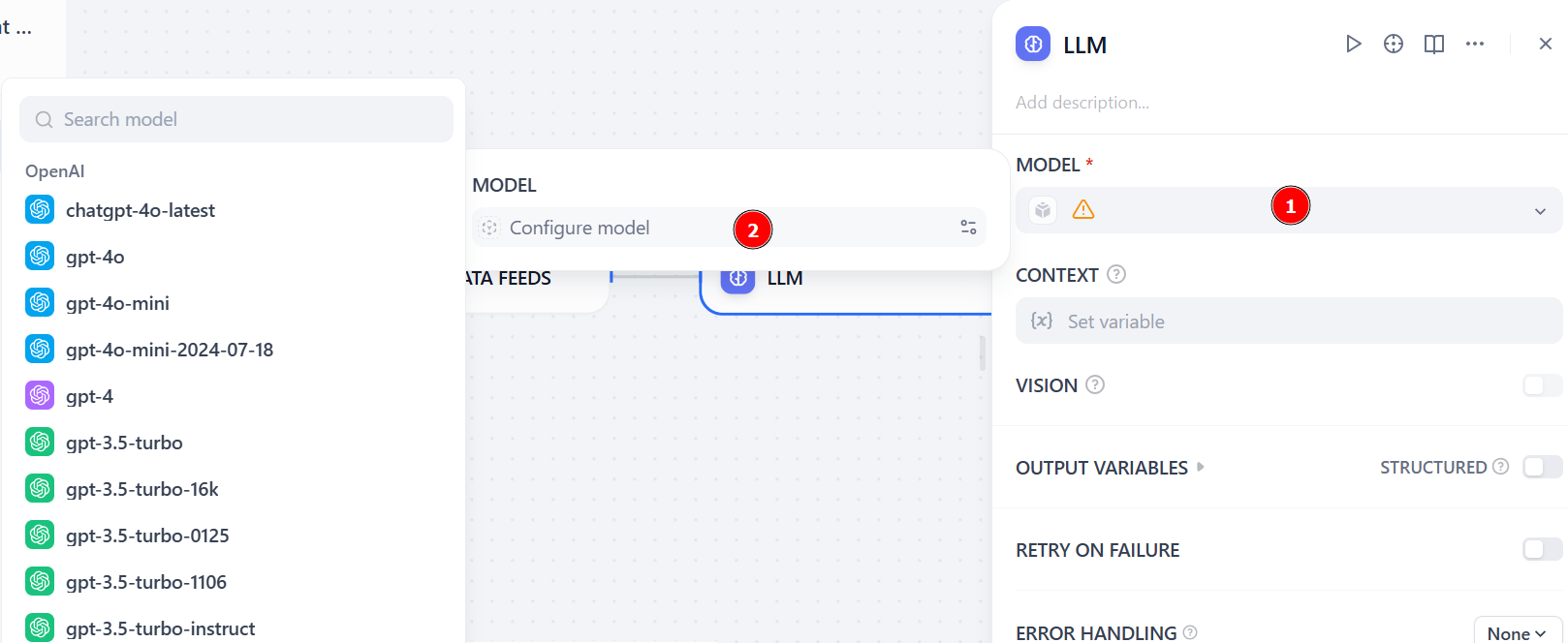
“시스템” 섹션에서 다음과 같은 프롬프트를 추가하세요:
당신은 전문 전자상거래 분석가입니다. 아마존 제품 페이지의 다음 구조화된 데이터를 바탕으로 잠재적 구매자를 위한 간결하고 유용한 요약문을 작성하세요.
다음 내용을 포함하세요:
- 제품명.
- 한 문장으로 요약.
- 글머리 기호 목록으로 정리된 3~5가지 주요 특징.
- 전체 별점 및 리뷰 수.
- 이 제품이 누구에게 적합한지에 대한 간단한 결론 문장.
데이터:
{{Structure_Data_Feeds.text}}이 프롬프트는 LLM이 전자상거래 분석가 역할을 수행하여 스크랩된 제품의 요약문을 작성하도록 지시합니다. 또한 제품명과 주요 기능 등 포함해야 할 구체적인 세부사항을 요청합니다. 마지막에 Bright Data 플러그인 노드의 텍스트 결과가 포함된다는 점에 유의하십시오.
작성된 섹션은 다음과 같습니다:
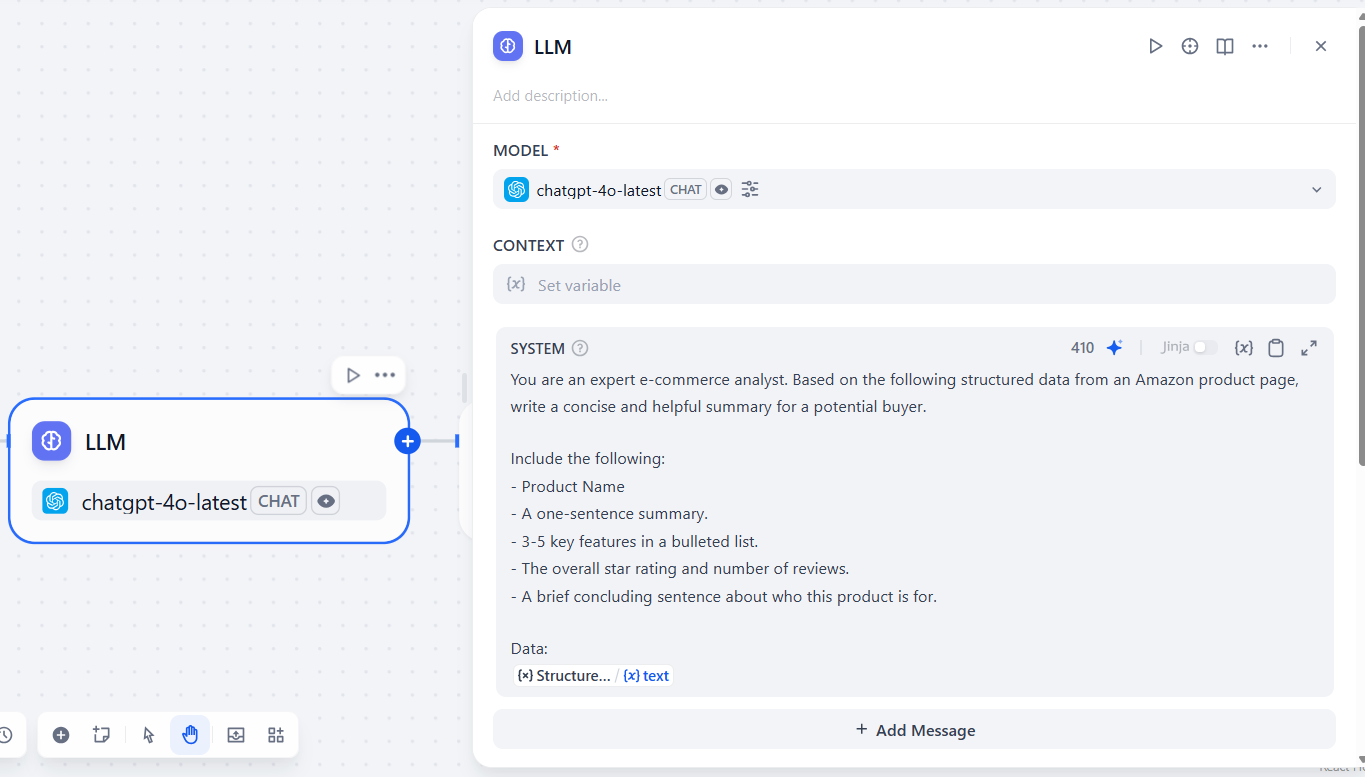
프롬프트의 “데이터” 섹션 아래에 텍스트를 입력 변수로 추가하세요. 이렇게 하면 LLM이 Bright Data 노드가 대상 URL에서 가져온 콘텐츠를 사용할 수 있습니다. “/”를 클릭하면 선택 가능한 변수 목록을 확인할 수 있습니다.
좋습니다! 이제 워크플로에 마지막 노드를 추가할 수 있습니다.
워크플로의 출력은 “End” 노드를 추가하여 얻을 수 있습니다:
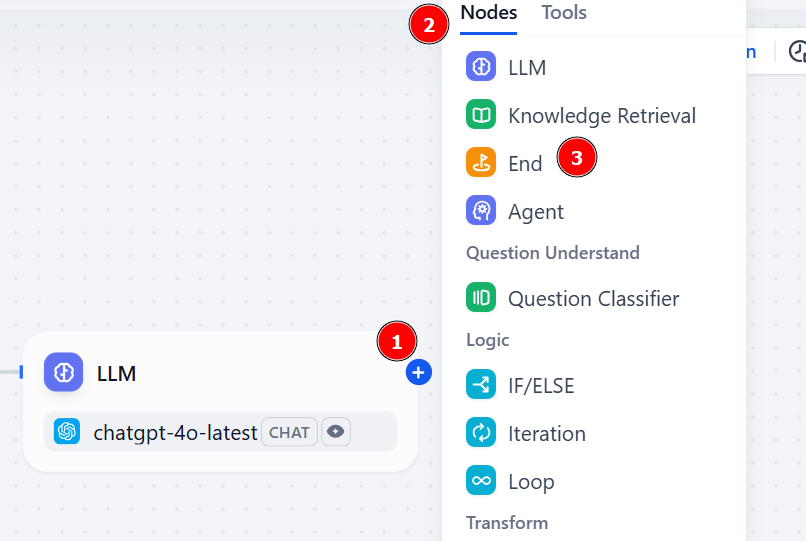
출력 변수는 LLM 노드에서 오는 문자열이어야 합니다. 이를 위해 “OUTPUT VARIABLE” 섹션을 클릭하고 “LLM” 아래에서 “text”를 선택하세요:
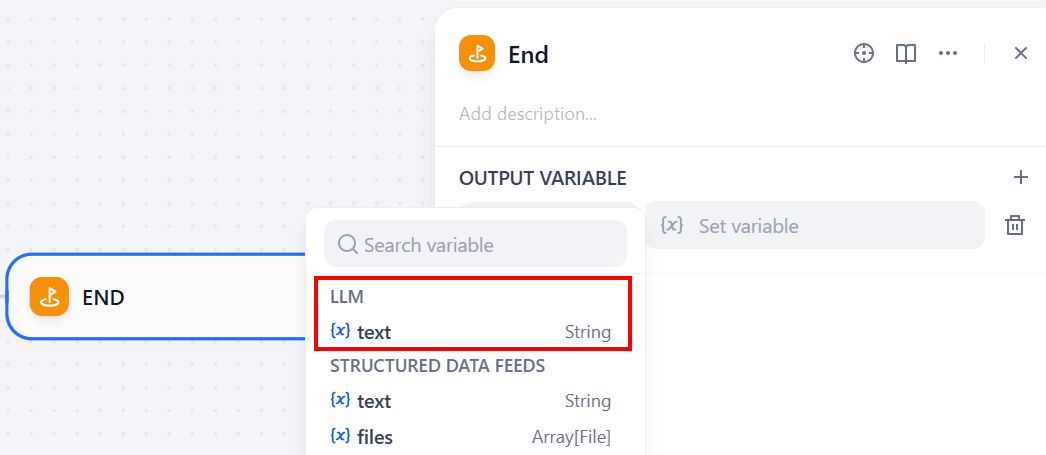
훌륭합니다! 워크플로가 올바르게 설정되었습니다. 이제 실행할 준비가 되었습니다.
4단계: 워크플로 실행
아래는 Bright Data 플러그인을 통한 Dify의 웹 스크래핑 워크플로우입니다:
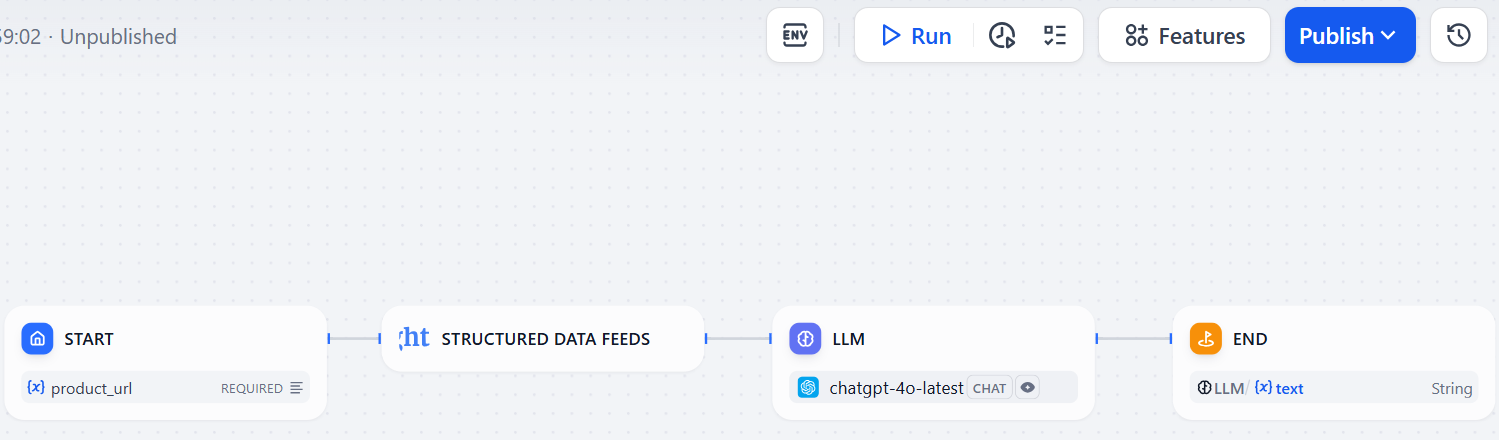
보시다시피, 본 장의 소개에서 예상했던 대로 단 4개의 노드로만 구성되어 있습니다. 또한 목표를 달성하기 위해 단 한 줄의 코드도 작성할 필요가 없었습니다!
워크플로우를 실행하려면 “Run”을 클릭하세요. 이때 “product_url” 필드에 아마존 제품의 URL을 추가해야 합니다. 그런 다음 “Start Run”을 클릭하여 Dify 웹 스크래핑 워크플로우를 시작하세요:
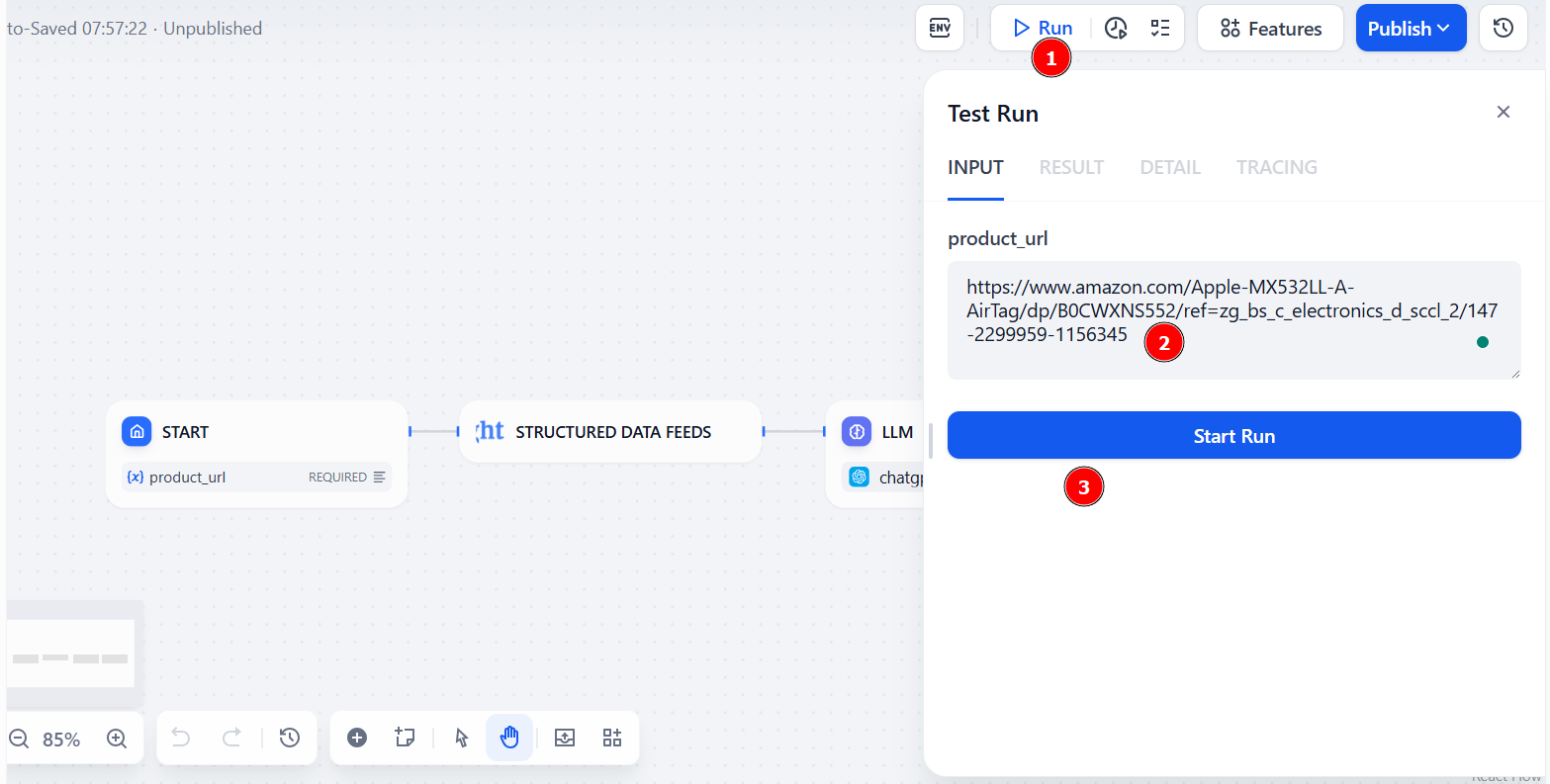
결과는 “Result” 탭에서 확인할 수 있습니다:
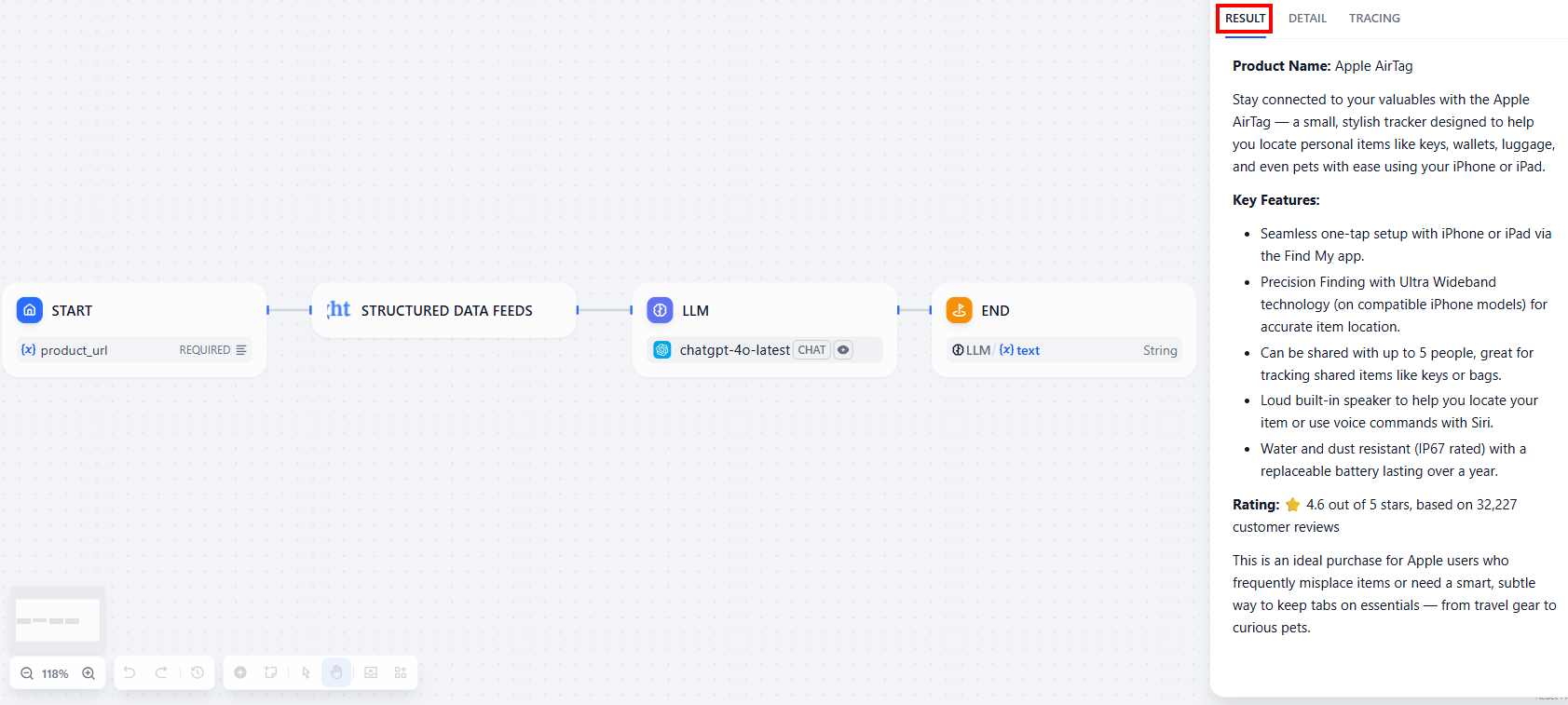
아래는 텍스트 형식의 결과입니다:
**제품명:** Apple AirTag
Apple AirTag로 소중한 물건과 연결을 유지하세요. 작고 세련된 이 추적기는 iPhone 또는 iPad를 사용하여 열쇠, 지갑, 수하물, 심지어 반려동물까지 손쉽게 찾을 수 있도록 설계되었습니다.
**주요 기능:**
- Find My 앱을 통해 iPhone 또는 iPad로 원터치 간편 설정.
- 초광대역 기술(호환 iPhone 모델에서 사용 가능)을 통한 정밀 위치 추적으로 정확한 물품 위치 파악.
- 최대 5명과 공유 가능하여 열쇠나 가방 같은 공유 물품 추적에 탁월.
- 물품 위치를 찾거나 Siri 음성 명령을 사용할 수 있도록 내장된 큰 소리 스피커.
- 교체 가능한 배터리로 1년 이상 사용 가능하며 방수 및 방진 기능(IP67 등급) 지원.
**평점:** ⭐ 5점 만점에 4.6점 (고객 리뷰 32,227건 기준)
자주 물건을 잃어버리거나 여행 용품부터 호기심 많은 반려동물까지 필수품을 스마트하고 은밀하게 관리할 방법이 필요한 Apple 사용자에게 이상적인 제품입니다.요청하신 대로, LLM은 프롬프트에 기재된 내용을 보고했습니다:
- 제품에 대한 한 문장 요약.
- 5가지 주요 기능.
- 평점.
- 이 제품이 누구를 위한 것인지 알려주는 결론 문장.
아마존 같은 주요 이커머스 사이트에서 스크래핑을 시도해 본 적이 있다면 그 어려움을 잘 알 것입니다:
바로 여기서 Bright Data 통합이 모든 차이를 만듭니다. 이 솔루션은 복잡한 스크래핑 방지 조치를 모두 처리하여 데이터 수집 과정이 예상대로 작동하도록 보장합니다.
자, 이제 Dify와 Bright Data를 통합한 첫 프로젝트를 성공적으로 완료했습니다.
결론
이 글에서는 Dify를 활용해 코딩 없이 AI 스크래핑 워크플로를 구축하는 방법을 알아보았습니다. Bright Data Dify 플러그인이 없었다면 불가능했을 것입니다. 여기서 보았듯이, 해당 플러그인은 AI 워크플로 내에서 웹 스크래핑을 위한 여러 고급 도구를 제공합니다.
이제 AI 에이전트를 위한 안정적인 스크래핑 워크플로우 구축의 주요 과제 중 하나는 고품질 웹 데이터에 접근하는 것입니다. 이를 위해서는 웹 콘텐츠를 검색, 검증, 변환하는 도구가 필요하며, 바로 이것이 Bright Data의 AI 인프라가 제공하는 핵심 기능입니다.
무료 Bright Data 계정을 생성하고 AI 활용이 가능한 데이터 도구로 지금 바로 실험을 시작해 보세요!





