파이썬은 현재 전 세계적으로 압도적으로 우세한 웹 스크래핑 언어입니다. 항상 그런 것은 아니었습니다. 1990년대 후반과 2000년대 초반에는 웹 스크래핑이 거의 전적으로 Perl과 PHP로 수행되었습니다.
오늘은 파이썬을 과거 웹 개발의 거물 중 하나인 PHP와 직접 비교해 보겠습니다. 각 언어의 차이점을 살펴보고 어느 쪽이 더 나은 스크래핑 경험을 제공하는지 알아보겠습니다.
필수 준비 사항
실습을 따라하려면 파이썬과 PHP가 설치되어 있어야 합니다. 각 언어의 다운로드 링크를 클릭하고 사용 중인 OS에 맞는 설치 안내를 따르세요.
- 파이썬
- PHP
다음 명령어로 각 언어의 설치 상태를 확인할 수 있습니다.
Python
python --version
다음과 같은 결과가 표시됩니다.
Python 3.10.12
PHP
php --version
출력 결과는 다음과 같습니다.
PHP 8.3.14 (cli) (빌드: 2024년 11월 25일 18:07:16) (NTS)
Copyright (c) The PHP Group
Zend Engine v4.3.14, Copyright (c) Zend Technologies
with Zend OPcache v8.3.14, Copyright (c), by Zend Technologies
두 언어에 대한 기본적인 이해가 도움이 되겠지만, 필수 조건은 아닙니다. 사실 저는 지금까지 PHP를 한 줄도 써본 적이 없었습니다!
웹 스크래핑을 위한 Python과 PHP 비교
프로젝트를 만들기 전에, 각 언어에 대해 좀 더 자세히 살펴볼 필요가 있습니다.
- 구문: Python은 특히 데이터 커뮤니티 전반에 걸쳐 널리 채택된 가독성 높은 구문을 가지고 있습니다.
- 표준 라이브러리: 두 언어 모두 풍부한 표준 라이브러리를 제공합니다.
- 스크래핑 프레임워크: Python은 훨씬 더 다양한 스크래핑 프레임워크를 선택할 수 있습니다.
- 성능: PHP는 웹 실행을 위해 설계되었기 때문에 일반적으로 더 빠른 속도를 제공합니다.
- 유지 관리: 파이썬은 명확한 구문과 강력한 커뮤니티 지원 덕분에 유지 관리가 더 쉬운 편입니다.
| 기능 | 파이썬 | PHP |
|---|---|---|
| 사용 편의성 | 초보자 친화적이고 배우기 쉬움 | 신규 개발자에게는 다소 어려움 |
| 표준 라이브러리 | 풍부하고 다양한 기능 | 풍부하고 기능이 가득 |
| 스크래핑 도구 | 다양한 제3자 스크래핑 도구 | 훨씬 작은 생태계 |
| 데이터 지원 | 데이터 처리를 염두에 두고 구축됨 | 기본 라이브러리 및 도구 제공 |
| 커뮤니티 | 대규모 커뮤니티 및 지원 | 지원이 제한된 소규모 커뮤니티 |
| 유지 관리 | 유지보수가 용이하고 널리 사용됨 | 어려움, 프로그래머 확보가 어려움 |
스크래핑 대상?
이것은 단지 데모용이며, 벤치마킹을 위해 일관성을 유지하는 사이트가 필요하므로 quotes.toscrape.com을 사용할 것입니다. 이 사이트는 일관된 콘텐츠를 제공하며 스크레이퍼를 차단하지 않습니다. 테스트 케이스에 완벽합니다.
아래 이미지에서 페이지의 인용문 항목 중 하나를 확인할 수 있습니다. 이는 'quote' 클래스를 가진 div입니다. 먼저 이러한 항목들을 모두 찾아야 합니다.
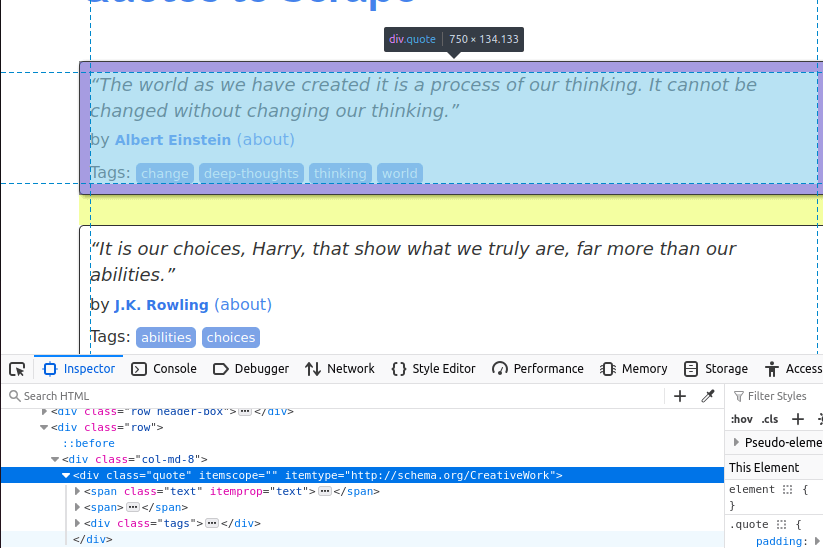
페이지의 모든 인용문 카드를 찾은 후에는 각 카드에서 개별 항목을 추출해야 합니다.
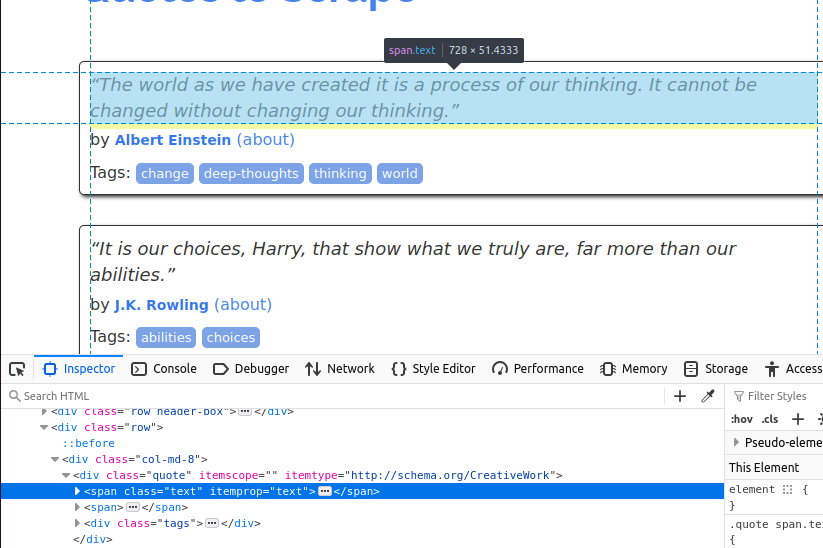
텍스트는 'text' 클래스를 가진 span 요소에 포함되어 있습니다.
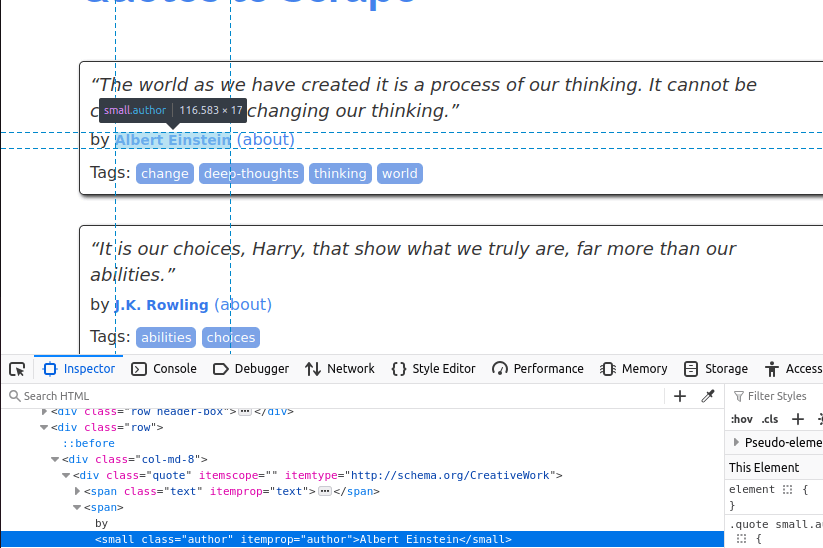
이제 저자를 가져와야 합니다. 저자는 'author' 클래스를 가진 작은 항목 안에 있습니다.
마지막으로 태그를 추출합니다. 이 태그들은 'tag' 클래스를 가진 element 안에 있습니다.

추출할 데이터가 명확해졌으니 본격적으로 시작해 보겠습니다.
시작하기
이제 모든 것을 설정할 시간입니다. Python과 PHP 모두에 몇 가지 종속성이 필요합니다.
Python
Python의 경우 Requests와 BeautifulSoup을 설치해야 합니다.
두 라이브러리 모두 pip로 설치할 수 있습니다.
pip install requests
pip install beautifulsoup4
PHP
분명히, 이 모든 종속성들은 PHP와 함께 미리 설치되어 있어야 합니다. 그러나, 제가 사용하려고 했을 때, 그들은 없었습니다.
sudo apt install php-curl
sudo apt install php-xml
의존성 설치가 완료되었으니 이제 코딩을 시작할 준비가 되었습니다.
데이터 스크래핑
저는 먼저 Python으로 다음과 같은 스크래퍼를 작성했습니다. 아래 코드는 quotes.toscrape.com에 일련의 요청을 보내 각 명언에서 텍스트, 이름, 저자를 추출합니다. 모든 명언을 수집한 후에는 이를 JSON 파일에 기록합니다. 자유롭게 복사하여 여러분의 Python 파일에 붙여넣으세요.
Python
import requests
from bs4 import BeautifulSoup
import json
page_number = 1
output_json = []
while page_number <= 5:
response = requests.get(f"https://quotes.toscrape.com/page/{page_number}")
soup = BeautifulSoup(response.text, "html.parser")
divs = soup.select("div[class='quote']")
for div in divs:
tags = []
quote_text = div.select_one("span[class='text']").text
author = div.select_one("small[class='author']").text
tag_holders = div.select("a[class='tag']")
for tag_holder in tag_holders:
tags.append(tag_holder.text)
quote_dict = {
"author": author,
"quote": quote_text.strip(),
"tags": tags
}
output_json.append(quote_dict)
page_number+=1
with open("quotes.json", "w") as file:
json.dump(output_json, file, indent=4)
print("스크래핑 완료. 인용문이 quotes.json에 저장되었습니다.")
- 먼저
page_number와output_json변수를 설정합니다. while page_number <= 5는스크레이퍼가 5페이지를 모두 스크레이핑할 때까지 작업을 계속하도록 지시합니다.response = requests.get(f"https://quotes.toscrape.com/page/{page_number}")는현재 페이지로 요청을 보냅니다.divs = soup.select("div[class='quote']")로 모든 대상div요소를 찾습니다.div를반복하여 데이터를 추출합니다:quote_text:div.select_one("span[class='text']").textauthor:div.select_one("small[class='author']").texttags: 모든tag_holder요소를 찾아 각각의 텍스트를 추출합니다.
- 이 모든 작업이 완료되면
output_json배열을 파일에 저장하고 터미널에 메시지를출력합니다.
다음은 실행 결과의 스크린샷입니다. 더 많은 실행을 수행했지만 간결함을 위해 여기서는 3회 실행 샘플을 사용합니다.
실행 1은 11.642초가 소요되었습니다.

실행 2는 11.413초가 소요되었습니다.

실행 3은 10.258초가 소요되었습니다.

Python의 평균 실행 시간은 11.104초입니다.
PHP
파이썬 코드를 작성한 후, ChatGPT에게 PHP로 다시 작성해 달라고 요청했습니다. 처음에는 코드가 작동하지 않았지만, 약간의 수정을 거친 후 사용 가능해졌습니다.
<?php
$pageNumber = 1;
$outputJson = [];
while ($pageNumber <= 5) {
$url = "https://quotes.toscrape.com/page/$pageNumber";
$ch = curl_init($url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
$response = curl_exec($ch);
curl_close($ch);
if ($response === false) {
echo "$pageNumber 페이지 불러오는 중 오류 발생n";
break;
}
$dom = new DOMDocument();
@$dom->loadHTML($response);
$xpath = new DOMXPath($dom);
$quoteDivs = $xpath->query("//div[@class='quote']");
foreach ($quoteDivs as $div) {
$quoteText = $xpath->query(".//span[@class='text']", $div)->item(0)->textContent ?? "";
$author = $xpath->query(".//small[@class='author']", $div)->item(0)->textContent ?? "";
$tagElements = $xpath->query(".//a[@class='tag']", $div);
$tags = [];
foreach ($tagElements as $tagElement) {
$tags[] = $tagElement->textContent;
}
$outputJson[] = [
"author" => trim($author),
"quote" => trim($quoteText),
"tags" => $tags
];
}
$pageNumber++;
}
$jsonData = json_encode($outputJson, JSON_PRETTY_PRINT | JSON_UNESCAPED_UNICODE);
file_put_contents("quotes.json", $jsonData);
echo "스크래핑 완료. 인용문이 quotes.json에 저장되었습니다.";
- 파이썬 코드와 유사하게,
pageNumber와outputJson변수로 시작합니다. - 실제 스크래핑 실행 시간을 제어하기 위해
while ($pageNumber <= 5)루프를 사용합니다. $ch = curl_init($url);로 HTTP 요청을 설정합니다. 리다이렉션을 따르기 위해curl_setopt()를사용합니다.$response = curl_exec($ch);HTTP 요청을 실행합니다.$dom = new DOMDocument();는 사용할 새DOM객체를 설정합니다. 이는 이전에BeautifulSoup()을 사용했던 것과 유사합니다.- CSS 선택자 대신 Xpath를 사용하여
div를가져옵니다:$quoteDivs = $xpath->query("//div[@class='quote']"); $quoteText = $xpath->query(".//span[@class='text']", $div)->item(0)->textContent ?? "";각 인용문의 텍스트를 반환합니다.$author = $xpath->query(".//small[@class='author']", $div)->item(0)->textContent ?? "";를 통해 저자를 얻습니다.태그요소를 모두 찾아 반복문을 통해 텍스트를 추출합니다.- 마지막으로 모든 작업이 완료되면 출력 결과를 json 파일에 저장하고 화면에 메시지를 출력합니다.
PHP를 사용한 실행 결과는 다음과 같습니다.
실행 1은 11.351초가 소요되었습니다.

실행 2는 9.846초가 걸렸습니다.

실행 3은 9.795초가 소요되었습니다.

PHP의 평균 실행 시간은 10.33초였습니다.
추가 테스트를 진행한 결과, PHP는 계속해서 더 빠른 결과를 보여주었습니다… 때로는 7초까지도 가능했습니다!
Bright Data 사용을 고려해 보세요
위 내용이 공감이 가셨다면, 웹 스크레이퍼를 작성해 보세요! 데이터를 추출하는 일을 직업으로 삼는다면, 위와 같은 코드를 항상 작성하게 될 것입니다!
당사는 스크레이퍼를 더욱 강력하게 만들어 줄 다양한 제품을 제공합니다.Scraping Browser는내장된 프록시 통합 및 JavaScript 렌더링 기능을 갖춘 원격 브라우저를 제공합니다. 브라우저 없이 프록시와 CAPTCHA 해결 기능만 원한다면Web Unlocker를 사용하세요.
스크레이퍼는 모든 사람에게 적합하지 않습니다.
데이터만 확보하고 업무를 진행하고 싶다면 저희 데이터셋을 살펴보세요.스크래핑은 저희가 대신해 드립니다.바로 사용 가능한 데이터셋을 확인해 보세요.가장 인기 있는 데이터셋은 LinkedIn, Amazon, Crunchbase, Zillow, Glassdoor입니다. 무료 샘플 데이터를 확인하고 CSV 또는 JSON 형식의 보고서를 다운로드할 수 있습니다.
결론
평균 속도 측정 결과, Python 스크레이퍼는 11.104초, PHP 스크레이퍼는 10.33초로 PHP 스크레이퍼가 Python 스크레이퍼보다 지속적으로 더 빠른 성능을 보였습니다. 일부는 서버 지연과 관련될 수 있으나, 추가 테스트에서도 PHP는 거의 모든 실행에서 Python을 앞섰습니다.
속도 부문에서는 확실히 파이썬을 앞섰지만, 구문 측면에서는 그렇지 않습니다. 오늘날 개발자 중 PHP나 Perl 같은 언어의 구문에 익숙한 사람은 많지 않습니다. 이들은 과거의 스크립팅 언어입니다. 게다가 팀이 PHP에 익숙하지 않을 수도 있습니다. 이런 종류의 코드를 지속적으로 작성하고 레거시 애플리케이션을 유지하는 데는 특별한 유형의 개발자가 필요합니다.
Bright Data로 스크래핑 작업을 한 단계 업그레이드하세요. 지금 가입하고 무료 체험을 시작하세요!