

Perl은가장 인기 있는 언어 중 하나이며, 방대한 모듈 컬렉션 덕분에 웹 스크레이퍼 작성에 탁월한 선택입니다.
본 문서에서는 다음을 다룹니다:
- 다음 방법을 사용하여 Perl로 웹 스크래핑하는 방법:
LWP::UserAgent및HTML::TreeBuilderWeb::ScraperMojo::UserAgent및Mojo::DOMXML::LibXML
- Perl을 사용한 웹 스크래핑의 과제
- 결론
Perl을 이용한 웹 스크래핑
본문 내용을 따라가려면 최신 버전의 Perl이 설치되어 있는지 확인하세요. 본문의 코드는 Perl 5.38.2로 테스트되었습니다. 또한cpanm을 사용한 Perl 모듈 설치 방법을 알고 있다고 가정합니다.
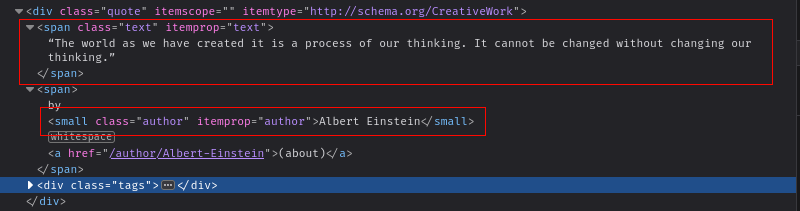
이 글에서는Quotes to Scrape 웹사이트에서명언을 추출하는 스크래핑 작업을 수행합니다. 웹사이트에서 데이터를 스크래핑하기 전에 HTML 구조를 이해해야 합니다. 브라우저에서 웹사이트를 열고CTRL + Shift + I(Windows) 또는Command + Shift + C(Mac)를 눌러요소 검사대화 상자를 엽니다.
요소를 검사하면 각 명언이'quote' 클래스의div에저장되어 있음을 확인할 수 있습니다. 각 명언은'text'클래스의span과텍스트 및 저자 이름을 각각 저장하는작은요소를 포함합니다:
LWP::UserAgent 및 HTML::TreeBuilder 사용
LWP::UserAgent는웹과 상호작용하는 모듈 그룹인LWP의 일부입니다.LWP::UserAgent모듈을 사용하면 웹 페이지에 HTTP 요청을 보내 HTML 콘텐츠를 반환할 수 있습니다. 그런 다음HTML::TreeBuilder모듈을 사용하여 HTML을 파싱하고 정보를 추출할 수 있습니다.
LWP::UserAgent 와 HTML::TreeBuilder를 사용하려면 다음 명령어로 모듈을 설치하세요:
cpanm Bundle::LWP
cpanm HTML::Tree
lwp-and-tree-builder.pl이라는 파일을 생성하세요. 여기에 코드를 작성할 것입니다. 그런 다음 해당 파일에 다음 두 줄을 붙여넣으세요:
use LWP::UserAgent;
use HTML::TreeBuilder;
이 코드는 Perl 인터프리터에 LWP::UserAgent 및 HTML::TreeBuilder 모듈을 포함하도록 지시합니다.
LWP::UserAgent 인스턴스를 정의하고 User-Agent 헤더를 Quotes Scraper로 설정합니다:
my $ua = LWP::UserAgent->new;
$ua->agent("Quotes Scraper");
대상 웹사이트의 URL을 정의하고 HTML::TreeBuilder의 인스턴스를 생성합니다:
my $url = "https://quotes.toscrape.com/";
my $root = HTML::TreeBuilder->new();
이제 HTTP 요청을 수행할 수 있습니다:
my $request = $ua->get($url) or die "오류 발생 $!n";
요청 성공 여부를 확인하는 다음 if-else 문을 붙여넣으세요:
if ($request->is_success) {
} else {
print "결과를 파싱할 수 없습니다. " . $request->status_line . "n";
}
요청이 성공하면 스크래핑을 시작할 수 있습니다.
HTML 응답을 파싱하려면 HTML::TreeBuilder의 parse 메서드를 사용하세요. 다음 코드를 if 블록 안에 붙여넣으세요:
$root->parse($request->content);
이제 look_down 메서드를 사용하여 class가 quote인 div 요소를 찾습니다:
my @quotes = $root->look_down(
_tag => 'div',
class => 'quote'
);
인용문 배열을 반복하며 look_down을 사용해 텍스트와 저자를 찾아 출력합니다:
foreach my $quote (@quotes) {
my $text = $quote->look_down(
_tag => 'span',
class => 'text'
)->as_text;
my $author = $quote->look_down(
_tag => 'small',
class => 'author'
)->as_text;
print "$text: $authorn";
}
전체 코드는 다음과 같습니다:
use LWP::UserAgent;
use HTML::TreeBuilder;
my $ua = LWP::UserAgent->new;
$ua->agent("Quotes Scraper");
my $url = "https://quotes.toscrape.com/";
my $root = HTML::TreeBuilder->new();
my $request = $ua->get($url) or die "오류 발생 $!n";
if ($request->is_success) {
$root->parse($request->content);
my @quotes = $root->look_down(
_tag => 'div',
class => 'quote'
);
foreach my $quote (@quotes) {
my $text = $quote->look_down(
_tag => 'span',
class => 'text'
)->as_text;
my $author = $quote->look_down(
_tag => 'small',
class => 'author'
)->as_text;
print "$text: $authorn";
}
} else {
print "결과를 파싱할 수 없습니다. " . $request->status_line . "n";
}
이 코드를 perl lwp-and-tree-builder.pl로 실행하면 다음과 같은 출력이 표시됩니다:
"우리가 창조한 세상은 우리의 사고 과정이다. 사고를 바꾸지 않고서는 세상을 바꿀 수 없다.": 알버트 아인슈타인
"해리, 우리의 능력보다 훨씬 더 우리 본질을 드러내는 것은 바로 우리의 선택이다.": J.K. 롤링
"인생을 사는 방법은 단 두 가지뿐이다. 하나는 아무것도 기적처럼 여기지 않는 삶이고, 다른 하나는 모든 것을 기적처럼 여기는 삶이다.": 알버트 아인슈타인
"좋은 소설에서 즐거움을 느끼지 못하는 사람은, 신사든 숙녀든, 참을 수 없을 만큼 어리석은 사람이다.": 제인 오스틴
"불완전함은 아름다움이고, 광기는 천재성이다. 그리고 완전히 지루한 것보다 완전히 우스꽝스러운 편이 낫다.": 마릴린 먼로
"성공한 사람이 되려 하지 마라. 차라리 가치 있는 사람이 되라.": 알버트 아인슈타인
"있는 그대로의 모습으로 미움받는 것이, 없는 모습으로 사랑받는 것보다 낫다.": 앙드레 지드
"나는 실패한 것이 아니다. 단지 1만 가지 안 되는 방법을 발견했을 뿐이다.": 토머스 에디슨
"여자는 티백과 같다. 뜨거운 물에 담기기 전까지는 그 강도를 알 수 없다.": 엘리너 루즈벨트
"햇빛 없는 하루는, 알다시피, 밤과 같다.": 스티브 마틴
Web::Scraper 사용하기
Web::Scraper는Ruby의 ScrAPI에서 영감을 받은 웹 스크래핑 라이브러리입니다. HTML 및 XML 문서 스크래핑을 위한 도메인 특정 언어(DSL)를 제공합니다. Ruby를 사용한 웹 스크래핑에 대해 자세히 알아보려면 이 글을 확인하세요.
Web::Scraper를 사용하려면 cpanm Web::Scraper 명령어로 모듈을 설치하세요.
web-scraper. pl이라는 새 파일을 생성하고 다음 필수 모듈을 포함하세요:
use URI;
use Web::Scraper;
use Encode;
다음으로 모듈의 DSL을 사용하여 스크레이퍼 블록을 정의해야 합니다. DSL을 사용하면 몇 줄의 코드로 스크레이퍼를 쉽게 정의할 수 있습니다. $quotes라는 스크레이퍼 블록을 정의하는 것으로 시작합니다:
my $quotes = scraper {
};
스크레이퍼 메서드는 스크레이퍼의 로직을 정의하며, 이는 나중에 scrape 메서드가 호출될 때 실행됩니다. 스크레이퍼 블록 내부에서는 process 메서드를 사용하여 CSS 선택자로 요소를 찾고 함수를 실행합니다.
quote 클래스를 가진 모든 div 요소를 찾는 것으로 시작합니다:
# `quote` 클래스를 가진 모든 `div` 파싱
process 'div.quote', "quotes[]" => scraper {
};
이 코드는 quote 클래스를 가진 모든 div 요소를 찾아 quotes 배열에 저장합니다. 각 요소에 대해 스크레이퍼 메서드를 실행하는데, 이는 다음과 같이 정의합니다:
# 각 div에서 `text` 클래스의 `span` 찾기
process_first "span.text", text => 'TEXT';
# `author` 클래스의 `small` 찾기
process_first "small", author => 'TEXT';
process_first 메서드는 CSS 선택자에 맞는 첫 번째 요소를 찾습니다. 여기서 text 클래스를 가진 첫 번째 span 요소를 찾은 후 그 텍스트를 추출하여 text 키에 저장합니다. 저자 이름의 경우, 첫 번째 small 요소를 찾고 텍스트를 추출하여 author 키에 저장합니다.
전체 스크레이퍼 블록은 다음과 같습니다:
my $quotes = scraper {
# 클래스 `quote`를 가진 모든 `div` 파싱
process 'div.quote', "quotes[]" => scraper {
# 그리고 각 div 내에서 클래스 `text`를 가진 `span` 찾기
process_first "span.text", text => 'TEXT';
# `author` 클래스를 가진 `small` 요소 획득
process_first "small", author => 'TEXT';
};
};
이제 scrape 메서드를 호출하고 스크래핑을 시작할 URL을 전달하세요:
my $res = $quotes->scrape( URI->new("https://quotes.toscrape.com/") );
마지막으로, 인용문 배열을 반복하며 결과를 출력합니다:
# 배열 반복
for my $quote (@{$res->{quotes}}) {
print Encode::encode("utf8", "$quote->{text}: $quote->{author}n");
}
전체 코드는 다음과 같습니다:
use URI;
use Web::Scraper;
use Encode;
my $quotes = scraper {
# 클래스 `quote`를 가진 모든 `div` 파싱
process 'div.quote', "quotes[]" => scraper {
# 그리고 각 div 내에서 클래스 `text`를 가진 `span` 찾기
process_first "span.text", text => 'TEXT';
# 클래스 `author`를 가진 `small` 요소 가져오기
process_first "small", author => 'TEXT';
};
};
my $res = $quotes->scrape( URI->new("https://quotes.toscrape.com/") );
# 배열을 반복 처리
for my $quote (@{$res->{quotes}}) {
print Encode::encode("utf8", "$quote->{text}: $quote->{author}n");
}
perl web-scraper.pl로 이전 코드를 실행하면 다음과 같은 출력이 나옵니다:
"우리가 창조한 세상은 우리의 사고 과정이다. 우리의 사고를 바꾸지 않고서는 세상을 바꿀 수 없다.": 알버트 아인슈타인
"해리, 우리의 진정한 모습을 드러내는 것은 능력보다 선택이다.": J.K. 롤링
"삶을 사는 방법은 두 가지뿐이다. 하나는 아무것도 기적이 아닌 것처럼 사는 것이고, 다른 하나는 모든 것이 기적인 것처럼 사는 것이다.": 알버트 아인슈타인
"좋은 소설에서 즐거움을 느끼지 못하는 사람은, 신사든 숙녀든, 참을 수 없을 만큼 어리석은 사람일 것이다.": 제인 오스틴
"불완전함은 아름다움이고, 광기는 천재성이다. 그리고 완전히 우스꽝스러운 것이 완전히 지루한 것보다 낫다.": 마릴린 먼로
"성공한 사람이 되려 하지 마라. 차라리 가치 있는 사람이 되라.": 알버트 아인슈타인
"있는 그대로의 모습으로 미움받는 것이, 없는 모습으로 사랑받는 것보다 낫다.": 앙드레 지드
"나는 실패한 것이 아니다. 단지 1만 가지 안 되는 방법을 발견했을 뿐이다.": 토머스 에디슨
"여자는 티백과 같다. 뜨거운 물에 담그기 전까지는 그 강함을 알 수 없다.": 엘리너 루스벨트
"햇빛 없는 하루는, 알다시피, 밤과 같다.": 스티브 마틴
Mojo::UserAgent 및 Mojo::DOM 사용
Mojo::UserAgent와Mojo::DOM은Perl용 실시간 웹 프레임워크인Mojolicious프레임워크의 일부입니다. 기능 면에서LWP::UserAgent및HTML::TreeBuilder와 유사합니다.
Mojo::UserAgent와 Mojo::DOM을 사용하려면 다음 명령어로 모듈을 설치하세요:
cpanm Mojo::UserAgent
cpanm Mojo::DOM
mojo.pl 이라는 새 파일을 생성하고 Mojo::UserAgent 및 Mojo::DOM 모듈을 포함시킵니다:
use Mojo::UserAgent;
use Mojo::DOM;
Mojo::UserAgent 인스턴스를 정의하고 HTTP 요청을 수행합니다:
my $ua = Mojo::UserAgent->new;
my $res = $ua->get('https://quotes.toscrape.com/')->result;
LWP::UserAgent와 유사하게, 요청이 성공했는지 확인하려면 다음 if-else 블록을 사용하세요:
if ($res->is_success) {
} else {
print "결과를 파싱할 수 없습니다. " . $res->message . "n";
}
if 블록 내에서 Mojo::DOM 인스턴스를 초기화합니다:
my $dom = Mojo::DOM->new($res->body);
find 메서드를 사용하여 quote 클래스를 가진 모든 div 요소를 찾습니다:
my @quotes = $dom->find('div.quote')->each;
quotes 배열을 반복하며 텍스트와 저자 이름을 추출합니다:
foreach my $quote (@quotes) {
my $text = $quote->find('span.text')->map('text')->join;
my $author = $quote->find('small.author')->map('text')->join;
print "$text: $authorn";
}
다음은 전체 코드입니다:
use Mojo::UserAgent;
use Mojo::DOM;
my $ua = Mojo::UserAgent->new;
my $res = $ua->get('https://quotes.toscrape.com/')->result;
if ($res->is_success) {
my $dom = Mojo::DOM->new($res->body);
my @quotes = $dom->find('div.quote')->each;
foreach my $quote (@quotes) {
my $text = $quote->find('span.text')->map('text')->join;
my $author = $quote->find('small.author')->map('text')->join;
print "$text: $authorn";
}
} else {
print "결과를 파싱할 수 없습니다. " . $res->message . "n";
}
이 코드를 perl mojo.pl로 실행하면 다음과 같은 출력이 나옵니다:
"우리가 창조한 세상은 우리의 사고 과정이다. 사고를 바꾸지 않고서는 세상을 바꿀 수 없다.": 알버트 아인슈타인
"해리, 우리의 진정한 모습을 드러내는 것은 능력보다 선택이다.": J.K. 롤링
"삶을 사는 방법은 두 가지뿐이다. 하나는 아무것도 기적처럼 여기지 않는 방식이고, 다른 하나는 모든 것을 기적처럼 여기는 방식이다.": 알버트 아인슈타인
"좋은 소설에서 즐거움을 느끼지 못하는 사람은, 신사든 숙녀든, 참을 수 없을 만큼 어리석은 사람일 것이다.": 제인 오스틴
"불완전은 아름다움이고, 광기는 천재이며, 완전히 우스꽝스러운 것이 완전히 지루한 것보다 낫다.": 마릴린 먼로
"성공한 사람이 되려 하지 마라. 차라리 가치 있는 사람이 되라.": 알버트 아인슈타인
"있는 그대로의 모습으로 미움받는 것이, 없는 모습으로 사랑받는 것보다 낫다.": 앙드레 지드
"나는 실패한 것이 아니다. 단지 1만 가지 안 되는 방법을 발견했을 뿐이다.": 토머스 에디슨
"여자는 티백과 같다. 뜨거운 물에 담그기 전까지는 그 강도를 알 수 없다.": 엘리너 루스벨트
"햇빛 없는 하루는, 알다시피, 밤과 같다.": 스티브 마틴
XML::LibXML 사용하기
Perl 모듈XML::LibXML은libxml2라이브러리를 감싼 래퍼입니다.XML::LibXML모듈은XPath기능을 갖춘 강력한 XHTML 파서를 제공합니다.
cpanm을 사용하여 모듈을 설치하세요:
cpanm XML::LibXML
그런 다음 xml-libxml.pl이라는 새 파일을 생성하세요. HTML::TreeBuilder의 경우와 마찬가지로, 웹사이트에 HTTP 요청을 보내 HTML 콘텐츠를 가져오려면 LWP::UserAgent와 같은 라이브러리를 사용해야 하며, 이 콘텐츠를 XML::LibXML에 전달합니다.
다음 코드를 붙여넣어 LWP::UserAgent 모듈을 설정하고 웹 페이지의 HTML 콘텐츠를 가져옵니다:
use LWP::UserAgent;
use XML::LibXML;
use open qw( :std :encoding(UTF-8) );
my $ua = LWP::UserAgent->new;
$ua->agent("Quotes Scraper");
my $url = "https://quotes.toscrape.com/";
my $request = $ua->get($url) or die "오류 발생 $!n";
if ($request->is_success) {
} else {
print "결과를 파싱할 수 없습니다. " . $request->status_line . "n";
}
if 블록 내부에서 load_html 메서드를 사용하여 HTML 문서를 파싱하기 시작합니다:
$dom = XML::LibXML->load_html(string => $request->content, recover => 1, suppress_errors => 1);
recover 옵션은 오류 발생 시에도 HTML 구문 분석을 계속하도록 지시하며, suppress_errors 옵션은 HTML 구문 분석 오류를 콘솔에 출력하지 않도록 합니다. HTML 문서는 XHTML 문서만큼 엄격하게 검증되지 않으므로 치명적이지 않은 구문 분석 오류를 자주 접하게 됩니다. 이러한 옵션들은 오류 발생 시에도 코드가 계속 작동하도록 합니다.
HTML이 파싱되면 indnodes 메서드를 사용하여 XPath 표현식을 기반으로 요소를 찾을 수 있습니다:
my $xpath = '//div[@class="quote"]';
foreach my $quote ($dom->findnodes($xpath)) {
my ($text) = $quote->findnodes('.//span[@class="text"]')->to_literal_list;
my ($author) = $quote->findnodes('.//small[@class="author"]')->to_literal_list;
print "$text: $authorn";
}
전체 코드는 다음과 같습니다:
use LWP::UserAgent;
use XML::LibXML;
use open qw( :std :encoding(UTF-8) );
my $ua = LWP::UserAgent->new;
$ua->agent("Quotes Scraper");
my $url = "https://quotes.toscrape.com/";
my $request = $ua->get($url) or die "오류 발생 $!n";
if ($request->is_success) {
$dom = XML::LibXML->load_html(string => $request->content, recover => 1, suppress_errors => 1);
my $xpath = '//div[@class="quote"]';
foreach my $quote ($dom->findnodes($xpath)) {
my ($text) = $quote->findnodes('.//span[@class="text"]')->to_literal_list;
my ($author) = $quote->findnodes('.//small[@class="author"]')->to_literal_list;
print "$text: $authorn";
}
} else {
print "결과를 파싱할 수 없습니다. " . $request->status_line . "n";
}
perl xml-libxml.pl로 코드를 실행하면 다음과 같은 출력이 표시됩니다:
"우리가 창조한 세상은 우리의 사고 과정이다. 사고를 바꾸지 않고서는 세상을 바꿀 수 없다.": 알버트 아인슈타인
"해리, 우리의 능력보다 우리의 선택이 진정한 모습을 보여준다.": J.K. 롤링
"삶을 사는 방법은 두 가지뿐이다. 하나는 아무것도 기적이 아닌 것처럼 사는 것이고, 다른 하나는 모든 것이 기적인 것처럼 사는 것이다.": 알버트 아인슈타인
"좋은 소설에서 즐거움을 느끼지 못하는 사람은, 신사든 숙녀든, 참을 수 없을 만큼 어리석은 사람일 것이다.": 제인 오스틴
"불완전은 아름다움이고, 광기는 천재다. 완전히 우스꽝스러운 편이 완전히 지루한 편보다 낫다.": 마릴린 먼로
"성공한 사람이 되려 하지 마라. 차라리 가치 있는 사람이 되라.": 알버트 아인슈타인
"있는 그대로 미움받는 것이 없는 척 사랑받는 것보다 낫다.": 앙드레 지드
"나는 실패한 것이 아니다. 단지 1만 가지 안 되는 방법을 발견했을 뿐이다.": 토머스 에디슨
"여자는 티백과 같다. 뜨거운 물에 담기기 전까지는 그 강도를 알 수 없다.": 엘리너 루즈벨트
"햇빛 없는 하루는, 알다시피, 밤과 같다.": 스티브 마틴
이 튜토리얼의 모든 코드는 이GitHub 저장소에서 확인할 수 있습니다.
Perl을 이용한 웹 스크래핑의 어려움
Perl은 강력한 모듈을 통해 웹 페이지 스크래핑을 쉽게 만들지만, 개발자들은 종종 웹 스크래핑을 느리게 하거나 완전히 방해하는 몇 가지 일반적인 문제에 직면합니다. 다음은 여러분이 마주칠 가능성이 높은 몇 가지 도전 과제입니다.
페이지네이션 처리
대량의 데이터를 다루는 웹사이트는 모든 데이터를 한 번에 전송하지 않는 경우가 많습니다. 일반적으로 데이터는 여러 페이지에 걸쳐 전송되며, 모든 데이터를 추출하려면 페이지 분할을 처리해야 합니다. 페이지 분할을 처리하는 데는 두 단계가 있습니다:
- 다른 페이지가 존재하는지 확인합니다. 일반적으로 페이지 내‘다음 페이지’버튼을 찾거나, 다음 페이지를 로드하여 오류 발생 여부를 확인할 수 있습니다.
- 다른 페이지가 존재하면 다음 페이지를 로드하여 스크래핑합니다.
각 페이지마다 고유 URL을 가진 정적 웹사이트의 경우, URL의 페이지 번호 매개변수를 증가시키며 새 페이지를 순차적으로 불러오는 루프를 실행할 수 있습니다. 또는WWW::Mechanize 같은 모듈을 사용한다면 단순히‘다음 페이지’URL을 따라가면 됩니다.
WWW::Mechanize를 사용해 페이지 분할을 처리하도록 수정된 인용문 스크래퍼 예시입니다. follow_link 사용법에 유의하세요:
use WWW::Mechanize ();
use HTML::TreeBuilder;
use open qw( :std :encoding(UTF-8) );
my $mech = WWW::Mechanize->new();
my $url = "https://quotes.toscrape.com/";
my $root = HTML::TreeBuilder->new();
my $request = $mech->get($url);
my $next_page = $mech->find_link(text_regex => qr/Next/);
while ($next_page) {
$root->parse($mech->content);
my @quotes = $root->look_down(
_tag => 'div',
class => 'quote'
);
foreach my $quote (@quotes) {
my $text = $quote->look_down(
_tag => 'span',
class => 'text'
)->as_text;
my $author = $quote->look_down(
_tag => 'small',
class => 'author'
)->as_text;
print "$text: $authorn";
}
$mech->follow_link(url => $next_page->url);
$next_page = $mech->find_link(text_regex => qr/Next/);
}
자바스크립트를 사용해 다음 페이지를 로드하는 동적 웹사이트를 처리하려면,파이썬으로 동적 웹사이트 스크래핑 가이드를 확인하거나 계속 읽어보세요.
회전 프록시
프록시는 웹 스크레이퍼가 개인 정보와 익명성을 보호하고 IP 차단 회피를 위해 흔히 사용합니다.LWP::UserAgent같은 모듈은 스크레이핑용 프록시 설정 옵션을 제공합니다. 하지만 단일 프록시 서버 사용 시에도 IP 차단 위험이 존재합니다. 따라서 여러 프록시 서버를 순환 사용하도록 설정하는 것이 권장됩니다.LWP::UserAgent를 사용한 매우 간단한 예시는 다음과 같습니다.
먼저 프록시 배열을 정의합니다. 그런 다음 무작위로 하나를 선택하고 proxy 메서드를 사용하여 프록시를 설정합니다:
my @proxies = ( 'https://proxy1.com', 'https://proxy2.com', 'http://proxy3.com' );
my $index = rand @proxies;
my $proxy = $proxies[$index];
$ua->proxy(['http', 'https'], $proxy);
이제 평소처럼 요청을 보낼 수 있습니다. 요청이 실패하면 프록시가 차단되었을 가능성이 높으므로 해당 프록시를 목록에서 제거하고 다른 프록시를 선택하여 다시 시도하세요:
if(request->is_success) {
# 스크래핑을 계속합니다
} else {
# 프록시를 목록에서 제거합니다
splice(@proxies, $index, 1);
# 다시 시도합니다
}
허니팟 트랩 처리
허니팟 트랩은웹 관리자가 봇과 스크레이퍼를 잡기 위해 흔히 사용하는 기법입니다. 일반적으로표시속성이'none'으로 설정된 링크를 사용하는데, 이는 인간 사용자에게는 보이지 않습니다. 하지만 봇은 이를 감지하고 링크를 따라가게 되며, 이는 미끼 웹 페이지로 연결되어 주요 제품에서 멀어지게 합니다.
이 문제를 해결하려면 링크를 따라가기 전에 링크의 display 속성을 확인하세요. 다음은 HTML::TreeBuilder를 사용한 한 가지 방법입니다:
my @links = $root->look_down(
_tag => 'a',
);
foreach my $link (@qlinks) {
my $style = $link->attr('style');
if(defined $style && $style =~ /dislay: none/) {
# 허니팟 감지!
} else {
# 안전하게 진행 가능
}
}
CAPTCHA 해결
CAPTCHA는 웹사이트에 대한 무단 접근을 방지하는 데 도움이 됩니다. 그러나 웹 스크레이퍼가 웹 페이지를 스크레이핑하는 것도 막을 수 있습니다.
CAPTCHA를 해결하기 위해 Bright Data Web Unlocker와 같은 서비스를 사용할 수 있습니다. 이 서비스는 CAPTCHA를 대신 해결해 줍니다.
다음은 Bright Data Web Unlocker를 사용하여 HTTP 요청을 수행하는 예시입니다:
use LWP::UserAgent;
my $agent = LWP::UserAgent->new();
$agent->proxy(['http', 'https'], "http://brd-customer-hl_6d74fc42-zone-residential_proxy4:[email protected]:22225");
print $agent->get('http://lumtest.com/myip.json')->content();
Web Unlocker를 사용하여 HTTP 요청을 수행하면 자동으로 CAPTCHA를 해결하고, 봇 방지 조치를 회피하며, 프록시 관리를 처리해 줍니다.
동적 웹사이트 스크래핑
지금까지 배운 예시는 모두 정적 웹사이트를 스크래핑하는 것이었습니다. 그러나 단일 페이지 애플리케이션(SPA) 및 기타 동적 웹사이트는 더 고급 기술이 필요합니다.
동적 웹사이트는 JavaScript를 사용하여 페이지 콘텐츠를 로드하므로, JavaScript를 실행할 수 있는 스크래핑 도구가 필요합니다.Selenium은브라우저를 에뮬레이트하여 동적 웹사이트를 실행할 수 있는 도구 중 하나입니다. 다음은 이 모듈을 사용한 아주 간단한 예제 코드 조각입니다:
use Selenium::Remote::Driver;
my $driver = Selenium::Remote::Driver->new;
$driver->get('http://example.com');
my $elem = $driver->find_element_by_id('foo');
print $elem->get_text();
$driver->quit();
결론
Perl은 강력한 모듈 집합 덕분에 웹 스크래핑에 탁월한 언어입니다. 이 글에서는 다음을 사용하여 Perl로 웹 페이지를 스크래핑하는 방법을 배웠습니다:
LWP::UserAgent및HTML::TreeBuilderWeb::ScraperMojo::UserAgent및Mojo::DOMXML::LibXML
그러나 보셨듯이, 웹사이트 소유자가 스크레이퍼의 접근을 막으려는 의지가 강한 실제 상황에서는 웹 스크레이핑이 많은 어려움에 직면합니다. 본 글은 몇 가지 일반적인 시나리오와 이에 대처하는 방법을 조명했습니다. 하지만 이러한 문제를 혼자 해결하려다 보면 지루하고 오류가 발생하기 쉽습니다. 바로 여기에Bright Data가도움을 드릴 수 있습니다. 최고의 프록시 서비스,스크래핑 브라우저,웹 언락커, 그리고 궁극의 웹 스크래퍼 API를 갖춘 Bright Data는 웹 스크래핑을 손쉽게 수행할 수 있는 포괄적인 솔루션입니다. 지금 바로 무료 체험을 시작하세요!





