

웹 스크래핑에 관심이 있다면 Crawlee가 도움이 될 수 있습니다. Crawlee는 데이터 과학자, 개발자, 연구원이 웹 데이터를 수집하는 데 사용하는 빠르고 상호작용적인 스크래핑 엔진입니다. Crawlee는 설정하기 쉽고 프록시 로테이션 및 세션 처리와 같은 기능을 제공합니다. 이러한 기능은 IP 주소가 차단되지 않고 대규모 또는 동적 웹사이트를 스크래핑하는 데 필수적이며, 원활하고 중단 없는 데이터 수집을 보장합니다.
이 튜토리얼에서는 Crawlee를 활용한 웹 스크래핑 방법을 배웁니다. 기본적인 웹 스크래핑 예제로 시작하여 세션 관리, 동적 페이지 스크래핑과 같은 고급 개념으로 단계적으로 진행합니다.
Crawlee를 이용한 웹 스크래핑 방법
본 튜토리얼을 시작하기 전에 컴퓨터에 다음 필수 구성 요소가 설치되어 있는지 확인하세요:
- Node.js
- npm
- Visual Studio Code
Crawlee를 이용한 기본 웹 스크래핑
모든 필수 요소를 준비했다면, 간단한 HTML 구조를 제공하여 학습에 적합한 Books to Scrape 웹사이트를 스크래핑하는 것으로 시작해 보겠습니다.
터미널 또는 셸을 열고 다음 명령어로 Node.js 프로젝트를 초기화하세요:
mkdir crawlee-tutorial
cd crawlee-tutorial
npm init -y
그런 다음 다음 명령어로 Crawlee 라이브러리를 설치하세요:
npm install crawlee
웹사이트에서 데이터를 효과적으로 스크래핑하려면, 스크래핑하려는 웹 페이지의 HTML 태그 세부 정보를 확인해야 합니다. 이를 위해 브라우저에서 웹사이트를 열고, 웹 페이지 아무 곳이나 마우스 오른쪽 버튼으로 클릭하여 개발자 도구 ( Developer Tools )로 이동하세요. 그런 다음 ‘검사(Inspect) ‘ 또는 ‘요소 검사(Inspect Element)‘를 클릭하세요:
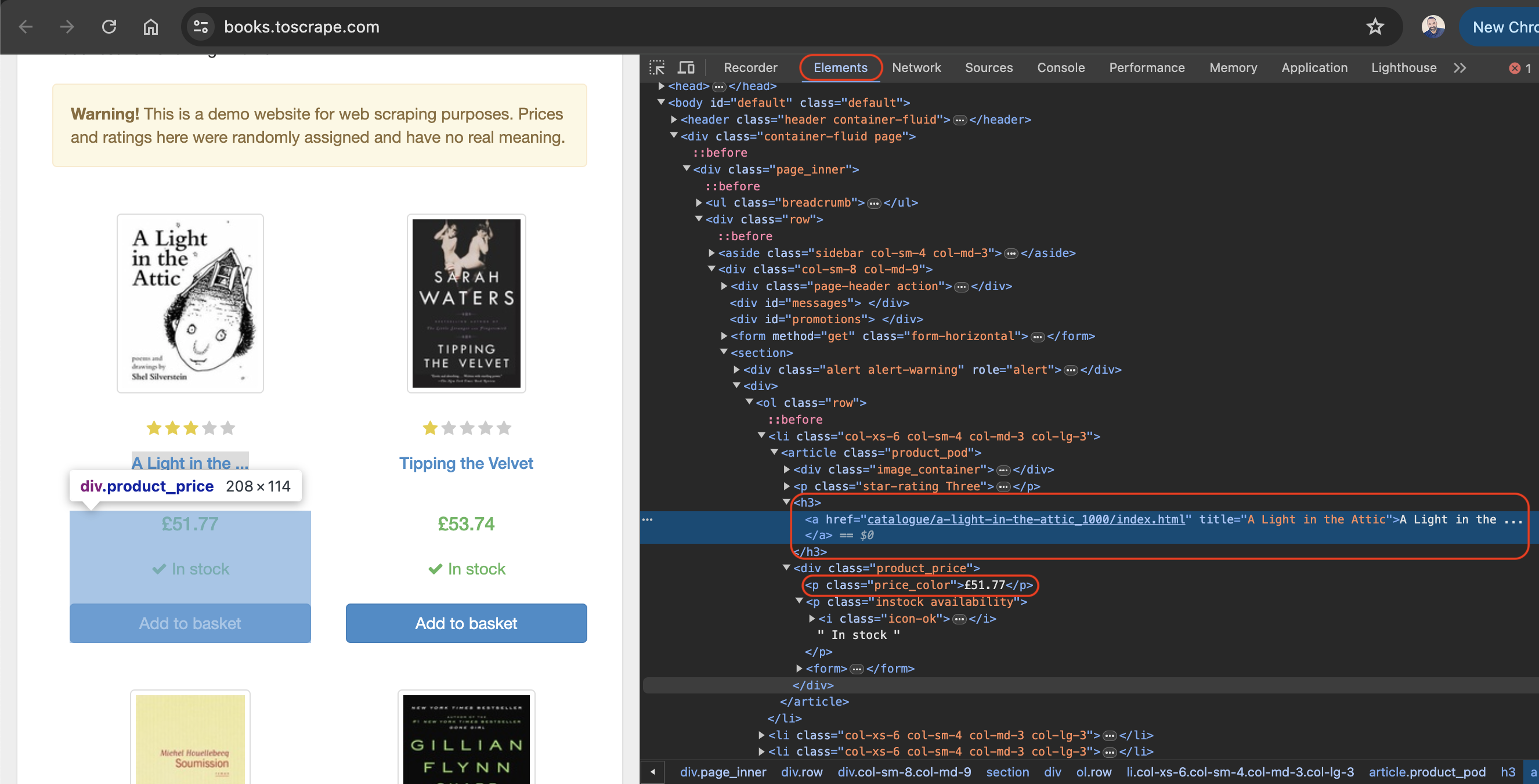
기본적으로 ‘요소’ 탭이 활성화되어 있으며, 이 탭은 웹 페이지의 HTML 레이아웃을 나타냅니다. 이 예시에서 표시된 모든 책은 product_pod 클래스를 가진 article HTML 태그 안에 배치됩니다. 각 article 내에서는 책 제목이 h3 태그에 포함됩니다. 책의 실제 제목은 h3 요소 내부에 위치한 a 태그의 title 속성에 포함됩니다. 책 가격은 price_color 클래스를 가진 p 태그 안에 위치합니다:
프로젝트 루트 디렉터리 아래에 scrape.js라는 파일을 생성하고 다음 코드를 추가하세요:
const { CheerioCrawler } = require('crawlee');
const crawler = new CheerioCrawler({
async requestHandler({ request, $ }) {
const books = [];
$('article.product_pod').each((index, element) => {
const title = $(element).find('h3 a').attr('title');
const price = $(element).find('.price_color').text();
books.push({ title, price });
});
console.log(books);
},
});
crawler.run(['https://books.toscrape.com/']);
이 코드에서는 crawlee의 CheerioCrawler를 사용하여 https://books.toscrape.com/에서 책 제목과 가격을 스크래핑합니다. 크롤러는 HTML 콘텐츠를 가져오고, jQuery와 유사한 구문을 사용하여 <article class="product_pod"> 요소에서 데이터를 추출한 후 결과를 콘솔에 기록합니다.
scrape.js 파일에 위 코드를 추가한 후 다음 명령어로 실행할 수 있습니다:
node scrape.js
터미널에 책 제목과 가격의 배열이 출력됩니다:
…출력 생략…
{
title: 'The Boys in the Boat: Nine Americans and Their Epic Quest for Gold at the 1936 Berlin Olympics',
price: '£22.60'
},
{ title: 'The Black Maria', price: '£52.15' },
{
title: 'Starving Hearts (Triangular Trade Trilogy, #1)',
price: '£13.99'
},
{ title: "Shakespeare's Sonnets", price: '£20.66' },
{ title: 'Set Me Free', price: '£17.46' },
{
title: "스캇 필그림의 소중한 작은 삶 (스캇 필그림 #1)",
price: '£52.29'
},
…출력 생략…
Crawlee를 이용한 프록시 로테이션
프록시는 컴퓨터와 인터넷 사이의 중개자 역할을 합니다. 프록시를 사용하면 웹 요청이 프록시 서버로 전송되고, 프록시 서버는 이를 대상 웹사이트로 전달합니다. 프록시 서버는 웹사이트의 응답을 다시 보내며, 프록시는 사용자의 IP 주소를 숨겨 속도 제한이나 IP 차단으로부터 보호합니다.
Crawlee는 재시도 및 오류 처리를 효율적으로 수행하는 내장형 프록시 처리 기능을 제공하여 프록시 구현을 간편하게 합니다. 또한 Crawlee는 회전 프록시 구현을 위한 다양한 프록시 구성을 지원합니다.
다음 섹션에서는 먼저 유효한 프록시를 획득하여 프록시를 설정합니다. 그런 다음 요청이 프록시를 통해 전송되는지 확인합니다.
프록시 설정하기
무료 프록시는 일반적으로 권장되지 않습니다. 속도가 느리고 안전하지 않을 수 있으며, 민감한 웹 작업에 필요한 지원을 제공하지 않을 수 있기 때문입니다. 대신 안전하고 안정적이며 신뢰할 수 있는 프록시 서비스인 Bright Data를 사용하는 것을 고려해 보세요. 무료 체험판도 제공되므로 구매 전에 테스트해 볼 수 있습니다.
Bright Data를 사용하려면 홈페이지의 ‘무료 체험 시작’ 버튼을 클릭하고 계정 생성에 필요한 정보를 입력하세요.
계정 생성 후 Bright Data 대시보드에 로그인하여‘프록시 및 스크래핑 인프라’로 이동한 다음‘주거용 프록시’를 선택해 새 프록시를 추가하세요:
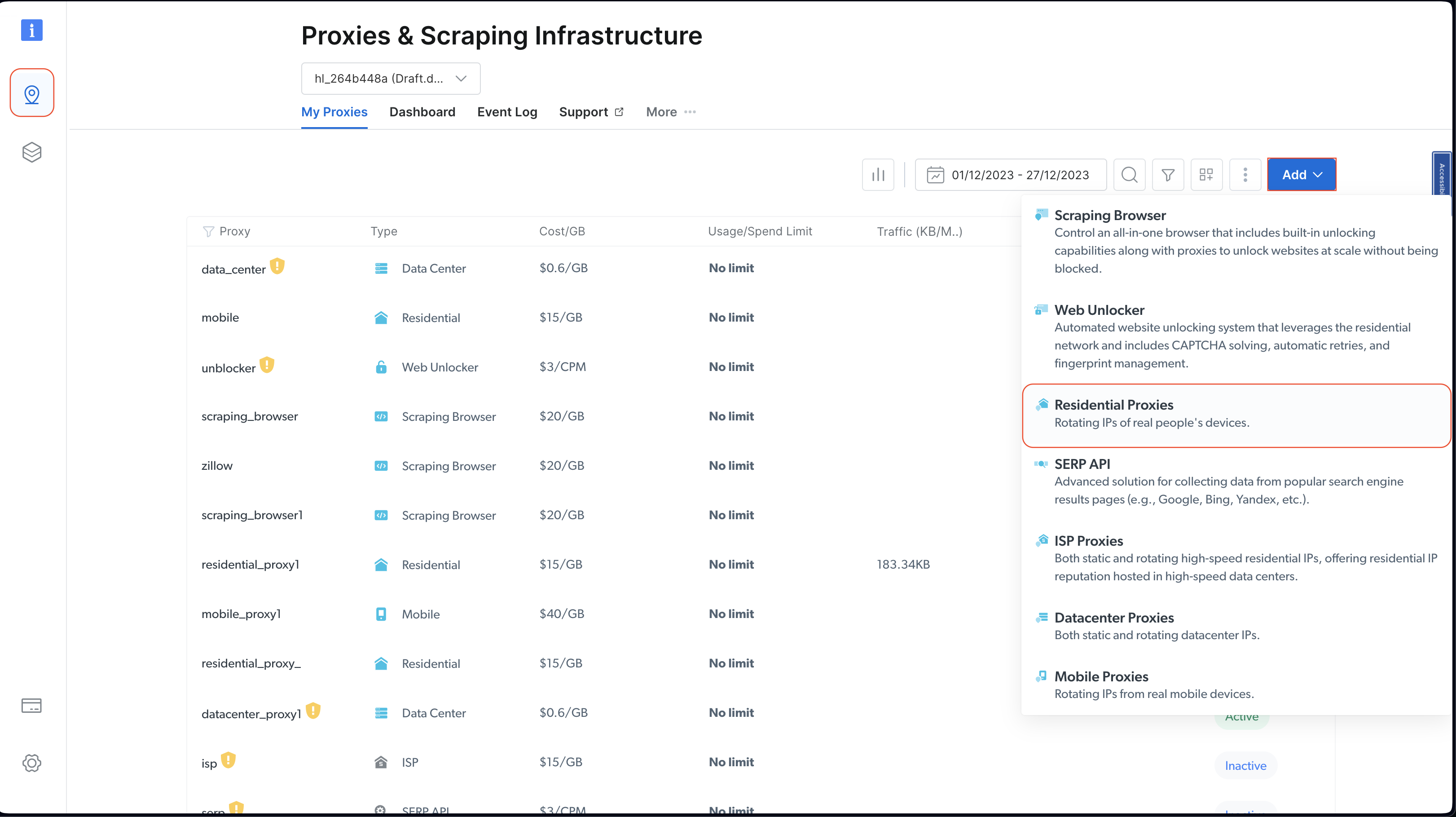
기본 설정을 유지한 상태에서 ‘추가’를 클릭하여 주거용 프록시 생성을 완료하세요.
인증서 설치를 요청받는 경우 ‘인증서 없이 진행’을 선택할 수 있습니다. 그러나 실제 운영 환경에서는 프록시 정보가 유출될 경우를 대비해 인증서를 설정하여 오용을 방지해야 합니다.
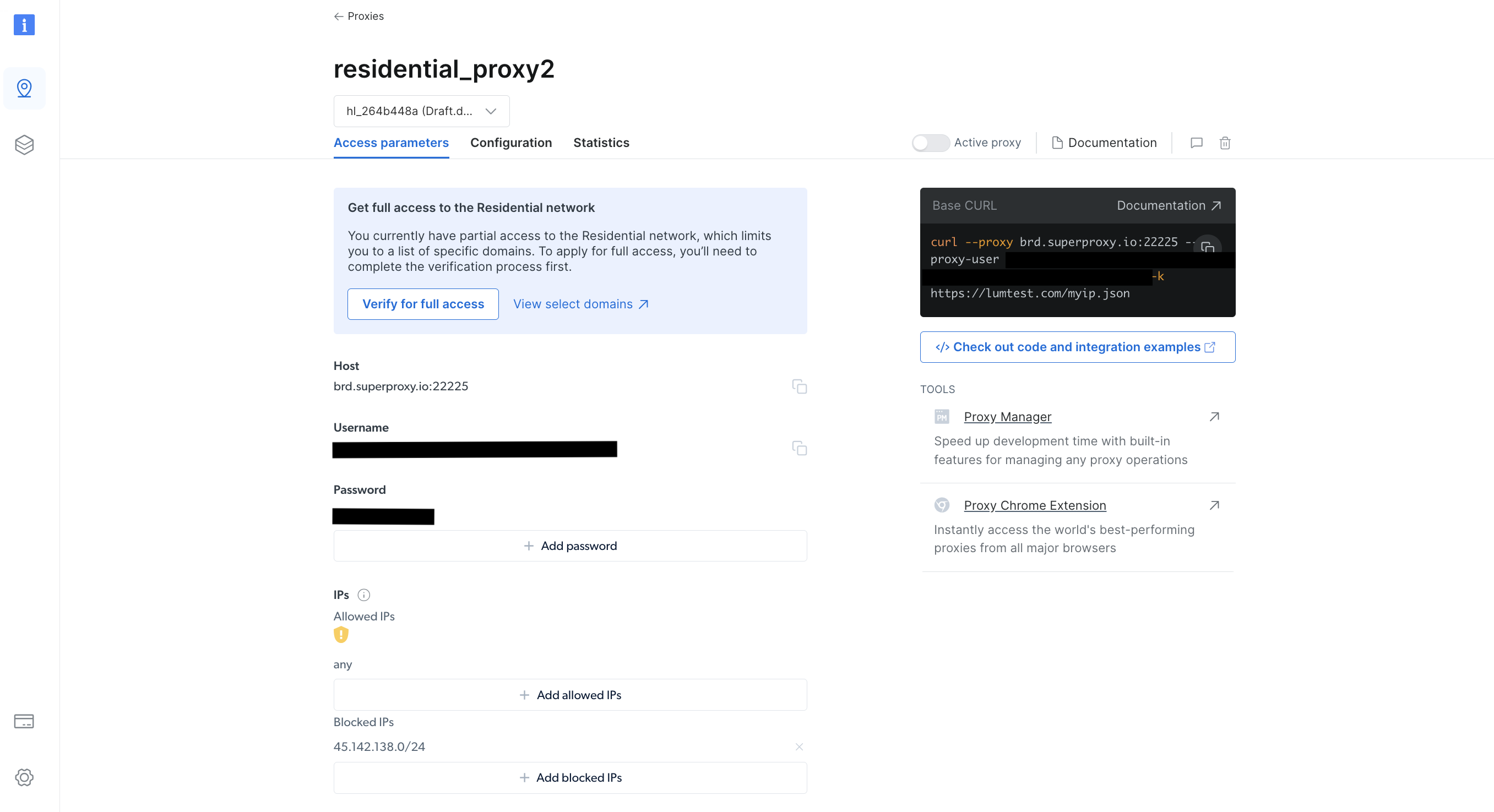
생성 후 호스트, 포트, 사용자 이름, 비밀번호를 포함한 프록시 자격 증명을 기록해 두세요. 다음 단계에서 필요합니다:
프로젝트 루트 디렉터리에서 다음 명령어를 실행하여 axios 라이브러리를 설치하세요:
npm install axios
axios 라이브러리를 사용하여 http://lumtest.com/myip.json에 GET 요청을 수행하면 스크립트 실행 시마다 사용 중인 프록시의 세부 정보가 반환됩니다.
다음으로 프로젝트 루트 디렉터리에서 scrapeWithProxy.js 파일을 생성하고 다음 코드를 추가하세요:
const { CheerioCrawler } = require("crawlee");
const { ProxyConfiguration } = require("crawlee");
const axios = require("axios");
const proxyConfiguration = new ProxyConfiguration({
proxyUrls: ["http://USERNAME:PASSWORD@HOST:PORT"],
});
const crawler = new CheerioCrawler({
proxyConfiguration,
async requestHandler({ request, $, response, proxies }) {
// 프록시 정보 URL에 GET 요청 수행
try {
const proxyInfo = await axios.get("http://lumtest.com/myip.json", {
proxy: {
host: "HOST",
port: PORT,
auth: {
username: "USERNAME",
password: "PASSWORD",
},
},
});
console.log("프록시 정보:", proxyInfo.data);
} catch (error) {
console.error("프록시 정보 가져오기 오류:", error.message);
}
const books = [];
$("article.product_pod").each((index, element) => {
const title = $(element).find("h3 a").attr("title");
const price = $(element).find(".price_color").text();
books.push({ title, price });
});
console.log(books);
},
});
crawler.run(["https://books.toscrape.com/"]);
참고:
HOST,PORT,USERNAME,PASSWORD를 본인 인증 정보로 반드시 교체하십시오.
이 코드에서는 crawlee의 CheerioCrawler를 사용하여 지정된 프록시를 통해 https://books.toscrape.com/에서 정보를 스크래핑합니다. ProxyConfiguration으로 프록시를 구성한 후, http://lumtest.com/myip.json에 대한 GET 요청을 통해 프록시 세부 정보를 가져와 로그에 기록합니다. 마지막으로 Cheerio의 jQuery와 유사한 구문을 사용하여 도서 제목과 가격을 추출하고 스크랩된 데이터를 콘솔에 기록합니다.
이제 코드를 실행하여 프록시가 정상 작동하는지 테스트할 수 있습니다:
node scrapeWithProxy.js
이전과 유사한 결과를 볼 수 있지만, 이번에는 요청이 Bright Data 프록시를 통해 라우팅됩니다. 콘솔에 프록시 세부 정보가 기록된 것도 확인할 수 있습니다:
Proxy Information: {
country: 'US',
asn: { asnum: 21928, org_name: 'T-MOBILE-AS21928' },
geo: {
city: 'El Paso',
region: 'TX',
region_name: 'Texas',
postal_code: '79925',
latitude: 31.7899,
longitude: -106.3658,
tz: 'America/Denver',
lum_city: 'elpaso',
lum_region: 'tx'
}
}
[
{ title: '다락방의 빛', price: '£51.77' },
{ title: '벨벳을 뒤집다', price: '£53.74' },
{ title: '복종', price: '£50.10' },
{ title: '샤프 오브젝트', price: '£47.82' },
{ title: '사피엔스: 인류의 짧은 역사', price: '£54.23' },
{ title: '레퀴엠 레드', price: '£22.65' },
…출력 생략..
node scrapingWithBrightData.js로 스크립트를 다시 실행하면 Bright Data 프록시 서버가 사용하는 다른 IP 주소 위치를 확인할 수 있습니다. 이는 Bright Data가 스크래핑 스크립트 실행 시마다 위치와 IP를 순환한다는 것을 검증합니다. 이 순환은 대상 웹사이트의 차단 또는 IP 금지를 우회하는 데 중요합니다.
참고:
proxyConfiguration에서다른 프록시 IP를 전달할 수도 있지만, Bright Data가 이를 자동으로 처리하므로 IP를 명시할 필요가 없습니다.
Crawlee를 통한 세션 관리
세션은 여러 요청에 걸쳐 상태를 유지하는 데 도움이 되며, 쿠키나 로그인 세션을 사용하는 웹사이트에 유용합니다.
세션을 관리하려면 프로젝트 루트 디렉터리에 scrapeWithSessions. js라는 파일을 생성하고 다음 코드를 추가하세요:
const { CheerioCrawler, SessionPool } = require("crawlee");
(async () => {
// 세션 풀 열기
const sessionPool = await SessionPool.open();
// 풀에 세션이 있는지 확인
let session = await sessionPool.getSession();
if (!session) {
session = await sessionPool.createSession();
}
const crawler = new CheerioCrawler({
useSessionPool: true, // 세션 풀 활성화
async requestHandler({ request, $, response, session }) {
// 세션 정보 로깅
console.log(`사용 중인 세션: ${session.id}`);
// 책 데이터 추출 및 로그 기록 (시연용)
const books = [];
$("article.product_pod").each((index, element) => {
const title = $(element).find("h3 a").attr("title");
const price = $(element).find(".price_color").text();
books.push({ title, price });
});
console.log(books);
},
});
// 첫 번째 실행
await crawler.run(["https://books.toscrape.com/"]);
console.log("첫 번째 실행 완료.");
// 두 번째 실행
await crawler.run(["https://books.toscrape.com/"]);
console.log("두 번째 실행 완료.");
})();
여기서는 crawlee의 CheerioCrawler와 SessionPool을 사용해 https://books.toscrape.com/에서 데이터를 스크래핑합니다. 세션 풀을 초기화한 후, 이 세션을 활용하도록 크롤러를 구성합니다. requestHandler 함수는 세션 정보를 기록하고 Cheerio의 jQuery 스타일 선택자를 사용하여 도서 제목과 가격을 추출합니다. 이 코드는 두 번의 연속적인 스크래핑 실행을 수행하며 각 실행마다 세션 ID를 기록합니다.
다른 세션이 사용되는지 확인하기 위해 코드를 실행하고 테스트하세요:
node scrapeWithSessions.js
이전과 유사한 결과가 표시되지만, 이번에는 각 실행마다 세션 ID도 함께 확인됩니다:
사용 중인 세션: session_GmKuZ2TnVX
[
{ title: 'A Light in the Attic', price: '£51.77' },
{ title: 'Tipping the Velvet', price: '£53.74' },
…출력 생략…
사용 중인 세션: session_lNRxE89hXu
[
{ title: 'A Light in the Attic', price: '£51.77' },
{ title: 'Tipping the Velvet', price: '£53.74' },
…출력 생략…
코드를 다시 실행하면 다른 세션 ID가 사용되는 것을 확인할 수 있습니다.
Crawlee를 통한 동적 콘텐츠 처리
동적 웹사이트 (즉, JavaScript로 콘텐츠가 채워지는 웹사이트) 를 다룰 때는 데이터를 접근하기 위해 JavaScript를 렌더링해야 하므로 웹 스크래핑이 매우 어려울 수 있습니다. 이러한 상황을 처리하기 위해 Crawlee는 Puppeteer와 통합됩니다. Puppeteer는 JavaScript를 렌더링하고 대상 웹사이트와 인간처럼 상호작용할 수 있는 헤드리스 브라우저입니다.
이 기능을 시연하기 위해 YouTube 페이지의 콘텐츠를 스크래핑해 보겠습니다. 항상 그렇듯, 스크래핑 전에 해당 페이지의 이용 약관 및 서비스 규정을 반드시 확인하세요.
이용약관을 검토한 후, 프로젝트 루트 디렉터리에 scrapeDynamicContent.js라는 파일을 생성하고 다음 코드를 추가하세요:
const { PuppeteerCrawler } = require("crawlee");
async function scrapeYouTube() {
const crawler = new PuppeteerCrawler({
async requestHandler({ page, request, enqueueLinks, log }) {
const { url } = request;
await page.goto(url, { waitUntil: "networkidle2" });
// 첫 10개 댓글 스크래핑
const comments = await page.evaluate(() => {
return Array.from(document.querySelectorAll("#comments #content-text"))
.slice(0, 10)
.map((el) => el.innerText);
});
log.info(`댓글: ${comments.join("n")}`);
},
launchContext: {
launchOptions: {
headless: true,
},
},
});
// 스크래핑할 YouTube 동영상 URL 추가
await crawler.run(["https://www.youtube.com/watch?v=wZ6cST5pexo"]);
}
scrapeYouTube();
그런 다음 다음 명령어로 코드를 실행하세요:
node scrapeDynamicContent.js
이 코드에서는 Crawlee 라이브러리의 PuppeteerCrawler를 사용하여 YouTube 동영상 댓글을 스크래핑합니다. 먼저 특정 YouTube 동영상 URL로 이동하고 페이지가 완전히 로드될 때까지 대기하는 크롤러를 초기화합니다. 페이지가 로드되면 코드는 지정된 CSS 선택자 #comments #content-text를 사용하여 요소를 선택해 첫 10개의 댓글을 추출합니다. 그런 다음 댓글을 콘솔에 기록합니다.
출력 결과에는 선택한 동영상과 관련된 첫 10개의 댓글이 포함되어야 합니다:
INFO PuppeteerCrawler: 크롤러 시작 중.
INFO PuppeteerCrawler: 댓글: 누구를 응원하시나요?? 미 해병대 vs 전과자들
Bro Mateo는 괴물이에요, 리프팅 스트랩 없이, 좁은 스탠스로.
푸시업을 하는 전과자는 괴물이에요.
말장난이나 긴 인트로/아웃트로 없이 영상이 정말 간결한 게 마음에 들어
"둘 다 전투 경험이 있다"는 대사가 끝내준다
군인 출신이 하는 데드리프트는 정말 장난이 아니네...
한쪽은 싸우기 위해 살고, 다른 쪽은 살기 위해 싸운다.
마침내 영화 속 서사가 진짜인지 검증할 수 있는 내용이 나왔군
모두의 우정이 마음에 든다. 특히 벤치 프레스에서... 양팀 멤버들이 부상 방지를 위해 재빨리 스포팅을 도왔다. 잘했어.
이런 스타일이 좋다. 유튜브식 장난 없이 바로 리프트로 들어가는 거
…출력 생략…
이 튜토리얼에 사용된 모든 코드는 GitHub에서 확인할 수 있습니다.
결론
이 글에서는 웹 스크래핑을 위해 Crawlee를 사용하는 방법을 배웠으며, Crawlee가 웹 스크래핑 프로젝트의 효율성과 신뢰성을 어떻게 향상시킬 수 있는지 확인했습니다.
데이터를 스크래핑할 때는 항상 대상 웹사이트의 robots.txt 파일과 이용 약관을 준수해야 합니다.
전문적인 수준의 데이터, 도구, 프록시로 웹 스크래핑 프로젝트를 한 단계 업그레이드할 준비가 되셨나요? Bright Data의 포괄적인 웹 스크래핑 플랫폼을 살펴보세요. 즉시 사용 가능한 데이터셋과 고급 프록시 서비스를 제공하여 데이터 수집 작업을 효율화합니다.
지금 가입하고 무료 체험을 시작하세요!





