이 Goutte 웹 스크래핑 가이드에서 다음을 배우게 됩니다:
- PHP 라이브러리 Goutte란 무엇인가
- 단계별 튜토리얼을 통한 웹 스크래핑 활용 방법
- 웹 스크래핑을 위한 Goutte 대안
- 이 접근법의 한계점과 가능한 해결책
자, 시작해 보겠습니다!
Goutte란 무엇인가?
Goutte는 스크린 스크래핑 및 웹 크롤링을 위한 PHP 라이브러리로, 웹사이트 탐색 및 HTML/XML 응답에서 데이터 추출을 위한 직관적인 API를 제공합니다. 통합 HTTP 클라이언트와 HTML 파싱 기능을 포함하여 HTTP 요청을 통해 웹 페이지를 가져오고 데이터 스크래핑을 위해 처리할 수 있습니다.
참고: 2023년 4월 1일 기준으로 Goutte는 더 이상 유지보수되지 않으며 이제 사용 중단된 것으로 간주됩니다. 그러나 이 글을 작성하는 시점에서는 여전히 안정적으로 작동합니다.
Goutte를 이용한 웹 스크래핑 수행 방법: 단계별 가이드
이 단계별 튜토리얼 섹션을 따라 “하키 팀” 사이트에서 데이터를 추출하기 위해 Goutte를 사용하는 방법을 확인하세요:
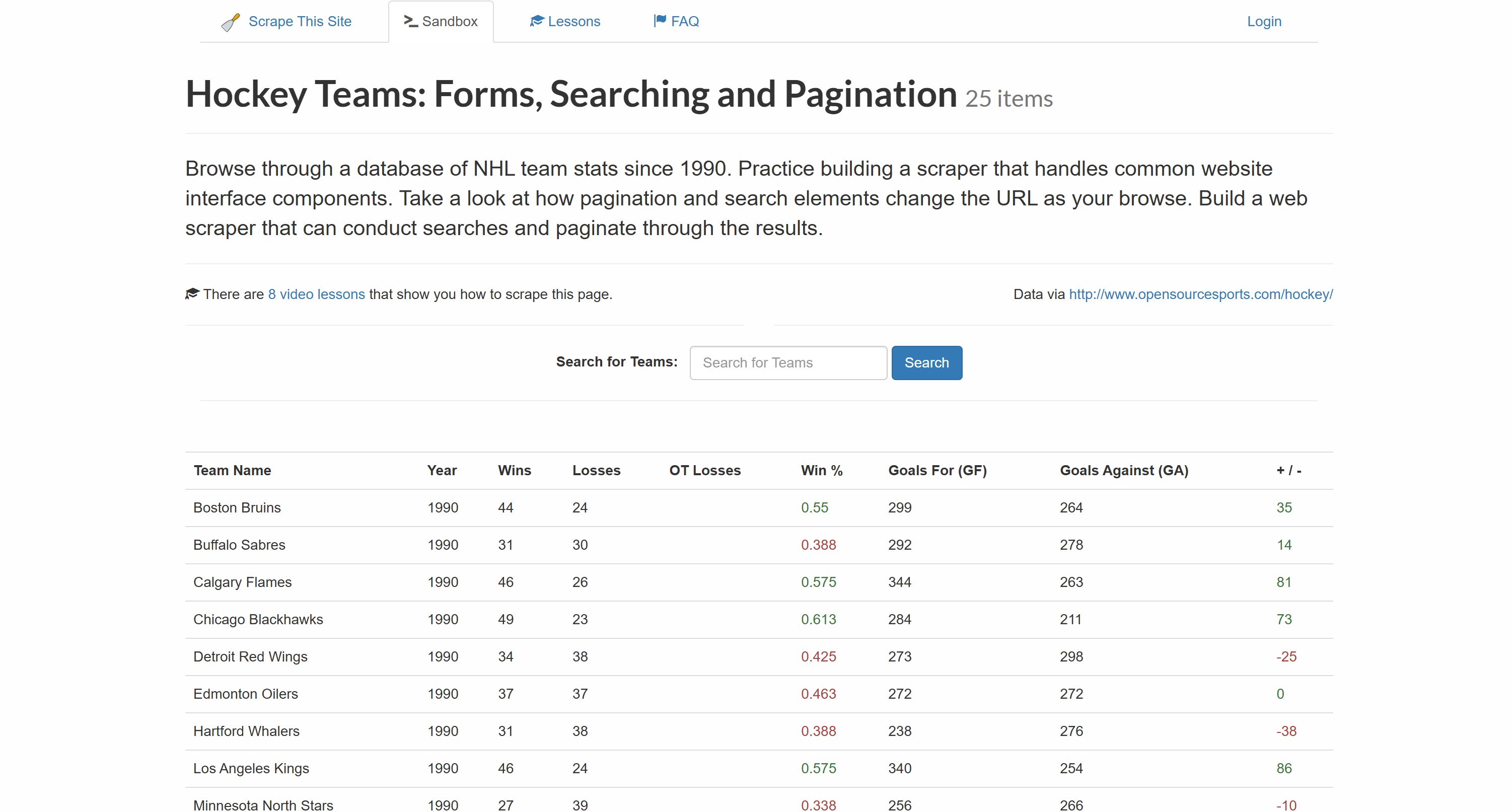
목표는 위 표의 데이터를 추출하여 CSV 파일로 내보내는 것입니다.
Goutte로 웹 스크래핑을 수행하는 방법을 배울 시간입니다!
1단계: 프로젝트 설정
시작하기 전에 시스템이 Goutte의 요구 사항(PHP 7.1 이상)을 충족하는지 확인하세요. 현재 PHP 버전을 확인하려면 다음 명령어를 실행하세요:
php -v출력 결과는 다음과 유사해야 합니다:
PHP 8.4.3 (cli) (built: Jan 19 2026 14:20:58) (NTS)
Copyright (c) The PHP Group
Zend Engine v4.4.3, Copyright (c) Zend Technologies
with Zend OPcache v8.4.3, Copyright (c), by Zend TechnologiesPHP 버전이 7.1 미만인 경우 진행하기 전에 PHP를 업그레이드해야 합니다.
다음으로, Goutte는 PHP용 의존성 관리자인 Composer를 통해 설치된다는 점을 유의하세요. 시스템에 Composer가 설치되어 있지 않다면 공식 사이트에서 다운로드하여 설치 지침을 따르세요.
이제 Goutte 프로젝트용 새 디렉터리를 생성하고 터미널에서 해당 디렉터리로 이동하세요:
mkdir goutte-parser
cd goutte-parser다음으로, composer init 명령어를 사용하여 폴더 내에서 Composer 프로젝트를 초기화하세요:
composer initComposer가 패키지 이름, 설명 등 프로젝트 세부 정보를 입력하도록 요청합니다. 기본값으로도 충분하지만, 필요에 따라 자유롭게 수정하세요.
이제 선호하는 PHP IDE에서 프로젝트 폴더를 엽니다. Visual Studio Code(PHP 확장 기능 포함) 나 IntelliJ WebStorm이 모두 좋은 선택입니다.
프로젝트 폴더에 빈 index.php 파일을 생성하고 다음 내용을 포함시킵니다:
php-html-parser/
├── vendor/
├── composer.json
└── index.phpindex.php 파일을 열고 Composer 라이브러리를 임포트하기 위해 다음 코드 줄을 추가하세요:
<?php
require_once __DIR__ . "/vendor/autoload.php";
// 스크래핑 로직...이 파일에는 곧 Goutte 스크래핑 로직이 포함될 것입니다.
이제 다음 명령어로 스크립트를 실행할 수 있습니다:
php index.php좋습니다! 이제 PHP에서 Goutte로 데이터 스크래핑을 시작할 준비가 모두 완료되었습니다.
2단계: Goutte 설치 및 구성
아래 Compose 명령어로 Goutte를 설치하세요:
composer require fabpot/goutte이렇게 하면 fabpot/goutte 종속성이 composer.json 파일에 추가됩니다. 이제 해당 파일에는 다음과 같은 내용이 포함됩니다:
"require": {
"fabpot/goutte": "^4.0"
}index.php 파일에서 다음 코드 줄을 추가하여 Goutte를 임포트하세요:
use GoutteClient;이렇게 하면 대상 페이지에 연결하고 HTML을 파싱하며 데이터를 추출하는 데 사용할 수 있는 Goutte HTTP 클라이언트가 노출됩니다. 다음 단계에서 그 방법을 확인하세요!
3단계: 대상 페이지의 HTML 가져오기
먼저 새로운 Goutte HTTP 클라이언트를 생성합니다:
$client = new Client();배경에서 Goutte의 Client 클래스는 단순히 Symfony의 BrowserKitHttpBrowser 컴포넌트를 감싼 래퍼입니다. Laravel을 사용한 웹 스크래핑 가이드에서 실제 동작을 확인해 보세요.
다음으로 대상 웹페이지 URL을 변수에 저장하고 request() 메서드를 사용하여 내용을 가져옵니다:
$url = "https://www.scrapethissite.com/pages/forms/";
$crawler = $client->request("GET", $url);이 코드는 웹페이지에 GET 요청을 보내 HTML 문서를 가져온 후 파싱합니다. 특히 $crawler 객체는 Symfony의 DomCrawler 컴포넌트의 모든 메서드에 접근할 수 있게 합니다. $crawler는 페이지 탐색 및 데이터 추출에 사용할 객체입니다.
대단합니다! 이제 Goutte 웹 스크래핑에 필요한 모든 것을 갖추셨습니다.
4단계: 관심 데이터 스크래핑 준비
데이터 추출 전에 대상 페이지의 HTML 구조를 숙지해야 합니다.
먼저, 관심 데이터가 테이블 내 행으로 표시된다는 점을 기억하세요. 해당 테이블에는 여러 행이 포함되므로, 스크래핑된 데이터를 저장하기에 배열이 훌륭한 데이터 구조입니다:
$teams = [];이제 테이블의 HTML 구조에 집중하세요. 브라우저에서 대상 페이지를 방문하고, 관심 데이터가 포함된 테이블을 마우스 오른쪽 버튼으로 클릭한 후 “검사” 옵션을 선택하세요:
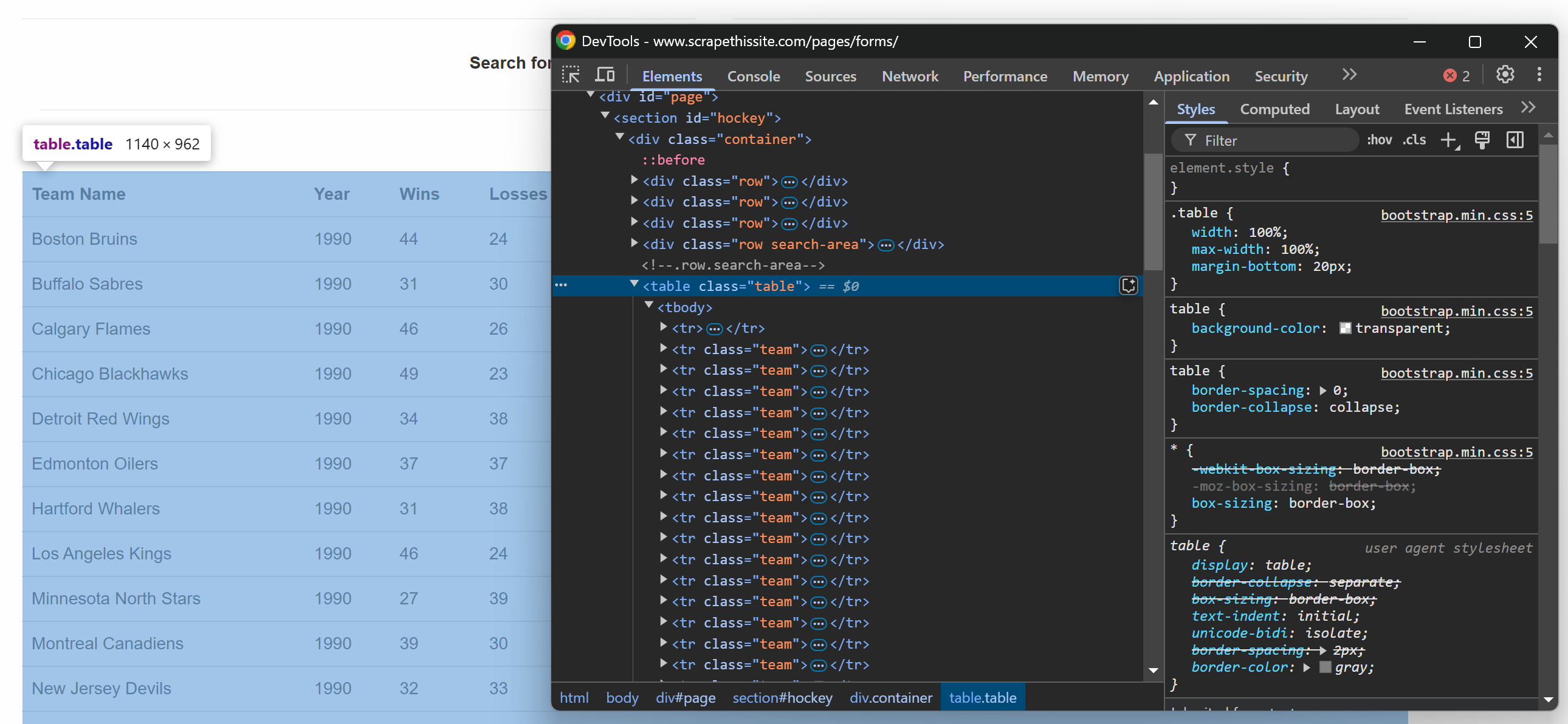
개발자 도구에서 테이블이 table 클래스를 가지며 id="hockey"인 <section> 요소 안에 포함되어 있음을 확인할 수 있습니다. 이는 다음 CSS 선택자로 테이블을 타겟팅할 수 있음을 의미합니다:
#hockey .table$crawler->filter() 메서드를 사용하여 CSS 선택기로 테이블 노드를 선택합니다:
$table = $crawler->filter("#hockey .table");그런 다음 각 행이 class team을 가진 <tr> 요소로 표현된다는 점을 유의하세요. 모든 행을 선택하고 반복 처리하여 데이터를 추출할 준비를 합니다:
$table->filter("tr.team")->each(function ($tr) use (&$teams) {
// 데이터 추출 로직...
});훌륭합니다! 이제 Goutte 데이터 스크래핑을 위한 기본 구조가 완성되었습니다.
단계 #5: 데이터 추출 로직 구현
이전과 마찬가지로, 이번에는 테이블 내부의 행을 살펴보세요:
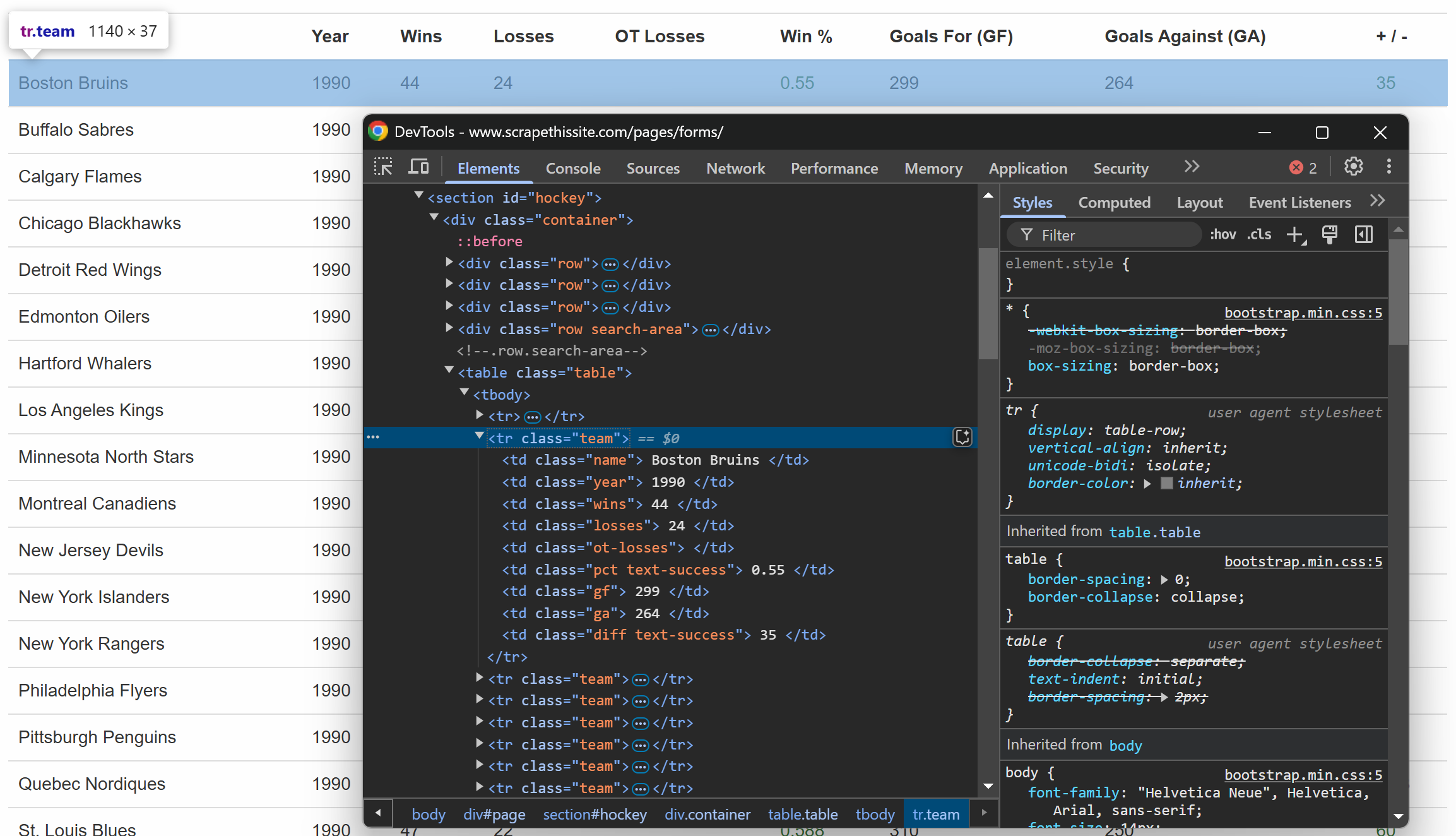
각 행에는 전용 열에 다음과 같은 정보가 포함되어 있음을 확인할 수 있습니다:
- 팀명 →
.name요소 내부에 위치 - 시즌 연도 →
.year요소 내부에 위치 - 승리 횟수 →
.wins요소 내부에 위치 - 패배 횟수 →
.losses요소 내부에 - 연장전 패배 →
.ot-losses요소 내부 - 승률 →
.pct요소 내부 - 득점 (득점 – GF) →
.gf요소 내부 - 실점 (실점 – GA) →
.ga요소 내부 - 골 득실차 →
.diff요소 내부
단일 정보를 검색하려면 다음 두 단계를 적용해야 합니다:
filter()를 사용하여 HTML 요소를 선택합니다text()메서드로 텍스트 콘텐츠를 추출하고trim()으로 불필요한 공백 제거
예를 들어, 팀 이름을 다음과 같이 스크래핑할 수 있습니다:
$teamElement = $tr->filter(".name");
$team = trim($teamElement->text());마찬가지로 이 논리를 다른 모든 열에 확장합니다:
$yearElement = $tr->filter(".year");
$year = trim($yearElement->text());
$winsElement = $tr->filter(".wins");
$wins = trim($winsElement->text());
$lossesElement = $tr->filter(".losses");
$losses = trim($lossesElement->text());
$otLossesElement = $tr->filter(".ot-losses");
$otLosses = trim($otLossesElement->text());
$pctElement = $tr->filter(".pct");
$pct = trim($pctElement->text());
$gfElement = $tr->filter(".gf");
$gf = trim($gfElement->text());
$gaElement = $tr->filter(".ga");
$ga = trim($gaElement->text());
$diffElement = $tr->filter(".diff");
$diff = trim($diffElement->text());관심 있는 데이터를 행에서 추출한 후 $teams 배열에 저장하세요:
$teams[] = [
"team" => $team,
"year" => $year,
"wins" => $wins,
"losses" => $losses,
"연장전패" => $otLosses,
"승률" => $pct,
"득점" => $gf,
"실점" => $ga,
"득실차" => $diff
];모든 행을 순회한 후, $teams 배열에는 다음이 포함됩니다:
Array
(
[0] => Array
(
[team] => Boston Bruins
[year] => 1990
[wins] => 44
[losses] => 24
[ot_losses] =>
[win_perc] => 0.55
[goals_for] => 299
[goals_against] => 264
[goal_diff] => 35
)
// ...
[24] => Array
(
[team] => Chicago Blackhawks
[year] => 1991
[승] => 36
[패] => 29
[연장전 패] =>
[승률] => 0.45
[득점] => 257
[실점] => 236
[득실차] => 21
)
)훌륭합니다! Goutte 데이터 스크래핑이 성공적으로 수행되었습니다.
6단계: 크롤링 로직 구현
이제 대상 사이트가 데이터를 여러 페이지에 걸쳐 표시하며 한 번에 일부만 보여준다는 점을 잊지 마세요. 테이블 아래에는 모든 페이지로 연결되는 링크를 제공하는 페이지네이션 요소가 있습니다:

따라서 스크래핑 스크립트에서 페이지네이션을 관리하려면 다음 간단한 단계를 따르세요:
- 페이지네이션 링크 요소 선택
- 페이지별 페이지의 URL 추출
- 각 페이지를 방문하여 앞서 설계한 스크래핑 로직 적용
페이지네이션 링크 요소를 검사하는 것으로 시작하세요:
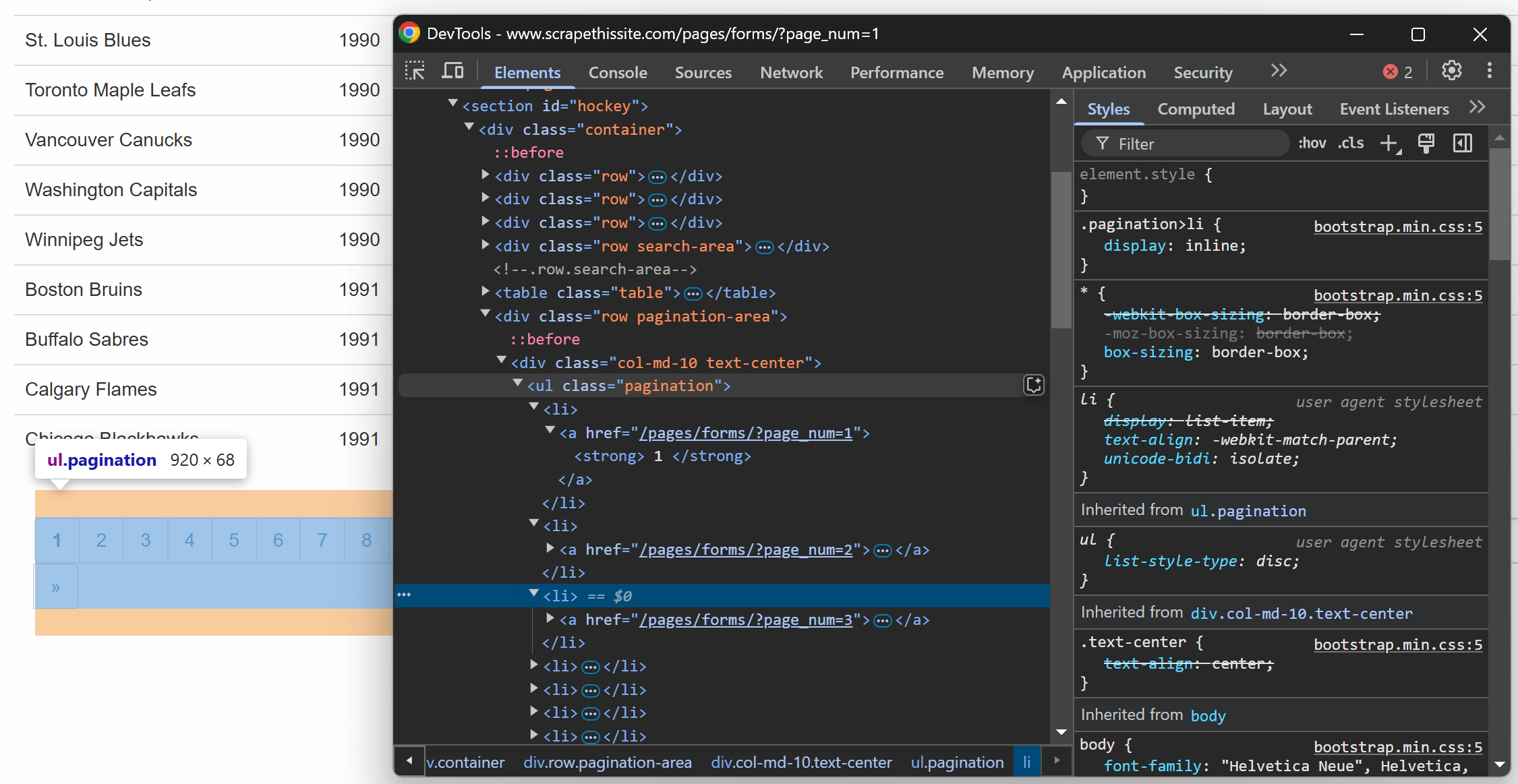
다음 CSS 선택자를 사용하면 모든 페이지네이션 링크를 선택할 수 있습니다:
.pagination li a2단계를 구현하고 모든 페이지네이션 URL을 수집하려면 다음 로직을 사용하세요:
$urls = [$url];
// 페이지네이션 링크 요소 선택
$crawler->filter(".pagination li a")->each(function ($a) use (&$urls) {
// 절대 URL 생성
$url = "https://www.scrapethissite.com" . $a->attr("href");
// 해당 페이지네이션 URL이 아직 목록에 없으면 추가
if (!in_array($url, $urls)) {
$urls[] = $url;
}
});이 코드는 첫 페이지 URL을 시작으로 페이지네이션 링크를 저장할 URL 목록을 초기화합니다. 이후 모든 페이지네이션 요소를 선택하여 반복 처리하며, 이미 존재하지 않는 경우에만 새 URL을 $urls 배열에 추가합니다. 페이지 내 URL은 상대 경로이므로 목록에 추가하기 전에 절대 URL로 변환해야 합니다.
페이지네이션 처리는 한 번만 실행되어야 하며 데이터 추출과 직접적으로 연결되지 않으므로 함수로 감싸는 것이 가장 좋습니다:
function getPaginationUrls($client, $url)
{
// 사이트 첫 페이지에 연결
$crawler = $client->request("GET", $url);
// 현재 URL로 스크래핑할 URL 목록 초기화
$urls = [$url];
// 페이지네이션 링크 요소 선택
$crawler->filter(".pagination li a")->each(function ($a) use (&$urls) {
// 절대 URL 생성
$url = "https://www.scrapethissite.com" . $a->attr("href");
// 페이징 URL이 아직 목록에 없으면 추가
if (!in_array($url, $urls)) {
$urls[] = $url;
}
});
return $urls;
}getPaginationUrls() 함수는 다음과 같이 호출할 수 있습니다:
$urls = getPaginationUrls($client, "https://www.scrapethissite.com/pages/forms/?page_num=1");실행 후 $urls에는 모든 페이지별 URL이 포함됩니다:
Array
(
[0] => https://www.scrapethissite.com/pages/forms/?page_num=1
[1] => https://www.scrapethissite.com/pages/forms/?page_num=2
[2] => https://www.scrapethissite.com/pages/forms/?page_num=3
[3] => https://www.scrapethissite.com/pages/forms/?page_num=4
[4] => https://www.scrapethissite.com/pages/forms/?page_num=5
[5] => https://www.scrapethissite.com/pages/forms/?page_num=6
[6] => https://www.scrapethissite.com/pages/forms/?page_num=7
[7] => https://www.scrapethissite.com/pages/forms/?page_num=8
[8] => https://www.scrapethissite.com/pages/forms/?page_num=9
[9] => https://www.scrapethissite.com/pages/forms/?page_num=10
[10] => https://www.scrapethissite.com/pages/forms/?page_num=11
[11] => https://www.scrapethissite.com/pages/forms/?page_num=12
[12] => https://www.scrapethissite.com/pages/forms/?page_num=13
[13] => https://www.scrapethissite.com/pages/forms/?page_num=14
[14] => https://www.scrapethissite.com/pages/forms/?page_num=15
[15] => https://www.scrapethissite.com/pages/forms/?page_num=16
[16] => https://www.scrapethissite.com/pages/forms/?page_num=17
[17] => https://www.scrapethissite.com/pages/forms/?page_num=18
[18] => https://www.scrapethissite.com/pages/forms/?page_num=19
[19] => https://www.scrapethissite.com/pages/forms/?page_num=20
[20] => https://www.scrapethissite.com/pages/forms/?page_num=21
[21] => https://www.scrapethissite.com/pages/forms/?page_num=22
[22] => https://www.scrapethissite.com/pages/forms/?page_num=23
[23] => https://www.scrapethissite.com/pages/forms/?page_num=24
)완벽합니다! 방금 Goutte에서 웹 크롤링을 구현했습니다.
7단계: 모든 페이지에서 데이터 스크래핑하기
이제 모든 페이지 URL이 배열에 저장되었으므로, 다음과 같이 하나씩 스크래핑할 수 있습니다:
- 목록을 반복 처리하기
- 각 URL의 HTML 콘텐츠를 가져와 파싱
- 필요한 데이터 추출
- 스크랩된 정보를
$teams배열에 저장합니다.
위 로직을 다음과 같이 구현하세요:
$teams = [];
// 모든 페이지를 반복하며 스크랩
foreach ($urls as $_ => $url) {
// 스크래퍼가 현재 작업 중인 페이지 기록
echo "웹페이지 "$url "$" 스크래핑 중...n";
// 현재 페이지의 HTML 가져와서 파싱
$crawler = $client->request("GET", $url);
// $table = $crawler-> ...
// 데이터 추출 로직
}스크레이퍼가 현재 작업 중인 페이지를 기록하는 echo 명령어에 주목하세요. 이 정보는 스크립트 실행 중 어떤 작업을 수행 중인지 이해하는 데 유용합니다.
훌륭합니다! 이제 스크랩된 데이터를 CSV와 같은 사람이 읽을 수 있는 형식으로 내보내기만 하면 됩니다.
8단계: 스크랩된 데이터를 CSV로 내보내기
현재 스크랩된 데이터는 $teams 배열에 저장되어 있습니다. 다른 팀에서도 접근 가능하고 분석하기 쉽도록 CSV 파일로 내보내세요.
PHP는 fputcsv() 함수를 통해 CSV 내보내기를 기본 지원합니다. 아래와 같이 이 함수를 사용해 스크랩한 데이터를 teams.csv라는 파일로 작성하세요:
// 쓰기 모드로 출력 파일 열기
$file = fopen("teams.csv", "w");
// 헤더 행 작성
fputcsv($file, ["팀명", "연도", "승리", "패배", "연장패", "승률", "득점(GF)", "실점(GA)", "+ / -"]);
// 각 팀을 새 행으로 추가
foreach ($teams as $team) {
fputcsv($file, [
$team["team"],
$team["year"],
$team["wins"],
$team["losses"],
$team["ot_losses"],
$team["win_perc"],
$team["goals_for"],
$team["goals_against"],
$team["goal_diff"]
]);
}
// 파일 닫기
fclose($file);미션 완료! Goutte 스크레이퍼가 완전히 작동합니다.
9단계: 모든 것을 통합하기
이제 Goutte 웹 스크래핑 스크립트에는 다음 내용이 포함되어야 합니다:
<?php
require_once __DIR__ . "/vendor/autoload.php";
use GoutteClient;
function getPaginationUrls($client, $url)
{
// 사이트 첫 페이지에 연결
$crawler = $client->request("GET", $url);
// 현재 URL로 스크래핑할 URL 목록 초기화
$urls = [$url];
// 페이지네이션 링크 요소 선택
$crawler->filter(".pagination li a")->each(function ($a) use (&$urls) {
// 절대 URL 생성
$url = "https://www.scrapethissite.com" . $a->attr("href");
// 페이징 URL이 아직 목록에 없으면 추가
if (!in_array($url, $urls)) {
$urls[] = $url;
}
});
return $urls;
}
// 새로운 Goutte HTTP 클라이언트 초기화
$client = new Client();
// 스크래핑할 페이지 URL 가져오기
$urls = getPaginationUrls($client, "https://www.scrapethissite.com/pages/forms/?page_num=1");
// 스크래핑된 데이터 저장 위치
$teams = [];
// 모든 페이지를 반복하며 스크래핑
foreach ($urls as $_ => $url) {
// 현재 스크래핑 중인 페이지 기록
echo "웹페이지 "$url "$n";
// 현재 페이지 HTML 가져와 파싱
$crawler = $client->request("GET", $url);
// 관심 데이터가 있는 테이블 요소 선택
$table = $crawler->filter("#hockey .table");
// 각 행 반복 처리 및 데이터 추출
$table->filter("tr.team")->each(function ($tr) use (&$teams) {
// 데이터 추출 로직
$teamElement = $tr->filter(".name");
$team = trim($teamElement->text());
$yearElement = $tr->filter(".year");
$year = trim($yearElement->text());
$winsElement = $tr->filter(".wins");
$wins = trim($winsElement->text());
$lossesElement = $tr->filter(".losses");
$losses = trim($lossesElement->text());
$otLossesElement = $tr->filter(".ot-losses");
$otLosses = trim($otLossesElement->text());
$pctElement = $tr->filter(".pct");
$pct = trim($pctElement->text());
$gfElement = $tr->filter(".gf");
$gf = trim($gfElement->text());
$gaElement = $tr->filter(".ga");
$ga = trim($gaElement->text());
$diffElement = $tr->filter(".diff");
$diff = trim($diffElement->text());
// 스크랩한 데이터를 배열에 추가
$teams[] = [
"team" => $team,
"year" => $year,
"wins" => $wins,
"losses" => $losses,
"ot_losses" => $otLosses,
"승률" => $pct,
"득점" => $gf,
"실점" => $ga,
"득실차" => $diff
];
});
}
// 출력 파일 쓰기 모드로 열기
$file = fopen("teams.csv", "w");
// 헤더 행 쓰기
fputcsv($file, ["팀명", "연도", "승리", "패배", "연장전 패배", "승률", "득점 (GF)", "실점 (GA)", "골 득실차"]);
// 각 팀을 새 행으로 추가
foreach ($teams as $team) {
fputcsv($file, [
$team["team"],
$team["year"],
$team["wins"],
$team["losses"],
$team["ot_losses"],
$team["win_perc"],
$team["goals_for"],
$team["goals_against"],
$team["goal_diff"]
]);
}
// 파일 닫기
fclose($file);다음 명령어로 실행하세요:
php index.php스크레이퍼는 다음과 같은 출력을 기록합니다:
웹페이지 "https://www.scrapethissite.com/pages/forms/?page_num=1" 스크래핑 중...
// 생략...
웹페이지 "https://www.scrapethissite.com/pages/forms/?page_num=24" 스크래핑 중...실행이 완료되면 프로젝트 폴더에 이 데이터를 포함한 teams.csv 파일이 생성됩니다:
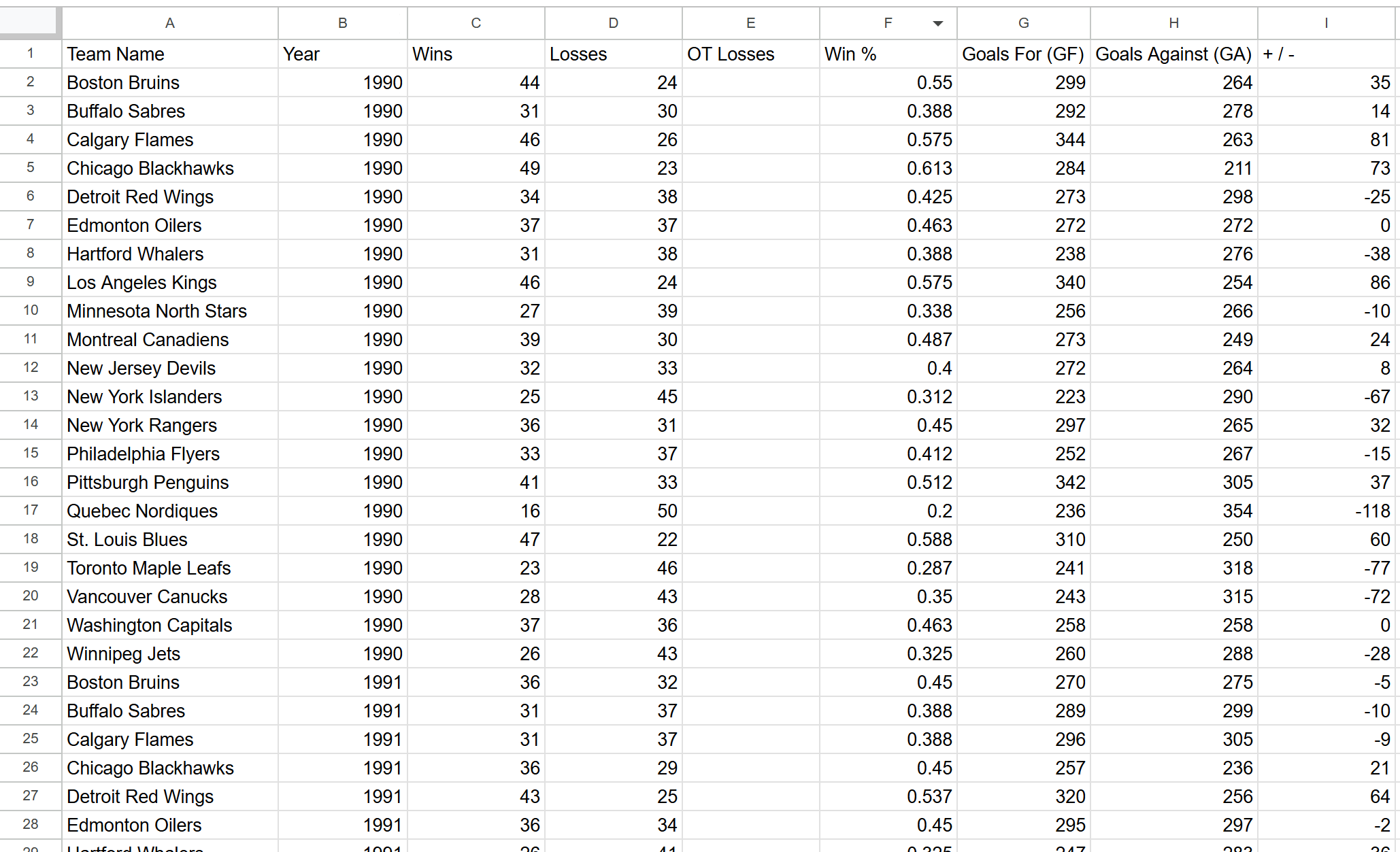
자, 이제 목표 사이트의 정확한 데이터가 구조화된 형식으로 이용 가능합니다.
웹 스크래핑을 위한 PHP Goutte 라이브러리 대체 솔루션
본문 초반에 언급했듯이 Goutte는 더 이상 유지보수되지 않는 구식 라이브러리입니다. 따라서 대체 솔루션을 고려해야 합니다.
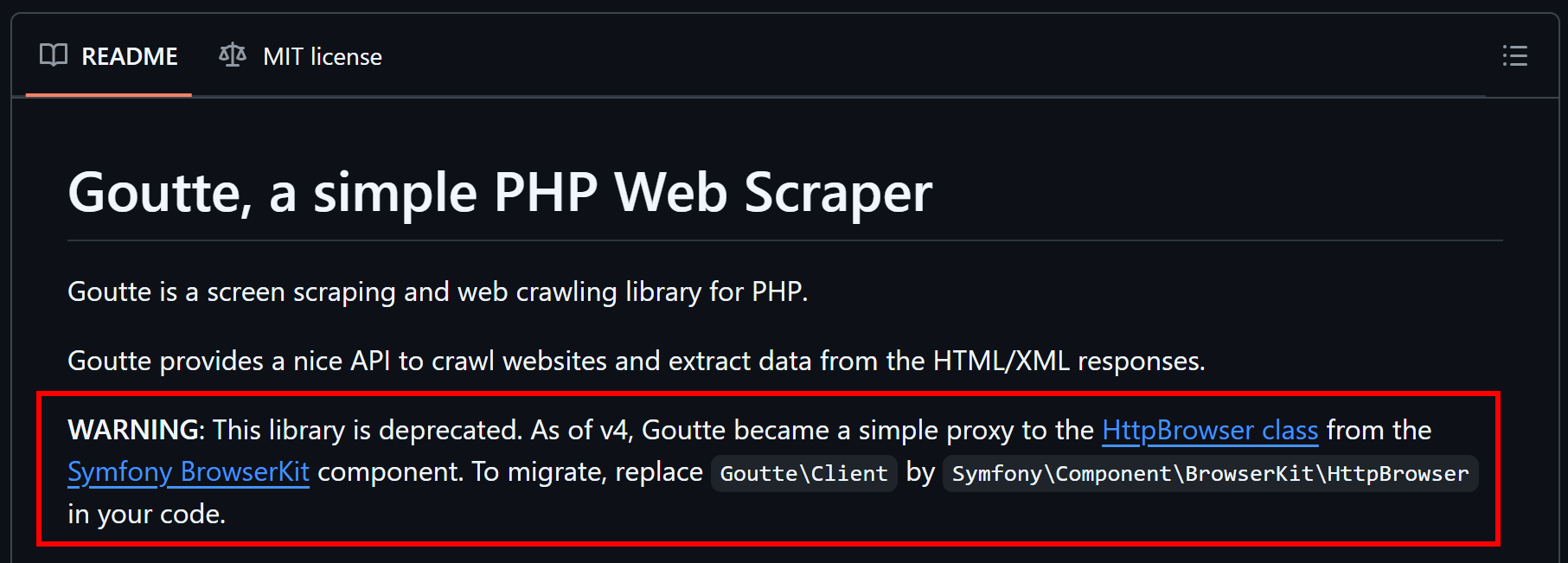
GitHub에서 설명한 바와 같이, Goutte v4는 본질적으로 Symfony의 HttpBrowser 클래스를 위한 프록시 역할을 하게 되었으므로, 해당 클래스로 마이그레이션해야 합니다. 이를 위해 다음 라이브러리를 설치하기만 하면 됩니다:
composer require symfony/browser-kit symfony/http-client그런 다음 다음을 교체하세요:
use GoutteClient;다음과 같이 변경하십시오:
use SymfonyComponentBrowserKitHttpBrowser;마지막으로 프로젝트에서 Goutte 의존성을 제거하세요. 기본 API는 동일하므로 스크립트에서 크게 변경할 필요는 없습니다.
Goutte 대신 HTTP 클라이언트와 HTML 파서를 결합하는 방법도 있습니다. 추천 대안:
- HTTP 요청을 위한 Guzzle 또는 cURL.
- PHP에서 HTML 파싱을 위한
DomHTMLDocument, Simple HTML DOM Parser 또는DomCrawler.
이러한 대안들은 더 많은 유연성을 제공하며, 장기적으로 웹 스크래핑 스크립트의 유지보수성을 보장합니다.
이 웹 스크래핑 접근법의 한계
Goutte는 강력한 도구이지만, 웹 스크래핑에 사용할 경우 다음과 같은 몇 가지 한계가 있습니다:
- 라이브러리가 더 이상 지원되지 않음
- API가 더 이상 유지 관리되지 않음
- 속도 제한 및 스크래핑 차단에 취약합니다
- 자바스크립트에 의존하는 동적 페이지를 처리할 수 없습니다
- IP 차단 회피에 필수적인 내장 프록시 지원이 제한적입니다
이러한 제한 사항 중 일부는 PHP를 활용한 웹 스크래핑 가이드에서 다루는 대체 라이브러리나 다른 접근법을 사용해 완화할 수 있습니다. 그러나 웹 언락커 API를 통해서만 우회 가능한 스크래핑 방지 조치에는 항상 직면하게 됩니다.
웹 언락커 API는 반봇 보호 기능을 우회하고 모든 웹페이지의 원시 HTML을 가져오도록 설계된 특수 스크래핑 엔드포인트입니다. 사용법은 API 호출을 수행하고 반환된 콘텐츠를 파싱하는 것만큼 간단합니다. 이 접근 방식은 본 문서에서 시연한 바와 같이 Goutte(또는 Symfony의 업데이트된 컴포넌트)와 완벽하게 통합됩니다.
결론
이 가이드에서는 단계별 튜토리얼을 통해 Goutte가 무엇이며 웹 스크래핑에 어떤 기능을 제공하는지 살펴보았습니다. 이 라이브러리가 이제 사용 중단되었으므로, 그 대안 중 일부도 살펴볼 기회가 있었습니다.
어떤 PHP 스크래핑 라이브러리를 선택하든 가장 큰 도전 과제는 대부분의 웹사이트가 봇 방지 및 스크래핑 방지 기술로 데이터를 보호한다는 점입니다. 이러한 메커니즘은 자동화된 요청을 탐지하고 차단하여 기존 스크래핑 방법을 무력화시킵니다.
다행히 Bright Data는 모든 문제를 해결할 수 있는 솔루션 제품군을 제공합니다:
- 웹 언락커(WebUnlocker): 안티 스크래핑 보호 기능을 우회하여 최소한의 노력으로 모든 웹페이지의 깨끗한 HTML을 제공하는 API입니다.
- 스크래핑 브라우저: 자바스크립트 렌더링이 가능한 클라우드 기반 제어형 브라우저입니다. CAPTCHA, 브라우저 지문 인식, 재시도 등을 자동으로 처리해 줍니다. Panther 또는 Selenium PHP와 원활하게 통합됩니다.
- 웹 스크래핑 API: 수십 개의 인기 도메인에서 구조화된 웹 데이터에 프로그래밍 방식으로 접근할 수 있는 엔드포인트입니다.
웹 스크래핑은 다루기 싫지만 ‘온라인 웹 데이터’에는 관심이 있으신가요? 바로 사용 가능한 데이터셋을 살펴보세요!
지금 Bright Data에 가입하고 무료 체험을 시작하여 스크래핑 솔루션을 테스트해 보세요.