

이 글에서 여러분은 다음을 배우게 됩니다:
- Azure Synapse Analytics의 정의와 제공 기능
- Azure Synapse Analytics에서 Bright Data의 SERP API를 통합하는 것이 효과적인 전략인 이유.
- Bright Data의 SERP API를 활용하여 웹 검색 데이터를 수집, 변환, 분석하는 Azure Synapse 파이프라인 구축 방법.
자, 시작해 보겠습니다!
Azure Synapse Analytics란 무엇인가요?
Azure Synapse Analytics는 데이터 통합, 엔터프라이즈 데이터 웨어하우징 및 빅 데이터 처리를 단일 작업 공간에서 통합하는 클라우드 기반 분석 플랫폼입니다. 파이프라인 오케스트레이션, Apache Spark 풀, 전용 및 서버리스 SQL 풀을 제공하여 단일 통합 환경에서 대규모로 데이터를 수집, 변환 및 쿼리할 수 있게 해줍니다.
주요 목표는 원시 데이터에서 비즈니스 인사이트로 전환하는 데 도움을 주는 것입니다. 이는 데이터 수집을 위한 파이프라인 엔진(Azure Data Factory 기반), 코드 기반 변환을 위한 Apache Spark 노트북, 쿼리 및 대시보드, ML 모델, 다운스트림 애플리케이션에 분석 준비가 된 데이터셋 제공을 위한 SQL 풀을 결합하여 달성됩니다.
Azure Synapse Analytics와 Azure AI Foundry의 차이점은 무엇인가요?
SERP API와 Azure AI Foundry 통합 가이드를 이미 읽으셨다면, Synapse Analytics가 어떻게 다른지 궁금하실 수 있습니다. 두 서비스는 근본적으로 다른 목적을 제공합니다:
- Azure AI Foundry는 AI 애플리케이션, 에이전트, 프롬프트 흐름 구축·배포·관리를 위한 통합 AI 개발 플랫폼입니다. Azure OpenAI, Meta, Mistral 등 다양한 대규모 언어 모델(LLM) 카탈로그에 접근할 수 있으며, 프롬프트 엔지니어링, 모델 미세 조정, RAG 워크플로를 포함한 AI 중심 개발을 위해 설계되었습니다.
- Azure Synapse Analytics는 대량의 데이터 수집, 복잡한 변환 실행, 대규모 구조화된 분석 제공에 중점을 둔 데이터 분석 및 웨어하우징 플랫폼입니다. ETL/ELT 파이프라인, Spark를 활용한 빅데이터 처리, SQL 기반 비즈니스 인텔리전스 분야에서 탁월합니다.
간단히 말해, Azure AI Foundry는 AI 기반 애플리케이션과 프롬프트 흐름을 구축하는 곳이며, Azure Synapse Analytics는 분석 및 보고를 위해 데이터를 수집, 변환, 저장하는 데이터 파이프라인을 구축하는 곳입니다.
두 플랫폼은 실제로 완벽하게 상호 보완합니다. Synapse를 활용해 대규모 웹 데이터 수집 및 저장소 구축이라는 데이터 기반을 마련한 후, 이를 AI Foundry에 공급하여 LLM 기반 분석을 수행할 수 있습니다. 본 튜토리얼에서는 Synapse Analytics가 Bright Data의 SERP API와 통합되어 검색 결과를 수집하고 Spark로 변환하며 SQL을 통해 분석을 제공하는 완전한 웹 데이터 파이프라인 구축 방식을 살펴봅니다.
Bright Data의 SERP API를 Azure Synapse Analytics에 통합해야 하는 이유
Azure Synapse Analytics는 파이프라인 엔진에 강력한 REST 커넥터를 제공하여 모든 REST API를 호출하고 결과를 Azure Data Lake Storage에 직접 저장할 수 있게 합니다. 이는 외부 데이터 소스를 분석 워크플로에 통합할 수 있는 길을 열어줍니다. 그러나 데이터 웨어하우스에 실시간 웹 검색 데이터를 주입하려면 안정적이고 확장 가능하며 구조화된 데이터 소스가 필요합니다.
이때 Bright Data의 SERP API가 해결책이 됩니다. SERP API를 사용하면 Google, Bing, DuckDuckGo, Yandex 등 검색 엔진에서 프로그래밍 방식으로 쿼리를 검색하고 전체 SERP 콘텐츠를 가져올 수 있습니다. 이 API는 파싱된 JSON, 원시 HTML, AI 활용 가능한 마크다운 등 다양한 형식으로 데이터를 반환하여 검증 가능한 최신 데이터의 안정적인 공급원을 제공합니다.
이 접근 방식은 특히 다음에 유용합니다:
- SEO 키워드 추적 파이프라인: 수천 개의 키워드에 대한 검색 순위를 매일 모니터링하고 시간 경과에 따른 트렌드를 파악합니다.
- 경쟁사 인텔리전스 저장소: 경쟁사 가시성 데이터를 수집하고 내부 지표와 결합하여 전략적 분석을 수행합니다.
- 산업, 지역, 기간별 검색 결과 트렌드를 집계하여 대규모 보고서를 작성하는시장 조사 데이터셋.
- 콘텐츠 성과 분석: 타깃 키워드에 대한 콘텐츠 순위를 추적하고 SEO 노력의 효과를 측정합니다.
Azure Synapse의 파이프라인 오케스트레이션 및 데이터 웨어하우징 기능과 Bright Data의 SERP API를 결합하면 스크래핑 인프라를 유지 관리할 필요 없이 대규모로 웹 검색 데이터를 지속적으로 수집, 변환 및 분석하는 데이터 파이프라인을 구축할 수 있습니다.
Bright Data를 사용하여 Azure Synapse에서 SERP 데이터 파이프라인 구축 방법
이 가이드 섹션에서는 일일 키워드 순위 추적기의 일환으로 Bright Data의 SERP API를 Azure Synapse 파이프라인에 통합하는 방법을 살펴봅니다. 이 파이프라인은 다섯 가지 주요 단계로 구성됩니다:
- 워크스페이스 설정: 연결된 Data Lake Storage 계정이 있는 Azure Synapse 워크스페이스를 생성합니다.
- 데이터 소스 구성: 보안 자격 증명 저장소와 함께 Bright Data의 SERP API를 가리키는 REST 링크된 서비스를 생성합니다.
- 인제스트 파이프라인: Synapse 파이프라인이 추적 대상 키워드 세트에 대해 SERP API를 호출하고 원시 JSON 결과를 데이터 레이크에 저장합니다.
- Spark 변환: Apache Spark 노트북이 원시 SERP 데이터를 평탄화하고 정규화하여 분석 준비가 완료된 Delta 테이블로 변환합니다.
- SQL 분석: 서버리스 SQL 쿼리로 순위 추세를 분석하고, Power BI 대시보드를 위한 뷰를 생성합니다.
참고: 이는 예시일 뿐이며, SERP API는 다양한 시나리오와 사용 사례에서 활용할 수 있습니다. 예를 들어 경쟁사 가격 모니터링 파이프라인 구축이나 머신러닝 모델에 SERP 데이터 공급 등이 가능합니다.
아래 지침에 따라 Azure Synapse Analytics 내에서 Bright Data의 SERP API로 구동되는 웹 데이터 파이프라인을 구축하세요!
필수 구성 요소
이 튜토리얼 섹션을 따라하려면 다음이 준비되어 있어야 합니다:
- Microsoft 계정
- Azure 구독(무료 체험판으로도 충분합니다).
- 활성 SERP API 영역과 API 키(관리자 권한 포함)가 있는 Bright Data 계정.
공식 Bright Data 문서를 따라 SERP API 영역을 설정하고 API 키를 발급받으세요. API 키와 영역 이름은 곧 필요하므로 안전한 곳에 보관하십시오.
1단계: Azure Synapse 워크스페이스 생성
Azure Synapse 파이프라인은 Synapse 작업 영역 내에서만 사용할 수 있으므로, 첫 번째 단계는 작업 영역을 생성하는 것입니다.
Azure 계정에 로그인한 후 Azure Portal 상단 검색창에서 ‘Azure Synapse Analytics’를 검색하세요:
Synapse Analytics 관리 페이지에서 ‘Create(만들기)’를 클릭하세요. 생성 양식을 작성하세요:
- Azure 구독을 선택하세요.
- 기존 리소스 그룹을 선택하거나 새 리소스 그룹을 생성합니다.
- 워크스페이스에 이름을 지정합니다(예:
bright-data-serp-pipeline). - 가까운 지역을 선택하세요.
- Data Lake Storage Gen2의 경우 새로 만들기를 선택하고 스토리지 계정 이름을 입력하세요(모두 소문자, 3~24자, 전역적으로 고유해야 함, 예:
serppipelinelake).raw라는새 파일 시스템을 만드세요.
검토 + 생성을 클릭한 다음 생성을 클릭하여 배포를 시작하세요.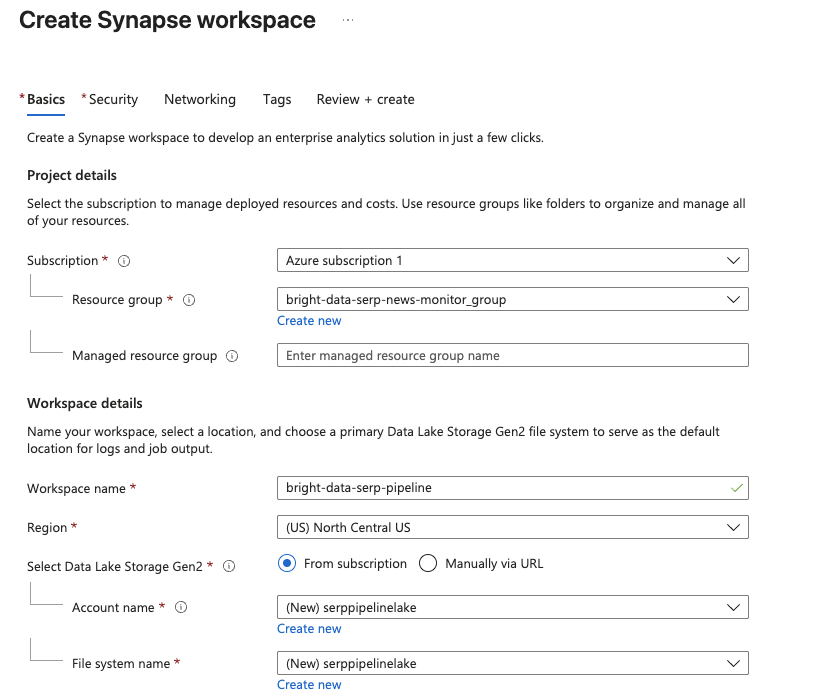
초기화 프로세스는 몇 분 정도 소요될 수 있습니다. 완료되면 확인 페이지가 표시됩니다. ‘리소스로 이동’을 클릭한 후 ‘Synapse Studio 열기’를 클릭하여 웹 기반 개발 환경을 실행합니다.
이제 파이프라인 구축, Spark 노트북 작성, SQL 쿼리 실행이 가능한 Synapse 작업 공간이 생성되었습니다.
2단계: Apache Spark 풀 생성
이 튜토리얼 후반부에 변환 노트북을 실행하려면 작업 공간에 Apache Spark 풀이 필요합니다.
- Synapse Studio에서 관리 > Apache Spark 풀 > 새로 만들기로 이동합니다.
- 풀에
sparkpool과같은 이름을 지정합니다. - 노드 크기를 Small (4 vCores / 32 GB)로 설정하세요. SERP 데이터 변환에는 이 정도면 충분합니다.
- 자동 확장 기능을 활성화하고 범위를 3~5개 노드로 설정합니다.
- 검토 + 생성, 생성 순으로 클릭합니다.
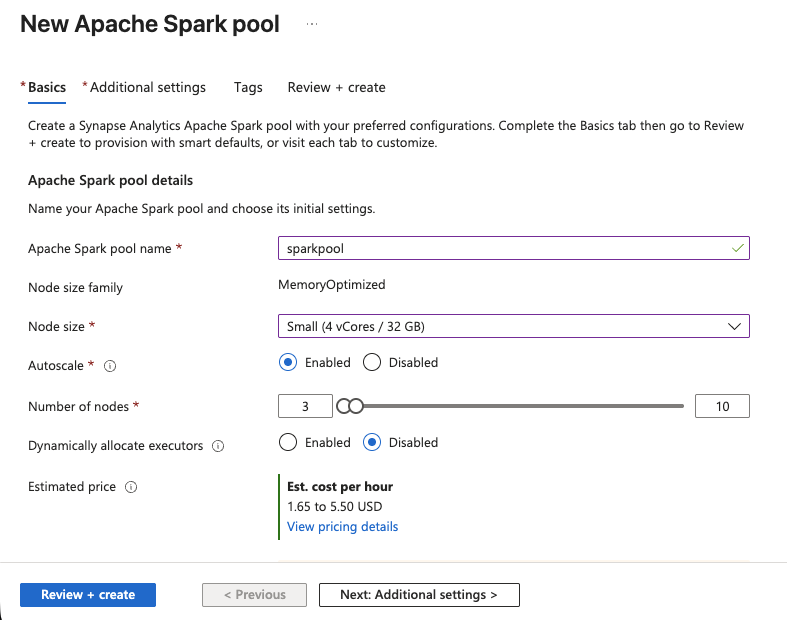
Spark 풀이 잠시 후 준비됩니다. 이제 PySpark 노트북을 실행할 컴퓨팅 성능이 확보되었습니다.
3단계: 수집 파이프라인 구축
이제 추적된 키워드 세트를 위해 Bright Data의 SERP API를 호출하고 결과를 데이터 레이크에 저장하는 Synapse 파이프라인을 생성합니다.
새 파이프라인 만들기
- 통합 > + > 파이프라인으로 이동합니다.
IngestSERPData라는이름을 지정합니다.
파이프라인 매개변수 추가
파이프라인 캔버스 배경을 클릭하여 파이프라인 속성을 엽니다. 매개변수 탭으로 이동하여 다음을 추가합니다:
| 이름 | 유형 | 기본값 |
|---|---|---|
키워드 |
배열 | ["웹 스크래핑 도구", "프록시 서비스", "데이터 추출 API"] |
이들은 순위를 추적하려는 키워드입니다. 이 목록은 언제든지 수정할 수 있습니다.
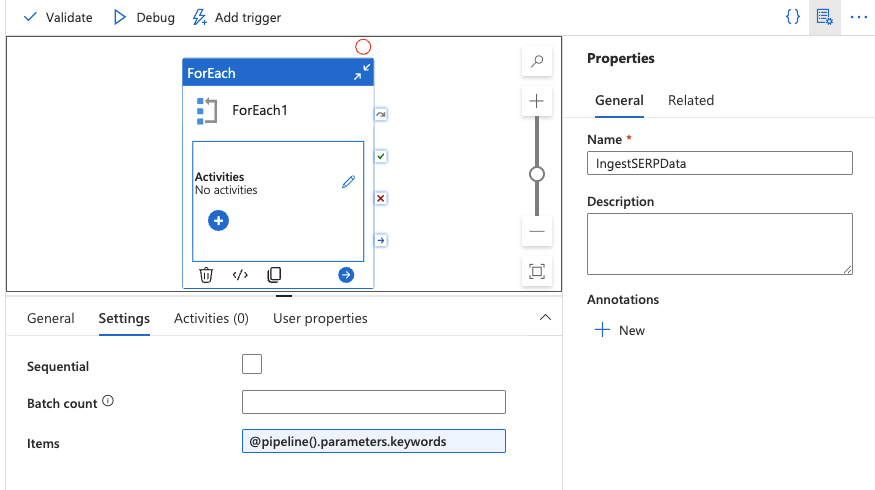
ForEach 활동 추가
- 활동 패널에서 ForEach 활동을 캔버스로 드래그합니다.
- 설정 탭에서 항목 필드를
@pipeline().parameters.keywords로설정합니다.
이렇게 하면 배열의 각 키워드를 반복 처리합니다.
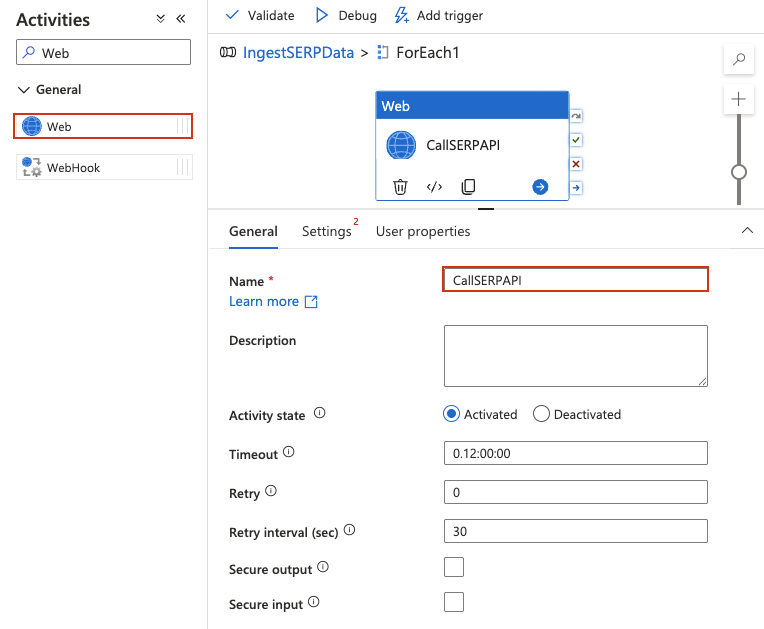
ForEach 내부에서 Web 활동 추가
웹 활동은 REST API를 직접 호출하므로 요청 자체에 데이터 세트나 연결된 서비스가 필요하지 않습니다.
- ForEach 활동을두 번 클릭하여 내부 캔버스를 엽니다. 디자이너 헤더가 ForEach 범위 내(
IngestSERPData > ForEach1과같은 브레드크럼 형태)임을 나타내도록 변경된 것을 확인할 수 있습니다. - 왼쪽의 활동 패널에서 일반을 확장하고 웹 활동을 내부 캔버스로 드래그합니다.
CallSERPAPI와같은 이름을 지정합니다.
웹 액티비티 구성
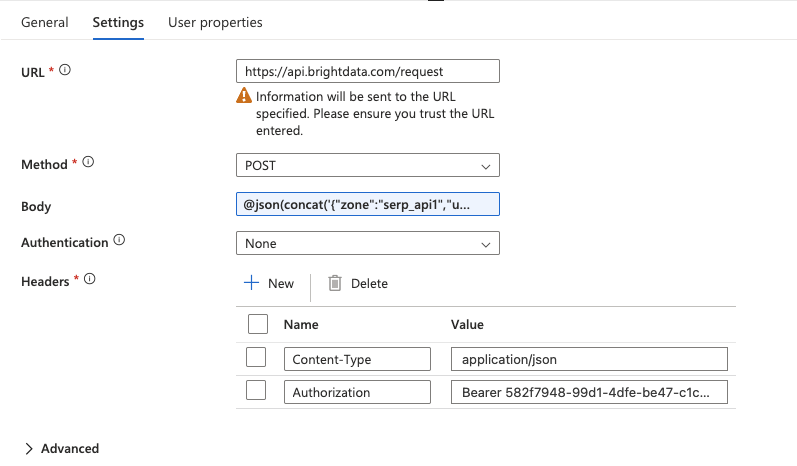
웹 액티비티를 클릭하여 선택한 후 설정 탭으로 이동하여 구성합니다:
- URL: 필드에 전체 API 엔드포인트를 직접 입력하세요:
https://api.brightdata.com/request- 메서드: 드롭다운에서
POST를선택하세요. - 헤더: + 추가 헤더를 두 번 클릭하여 다음을 추가합니다: 이름 값
Content-Typeapplication/jsonAuthorizationBearer YOUR_BRIGHT_DATA_API_KEY - 본문: ForEach 루프에서 현재 키워드와 함께 SERP API 요청을 전달하는 부분입니다. 본문 필드에 다음 표현식을 직접 입력하세요(“동적 콘텐츠 추가” 팝업 사용 금지):
@concat('{"zone":"YOUR_SERP_API_ZONE","url":"https://www.google.com/search?q=',replace(item(),' ','+'),'&hl=en&gl=us","format":"raw","data_format":"json"}')YOUR_SERP_API_ZONE을 Bright Data 대시보드의 실제 존 이름으로 교체하세요.
중요: 필드 첫 번째
문자는 반드시 @이어야 하며, 선행 공백이 없어야 합니다. 이는 Synapse가 텍스트를 표현식으로 평가하도록 지시합니다. 올바르게 입력하면 필드가 표현식으로 강조 표시됩니다. 일반 텍스트로 표시되면 삭제 후 재입력하며,@가제로 위치에 있는지 확인하십시오.이 코드의 역할:
item()함수는 ForEach 루프의 현재 키워드(예:"웹 스크래핑 도구")를 반환합니다.replace()함수는 공백을+문자로 대체하여 유효한 URL 쿼리 매개변수를 생성합니다.concat()함수는 전체 JSON 요청 본문을 단일 문자열로 구성합니다.
- 인증:
None으로 설정 (인증은 이미 Authorization 헤더를 통해 처리됨).
스케줄 트리거 추가
- 메인 파이프라인 캔버스로 돌아가서 트리거 추가 > 새로 만들기/편집을 클릭합니다.
- 새로 만들기를 선택하고 매일 반복 (예: 오전 6:00 UTC)으로 설정합니다.
- 확인을 클릭한 후 모두 게시를 클릭하여 파이프라인을 저장하고 배포합니다.
즉시 테스트하려면 지금 트리거 > 확인을 클릭합니다. 모니터 > 파이프라인 실행으로 이동하여 실행을 확인합니다. 파이프라인이 성공적으로 완료되고 데이터 레이크의 raw/serp/ 경로 아래에 JSON 파일이 생성된 것을 확인할 수 있습니다.
메인 파이프라인 캔버스로 돌아가기
디자이너 상단의 브레드크럼에서 파이프라인 이름(IngestSERPData)을 클릭하여 메인 캔버스로 돌아갑니다. 자식 활동이 포함되어 있음을 나타내는 표시기가 있는 ForEach 활동이 표시되어야 합니다.
스케줄 트리거 추가
- 파이프라인 디자이너 상단의 트리거 추가 > 새로 만들기/편집을 클릭합니다.
- 드롭다운에서 새 항목을 선택합니다.
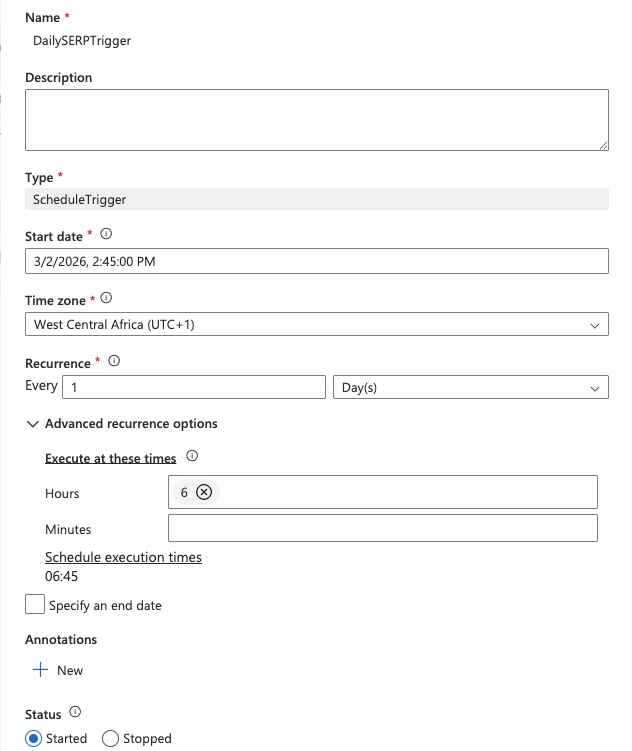
- 트리거에 이름을 지정하고(예:
DailySERPTrigger), 유형 을 스케줄로 설정한 후 다음을 구성합니다.
- 시작 날짜: 오늘 날짜
- 반복 주기:
매일 - 시간:
6(UTC 기준 오전 6시)
- 확인 버튼을 클릭한 후 트리거 매개변수를 확인하세요.
- Synapse Studio 상단의 ‘모두 게시’를 클릭하여 모든 내용을 저장하고 배포합니다.
파이프라인 테스트
예약된 트리거를 기다리지 않고 즉시 파이프라인을 실행하려면:
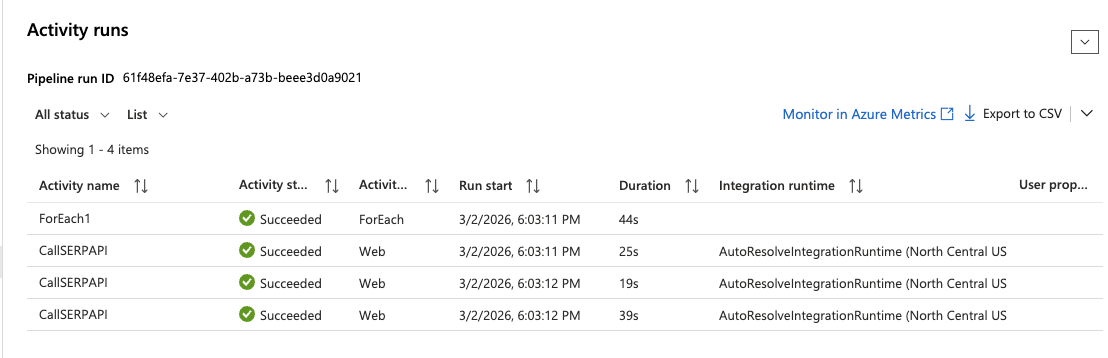
- 파이프라인 디자이너 상단의 지금 트리거 > 확인을 클릭합니다.
- 왼쪽 메뉴에서 모니터 > 파이프라인 실행 으로 이동합니다.
- 런이 완료될 때까지 기다리면 녹색 ‘성공’ 상태가 표시됩니다.
- 실행 항목을 클릭하고 ForEach 활동을 확장하여 각 웹 활동 실행을 확인합니다.
CallSERPAPI반복 항목을 클릭하면 출력 섹션에서 전체 API 응답을 볼 수 있습니다.
4단계: Apache Spark를 사용한 데이터 수집 및 변환
3단계의 웹 활동은 SERP API 통합이 작동함을 검증하고 스케줄링을 통한 파이프라인 오케스트레이션을 시연했습니다. 데이터 수집 및 변환 단계에서는 Python을 사용하여 SERP API를 직접 호출하고, 원시 응답을 데이터 레이크에 저장한 후 분석 준비가 된 Delta 테이블로 변환하는 Apache Spark 노트북을 사용합니다.
이 접근 방식은 데이터 엔지니어링에서 표준으로, 파이프라인이 오케스트레이션과 스케줄링을 처리하는 반면 노트북은 실제 데이터 처리 로직을 처리합니다.
Spark 노트북 생성
- 개발 > + > 노트북으로 이동합니다.
- 이름을
TransformSERPData로지정합니다. sparkpoolApache Spark 풀에 연결합니다.- 언어로 PySpark(Python) 이 선택되어 있는지 확인합니다.
셀 1: SERP 데이터 수집 및 데이터 레이크 저장
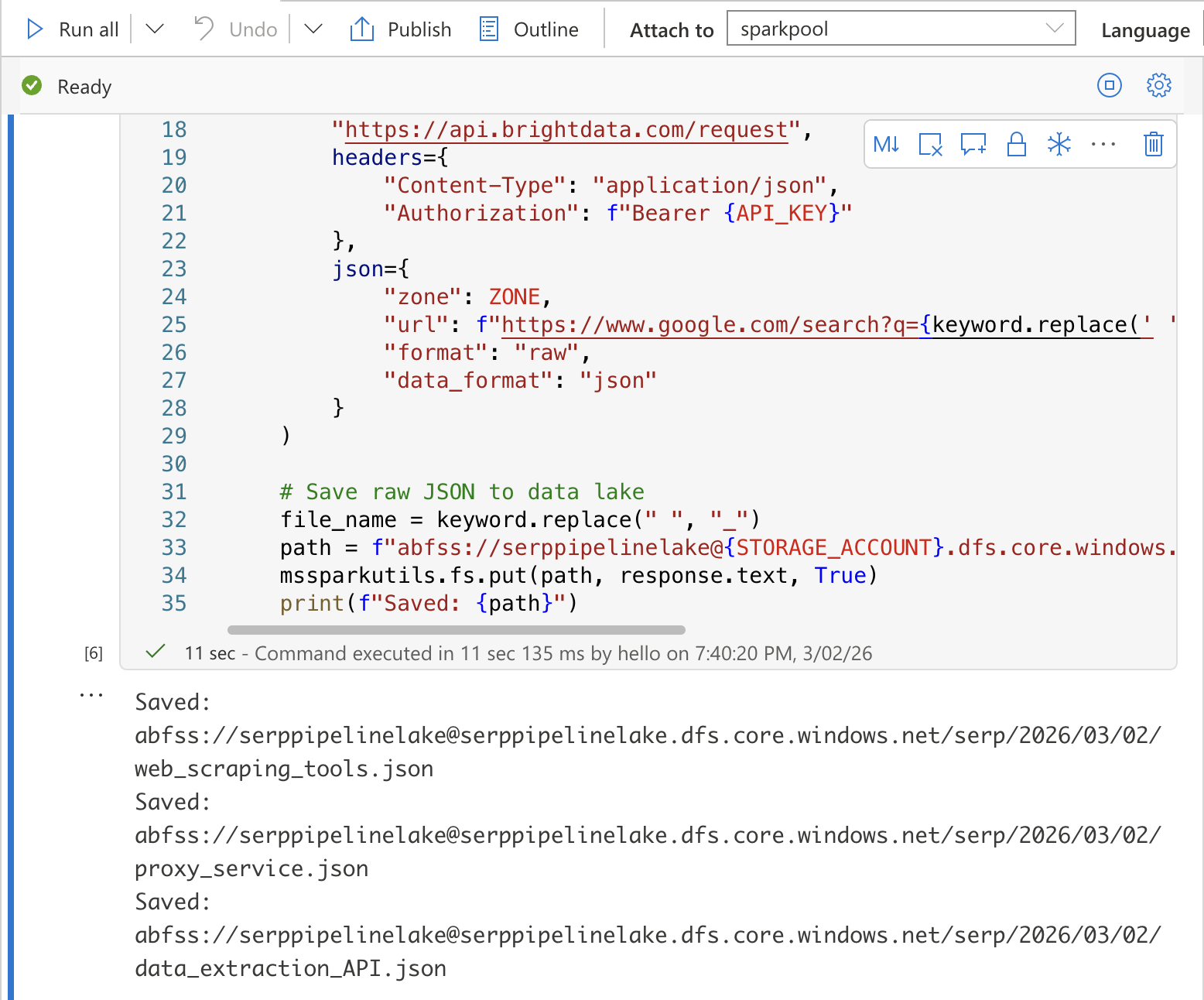
첫 번째 셀에 다음 코드를 추가합니다. 각 키워드에 대해 Bright Data SERP API를 호출하고 원시 JSON 응답을 데이터 레이크에 저장합니다:
import requests
import json
from datetime import datetime
from notebookutils import mssparkutils
# 구성
API_KEY = "YOUR_BRIGHT_DATA_API_KEY"
ZONE = "YOUR_SERP_API_ZONE"
STORAGE_ACCOUNT = "YOUR_STORAGE_ACCOUNT"
import requests
import json
from datetime import datetime
from notebookutils import mssparkutils
# 각 키워드별 SERP 데이터 수집
today = datetime.utcnow().strftime("%Y/%m/%d")
for keyword in KEYWORDS:
# Bright Data SERP API 호출
response = requests.post(
"https://api.brightdata.com/request",
headers={
"Content-Type": "application/json",
"Authorization": f"Bearer {API_KEY}"
},
json={
"zone": ZONE,
"url": f"abfss://[email protected]/serp/{today}/{file_name}.json"
}
)
# 원시 JSON을 데이터 레이크에 저장
file_name = keyword.replace(" ", "_")
path = f"abfss://raw@{STORAGE_ACCOUNT}.dfs.core.windows.net/serp/{today}/{file_name}.json"
mssparkutils.fs.put(path, response.text, True)
print(f"저장됨: {path}")YOUR_BRIGHT_DATA_API_KEY, YOUR_SERP_API_ZONE, YOUR_STORAGE_ACCOUNT를 실제 값으로 대체하세요.
보안 팁: 실제 운영 환경에서는 API 키를 Azure Key Vault에 저장하고, 하드코딩 대신
mssparkutils.credentials.getSecret("your-keyvault-name", "BRIGHT_DATA_API_KEY")를 사용하여 가져오세요.
Shift + Enter를 눌러 셀을 실행하세요. 각 파일이 데이터 레이크에 저장되었음을 확인하는 출력이 표시됩니다.
셀 2: SERP 데이터 변환 및 평탄화
새 셀에 원시 JSON을 읽고 구조화된 테이블로 평탄화하는 변환 코드를 추가하세요:
from pyspark.sql.functions import explode, col, current_timestamp
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, ArrayType
# 데이터 레이크에서 원시 SERP 데이터 읽기
serp_raw = spark.read.option("multiline", "true").json(
f"abfss://serppipelinelake@{STORAGE_ACCOUNT}.dfs.core.windows.net/serp/{today}/*.json")
# 평탄화: general.query에서 키워드 추출 및 유기적 결과 폭발
serp_flattened = serp_raw.select(
col("general.query").alias("keyword"),
col("general.language").alias("language"),
col("general.location").alias("location"),
explode(col("organic")).alias("result")
).select(
"keyword",
"language",
"location",
col("result.rank").cast("int").alias("rank"),
col("result.title").alias("title"),
col("result.link").alias("url"),
col("result.source").alias("source"),
col("result.description").alias("snippet"),
current_timestamp().alias("collected_at"))
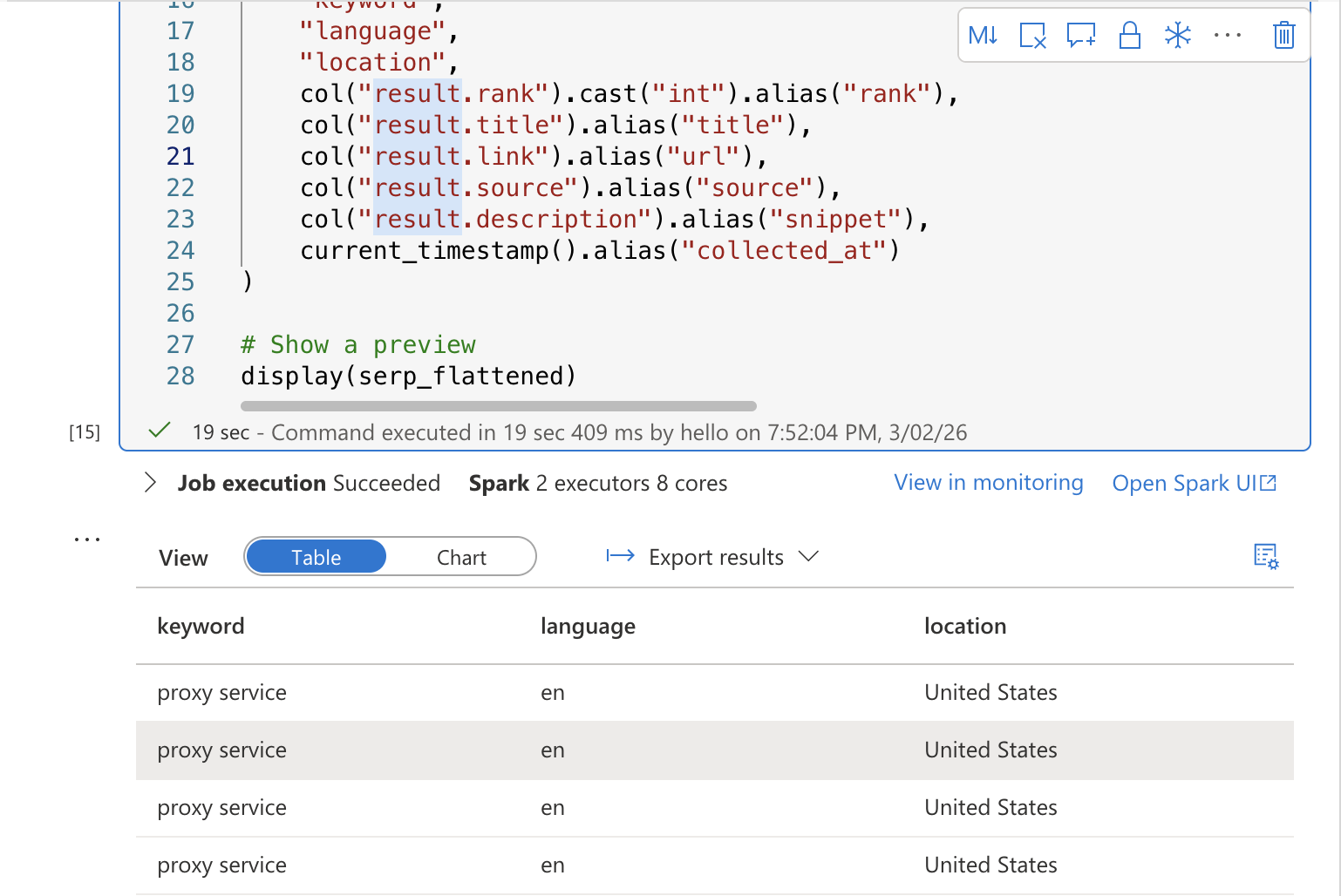
# 미리보기 표시
display(serp_flattened)셀 실행. 키워드, 순위, 제목, URL, 스니펫, 수집 타임스탬프 열이 포함된 평탄화된 SERP 결과 미리보기 테이블이 표시됩니다.
셀 3: 델타 테이블에 저장
세 번째 셀에서 변환된 데이터를 SQL 분석을 위한 Delta 테이블에 작성합니다:
# 변환된 데이터를 델타 테이블로 데이터 레이크에 저장
serp_flattened.write.format("delta").mode("append").save(
f"abfss://[email protected]/curated/serp_rankings"
)
print("curated/serp_rankings에 데이터 작성 완료") 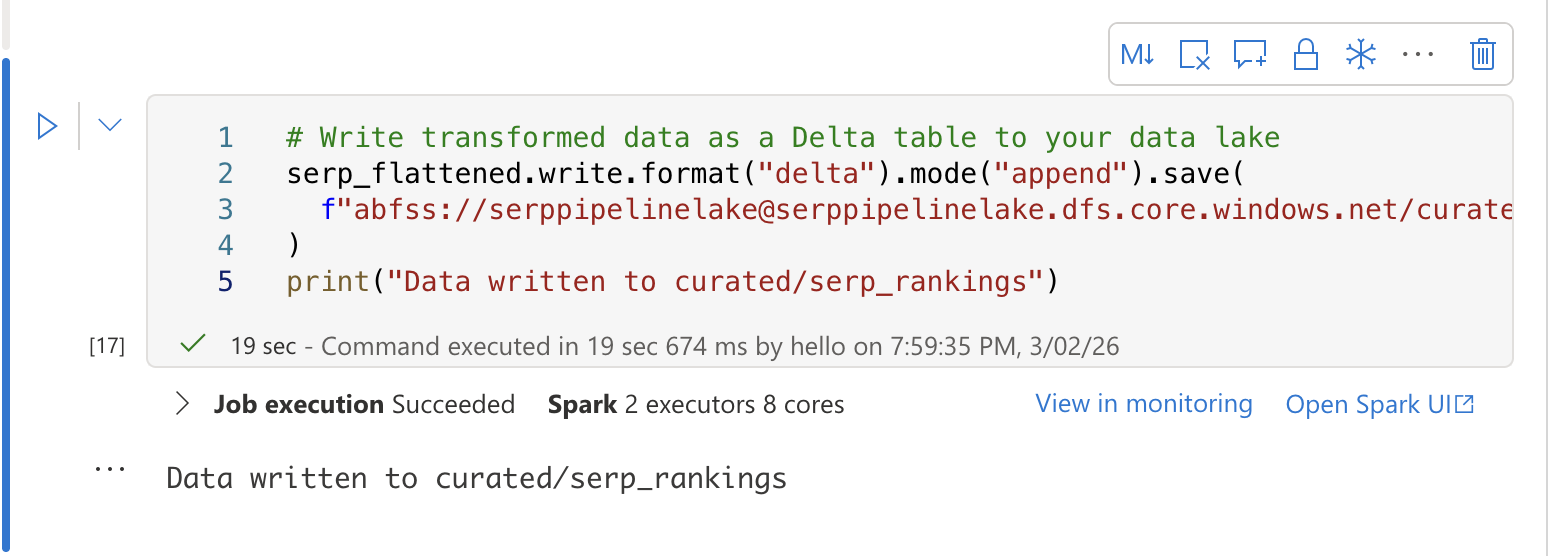
파이프라인에 노트북 추가
- 통합 허브에서
IngestSERPData파이프라인으로 돌아갑니다. - 노트북 활동을 캔버스에 끌어다 놓으세요. ForEach 활동 바깥쪽, 그 뒤에 위치시켜야 합니다.
- 설정 탭에서
TransformSERPData노트북을 선택하고sparkpool에 연결합니다. - 성공 종속성(녹색 화살표 드래그)으로 ForEach 활동을 Notebook 활동에 연결합니다.
- 저장을 위해 모두 게시를 클릭하세요.
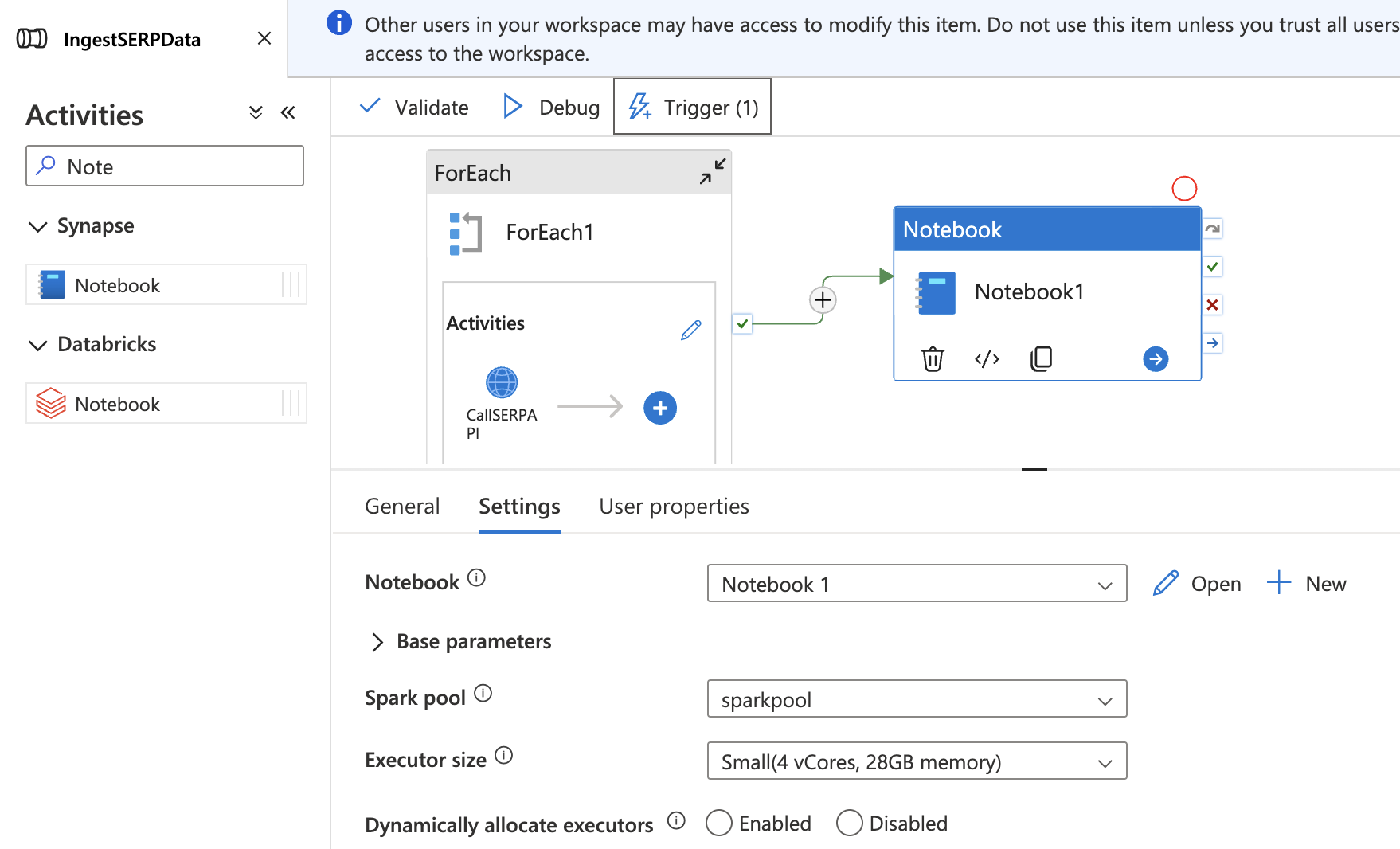
이제 전체 파이프라인이 종단 간 실행됩니다: SERP 데이터 수집 → 데이터 레이크에 저장 → Delta 테이블로 변환.
5단계: SQL로 순위 분석하기
데이터가 Delta 테이블에 저장되면 추가 프로비저닝 없이 Synapse의 서버리스 SQL 풀을 사용하여 직접 쿼리할 수 있습니다. 서버리스 SQL 풀은 OPENROWSET 함수를 사용하여 데이터 레이크에서 Delta 파일을 직접 읽습니다.
데이터베이스 생성
개발 > + > SQL 스크립트로 이동합니다. 스크립트 편집기 상단에서 SQL 풀로 ‘내장 (서버리스)’이 선택되었는지 확인하세요. SERP 분석 전용 데이터베이스를 생성하려면 다음을 실행하세요:
CREATE DATABASE serp_analytics;데이터베이스 생성 후 스크립트 편집기 상단의 데이터베이스 드롭다운에서 serp_analytics를 선택하여 전환합니다.
시간 경과에 따른 순위 변화 추적
새 SQL 스크립트를 생성하거나(기존 스크립트를 지운 후) 다음 쿼리를 실행합니다. OPENROWSET을 사용하여 데이터 레이크에서 델타 테이블을 직접 읽습니다:
-- 키워드 및 URL별 일별 순위 변동 확인
SELECT
keyword,
url,
rank,
collected_at,
rank - LAG(rank) OVER (PARTITION BY keyword, url ORDER BY collected_at) AS rank_change
FROM OPENROWSET(
BULK 'abfss://[email protected]/curated/serp_rankings/',
FORMAT = 'DELTA')
AS serp_rankings
WHERE keyword = '웹 스크래핑 도구'
ORDER BY collected_at DESC, rank ASC;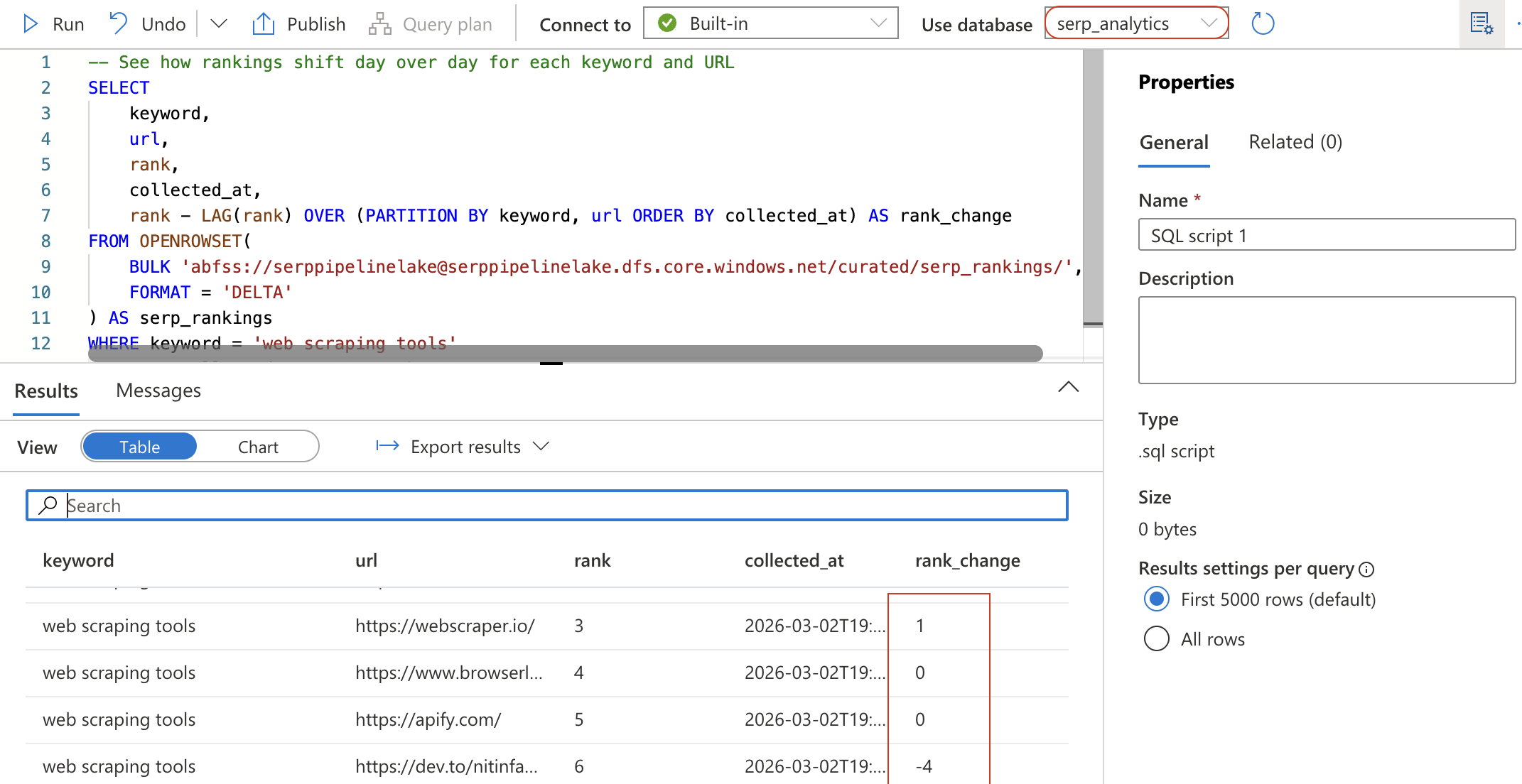
이 쿼리는 LAG 윈도우 함수를 사용하여 각 URL의 순위가 이전 수집 이후 어떻게 변동했는지 계산합니다. 음수 rank_change 값은 URL의 순위가 상승했음을 의미합니다.
Power BI용 요약 뷰 생성
Power BI에서 데이터를 쉽게 활용할 수 있도록 키워드별 일일 순위를 요약하는 뷰를 생성합니다:
CREATE VIEW daily_serp_summary AS
SELECT
keyword,
CAST(collected_at AS DATE) AS report_date,
COUNT(*) AS total_results,
AVG(CAST(rank AS FLOAT)) AS avg_rank,
MIN(rank) AS best_rank
FROM OPENROWSET(
BULK 'abfss://[email protected]/curated/serp_rankings/',
FORMAT = 'DELTA')
AS serp_rankings
GROUP BY keyword, CAST(collected_at AS DATE);실행을 클릭하세요. 이렇게 하면 이름으로 참조할 수 있는 저장된 쿼리인 뷰가 생성됩니다. 다음을 실행하여 정상 작동하는지 확인하세요:
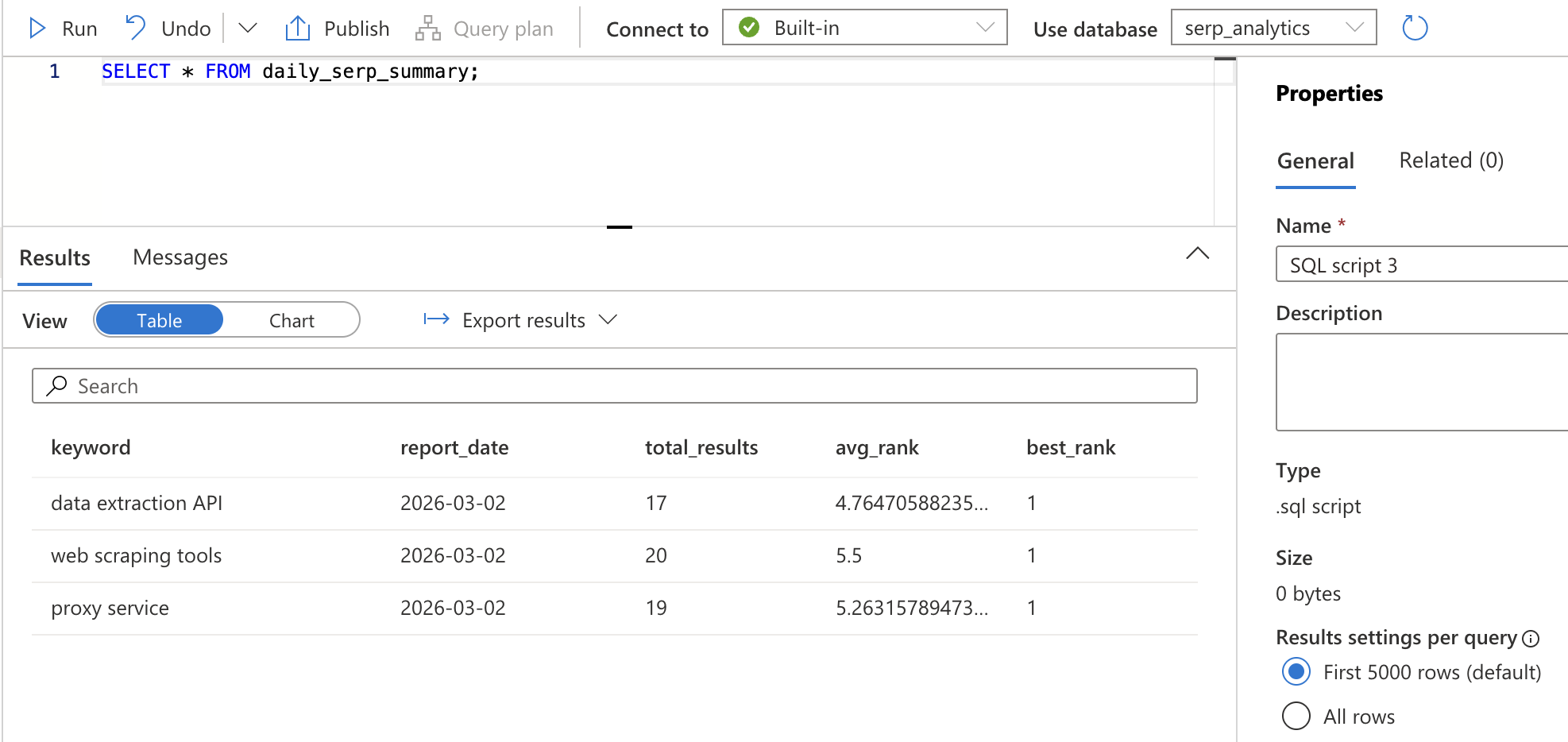
SELECT * FROM daily_serp_summary;키워드별, 일별로 한 행씩 표시되며, 총 결과 수, 평균 순위, 최고 순위가 표시됩니다.
6단계: 결과 확인
전체 파이프라인이 실행된 후 Synapse Studio에서 각 단계를 확인할 수 있습니다.
모니터 > 파이프라인 실행 으로 이동하여 가장 최근 실행을 클릭하여 확인하세요. 각 단계의 시각적 표현이 표시되며 다음을 확인할 수 있습니다:
- 각 키워드 반복을 수행하는 ForEach 활동과 Web 활동 결과.
- Spark 작업 실행 세부 정보가 포함된 Notebook 활동.
ForEach 활동을 확장하여 각 키워드에 대해 SERP 데이터가 성공적으로 검색되었는지 확인합니다. CallSERPAPI 웹 활동 실행을 클릭하면 입력 및 출력 섹션에서 요청/응답 세부 정보를 볼 수 있습니다.
데이터 > 연결됨 > 저장소 계정으로 이동하여 raw/serp/ 폴더 내 원시 JSON 파일을 탐색하세요. 날짜별로 분할된 폴더와 키워드별 JSON 파일이 표시됩니다.
마지막으로 개발 허브를 열고 TransformSERPData 노트북으로 이동한 후 다음 쿼리를 실행하여 델타 테이블을 확인하세요:
SELECT * FROM curated.serp_rankings ORDER BY collected_at DESC LIMIT 20;키워드, 순위, 제목, URL, 스니펫, 수집 타임스탬프가 포함된 구조화된 행을 확인할 수 있습니다. 이는 원시 SERP 결과에서 구축된 깨끗하고 분석 준비가 완료된 데이터입니다. Bright Data의 SERP API는 어려운 부분을 처리했습니다: 대규모로 Google 검색 결과를 안정적으로 가져오고, 봇 방지 조치 및 속도 제한을 우회하며, 파이프라인에 바로 사용할 수 있는 구조화된 데이터를 반환합니다.
더 나아가기
이 예시는 키워드 순위 추적기를 보여줍니다. 그러나 Synapse 파이프라인을 다양한 방향으로 확장할 수 있습니다:
- SERP API 호출을 Bright Data의 웹 스크레이퍼 API로 대체하여 제품 가격, 리뷰 또는 채용 공고를 수집하고 경쟁력 있는 가격 인텔리전스 대시보드를 구축하세요.
- 두 번째 Spark 노트북을 추가하여 SERP 스니펫에 대한 감성 분석을 실행하고 각 결과에 대해 긍정적 또는 부정적 프레임으로 점수를 매깁니다.
- 큐레이션된 델타 테이블을 Azure Machine Learning에 연결하여 순위 변화 예측이나 신흥 검색 트렌드 식별과 같은 예측 분석을 수행하세요.
- SERP 데이터는 Azure Data Lake에 저장하고 민감한 내부 데이터는 온프레미스에 유지하는 하이브리드 클라우드 아키텍처를 구축하세요. Synapse가 연동 쿼리를 통해 양쪽 데이터를 모두 조회합니다.
- 변환된 데이터를 Azure AI Foundry 프롬프트 흐름으로 전달하여 LLM 기반 분석을 수행하고, Synapse의 데이터 엔지니어링과 AI Foundry의 AI 기능을 결합하세요.
- LangChain이나 CrewAI 같은 도구와 통합하여 선별된 SERP 데이터를 활용하는 에이전트 워크플로를 구축하세요.
가능성은 사실상 무한합니다!
결론
이 블로그 게시물에서는 Bright Data의 SERP API를 사용하여 Google에서 최신 검색 결과를 가져오고 Azure Synapse Analytics의 완벽한 데이터 파이프라인에 통합하는 방법을 배웠습니다.
여기서 소개한 파이프라인은 SERP 데이터를 지속적으로 수집하고, 분석 가능한 테이블로 변환하며, SQL 쿼리와 Power BI 대시보드를 통해 인사이트를 제공하는 자동화된 키워드 순위 추적기를 구축하려는 모든 분에게 이상적입니다. AI 중심 프롬프트 엔지니어링 및 RAG 워크플로에 적합한 Azure AI Foundry 접근 방식과 달리, Azure Synapse Analytics는 비즈니스 인텔리전스 및 분석을 위한 대규모 데이터 수집, 변환 및 웨어하우징에 탁월합니다.
더 진보된 데이터 파이프라인을 구축하려면 실시간 웹 데이터 수집, 검증 및 변환을 위한 Bright Data의 웹 스크래핑 도구 전체 제품군을 살펴보세요. 데이터 파이프라인 아키텍처 패턴에 대한 심층 분석은 Bright Data 블로그에서 기본 개념을 다루고 있습니다.
지금 바로 무료 Bright Data 계정에 가입하고 AI 지원 웹 데이터 솔루션을 실험해 보세요!






