
이 글에서 배울 내용:
- 아마존 가격 추적기가 무엇이며 왜 유용한지
- 파이썬을 활용한 단계별 튜토리얼로 트래커 구축 방법
- 이 접근법의 한계점과 극복 방법
자, 시작해 보겠습니다!
아마존 가격 추적기란 무엇인가요?
아마존 가격 추적기는 하나 이상의 아마존 상품 가격을 시간 경과에 따라 모니터링하는 도구, 서비스 또는 스크립트입니다. 가격 변동에 대한 주기적인 업데이트를 제공하여 가격 하락, 할인 또는 변동을 식별할 수 있게 합니다.
아마존 상품 가격을 추적해야 하는 이유는?
아마존 가격 추적은 다음과 같은 이점을 제공합니다:
- 최저가로 제품을 구매하여 비용 절감
- 세일이나 프로모션 기간에 맞춰 구매할 수 있습니다
- 판매자라면 경쟁력 있는 상품 가격 설정
또한 아마존 가격 추적은 계절별 트렌드 모니터링과 시장 동향 파악에 필수적입니다.
아마존 가격 추적기 만들기: 단계별 가이드
이 튜토리얼 섹션에서는 Python을 사용하여 아마존 가격 추적기를 구축하는 방법을 배웁니다. 아래 단계를 따라 스크래핑 봇을 생성하세요:
- 지정된 상품의 아마존 페이지에 연결
- 해당 페이지에서 가격 데이터를 스크래핑합니다
- 시간 경과에 따른 가격 변동 추적
다른 데이터에도 관심이 있다면, 아마존 제품 데이터 스크래핑 방법 가이드를 참고하세요.
이제 아마존 가격 추적 스크립트를 구현해 볼 시간입니다!
1단계: 프로젝트 설정
시작하기 전에 컴퓨터에 Python 3 이상이 설치되어 있는지 확인하세요. 설치되어 있지 않다면 공식 사이트에서 다운로드하고 설치 지침을 따르세요.
그런 다음 다음 명령어로 아마존 가격 추적 프로젝트용 디렉터리를 생성하세요:
mkdir amazon-price-tracker
해당 디렉터리로 이동하여 가상 환경을 설정하세요:
cd amazon-price-tracker
python -m venv venv
선호하는 Python IDE로 프로젝트 폴더를 엽니다. Python 확장 프로그램이 설치된 Visual Studio Code나 PyCharm Community Edition이 모두 좋은 선택입니다.
프로젝트 폴더에 scraper.py 파일을 생성합니다. 이제 다음과 같은 파일 구조가 구성됩니다:
scraper.py에는 아마존 가격 추적 로직이 포함됩니다.
IDE 터미널에서 가상 환경을 활성화하세요. Linux 또는 macOS에서는 다음 명령어를 사용합니다:
./venv/bin/activate
Windows에서는 다음과 같이 실행하세요:
venv/Scripts/activate
좋습니다! 이제 설정이 완료되어 시작할 준비가 되었습니다.
2단계: 스크래핑 라이브러리 구성
전자상거래 사이트 스크래핑 가이드에서 설명한 바와 같이, 아마존 스크래핑에는 브라우저 자동화 도구가 필요합니다. 이는 사이트 자체가 특히 동적이기 때문이 아니라, 아마존이 자동화된 요청을 탐지하고 차단하기 위한 봇 방지 조치를 사용하기 때문입니다.
간단히 말해, 아마존에서 데이터를 가져오려면 Selenium과 같은 브라우저 자동화 도구가 필요합니다. 시작하려면 다음과 같이 Selenium을 설치하세요:
pip install selenium
이 라이브러리에 익숙하지 않다면, 셀레니움 웹 스크래핑 튜토리얼을 참고하세요.
스크레이퍼 스크립트 (scraper.py )에 Selenium 라이브러리를 임포트하세요:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
다음으로 Chrome 브라우저 인스턴스를 제어할 ChromeDriver 객체를 생성합니다:
# Chrome 제어용 WebDriver 초기화
driver = webdriver.Chrome(service=Service())
# 스크래핑 로직...
# 드라이버 리소스 해제
driver.quit()
driver는 가격 추적을 위해 Amazon 제품 페이지와 상호작용하는 데 사용됩니다.
아마존은 헤드리스 브라우저를 차단할 수 있는 스크래핑 방지 조치를 채택하고 있음을 기억하세요. 문제를 피하려면 Selenium으로 제어하는 브라우저를 헤드드 모드로 유지하세요.
좋아요! 이제 아마존 스크래핑 로직을 자동화할 시간입니다.
3단계: 대상 페이지에 연결하기
예를 들어 아마존에서 PS5 가격을 추적하고 싶다면:
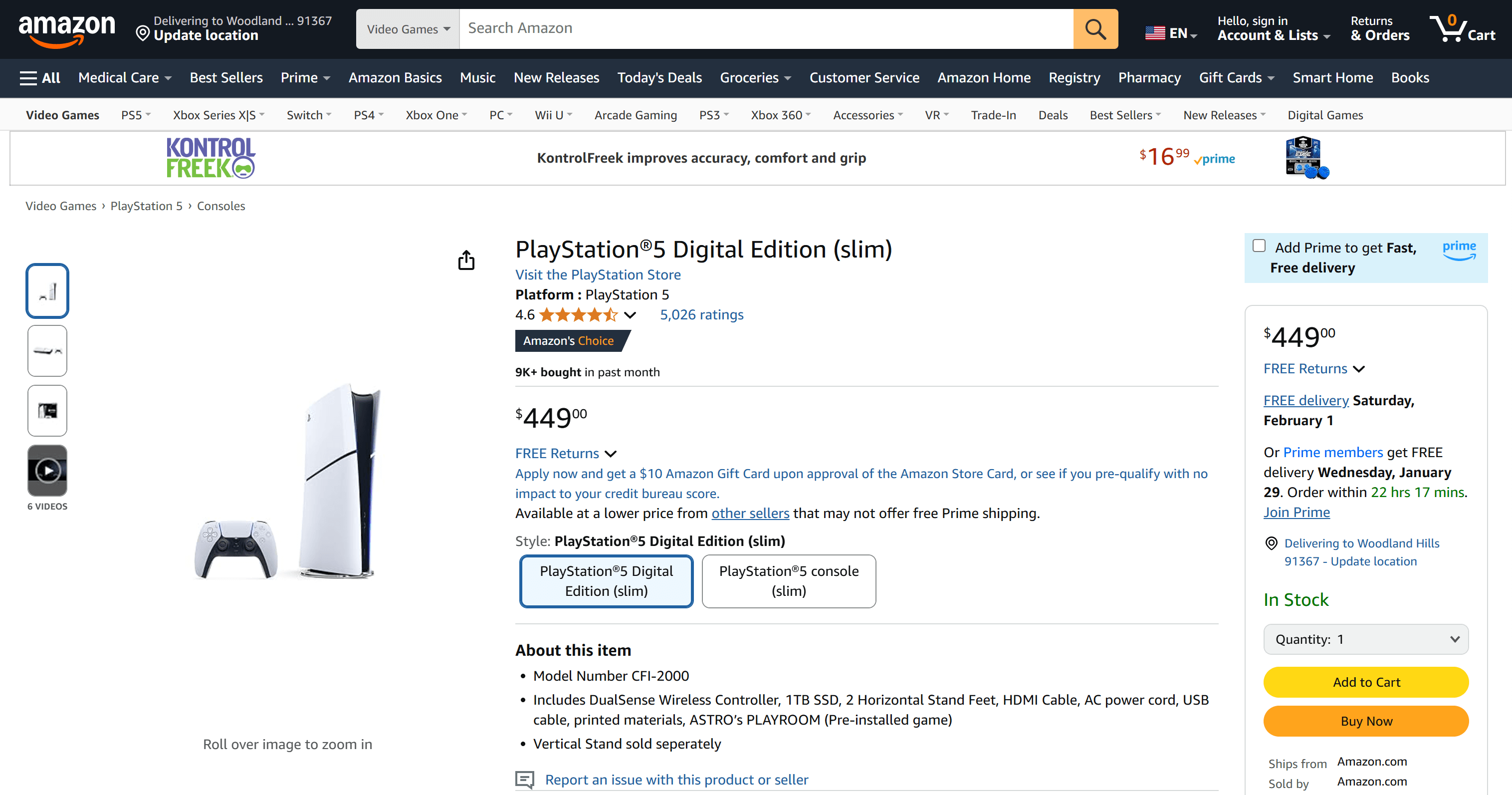
해당 제품 페이지 URL은 다음과 같습니다:
https://www.amazon.com/PlayStation%C2%AE5-Digital-slim-PlayStation-5/dp/B0CL5KNB9M/
amazon.com 이후 부분은 가독성을 위한 슬러그일 뿐이며, 중요한 부분은 /dp/ 이후의 코드입니다 . 이 코드는 아마존 ASIN이라고 불리며, 아마존 제품의 고유 식별자입니다.
다시 말해, 동일한 제품 페이지를 다음 형식으로 ASIN을 직접 사용해 접근할 수 있습니다:
https://www.amazon.com/product/dp/<AMAZON_ASIN>
이 예시에서 PS5의 ASIN은 B0CL5KNB9M입니다. 이 ASIN을 변수에 저장하고 아마존 제품 URL을 생성하는 데 사용하세요:
amazon_asin = "B0CL5KNB9M"
amazon_url = f"https://www.amazon.com/product/dp/{amazon_asin}"
다음으로 Selenium의 get() 메서드를 사용하여 브라우저가 대상 페이지로 이동하도록 지시합니다:
driver.get(amazon_url)
driver.quit() 명령어 앞에 중단점을 설정한 후 스크립트를 실행하세요. 이제 브라우저에 아마존 제품 페이지가 로드된 것을 확인할 수 있습니다:
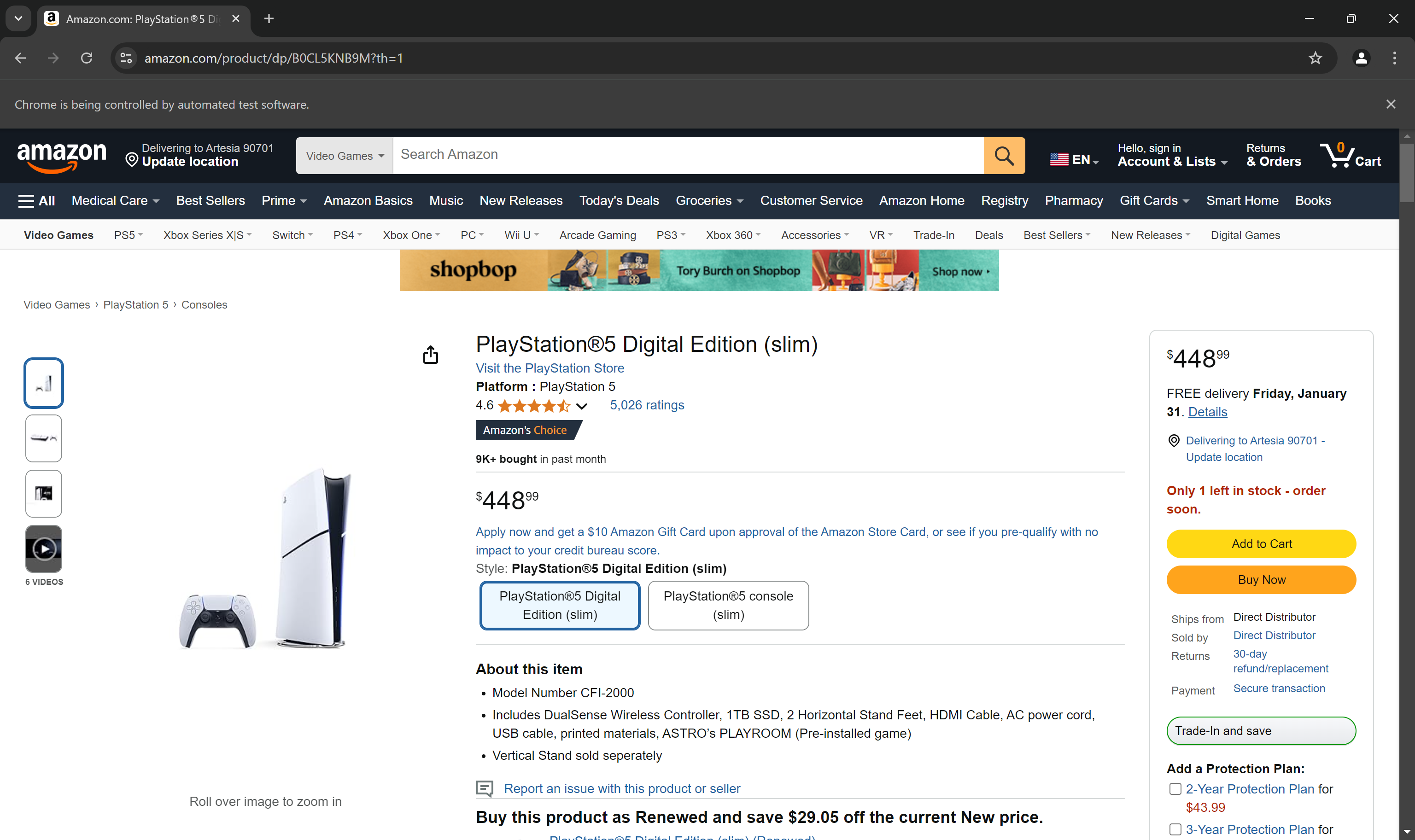
“Chrome이 자동화된 소프트웨어에 의해 제어되고 있습니다”라는 메시지는 Selenium이 의도한 대로 브라우저에서 작동하고 있음을 증명합니다.
아마존은 봇 방지 조치를 사용하므로 CAPTCHA 확인이나 요청 차단이 발생할 수 있습니다. 이 문서 후반부에서 이러한 문제를 처리하는 전략을 논의할 예정이니 걱정하지 마십시오.
Bright Data의 Amazon ASIN 스크레이퍼에 대해 자세히 알아보세요.
4단계: 가격 정보 스크래핑
브라우저에서 대상 상품 페이지를 시크릿 모드로 엽니다. 그런 다음 페이지에 표시된 가격을 마우스 오른쪽 버튼으로 클릭하고 “검사” 옵션을 선택하세요:
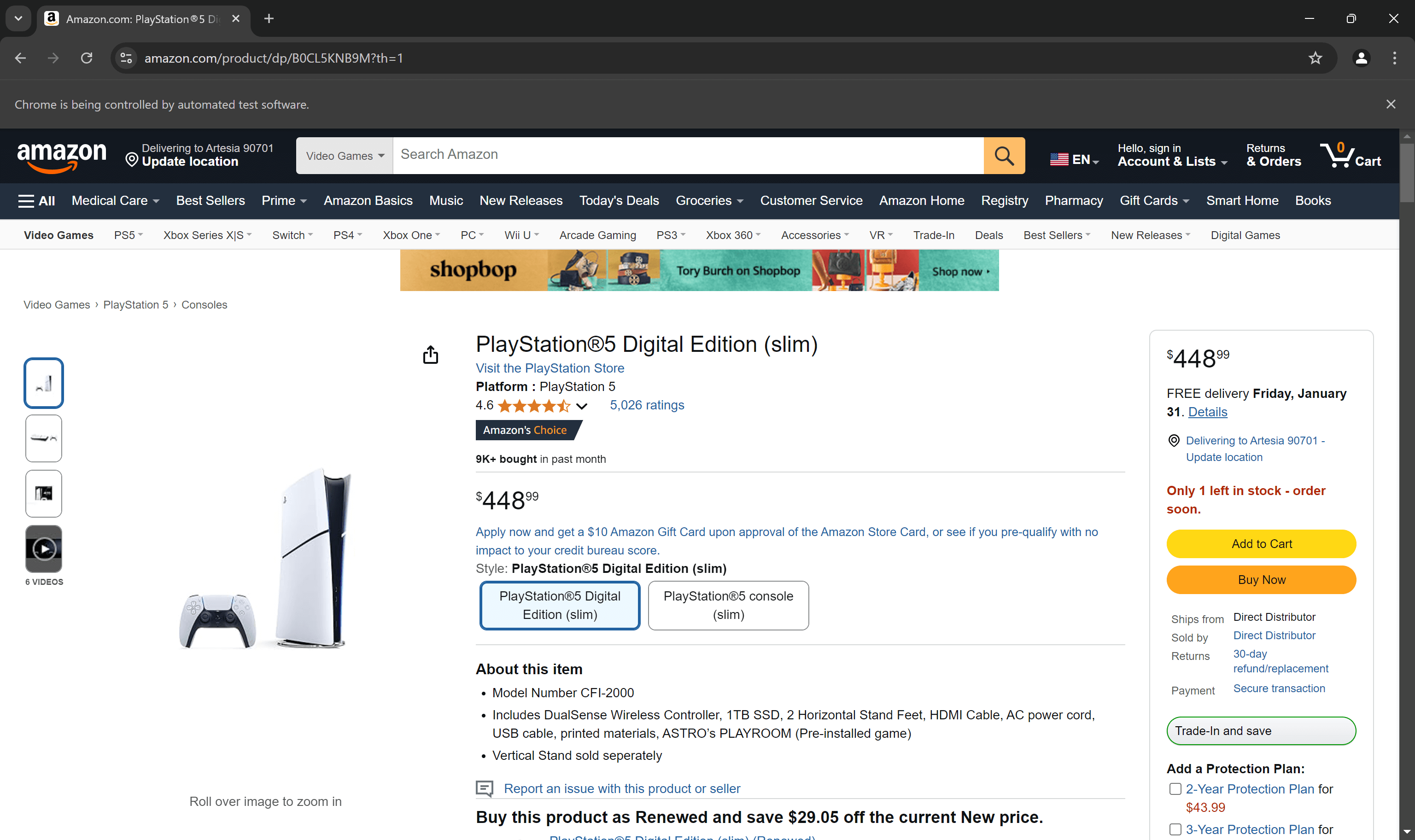
개발자 도구(DevTools) 섹션에서 가격 요소의 HTML을 확인하세요. 가격은 .a-price 요소 안에 있음을 유의하세요.
CSS 선택자로 해당 요소를 선택하고 데이터를 추출합니다:
price_element = driver.find_element(By.CLASS_NAME, "a-price")
price = price_element.text.replace("n", ".")
replace() 함수는 가격에서 줄바꿈 문자를 제거하는 데 사용됩니다.
By를 반드시 임포트하세요:
from selenium.webdriver.common.by import By
훌륭합니다! 아마존 가격 추적기의 핵심 기능인 가격 스크래핑을 성공적으로 구현했습니다.
5단계: 가격 저장
아마존 가격 추적기의 핵심 기능은 가격 변동과 추이를 평가할 수 있도록 가격 이력을 추적하는 능력입니다. 이를 위해 가격 데이터를 데이터베이스나 파일 등에 저장해야 합니다.
간편함을 위해 JSON 파일을 데이터베이스로 사용할 것입니다. 이 파일에는 제품의 ASIN과 과거 가격 목록이 저장됩니다.
먼저, 다음 구조로 JSON 파일이 존재하는지 확인하세요:
{
"asin": "<AMAZON_ASIN>",
"prices": []
}
파일이 존재하지 않을 경우 Python에서 초기화하는 방법은 다음과 같습니다:
# JSON 데이터베이스 파일명 및 초기 데이터
file_name = "price_history.json"
initial_data = {
"asin": amazon_asin,
"prices": []
}
# JSON 데이터베이스 파일이 존재하지 않으면 작성
if not os.path.exists(file_name):
with open(file_name, "w") as file:
json.dump(initial_data, file, indent=4)
# Selenium 로직...
위 코드 조각이 작동하려면 다음 두 가지 임포트가 필요합니다:
import os
import json
스크래핑 로직 전에 JSON 파일을 로드하여 현재 데이터에 접근합니다:
# JSON 파일을 읽기 및 쓰기 모드로 열기
with open(file_name, "r+") as file:
# 현재 가격 데이터 로드
price_data = json.load(file)
# 스크래핑 로직...
가격을 스크래핑한 후, 새 가격과 타임스탬프를 prices 목록에 추가합니다:
price = price_element.text.replace("n", "")
# 현재 타임스탬프
timestamp = datetime.now().isoformat()
# 새로운 가격 정보 포인트 추가
price_data["prices"].append({
"price": price,
"timestamp": timestamp
})
다음 임포트를 추가하세요:
from datetime import datetime
마지막으로 JSON 파일을 업데이트합니다:
# 파일 포인터를 시작 부분으로 이동
file.seek(0)
# 스크랩된 데이터 덮어쓰기
json.dump(price_data, file, indent=4)
# 새 내용이 기존 내용보다 짧을 경우 초과 데이터가 삭제되도록 파일 잘라내기
file.truncate()
훌륭합니다! 가격 추적 로직이 구현되었습니다.
6단계: 가격 추적 로직 예약
현재는 아마존 가격을 스크랩하고 추적할 때마다 수동으로 스크립트를 실행해야 합니다. 가끔 사용하는 경우에는 괜찮을 수 있습니다. 하지만 정기적으로 실행되도록 스크립트를 자동화하면 훨씬 더 효과적입니다.
Python 스케줄 라이브러리를 사용해 이를 달성하세요. 이 라이브러리는 Python에서 작업을 스케줄링하기 위한 직관적인 API를 제공합니다.
활성화된 가상 환경에서 다음 명령어를 실행하여 라이브러리를 설치하세요:
pip install schedule
그런 다음 전체 아마존 가격 추적 로직을 ASIN을 매개변수로 받는 함수로 캡슐화하세요:
def track_price(amazon_asin):
# 전체 아마존 가격 추적 로직...
이제 12시간마다 실행되도록 스케줄링할 수 있는 Python 작업이 생성되었습니다:
# 즉시 실행
amazon_asin="B0CL5KNB9M"
track_price(amazon_asin)
# 이후 12시간마다 작업 실행 예약
schedule.every(12).hours.do(track_price, amazon_asin=amazon_asin)
while True:
schedule.run_pending()
time.sleep(1)
while 루프는 예약된 작업을 처리하기 위해 스크립트가 계속 활성화되도록 보장합니다.
다음 두 가지 임포트를 잊지 마세요:
import schedule
import time
완벽합니다! 이제 전체 프로세스를 자동화하여 스크립트를 완전 자동화 아마존 가격 추적기로 만들었습니다.
7단계: 모든 것을 통합하기
이제 Python 아마존 가격 추적기는 다음과 같아야 합니다:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import json
import os
from datetime import datetime
import schedule
import time
def track_price(amazon_asin):
# WebDriver 초기화 (Chrome 제어용)
driver = webdriver.Chrome(service=Service())
# 아마존 상품 URL 생성
amazon_url = f"https://www.amazon.com/product/dp/{amazon_asin}"
# JSON 데이터베이스 파일명 및 초기 데이터
file_name = "price_history.json"
initial_data = {
"asin": amazon_asin,
"prices": []
}
# JSON DB 파일이 존재하지 않으면 작성
if not os.path.exists(file_name):
with open(file_name, "w") as file:
json.dump(initial_data, file, indent=4)
# JSON 파일을 읽기/쓰기 모드로 열기
with open(file_name, "r+") as file:
# 현재 가격 데이터 로드
price_data = json.load(file)
# 대상 페이지로 이동
driver.get(amazon_url)
# 가격 스크래핑
price_element = driver.find_element(By.CSS_SELECTOR, ".a-price")
price = price_element.text.replace("n", ".")
# 현재 타임스탬프
timestamp = datetime.now().isoformat()
# 새 가격 정보 포인트 추가
price_data["prices"].append({
"price": price,
"timestamp": timestamp
})
# 파일 포인터를 시작 부분으로 이동
file.seek(0)
# 스크랩된 데이터 덮어쓰기
json.dump(price_data, file, indent=4)
# 새 내용이 기존 내용보다 짧을 경우 초과 데이터가 삭제되도록 파일 잘라내기
file.truncate()
# 드라이버 리소스 해제
driver.quit()
# 즉시 실행
amazon_asin="B0CL5KNB9M"
track_price(amazon_asin)
# 이후, 12시간마다 작업 실행 예약
schedule.every(12).hours.do(track_price, amazon_asin=amazon_asin)
while True:
schedule.run_pending()
time.sleep(1)
아래와 같이 실행:
python3 scraper.py
또는 윈도우에서:
python scraper.py
스크립트를 몇 시간 동안 실행합니다. 스크립트는 다음과 유사한 price_history.json 파일을 생성합니다:
{
"asin": "B0CL5KNB9M",
"prices": [
{
"price": "$449.00",
"timestamp": "2026-01-27T08:02:20.333369"
},
{
"price": "$449.00",
"timestamp": "2026-01-27T20:02:20.935339"
},
{
"price": "$449.00",
"timestamp": "2026-01-28T08:02:21.109284"
},
{
"price": "$449.00",
"timestamp": "2026-01-28T20:02:21.385681"
},
{
"price": "$449.00",
"timestamp": "2026-01-29T08:02:22.123612"
}
]
}
가격 배열의 각 항목이 이전 항목으로부터 정확히 12시간 후에 기록되는 것을 확인하세요.
미션 완료!
단계 #8: 다음 단계
이제 기능적인 아마존 가격 추적기를 구축했지만, 한 단계 업그레이드할 여지가 있습니다. 가능한 개선 사항은 다음과 같습니다:
- 로깅 추가: 무인 프로세스인 만큼, 진행 상황을 파악하는 것이 중요합니다. 이를 위해 스크립트의 동작을 추적할 수 있도록 로깅을 추가하세요.
- 데이터베이스 사용: JSON 파일을 데이터베이스로 대체하여 데이터를 저장하세요. 이렇게 하면 여러 기기나 애플리케이션에서 가격 이력을 공유하고 접근하기가 더 쉬워집니다.
- 오류 처리 구현: 봇 방지 조치, 네트워크 시간 초과, 예기치 않은 오류 등을 관리하기 위한 강력한 오류 처리 기능을 추가하세요. 오류 발생 시 스크립트가 재시도하거나 우아하게 건너뛰도록 보장합니다.
- CLI에서 옵션 읽기: ASIN 및 스케줄링 옵션과 같은 명령줄 입력을 스크립트가 받아들일 수 있도록 허용하세요. 이를 통해 유연성이 향상됩니다.
- 알림 시스템: 이메일이나 메신저 앱을 통한 알림을 통합하여 주요 가격 변동을 알려줍니다.
이 접근법의 한계와 극복 방안
이전 장에서 구축한 아마존 가격 추적 스크립트는 기본적인 예시에 불과합니다. 다음 단계를 구현하지 않는 한, 이렇게 단순한 스크립트를 장기적으로 사용하기는 어렵습니다. 이러한 단계들은 스크립트를 향상시키지만 동시에 더 복잡해지고 관리가 어려워질 것입니다.
그러나 스크립트가 아무리 정교해져도 아마존은 여전히 CAPTCHA로 이를 차단할 수 있습니다:
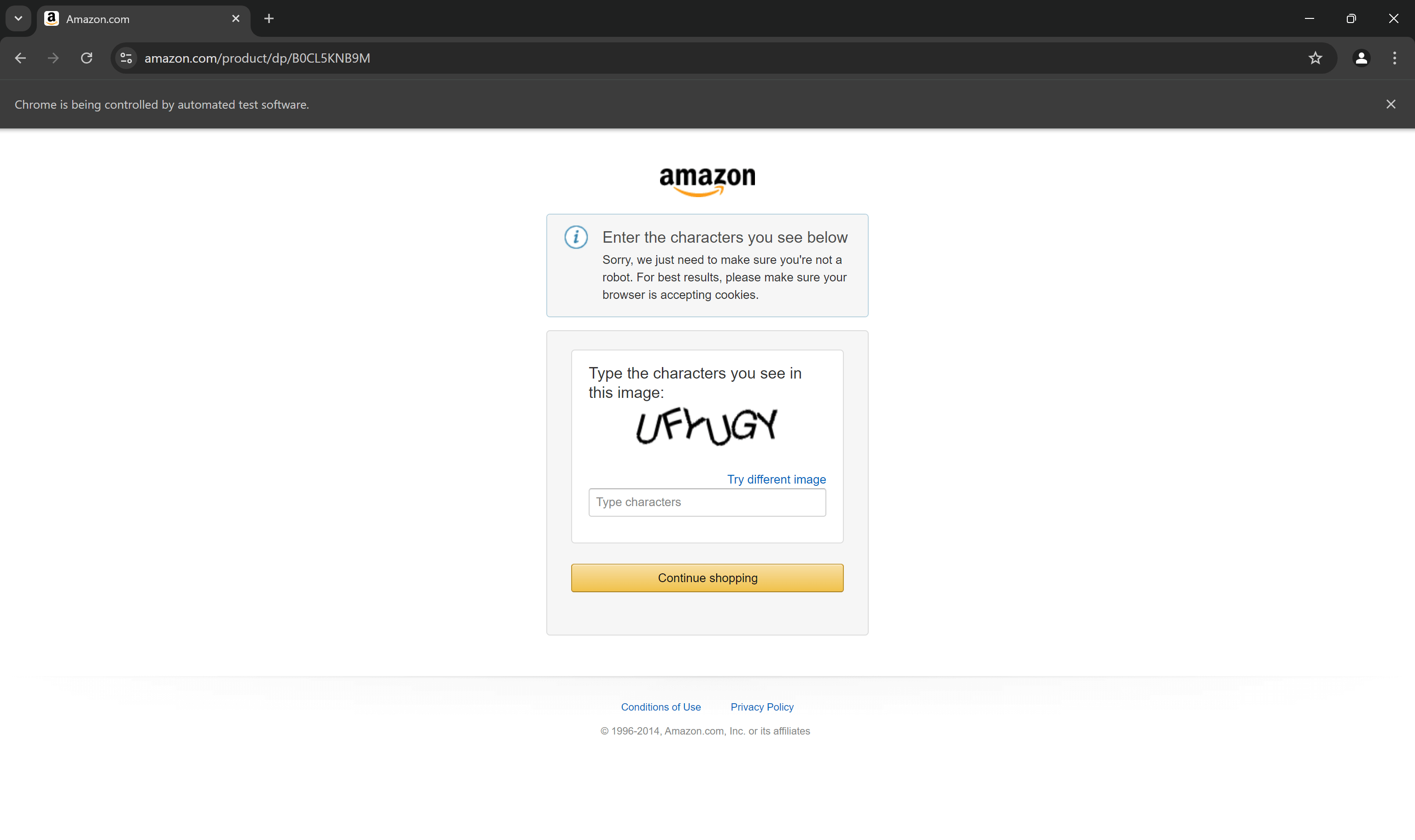
사실, 현재 사용 중인 셀레니움 기반 아마존 스크래핑 스크립트가 이미 CAPTCHA로 차단되고 있을 가능성이 높습니다. 첫 번째 단계로, 파이썬에서 CAPTCHA 우회 방법에 대한 가이드를 따르는 것을 고려해 보세요.
그럼에도 엄격한 속도 제한으로 인해 429 Too Many Requests 오류가 발생할 수 있습니다. 이 경우 셀레니움에 프록시를 통합하여 출구 IP를 순환시키는 것이 효과적인 전략입니다.
이러한 문제들은 적절한 도구 없이는 아마존 같은 사이트를 스크래핑하는 일이 얼마나 좌절감을 주는지 보여줍니다. 또한 브라우저 자동화 도구를 사용할 수 없으면 스크립트가 느려지고 리소스를 많이 소모하게 됩니다.
그렇다면 포기해야 할까요? 전혀 아닙니다! 진정한 해결책은 Bright Insights와 같은 서비스를 활용하는 것입니다. 이 서비스는 실행 가능한 AI 기반 전자상거래 인사이트를 제공하여 다음과 같은 도움을 줍니다:
- 손실된 매출 복구: 상품 삭제, 품절, 노출 문제로 인한 매출 손실을 파악하고 해결합니다.
- 판매 및 시장 점유율 추적: 미개척 시장 기회 발견, 경쟁사 판매 추적, 트렌드 조기 포착.
- 가격 최적화: 실시간 경쟁사 가격 모니터링으로 경쟁력 유지
- 리테일 미디어 극대화: 분석을 활용해 광고를 최적화하고, ROI를 극대화하며, 지속적으로 성장하는 결과를 보장합니다.
- 제품 구성 최적화: 경쟁사 추적 및 수익 극대화를 통해 제품 구성을 개선합니다.
- 크로스 채널 최적화: 크로스 채널 인텔리전스를 활용하여 제품 판매를 관리하고 모든 플랫폼에서 승리하세요.
Bright Insights는 아마존 가격 추적 기능을 포함하여 필요한 모든 전자상거래 데이터를 제공합니다.
결론
이 블로그 글에서는 아마존 가격 추적기가 무엇이며 어떤 장점을 제공하는지 알아보았습니다. 또한 웹 스크래핑을 위해 Python과 Selenium을 사용하여 이를 구축하는 방법도 살펴보았습니다.
문제는 아마존이 CAPTCHA, 브라우저 지문 인식, IP 차단 등 자동화된 스크립트를 차단하기 위한 엄격한 반봇(anti-bot) 조치를 시행한다는 점입니다. 하지만 저희 아마존 가격 추적기를 사용하면 이러한 문제들을 잊고 아마존 가격을 얻을 수 있습니다.
웹 스크래핑에 관심이 있고 다양한 유형의 아마존 데이터에 관심이 있다면, 저희 아마존 스크레이퍼 API도 고려해 보세요!
지금 바로 Bright Data 무료 계정을 생성하고 서비스를 살펴보세요.






