

Node.js는 웹 스크레이퍼 구축을 위한 강력한 옵션으로 부상했으며, 클라이언트 측과 서버 측 개발 모두에 편의를 제공합니다. 방대한 라이브러리 카탈로그 덕분에 Node.js를 활용한 웹 스크래핑은 매우 간편합니다. 본 문서에서는 cheerio를 집중 조명하고 효율적인 웹 스크래핑을 위한 그 기능을 살펴보겠습니다.
Cheerio는 HTML 및 XML 문서를 파싱하고 조작하기 위한 빠르고 유연한 라이브러리입니다. jQuery 기능의 하위 집합을 구현하므로 jQuery에 익숙한 사람이라면 cheerio의 구문도 쉽게 익힐 수 있습니다. 내부적으로는 HTML 및 XML 문서 파싱을 위해 parse5 라이브러리를 기본으로 사용하고, 선택적으로 htmlparser2 라이브러리도 활용합니다.
이 글에서는 cheerio를 활용한 프로젝트를 만들고, 동적 웹사이트와 정적 웹 페이지에서 데이터를 스크래핑하는 방법을 배울 것입니다.
cheerio를 활용한 웹 스크래핑
이 튜토리얼을 시작하기 전에 시스템에 Node.js가 설치되어 있는지 확인하세요. 아직 설치하지 않았다면 공식 문서를 참고하여 설치할 수 있습니다.
Node.js 설치 후 cheerio-demo 디렉터리를 생성하고 해당 디렉터리로 이동합니다:
mkdir cheerio-demo u0026u0026 cd cheerio-demon
그런 다음 디렉터리 내에서 npm 프로젝트를 초기화하세요:
npm init -yn
npm install cheerio axiosn
이 튜토리얼의 코드를 작성할 index.js 파일을 생성하세요. 그런 다음 선호하는 편집기로 이 파일을 열어 시작하세요.
가장 먼저 필요한 모듈을 임포트해야 합니다:
const axios = require(u0022axiosu0022);nconst cheerio = require(u0022cheeriou0022);n
이 튜토리얼에서는 웹 스크레이퍼 테스트용 공개 샌드박스인 Books to Scrape 페이지를 스크레이핑합니다. 먼저 Axios를 사용하여 다음 코드로 웹 페이지에 GET 요청을 보냅니다:
axios.get(u0022https://books.toscrape.com/u0022).then((response) =u003e {n n});n
콜백 함수의 응답 객체에는 data 속성에 웹 페이지의 HTML 코드가 포함됩니다. 이 HTML은 cheerio 모듈의 load 함수에 전달되어야 합니다. 이 함수는 CheerioAPI 인스턴스를 반환하며, 이후 코드에서 DOM에 접근하고 조작하는 데 사용됩니다. CheerioAPI 인스턴스는 $라는 변수에 저장되는데, 이는 jQuery 구문을 연상시키는 것입니다:
axios.get(u0022https://books.toscrape.com/u0022).then((response) =u003e {n const $ = cheerio.load(response.data);n});n
요소 찾기
cheerio는 페이지에서 요소를 선택하기 위해 CSS 및 XPath 선택자를 지원합니다. jQuery를 사용해 본 적이 있다면 구문이 익숙할 것입니다—CSS 선택자를 $() 함수에 전달하세요. 이 구문을 사용하여 Books to Scrape 웹사이트의 첫 페이지에서 정보를 찾고 추출해 보세요.
https://books.toscrape.com/을 방문하여 개발자 콘솔을 엽니다. ‘요소 검사’ 탭을 검색하면 페이지의 HTML 구조에 대해 자세히 알 수 있습니다. 이 경우, 책에 대한 모든 정보가 product-pod 클래스를 가진 article 태그에 포함되어 있음을 확인할 수 있습니다:
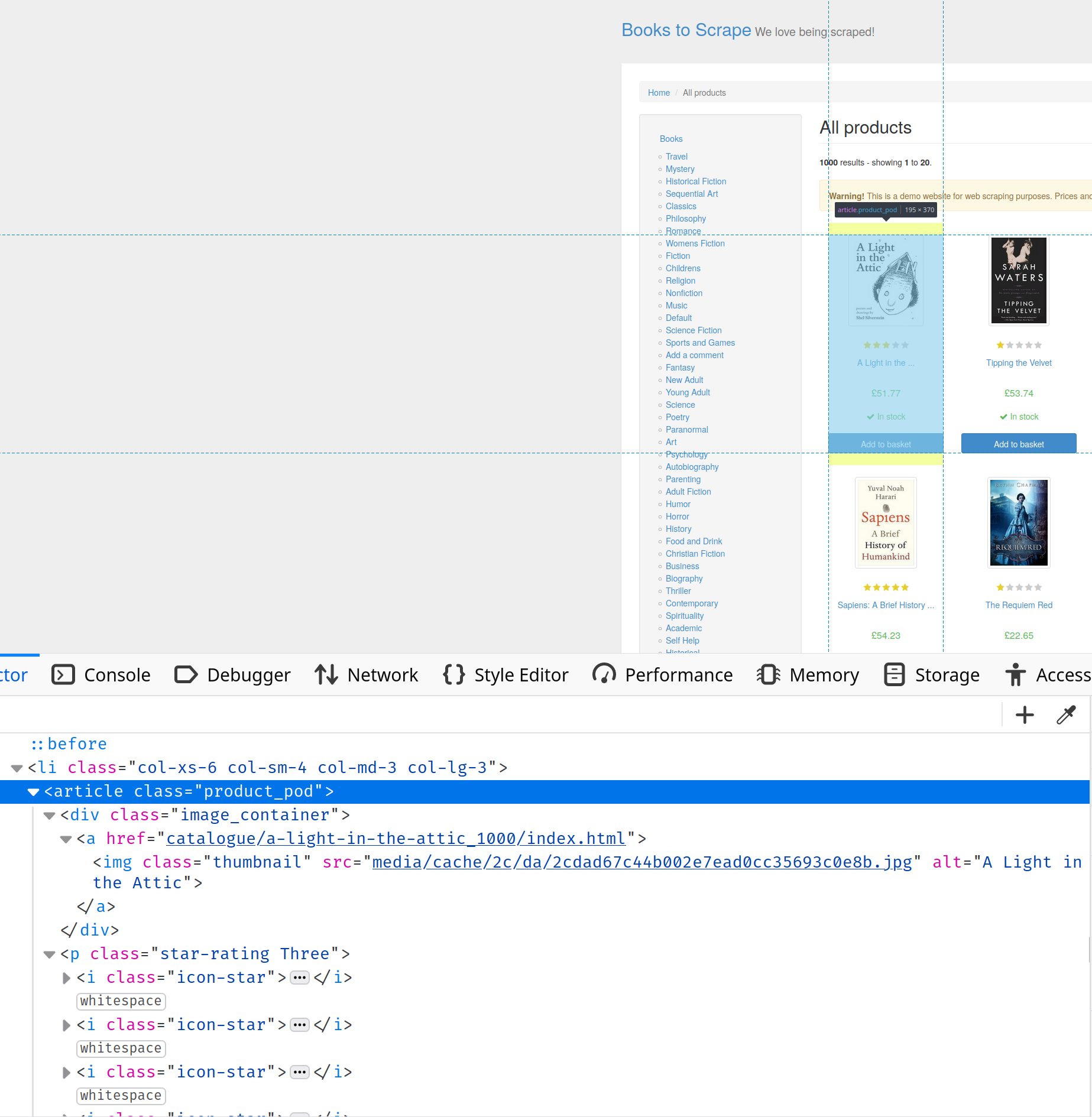
책을 선택하려면 다음과 같이 article.product_pod CSS 선택자를 사용해야 합니다:
$(u0022article.product_podu0022);n
이 함수는 선택자와 일치하는 모든 요소의 목록을 반환합니다. each 메서드를 사용해 목록을 반복 처리할 수 있습니다:
$(u0022article.product_podu0022).each( (i, element) =u003e {nn});n
루프 내부에서 element 변수를 사용해 데이터를 추출할 수 있습니다.
첫 페이지의 책 제목을 추출해 보세요. 요소 검사 콘솔로 돌아가면 제목이 어떻게 저장되어 있는지 확인할 수 있습니다:

element 변수의 자식인 h3 요소를 찾아야 함을 알 수 있습니다. h3 내부에는 책 제목을 포함하는 a 요소가 있습니다. CSS 선택자와 함께 find 메서드를 사용해 요소의 자식 요소를 찾을 수 있지만, 먼저 element를 $를 통해 Cheerio 인스턴스로 변환해야 합니다:
$(u0022article.product_podu0022).each( (i, element) =u003e {n const titleH3 = $(element).find(u0022h3u0022);nn});n
이제 titleH3 내부의 a 를 찾을 수 있습니다:
$(u0022article.product_podu0022).each( (i, element) =u003e {n const titleH3 = $(element).find(u0022h3u0022);n const title = titleH3.find(u0022au0022);n});n
참고:
titleH3는이미Cheerio인스턴스이므로$를통해 전달할 필요가 없습니다.
텍스트 추출
요소를 선택한 후 text 메서드를 사용해 해당 요소의 텍스트를 가져올 수 있습니다.
이전 예제를 수정하여 find 메서드 결과에 text 메서드를 호출해 책 제목을 추출합니다:
$(u0022article.product_podu0022).each( (i, element) =u003e {n const titleH3 = $(element).find(u0022h3u0022);n const title = titleH3.find(u0022au0022).text();nn console.log(title);n});n
완성된 코드는 다음과 같아야 합니다:
const axios = require(u0022axiosu0022);nconst cheerio = require(u0022cheeriou0022);nnaxios.get(u0022https://books.toscrape.com/u0022).then((response) =u003e {n const $ = cheerio.load(response.data);nn $(u0022article.product_podu0022).each( (i, element) =u003e {n const titleH3 = $(element).find(u0022h3u0022);n const title = titleH3.find(u0022au0022).text();nn console.log(title);n });n});n
node index.js로 코드를 실행하면 다음과 같은 출력이 표시됩니다:
A Light in the ...nTipping the VelvetnSoumissionnSharp ObjectsnSapiens: A Brief History ...nThe Requiem RednThe Dirty Little Secrets ...nThe Coming Woman: A ...nThe Boys in the ...nThe Black MarianStarving Hearts (Triangular Trade ...nShakespeare's SonnetsnSet Me FreenScott Pilgrim's Precious Little ...nRip it Up and ...nOur Band Could Be ...nOlionMesaerion: The Best Science ...nLibertarianism for BeginnersnIt's Only the Himalayasn
DOM 탐색: 자식 요소 및 형제 요소 찾기
제목을 추출한 후에는 각 책의 가격과 재고 상태를 추출할 차례입니다. Inspect Element를 통해 가격과 재고 상태가 모두 product_price 클래스의 div에 저장되어 있음을 확인할 수 있습니다. 이 div를 .product_price CSS 선택자로 선택할 수 있지만, CSS 선택자에 대해서는 이미 다루었으므로 다음에서는 다른 방법을 설명하겠습니다:
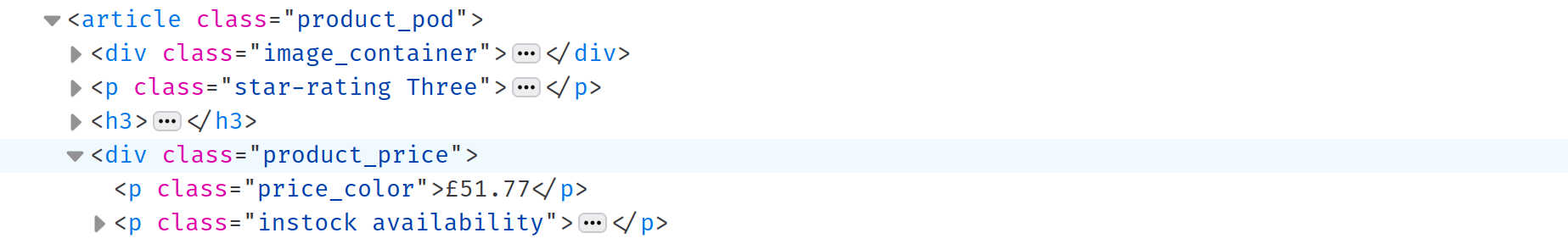
참고: 이
div는이전에 선택한titleH3의형제 요소입니다.titleH3의next메서드를 호출하면 다음 형제 요소를 선택할 수 있습니다:
const priceDiv = titleH3.next();n
find 메서드를 사용해 CSS 선택자에 기반한 요소의 자식 요소를 찾을 수 있다는 점은 이미 확인하셨습니다. children 메서드로 모든 자식 요소를 선택한 후 eq 메서드를 사용해 특정 자식 요소를 선택할 수도 있습니다. 이는 nth-child CSS 선택자와 동일합니다.
이 경우 price는 priceDiv의 첫 번째 자식이고, availability는 priceDiv의 두 번째 자식입니다. 즉, 각각 priceDiv.children().eq(0) 과 priceDiv.children().eq(1)으로 선택할 수 있습니다. 이렇게 선택한 후 가격과 재고 상태를 출력해 보세요:
$(u0022article.product_podu0022).each( (i, element) =u003e {n const titleH3 = $(element).find(u0022h3u0022);n const title = titleH3.find(u0022au0022).text();nnn const priceDiv = titleH3.next();n const price = priceDiv.children().eq(0).text().trim();n const availability = priceDiv.children().eq(1).text().trim();n console.log(title, price, availability);n});n
이제 코드를 실행하면 다음과 같은 결과가 출력됩니다:
A Light in the ... £51.77 In stocknTipping the Velvet £53.74 In stocknSoumission £50.10 In stocknSharp Objects £47.82 In stocknSapiens: A Brief History ... £54.23 In stocknThe Requiem Red £22.65 In stocknThe Dirty Little Secrets ... £33.34 In stocknThe Coming Woman: A ... £17.93 In stocknThe Boys in the ... £22.60 In stocknThe Black Maria £52.15 In stocknStarving Hearts (Triangular Trade ... £13.99 In stocknShakespeare's Sonnets £20.66 In stocknSet Me Free £17.46 In stocknScott Pilgrim's Precious Little ... £52.29 In stocknRip it Up and ... £35.02 In stocknOur Band Could Be ... £57.25 In stocknOlio £23.88 In stocknMesaerion: The Best Science ... £37.59 In stocknLibertarianism for Beginners £51.33 In stocknIt's Only the Himalayas £45.17 In stockn
속성 접근
지금까지 DOM을 탐색하고 요소에서 텍스트를 추출하는 방법을 살펴보았습니다. cheerio를 사용하면 요소에서 속성도 추출할 수 있으며, 이번 섹션에서는 이를 수행할 것입니다. 여기서는 요소의 class 목록을 읽어 책의 평점을 추출할 것입니다.
책의 평점은 흥미로운 구조를 가집니다. 평점은 p 태그 안에 포함되어 있습니다. 각 p 태그에는 정확히 다섯 개의 별이 있지만, 별은 p 요소의 클래스 이름을 기반으로 CSS를 사용하여 색상이 지정됩니다. 예를 들어, star-rating.Four 클래스를 가진 p에서는 처음 네 개의 별이 노란색으로 표시되어 4점 평점을 나타냅니다:

책의 평점을 추출하려면 p 요소의 클래스 이름을 추출해야 합니다. 첫 번째 단계는 평점이 포함된 단락을 찾는 것입니다:
const ratingP = $(element).find(u0022p.star-ratingu0022);n
attr 메서드에 속성 이름을 전달하면 요소의 속성을 읽을 수 있습니다. 이 경우 클래스 목록을 읽어야 하며, 다음 코드에서 이를 보여줍니다:
const starRating = ratingP.attr('class');n
클래스 목록은 다음과 같은 형식입니다: star-rating X, 여기서 X는 One, Two, Three, Four, Five 중 하나입니다. 즉, 클래스 목록을 공백으로 분할하고 두 번째 요소를 가져와야 합니다. 다음 코드는 이를 수행하고 텍스트 등급을 숫자 등급으로 변환합니다:
const rating = { One: 1, Two: 2, Three: 3, Four: 4, Five: 5 }[starRating.split(u0022 u0022)[1]];n
모든 것을 합치면 코드는 다음과 같습니다:
$(u0022article.product_podu0022).each( (i, element) =u003e {n const titleH3 = $(element).find(u0022h3u0022);n const title = titleH3.find(u0022au0022).text();nnn const priceDiv = titleH3.next();n const price = priceDiv.children().eq(0).text().trim();n const availability = priceDiv.children().eq(1).text().trim();nn const ratingP = $(element).find(u0022p.star-ratingu0022);n const starRating = ratingP.attr('class');n const rating = { One: 1, Two: 2, Three: 3, Four: 4, Five: 5 }[starRating.split(u0022 u0022)[1]];nn console.log(title, price, availability, rating);n});n
출력 결과는 다음과 같습니다:
A Light in the ... £51.77 In stock 3nTipping the Velvet £53.74 In stock 1nSoumission £50.10 In stock 1nSharp Objects £47.82 In stock 4nSapiens: A Brief History ... £54.23 In stock 5nThe Requiem Red £22.65 In stock 1nThe Dirty Little Secrets ... £33.34 In stock 4nThe Coming Woman: A ... £17.93 In stock 3nThe Boys in the ... £22.60 In stock 4nThe Black Maria £52.15 In stock 1nStarving Hearts (Triangular Trade ... £13.99 In stock 2nShakespeare's Sonnets £20.66 In stock 4nSet Me Free £17.46 In stock 5nScott Pilgrim's Precious Little ... £52.29 In stock 5nRip it Up and ... £35.02 In stock 5nOur Band Could Be ... £57.25 In stock 3nOlio £23.88 In stock 1nMesaerion: The Best Science ... £37.59 In stock 1nLibertarianism for Beginners £51.33 In stock 2nIt's Only the Himalayas £45.17 In stock 2n
데이터 저장
웹 페이지에서 데이터를 스크래핑한 후에는 일반적으로 이를 저장하고 싶을 것입니다. 파일 저장, 데이터베이스 저장, 데이터 처리 파이프라인으로 전송하는 등 여러 방법이 있습니다. 이 섹션에서는 가장 간단한 방법인 CSV 파일로 데이터 저장하는 법을 배웁니다.
이를 위해 node-csv 패키지를 설치하세요:
npm install csvn
index.js에서 fs 및 csv-stringify 모듈을 임포트하세요:
const fs = require(u0022fsu0022);nconst { stringify } = require(u0022csv-stringifyu0022);n
로컬 파일을 작성하려면 WriteStream을 생성해야 합니다:
const filename = u0022scraped_data.csvu0022;nconst writableStream = fs.createWriteStream(filename);n
CSV 파일에 헤더로 추가될 열 이름을 선언합니다:
const columns = [n u0022titleu0022,n u0022ratingu0022,n u0022priceu0022,n u0022availabilityu0022n];n
열 이름을 사용해 stringifier를 생성합니다:
const stringifier = stringify({ header: true, columns: columns });n
each 함수 내부에서 stringifier를 사용하여 데이터를 작성합니다:
$(u0022article.product_podu0022).each( (i, element) =u003e {n ...nn const data = { title, rating, price, availability };n stringifier.write(data);nn});n
마지막으로 each 함수 외부에서 stringifier의 내용을 writableStream 변수에 작성해야 합니다:
stringifier.pipe(writableStream);n
이 시점에서 코드는 다음과 같아야 합니다:
const axios = require(u0022axiosu0022);nconst cheerio = require(u0022cheeriou0022);nconst fs = require(u0022fsu0022);nconst { stringify } = require(u0022csv-stringifyu0022);nnconst filename = u0022scraped_data.csvu0022;nconst writableStream = fs.createWriteStream(filename);nnconst columns = [n u0022titleu0022,n u0022ratingu0022,n u0022priceu0022,n u0022availabilityu0022n];nconst stringifier = stringify({ header: true, columns: columns });nnaxios.get(u0022https://books.toscrape.com/u0022).then((response) =u003e {n const $ = cheerio.load(response.data);nn $(u0022article.product_podu0022).each( (i, element) =u003e {n const titleH3 = $(element).find(u0022h3u0022);n const title = titleH3.find(u0022au0022).text();n n const priceDiv = titleH3.next();n const price = priceDiv.children().eq(0).text().trim();n const availability = priceDiv.children().eq(1).text().trim();n const ratingP = $(element).find(u0022p.star-ratingu0022);n const starRating = ratingP.attr('class');n const rating = { One: 1, Two: 2, Three: 3, Four: 4, Five: 5 }[starRating.split(u0022 u0022)[1]];nn console.log(title, price, availability, rating);nn const data = { title, rating, price, availability };n stringifier.write(data);nn });nn stringifier.pipe(writableStream);nn});n
코드를 실행하면 스크랩된 데이터가 포함된 scraped_data.csv 파일이 생성됩니다:
title,rating,price,availabilitynA Light in the ...,3,£51.77,In stocknTipping the Velvet,1,£53.74,In stocknSoumission,1,£50.10,In stocknSharp Objects,4,£47.82,In stocknSapiens: A Brief History ...,5,£54.23,In stocknThe Requiem Red,1,£22.65,In stocknThe Dirty Little Secrets ...,4,£33.34,In stocknThe Coming Woman: A ...,3,£17.93,In stocknThe Boys in the ...,4,£22.60,In stocknThe Black Maria,1,£52.15,In stocknStarving Hearts (Triangular Trade ...,2,£13.99,In stocknShakespeare's Sonnets,4,£20.66,In stocknSet Me Free,5,£17.46,In stocknScott Pilgrim's Precious Little ...,5,£52.29,In stocknRip it Up and ...,5,£35.02,In stocknOur Band Could Be ...,3,£57.25,In stocknOlio,1,£23.88,In stocknMesaerion: The Best Science ...,1,£37.59,In stocknLibertarianism for Beginners,2,£51.33,In stocknIt's Only the Himalayas,2,£45.17,In stockn
결론
여기서 보셨듯이, cheerio 라이브러리는 jQuery와 유사한 구문과 매우 빠른 작동으로 웹 스크래핑을 쉽게 만들어 줍니다. 이 글에서는 다음을 수행하는 방법을 배웠습니다:
- cheerio로 HTML 웹 페이지 로드 및 파싱
- CSS 선택자로 요소 찾기
- 요소에서 데이터 추출하기
- DOM 탐색하기
- 스크래핑한 데이터를 로컬 파일 저장소에 저장하기
전체 코드는 GitHub에서 확인할 수 있습니다.
그러나 cheerio는 단순한 HTML 파서이므로 자바스크립트 코드를 실행할 수 없습니다. 즉, 동적 웹 페이지나 단일 페이지 애플리케이션(SPA) 스크래핑에는 사용할 수 없습니다. 이러한 페이지를 스크래핑하려면 cheerio를 넘어 Selenium이나 Playwright 같은 복잡한 도구를 살펴봐야 합니다. 바로 여기에 Bright Data가 필요한 이유입니다. Bright Data의 방대한 웹 스크래핑 솔루션에는 Selenium 스크래핑 브라우저와 Playwright 스크래핑 브라우저가 포함됩니다. 제품에 대한 자세한 내용은 스크래핑 브라우저 문서를 참조하세요.






