

판매자이거나 시장 조사를 수행 중이라면 제품의 ASIN을 알면 정확한 제품 일치를 빠르게 찾고, 경쟁사 리스팅을 분석하며, 시장에서 앞서 나갈 수 있습니다. 이 글에서는 대규모로 아마존 ASIN을 스크래핑하는 간단하고 효과적인 방법을 보여드립니다. 또한 이 과정을 크게 가속화할 수 있는 Bright Data의 솔루션에 대해서도 알아보실 수 있습니다.
아마존에서 ASIN이란 무엇인가요?
ASIN은 문자와 숫자를 조합한 10자리 코드입니다(예: B07PZF3QK9). 아마존은 도서부터 전자제품, 의류에 이르기까지 카탈로그 내 모든 상품에 이 고유 코드를 할당합니다.
제품의 ASIN을 찾는 두 가지 간단한 방법은 다음과 같습니다:
1. 상품 URL 확인 – 주소창에서 “/dp/” 바로 뒤에 ASIN이 표시됩니다.
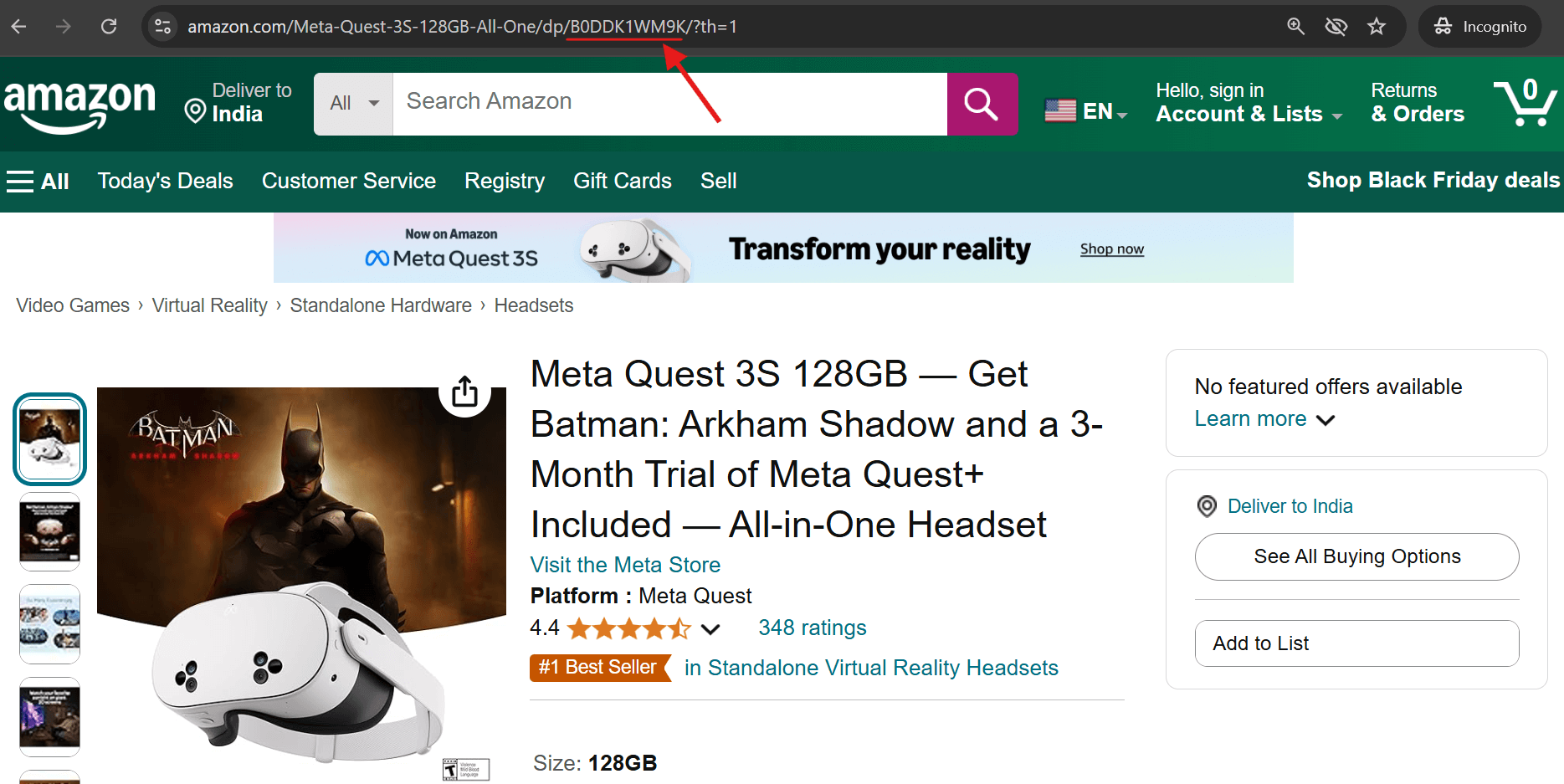
2. 아마존 상품 페이지의 하단 ‘상품 정보’ 섹션으로 스크롤하면 ASIN이 기재되어 있습니다.
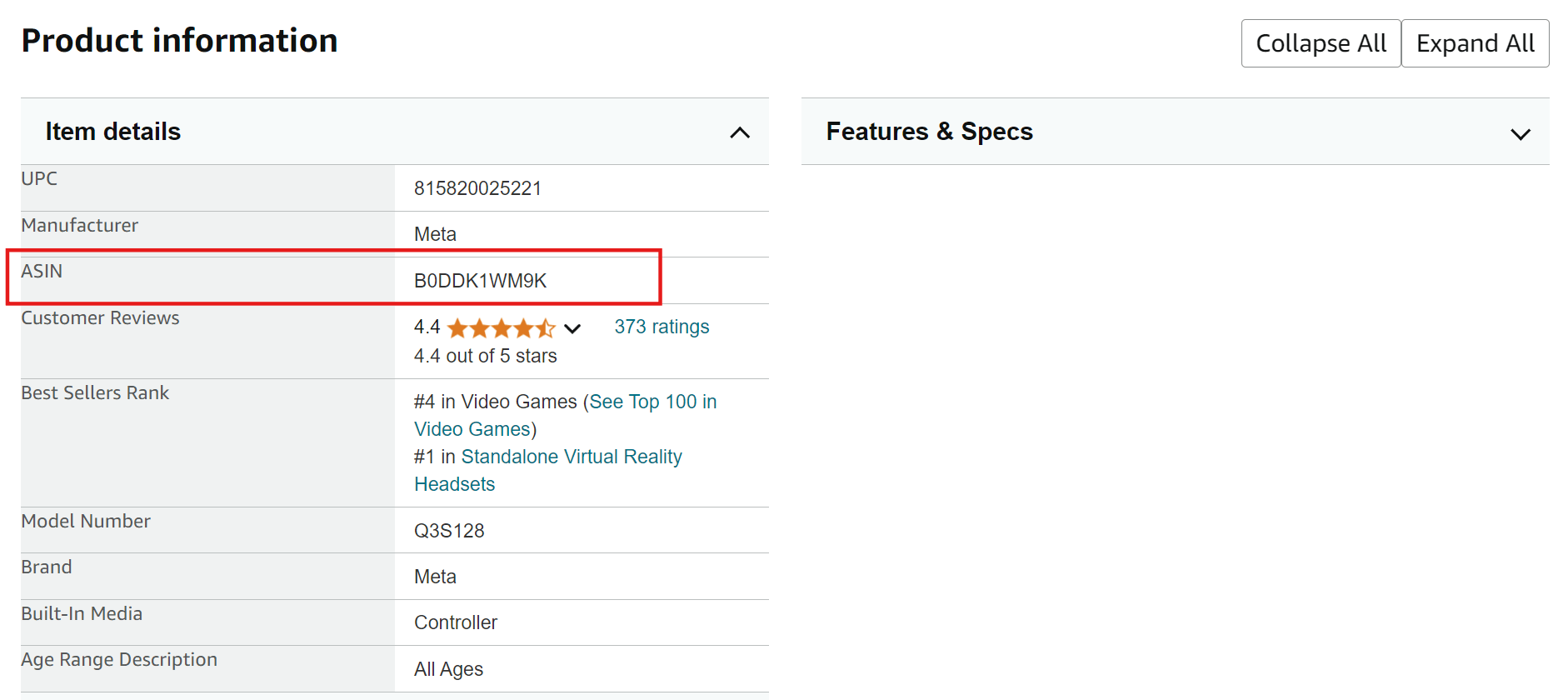
아마존에서 ASIN 추출 방법
아마존에서 데이터를 스크래핑하는 것은 처음에는 간단해 보일 수 있지만, 강력한 스크래핑 방지 조치로 인해 상당히 어렵습니다. 아마존은 다음과 같은 정교한 방법을 통해 자동화된 데이터 수집을 적극적으로 차단합니다:
- CAPTCHA 인증
- 요청된 페이지 접근을 차단하는 HTTP 503 오류
- 파싱 로직을 무력화하는 빈번한 웹사이트 레이아웃 변경
아마존에서 발생하는 전형적인 HTTP 503 오류 화면 캡처:

아마존 ASIN을 스크래핑하기 위한 간단한 스크립트를 시도해 볼 수 있습니다:
import asyncio import os from curl_cffi import requests from bs4 import BeautifulSoup from tenacity import retry, stop_after_attempt, wait_random class AsinScraper: def __init__(self): self.session = requests.Session() self.asins = set() def create_url(self, keyword: str, page: int) -> str: return f"https://www.amazon.com/s?k={keyword.replace(' ', '+')}&page={page}" @retry(stop=stop_after_attempt(3), wait=wait_random(min=2, max=5)) async def fetch_page(self, url: str) -> str | None: try: print(f"URL 가져오기: {url}") response = self.session.get( url, impersonate="chrome120", timeout=30) print(f"HTTP 상태 코드: {response.status_code}") if response.status_code == 200: # 응답에 차단 표시가 있는지 확인 if "Sorry" not in response.text: return response.text else: print("죄송합니다, 요청이 차단되었습니다!") else: print(f"예상치 못한 HTTP 상태 코드: {response.status_code}") except Exception as e: print(f"데이터 가져오기 중 예외 발생: {e}") return None def extract_asins(self, html: str) -> set[str]: soup = BeautifulSoup(html, "lxml") containers = soup.find_all( "div", {"data-component-type": "s-search-result"}) new_asins = set() for container in containers: asin = container.get("data-asin") if asin and asin.strip(): new_asins.add(asin) return new_asins def save_to_csv(self, keyword: str): if not self.asins: print("저장할 ASIN이 없습니다") return # 결과 디렉터리가 존재하지 않으면 생성 os.makedirs("results", exist_ok=True) # 파일명 생성 csv_path = f"results/amazon_asins_{keyword.replace(' ', '_')}.csv" # CSV로 저장 with open(csv_path, 'w') as f: f.write("asinn") for asin in sorted(self.asins): f.write(f"{asin}n") print(f"ASIN 저장 위치: {csv_path}") async def main(): scraper = AsinScraper() keyword = "노트북" max_pages = 5 for page in range(1, max_pages + 1): print(f"페이지 {page} 스크래핑 중...") html = await scraper.fetch_page(scraper.create_url(keyword, page)) if not html: print(f"페이지 {page} 가져오기 실패") break new_asins = scraper.extract_asins(html) if new_asins: scraper.asins.update(new_asins) print(f"페이지 {page}에서 {len(new_asins)}개의 ASIN 발견. 총 ASIN 수: {len(scraper.asins)}") else: print("더 이상 ASIN을 찾지 못했습니다. 스크래핑을 종료합니다.") break # 결과를 CSV로 저장 scraper.save_to_csv(keyword) if __name__ == "__main__": asyncio.run(main())
그렇다면 아마존 ASIN 스크래핑을 위한 해결책은 무엇일까요? 가장 신뢰할 수 있는 방법은 최고의 프록시 제공업체의 주거용 프록시와 적절한 HTTP 헤더를 함께 사용하는 것입니다.
Bright Data 프록시를 사용한 아마존 ASIN 스크래핑
Bright Data는 글로벌 프록시 네트워크를 보유한 선도적인 프록시 제공업체입니다. 공유 서버와 전용 서버 모두에서 다양한 유형의 프록시를 제공하여 광범위한 사용 사례를 지원합니다. 이 서버들은 HTTP, HTTPS 및 SOCKS 프로토콜을 사용하여 트래픽을 라우팅할 수 있습니다.
아마존 스크래핑에 Bright Data를 선택해야 하는 이유
- 방대한 IP 네트워크: 195개국에 걸쳐 400M+ monthly개의 IP에 접근 가능
- 정밀한 지리적 위치 타겟팅: 특정 도시, 우편번호, 심지어 통신사까지 타겟팅 가능
- 다양한 프록시 유형: 주거용, 데이터센터, 모바일 또는 ISP 프록시 중에서 선택 가능
- 높은 신뢰성: 99.9% 성공률, 선택 가능한 100% 가동 시간 보장
- 유연한 확장성: 모든 규모의 기업을 위한 종량제 옵션 제공
아마존 스크래핑을 위한 Bright Data 설정
Amazon ASIN 스크래핑에 Bright Data 프록시를 사용하려면 다음 간단한 단계를 따르세요:
1단계: Bright Data 가입
Bright Data 웹사이트를 방문하여 계정을 생성하세요. 이미 계정이 있다면 다음 단계로 진행하세요.
2단계: 새 프록시 영역 생성
로그인 후 ‘프록시 및 스크래핑 인프라’ 섹션으로 이동하여 ‘추가’를 클릭해 새 프록시 영역을 생성하세요. 실제 기기 IP를 사용하므로 스크래핑 방지 제한을 피하는 데 가장 적합한 ‘레지던셜 프록시’를 선택하세요.
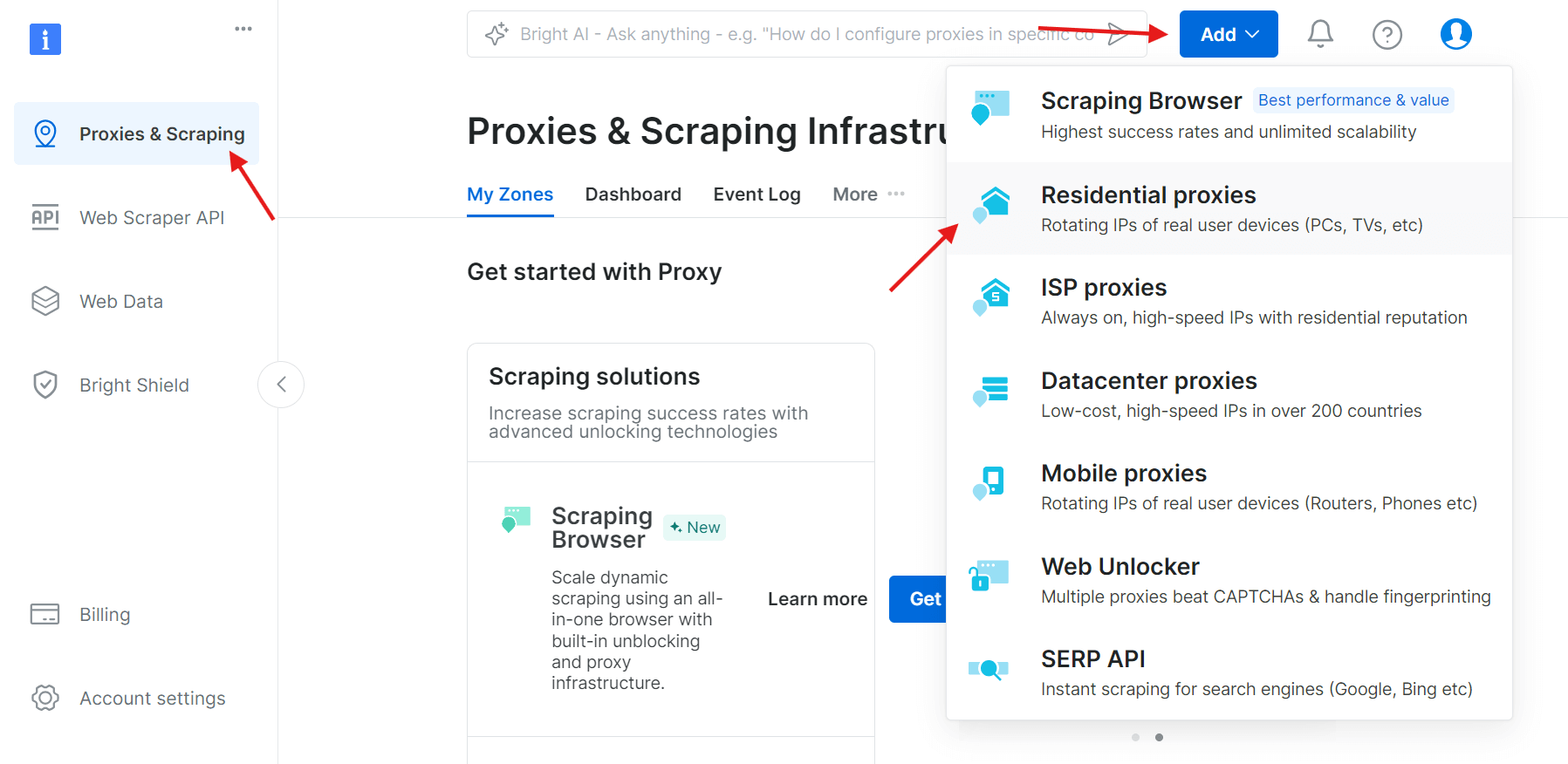
3단계: 프록시 설정 구성
브라우징할 지역 또는 국가를 선택하세요. 영역에 적절한 이름을 지정하세요(예: “asin_scraping”).
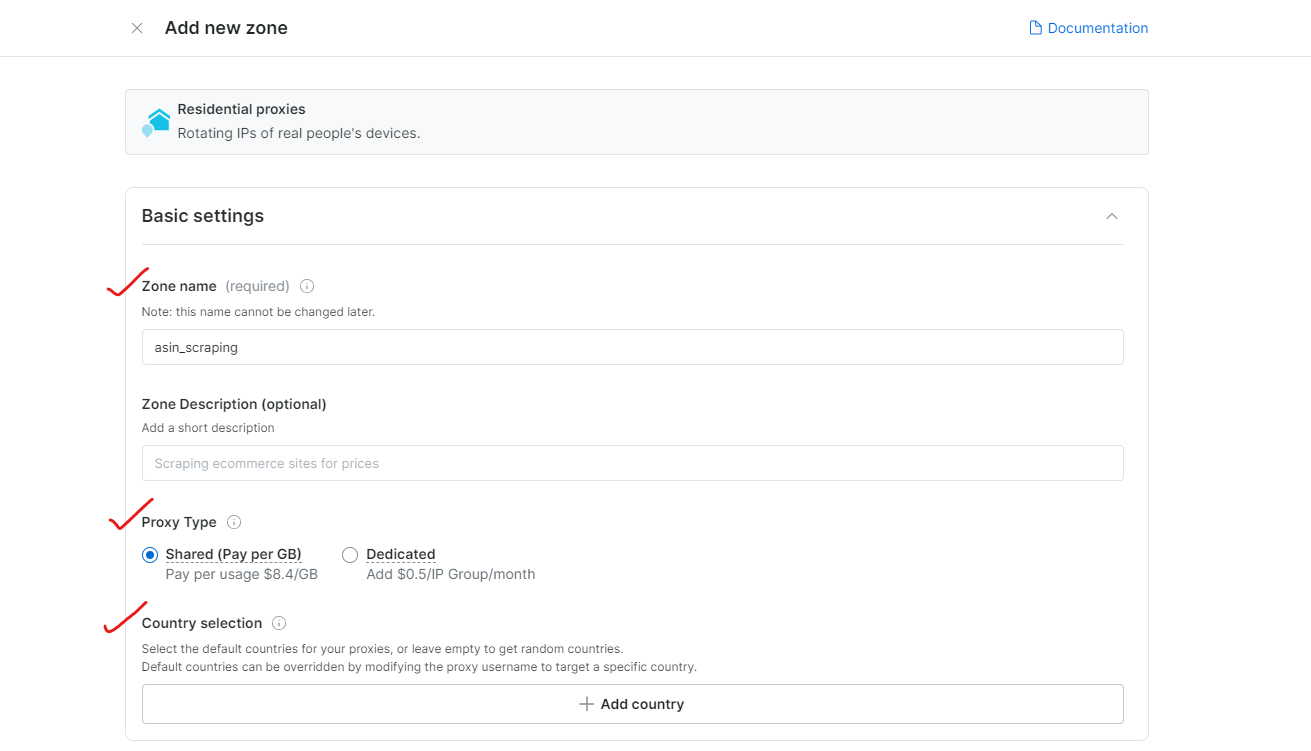
Bright Data는 도시 또는 우편번호 단위까지 정밀한 지리적 위치 타겟팅을 지원합니다.
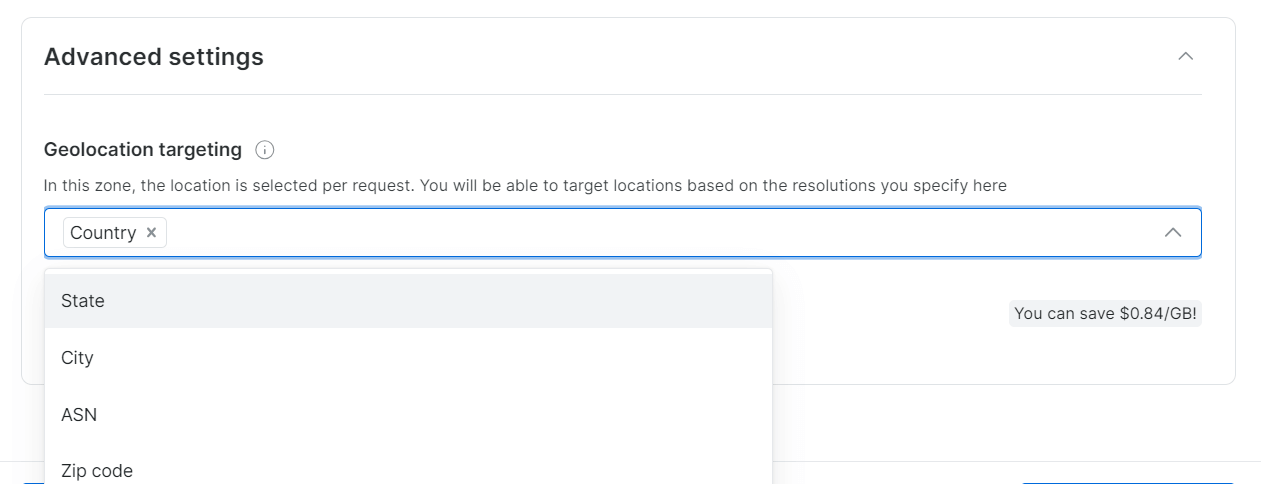
4단계: KYC 인증 완료
Bright Data의 주거용 프록시를 완전히 이용하려면 KYC 인증 절차를 완료하세요.
5단계: 프록시 사용 시작
프록시 영역이 생성되면 스크래핑을 시작할 수 있는 자격 증명(호스트, 포트, 사용자 이름, 비밀번호)이 표시됩니다.
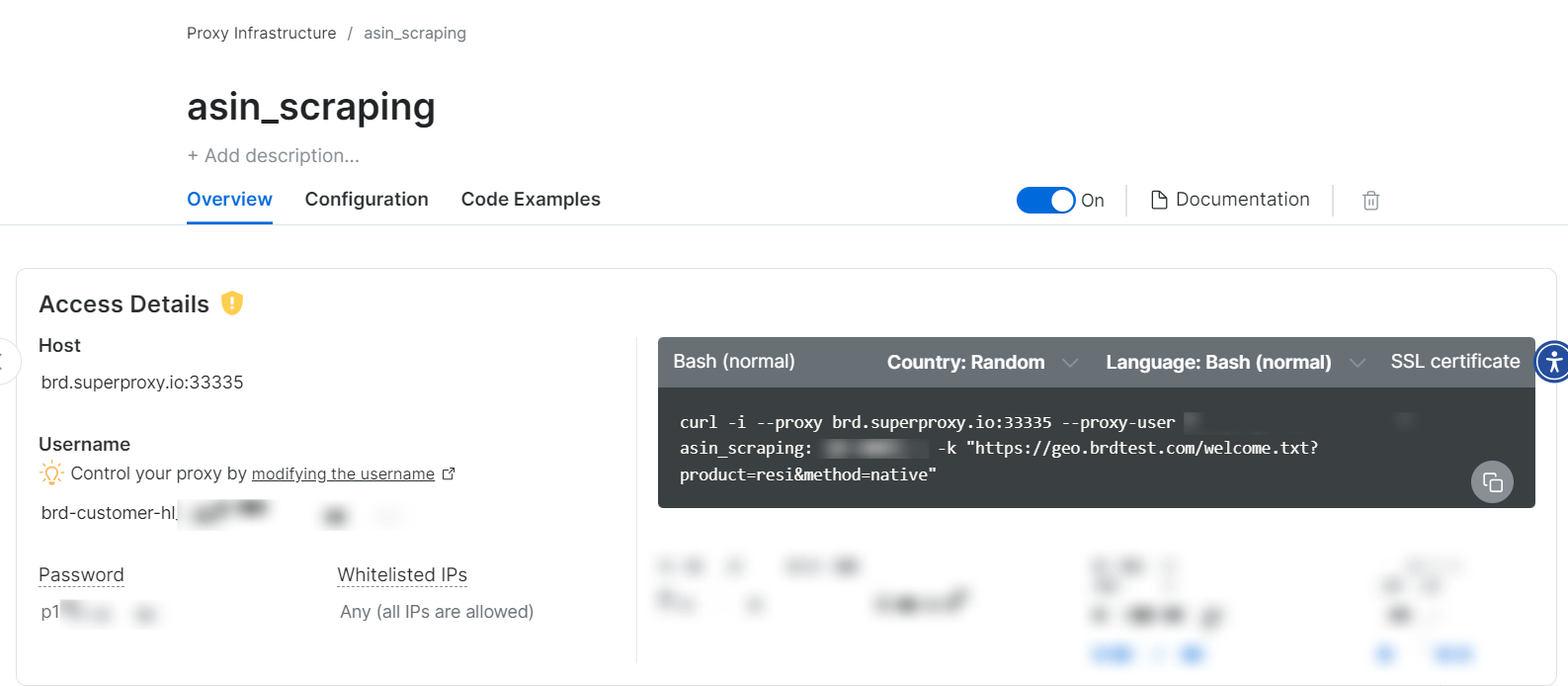
네, 정말 간단합니다!
스크레이퍼 구현
1단계: 브라우저 헤더 설정
headers = {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8",
"accept-language": "en-US,en;q=0.9",
"sec-ch-ua": '"Chromium";v="119", "Not?A_Brand";v="24"',
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": '"Windows"',
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "none",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36",
}
2단계: 프록시 설정 구성
proxy_config = {
"username": "YOUR_USERNAME",
"password": "YOUR_PASSWORD",
"server": "brd.superproxy.io:33335",
}
proxy_url = f"http://{proxy_config['username']}:{proxy_config['password']}@{proxy_config['server']}"
3단계: 요청 수행
curl_cffi 라이브러리를 사용하여 헤더와 프록시를 포함한 요청을 수행합니다:
response = session.get(
url,
headers=headers,
impersonate="chrome120",
proxies={"http": proxy_url, "https": proxy_url},
timeout=30,
verify=False,
)
참고: curl_cffi 라이브러리는 웹 스크래핑에 탁월한 선택으로, 표준 requests 라이브러리를 능가하는 고급 브라우저 임페르소네이션 기능을 제공합니다.
4단계: 스크레이퍼 실행
스크레이퍼를 실행하려면 대상 키워드를 구성해야 합니다. 예시는 다음과 같습니다:
keywords = [
"coffee maker",
"office desk",
"cctv camera"
]
max_pages = None # 모든 페이지를 처리하려면 None으로 설정
전체 코드는 여기에서 확인하세요.
스크레이퍼는 다음 내용을 포함한 CSV 파일로 결과를 출력합니다:
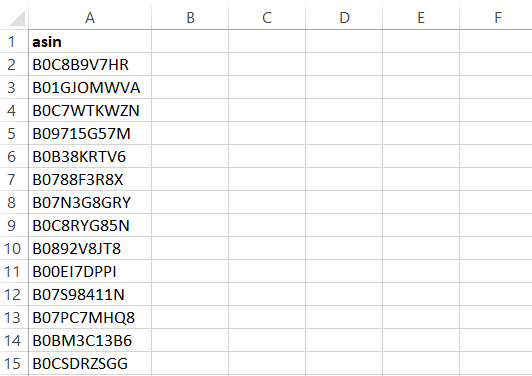
Bright Data Amazon 스크레이퍼 API를 사용한 ASIN 추출
프록시 기반 스크래핑도 가능하지만, Bright Data Amazon Scraper API를 사용하면 다음과 같은 상당한 이점이 있습니다:
- 인프라 관리 불필요: 프록시, IP 로테이션, 캡차 걱정 없음
- 지리적 위치 스크래핑: 모든 지역에서 스크래핑 가능
- 간편한 통합: 모든 프로그래밍 언어로 몇 분 안에 구현 가능
- 다양한 데이터 전송 옵션: 아마존 S3(), 구글 클라우드, 애저, 스노우플레이크(Snowflake), SFTP
- Amazon S3, Google Cloud, Azure, Snowflake 또는 SFTP로 내보내기
- JSON, NDJSON, CSV 또는 .gz 형식으로 데이터 획득
- GDPR 및 CCPA 준수: 윤리적인 웹 스크래핑을 위한 개인정보 보호 규정 준수 보장
- 20회 무료 API 호출: 서비스 사용 전 테스트 가능
- 연중무휴 24시간 지원: API 관련 질문이나 문제 해결을 위한 전담 지원
Amazon Scraper API 설정하기
API 설정은 간단하며 몇 단계로 완료할 수 있습니다.
1단계: API에 접근하기
웹 스크레이퍼 API로 이동하여 사용 가능한 API에서 “amazon products search”를 검색하세요:
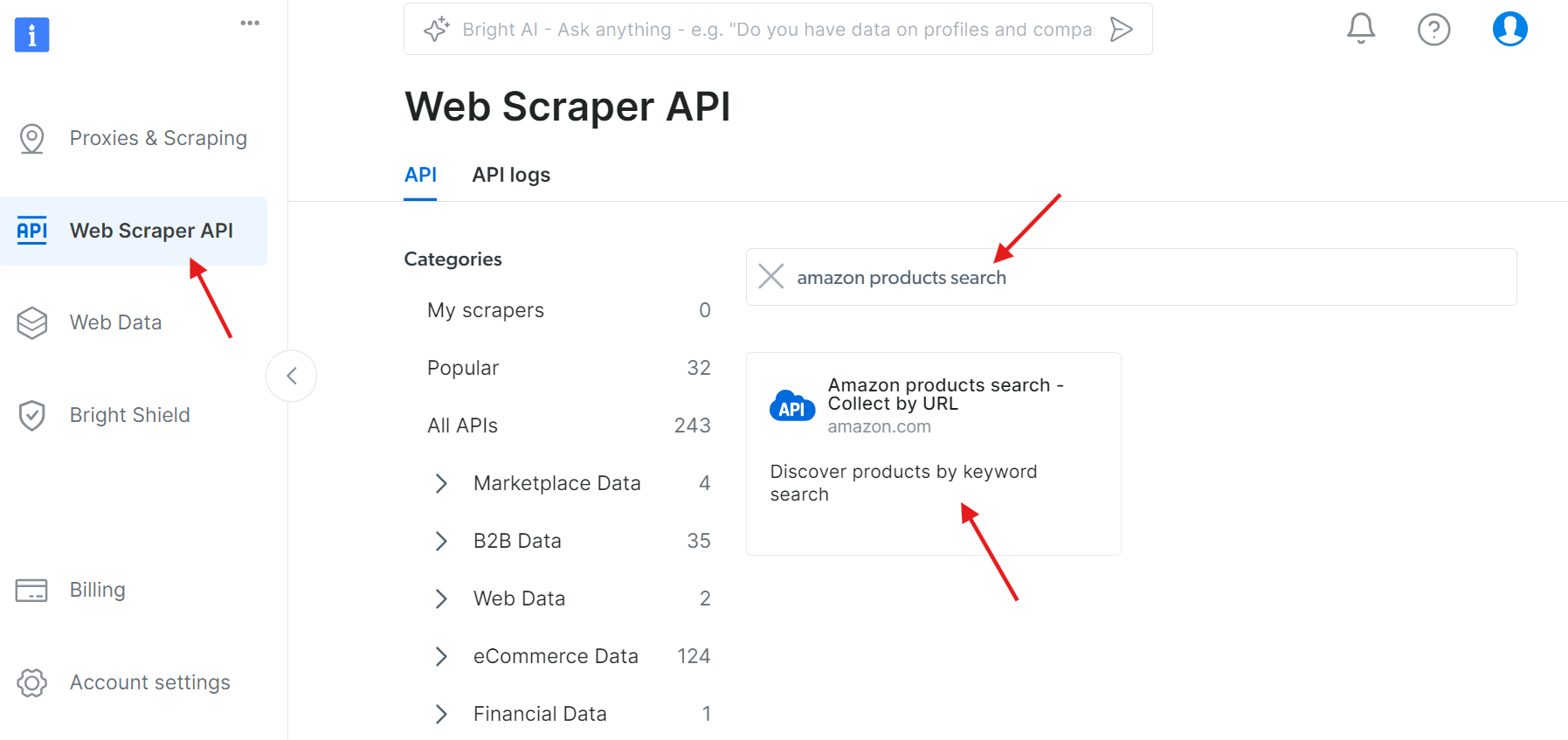
“API 호출 설정 시작”을 클릭하세요:
단계 2: API 토큰 획득
“API 토큰 받기”를 클릭하세요:
“토큰 추가”를 선택하세요:
새 API 토큰을 안전하게 저장하세요:
단계 3: 데이터 수집 구성
데이터 수집 API 탭에서:
- 제품 검색을 위한 키워드 지정
- 대상 아마존 도메인 설정
- 스크래핑할 페이지 수 정의
- 추가 필터 (선택 사항)
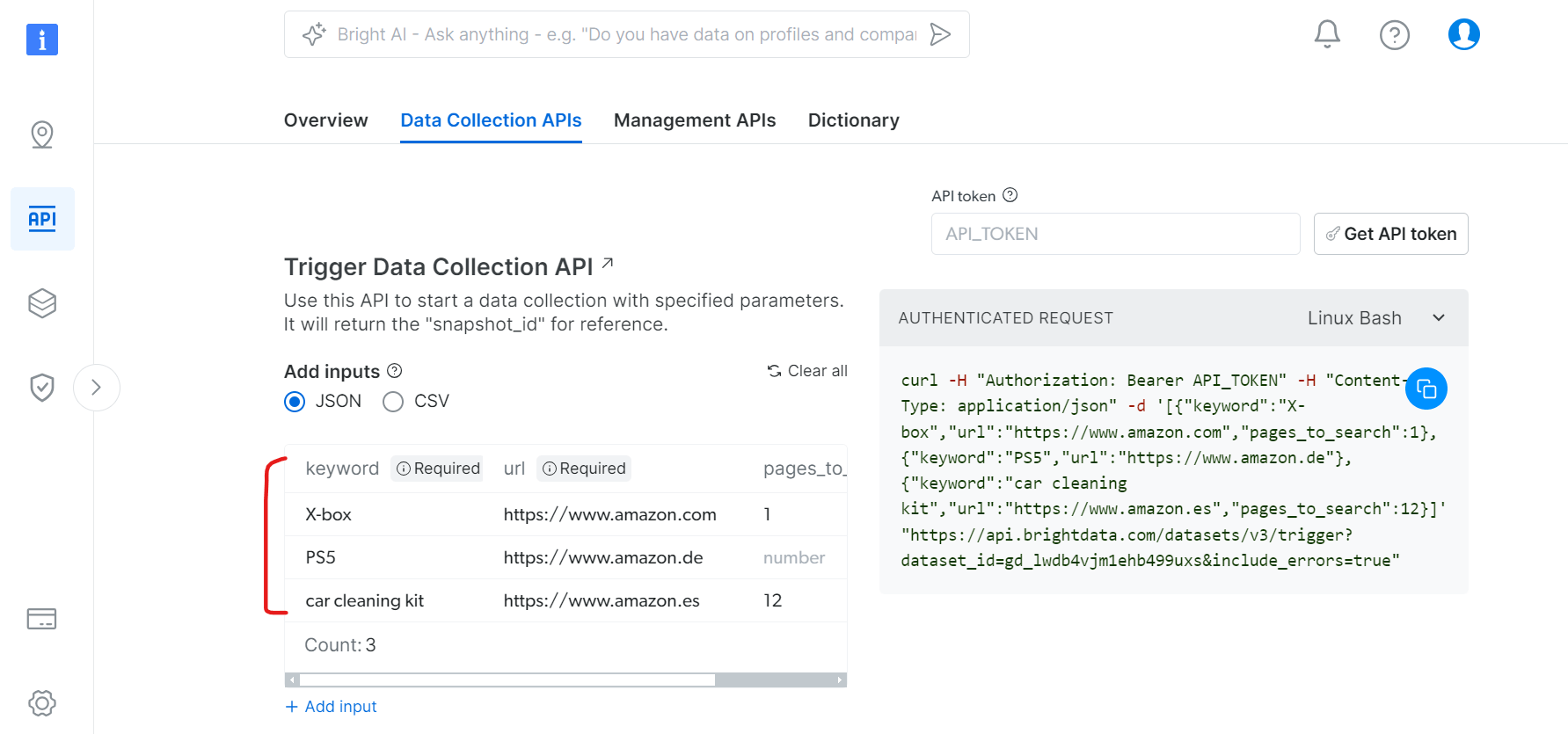
Python을 사용한 API 활용
데이터 수집을 트리거하고 결과를 가져오는 Python 스크립트 예시:
import json
import requests
import time
from typing import Dict, List, Optional, Union, Tuple
from datetime import datetime, timedelta
import logging
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
from enum import Enum
class SnapshotStatus(Enum):
SUCCESS = "success"
PROCESSING = "processing"
FAILED = "failed"
TIMEOUT = "timeout"
class BrightDataAmazonScraper:
def __init__(self, api_token: str, dataset_id: str):
self.api_token = api_token
self.dataset_id = dataset_id
self.base_url = "https://api.brightdata.com/datasets/v3"
self.headers = {
"Authorization": f"Bearer {api_token}",
"Content-Type": "application/json",
}
# 사용자 정의 형식으로 로깅 설정
logging.basicConfig(
level=logging.INFO,
format='%(message)s' # 메시지만 표시하는 간소화된 형식
)
self.logger = logging.getLogger(__name__)
# 재시도 전략을 적용한 세션 설정
self.session = self._create_session()
# 진행 상황 추적
self.last_progress_update = 0
def _create_session(self) -> requests.Session:
"""재시도 전략을 가진 세션 생성"""
session = requests.Session()
retry_strategy = Retry(
total=3,
backoff_factor=0.5,
status_forcelist=[500, 502, 503, 504]
)
adapter = HTTPAdapter(max_retries=retry_strategy)
session.mount("https://", adapter)
session.mount("http://", adapter)
return session
def trigger_collection(self, datasets: List[Dict]) -> Optional[str]:
"""지정된 데이터셋에 대한 데이터 수집을 트리거합니다"""
trigger_url = f"{self.base_url}/trigger?dataset_id={self.dataset_id}"
try:
response = self.session.post(
trigger_url,
headers=self.headers,
json=datasets
)
response.raise_for_status()
snapshot_id = response.json().get("snapshot_id")
if snapshot_id:
self.logger.info("Amazon 데이터 수집 초기화 중...")
return snapshot_id
else:
self.logger.error("데이터 수집 초기화에 실패했습니다.")
return None
except requests.exceptions.RequestException as e:
self.logger.error(f"컬렉션 초기화 실패: {str(e)}")
return None
def check_snapshot_status(self, snapshot_id: str) -> Tuple[SnapshotStatus, Optional[Dict]]:
"""스냅샷의 현재 상태 확인"""
snapshot_url = f"{self.base_url}/snapshot/{snapshot_id}?format=json"
try:
response = self.session.get(snapshot_url, headers=self.headers)
if response.status_code == 200:
return SnapshotStatus.SUCCESS, response.json()
elif response.status_code == 202:
return SnapshotStatus.PROCESSING, None
else:
return SnapshotStatus.FAILED, None
except requests.exceptions.RequestException:
return SnapshotStatus.FAILED, None
def wait_for_snapshot_data(
self,
snapshot_id: str,
timeout: Optional[int] = None,
check_interval: int = 10,
max_interval: int = 300,
callback=None
) -> Optional[Dict]:
"""최소한의 콘솔 출력으로 스냅샷 데이터를 기다립니다"""
start_time = datetime.now()
current_interval = check_interval
attempts = 0
progress_shown = False
while True:
attempts += 1
if timeout is not None:
elapsed_time = (datetime.now() - start_time).total_seconds()
if elapsed_time >= timeout:
self.logger.error("데이터 수집 시간 초과.")
return None
status, data = self.check_snapshot_status(snapshot_id)
if status == SnapshotStatus.SUCCESS:
self.logger.info(
"Amazon 데이터 수집이 성공적으로 완료되었습니다!")
return data
elif status == SnapshotStatus.FAILED:
self.logger.error("데이터 수집 중 오류가 발생했습니다.")
return None
elif status == SnapshotStatus.PROCESSING:
# 30초마다 진행률 표시기만 표시
current_time = time.time()
if not progress_shown:
self.logger.info("Amazon에서 데이터 수집 중...")
progress_shown = True
elif current_time - self.last_progress_update >= 30:
self.logger.info("데이터 수집 진행 중...")
self.last_progress_update = current_time
if callback:
callback(attempts, (datetime.now() -
start_time).total_seconds())
time.sleep(current_interval)
current_interval = min(current_interval * 1.5, max_interval)
def store_data(self, data: Dict, filename: str = "amazon_data.json") -> None:
"""수집된 데이터를 JSON 파일에 저장"""
if data:
try:
with open(filename, "w", encoding='utf-8') as file:
json.dump(data, file, indent=4, ensure_ascii=False)
self.logger.info(f"데이터가 {filename}에 성공적으로 저장되었습니다")
except IOError as e:
self.logger.error(f"데이터 저장 오류: {str(e)}")
else:
self.logger.warning("저장할 데이터가 없습니다.")
def progress_callback(attempts: int, elapsed_time: float):
"""최소한의 콜백 함수 - 필요에 따라 커스터마이징 가능"""
pass # 기본적으로 무음 처리
def main():
# 구성
API_TOKEN = "YOUR_API_TOKEN"
DATASET_ID = "gd_lwdb4vjm1ehb499uxs"
# 스크레이퍼 초기화
scraper = BrightDataAmazonScraper(API_TOKEN, DATASET_ID)
# 검색 매개변수 정의
datasets = [
{"keyword": "X-box", "url": "https://www.amazon.com", "pages_to_search": 1},
{"keyword": "PS5", "url": "https://www.amazon.de"},
{"keyword": "car cleaning kit",
"url": "https://www.amazon.es", "pages_to_search": 4},
]
# 스크래핑 프로세스 실행
snapshot_id = scraper.trigger_collection(datasets)
if snapshot_id:
data = scraper.wait_for_snapshot_data(
snapshot_id,
timeout=None,
check_interval=10,
max_interval=300,
callback=progress_callback
)
if data:
scraper.store_data(data)
print("n스크래핑 프로세스 성공적으로 완료되었습니다!n")
if __name__ == "__main__":
main()
이 코드를 실행하려면 다음 값을 반드시 실제 API 토큰으로 교체하십시오:
API_TOKEN을실제 API 토큰으로 교체하십시오.- 검색하려는 상품 또는 키워드를 포함하도록
데이터셋목록을 수정하세요.
검색된 데이터의 JSON 구조 예시:
{
"asin": "B0CJ3XWXP8",
"url": "https://www.amazon.com/Xbox-X-Console-Renewed/dp/B0CJ3XWXP8/ref=sr_1_1",
"name": "Xbox Series X Console (Renewed) Xbox Series X Console (Renewed)Sep 15, 2023",
"sponsored": "false",
"initial_price": 449.99,
"final_price": 449.99,
"currency": "USD",
"sold": 2000,
"rating": 4.1,
"평점 수": 1529,
"변형": null,
"배지": null,
"사업 유형": null,
"브랜드": null,
"배송": ["무료 배송 12월 1일 일요일", "또는 가장 빠른 배송 11월 29일 금요일"],
"keyword": "X-box",
"image": "https://m.media-amazon.com/images/I/51ojzJk77qL._AC_UY218_.jpg",
"domain": "https://www.amazon.com/",
"지난달_구매량": 2000,
"페이지_번호": 1,
"페이지_순위": 1,
"타임스탬프": "2024-11-26T05:15:24.590Z",
"input": {
"keyword": "X-box",
"url": "https://www.amazon.com",
"pages_to_search": 1,
},
}
이 샘플 JSON 파일을 다운로드하여 전체 출력을 확인할 수 있습니다.
결론
Python을 사용한 Amazon ASIN 수집 과정을 살펴보았지만, 그 과정에서 여러 가지 문제점도 마주쳤습니다. CAPTCHA나 속도 제한 같은 문제는 데이터 수집 작업을 크게 방해할 수 있습니다. 해결책으로 Bright Data의 프록시나 Amazon Scraper API 같은 도구를 사용할 수 있습니다. 이러한 옵션은 프로세스 속도를 높이고 일반적인 장애물을 우회하는 데 도움이 됩니다. 스크래핑 도구 설정의 번거로움을 완전히 피하고 싶다면, Bright Data는 즉시 사용할 수 있는 완성된 Amazon 데이터셋도 제공합니다.
지금 가입하고 무료 체험을 시작하세요!





