

이 실습 튜토리얼에서는 Playwright Python을 사용하여 Glassdoor에서 데이터를 스크래핑하는 방법을 배웁니다. 또한 Glassdoor가 사용하는 스크래핑 방지 기술과 Bright Data가 어떻게 도움이 되는지 알아봅니다. Glassdoor 스크래핑을 훨씬 빠르게 만드는 Bright Data 솔루션에 대해서도 배울 수 있습니다.
스크래핑은 건너뛰고, 데이터만 얻으세요
스크래핑 과정을 건너뛰고 직접 데이터에 접근하고 싶으신가요? 저희 Glassdoor 데이터셋을 살펴보시기 바랍니다.
Glassdoor 데이터셋은 직무와 기업에 대한 통찰력을 제공하는 리뷰 및 FAQ가 포함된 완전한 기업 개요를 제공합니다. Glassdoor 데이터셋을 활용하여 기업에 대한 시장 동향 및 비즈니스 정보를 찾고, 현재 및 과거 직원들이 기업을 어떻게 인식하고 평가하는지 파악할 수 있습니다. 요구 사항에 따라 전체 데이터셋 또는 맞춤형 하위 집합을 구매할 수 있습니다.
데이터셋은 JSON, NDJSON, JSON Lines, CSV, Parquet 등의 형식으로 제공되며, 선택적으로 .gz 파일로 압축할 수도 있습니다.
글래스도어 스크래핑은 합법인가요?
예, Glassdoor에서 데이터를 스크래핑하는 것은 합법적입니다. 다만 Glassdoor의 서비스 약관, robots.txt 파일 및 개인정보 보호정책을 준수하며 윤리적으로 수행되어야 합니다. 가장 큰 오해 중 하나는 회사 리뷰나 채용 공고 같은 공개 데이터를 스크래핑하는 것이 불법이라는 것입니다. 그러나 이는 사실이 아닙니다. 법적·윤리적 한도 내에서 수행되어야 합니다.
글래스도어 데이터 스크래핑 방법
Glassdoor는 콘텐츠 렌더링에 JavaScript를 사용하므로 스크래핑이 더 복잡해질 수 있습니다. 이를 처리하려면 JavaScript를 실행하고 브라우저처럼 웹페이지와 상호작용할 수 있는 도구가 필요합니다. 대표적인 선택지로는 Playwright, Puppeteer, Selenium 등이 있습니다. 본 튜토리얼에서는 Playwright Python을 사용할 것입니다.
이제 Glassdoor 스크레이퍼를 처음부터 만들어 보겠습니다! Playwright를 처음 접하는 분이든 이미 익숙하신 분이든, 이 튜토리얼은 Playwright Python을 사용해 웹 스크레이퍼를 구축하는 데 도움을 드리기 위해 마련되었습니다.
작업 환경 설정
시작하기 전에 컴퓨터에 다음 환경이 설정되어 있는지 확인하세요:
- 공식 웹사이트
- Visual Studio Code
다음으로 터미널을 열고 Python 프로젝트용 새 폴더를 생성한 후 해당 폴더로 이동하세요:
mkdir glassdoor-scraper
cd glassdoor-scraper
가상 환경 생성 및 활성화:
python -m venv glassdoorenv
glassdoorenvScriptsactivate
Playwright 설치:
pip install playwright
그런 다음 브라우저 바이너리를 설치합니다:
playwright install
설치에 시간이 다소 소요될 수 있으니 기다려 주십시오.
전체 설정 과정은 다음과 같습니다:
이제 설정이 완료되었으며 Glassdoor 스크래퍼 코드 작성을 시작할 준비가 되었습니다!
Glassdoor 웹사이트 구조 이해하기
Glassdoor 스크래핑을 시작하기 전에 사이트 구조를 이해하는 것이 중요합니다. 본 튜토리얼에서는 특정 지역에 위치한 기업 중 특정 직무를 가진 회사 정보를 스크래핑하는 방법에 집중하겠습니다.
예를 들어, 뉴욕 시에 위치한 기업 중 머신러닝 직무를 제공하며 종합 평점이 3.5 이상인 기업을 찾고자 한다면, 검색에 적절한 필터를 적용해야 합니다.
글래스도어 기업 페이지를 살펴보세요:

이제 원하는 필터를 적용하여 많은 기업 목록을 확인할 수 있으며, 어떤 구체적인 데이터를 수집할지 궁금하실 수 있습니다. 다음에 살펴보겠습니다!
핵심 데이터 포인트 식별
Glassdoor에서 데이터를 효과적으로 수집하려면 스크래핑하려는 콘텐츠를 식별해야 합니다.
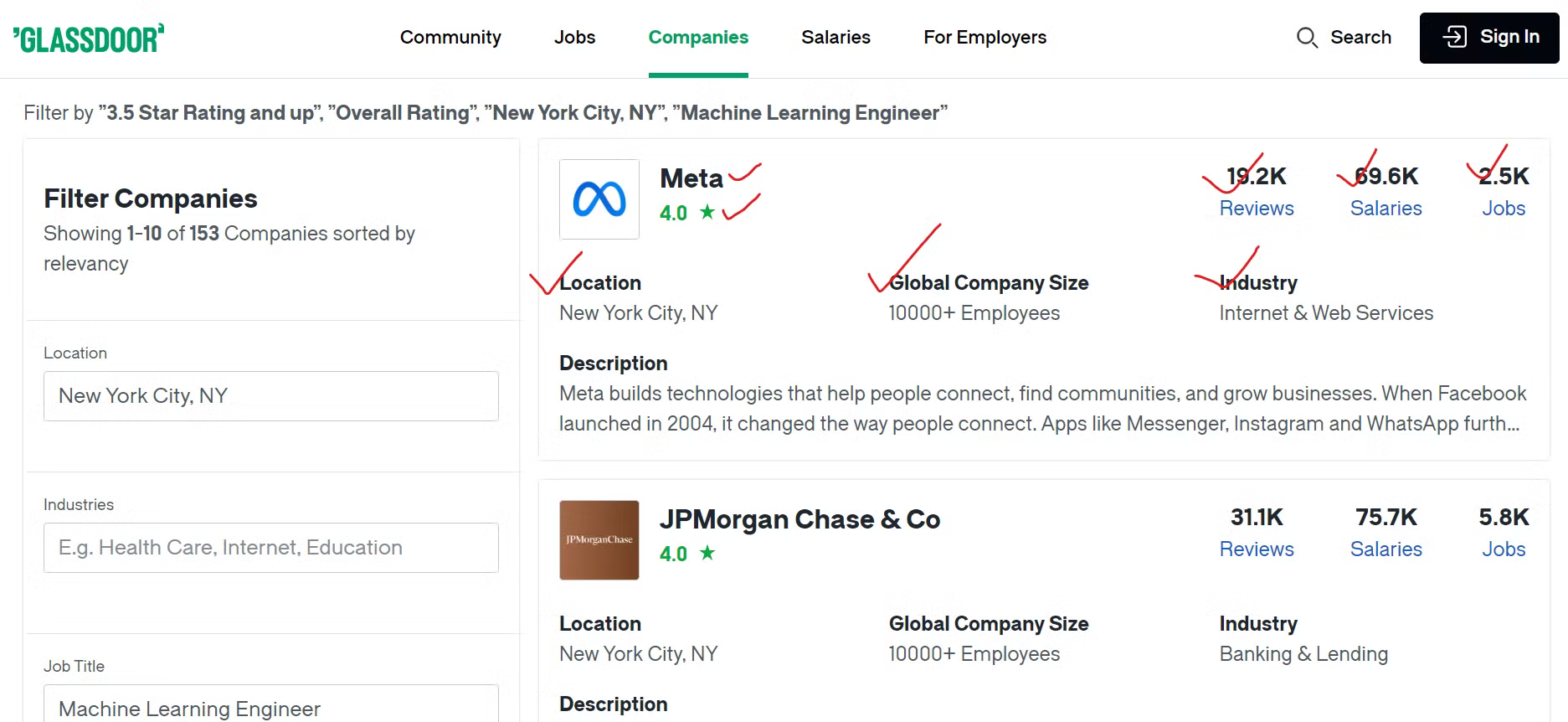
각 기업에 대해 회사명, 채용 공고 링크, 총 채용 공고 수 등 다양한 세부 정보를 추출합니다. 또한 직원 리뷰 수, 보고된 급여 건수, 해당 기업의 업종도 스크래핑합니다. 더불어 기업의 지리적 위치와 전 세계 총 직원 수 역시 추출할 예정입니다.
글래스도어 스크래퍼 구축
스크래핑할 데이터를 확인했으니, 이제 Playwright Python을 사용해 스크래퍼를 구축할 차례입니다.
아래 이미지와 같이 Glassdoor 웹사이트를 검사하여 회사명과 평점 요소를 찾아보는 것으로 시작하세요:
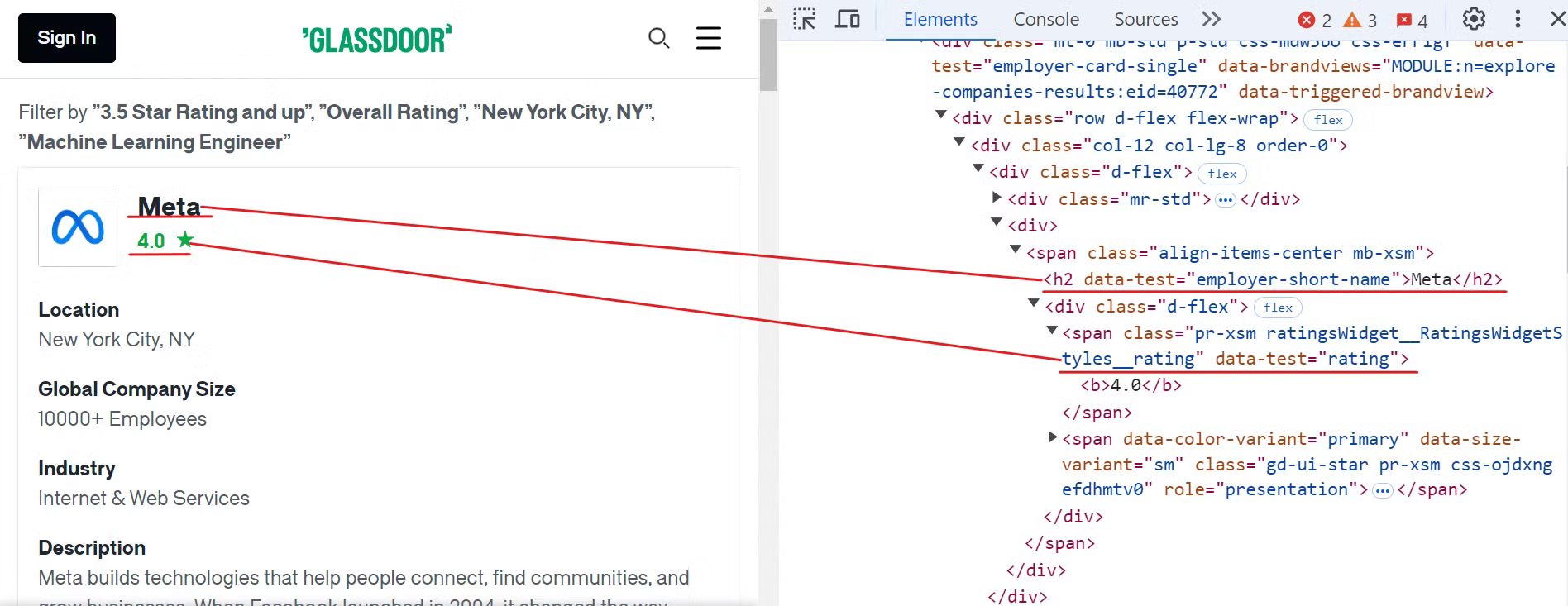
이 데이터를 추출하려면 다음 CSS 선택자를 사용할 수 있습니다:
[data-test="employer-short-name"]
[data-test="rating"]
마찬가지로, 아래 이미지와 같이 간단한 CSS 선택자를 사용하여 다른 관련 데이터를 추출할 수 있습니다:
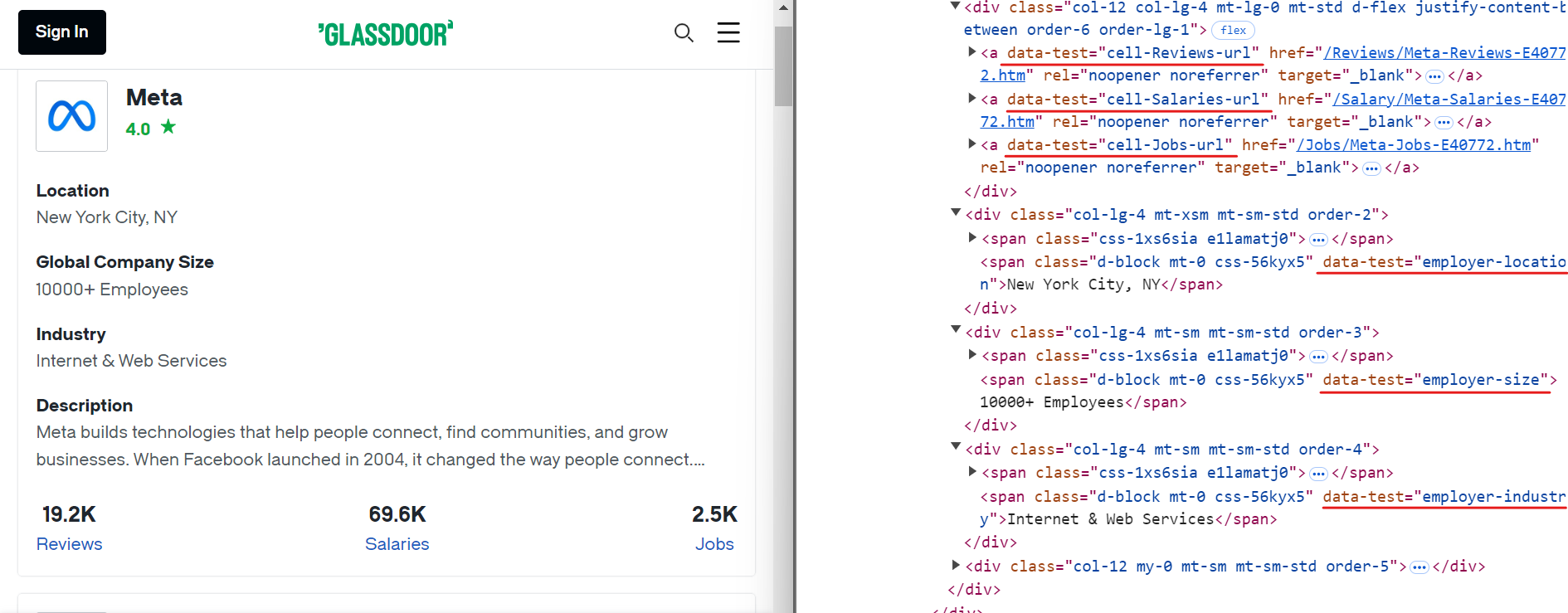
추가 데이터 추출에 사용할 수 있는 CSS 선택자는 다음과 같습니다:
[data-test="employer-location"] /* 회사의 지리적 위치 */
[data-test="employer-size"] /* 전 세계 직원 수 */
[data-test="employer-industry"] /* 회사가 운영하는 산업 분야 */
[data-test="cell-Jobs-url"] /* 회사 채용 공고 링크 */
[data-test="cell-Jobs"] h3 /* 총 채용 공고 수 */
[data-test="cell-Reviews"] h3 /* 직원 리뷰 수 */
[data-test="cell-Salaries"] h3 /* 보고된 급여 수 */
다음으로 glassdoor. py라는 새 파일을 생성하고 다음 코드를 추가하세요:
import asyncio
from urllib.parse import urlencode, urlparse
from playwright.async_api import async_playwright, Playwright
async def scrape_data(playwright: Playwright):
# Chromium 브라우저 인스턴스 실행
browser = await playwright.chromium.launch(headless=False)
page = await browser.new_page()
# Glassdoor 검색을 위한 기본 URL 및 쿼리 매개변수 정의
base_url = "https://www.glassdoor.com/Explore/browse-companies.htm?"
query_params = {
"overall_rating_low": "3.5",
"locId": "1132348",
"locType": "C",
"locName": "New York, NY (US)",
"occ": "Machine Learning Engineer",
"filterType": "RATING_OVERALL",
}
# 쿼리 매개변수를 포함한 전체 URL 생성 및 이동
url = f"{base_url}{urlencode(query_params)}"
await page.goto(url)
# 추출된 레코드 카운터 초기화
record_count = 0
# 페이지의 모든 회사 카드 찾기 및 데이터 추출을 위한 반복 처리
company_cards = await page.locator('[data-test="employer-card-single"]').all()
for card in company_cards:
try:
# 각 회사 카드에서 관련 데이터 추출
company_name = await card.locator('[data-test="employer-short-name"]').text_content(timeout=2000) or "N/A"
rating = await card.locator('[data-test="rating"]').text_content(timeout=2000) or "N/A"
location = await card.locator('[data-test="employer-location"]').text_content(timeout=2000) or "N/A"
global_company_size = await card.locator('[data-test="employer-size"]').text_content(timeout=2000) or "N/A"
industry = await card.locator('[data-test="employer-industry"]').text_content(timeout=2000) or "N/A"
# 채용 공고용 URL 생성
jobs_url_path = await card.locator('[data-test="cell-Jobs-url"]').get_attribute("href", timeout=2000) or "N/A"
parsed_url = urlparse(base_url)
jobs_url_path = f"{parsed_url.scheme}://{parsed_url.netloc}{jobs_url_path}"
# 채용 공고, 리뷰, 급여에 대한 추가 데이터 추출
jobs_count = await card.locator('[data-test="cell-Jobs"] h3').text_content(timeout=2000) or "N/A"
reviews_count = await card.locator('[data-test="cell-Reviews"] h3').text_content(timeout=2000) or "N/A"
salaries_count = await card.locator('[data-test="cell-Salaries"] h3').text_content(timeout=2000) or "N/A"
# 추출된 데이터 출력
print({
"회사명": company_name,
"평점": rating,
"채용 공고 URL": jobs_url_path,
"Jobs Count": jobs_count,
"Reviews Count": reviews_count,
"Salaries Count": salaries_count,
"Industry": industry,
"Location": location,
"Global Company Size": global_company_size,
})
기록_수 += 1
except Exception as e:
print(f"회사 데이터 추출 오류: {e}")
print(f"추출된 총 기록 수: {기록_수}")
# 브라우저 닫기
await browser.close()
# 스크립트의 진입점
async def main():
async with async_playwright() as playwright:
await scrape_data(playwright)
if __name__ == "__main__":
asyncio.run(main())
이 코드는 특정 필터를 적용하여 회사 데이터를 스크래핑하는 Playwright 스크립트를 설정합니다. 예를 들어, 위치(뉴욕, NY), 평점(3.5+), 직책(머신러닝 엔지니어) 등의 필터를 적용합니다.
그런 다음 크로미움 브라우저 인스턴스를 실행하고, 이러한 필터가 포함된 글래스도어 URL로 이동하여 페이지의 각 회사 카드에서 데이터를 추출합니다. 데이터를 수집한 후 추출된 정보를 콘솔에 출력합니다.
그리고 출력 결과는 다음과 같습니다:

잘 했어요!
아직 문제가 있습니다. 현재 코드는 10개의 레코드만 추출하는데, 해당 페이지에는 약 150개의 레코드가 있습니다. 이는 스크립트가 첫 페이지의 데이터만 캡처한다는 것을 의미합니다. 더 많은 레코드를 추출하려면 다음 섹션에서 다루는 페이지네이션 처리를 구현해야 합니다.
페이지네이션 처리
Glassdoor의 각 페이지에는 약 10개 기업의 데이터가 표시됩니다. 사용 가능한 모든 레코드를 추출하려면 마지막 페이지에 도달할 때까지 각 페이지를 탐색하며 페이지네이션을 처리해야 합니다. 페이지네이션을 처리하려면 “다음” 버튼을 찾아 활성화 상태인지 확인한 후 클릭하여 다음 페이지로 이동해야 합니다. 더 이상 페이지가 없을 때까지 이 과정을 반복합니다.
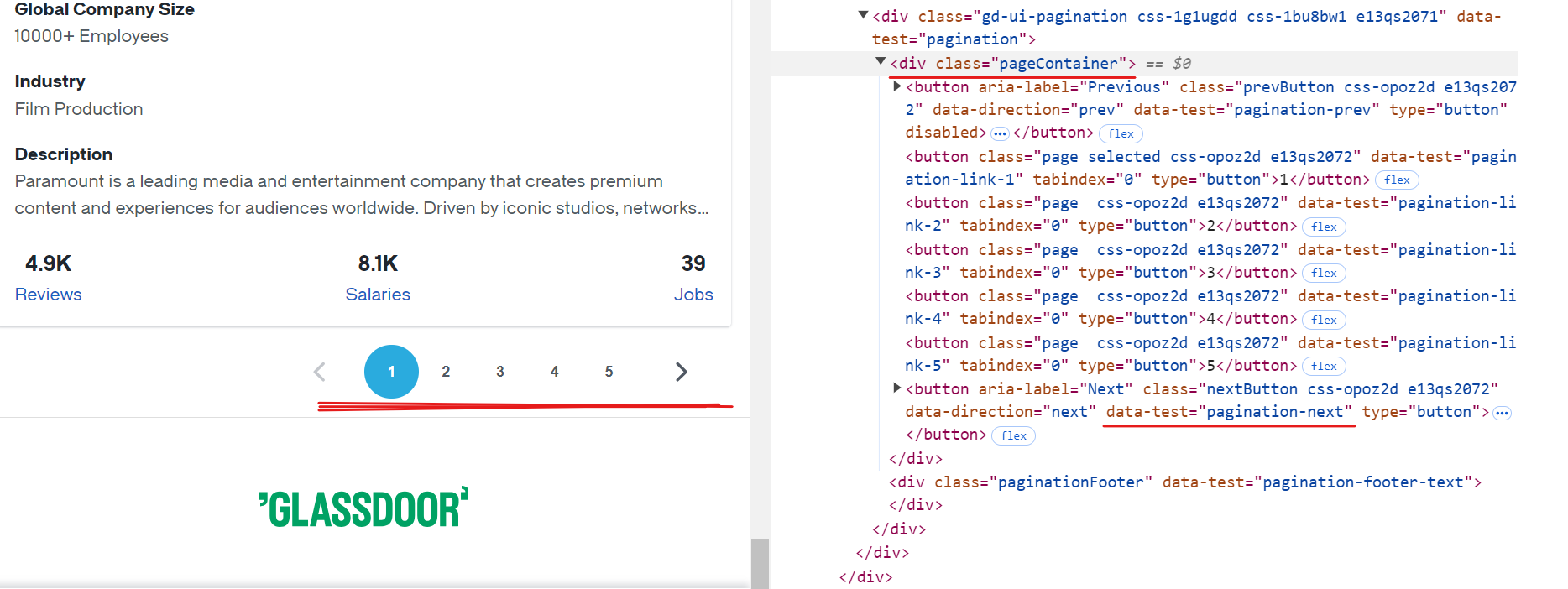
“다음” 버튼의 CSS 선택자는 [data-test="pagination-next"]이며, 위 이미지에서 볼 수 있듯이 pageContainer 클래스를 가진 <div> 태그 내에 위치합니다.
다음은 페이지네이션 처리 방법을 보여주는 코드 스니펫입니다:
while True:
# 진행 전에 페이지네이션 컨테이너가 표시되었는지 확인
await page.wait_for_selector(".pageContainer", timeout=3000)
# 페이지에서 "다음" 버튼 식별
next_button = page.locator('[data-test="pagination-next"]')
# "다음" 버튼이 비활성화되어 더 이상 페이지가 없는지 확인
is_disabled = await next_button.get_attribute("disabled") is not None
if is_disabled:
break # 더 이상 이동할 페이지가 없으면 중단
# 다음 페이지로 이동
await next_button.click()
await asyncio.sleep(3) # 페이지가 완전히 로드될 시간을 허용
수정된 코드는 다음과 같습니다:
import asyncio
from urllib.parse import urlencode, urlparse
from playwright.async_api import async_playwright, Playwright
async def scrape_data(playwright: Playwright):
# Chromium 브라우저 인스턴스 실행
browser = await playwright.chromium.launch(headless=False)
page = await browser.new_page()
# Glassdoor 검색을 위한 기본 URL 및 쿼리 매개변수 정의
base_url = "https://www.glassdoor.com/Explore/browse-companies.htm?"
query_params = {
"overall_rating_low": "3.5",
"locId": "1132348",
"locType": "C",
"locName": "New York, NY (US)",
"occ": "Machine Learning Engineer",
"filterType": "RATING_OVERALL",
}
# 쿼리 매개변수를 포함한 전체 URL 생성 및 이동
url = f"{base_url}{urlencode(query_params)}"
await page.goto(url)
# 추출된 레코드 카운터 초기화
record_count = 0
while True:
# 페이지 내 모든 회사 카드 위치 파악 후 데이터 추출
company_cards = await page.locator('[data-test="employer-card-single"]').all()
for card in company_cards:
try:
# 각 회사 카드에서 관련 데이터 추출
company_name = await card.locator('[data-test="employer-short-name"]').text_content(timeout=2000) or "N/A"
rating = await card.locator('[data-test="rating"]').text_content(timeout=2000) or "N/A"
location = await card.locator('[data-test="employer-location"]').text_content(timeout=2000) or "N/A"
global_company_size = await card.locator('[data-test="employer-size"]').text_content(timeout=2000) or "N/A"
industry = await card.locator('[data-test="employer-industry"]').text_content(timeout=2000) or "N/A"
# 채용 공고용 URL 생성
jobs_url_path = await card.locator('[data-test="cell-Jobs-url"]').get_attribute("href", timeout=2000) or "N/A"
parsed_url = urlparse(base_url)
jobs_url_path = f"{parsed_url.scheme}://{parsed_url.netloc}{jobs_url_path}"
# 채용 공고, 리뷰, 급여에 대한 추가 데이터 추출
jobs_count = await card.locator('[data-test="cell-Jobs"] h3').text_content(timeout=2000) or "N/A"
reviews_count = await card.locator('[data-test="cell-Reviews"] h3').text_content(timeout=2000) or "N/A"
salaries_count = await card.locator('[data-test="cell-Salaries"] h3').text_content(timeout=2000) or "N/A"
# 추출된 데이터 출력
print({
"Company": company_name,
"Rating": rating,
"Jobs URL": jobs_url_path,
"Jobs Count": jobs_count,
"Reviews Count": reviews_count,
"Salaries Count": salaries_count,
"Industry": industry,
"Location": location,
"Global Company Size": global_company_size,
})
기록_카운트 += 1
except Exception as e:
print(f"회사 데이터 추출 오류: {e}")
try:
# 진행 전에 페이지네이션 컨테이너가 표시되었는지 확인
await page.wait_for_selector(".pageContainer", timeout=3000)
# 페이지의 "다음" 버튼 식별
next_button = page.locator('[data-test="pagination-next"]')
# "다음" 버튼이 비활성화되어 더 이상 페이지가 없는지 확인
is_disabled = await next_button.get_attribute("disabled") is not None
if is_disabled:
break # 더 이상 이동할 페이지가 없으면 중단
# 다음 페이지로 이동
await next_button.click()
await asyncio.sleep(3) # 페이지가 완전히 로드될 시간을 허용
except Exception as e:
print(f"다음 페이지로 이동 중 오류: {e}")
break # 이동 오류 시 루프 종료
print(f"추출된 총 레코드 수: {record_count}")
# 브라우저 닫기
await browser.close()
# 스크립트 진입점
async def main():
async with async_playwright() as playwright:
await scrape_data(playwright)
if __name__ == "__main__":
asyncio.run(main())
결과는 다음과 같습니다:

좋아요! 이제 첫 페이지뿐만 아니라 모든 사용 가능한 페이지에서 데이터를 추출할 수 있습니다.
데이터를 CSV로 저장
데이터를 추출했으니, 추가 처리를 위해 CSV 파일로 저장해 보겠습니다. 이를 위해 Python의 csv 모듈을 사용할 수 있습니다. 아래는 스크랩한 데이터를 CSV 파일로 저장하는 업데이트된 코드입니다:
import asyncio
import csv
from urllib.parse import urlencode, urlparse
from playwright.async_api import async_playwright, Playwright
async def scrape_data(playwright: Playwright):
# Chromium 브라우저 인스턴스 실행
browser = await playwright.chromium.launch(headless=False)
page = await browser.new_page()
# Glassdoor 검색을 위한 기본 URL 및 쿼리 매개변수 정의
base_url = "https://www.glassdoor.com/Explore/browse-companies.htm?"
query_params = {
"overall_rating_low": "3.5",
"locId": "1132348",
"locType": "C",
"locName": "New York, NY (US)",
"occ": "Machine Learning Engineer",
"filterType": "RATING_OVERALL",
}
# 쿼리 매개변수를 포함한 전체 URL 생성 및 이동
url = f"{base_url}{urlencode(query_params)}"
await page.goto(url)
# 추출된 데이터 기록을 위한 CSV 파일 열기
with open("glassdoor_data.csv", mode="w", newline="", encoding="utf-8") as file:
writer = csv.writer(file)
writer.writerow([
"회사명", "채용 공고 URL", "채용 공고 수", "리뷰 수", "급여 정보 수",
"산업 분야", "근무지", "글로벌 기업 규모", "평점"
])
# 추출된 레코드 카운터 초기화
record_count = 0
while True:
# 페이지 내 모든 회사 카드 위치 파악 후 데이터 추출 반복
company_cards = await page.locator('[data-test="employer-card-single"]').all()
for card in company_cards:
try:
# 각 기업 카드에서 관련 데이터 추출
company_name = await card.locator('[data-test="employer-short-name"]').text_content(timeout=2000) or "N/A"
rating = await card.locator('[data-test="rating"]').text_content(timeout=2000) or "N/A"
location = await card.locator('[data-test="employer-location"]').text_content(timeout=2000) or "N/A"
global_company_size = await card.locator('[data-test="employer-size"]').text_content(timeout=2000) or "N/A"
industry = await card.locator('[data-test="employer-industry"]').text_content(timeout=2000) or "N/A"
# 채용 공고 URL 생성
jobs_url_path = await card.locator('[data-test="cell-Jobs-url"]').get_attribute("href", timeout=2000) or "N/A"
parsed_url = urlparse(base_url)
jobs_url_path = f"{parsed_url.scheme}://{parsed_url.netloc}{jobs_url_path}"
# 채용 공고, 리뷰, 급여에 대한 추가 데이터 추출
jobs_count = await card.locator('[data-test="cell-Jobs"] h3').text_content(timeout=2000) or "N/A"
reviews_count = await card.locator('[data-test="cell-Reviews"] h3').text_content(timeout=2000) or "N/A"
salaries_count = await card.locator('[data-test="cell-Salaries"] h3').text_content(timeout=2000) or "N/A"
# 추출된 데이터를 CSV 파일에 기록
writer.writerow([
company_name, jobs_url_path, jobs_count, reviews_count, salaries_count,
industry, location, global_company_size, rating
])
record_count += 1
except Exception as e:
print(f"회사 데이터 추출 오류: {e}")
try:
# 진행 전에 페이지네이션 컨테이너가 표시되었는지 확인
await page.wait_for_selector(".pageContainer", timeout=3000)
# 페이지의 "다음" 버튼 식별
next_button = page.locator('[data-test="pagination-next"]')
# "다음" 버튼이 비활성화되어 더 이상 페이지가 없는지 확인
is_disabled = await next_button.get_attribute("disabled") is not None
if is_disabled:
break # 더 이상 이동할 페이지가 없으면 중단
# 다음 페이지로 이동
await next_button.click()
await asyncio.sleep(3) # 페이지가 완전히 로드될 시간을 허용
except Exception as e:
print(f"다음 페이지로 이동 중 오류: {e}")
break # 이동 오류 시 루프 종료
print(f"추출된 총 레코드 수: {record_count}")
# 브라우저 닫기
await browser.close()
# 스크립트 진입점
async def main():
async with async_playwright() as playwright:
await scrape_data(playwright)
if __name__ == "__main__":
asyncio.run(main())
이 코드는 이제 추출된 데이터를 glassdoor_data.csv라는 CSV 파일에 저장합니다.
결과는 다음과 같습니다:
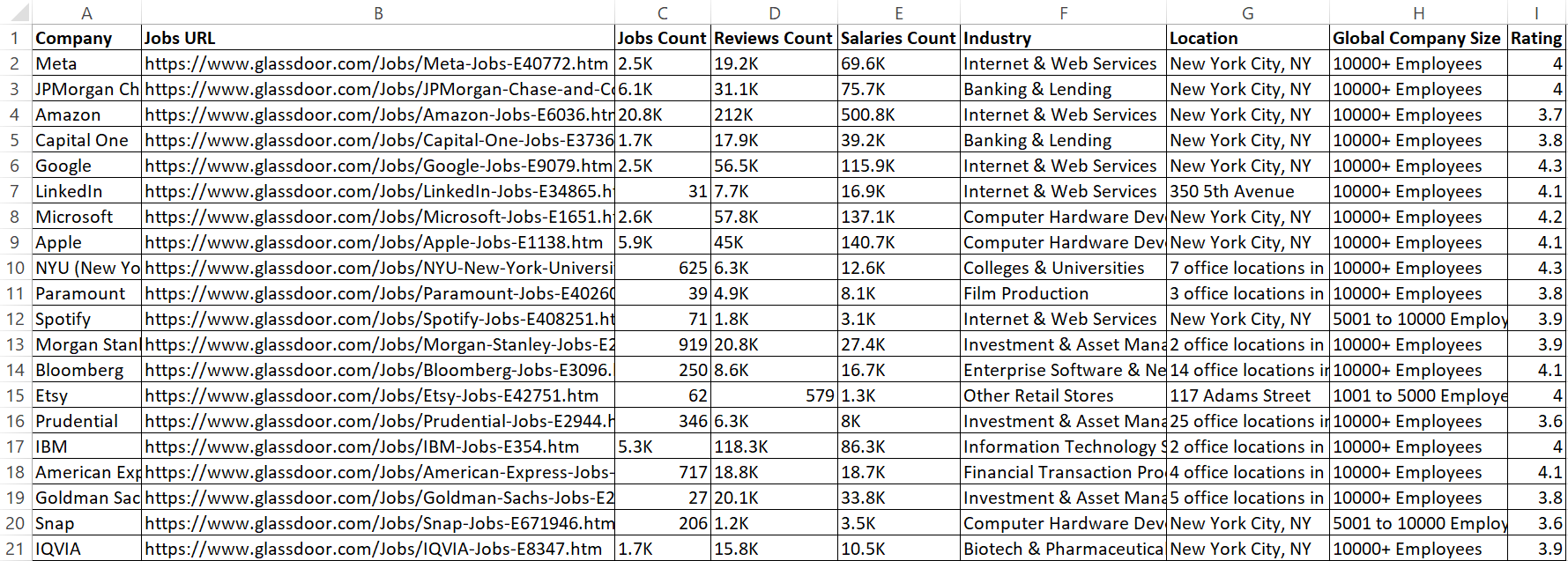
훌륭합니다! 이제 데이터가 더 깔끔하고 읽기 쉬워졌습니다.
글래스도어가 사용하는 스크래핑 방지 기술
글래스도어는 특정 기간 내 IP 주소에서 발생하는 요청 횟수를 모니터링합니다. 요청이 설정된 한도를 초과할 경우, 글래스도어는 해당 IP 주소를 일시적 또는 영구적으로 차단할 수 있습니다. 또한 비정상적인 활동이 감지될 경우, 제가 경험한 것처럼 글래스도어는 CAPTCHA 인증을 요구할 수 있습니다.
위에서 논의한 방법은 수백 개 기업을 스크래핑하는 데 적합합니다. 그러나 수천 개를 스크래핑해야 하는 경우, 대규모 데이터 스크래핑 시 제가 겪었던 것처럼 Glassdoor의 반봇 메커니즘이 자동 스크래핑 스크립트를 탐지할 위험이 높아집니다.
Glassdoor의 데이터 스크래핑은 반스크래핑 메커니즘으로 인해 어려울 수 있습니다. 이러한 반봇 메커니즘을 우회하는 것은 좌절감을 주고 많은 자원을 소모할 수 있습니다. 그러나 스크래퍼가 인간 행동을 모방하고 차단될 가능성을 줄이는 데 도움이 되는 전략들이 있습니다. 일반적인 기법으로는 프록시 로테이션, 실제 요청 헤더 설정, 요청 속도 무작위화 등이 있습니다. 이러한 기법들은 스크래핑 성공률을 높일 수 있지만, 100% 성공을 보장하지는 않습니다.
따라서 Glassdoor의 반봇 조치에도 불구하고 데이터를 추출하는 최선의 방법은 Glassdoor 스크레이퍼 API를 사용하는 것입니다 🚀
더 나은 대안: Glassdoor 스크레이퍼 API
Bright Data는 블로그에서 앞서 논의한 바와 같이, 분석을 위해 미리 수집 및 구조화된 Glassdoor 데이터 세트를 제공합니다. 데이터 세트를 구매하고 싶지 않고 더 효율적인 솔루션을 찾고 있다면, Bright Data의 Glassdoor 스크레이퍼 API 사용을 고려해 보세요.
이 강력한 API는 Glassdoor 데이터를 원활하게 스크래핑하도록 설계되어 동적 콘텐츠를 처리하고 봇 방지 조치를 손쉽게 우회합니다. 이 도구를 사용하면 시간을 절약하고 데이터 정확성을 보장하며, 데이터에서 실행 가능한 인사이트를 추출하는 데 집중할 수 있습니다.
Glassdoor Scraper API를 시작하려면 다음 단계를 따르세요:
먼저 계정을 생성하세요. Bright Data 웹사이트를 방문하여 ‘무료 체험 시작’을 클릭하고 가입 절차를 따르세요. 로그인 후 대시보드로 이동하면 무료 크레딧을 받을 수 있습니다.
이제 웹 스크레이퍼 API 섹션으로 이동하여 B2B 데이터 카테고리에서 Glassdoor를 선택하세요. URL로 기업 수집, URL로 채용 공고 수집 등 다양한 데이터 수집 옵션을 확인할 수 있습니다.
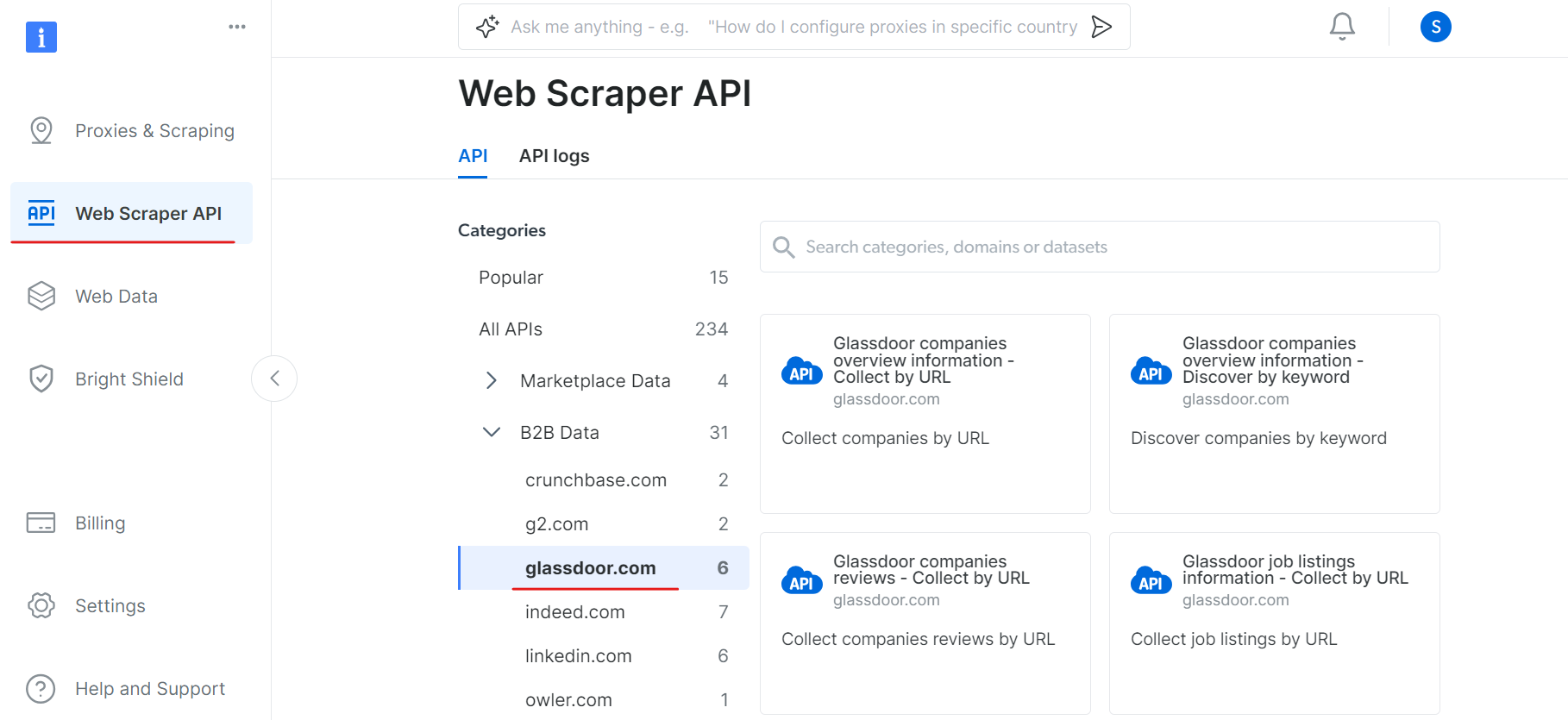
‘Glassdoor 기업 개요 정보’ 항목에서 API 토큰을 발급받고 데이터셋 ID(예: gd_l7j0bx501ockwldaqf)를 복사하세요.
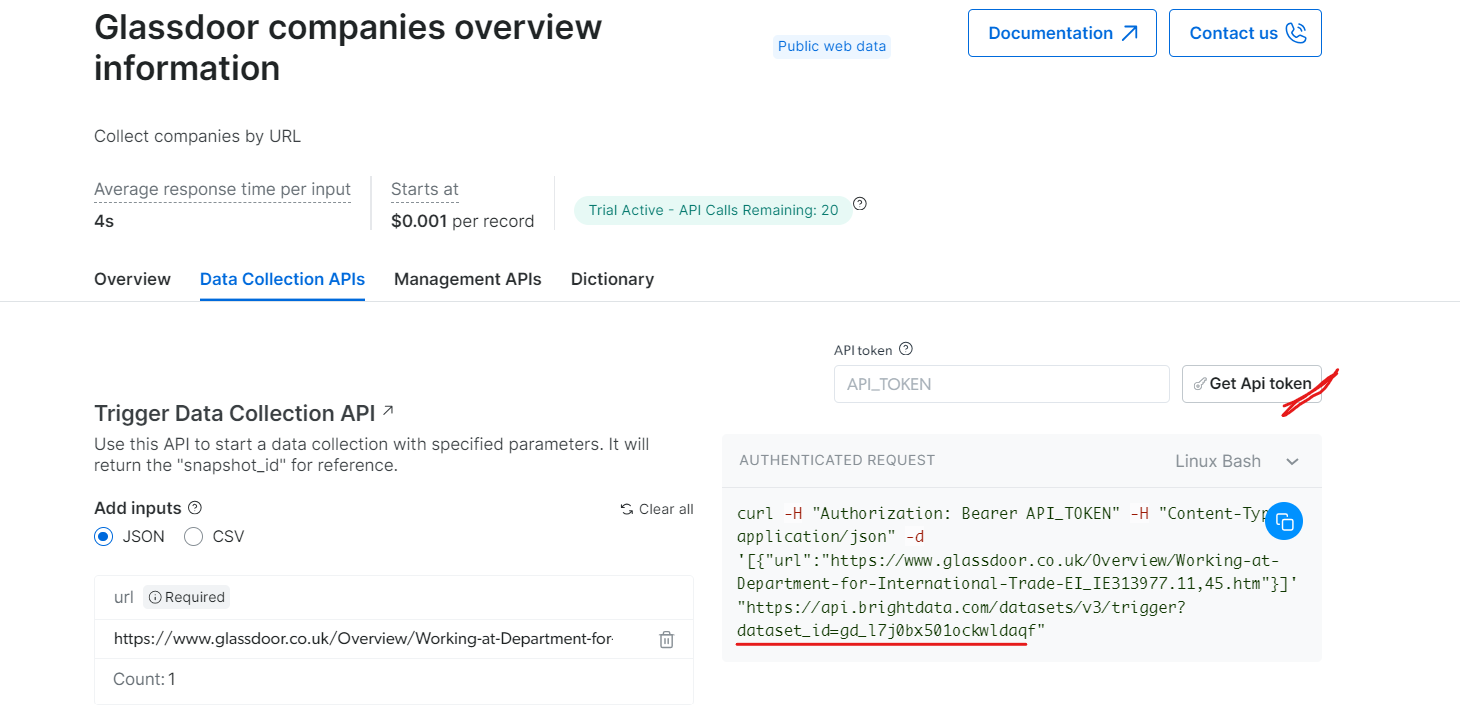
이제 URL, API 토큰, 데이터셋 ID를 제공하여 회사 데이터를 추출하는 방법을 보여주는 간단한 코드 스니펫입니다.
import requests
import json
def trigger_dataset(api_token, dataset_id, company_url):
"""
BrightData API를 사용하여 데이터셋을 트리거합니다.
인수:
api_token (문자열): 인증용 API 토큰.
dataset_id (문자열): 트리거할 데이터셋 ID.
company_url (str): 분석할 회사 페이지의 URL.
반환값:
dict: API로부터 받은 JSON 응답.
"""
headers = {
"Authorization": f"Bearer {api_token}",
"Content-Type": "application/json",
}
payload = json.dumps([{"url": company_url}])
response = requests.post(
"https://api.brightdata.com/datasets/v3/trigger",
headers=headers,
params={"dataset_id": dataset_id},
data=payload,
)
return response.json()
api_token = "API_Token"
dataset_id = "DATASET_ID"
company_url = "COMPANY_PAGE_URL"
response_data = trigger_dataset(api_token, dataset_id, company_url)
print(response_data)
코드를 실행하면 아래와 같이 스냅샷 ID를 받게 됩니다:

스냅샷 ID를 사용하여 해당 기업의 실제 데이터를 조회하세요. 터미널에서 다음 명령어를 실행하세요. Windows의 경우:
curl.exe -H "Authorization: Bearer API_TOKEN"
"https://api.brightdata.com/datasets/v3/snapshot/s_m0v14wn11w6tcxfih8?format=json"
Linux의 경우:
curl -H "Authorization: Bearer API_TOKEN"
"https://api.brightdata.com/datasets/v3/snapshot/s_m0v14wn11w6tcxfih8?format=json"
명령어를 실행하면 원하는 데이터를 얻을 수 있습니다.
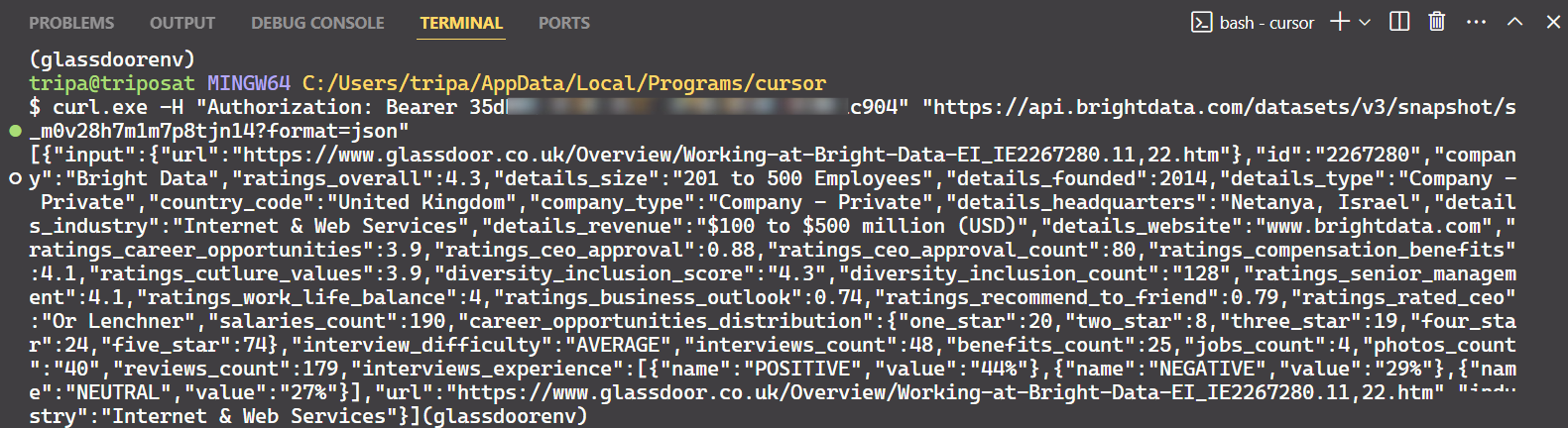
이게 전부입니다!
마찬가지로 코드를 수정하여 Glassdoor에서 다양한 유형의 데이터를 추출할 수 있습니다. 한 가지 방법을 설명했지만, 이를 수행하는 다른 다섯 가지 방법이 더 있습니다. 따라서 원하는 데이터를 스크래핑하기 위해 이러한 옵션들을 탐색해 보시길 권장합니다. 각 방법은 특정 데이터 요구 사항에 맞춰져 있으며, 필요한 정확한 데이터를 얻는 데 도움이 됩니다.
결론
이 튜토리얼에서는 Playwright Python을 사용해 Glassdoor 데이터를 스크래핑하는 방법을 배웠습니다. 또한 Glassdoor가 사용하는 스크래핑 방지 기술과 이를 우회하는 방법도 알아보았습니다. 이러한 문제를 해결하기 위해 Bright Data Glassdoor 스크래퍼 API가 소개되었으며, 이를 통해 Glassdoor의 스크래핑 방지 조치를 극복하고 필요한 데이터를 원활하게 추출할 수 있습니다.
또한 차세대 브라우저인 Scraping Browser를 사용해 볼 수도 있습니다. 이 브라우저는 다른 모든 브라우저 자동화 도구와 통합할 수 있습니다. Scraping Browser는 사용자 에이전트 로테이션, IP 로테이션, CAPTCHA 해결과 같은 기능을 활용하여 브라우저 지문 인식(fingerprinting)을 피하면서 안티봇 기술을 쉽게 우회할 수 있습니다.
지금 가입하여 Bright Data 제품을 무료로 체험해 보세요.






