

약 25년 동안 트립어드바이저는 웹에서 다양한 여행지를 발견할 수 있는 훌륭한 장소였습니다. 오늘은 트립어드바이저에서 호텔 데이터를 스크래핑할 것입니다. 트립어드바이저는 다음과 같은 다양한 기법을 사용하여 웹 스크래퍼를 차단합니다:
- 자바스크립트 관련 문제점
- 브라우저 지문 인식
- 동적 페이지 콘텐츠
아래 가이드를 따라가면, 마지막에는 트립어드바이저를 손쉽게 스크래핑할 수 있을 것입니다.
필수 조건
트립어드바이저는 다양한 차단 기술을 사용합니다. 간단하게 설명하기 위해 아래 목록으로 정리했습니다.
- 자바스크립트 챌린지: 트립어드바이저는 CAPTCHA 형태의 간단한 챌린지(자바스크립트)를 브라우저로 전송합니다. 브라우저가 이를 해결하지 못하면 봇으로 간주될 가능성이 높습니다.
- 브라우저 지문 인식: 브라우저에 쿠키를 전송한 후 이를 통해 사용자를 추적합니다.
- 동적 콘텐츠: 초기에는 빈 페이지를 받습니다. 이후 API 호출을 통해 데이터를 가져와 렌더링합니다.
Python Requests와 BeautifulSoup만으로는 작업을 완료할 수 없습니다. 실제 브라우저가 필요합니다. Selenium을 사용하면 웹드라이버를 통해 Python 스크립트 내부에서 브라우저를 직접 제어할 수 있습니다. Selenium은 필요한 모든 기능을 미리 포함하고 있습니다. Selenium을 활용한 웹 스크래핑에 대해 자세히 알아보세요 .
이제 Selenium을 설치해 보겠습니다. 웹드라이버도 설치되어 있는지 확인해야 합니다. 최신 웹드라이버 버전은 여기서 찾을 수 있습니다. 크롬드라이버 버전이 사용 중인 크롬 버전과 일치하는지 반드시 확인하세요.
다음 명령어로 버전 번호를 확인할 수 있습니다. 크롬드라이버 버전과 일치하는지 반드시 확인하세요.
google-chrome --version
다음과 유사한 결과가 출력되어야 합니다.
Google Chrome 130.0.6723.116
다음 명령어로 Selenium을 설치할 수 있습니다.
pip install selenium
Selenium이 설치되면 다른 것은 설치할 필요가 없습니다. Selenium이 스크래핑 관련 모든 작업을 처리해 줍니다. 이 튜토리얼에서 사용하는 다른 패키지들은 모두 Python에 미리 포함되어 있습니다.
트립어드바이저에서 스크래핑할 내용
트립어드바이저에서 호텔 정보를 정확히 어떻게 스크래핑할지 살펴보겠습니다. 트립어드바이저에서 마이애미에 대한 기본 검색을 수행하면 아래 스크린샷과 유사한 페이지가 표시됩니다. 확인해보면 호텔 결과뿐만 아니라 모든 카테고리의 결과가 함께 제공됩니다.
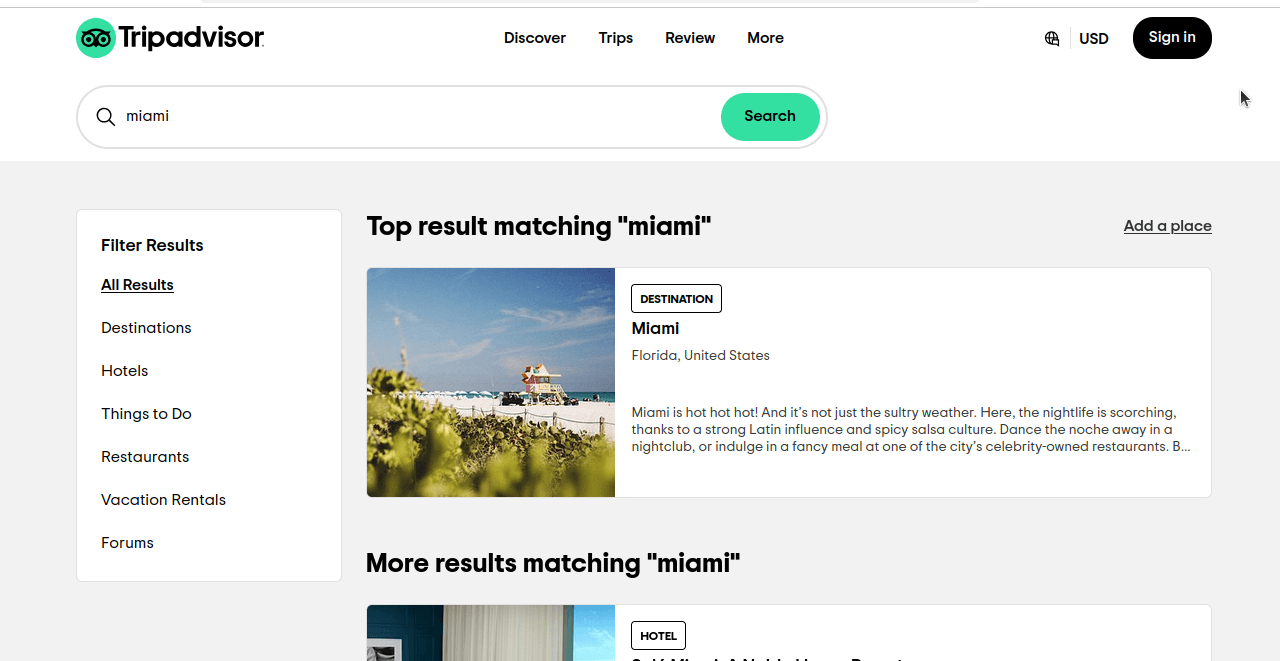
이 페이지의 URL을 자세히 살펴보세요: https://www.tripadvisor.com/Search?q=miami&geo=1&ssrc=a&searchNearby=false&searchSessionId=001f4b791e61703a.ssid&offset=0. 이제 ‘호텔’을 클릭하고 URL을 확인해 봅시다: https://www.tripadvisor.com/Search?q=miami&geo=1&ssrc=h&searchNearby=false&searchSessionId=001f4b791e61703a.ssid&offset=0. URL은 여전히 매우 유사해 보입니다. 아래에서 이 URL들을 살펴보겠지만, 불필요한 부분은 제거하겠습니다.
- 전체 결과:
https://www.tripadvisor.com/Search?q=miami&geo=1&ssrc=a - 호텔:
https://www.tripadvisor.com/Search?q=miami&geo=1&ssrc=h.
ssrc는 결과를 선택하는 데 사용하는 쿼리입니다. ssrc=a는 전체 결과에 사용됩니다. ssrc=h는 호텔에 사용됩니다. 이 링크 https://www.tripadvisor.com/Search?q=miami&geo=1&ssrc=h를 클릭하면 아래 스크린샷과 유사한 페이지가 표시됩니다.
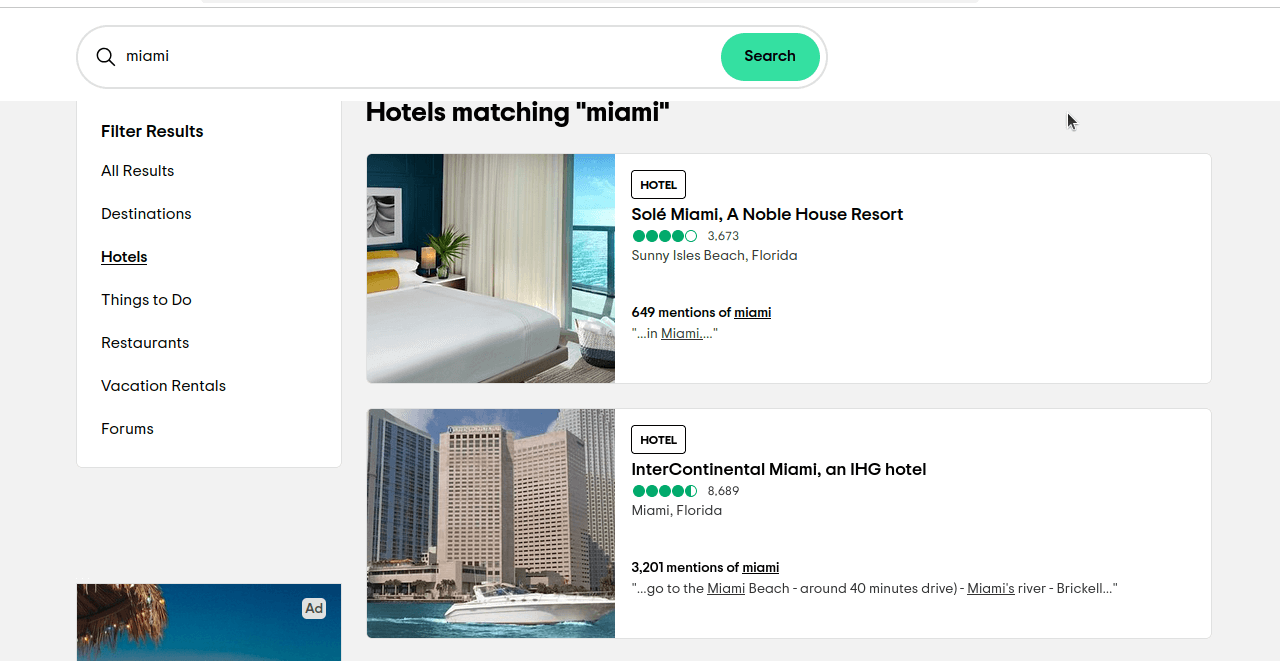
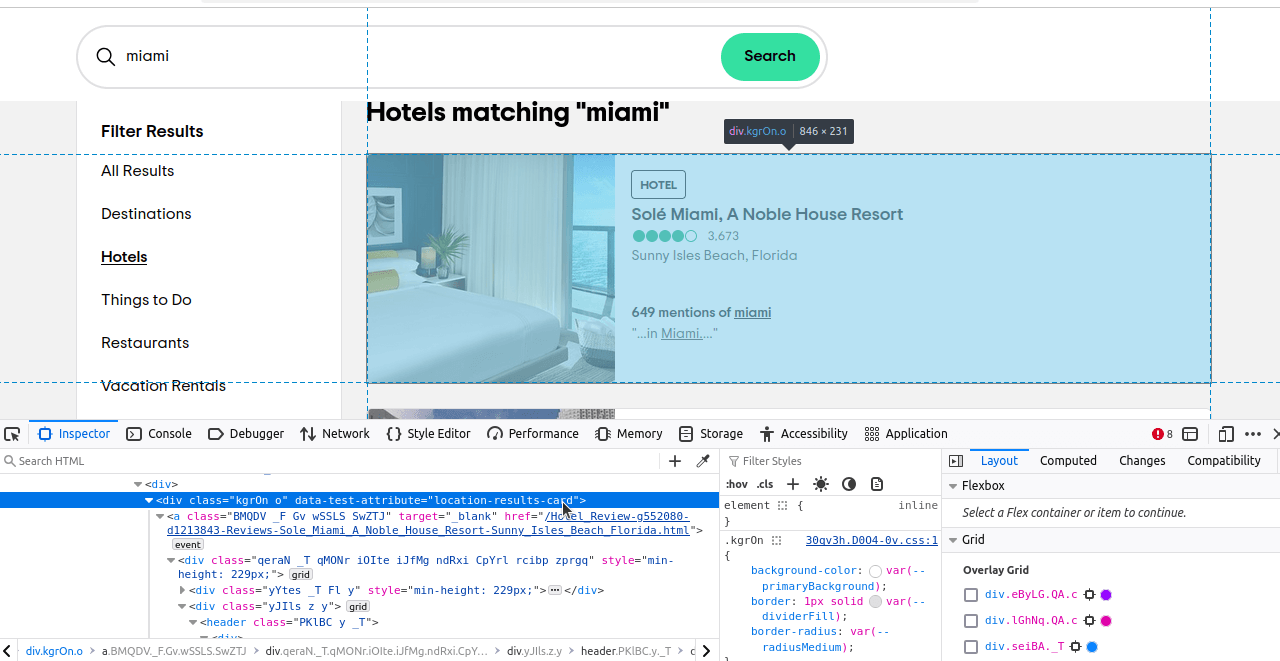
이제 우리가 찾고자 하는 요소가 무엇인지 파악하기만 하면 됩니다. 이 요소들을 검사해 보면 각 결과에 "location-results-card"라는 data-test-attribute가 있다는 것을 알 수 있습니다. 이 부분이 정말 중요합니다. 이를 활용해 CSS 선택자를 작성할 수 있습니다: div[data-test-attribute='location-results-card']. 실제 페이지를 스크래핑할 때 이 선택자와 일치하는 모든 요소를 찾아낼 것입니다.
순수 Selenium으로 트립어드바이저 스크래핑하기
이제 기본적인 Selenium을 사용해 Tripadvisor를 스크래핑해 보겠습니다. 전체적으로 매우 간단한 스크립트를 작성할 예정입니다. 실제로 필요한 함수는 두 가지뿐입니다. 스크래핑을 수행하는 함수와 데이터를 CSV로 쓰는 함수입니다. 이 두 가지를 확보한 후 모든 것을 통합해 완전히 작동하는 스크립트를 만들 것입니다.
write_to_csv() 함수를 살펴보세요. 이 함수는 두 개의 인자( data, page_number)를 받습니다. data는 기록할 딕셔너리 ( dict ) 또는 딕셔너리 객체 배열일 수 있습니다. page_number는 파일명을 지정하는 데 사용됩니다. Path(filename).exists() 를 사용해 파일 존재 여부를 확인합니다. mode는 파일 열기 모드를 지정합니다. 파일이 존재하면 모드를 "a"( 추가)로 설정합니다. 파일이 존재하지 않으면 기본 모드인 "w"( 쓰기) 를 유지합니다. 이 두 모드 설정으로 항상 파일을 확보하거나 기존 파일을 덮어쓰지 않도록 보장합니다.
개별 함수
def write_to_csv(data, page_number):
if type(data) != list:
data = [data]
print("CSV에 쓰기 중...")
filename = f"tripadvisor-{page_number}.csv"
mode = "w"
if Path(filename).exists():
mode = "a"
print("CSV 파일에 데이터 기록 중...")
with open(filename, mode) as file:
writer = csv.DictWriter(file, fieldnames=data[0].keys())
if mode == "w":
writer.writeheader()
writer.writerows(data)
print(f"{page} 페이지를 CSV에 성공적으로 작성했습니다...")
- 함수 시작 부분에서
데이터가리스트인지 확인합니다. 리스트가 아니면 리스트로 변환합니다. f"tripadvisor-{page_number}.csv"로 파일명을 구성합니다.- 기본
모드는"w"이지만, 파일이 존재할 경우 모드를"a"로 변경합니다. csv.DictWriter(file, fieldnames=data[0].keys())로 파일 라이터를 초기화합니다.- 쓰기 모드인 경우, 헤더로 첫 번째 객체의 키를 사용합니다. 파일을 추가하는 경우, 이 작업을 수행할 필요가 없습니다.
- 파일 설정이 완료된 후,
writer.writerows(data)를 사용하여 데이터를 CSV 파일에 기록합니다.
이제 스크래핑 함수를 살펴보겠습니다. 이 함수는 page_number라는단일 인자를 받습니다…설명이 필요 없을 정도로 직관적입니다. 먼저 사용자 정의 ChromeOptions를 설정합니다. 브라우저를 헤드리스 모드로 전환하고 가짜 사용자 에이전트를 사용하도록 인자를 추가합니다. 이렇게 하면 트립어드바이저가 우리를 차단하지 않도록 브라우저를 충분히 위장할 수 있을 것입니다. 그런 다음 webdriver를 사용하여 브라우저를 실행하고 검색 결과 페이지로 이동합니다. sleep(5)를 사용해 콘텐츠 로딩을 위해 5초간 대기하며, 이는 일반 사용자와 유사한 행동을 보이기 위함입니다. 앞서 ‘스크래핑 대상’ 섹션에서 언급한 CSS 선택자를 사용합니다. hotel_cards가 존재하지 않으면 스크린샷을 찍고 함수를 조기 종료합니다. hotel_cards가 존재할 경우 해당 데이터를 추출하여 scraped_data 배열에 추가합니다. 데이터 스크래핑이 완료되면 모든 내용을 CSV로 출력합니다.
def scrape_page(page_number: int):
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument(f"--user-agent={USER_AGENT}")
print("스크래핑 브라우저 연결 중...")
scraped_data = []
print("-------------------------------")
driver = webdriver.Chrome(options=options)
driver.get(f"https://www.tripadvisor.com/Search?q=Miami&geo=1&ssrc=h&offset={page_number*30}")
print("연결 완료! 페이지 스크래핑 중...")
sleep(5)
hotel_cards = driver.find_elements(By.CSS_SELECTOR, "div[data-test-attribute='location-results-card']")
if not hotel_cards:
driver.save_screenshot("error.png")
driver.quit()
return
for index, card in enumerate(hotel_cards):
score = None
divs = card.find_elements(By.CSS_SELECTOR, "div")
for div in divs:
aria_label = div.get_attribute("aria-label")
if aria_label:
if "bubbles" in aria_label:
score = aria_label
break
data_array = card.text.split("n")
hotel_dict = {
"name": data_array[1],
"reviews": int(data_array[2].replace(",", "")),
"score": float(aria_label[0:3]),
"location": data_array[3],
"location_mentions": data_array[4].split(" ")[0],
"review_summary": data_array[5]
}
scraped_data.append(hotel_dict)
print(f"카드 {index} 스크래핑 성공")
print(f"페이지 {page_number} 스크랩 완료")
write_to_csv(scraped_data, page_number)
트립어드바이저 데이터 스크래핑
모든 것을 합치면 다음과 같은 스크립트가 됩니다. 아래 코드를 자유롭게 복사하여 자신의 Python 파일에 붙여넣으세요.
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
import csv
from pathlib import Path
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36"
def write_to_csv(data, page_number):
if type(data) != list:
data = [data]
print("CSV에 쓰기 중...")
filename = f"tripadvisor-{page_number}.csv"
mode = "w"
if Path(filename).exists():
mode = "a"
print("CSV 파일에 데이터 쓰기 중...")
with open(filename, mode) as file:
writer = csv.DictWriter(file, fieldnames=data[0].keys())
if mode == "w":
writer.writeheader()
writer.writerows(data)
print(f"{page} 페이지 데이터를 CSV에 성공적으로 작성했습니다...")
def scrape_page(page_number: int):
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument(f"--user-agent={USER_AGENT}")
print("스크래핑 브라우저에 연결 중...")
scraped_data = []
print("-------------------------------")
driver = webdriver.Chrome(options=options)
driver.get(f"https://www.tripadvisor.com/Search?q=Miami&geo=1&ssrc=h&offset={page_number*30}")
print("연결됨! 페이지 스크래핑 중...")
sleep(5)
hotel_cards = driver.find_elements(By.CSS_SELECTOR, "div[data-test-attribute='location-results-card']")
if not hotel_cards:
driver.save_screenshot("error.png")
driver.quit()
return
for index, card in enumerate(hotel_cards):
score = None
divs = card.find_elements(By.CSS_SELECTOR, "div")
for div in divs:
aria_label = div.get_attribute("aria-label")
if aria_label:
if "bubbles" in aria_label:
score = aria_label
break
data_array = card.text.split("n")
hotel_dict = {
"name": data_array[1],
"reviews": int(data_array[2].replace(",", "")),
"score": float(aria_label[0:3]),
"location": data_array[3],
"location_mentions": data_array[4].split(" ")[0],
"review_summary": data_array[5]
}
scraped_data.append(hotel_dict)
print(f"카드 {index} 스크래핑 성공")
print(f"페이지 {page_number} 스크랩 완료")
write_to_csv(scraped_data, page_number)
if __name__ == '__main__':
PAGES = 1
for page in range(PAGES):
scrape_page(page)
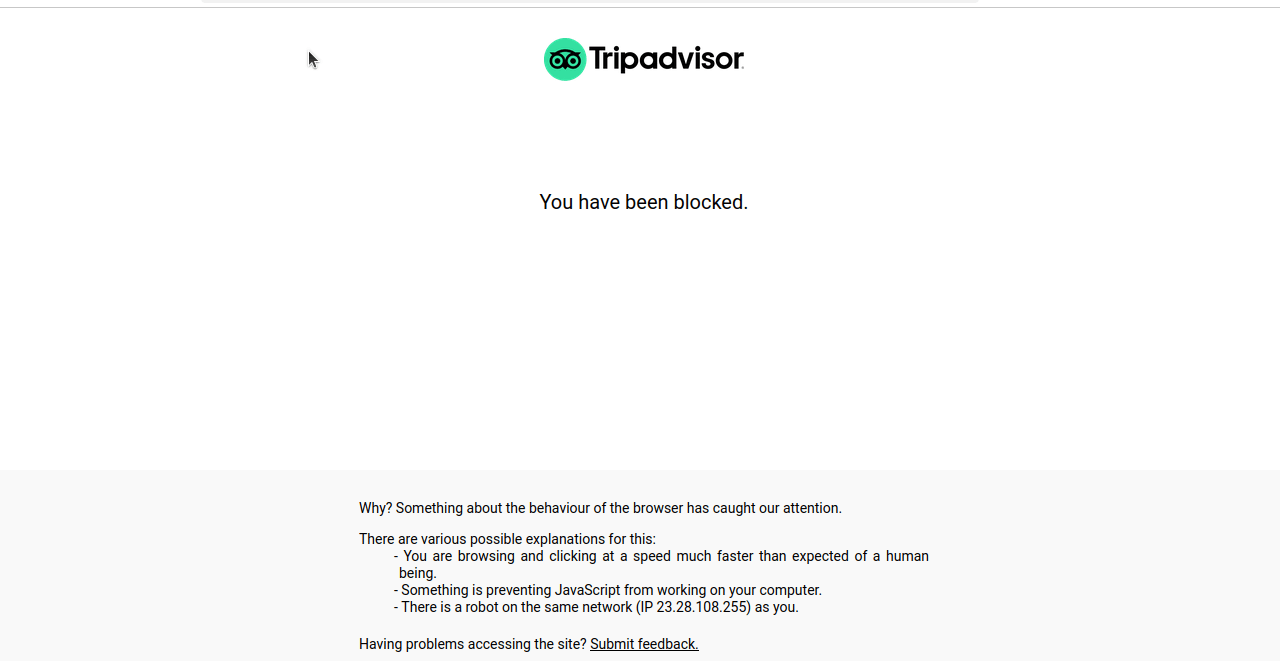
이 코드를 실행하면 대부분의 경우 아래 스크린샷과 같은 화면이 멈추거나 CAPTCHA가 나타납니다.

고급 기법
다음은 스크립트에서 사용되는 고급 기법들입니다. 주로 페이지네이션 처리 방식과 차단 방지 기법들을 살펴보겠습니다.
페이지네이션 처리
사용하는 URL을 살펴보세요: https://www.tripadvisor.com/Search?q=Miami&geo=1&ssrc=h&offset={page_number*30}. 페이지네이션은 offset 매개변수로 처리됩니다. 페이지당 30개의 결과를 얻습니다. page_number*30은 페이지 번호에 페이지당 결과 수(30)를 곱합니다. 페이지 0은 1번부터 30번까지의 결과를 반환합니다. 페이지 2는 31번부터 60번까지의 결과를 담고 있으며, 이처럼 계속 이어집니다.
메인 함수도 자세히 살펴보세요. PAGES는 스크래핑할 페이지 수를 저장합니다. 데이터의 첫 5페이지를 스크래핑하려면 PAGES = 1을 PAGES = 5로 변경하기만 하면 됩니다.
if __name__ == '__main__':
PAGES = 1
for page in range(PAGES):
scrape_page(page)
차단 방지
바닐라 셀레니움을 사용할 때, 차단되는 것을 방지하기 위해 몇 가지 기법을 사용합니다. 가짜 사용자 에이전트와 sleep(5)를 함께 사용합니다. 이 sleep 함수는 페이지가 로드되도록 허용하며, 여러 페이지를 스크래핑할 때 요청 간격을 벌려줍니다.
다음은 우리의 사용자 에이전트입니다. 이는 트립어드바이저에 우리의 브라우저가 Chrome 130.0.0.0 및 Safari 537.36과 호환된다고 알립니다. 트립어드바이저가 이를 읽으면, 그들의 서버는 해당 브라우저들과 호환되는 페이지를 우리에게 반환합니다.
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36
그러나 여전히 탐지될 가능성이 있으며 스크래퍼가 차단될 수 있습니다. 그들의 차단을 지속적으로 우회하려면 Vanilla Selenium보다 조금 더 강력한 도구가 필요합니다.
Bright Data 사용 고려
Bright Data는 Vanilla Selenium에서 마주친 차단들을 우회할 수 있는 다양한 솔루션을 제공합니다. Scraping Browser는 Bright Data의 최상급 프록시만을 사용하여 Selenium의 원격 인스턴스를 실행할 수 있는 기능을 제공합니다. 먼저 가입 과정을 살펴보겠습니다. 그런 다음 이전 스크립트를 Scraping Browser로 실행하도록 수정하겠습니다.
계정 생성하기
먼저 스크래핑 브라우저 페이지로 이동하세요. ‘무료 체험 시작’을 클릭하세요. Google, Github 또는 이메일 주소로 계정을 생성할 수 있습니다.
계정 생성 후 대시보드로 이동합니다. ‘추가(Add)’를 클릭하세요.
아래 이미지와 유사한 드롭다운 메뉴가 표시됩니다. ‘Scraping Browser‘를 클릭하세요.
이제 Scraping Browser 설정 페이지로 이동합니다. 기본 설정 그대로 진행하겠습니다. 기본적으로 Scraping Browser에는 내장형 CAPTCHA 해결기가 포함되어 있습니다.
마지막으로 스크래핑 브라우저 영역 생성을 요청받게 됩니다. 스크래핑 브라우저 사용 준비가 되었다면 ‘예’를 클릭하세요.
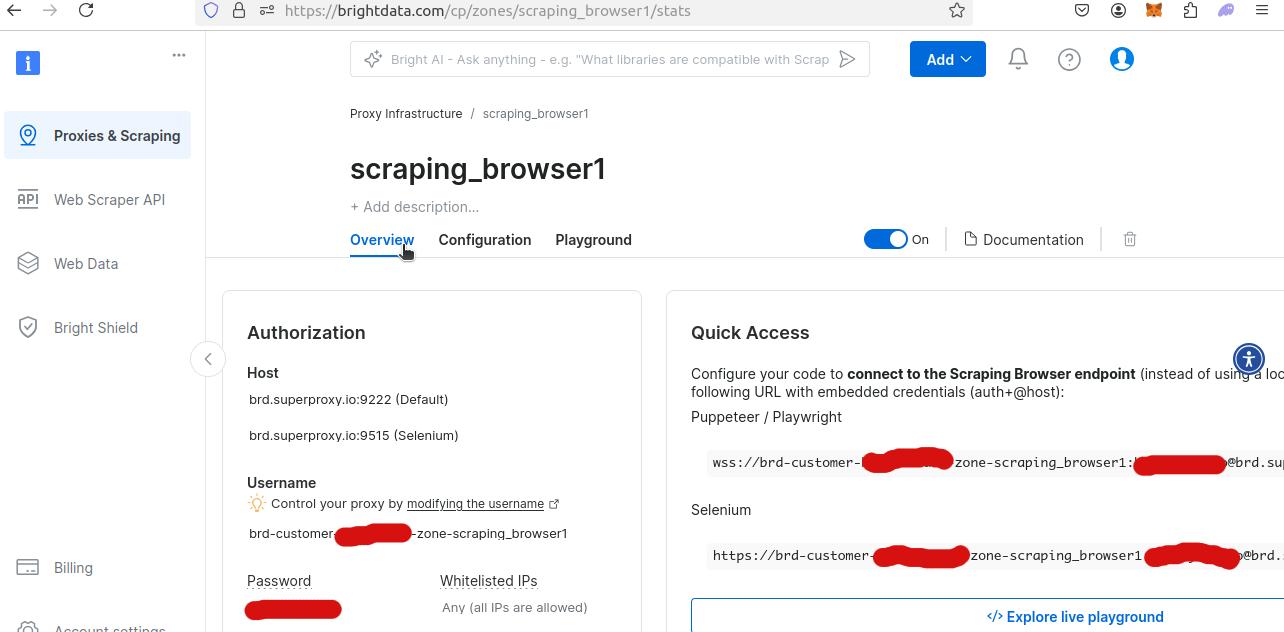
새 스크래핑 브라우저 영역의 개요를 확인하면 고유한 사용자 이름과 비밀번호를 얻을 수 있습니다. Python 스크립트 내에서 스크래핑 브라우저에 접근하려면 이 정보가 필요합니다.
Bright Data Scraping Browser를 사용한 데이터 추출
아래 코드 예제는 Scraping Browser와 함께 Remote Webdriver를 사용하도록 수정되었습니다. YOUR_USERNAME, YOUR_ZONE_NAME, YOUR_PASSWORD를 실제 사용자 이름, 영역, 비밀번호로 반드시 교체하세요!
from selenium.webdriver import Remote, ChromeOptions
from selenium.webdriver.chromium.remote_connection import ChromiumRemoteConnection
from selenium.webdriver.common.by import By
from time import sleep
import csv
from pathlib import Path
AUTH = "brd-customer-YOUR_USERNAME-zone-YOUR_ZONE_NAME:YOUR_PASSWORD"
SBR_WEBDRIVER = f"https://{AUTH}@zproxy.lum-superproxy.io:9515"
def write_to_csv(data, page_number):
if type(data) != list:
data = [data]
print("CSV에 쓰기 중...")
filename = f"tripadvisor-{page_number}.csv"
mode = "w"
if Path(filename).exists():
mode = "a"
print("CSV 파일에 데이터 쓰기 중...")
with open(filename, mode) as file:
writer = csv.DictWriter(file, fieldnames=data[0].keys())
if mode == "w":
writer.writeheader()
writer.writerows(data)
print(f"{page} 페이지 CSV 작성 성공...")
def scrape_page(page_number: int):
print("스크래핑 브라우저에 연결 중...")
sbr_connection = ChromiumRemoteConnection(SBR_WEBDRIVER, "goog", "chrome")
scraped_data = []
print("-------------------------------")
with Remote(sbr_connection, options=ChromeOptions()) as driver:
driver.get(f"https://www.tripadvisor.com/Search?q=Miami&geo=1&ssrc=h&offset={page_number*30}")
print("연결됨! 페이지 스크래핑 중...")
sleep(5)
hotel_cards = driver.find_elements(By.CSS_SELECTOR, "div[data-test-attribute='location-results-card']")
if not hotel_cards:
print("호텔 카드 없음! 스크린샷을 찍고 종료합니다.")
driver.get_screenshot_as_file(f"./error_screenshot_page_{page_number}.png")
return
for index, card in enumerate(hotel_cards):
score = None
divs = card.find_elements(By.CSS_SELECTOR, "div")
for div in divs:
aria_label = div.get_attribute("aria-label")
if aria_label:
if "bubbles" in aria_label:
score = aria_label
break
data_array = card.text.split("n")
hotel_dict = {
"name": data_array[1],
"reviews": int(data_array[2].replace(",", "")),
"score": float(aria_label[0:3]),
"location": data_array[3],
"location_mentions": data_array[4].split(" ")[0],
"review_summary": data_array[5]
}
scraped_data.append(hotel_dict)
print(f"카드 {index} 스크랩 성공")
print(f"페이지 {page_number} 스크랩 완료")
write_to_csv(scraped_data, page_number)
if __name__ == '__main__':
PAGES = 1
for page in range(PAGES):
scrape_page(page)
이 예제는 Vanilla Selenium을 사용한 예제와 상당히 유사하지만, 몇 가지 작은 차이점이 있습니다. 주로 표준 웹드라이버 대신 원격 웹드라이버를 사용한다는 점과 관련이 있습니다.
- 프록시 연결을 사용하여 원격 웹드라이버 인스턴스를 설정합니다:
SBR_WEBDRIVER = f"https://{AUTH}@zproxy.lum-superproxy.io:9515". - 오류 처리 방식이 약간 변경되었습니다:
driver.get_screenshot_as_file(f"./error_screenshot_page_{page_number}.png"). 이제driver.save_screenshot()대신driver.get_screenshot_as_file()을사용합니다.
원격 프록시 연결을 위한 몇 가지 사소한 수정 외에는, Selenium을 사용한 Scraping Browser의 코드는 Vanilla Selenium과 거의 동일합니다. 가장 큰 차이점은 Scraping Browser가 결과를 쉽게 가져온다는 점입니다 .
이 코드를 실행할 때 아래와 같은 오류가 발생할 수 있습니다. 이는 원격 연결 시 발생할 수 있는 현상입니다. 오류가 발생하면 스크립트를 재실행하세요. 안정적인 연결을 구축하려면 여러 번 시도해야 할 때도 있습니다.
urllib3.exceptions.ProtocolError: ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response'))
스크립트가 성공적으로 실행되면 아래와 같은 출력을 확인하실 수 있습니다.
Scraping Browser에 연결 중...
-------------------------------
연결 완료! 페이지 스크래핑 중...
카드 0 스크래핑 성공
카드 1 스크래핑 성공
카드 2 스크래핑 성공
카드 3 스크래핑 성공
카드 4 스크래핑 성공
카드 5 스크래핑 성공
카드 6 스크래핑 성공
카드 7 스크래핑 성공
카드 8 스크래핑 성공
카드 9 스크래핑 성공
카드 10 스크래핑 성공
카드 11 스크래핑 성공
카드 12 스크래핑 성공
카드 13 스크래핑 성공
카드 14 성공적으로 스크랩함
카드 15 성공적으로 스크랩함
카드 16 성공적으로 스크랩함
카드 17 성공적으로 스크랩함
카드 18 성공적으로 스크랩함
카드 19 성공적으로 스크랩함
카드 20 성공적으로 스크랩함
카드 21 성공적으로 스크랩함
카드 22 성공적으로 스크랩함
카드 23 성공적으로 스크랩함
카드 24 성공적으로 스크랩함
카드 25 성공적으로 스크랩함
카드 26 성공적으로 스크랩함
카드 27 성공적으로 스크랩함
카드 28 성공적으로 스크랩함
카드 29 성공적으로 스크랩함
페이지 0 스크랩함
CSV에 쓰기 중...
CSV 파일에 데이터 쓰기 중...
CSV에 0 성공적으로 기록함...
다음은 ONLYOFFICE를 사용한 CSV 데이터의 스크린샷입니다.
이미지 표시되지 않음 가능한 원인
- 이미지 파일이 손상되었을 수 있습니다
- 이미지를 호스팅하는 서버에 연결할 수 없음
- 이미지 경로가 잘못되었습니다
- 이미지 형식이 지원되지 않음
대안 접근법: 데이터셋
스크레이퍼를 코딩하는 것이 선호하는 방법이 아니거나 대규모 데이터가 필요한 경우, 구조화된 트립어드바이저 데이터셋을 활용하는 것을 고려해 보십시오. 당사의 데이터셋은 여행 트렌드 분석, 경쟁사 가격 모니터링, 고객 경험 최적화를 손쉽게 수행할 수 있도록 요구 사항에 맞춰 체계적으로 정리된 고품질 데이터를 제공합니다.
트립어드바이저 데이터셋을 통해 호텔명, 리뷰, 평점, 편의시설, 가격 등 핵심 데이터 포인트에 접근할 수 있습니다. 모든 데이터는 유연한 형식(예: JSON, CSV, Parquet)으로 제공되며, 귀사의 워크플로우에 맞는 일정으로 업데이트됩니다. 무엇보다도 이 데이터셋은 100% 규정 준수 및 확장 가능하여 정확성을 보장하면서 시간과 자원을 절약해 줍니다.
주요 이점:
- 차단 없이 모든 주요 트립어드바이저 데이터 포인트에 접근하세요.
- 필터 및 맞춤 형식으로 특정 요구사항에 맞게 데이터셋 조정 가능.
- Snowflake, S3, Azure 같은 플랫폼으로 데이터 전달을 자동화하세요.
데이터 수집이 아닌 분석에 집중하세요—어려운 부분은 저희가 처리합니다. 지금 바로 트립어드바이저 데이터셋을 살펴보세요!
결론
자바스크립트 문제부터 완전한 동적 콘텐츠까지, 트립어드바이저 데이터 수집은 정말 까다로울 수 있습니다. 본 가이드를 마친 지금, 조금은 수월해졌을 것입니다. 이쯤 되면 셀레니움을 활용해 로컬 및 원격 세션으로 브라우저를 제어할 수 있다는 점을 이해하셨을 겁니다. 헤드리스 브라우저(셀레니움 등)를 사용하면 데이터 스크린샷을 찍을 수도 있습니다. 이는 스크레이퍼 디버깅을 훨씬 쉽게 만들어줍니다. 호텔 데이터를 추출하는 방법을 알게 되었고, 별도의 설치 없이도 평범한 Python으로 CSV 파일을 작성하는 방법을 알게 되었습니다!
대규모 스크래핑을 원하신다면, Bright Data가 이를 지원하는 다양한 제품을 보유하고 있습니다. Scraping Browser는 모든 스크래핑 관련 작업에 최적화된 도구를 제공합니다. 선택한 헤드리스 브라우저로 안정적인 프록시 연결을 통해 실제 브라우저를 제어할 수 있습니다. CAPTCHA에 대한 걱정도 필요 없습니다!
또는 가장 효율적인 데이터 획득 방법을 선택하세요 – 바로 사용 가능한 Tripadvisor 데이터셋을 구매하세요. 지금 가입하여 무료 체험을 시작하세요!






