

웹 스크래핑 시 콘텐츠가 여러 페이지에 분산된 페이지네이션을 자주 접하게 됩니다. 웹사이트마다 다른 페이지네이션 기법을 사용하기 때문에 이를 처리하는 것은 어려울 수 있습니다.
이 글에서는 일반적인 페이지 분할 기법을 설명하고, 실제 코드 예시를 통해 이를 처리하는 방법을 보여드리겠습니다.
페이지 매김이란?
전자상거래 플랫폼, 구인 게시판, 소셜 미디어 같은 웹사이트는 대량의 데이터를 관리하기 위해 페이지 매김을 사용합니다. 모든 내용을 한 페이지에 표시하면 로딩 시간이 크게 증가하고 메모리를 과도하게 소모합니다. 페이지 매김은 콘텐츠를 여러 페이지로 나누고 “다음”, 페이지 번호, 스크롤 시 자동 로딩 같은 탐색 옵션을 제공합니다. 이를 통해 탐색이 더 빠르고 체계적으로 이루어집니다.
페이지네이션의 유형
페이지네이션의 복잡성은 단순한 번호 기반 페이지네이션부터 무한 스크롤이나 동적 콘텐츠 로딩 같은 고급 기법까지 다양합니다. 제 경험상 웹사이트에서 가장 흔히 사용되는 세 가지 주요 유형은 다음과 같습니다:
- 번호 매기기 방식 페이지네이션: 사용자가 번호가 매겨진 링크를 통해 개별 페이지를 탐색합니다.
- 클릭 로드 페이지네이션: 사용자가 버튼(예: “더 보기”)을 클릭하여 추가 콘텐츠를 로드합니다.
- 무한 스크롤: 사용자가 페이지를 아래로 스크롤할 때 콘텐츠가 자동으로 로드됩니다.
이제 각각을 더 자세히 살펴보겠습니다!
번호별 페이지네이션
가장 흔한 페이지네이션 기법으로, “다음/이전 페이지네이션”, “화살표 페이지네이션”, “URL 기반 페이지네이션” 등으로 불립니다. 명칭은 다르지만 핵심 개념은 동일합니다—번호가 매겨진 링크로 페이지가 연결됩니다. URL의 페이지 번호를 변경하여 이동할 수 있습니다. 페이지네이션을 중단할 시점은 “다음” 버튼이 비활성화되었거나 새 데이터가 없을 때 확인합니다.
일반적으로 다음과 같습니다:

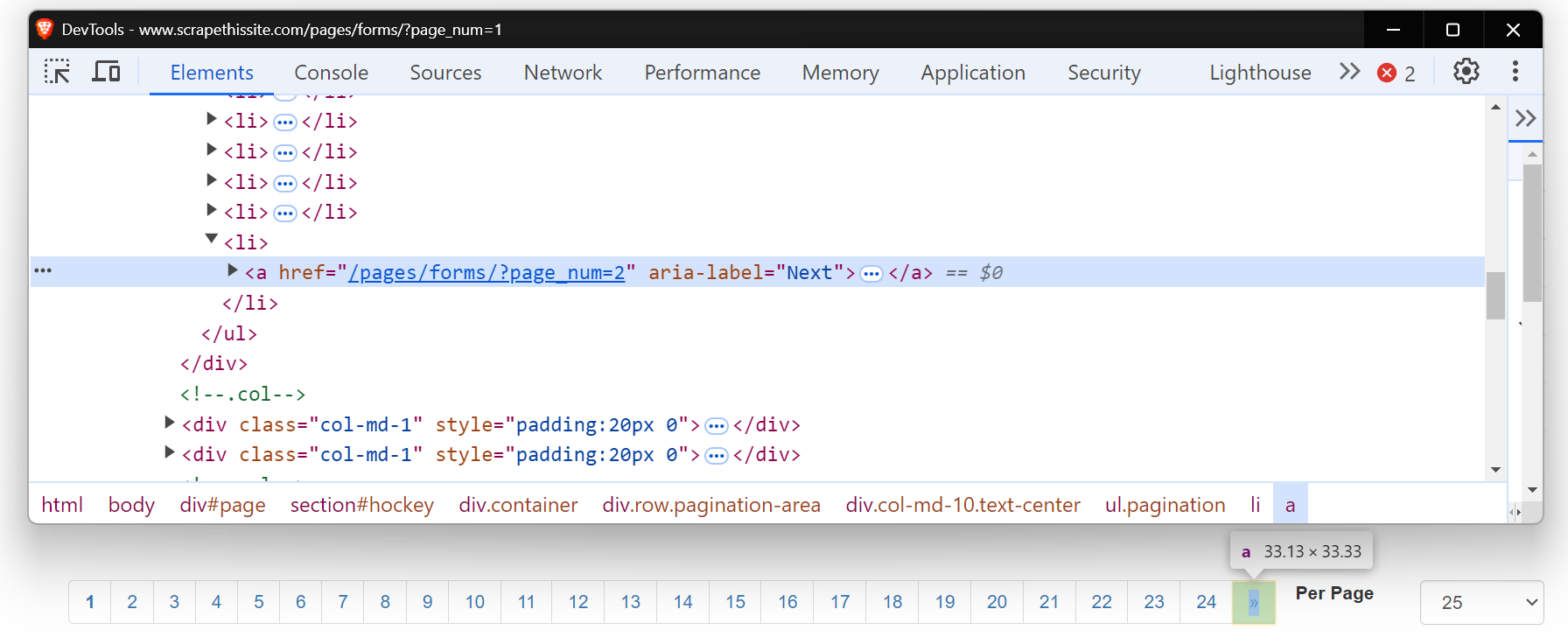
`예시를 들어 보겠습니다! Scrapethesite 웹사이트의 모든 페이지를 탐색해 보겠습니다. 이 사이트의 페이지네이션 바에는 총 24페이지가 있습니다.

“>>” 버튼을 클릭하면 URL이 다음과 같이 변경되는 것을 확인할 수 있습니다:
- 1페이지: https://www.scrapethissite.com/pages/forms/
- 2번째 페이지: https://www.scrapethissite.com/pages/forms/?page_num=2
- 3번째 페이지: https://www.scrapethissite.com/pages/forms/?page_num=3
이제 이 “다음” 버튼의 HTML을 살펴보세요. href 속성이 다음 페이지로 연결되는 앵커 태그(<a>)입니다. aria-label 속성은 “다음” 버튼이 여전히 활성화되었음을 나타냅니다.
더 이상 페이지가 없을 때는 aria-label이 없어져 페이지네이션의 끝을 나타냅니다.
이 페이지들을 탐색할 기본적인 웹 스크레이퍼를 작성해 보겠습니다. 먼저 필요한 패키지를 설치하여 환경을 설정하세요. 파이썬을 이용한 웹 스크래핑에 대한 자세한 가이드는 여기에서 심층 블로그 포스트를 확인하실 수 있습니다.
pip install requests beautifulsoup4 lxml각 페이지를 넘겨가며 처리하는 코드는 다음과 같습니다:
import requests
from bs4 import BeautifulSoup
base_url = "https://www.scrapethissite.com/pages/forms/?page_num="
# 1페이지부터 시작
page_num = 1
while True:
url = f"{base_url}{page_num}"
response = requests.get(url)
soup = BeautifulSoup(response.content, "lxml")
print(f"현재 페이지: {page_num}")
# '다음' 버튼 존재 여부 확인
next_button = soup.find("a", {"aria-label": "Next"})
if next_button:
# 다음 페이지로 이동
page_num += 1
else:
# 더 이상 페이지 없음, 루프 종료
print("마지막 페이지에 도달했습니다.")
break이 코드는 “Next” 버튼( aria-label="Next")이 존재하는지 확인하며 페이지를 탐색합니다. 버튼이 존재하면 page_num을 증가시키고 업데이트된 URL로 새 요청을 수행합니다. “Next” 버튼이 더 이상 발견되지 않을 때까지 루프가 계속되며, 이는 마지막 페이지에 도달했음을 나타냅니다.
코드를 실행하면 모든 페이지를 성공적으로 탐색한 것을 확인할 수 있습니다.

일부 웹사이트의 ‘다음’ 버튼은 URL을 변경하지 않고 동일 페이지에 새 콘텐츠를 로드합니다. 이런 경우 기존 웹 스크래핑 방식이 제대로 작동하지 않을 수 있습니다. Selenium이나 Playwright 같은 도구가 더 적합한데, 페이지와 상호작용하여 버튼 클릭 같은 동작을 시뮬레이션해 동적으로 로드된 콘텐츠를 가져올 수 있기 때문입니다. Selenium을 활용한 자세한 가이드를 여기에서 확인할 수 있습니다.
NGINX 블로그 페이지를 스크래핑할 때도 비슷한 상황을 마주하게 될 것입니다.
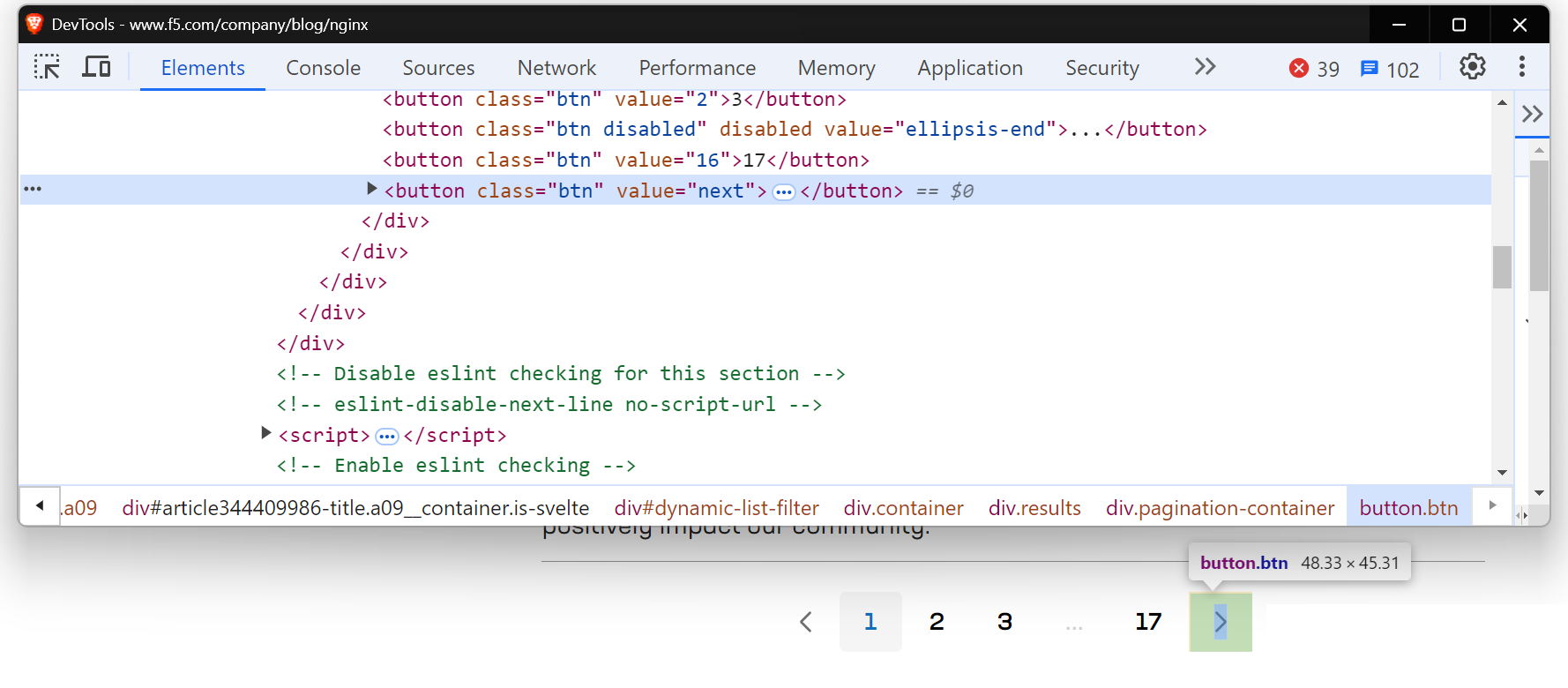
Playwright를 활용해 동적으로 로드되는 콘텐츠를 처리해 보겠습니다. Playwright가 처음이라면 이 유용한 시작 가이드를 참고하세요.
코드를 작성하기 전에, 컴퓨터에 Playwright를 설치하기 위해 다음 명령어를 실행하세요:
pip install playwright
playwright install다음은 코드입니다:
import asyncio
from playwright.async_api import async_playwright
# 비동기 함수 정의
async def scrape_nginx_blog():
async with async_playwright() as p:
# 헤드리스 모드로 크로미움 브라우저 인스턴스 실행
browser = await p.chromium.launch(headless=True)
page = await browser.new_page()
# NGINX 블로그 페이지로 이동
await page.goto("https://www.f5.com/company/blog/nginx")
page_num = 1
while True:
print(f"현재 {page_num} 페이지에 있습니다")
# 값이 "next"인 버튼 로케이터를 사용하여 '다음' 버튼 찾기
next_button = page.locator('button[value="next"]')
# '다음' 버튼이 활성화되었는지 확인
if await next_button.is_enabled():
await next_button.click() # '다음' 버튼 클릭하여 다음 페이지로 이동
await page.wait_for_timeout(
2000
) # 새 콘텐츠 로딩을 위해 2초 대기
page_num += 1
else:
print("더 이상 페이지가 없습니다. 스크래핑 완료.")
break # 더 이상 페이지가 없을 경우 루프 종료
await browser.close() # 브라우저 닫기
# 비동기 스크래핑 함수 실행
asyncio.run(scrape_nginx_blog())이 코드는 비동기식 Playwright를 사용하여 모든 페이지를 탐색합니다. ‘다음’ 버튼을 확인하는 루프에 진입합니다. 버튼이 활성화된 경우 클릭하여 다음 페이지로 이동하고 콘텐츠가 로드될 때까지 대기합니다. 이 과정은 더 이상 페이지가 없을 때까지 반복됩니다. 마지막으로 스크래핑이 완료되면 브라우저를 닫습니다.
코드를 실행하면 모든 페이지를 성공적으로 탐색한 것을 확인할 수 있습니다.
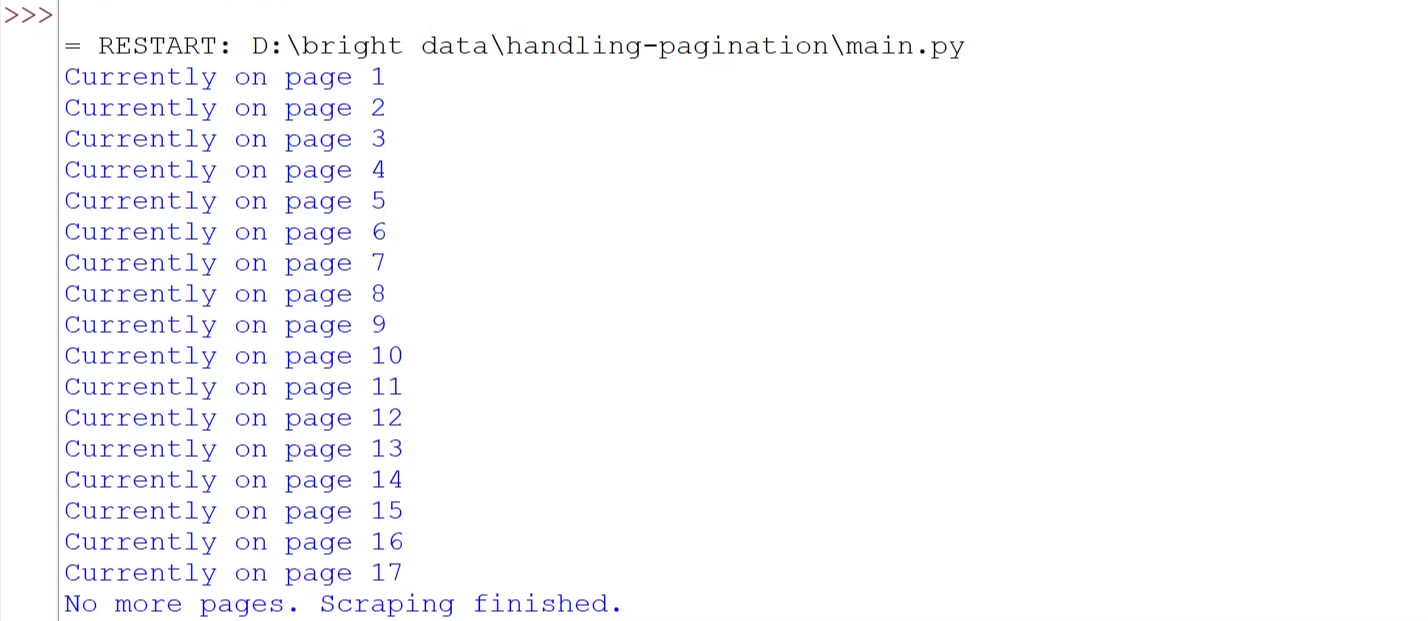
클릭하여 로드하는 페이지네이션
많은 웹사이트에서 “더 보기”, “추가 표시”, “더 보기”와 같은 버튼을 본 적이 있을 것입니다. 이는 현대적인 사이트에서 흔히 사용되는 클릭 기반 로딩 페이지네이션의 예시입니다. 이러한 버튼들은 자바스크립트를 통해 동적으로 콘텐츠를 로드합니다. 여기서 핵심 과제는 사용자 상호작용을 시뮬레이션하는 것, 즉 버튼을 클릭하여 더 많은 콘텐츠를 로드하는 과정을 자동화하는 것입니다.
Bright Data 블로그 섹션을 예로 들어 보겠습니다. 방문하여 아래로 스크롤하면 “더 보기” 버튼이 표시되며, 클릭하면 블로그 게시물이 로드됩니다.
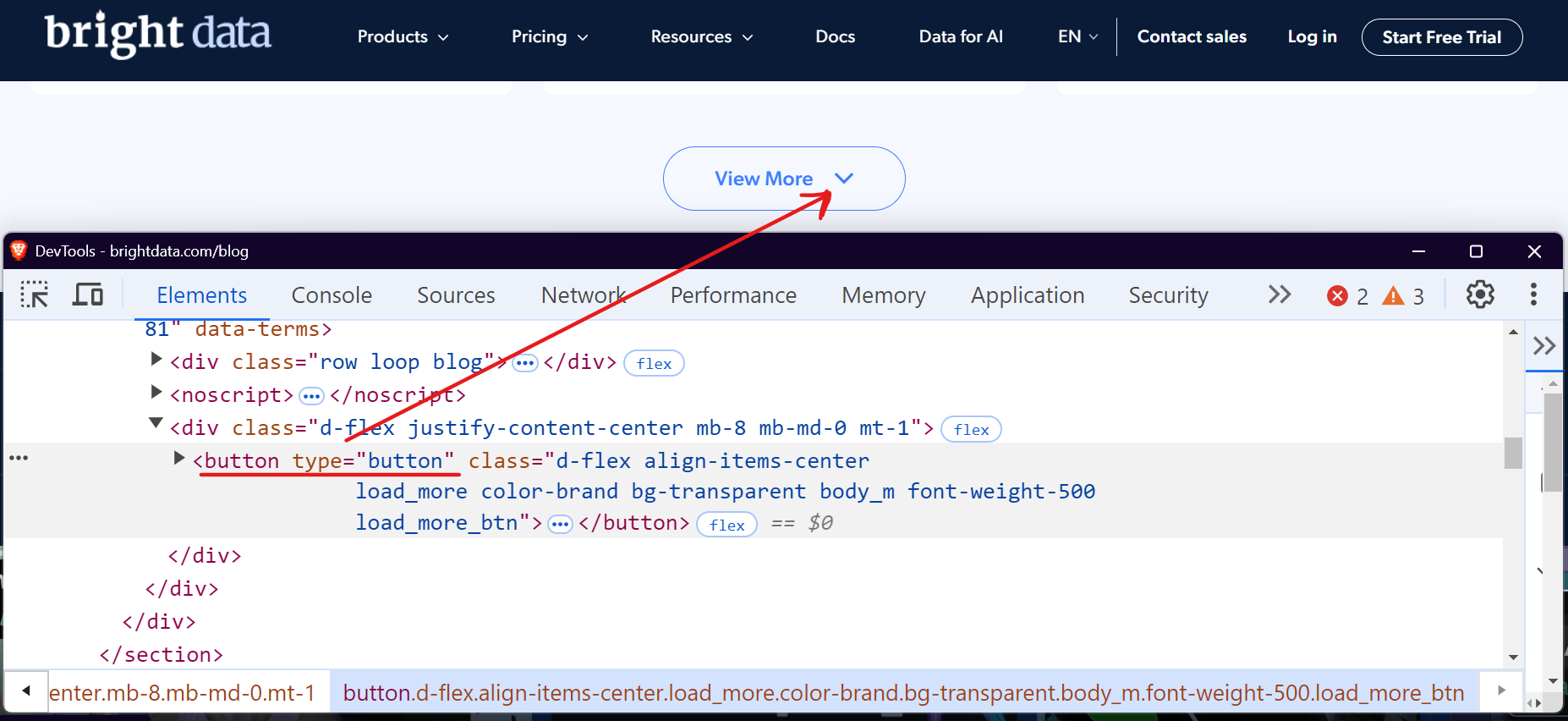
Selenium이나 Playwright 같은 도구를 사용해 “더 보기” 버튼을 더 이상 콘텐츠가 없을 때까지 반복적으로 클릭함으로써 이 과정을 자동화할 수 있습니다. Playwright로 이를 쉽게 처리하는 방법을 살펴보겠습니다.
import asyncio
from playwright.async_api import async_playwright
async def scrape_brightdata_blog():
async with async_playwright() as p:
# 헤드리스 브라우저 실행
browser = await p.chromium.launch(headless=True)
page = await browser.new_page()
# Bright Data 블로그로 이동
await page.goto("https://brightdata.com/blog")
page_num = 1
while True:
print(f"현재 {page_num} 페이지")
# "더 보기" 버튼 위치 파악
view_more_button = page.locator("button.load_more_btn")
# 버튼이 보이고 활성화되었는지 확인
if (
await view_more_button.count() > 0
and await view_more_button.is_visible()
):
await view_more_button.click()
await page.wait_for_timeout(2000)
page_num += 1
else:
print("더 이상 로드할 페이지가 없습니다. 스크래핑 완료.")
break
# 브라우저 닫기
await browser.close()
# 스크래핑 함수 실행
asyncio.run(scrape_brightdata_blog())이 코드는 CSS 선택자 button.load_more_btn을 사용하여 “더 보기” 버튼을 찾습니다. 그런 다음 count() > 0 및 is_visible()을 사용하여 버튼이 존재하고 보이는지 확인합니다. 버튼이 보이면 click() 메서드를 사용하여 상호작용하고 새 콘텐츠가 로드될 수 있도록 2초 동안 대기합니다. 이 과정은 버튼이 더 이상 보이지 않을 때까지 반복됩니다.
코드를 실행하면 모든 페이지를 성공적으로 탐색한 것을 확인할 수 있습니다.

Bright Data 블로그 섹션의 총 52개 페이지를 모두 성공적으로 스크래핑했습니다. 이는 사이트에 총 52개의 페이지가 있음을 보여주며, 이는 스크래핑 과정 후에야 확인된 사실입니다. 그러나 스크래핑 전에 총 페이지 수를 알 수도 있습니다.
이를 위해 개발자 도구를 열고 “네트워크” 탭으로 이동한 후 “Fetch/XHR”을 선택하여 요청을 필터링하세요. 그런 다음 “더 보기” 버튼을 다시 클릭하면 AJAX 요청이 트리거되는 것을 확인할 수 있습니다.
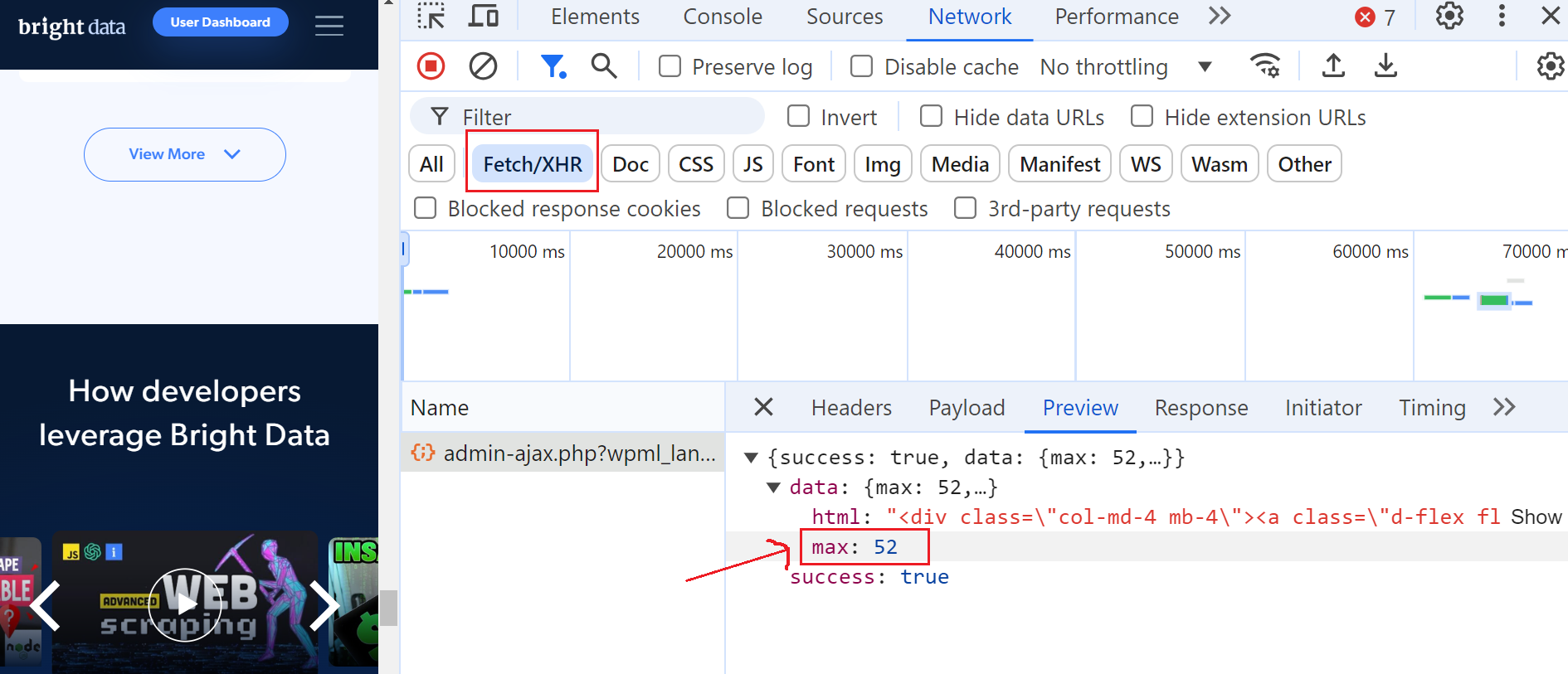
이 요청을 클릭하고 “미리 보기” 섹션으로 이동하면 최대 페이지 수가 52개임을 확인할 수 있습니다. 그런 다음 “페이로드” 섹션으로 이동하면 페이지당 6개의 블로그 게시물이 있으며 현재 3페이지에 있음을 알 수 있습니다.
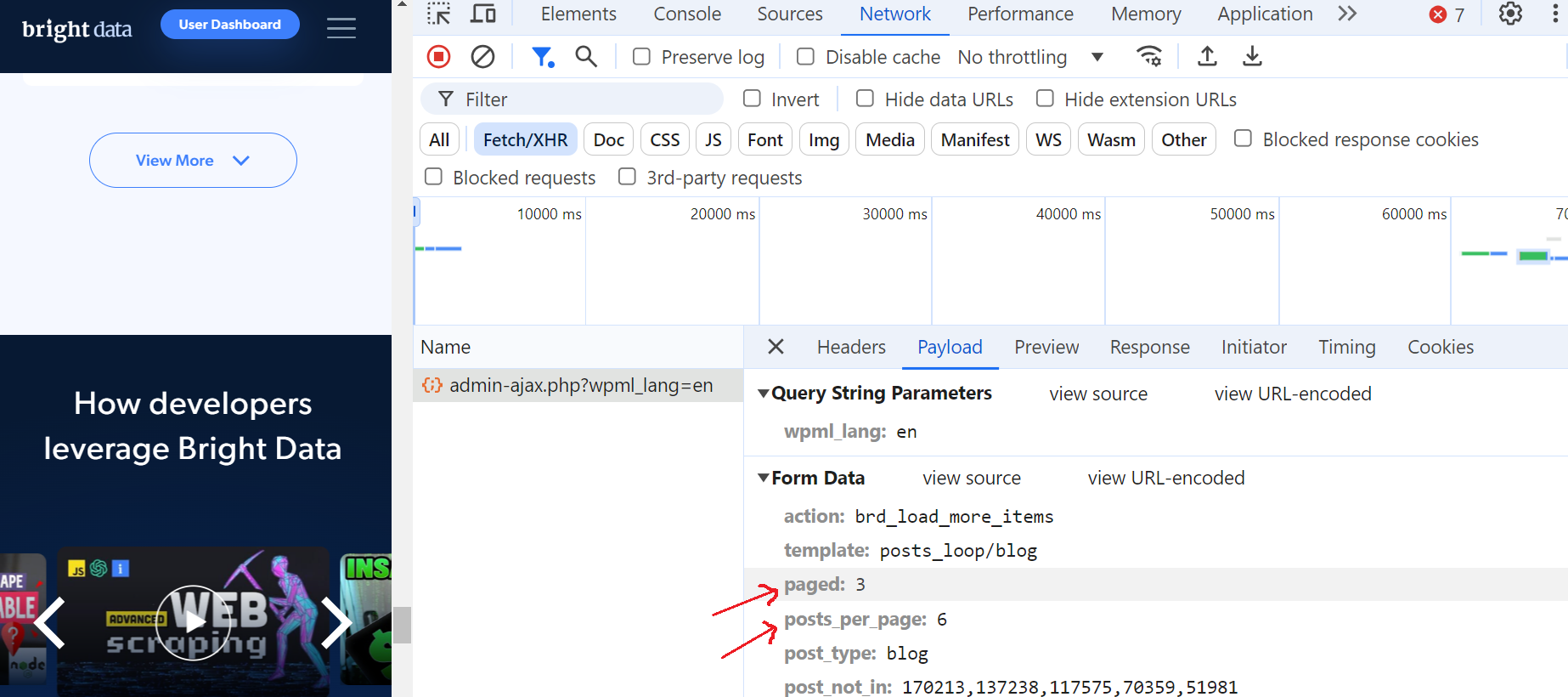
정말 훌륭하네요!
무한 스크롤 페이지네이션
많은 웹사이트가 이제 “이전/다음” 버튼 대신 무한 스크롤을 사용합니다. 이는 여러 페이지를 클릭할 필요 없이 콘텐츠를 불러와 사용자 경험을 향상시킵니다. 이 기술은 사용자가 아래로 스크롤할 때마다 자동으로 새 콘텐츠를 로드합니다. 그러나 웹 스크레이퍼에게는 DOM 변경 사항을 모니터링하고 AJAX 요청을 처리해야 하므로 독특한 도전 과제를 제시합니다.
실제 사례를 살펴보겠습니다. 나이키 웹사이트를 방문하면 아래로 스크롤할 때마다 신발 제품이 자동으로 로드되는 것을 확인할 수 있습니다. 스크롤할 때마다 로딩 아이콘이 잠깐 나타나고, 눈 깜짝할 사이에 아래 이미지처럼 더 많은 신발이 표시됩니다:
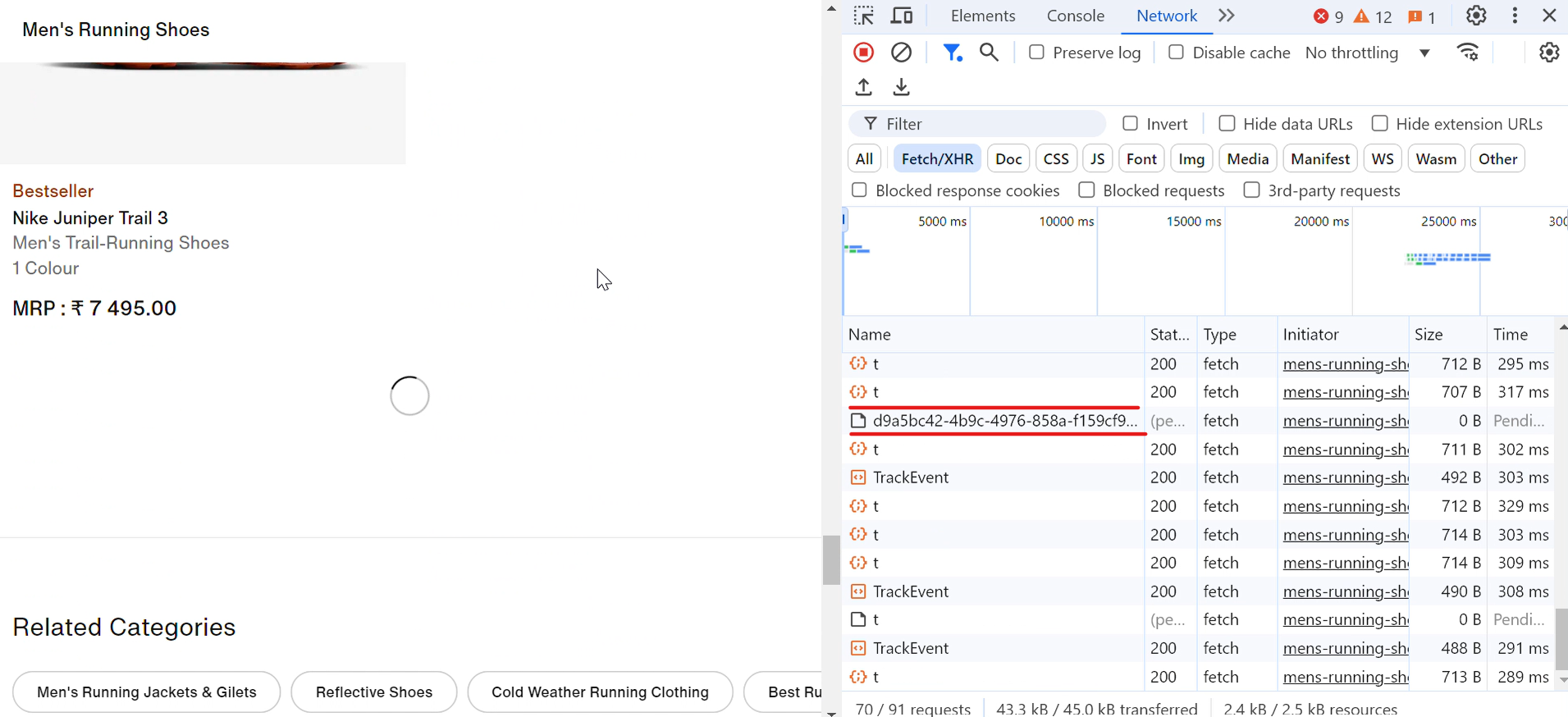
요청(d9a5bc)을 클릭하면 “응답” 탭에서 현재 페이지의 모든 데이터를 확인할 수 있습니다.
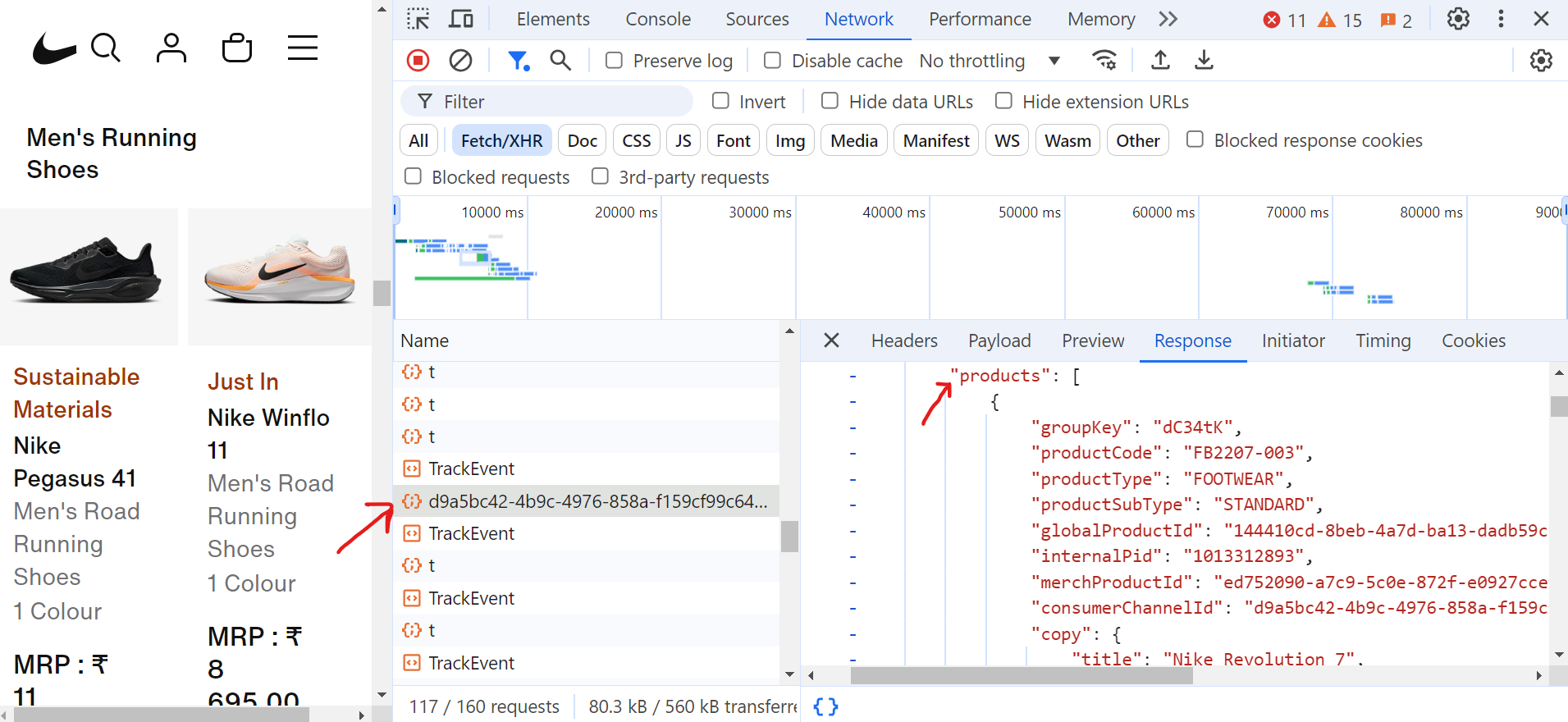
이제 페이지네이션을 처리하려면 페이지 끝까지 계속 스크롤해야 합니다. 스크롤하는 동안 브라우저는 수많은 요청을 수행하지만, 필요한 실제 데이터를 포함하는 Fetch/XHR 요청은 일부에 불과합니다.
페이지네이션을 처리하고 신발 제목을 추출하는 코드는 다음과 같습니다:
import asyncio
from urllib.parse import parse_qs, urlparse
from playwright.async_api import async_playwright
async def scroll_to_bottom(page) -> None:
"""더 이상 콘텐츠가 로드되지 않을 때까지 페이지 하단으로 스크롤합니다."""
last_height = await page.evaluate("document.body.scrollHeight")
scroll_count = 0
while True:
# 스크롤 다운
await page.evaluate("window.scrollTo(0, document.body.scrollHeight);")
await asyncio.sleep(2) # 새 콘텐츠 로딩 대기
scroll_count += 1
print(f"스크롤 반복: {scroll_count}")
# 스크롤 높이가 변경되었는지 확인
new_height = await page.evaluate("document.body.scrollHeight")
if new_height == last_height:
print("페이지 하단에 도달했습니다.")
break # 새 콘텐츠가 로드되지 않으면 종료
last_height = new_height
async def extract_product_data(response, extracted_products) -> None:
"""응답에서 제품 데이터를 추출합니다."""
parsed_url = urlparse(response.url)
query_params = parse_qs(parsed_url.query)
if "queryType" in query_params and query_params["queryType"][0] == "PRODUCTS":
data = await response.json()
for grouping in data.get("productGroupings", []):
for product in grouping.get("products", []):
title = product.get("copy", {}).get("title")
extracted_products.append({"title": title})
async def scrape_shoes(target_url: str) -> None:
async with async_playwright() as playwright:
browser = await playwright.chromium.launch(headless=True)
page = await browser.new_page()
extracted_products = []
# 제품 데이터 응답을 위한 리스너 설정
page.on(
"response",
lambda response: extract_product_data(
response, extracted_products),
)
# 페이지로 이동하고 하단으로 스크롤
print("페이지로 이동 중...")
await page.goto(target_url, wait_until="domcontentloaded")
await asyncio.sleep(2)
await scroll_to_bottom(page)
# 제품 제목을 텍스트 파일에 저장
with open("product_titles.txt", "w") as title_file:
for product in extracted_products:
title_file.write(product["title"] + "n")
print(f"스크래핑 완료!")
await browser.close()
if __name__ == "__main__":
asyncio.run(
scrape_shoes(
"https://www.nike.com/in/w/mens-running-shoes-37v7jznik1zy7ok")
)이 코드에서 scroll_to_bottom 함수는 더 많은 콘텐츠를 로드하기 위해 페이지 하단으로 계속 스크롤합니다. 현재 스크롤 위치를 기록한 후 반복적으로 아래로 스크롤합니다. 각 스크롤 후, 새로 기록된 스크롤 위치가 이전 기록과 다른지 확인합니다. 높이가 변하지 않으면 더 이상 콘텐츠가 로드되지 않는다고 판단하고 루프를 종료합니다. 이 접근 방식은 스크래핑 프로세스가 계속되기 전에 사용 가능한 모든 제품이 완전히 로드되도록 보장합니다.
코드를 실행하면 다음과 같은 결과가 나타납니다:

코드가 성공적으로 실행되면 나이키 신발의 모든 제목이 포함된 새 텍스트 파일이 생성됩니다.
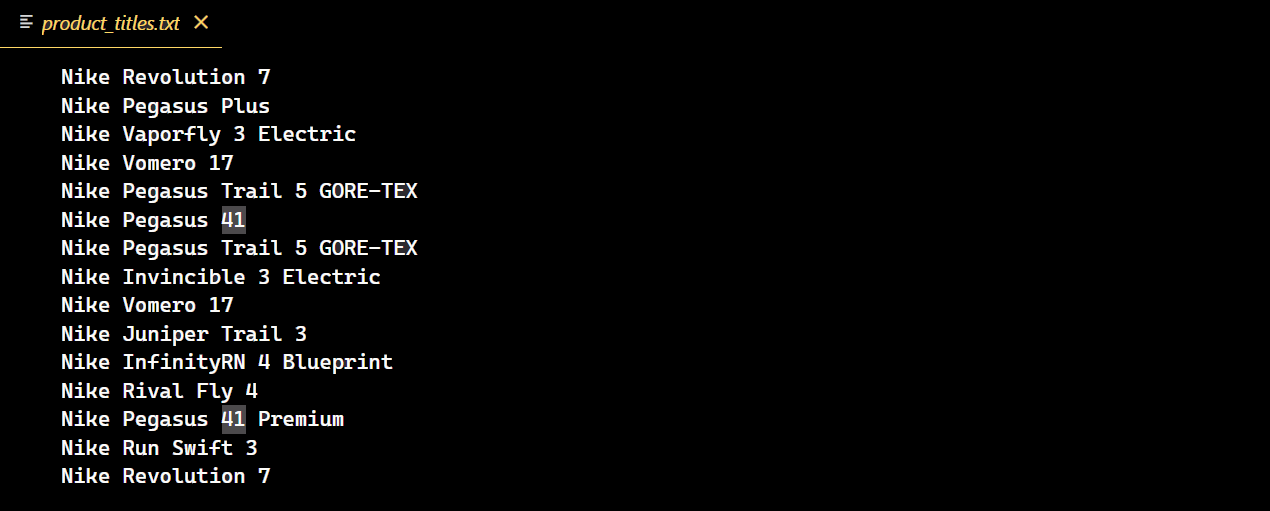
페이지네이션의 어려움
페이지네이션된 콘텐츠를 다룰 때는 차단될 위험이 증가하며, 일부 웹사이트는 단 한 페이지만 스크래핑해도 차단할 수 있습니다. 예를 들어 Glassdoor를 스크래핑하려고 시도하면 다양한 웹 스크래핑 문제를 마주칠 수 있는데, 제가 경험한 바와 같이 Cloudflare CAPTCHA 챌린지가 그중 하나입니다.
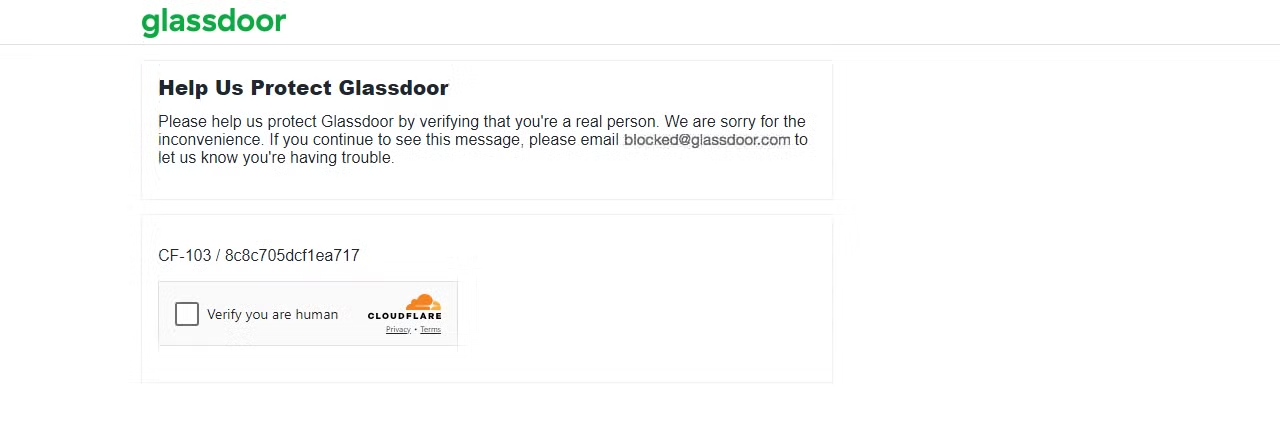
Glassdoor 페이지에 요청을 보내서 어떤 일이 발생하는지 살펴보겠습니다.
import requests
url = "https://www.glassdoor.com/"
response = requests.get(url)
print(f"Status code: {response.status_code}")결과는 403 상태 코드입니다.
이는 Glassdoor가 귀하의 요청을 봇이나 스크레이퍼로 감지하여 CAPTCHA 도전을 유발했음을 의미합니다. 계속해서 다수의 요청을 보내면 IP가 즉시 차단될 수 있습니다.
이러한 차단을 우회하고 필요한 데이터를 효과적으로 추출하려면 Python Requests에서 프록시를 사용해 IP 차단을 피하거나 사용자 에이전트를 순환시켜 실제 브라우저를 모방할 수 있습니다. 그러나 이러한 방법 중 어느 것도 고급 봇 탐지를 피할 수 있다는 보장은 없다는 점을 유의해야 합니다.
그렇다면 궁극적인 해결책은 무엇일까요? 다음에서 자세히 알아보겠습니다!
Bright Data 솔루션 도입
Bright Data는 정교한 안티봇 방어 체계를 우회하는 탁월한 솔루션입니다. 단 몇 줄의 코드로 프로젝트에 손쉽게 통합되며, 모든 고급 안티봇 메커니즘에 대응하는 다양한 솔루션을 제공합니다.
그중 하나인 웹 스크레이퍼 API는 IP 로테이션과 CAPTCHA 해결을 자동으로 처리하여 모든 웹사이트에서 데이터 추출을 간소화합니다. 이를 통해 데이터 수집의 복잡한 과정보다 데이터 분석에 집중할 수 있습니다.
예를 들어, 저희는 Glassdoor의 CAPTCHA 우회 과정에서 어려움을 겪었습니다. 이를 해결하기 위해 Bright Data의 Glassdoor 스크레이퍼 API를 활용할 수 있습니다. 이 API는 이러한 장애물을 우회하고 사이트에서 원활하게 데이터를 추출하도록 특별히 설계되었습니다.
Glassdoor 스크레이퍼 API를 시작하려면 다음 단계를 따르세요:
먼저 계정을 생성하세요. Bright Data 웹사이트를 방문하여 ‘무료 체험 시작’을 클릭하고 가입 절차를 따르세요. 로그인 후 대시보드로 이동하면 무료 크레딧을 받을 수 있습니다.
이제 웹 스크레이퍼 API 섹션으로 이동하여 B2B 데이터 카테고리에서 Glassdoor를 선택하세요. URL별 기업 수집이나 URL별 채용 공고 수집 등 다양한 데이터 수집 옵션을 확인할 수 있습니다.
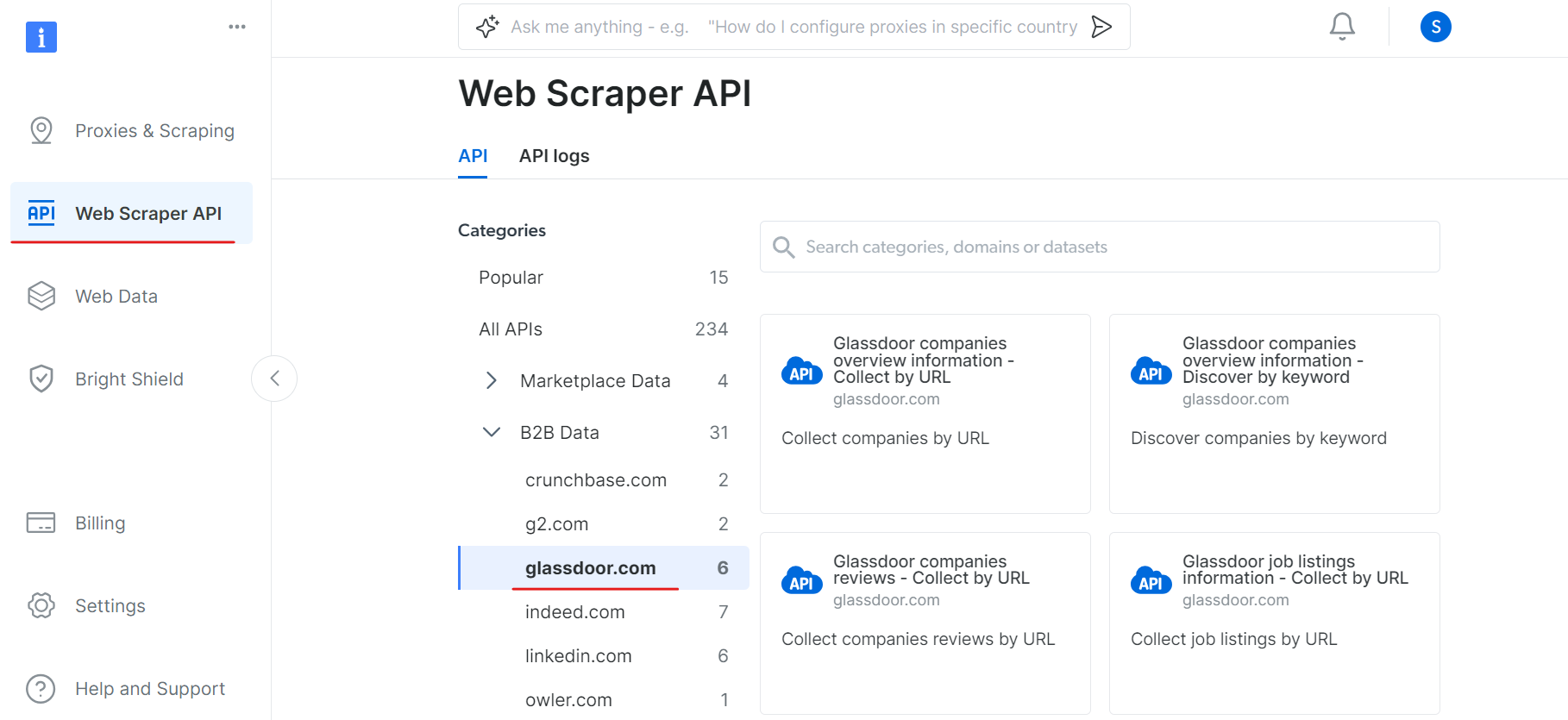
‘Glassdoor 기업 개요 정보’ 항목에서 API 토큰을 획득하고 데이터셋 ID(예: gd_l7j0bx501ockwldaqf)를 복사하세요.
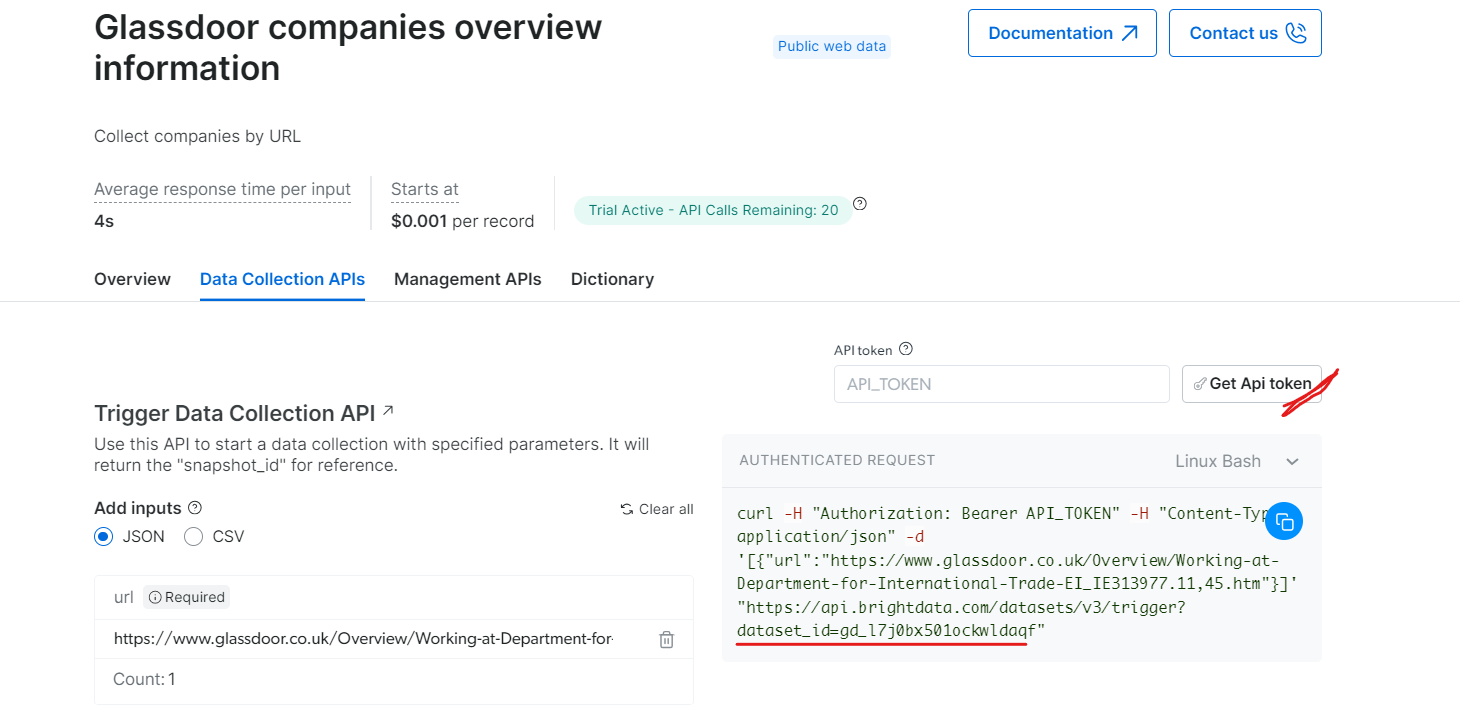
이제 URL, API 토큰, 데이터셋 ID를 제공하여 회사 데이터를 추출하는 방법을 보여주는 간단한 코드 스니펫입니다.
import requests
import json
def trigger_dataset(api_token, dataset_id, company_url):
"""
BrightData API를 사용하여 데이터셋을 트리거합니다.
인수:
api_token (str): 인증용 API 토큰.
dataset_id (str): 트리거할 데이터셋 ID.
company_url (str): 분석할 회사 페이지의 URL.
반환값:
dict: API로부터 받은 JSON 응답.
"""
headers = {
"Authorization": f"Bearer {api_token}",
"Content-Type": "application/json",
}
payload = json.dumps([{"url": company_url}])
response = requests.post(
"https://api.brightdata.com/datasets/v3/trigger",
headers=headers,
params={"dataset_id": dataset_id},
data=payload,
)
return response.json()
api_token = "API_Token"
dataset_id = "DATASET_ID"
company_url = "https://www.glassdoor.com/"
response_data = trigger_dataset(api_token, dataset_id, company_url)
print(response_data)코드를 실행하면 아래와 같은 스냅샷 ID를 받게 됩니다:

스냅샷 ID를 사용하여 해당 기업의 실제 데이터를 조회하세요. 터미널에서 다음 명령어를 실행하세요. Windows의 경우:
curl.exe -H "Authorization: Bearer API_TOKEN"
"https://api.brightdata.com/datasets/v3/snapshot/s_m0v14wn11w6tcxfih8?format=json"Linux의 경우:
curl -H "Authorization: Bearer API_TOKEN"
"https://api.brightdata.com/datasets/v3/snapshot/s_m0v14wn11w6tcxfih8?format=json"명령어를 실행하면 원하는 데이터를 얻을 수 있습니다.
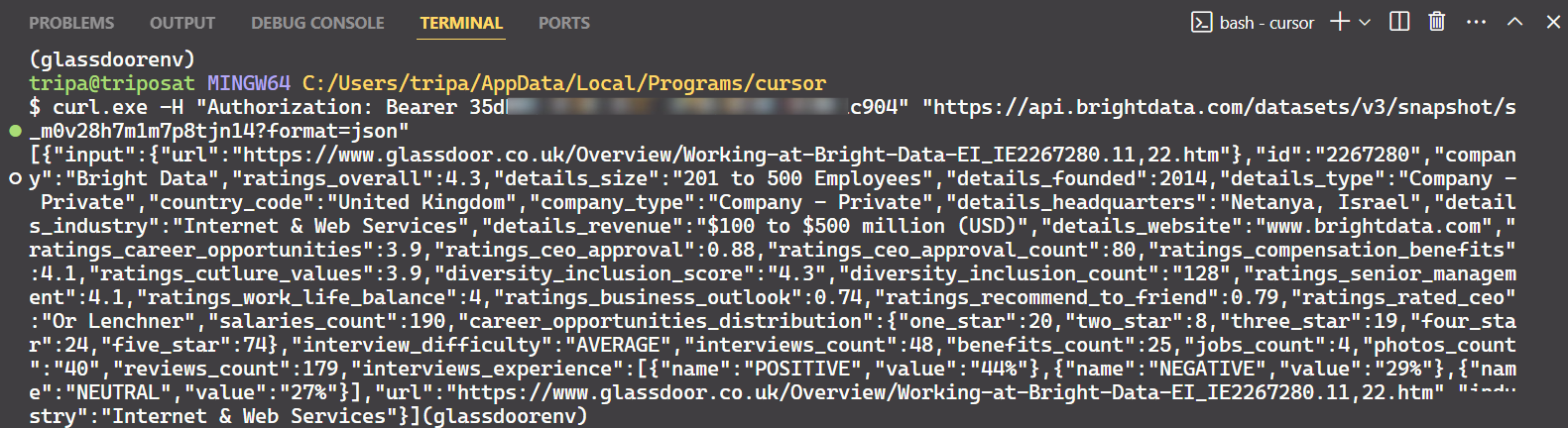
이게 전부입니다!
마찬가지로 코드를 수정하여 Glassdoor에서 다양한 유형의 데이터를 추출할 수 있습니다. 한 가지 방법을 설명했지만, 이를 수행하는 다른 다섯 가지 방법이 더 있습니다. 따라서 원하는 데이터를 스크래핑하기 위해 이러한 옵션을 탐색해 보시길 권장합니다. 각 방법은 특정 데이터 요구 사항에 맞춰져 있으며 필요한 정확한 데이터를 얻는 데 도움이 됩니다.
결론
이 글에서는 현대 웹사이트에서 흔히 사용되는 번호별 페이지네이션, “더 보기” 버튼, 무한 스크롤 등 다양한 페이지네이션 기법을 다루었습니다. 또한 이러한 페이지네이션 기술을 효과적으로 구현하기 위한 코드 예제도 제공했습니다. 그러나 페이지네이션 처리는 웹 스크래핑의 한 부분일 뿐, 봇 탐지 방지를 극복하는 것이 진정한 난관이었습니다.
고급 봇 방지 탐지를 회피하는 것은 상당히 복잡할 수 있으며 종종 성공률이 들쭉날쭉합니다. Bright Data의 도구는 웹 스크래핑에 필요한 모든 것을 위한 Web Unlocker, Scraping Browser, Web Scraper API를 포함한 간소화되고 비용 효율적인 솔루션을 제공합니다. 복잡한 봇 방지 조치를 관리하는 번거로움 없이 몇 줄의 코드만으로 더 높은 성공률을 달성할 수 있습니다.
스크래핑 과정에 전혀 관여하고 싶지 않으신가요? 저희 데이터셋 마켓플레이스를 확인해 보세요!
지금 바로 무료 체험판에 가입하세요.





