다양한 훌륭한파싱 도구가존재합니다. Python에서는선택지가거의 무한해 보입니다. 그러나 Go에서는 선택의 폭이 그리 넓지 않습니다.
Go는 성능과 메모리 관리에 탁월한 언어이지만, 파싱 라이브러리는 상당히 제한적입니다. Go 표준 라이브러리에서 사용할 수 있는 두 가지 옵션은 Node Parser와 Tokenizer입니다. 웹 스크래핑 작동 방식이 전혀 익숙하지 않다면이 가이드를 참고하세요. 함께 따라가며 이러한 도구를 언제 사용해야 하는지, 또는 더 완벽한 스크래핑 솔루션을 위해 제3자 라이브러리를 선택해야 하는 시점을 배워보세요.
필수 조건
Go와 웹 스크래핑에 대한 기본적인 이해가 있으면 도움이 되지만 필수는 아닙니다. Go에 익숙하지만 웹 스크래핑 과정을 알고 싶다면이 가이드를 참고하세요.
시작하려면 컴퓨터에 Go가 설치되어 있는지 확인하세요. 최신 버전은여기에서 찾을 수 있습니다. 시스템에 맞는 최신 버전을 다운로드하면 바로 시작할 수 있습니다!
새 프로젝트 폴더를 생성하고 해당 폴더로 이동합니다.
mkdir goparser
cd goparser
새로운 Go 프로젝트를 초기화합니다.
go mod init goparser
구성 테스트
다음 코드를 새 파일 main.go에 붙여넣으세요.
package main
import "fmt"
func main() {
fmt.Println("Hello, World!")
}
다음 명령어로 파일을 실행할 수 있습니다.
go run main.go
모든 것이 정상적으로 작동한다면 다음과 같은 출력이 표시됩니다.
Hello, World!
유일한 종속성을 설치합니다.
go get golang.org/x/net/html
페이지 검토
Quotes to Scrape는튜토리얼 스크래핑을 위해 특별히 구축된 사이트입니다. 이 튜토리얼에서는 페이지에서 각 인용문과 그 저자를 추출할 것입니다.
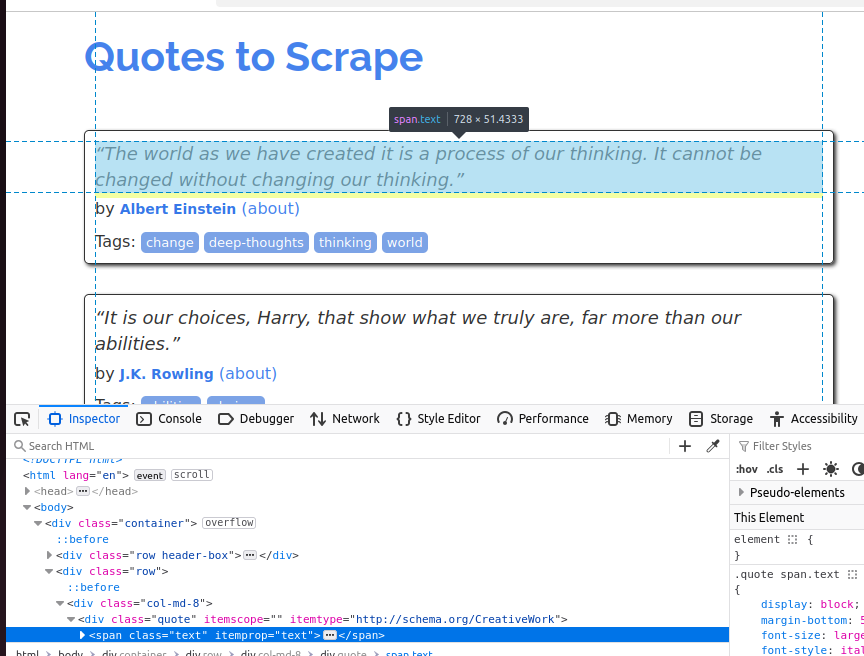
인용문 객체를 더 잘 이해하려면 아래 스크린샷을 살펴보세요. 각 인용문은 span 요소이며 그 클래스는 text입니다.
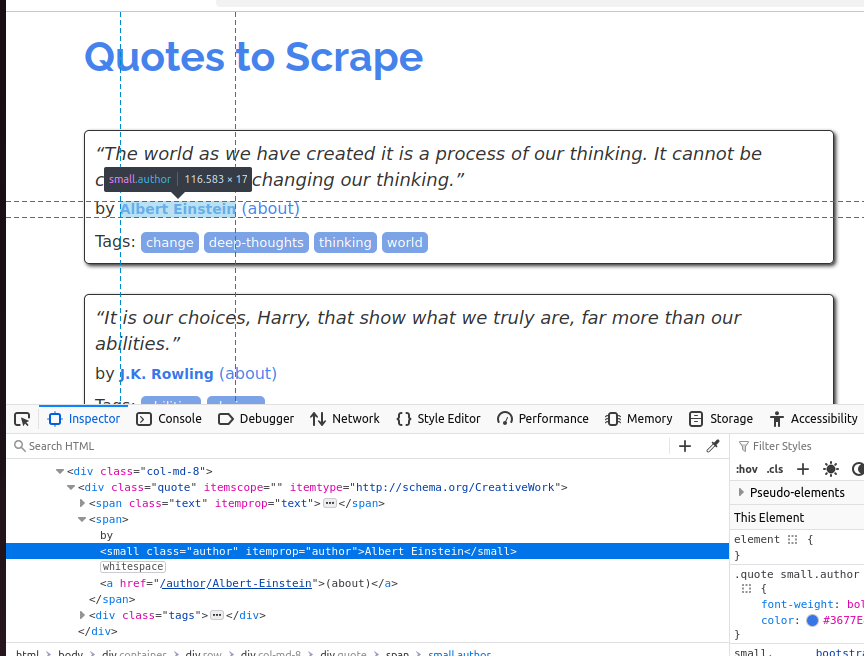
다음 스크린샷에서는 저자를 살펴봅니다. 작은 요소이며 클래스는 author입니다.
Node Parser와 Tokenizer 예제 모두 아래와 동일한 결과를 생성합니다.
인용문: "우리가 창조한 세상은 우리의 사고 과정이다. 사고를 바꾸지 않고서는 세상을 바꿀 수 없다."
저자: 알버트 아인슈타인
인용문: "해리, 우리의 진정한 모습을 보여주는 것은 능력보다 선택이다."
저자: J.K. 롤링
인용문: "삶을 사는 방법은 두 가지뿐이다. 하나는 아무것도 기적처럼 여기지 않는 삶이고, 다른 하나는 모든 것이 기적인 것처럼 사는 것이다.”
저자: 알버트 아인슈타인
인용: “좋은 소설에서 즐거움을 느끼지 못하는 사람은, 신사든 숙녀든, 참을 수 없을 만큼 어리석은 사람일 것이다.”
저자: 제인 오스틴
인용: “불완전함은 아름다움이고, 광기는 천재이며, 완전히 우스꽝스러운 것이 완전히 지루한 것보다 낫다.”
작가: 마릴린 먼로
인용: “성공한 사람이 되려 하지 마라. 차라리 가치 있는 사람이 되라.”
작가: 알베르트 아인슈타인
인용: “있는 그대로의 모습으로 미움받는 것이, 없는 모습으로 사랑받는 것보다 낫다.”
작가: 앙드레 지드
인용: “나는 실패한 것이 아니다. 단지 1만 가지 안 되는 방법을 발견했을 뿐이다.”
저자: 토머스 A. 에디슨
인용: "여자는 티백과 같다. 뜨거운 물에 담그기 전까지는 그 강도를 알 수 없다."
저자: 엘리너 루스벨트
인용: "햇빛 없는 하루는, 알다시피, 밤과 같다."
저자: 스티브 마틴
Node Parser를 이용한 데이터 추출
Go의 Node Parser는 DOM(문서 객체 모델)을 탐색하고 재귀적으로 조작할 수 있게 해줍니다. Node Parser를 사용하면 전체 HTML 페이지를 트리 구조의 Node 객체로 변환하여 진행하면서 파싱할 수 있습니다.
아래 코드에서는 재귀 함수 processNode()를 생성합니다. 이 함수는 HTML 노드 포인터를 인수로 받습니다. 노드가 span이고 그 class가 text라면, 해당 인용문을 콘솔에 출력합니다. 노드가 small 요소이고 그 class가 author라면, 저자를 콘솔에 출력합니다. 이는 앞서 페이지 검사 시 발견한 속성과 동일합니다.
package main
import (
"fmt"
"net/http"
"golang.org/x/net/html")
func main() {
resp, _ := http.Get("http://quotes.toscrape.com")
defer resp.Body.Close()
doc, _ := html.Parse(resp.Body)
var processNode func(*html.Node)
processNode = func(n *html.Node) {
if n.Type == html.ElementNode && n.Data == "span" {
for _, a := range n.Attr {
if a.Key == "class" && a.Val == "text" {
fmt.Println("Quote:", n.FirstChild.Data)
}
}
}
if n.Type == html.ElementNode && n.Data == "small" {
for _, a := range n.Attr {
if a.Key == "class" && a.Val == "author" {
fmt.Println("Author:", n.FirstChild.Data)
}
}
}
for c := n.FirstChild; c != nil; c = c.NextSibling {
processNode(c)
}
}
processNode(doc)
}
문서 전체를 처리해야 할 때는 Node Parser API가 유용합니다. 메모리 효율성을 위해 실제 문서에 대한 포인터를 사용하고, 문서를 탐색하면서 데이터를 처리할 수 있습니다.
토큰라이저를 이용한 데이터 추출
토큰라이저는 페이지를 약간 다르게 처리합니다. html.NewTokenizer(resp.Body) 를 사용하여 응답 본문을 토큰라이저 객체로 생성합니다. 그런 다음 페이지에서 추출할 토큰(HTML 태그, 텍스트 콘텐츠 또는 속성)을 선택합니다.
각 토큰을 처리할 때 inQuote와 inAuthor라는 두 개의 부울 객체가 있습니다. 토큰이 인용문이나 저자 태그 안에 있으면 해당 토큰을 트리밍하여 데이터를 콘솔에 출력합니다. 이 코드의 출력은 동일하지만 실제 작동 방식은 매우 다릅니다. Node Parser는 트리를 탐색하며 데이터를 한 번에 하나의 노드씩 처리하는 반면, 토큰라이저는 한 번에 하나의 청크(chunk)씩 처리합니다.
아래 코드에서는 두 개의 시작 토큰( span, small)을 지정합니다. 처리 중인 청크가 span 요소이고 그 클래스가 text라면 콘솔에 출력합니다. 청크가 small 이고 그 클래스가 author라면 역시 콘솔에 출력합니다. 페이지의 다른 모든 토큰(HTML 태그)은 완전히 무시됩니다.
package main
import (
"fmt"
"net/http"
"strings"
"golang.org/x/net/html"
)
func main() {
resp, _ := http.Get("http://quotes.toscrape.com")
defer resp.Body.Close()
tokenizer := html.NewTokenizer(resp.Body)
inQuote := false
inAuthor := false
for {
tt := tokenizer.Next()
switch tt {
case html.ErrorToken:
return
case html.StartTagToken:
t := tokenizer.Token()
if t.Data == "span" {
for _, a := range t.Attr {
if a.Key == "class" && a.Val == "text" {
inQuote = true
}
}
}
if t.Data == "small" {
for _, a := range t.Attr {
if a.Key == "class" && a.Val == "author" {
inAuthor = true
}
}
}
case html.TextToken:
if inQuote {
fmt.Println("Quote:", strings.TrimSpace(tokenizer.Token().Data))
inQuote = false
}
if inAuthor {
fmt.Println("Author:", strings.TrimSpace(tokenizer.Token().Data))
inAuthor = false
}
}
}
}
토큰화기는 노드 파서보다 약간 더 저수준이지만 훨씬 효율적입니다. 문서 전체를 탐색하는 대신 관련 토큰(HTML 태그)만 처리하면 됩니다. 이는 데이터 스트림에서 대량의 데이터를 처리할 때 가장 적합합니다. 토큰화기를 사용하면 전체 페이지 대신 관련 데이터만 처리하면 됩니다.
타사 대안 도구
Node Parser와 Tokenizer는 Python이나 JavaScript에서 제공하는 도구들에 비해 상당히 저수준입니다. 스크래핑을 좀 더 쉽게 만들어 줄 수 있는 몇 가지 타사 도구를 소개합니다.
Goquery
Jquery의 Go 기반 대안으로 개발된Goquery는직관적인 파서를 찾는 경우 탁월한 선택입니다. Goquery를 사용하면 DOM 탐색 및 CSS 선택기 지원을 받을 수 있습니다. 이는 다른 언어에서 익숙한 솔루션과 훨씬 유사합니다.
htmlquery
Goquery와 유사하게htmlquery도DOM 탐색과 선택자를 모두 사용할 수 있게 해줍니다. 다만 htmlquery에서는 CSS 선택자 대신 XPath 선택자를 사용합니다. Goquery와 htmlquery 중 선택은 선호하는 선택자 유형에 따라 결정해야 합니다.
Colly
Colly는Go용 완전한 웹 스크래핑 프레임워크입니다. Colly를 사용하면 CSS 선택자, 동시성 처리 등 다양한 기능을 지원받을 수 있습니다.Scrapy의 Go 버전이라고 생각하시면 됩니다. Colly 사용에 관심이 있으시다면,여기에서 훌륭한 튜토리얼을 확인하실 수 있습니다.
Bright Data 웹 스크레이퍼
당사의웹 스크레이퍼를사용하면 스크래핑 과정을 완전히 우회할 수 있습니다. 웹 스크레이퍼는 페이지를 스크래핑하여 데이터를 JSON 형식으로 반환합니다. DOM 탐색, 토큰 작성 또는 셀렉터 작성 대신 API 요청만 수행하고 작업을 진행하고 싶을 때 탁월한 선택입니다. 저희 웹 스크레이퍼는 Go 라이브러리가 아닌 API 서비스입니다. REST API 처리 방법을 알고 계시다면, 스크래핑 프로세스를 자동화하는 정말 간단한 방법입니다.
결론
이제 Go를 사용해 HTML을 파싱하는 방법을 알게 되었습니다. 더 포괄적인 기능 세트를 원한다면Go에서의 프록시 통합 가이드를 참고하세요. 페이지 전체를 탐색하려면 Node Parser를 사용하세요. 페이지에서 관련 데이터만 파싱하고 싶다면 Tokenizer를 시도해 보세요. 이 둘 모두 적합하지 않다면 Bright Data의 웹 스크레이퍼와 같은 다양한 타사 도구가 있습니다. 지금 가입하고 무료 체험을 시작하세요!