

이 튜토리얼에서는 Go가 웹 스크래핑을 효율적으로 수행하는 최고의 언어 중 하나인 이유를 이해하고, Go 스크래퍼를 처음부터 구축하는 방법을 배웁니다.
이 글에서는 다음을 다룹니다:
- Go로 웹 스크래핑을 수행할 수 있나요?
- 최고의 Go 웹 스크래핑 라이브러리
- Go로 웹 스크레이퍼 구축하기
Go로 웹 스크래핑을 수행할 수 있나요?
Go(골랭)은 Google이 개발한 정적 타입 프로그래밍 언어입니다. 효율적이고 동시 실행이 가능하며, 코드 작성과 유지보수가 용이하도록 설계되었습니다. 이러한 특성 덕분에 최근 웹 스크래핑을 포함한 다양한 분야에서 Go가 널리 채택되고 있습니다.
구체적으로 Go는 웹 스크래핑 작업에 유용한 강력한 기능을 제공합니다. 여기에는 여러 웹 요청의 동시 처리를 지원하는 내장 동시성 모델이 포함됩니다. 이는 Go를 여러 웹사이트에서 대량의 데이터를 효율적으로 스크래핑하는 데 이상적인 언어로 만듭니다. 또한 Go의 표준 라이브러리에는 웹 페이지 가져오기, HTML 파싱, 웹사이트에서 데이터 추출에 사용할 수 있는 HTTP 클라이언트 및 HTML 파싱 패키지가 포함되어 있습니다.
이러한 기능과 기본 패키지가 부족하거나 사용이 어렵다면, 여러 Go 웹 스크래핑 라이브러리도 존재합니다. 가장 인기 있는 라이브러리를 살펴보겠습니다!
최고의 Go 웹 스크래핑 라이브러리
다음은 Go용 최고의 웹 스크래핑 라이브러리 목록입니다:
- Colly: Go용 강력한 웹 스크래핑 및 크롤링 프레임워크입니다. HTTP 요청 생성, 헤더 관리, DOM 파싱을 위한 함수형 API를 제공합니다. Colly는 병렬 스크래핑, 속도 제한, 자동 쿠키 처리도 지원합니다.
- Goquery: jQuery와 유사한 구문을 기반으로 한 Go의 인기 HTML 파싱 라이브러리입니다. CSS 선택자를 통해 HTML 요소를 선택하고, DOM을 조작하며, 데이터를 추출할 수 있습니다.
- Selenium: 가장 널리 쓰이는 웹 테스트 프레임워크의 Go 클라이언트입니다. 웹 스크래핑을 포함한 다양한 작업을 위해 웹 브라우저를 자동화할 수 있게 합니다. 특히 Selenium은 웹 브라우저를 제어하고 인간 사용자와 동일하게 페이지와 상호작용하도록 지시할 수 있습니다. 또한 데이터 검색이나 렌더링에 JavaScript를 사용하는 웹 페이지에서도 스크래핑을 수행할 수 있습니다.
필수 조건
시작하기 전에 컴퓨터에 Go를 설치해야 합니다. 설치 절차는 운영 체제에 따라 달라집니다.
macOS에서 Go 설정하기
- Go를 다운로드합니다.
- 다운로드한 파일을 열고 설치 안내를 따릅니다. 패키지는 Go를 /usr/local/go에 설치하고 PATH 환경 변수에 /usr/local/go/bin을 추가합니다.
- 열려 있는 터미널 세션을 모두 다시 시작하세요.
Windows에서 Go 설정하기
- Go 다운로드
- 다운로드한 MSI 파일을 실행하고 설치 마법사를 따르세요. 설치 프로그램은 Go를 C:/Program Files 또는 C:/rogram Files (x86)에 설치하고 bin 폴더를 PATH 환경 변수에 추가합니다.
- 열려 있는 명령 프롬프트를 닫고 다시 엽니다.
Linux에서 Go 설정하기
- Go 다운로드
- 시스템에 /usr/local/go 폴더가 없는지 확인하십시오. 존재하는 경우 다음 명령어로 삭제하십시오:
rm -rf /usr/local/go- 다운로드한 아카이브를 /usr/local에 추출하세요:
tar -C /usr/local -xzf goX.Y.Z.linux-amd64.tar.gzX.Y.Z는 다운로드한 Go 패키지 버전으로 반드시 교체하십시오.
- PATH 환경 변수에 /usr/local/go/bin을 추가하십시오:
export PATH=$PATH:/usr/local/go/bin- PC를 재부팅하세요.
사용 중인 OS와 관계없이 아래 명령어로 Go가 성공적으로 설치되었는지 확인하세요:
go version다음과 같은 결과가 반환됩니다:
go version go1.20.3잘하셨습니다! 이제 Go 웹 스크래핑을 시작할 준비가 되었습니다!
Go로 웹 스크레이퍼 구축하기
여기서는 Go 웹 스크레이퍼를 구축하는 방법을 배웁니다. 이 자동화된 스크립트는 Bright Data 홈페이지에서 데이터를 자동으로 가져올 수 있습니다. Go 웹 스크래핑 프로세스의 목표는 페이지에서 특정 HTML 요소를 선택하고, 해당 요소에서 데이터를 추출한 후 수집된 데이터를 탐색하기 쉬운 형식으로 변환하는 것입니다.
작성 시점 기준, 대상 사이트의 모습은 다음과 같습니다:
단계별 튜토리얼을 따라가며 Go로 웹 스크래핑을 수행하는 방법을 배워보세요!
1단계: Go 프로젝트 설정
Go 웹 스크레이퍼 프로젝트를 시작할 시간입니다. 터미널을 열고 go-web-scraper 폴더를 생성하세요:
mkdir go-web-scraper이 디렉토리에 Go 프로젝트가 포함됩니다.
다음으로 아래 init 명령어를 실행하세요:
go mod init web-scraper이렇게 하면 프로젝트 루트 내에 웹 스크레이퍼 모듈이 초기화됩니다.
이제 go-web-scraper 디렉토리에 다음 go.mod 파일이 포함됩니다:
module web-scraper
go 1.20마지막 줄은 사용 중인 Go 버전에 따라 달라집니다.
이제 IDE에서 Go 로직 작성을 시작할 준비가 되었습니다! 이 튜토리얼에서는 Visual Studio Code를 사용할 예정입니다. Go를 기본적으로 지원하지 않으므로 먼저 Go 확장 프로그램을 설치해야 합니다.
VS Code를 실행하고 왼쪽 바의 “확장 프로그램” 아이콘을 클릭한 후 “Go”를 입력하세요.
첫 번째 카드의 “설치” 버튼을 클릭하여 Visual Studio Code용 Go 확장 프로그램을 추가하세요.
“파일”을 클릭하고 “폴더 열기…”를 선택한 후 go-web-scraper 디렉터리를 엽니다.
“탐색기” 섹션을 마우스 오른쪽 버튼으로 클릭하고 “새 파일…”을 선택한 후 다음과 같이 scraper.go 파일을 생성하세요:
// scraper.go
package main
import (
"fmt")
func main() {
fmt.Println("Hello, World!")
}main() 함수는 모든 Go 애플리케이션의 진입점을 나타낸다는 점을 기억하세요. 여기에 Golang 웹 스크래핑 로직을 배치해야 합니다.
Visual Studio Code는 Go와의 통합을 완료하기 위해 일부 패키지 설치를 요청할 것입니다. 모두 설치하세요. 그런 다음 VS 터미널에서 아래 명령을 실행하여 Go 스크립트를 실행합니다:
go run scraper.go
그러면 다음과 같이 출력됩니다:
Hello, World!2단계: Colly 시작하기
Go로 웹 스크레이퍼를 더 쉽게 구축하려면 앞서 소개된 패키지 중 하나를 사용해야 합니다. 하지만 먼저, 어떤 Golang 웹 스크래핑 라이브러리가 목표에 가장 적합한지 파악해야 합니다. 이를 위해 대상 웹사이트를 방문하고, 배경에서 마우스 오른쪽 버튼을 클릭한 후 “검사” 옵션을 선택하세요. 그러면 브라우저의 개발자 도구(DevTools)가 열립니다. “네트워크” 탭에서 “Fetch/XHR” 섹션을 살펴보세요.

위에서 볼 수 있듯이 대상 웹 페이지는 소수의 AJAX 요청만 수행합니다. 각 XHR 요청을 살펴보면 의미 있는 데이터를 반환하지 않음을 알 수 있습니다. 즉, 서버가 반환하는 HTML 문서에 이미 모든 데이터가 포함되어 있습니다. 이는 일반적으로 정적 콘텐츠 사이트에서 발생하는 현상입니다.
이는 대상 사이트가 데이터를 동적으로 가져오거나 렌더링 목적으로 자바스크립트에 의존하지 않음을 보여줍니다. 따라서 대상 웹 페이지에서 데이터를 가져오기 위해 헤드리스 브라우저 기능을 가진 라이브러리가 필요하지 않습니다. 셀레니움을 사용할 수는 있지만, 이는 성능 오버헤드만 발생시킬 뿐입니다. 이러한 이유로 Colly와 같은 간단한 HTML 파서를 사용하는 것이 좋습니다.
프로젝트 종속성에 Colly를 추가하려면 다음을 실행하세요:
go get github.com/gocolly/colly이 명령어는 go.sum 파일을 생성하고 go.mod 파일을 자동으로 업데이트합니다.
사용을 시작하기 전에 Colly의 핵심 개념을 숙지해야 합니다.
Colly의 핵심 엔터티는 Collector입니다. 이 객체를 통해 다음 콜백을 통해 HTTP 요청을 수행하고 웹 스크래핑을 실행할 수 있습니다:
- OnRequest(): Visit()로 HTTP 요청을 수행하기 전에 호출됩니다.
- OnError(): HTTP 요청 중 오류 발생 시 호출됩니다.
- OnResponse(): 서버로부터 응답을 받은 후 호출됩니다.
- OnHTML(): 서버가 유효한 HTML 문서를 반환한 경우 OnResponse() 이후 호출됩니다.
- OnScraped(): 모든 OnHTML() 호출이 종료된 후 호출됩니다.
이러한 각 함수는 콜백을 매개 변수로 받습니다. 함수와 관련된 이벤트가 발생하면 Colly는 입력된 콜백을 실행합니다. 따라서 Colly에서 데이터 스크레이퍼를 구축하려면 콜백을 기반으로 한 함수형 접근 방식을 따라야 합니다.
NewCollector() 함수로 Collector 객체를 초기화할 수 있습니다:
c := colly.NewCollector()
Colly를 임포트하고 scraper.go를 다음과 같이 업데이트하여 Collector를 생성합니다:
// scraper.go
package main
import (
// Colly 임포트
"github.com/gocolly/colly")
func main() {
c := colly.NewCollector()
// 스크래핑 로직...
}3단계: 대상 웹사이트에 연결하기
Colly를 사용하여 다음 명령어로 대상 페이지에 연결합니다:
c.Visit("https://brightdata.com/")Visit() 함수는 내부적으로 HTTP GET 요청을 수행하여 서버에서 대상 HTML 문서를 가져옵니다. 구체적으로 onRequest 이벤트를 발생시키고 Colly 기능 라이프사이클을 시작합니다. Visit()는 다른 Colly 콜백을 등록한 후에 호출해야 합니다.
Visit()가 수행하는 HTTP 요청은 실패할 수 있습니다. 이 경우 Colly는 OnError 이벤트를 발생시킵니다. 실패 원인은 서버 일시적 접속 불가부터 유효하지 않은 URL까지 다양합니다. 동시에 대상 사이트가 봇 방지 조치를 채택한 경우 웹 스크레이퍼는 일반적으로 실패합니다. 예를 들어, 이러한 기술은 일반적으로 유효한 User-Agent HTTP 헤더가 없는 요청을 걸러냅니다. 웹 스크레이핑용 User-Agent에 대해 자세히 알아보려면 가이드를 참조하세요.
기본적으로 Colly는 인기 브라우저에서 사용하는 에이전트와 일치하지 않는 자리 표시자 User-Agent를 설정합니다. 이로 인해 Colly 요청은 스크래핑 방지 기술에 의해 쉽게 식별됩니다. 이를 방지하려면 아래와 같이 Colly에 유효한 User-Agent 헤더를 지정하세요:
c.UserAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36이제 모든 Visit() 호출은 해당 HTTP 헤더로 요청을 수행합니다.
이제 scraper.go 파일은 다음과 같아야 합니다:
// scraper.go
package main
import (
// Colly 가져오기
"github.com/gocolly/colly")
func main() {
// 수집기 초기화
c := colly.NewCollector()
// 유효한 User-Agent 헤더 설정
c.UserAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36"
// 대상 사이트에 연결
c.Visit("https://brightdata.com/")
// 스크래핑 로직...
}4단계: HTML 페이지 검사
효과적인 데이터 추출 전략을 정의하기 위해 대상 웹 페이지의 DOM을 분석해 보겠습니다.
브라우저에서 Bright Data 홈페이지를 엽니다. 살펴보면 Bright Data 서비스가 경쟁 우위를 제공할 수 있는 산업별 카드 목록이 표시됩니다. 스크래핑하기에 흥미로운 정보입니다.
이러한 HTML 카드 중 하나를 마우스 오른쪽 버튼으로 클릭하고 “검사”를 선택하세요:
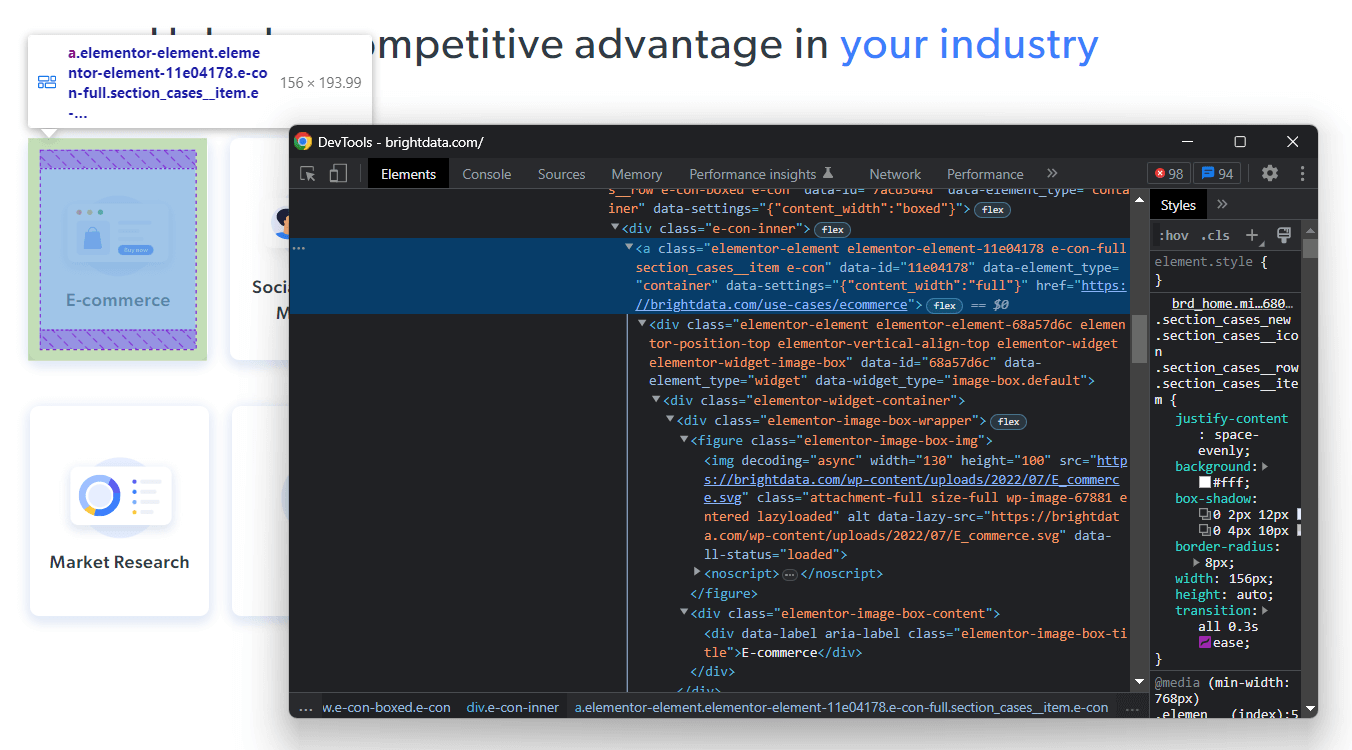
개발자 도구(DevTools)에서 선택한 노드의 DOM HTML 코드를 확인할 수 있습니다. 각 산업 카드마다 <a> HTML 요소가 사용된다는 점에 유의하세요. 구체적으로 각 <a> 요소는 다음 두 가지 핵심 HTML 요소를 포함합니다:
- 산업 카드의 이미지를 저장하는 <figure>
- 해당 산업 분야명을 표시하는 <div>
이제 관심 대상 HTML 요소와 그 상위 요소가 사용하는 CSS 클래스에 집중하세요. 이를 통해 원하는 DOM 요소를 추출하는 데 필요한 CSS 선택기 전략을 정의할 수 있습니다.
자세히 설명하면, 각 카드는 section_cases__item 클래스로 특징지어지며 .elementor-element-6b05593c <div>에 포함됩니다. 따라서 다음 CSS 선택자로 모든 산업 카드를 가져올 수 있습니다:
.elementor-element-6b05593c .section_cases__item특정 카드를 대상으로 할 경우, 해당 카드의 <figure> 및 <div> 자식 요소를 다음과 같이 선택할 수 있습니다:
.elementor-image-box-img img
.elementor-image-box-content .elementor-image-box-titleGo 스크레이퍼의 목표는 각 카드에서 URL, 이미지, 산업명을 추출하는 것입니다.
5단계: Colly로 HTML 요소 선택
Colly에서 CSS 또는 XPath 선택자를 다음과 같이 적용할 수 있습니다:
c.OnHTML(".your-css-selector", func(e *colly.HTMLElement) {
// 데이터 추출 로직...
})Colly는 CSS 선택자와 일치하는 각 HTML 요소에 대해 매개변수로 전달된 함수를 호출합니다. 즉, 선택된 모든 요소를 자동으로 반복 처리합니다.
콜렉터에는 여러 개의 OnHTML() 콜백이 있을 수 있다는 점을 잊지 마십시오. 이들은 코드에 onHTML() 지시문이 나타나는 순서대로 실행됩니다.
6단계: Colly로 웹페이지 데이터 스크래핑하기
Colly를 사용하여 HTML 웹페이지에서 원하는 데이터를 추출하는 방법을 알아보세요.
스크래핑 로직을 작성하기 전에 추출된 데이터를 저장할 데이터 구조가 필요합니다. 예를 들어, 다음과 같이 Struct를 사용하여 Industry 데이터 유형을 정의할 수 있습니다:
type Industry struct {
Url, Image, Name string
}Go에서 Struct는 객체로 인스턴스화될 수 있는 일련의 타입화된 필드를 지정합니다. 객체 지향 프로그래밍에 익숙하다면 Struct를 일종의 클래스로 생각할 수 있습니다.
그런 다음 Industry 유형의 슬라이스가 필요합니다:
var industries []IndustryGo의 슬라이스는 단순한 리스트에 불과합니다.
이제 OnHTML() 함수를 사용하여 아래와 같이 스크래핑 로직을 구현할 수 있습니다:
// 산업 카드 목록 반복
// HTML 요소
c.OnHTML(".elementor-element-6b05593c .section_cases__item", func(e *colly.HTMLElement) {
url := e.Attr("href")
image := e.ChildAttr(".elementor-image-box-img img", "data-lazy-src")
name := e.ChildText(".elementor-image-box-content .elementor-image-box-title")
// 원하지 않는 데이터 필터링
if url!= "" || image != "" || name != "" {
// 새로운 Industry 인스턴스 초기화
industry := Industry{
Url: url,
Image: image,
Name: name,
}
// 스크랩된 산업 목록에 인스턴스 추가
// 스크랩된 산업 목록에
industries = append(industries, industry)
}
})위의 웹 스크래핑 Go 코드 조각은 Bright Data 홈페이지에서 모든 산업 카드를 선택하고 이를 반복 처리합니다. 그런 다음 각 카드와 연관된 URL, 이미지, 산업 이름을 스크래핑하여 채웁니다. 마지막으로 새로운 Industry 객체를 생성하고 industries 슬라이스에 추가합니다.
보시다시피 Colly에서 스크래핑을 실행하는 것은 간단합니다. Attr() 메서드를 사용하면 현재 요소에서 HTML 속성을 추출할 수 있습니다. 대신 ChildAttr() 과 ChildText() 는 CSS 선택자를 통해 선택한 HTML 자식 요소의 속성값과 텍스트를 제공합니다.
산업 상세 페이지에서도 데이터를 수집할 수 있다는 점을 기억하세요. 현재 페이지에서 발견된 링크를 따라가며 새로운 스크래핑 로직을 구현하기만 하면 됩니다. 이것이 바로 웹 크롤링과 웹 스크래핑의 핵심입니다!
잘하셨습니다! 이제 Go를 사용해 웹 스크래핑 목표를 달성하는 방법을 배웠습니다!
7단계: 추출된 데이터 내보내기
OnHTML() 명령어 실행 후 industries에는 Go 객체 형태로 스크래핑된 데이터가 포함됩니다. 웹에서 추출한 데이터를 더 쉽게 활용하려면 다른 형식으로 변환해야 합니다. 스크래핑된 데이터를 CSV 및 JSON으로 내보내는 방법을 살펴보겠습니다.
참고: Go 표준 라이브러리는 고급 데이터 내보내기 기능을 제공합니다. 데이터를 CSV 및 JSON으로 변환하기 위해 외부 패키지가 필요하지 않습니다. Go 스크립트에 다음 임포트가 포함되어 있는지 확인하기만 하면 됩니다:
- CSV 내보내기:
import (
"encoding/csv"
"log"
"os"
)
- JSON 내보내기의 경우:
import (
"encoding/json"
"log"
"os"
)다음과 같이 Go에서 industries 슬라이스를 industries.csv 파일로 내보낼 수 있습니다:
// 출력 CSV 파일 열기
file, err := os.Create("industries.csv")
// 파일 생성 실패 시
if err != nil {
log.Fatalln("출력 CSV 파일 생성 실패", err)
}
// 실행 종료 전 파일 처리용 할당된 리소스 해제
defer file.Close()
// CSV 파일 라이터 생성
writer := csv.NewWriter(file)
// 실행 종료 전에 파일 라이터와 연관된 리소스 해제
defer writer.Flush()
// CSV에 헤더 행 추가
headers := []string{
"url",
"image",
"name",
}
writer.Write(headers)
// 각 Industry 제품을 출력 CSV 파일에 저장
for _, industry := range industries {
// Industry 인스턴스를 문자열 슬라이스로 변환
record := []string{
industry.Url,
industry.Image,
industry.Name,
}
// 새 CSV 레코드 추가
writer.Write(record)
}위의 코드 조각은 CSV 파일을 생성하고 헤더 행으로 초기화합니다. 그런 다음 Industry 객체 슬라이스를 반복하며 각 요소를 문자열 슬라이스로 변환하고 출력 파일에 추가합니다. Go CSV Writer는 문자열 목록을 자동으로 CSV 형식의 새 레코드로 변환합니다.
스크립트 실행 방법:
go run scraper.go실행 후 Go 프로젝트 루트 폴더에 industries.csv 파일이 생성된 것을 확인할 수 있습니다. 파일을 열면 다음과 같은 데이터가 표시됩니다:
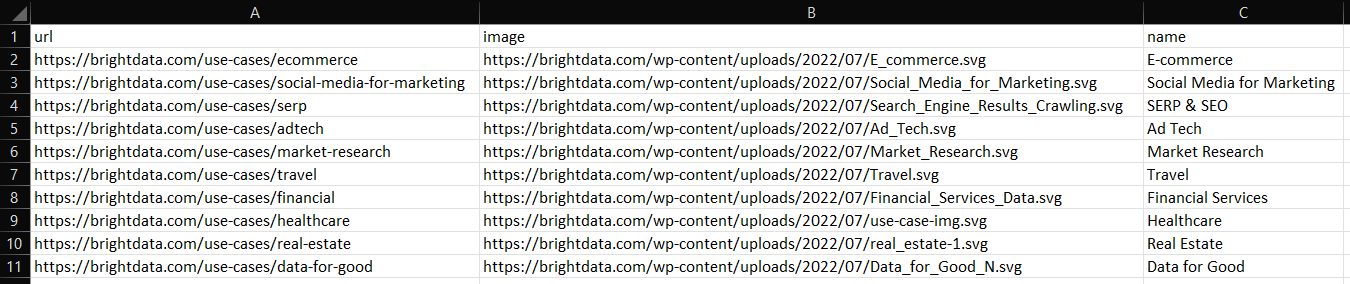
마찬가지로 아래와 같이 industries를 industry.json으로 내보낼 수 있습니다:
file, err := os.Create("industries.json")
if err != nil {
log.Fatalln("출력 JSON 파일 생성 실패", err)
}
defer file.Close()
// industries를 들여쓰기된 JSON 문자열로 변환
jsonString, _ := json.MarshalIndent(industries, " ", " ")
// JSON 문자열을 파일에 기록
file.Write(jsonString)
이렇게 하면 아래와 같은 JSON 파일이 생성됩니다:
[
{
"Url": "https://brightdata.com/use-cases/ecommerce",
"Image": "https://media.brightdata.com/2022/07/E_commerce.svg",
"Name": "E-commerce"
},
// ...
{
"Url": "https://brightdata.com/use-cases/real-estate",
"Image": "https://media.brightdata.com/2022/07/real_estate-1.svg",
"Name": "Real Estate"
},
{
"Url": "https://brightdata.com/use-cases/data-for-good",
"Image": "https://media.brightdata.com/2022/07/Data_for_Good_N.svg",
"Name": "Data for Good"
}
]자, 이제 수집한 데이터를 더 유용한 형식으로 변환하는 방법을 알게 되셨군요!
8단계: 모든 것을 통합하기
다음은 Golang 스크레이퍼의 전체 코드입니다:
// scraper.go
package main
import (
"encoding/csv"
"encoding/json"
"log"
"os"
// Colly 임포트
"github.com/gocolly/colly"
)
// 스크랩된 데이터를 저장할
// 데이터 구조체 정의
type Industry struct {
Url, Image, Name string
}
func main() {
// 구조체 슬라이스 초기화
var industries []Industry
// Collector 초기화
c := colly.NewCollector()
// 유효한 User-Agent 헤더 설정
c.UserAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36"
// 산업 카드 목록 반복
// HTML 요소
c.OnHTML(".elementor-element-6b05593c .section_cases__item", func(e *colly.HTMLElement) {
url := e.Attr("href")
image := e.ChildAttr(".elementor-image-box-img img", "data-lazy-src")
name := e.ChildText(".elementor-image-box-content .elementor-image-box-title")
// 원하지 않는 데이터 필터링
if url != "" && image != "" && name != "" {
// 새로운 Industry 인스턴스 초기화
industry := Industry{
Url: url,
Image: image,
Name: name,
}
// 스크랩된 산업 목록에 인스턴스 추가
industries = append(industries, industry)
}
})
// 대상 사이트 접속
c.Visit("https://brightdata.com/")
// --- CSV로 내보내기 ---
// 출력 CSV 파일 열기
csvFile, csvErr := os.Create("industries.csv")
// 파일 생성 실패 시
if csvErr != nil {
log.Fatalln("출력 CSV 파일 생성 실패", csvErr)
}
// 실행 종료 전에 파일 처리에 할당된 리소스 해제
defer csvFile.Close()
// CSV 파일 라이터 생성
writer := csv.NewWriter(csvFile)
// 실행 종료 전에 파일 라이터 관련 리소스 해제
defer writer.Flush()
// CSV에 헤더 행 추가
headers := []string{
"url",
"image",
"name",
}
writer.Write(headers)
// 각 산업별 제품을 출력 CSV 파일에 저장
for _, industry := range industries {
// Industry 인스턴스를 문자열 슬라이스로 변환
record := []string{
industry.Url,
industry.Image,
industry.Name,
}
// 새 CSV 레코드 추가
writer.Write(record)
}
// --- JSON으로 내보내기 ---
// 출력 JSON 파일 열기
jsonFile, jsonErr := os.Create("industries.json")
if jsonErr != nil {
log.Fatalln("출력 JSON 파일 생성 실패", jsonErr)
}
defer jsonFile.Close()
// industries를 들여쓰기된 JSON 문자열로 변환
jsonString, _ := json.MarshalIndent(industries, " ", " ")
// JSON 문자열을 파일에 기록
jsonFile.Write(jsonString)
}100줄 미만의 코드로 Go에서 데이터 스크레이퍼를 구축할 수 있습니다!
결론
이 튜토리얼에서는 Go가 웹 스크래핑에 적합한 언어인 이유를 살펴보았습니다. 또한 최고의 Go 스크래핑 라이브러리가 무엇이며 어떤 기능을 제공하는지 알아보았습니다. 그런 다음 Colly와 Go의 표준 라이브러리를 사용하여 웹 스크래핑 애플리케이션을 만드는 방법을 배웠습니다. 여기서 구축한 Go 스크래퍼는 실제 대상에서 데이터를 추출할 수 있습니다. 보셨듯이 Go를 사용한 웹 스크래핑은 몇 줄의 코드만으로 가능합니다.
동시에, 인터넷에서 데이터를 추출할 때 고려해야 할 많은 도전 과제가 있다는 점을 명심하세요. 이 때문에 많은 웹사이트가 Go 스크래핑 스크립트를 탐지하고 차단할 수 있는 안티 스크래핑 및 안티 봇 솔루션을 채택합니다. Bright Data는 다양한 솔루션을 제공합니다. 사용 사례에 맞는 완벽한 솔루션을 찾으려면 저희에게 문의하세요.
웹 스크래핑 자체는 다루고 싶지 않지만 웹 데이터에는 관심이 있으신가요? 바로 사용 가능한 데이터셋을 살펴보세요.




