

웹 스크래핑은 특수 도구나 프로그램을 사용하여 웹사이트에서 데이터를 자동으로 추출하고 수집하는 기술입니다. 데이터 기반 의사 결정 프로세스를 개선하려는 기업에게 특히 유용합니다.
그러나 대부분의 웹사이트에서 발견되는 복잡한 HTML 구조, 동적 콘텐츠, 다양한 데이터 형식 때문에 웹 스크래핑의 효과는 사용하는 도구에 따라 달라집니다.
Scrapy와 Selenium은 웹 스크래핑을 용이하게 하기 위해 설계된 강력한 도구입니다. Scrapy는 정적 웹사이트에서 데이터를 추출하는 반면, Selenium은 웹 브라우저 자동화를 수행하고 동적 웹사이트에서 데이터를 추출할 수 있습니다.
이 글에서는 두 도구를 사용 편의성, 성능 및 확장성, 다양한 유형의 웹 콘텐츠에 대한 적합성, 통합 기능 등을 기준으로 비교해 보겠습니다.
사용 편의성
Scrapy는 Linux, Windows, macOS 및 Berkeley Software Distribution(BSD)에서 실행 가능한 Python 기반 웹 스크래핑 도구입니다. Scrapy는 사용하기 쉬울 뿐만 아니라 웹 스크래핑 작업을 위한 고급 API를 제공하여 웹 스크래핑 프로세스를 더욱 단순화할 수 있습니다.
Scrapy를 설정하려면 설치하고 Python 코드를 사용하여 몇 가지 스파이더를 구성하기만 하면 됩니다(여기에는 웹 스크래핑 개념에 대한 어느 정도의 이해가 필요합니다). 프로젝트를 시작하기 위해 Scrapy 명령어를 실행하면 해당 프로젝트 전용 폴더가 생성됩니다. 이 폴더 내에는items.py,pipelines.py,settings.py와 같은 기본 Python 파일이 포함되어 있습니다. 이러한 파일들은 간소화된 구조로 구성되어 있어 웹 스크래핑을 쉽게 시작할 수 있습니다.
Scrapy는 심층적인 문서와 함께 선별된 문서 및 동영상을 제공하여 여러분의 질문에 답할 수 있도록 돕습니다. 또한 활발한 서브레딧과 디스코드 커뮤니티를 운영하여 다양한 토론이나 주제에 참여할 수 있습니다.
반면 Selenium은 Java, JavaScript, Python, C# 등 다양한 프로그래밍 언어를 지원하며, Windows, macOS, Linux 등 Scrapy와 동일한 운영체제와 호환됩니다. Scrapy에 비해 Selenium은 학습이 쉽지 않으며 숙달되기까지 더 많은 시간, 노력, 때로는 자원이 필요합니다.
Selenium을 설정하려면 Selenium 라이브러리를 설치한 후 브라우저 자동화를 처리하는 WebDrivers를 구성해야 합니다. 로그인이 필요한 동적 웹사이트에서 데이터를 스크래핑하는 경우, 데이터 스크래핑을 시작하기 전에 로그인 프로세스를 처리할 웹 자동화를 설정해야 합니다.
Selenium은 웹 페이지에서 요소를 쉽게 찾을 수 있도록 사용자 정의 가능한 풍부한 탐색 방법을 제공합니다. 또한 클릭, 더블 클릭, 드래그, 드롭, 스크롤 등 상호작용 동작 체인을 제공하여 웹 페이지와의 손쉬운 상호작용을 가능하게 합니다.
Selenium 공식 문서에는 웹 자동화와 웹 스크래핑 모두와 관련된 인상적인 가이드라인, 단계별 지침 및 튜토리얼이 포함되어 있습니다.
셀레늄은 웹 자동화를 위한 보다 범용적인 도구이기 때문에 더 크고 다양한 커뮤니티를 보유하고 있습니다. 셀레늄 작업 중 질문이 있을 경우 공식 사용자 그룹과 서브레딧 커뮤니티에서 도움을 받을 수 있습니다. 즉각적인 답변이 필요한 문제가 있다면 IRC 채팅방을 활용할 수도 있습니다.
성능과 확장성
웹 스크래핑 도구의 효과성은 대량의 데이터를 신속하게 수집하는 것이 목표이므로 속도에 크게 좌우됩니다.
Scrapy는 정적 웹 페이지의 콘텐츠 스크래핑에 탁월하여 Selenium보다 빠른 데이터 추출이 가능합니다. 이는 Selenium이 버튼 클릭이나 양식 작성과 같은 다양한 상호작용을 실행하기 위해 브라우저 인스턴스에 의존하기 때문입니다.
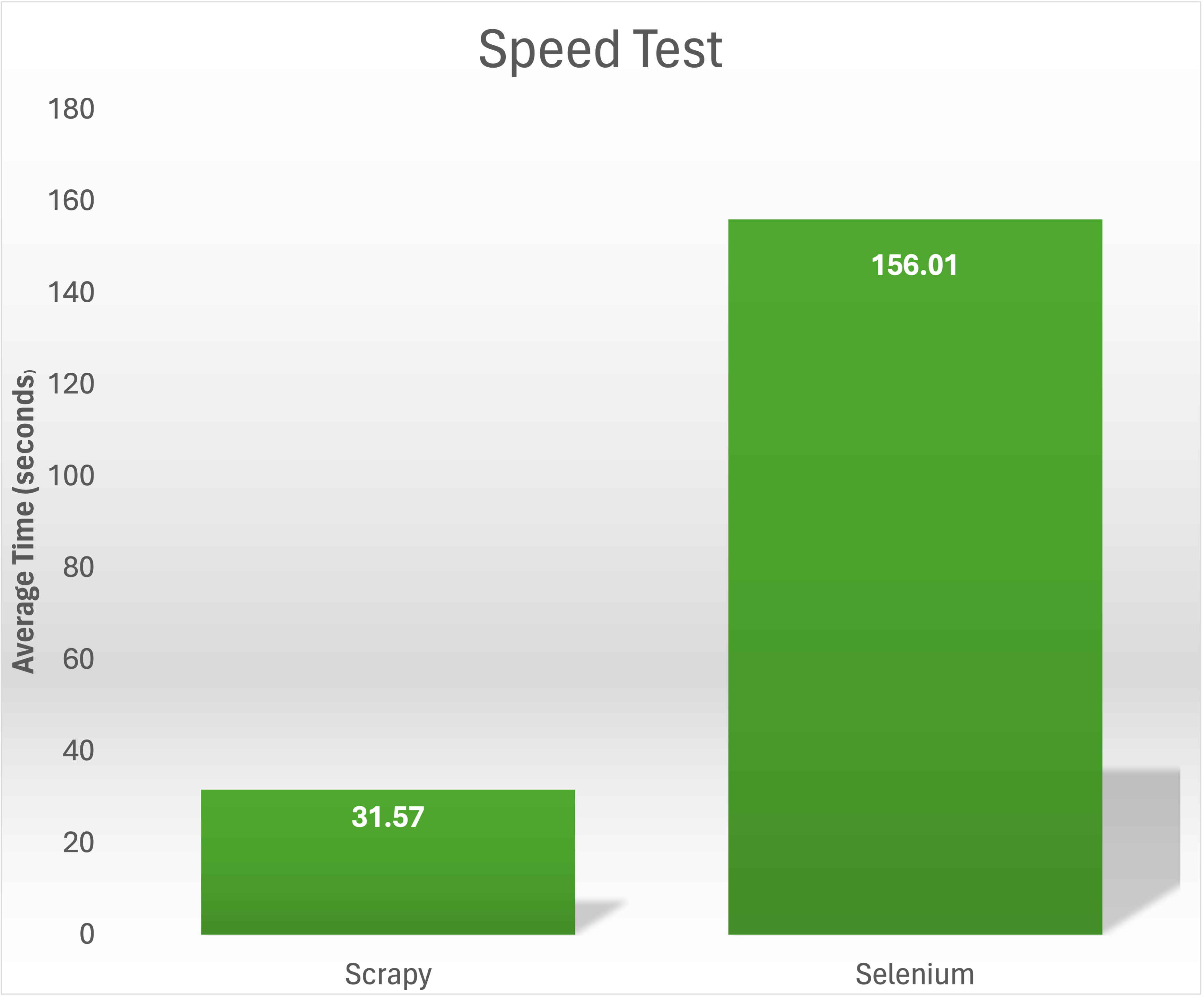
https://books.toscrape.com/에서 1,000권의 책 제목과 가격을 수집하는 속도 테스트에서 Scrapy는 31.57초 만에 작업을 완료했습니다. 반면 Selenium은 동일한 콘텐츠를 스크래핑하는 데 평균 156.01초가 소요되었습니다:
Scrapy 아키텍처는 응답과 항목을 연속적인 프로세스로 처리함으로써 메모리를 효율적으로 관리합니다. 이는 웹 페이지 전체를 한 번에 메모리에 로드할 필요가 없도록 합니다. 또한 Scrapy는 캐싱과 증분 스크래핑을 기본 지원하여 중복 요청을 최소화하고 새로 추가되거나 업데이트된 콘텐츠만 처리함으로써 확장성을 향상시킵니다.
또한 Scrapy는 동시 요청 수, 깊이 제한, 항목 파이프라인과 같은 설정을 통해 메모리 사용량을 미세 조정할 수 있는 옵션을 제공합니다. 이러한 기능을 통해 웹 스크래핑 프로젝트의 특정 요구 사항에 따라 메모리 소비를 최적화할 수 있습니다.
셀레늄은 일반적으로 자바스크립트 중심 웹사이트와 상호작용할 때 상당한 양의 메모리를 소비하여 메모리 사용량이 증가합니다. 이는 특히 대규모 스크래핑 프로젝트에서 확장성과 성능에 부정적인 영향을 미칠 수 있습니다.
Scrapy의 내장 미들웨어인 HTTPCacheMiddleware는 스파이더가 수행한 요청과 관련 응답을 캐싱합니다. 프로젝트의settings.py파일에 다음 코드를 추가하여 캐싱을 활성화할 수 있습니다:
# HTTP 캐싱 활성화 및 구성 (기본값: 비활성화)
HTTPCACHE_ENABLED = True
대규모 데이터 스크래핑을 처리하기 위해 Selenium을 확장하려면 분산 시스템에 여러 인스턴스를 배포해야 하며, 이는 RAM 및 CPU와 같은 리소스 수요 증가로 이어집니다.
다양한 유형의 웹 콘텐츠에 대한 적합성
인터넷상의 대부분의 웹사이트는 동적 또는 정적 웹 페이지를 특징으로 합니다. Scrapy와 Selenium이 두 유형의 웹 페이지를 어떻게 처리하는지 살펴보겠습니다.
동적 웹 페이지
대부분의 동적 웹 페이지는 Angular나 React 같은 JavaScript 프레임워크를 통해 페이지 전체를 재로딩하지 않고도 콘텐츠를 업데이트합니다.
Selenium은 다양한 웹사이트의 동적 콘텐츠를 스크래핑할 수 있지만, Scrapy는 기본적으로 JavaScript로 생성된 동적 콘텐츠 스크래핑을 지원하지 않습니다. 이 기능을 얻으려면 Scrapy를 Selenium이나 Splash와 같은 도구와 통합할 수 있습니다.
정적 웹 페이지
정적 웹 페이지는 동적 페이지에 비해 상호작용이 제한적이며, 일반적으로 사용자가 콘텐츠를 보거나 링크를 클릭하는 것만 허용합니다.
앞서 언급한 바와 같이 Selenium은 정적 페이지를 스크래핑할 수 있지만, 이 작업에 가장 효율적인 도구는 아닙니다. 반면 Scrapy는 정적 데이터 스크래핑에 탁월하여 원하는 정보를 수집하는 데 원활하고 효율적인 경험을 제공합니다.
통합 기능
Scrapy는 스크랩된 데이터를 저장하기 위해 MySQL, PostgreSQL, MongoDB와 같은 데이터베이스를 포함한 대부분의 Python 도구와 쉽게 통합할 수 있습니다. SQLAlchemy와 같은 객체 관계형 매퍼(ORM)를 사용하여 관계형 데이터베이스에 데이터를 저장하는 과정을 단순화할 수도 있습니다. 데이터를 더 처리하고 분석하려면 Python용 인기 있는 데이터 조작 및 분석 라이브러리인 pandas를 사용할 수 있습니다.
Scrapy는 Django나 Flask 같은 웹 프레임워크와도 통합되어 웹 스크래핑 기능을 포함하는 웹 애플리케이션을 구축할 수 있습니다. 또한 FastAPI와의 통합을 통해 비동기 지원을 갖춘 고성능 웹 API를 구축할 수 있어 스크래핑 요청을 효율적으로 처리하는 데 적합합니다.
반면 Selenium은 Selenium WebDriver API와 브라우저 사이의 중개자 역할을 하는 브라우저 드라이버를 제공합니다. 원하는 웹 브라우저와 통합하기 위해 WebDriver를 다운로드하여 설치할 수 있습니다. Selenium은 현재 Chrome, Edge, Firefox, Safari용 브라우저 드라이버를 제공합니다.
Selenium은 웹 애플리케이션 기능의 자동 테스트에도 활용될 수 있으나, 내장 테스트 프레임워크가 없다는 점을 유의해야 합니다. CodeceptJS, Helium, Selenide 등 다른 인기 테스트 프레임워크와 Selenium을 통합할 수 있습니다.
이전에는 Selenium이 Jenkins, Travis CI와 같은 CI 도구와 통합되어 자동화 스크립트가 지속적 통합/지속적 배포(CI/CD) 파이프라인의 일환으로 자동 실행되도록 했습니다. 그러나 현재는 지속적 테스트 및 배포 프로세스를 지원하는 GitHub Actions로 모든 작업을 실행합니다.
Scrapy는 Bright Data와 같은 다양한 프록시 서비스 제공업체와 통합될 수 있으며, 프록시 IP와 포트를 요청 매개변수로 전달하는 방식으로 작동합니다. 특정 프록시를 프로젝트에 사용하려는 경우 이 방법을 권장합니다.
예를 들어 프록시 서버를 통합하려면 다음과 같이pip 명령어를사용하여Scrapy를 설치할수 있습니다:
# scrapy 모듈 임포트
import scrapy
class BookSpider(scrapy.Spider):
name = "books"
def start_requests(self):
start_urls = ["https://example.com/products"]
for url in start_urls:
yield scrapy.Request(
url=url,
callback=self.parse,
# 프록시 연결
meta={"proxy": "http://USERNAME:[email protected]:22225"},
)
def parse(self, response):
for book in response.css(".book-card"):
yield {
"title": book.css(".title ::text").get(),
"price": book.css(".price-wrapper ::text").get(),
}
여기서는 Scrapy를 임포트하고 Scrapy의 spider 클래스에서상속받은 BookSpider라는클래스를 정의하여 웹사이트에서 도서 목록을 스크래핑합니다.start_requests()메서드는 지정된 URL과 프록시를 사용하여 요청을 시작하고,parse()메서드는 CSS 선택자를 사용하여 도서 제목과 가격을 추출합니다.
반면 Selenium은 ChromeDriver나 geckodriver 같은 다양한 브라우저 드라이버를 통해 간편한 프록시 통합을 지원합니다. HTTP 요청을 프록시 서버를 통해 전달하도록 Selenium WebDriver를 설정하기만 하면 됩니다.
예를 들어, Bright Data에서 제공하는 프록시 IP와 포트를 지정하여 Selenium을 프록시와 통합할 수 있습니다. 다음과 같습니다:
# selenium 모듈 임포트
from selenium import webdriver
from selenium.webdriver.common.proxy import Proxy, ProxyType
# 프록시 설정
proxy_address = "http://USERNAME:[email protected]"
proxy_port = "22225"
# Bright Data 프록시 자격 증명 통합 Selenium 옵션
options = webdriver.ChromeOptions()
options.add_argument('--proxy-server=%s:%s' % (proxy_address, proxy_port))
# Selenium 웹드라이버 인스턴스화
driver = webdriver.Chrome(options=options)
# 사용 예시: 웹페이지 스크래핑
url = "https://example.com"
driver.get(url)
print(driver.page_source)
# 드라이버 종료
driver.quit()
여기서는 필요한 Selenium 모듈을 임포트하고 프록시 설정을 구성합니다. 그런 다음 정의된 프록시 서버를 사용하도록 Chrome을 구성하고, WebDriver를 인스턴스화하며, 웹 페이지("https://example.com")를 스크래핑하고, 페이지 소스를 출력한 후 WebDriver를 닫아 프로세스를 종료합니다.
결론
이 글에서는 두 가지 인기 웹 스크래핑 도구인 Scrapy와 Selenium을 비교했습니다.
Scrapy는 사용하기 쉬운 Python 기반 스크래핑 도구로, 정적 웹사이트의 데이터 추출에 이상적입니다. 반면 Selenium은 여러 프로그래밍 언어를 사용한 자동화 및 스크래핑 기능을 제공하며 다양한 웹 브라우저를 지원합니다. 동적 콘텐츠나 JavaScript로 렌더링된 콘텐츠를 스크래핑할 때는 Selenium이 더 나은 선택입니다.
어떤 도구를 선택하든 Bright Data와 같은 데이터 플랫폼을 함께 사용하는 것이 좋습니다. 이는 웹 스크래핑 스크립트에 지리적 제한, 차단 회피 및 CAPTCHA 해결 기능을 추가하는 데 도움이 됩니다. 또한 Bright Data API 및 SDK를 활용하여 더 광범위한 스크래핑 요구 사항을 해결함으로써 웹 스크래핑 프로젝트의 효율성, 속도, 정확성 및 확장성을 보장할 수 있습니다. 데이터 수집을 한 단계 더 발전시키고 싶으신가요? 맞춤형 데이터셋을 구매하세요 (무료 샘플 제공).




