

Crawl4AI와 Firecrawl은 데이터 수집 업계에서 가장 주목받는 두 가지 AI 제품입니다. 본 가이드에서는 두 제품의 기본 사용법과 통계를 살펴보겠습니다.
이 글을 다 읽으시면 다음 질문들에 답할 수 있게 될 것입니다.
- Crawl4AI란 무엇인가요?
- Firecrawl이란 무엇인가요?
- 각각의 강점은 무엇인가요?
- 어디에서 부족한 점이 있나요?
- Bright Data가 두 도구 모두에 대한 훌륭한 대안인 이유는 무엇인가요?
이러한 새로운 도구들을 비교해 보면 Bright Data의 포괄적이고 확장 가능한 솔루션이 더욱 두드러지게 보입니다. 일반적인 스크래핑 기능이 필요하든, 본격적인 데이터 수집 제품군이 필요하든, Bright Data는 검증된 기술을 제공합니다.
개요 및 목적
구체적인 내용으로 들어가기 전에, 각 제품이 무엇이며 누구를 대상으로 하는지 자세히 살펴보겠습니다. 서로 다른 목적을 위해 만들어졌기 때문에, 이는 단순한 비교가 아닙니다. 오히려 “도구 상자와 스위스 군용 칼”을 비교하는 것에 가깝습니다.
Crawl4AI

Crawl4AI는 AI 기반 웹 스크래핑을 더 쉽고 접근성 있게 만드는 오픈 소스 Python 라이브러리입니다. 추출 파이프라인 확장에 주력하는 개발자를 대상으로 합니다. 완전히 오픈 소스이며, 코드는 GitHub 페이지에서 자유롭게 이용 가능합니다. Crawl4AI는 Bright Data의 기존 스크래핑 도구와 더 유사합니다.
Firecrawl
Firecrawl은 AI 기반 웹 스크래핑 분야의 기업용 선도 솔루션 중 하나입니다. 언어에 구애받지 않는 프레임워크와 다양한 통합 옵션을 제공합니다. Firecrawl은 전통적으로 데이터 수집이나 개발 분야에 종사하지 않는 사람들에게 가장 큰 관심을 끌고 있습니다. Firecrawl을 통해 코딩 기술이 항상 필요하지 않은 사람들도 스크래핑을 쉽게 접근할 수 있게 됩니다.
독보적인 기능
Crawl4AI
Crawl4AI는 완전한 오픈 소스이며 관대한 라이선스를 사용한다는 점에서 두드러집니다. 개발자에게 매우 매력적인 옵션으로 만드는 기능을 살펴보세요. 이 도구는 구성 가능한 옵션과 코드의 투명성을 통한 신뢰를 제공합니다.
- 오픈 소스: 누구나 코드를 확인할 수 있습니다. 버그는 커뮤니티에 의해 신속하게 발견되고 수정됩니다. 투명한 코드베이스는 코드를 읽을 줄 안다면 예상치 못한 문제가 발생하지 않음을 의미합니다.
- LLM 기반 및 LLM 프리 추출: Crawl4AI를 사용하면 추출을 위해 소형 로컬 모델을 선택하거나 Deepseek과 같은 외부 모델에 연결할 수 있습니다.
- 관대한 라이선스: Crawl4AI의 라이선스는 매우 유연하고 관대합니다. 이는 취미 개발자와 기업 개발자 모두의 관심을 끌고 있습니다.
- Python 라이브러리: Crawl4AI는 구독 서비스가 아닙니다. Python 라이브러리입니다. 다른 시스템에 통합할 수 있으며, 원한다면 Crawl4AI를 백엔드로 활용해 자체 스크래퍼를 구축할 수도 있습니다.
Firecrawl
Firecrawl은 웹 스크래핑 분야에서 가장 인기 있는 기업용 도구 중 하나입니다. 언어에 구애받지 않는 프레임워크를 제공하여 Python, JavaScript 또는 GUI 웹사이트를 통해 추출 작업을 수행할 수 있습니다. 취미 개발자와 기업 고객 모두를 위한 다양한 플랜을 제공합니다.
- 기업용: Firecrawl은 기업용 제품입니다. 오픈소스 옵션도 제공하지만, 주요 제품 라인은 확장 가능한 데이터 수집이 필요한 사용자를 대상으로 합니다.
- 언어 독립적: Firecrawl은 웹앱을 통한 GUI 지원을 제공합니다. 또한 Python과 JavaScript용 SDK 지원도 제공합니다. Go와 Rust용 커뮤니티 주도 SDK도 존재합니다. Firecrawl을 사용하면 Python에 국한되지 않습니다. 심지어 프로그래밍 환경에도 제한받지 않습니다.
- 자연어 처리(NLP): Firecrawl은 자연어를 통한 개발 및 데이터 수집에 중점을 둡니다. 사용자가 모델에 수행할 작업을 지시하면, 모델이 수집 작업을 수행합니다.
사용 편의성
Crawl4AI
Crawl4AI 시작은 비교적 간단합니다. pip를 통해 설치하고 Python 환경에서 호출할 수 있습니다. 아래 코드 조각은 설치 방법과 설치 확인 방법을 보여줍니다.
아래 명령어로 Crawl4AI를 설치하세요.
pip install crawl4ai브라우저 및 도구 설치를 위해 설정을 실행하세요.
crawl4ai-setup설치 상태를 확인하고 문제를 파악하려면 doctor 명령어를 사용하세요.
crawl4ai-doctor아래 코드는 매우 간단합니다. Crawl4AI 문서에서 직접 가져온 것입니다. 이 코드를 Python 파일에 붙여넣고 python 파일명.py로 실행하세요. 실제로 Crawl4AI는 셸 명령어로 실행하는 것이 더 원활합니다. VSCode나 다른 IDE에서 직접 실행하면 asyncio 관련 문제가 발생할 수 있습니다.
import asyncio
from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig
async def main():
async with AsyncWebCrawler() as crawler:
result = await crawler.arun(
url="https://www.example.com",
)
print(result.markdown[:300]) # 추출된 텍스트의 첫 300자 표시
if __name__ == "__main__":
asyncio.run(main())Firecrawl
Firecrawl을 시작하려면 플레이 그라운드로 이동하여 대상 URL을 입력하기만 하면 됩니다. 이 인터페이스는 비개발자에게 매우 친숙합니다.
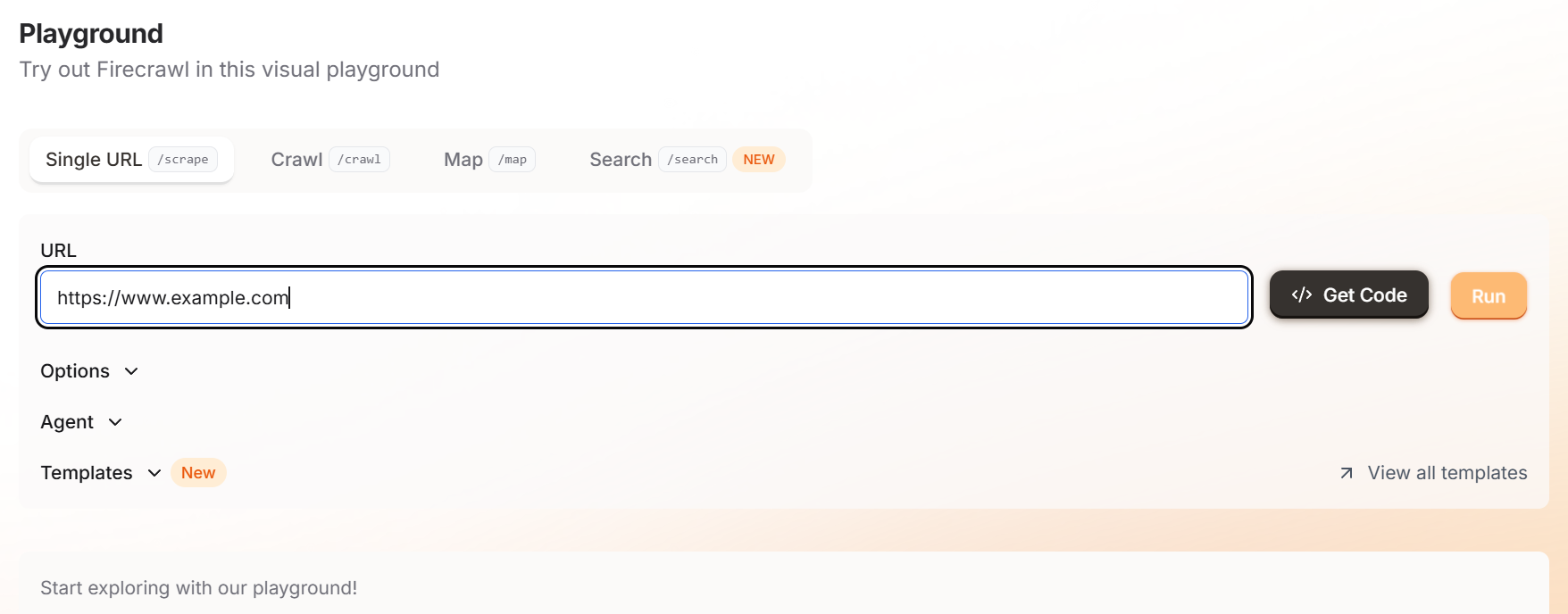
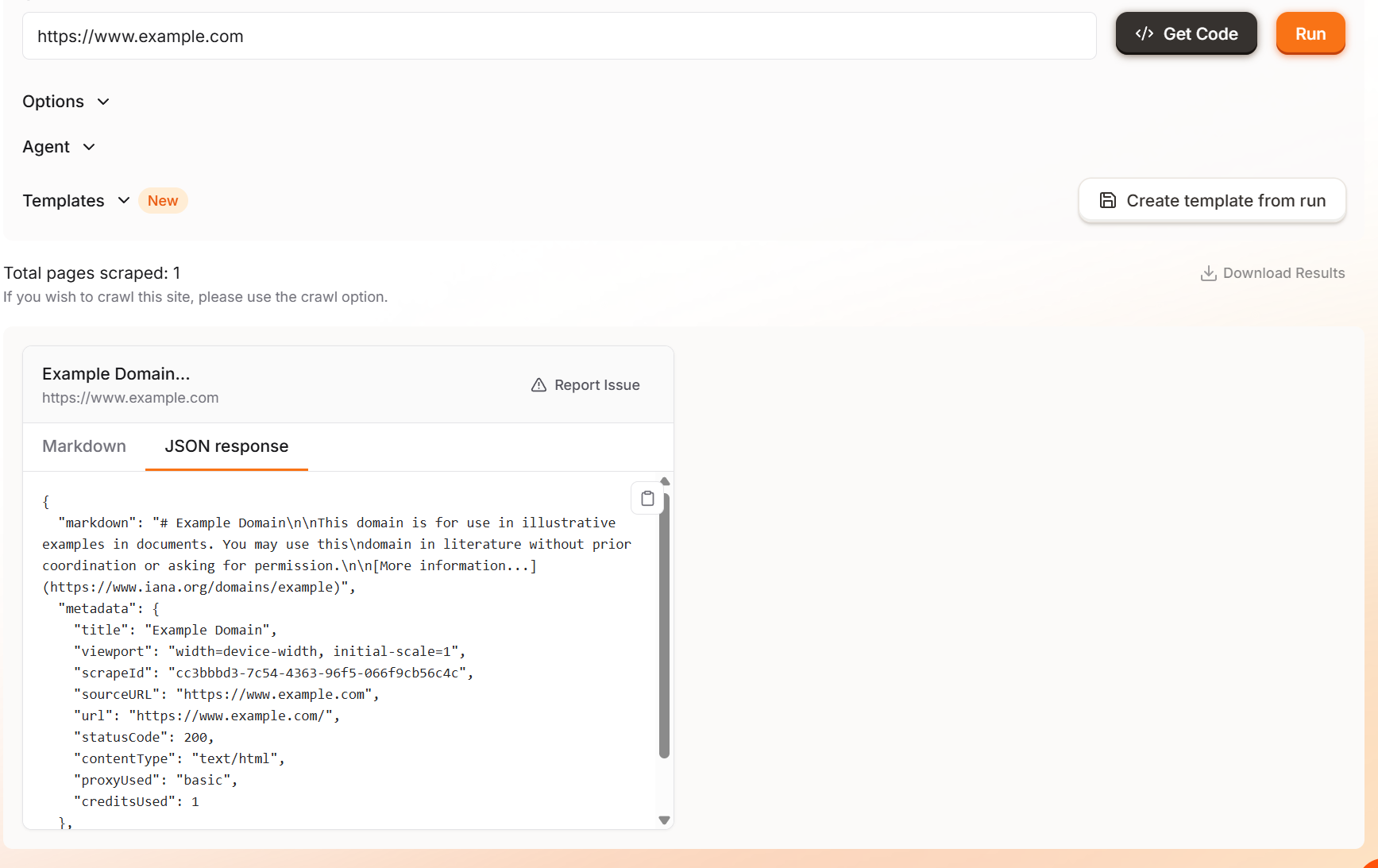
“실행” 버튼을 클릭하면 마크다운 또는 JSON 형식으로 선택한 예제 출력을 확인할 수 있습니다.
성능 및 확장성
Crawl4AI
아래 스니펫은 앞서 보신 예제 코드에서 가져온 것입니다. 전체적으로 예제 도메인을 스크래핑하는 데 2초 미만이 소요되었습니다. LLM 없이도 Crawl4AI는 매우 빠릅니다. 성능 면에서 Requests와 BeautifulSoup을 사용한 수동 스크래핑과 견줄 만합니다.

그러나 마크다운 스크래핑과 원시 HTML은 최대한 깔끔한 수준입니다. Crawl4AI는 LLM 없이 JSON 추출을 지원한다고 명시하지만 지원 범위가 제한적이고 버그가 있습니다. 완전한 데이터 구조를 추출하려면 코드에 LLM 지원을 추가해야 합니다. 이것이 Crawl4AI의 숨겨진 비용으로, 실제 파싱 작업을 완료하려면 외부 LLM을 호스팅하거나 비용을 지불해야 합니다.
아래 코드에서는 OpenAI 모델을 사용해 Books to Scrape 페이지를 파싱합니다. 직접 실행할 경우 API 키를 본인 것으로 교체해야 합니다.
import asyncio
import json
from pydantic import BaseModel
from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig, CacheMode, LLMConfig
from crawl4ai.extraction_strategy import LLMExtractionStrategy
openai_api_key = "your-openai-api-key"
class Product(BaseModel):
name: str
price: str
async def main():
# LLM에 스크래핑할 내용과 설정을 전달
llm_strategy = LLMExtractionStrategy(
llm_config = LLMConfig(provider="openai/gpt-4o-mini", api_token=openai_api_key),
schema=Product.model_json_schema(),
extraction_type="schema",
instruction="콘텐츠에서 'name'과 'price'를 가진 모든 제품 객체를 추출하세요.",
chunk_token_threshold=1000,
overlap_rate=0.0,
apply_chunking=True,
input_format="markdown",
extra_args={"temperature": 0.0, "max_tokens": 800}
)
# 크롤러 구성 생성
crawl_config = CrawlerRunConfig(
extraction_strategy=llm_strategy,
cache_mode=CacheMode.BYPASS
)
# 필요한 경우 브라우저 구성 생성
browser_cfg = BrowserConfig(headless=True)
async with AsyncWebCrawler(config=browser_cfg) as crawler:
# 단일 페이지 크롤링
result = await crawler.arun(
url="https://books.toscrape.com",
config=crawl_config
)
if result.success:
# 추출된 콘텐츠가 json이라고 가정
data = json.loads(result.extracted_content)
print("추출된 항목:", data)
#사용량 통계 표시
llm_strategy.show_usage()
else:
print("오류:", result.error_message)
if __name__ == "__main__":
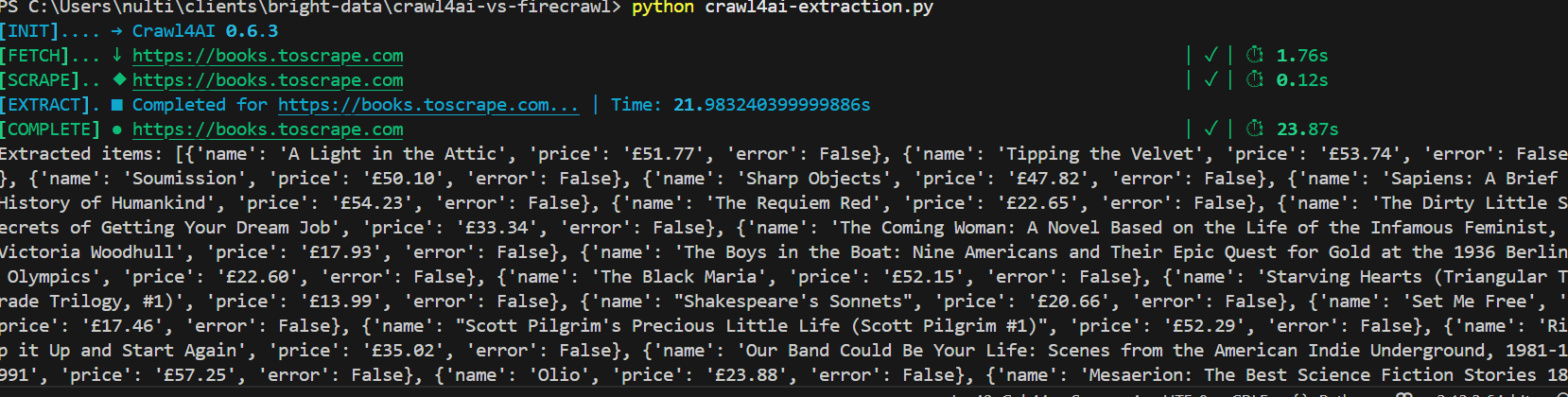
asyncio.run(main())다음은 출력 결과입니다. 총 소요 시간은 25초 미만이었습니다. 각 도서가 가격과 함께 깔끔하게 구조화된 JSON 객체로 나열된 것도 확인할 수 있습니다.
Firecrawl
Firecrawl은 URL을 입력하기만 하면 해당 페이지를 스크래핑합니다. 기본 버전으로 사용할 경우, 페이지를 JSON 객체에 원시 마크다운 형식으로 출력합니다.
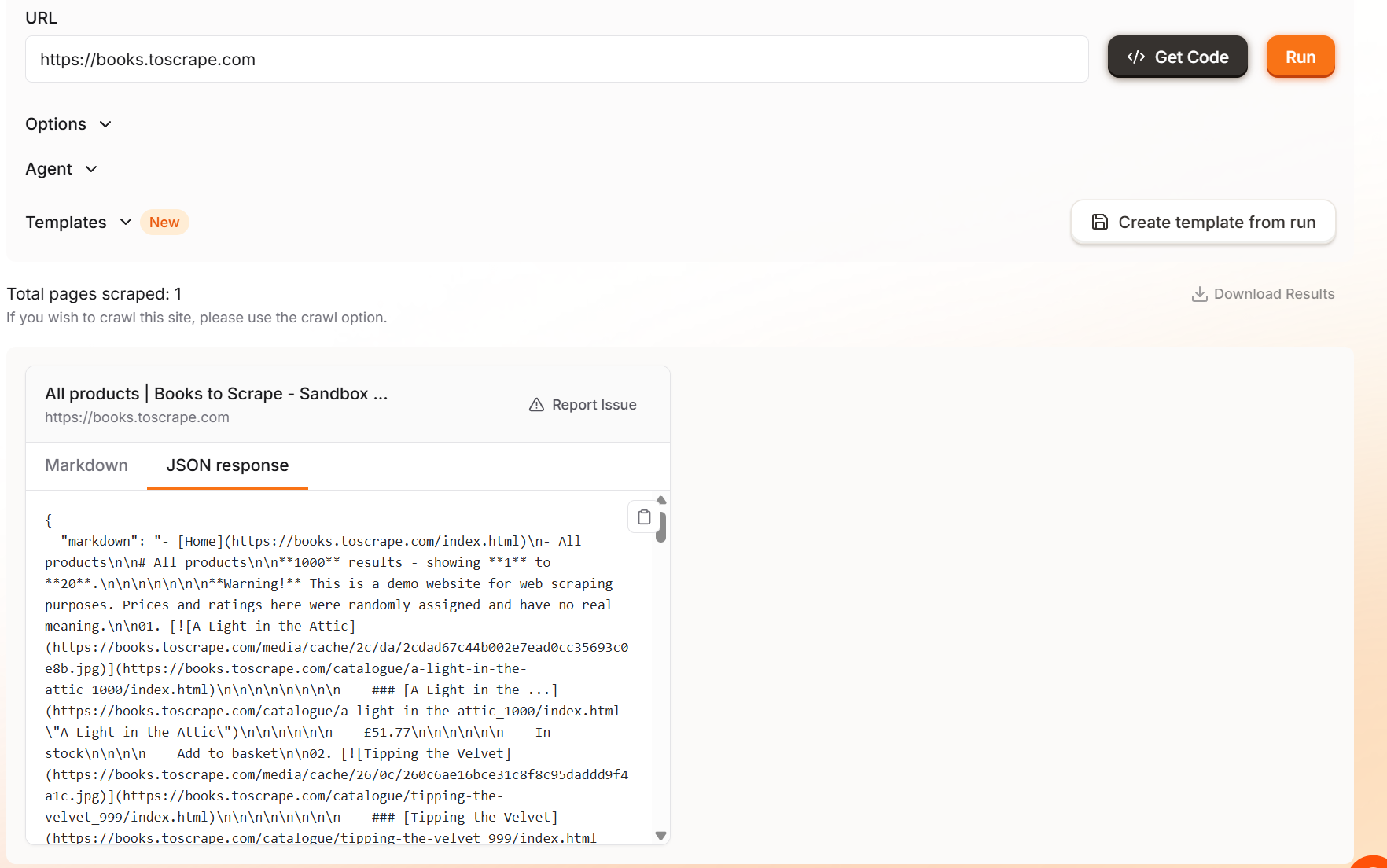
Firecrawl은 코드 실행 시 멋진 기능을 제공합니다. 스크레이퍼가 실행되는 동안 브라우저가 페이지를 렌더링하는 과정을 실시간으로 확인할 수 있습니다.
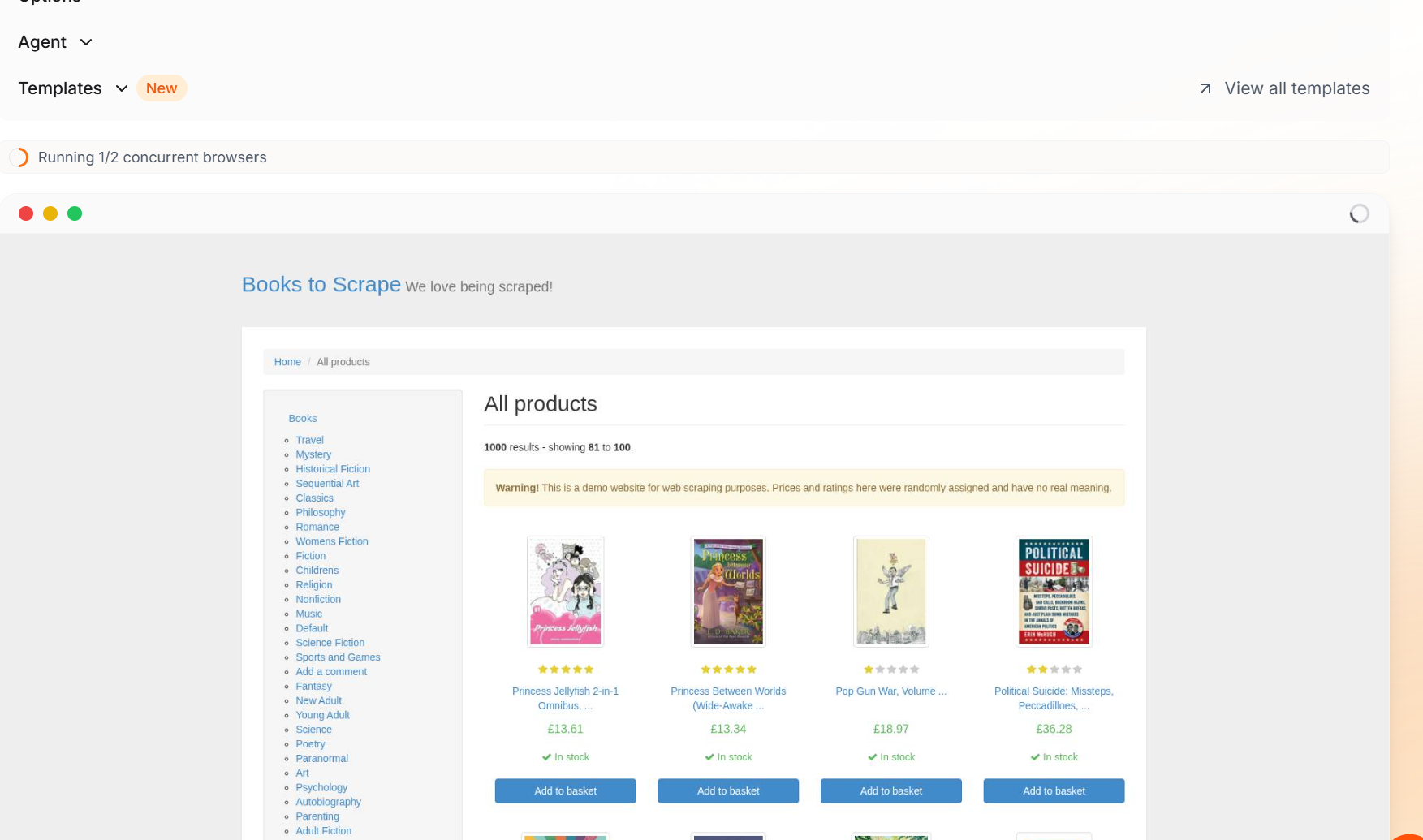
데이터 품질 및 정확도
Crawl4AI
GPT-4o에 연결했을 때 Crawl4AI는 100% 정확도로 작동했습니다. 항목 수를 확인하기 위해 코드에 다음 줄을 추가했습니다.
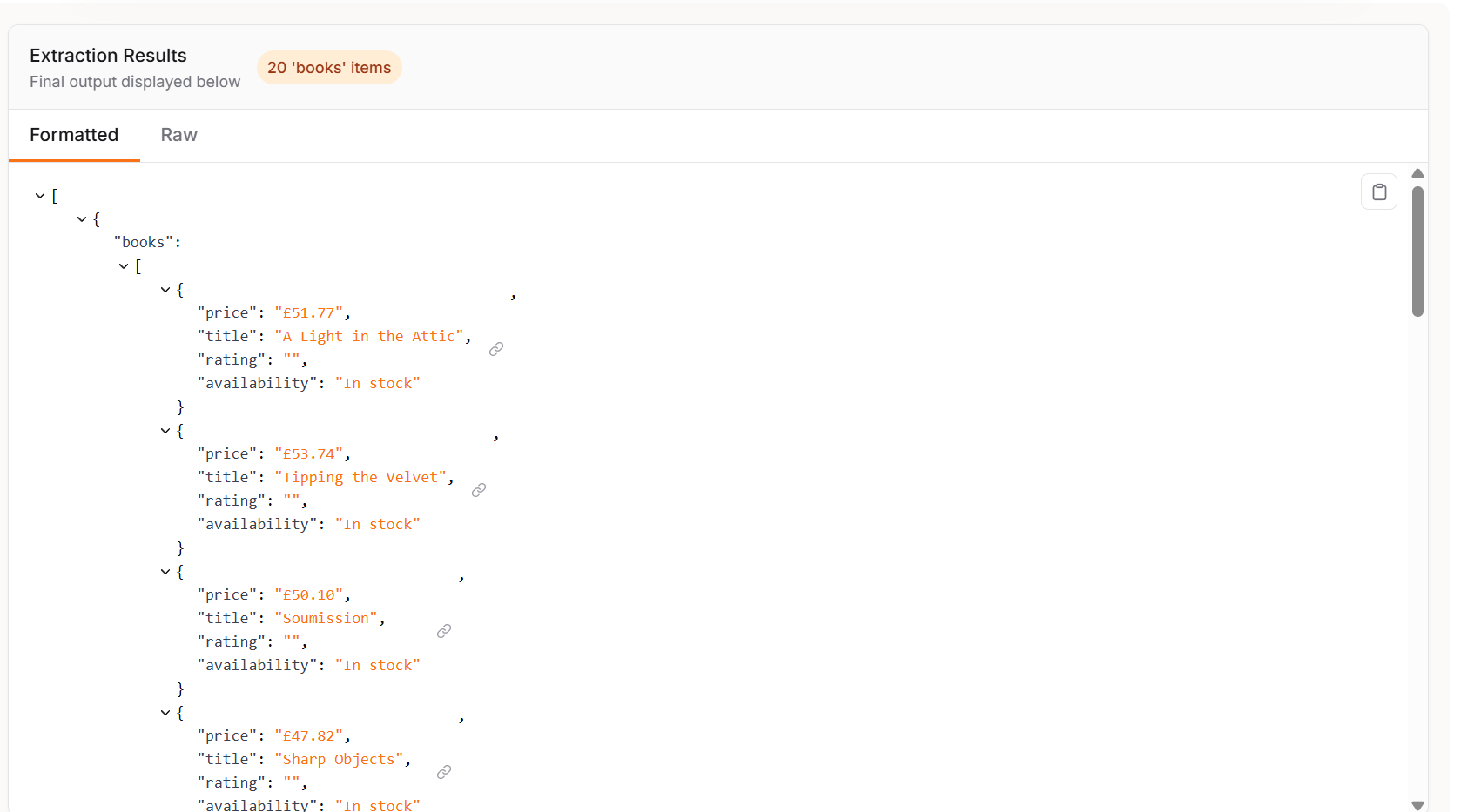
print("총 스크랩된 상품 수:", len(data))아래 출력에서 볼 수 있듯이, Crawl4AI와 GPT-4o는 페이지에 있는 20개 항목을 모두 찾아냈습니다.

LLM과 결합하면 Crawl4AI는 놀라운 정확도를 가진 매우 강력한 도구가 됩니다.
Firecrawl
스크래핑과 관련하여 Firecrawl은 실제로 두 가지 다른 제품을 제공합니다. 간단하고 더러운 스크래핑 옵션에는 평범한 구식 Firecrawl을 사용할 수 있습니다. Firecrawl Extract를 사용하면 구조화된 JSON 객체를 추출할 수 있습니다.
일반 Firecrawl
이것은 일반 Firecrawl을 사용한 Books To Scrape 출력 결과입니다. 보시다시피 상태가 매우 나쁩니다. Firecrawl은 페이지를 마크다운으로 변환한 후, 원시 마크다운을 무작위로 보이는 JSON 필드로 분할했습니다. 이 데이터는 수동 코드로 추가 정제하거나 LLM에 전달해야 합니다.
{
"markdown": "All products \| Books to Scrape - Sandboxnn[Books to Scrape](index.html) We love being scraped!nn- [Home](index.html)n- All productsnn- [Books](catalogue/category/books_1/index.html) - [여행](catalogue/category/books/travel_2/index.html)n - [미스터리](catalogue/category/books/mystery_3/index.html)n - [역사 소설](catalogue/category/books/historical-fiction_4/index.html)n - [연재 만화](catalogue/category/books/sequential-art_5/index.html)n - [고전](catalogue/category/books/classics_6/index.html)n - [철학](catalogue/category/books/philosophy_7/index.html)n - [로맨스](catalogue/category/books/romance_8/index.html)n - [여성 소설](catalogue/category/books/womens-fiction_9/index.html)n - [소설](catalogue/category/books/fiction_10/index.html)n - [아동](catalogue/category/books/childrens_11/index.html)n - [종교](catalogue/category/books/religion_12/index.html)n - [논픽션](catalogue/category/books/nonfiction_13/index.html)n - [음악](catalogue/category/books/music_14/index.html)n - [기본](catalogue/category/books/default_15/index.html)n - [공상과학](catalogue/category/books/science-fiction_16/index.html)n - [스포츠와 게임](catalogue/category/books/sports-and-games_17/index.html)n - [댓글 추가](catalogue/category/books/add-a-comment_18/index.html)n - [판타지](catalogue/category/books/fantasy_19/index.html)n - [뉴 어덜트](catalogue/category/books/new-adult_20/index.html)n - [청소년](catalogue/category/books/young-adult_21/index.html)n - [과학](catalogue/category/books/science_22/index.html)n - [시](catalogue/category/books/poetry_23/index.html)n - [초자연적](catalogue/category/books/paranormal_24/index.html)n - [미술](catalogue/category/books/art_25/index.html)n - [심리학](catalogue/category/books/psychology_26/index.html)n - [자서전](catalogue/category/books/autobiography_27/index.html)n - [육아](catalogue/category/books/parenting_28/index.html)n - [성인 소설](catalogue/category/books/adult-fiction_29/index.html)n - [유머](catalogue/category/books/humor_30/index.html)n - [공포](catalogue/category/books/horror_31/index.html)- [역사](catalogue/category/books/history_32/index.html)n - [음식 및 음료](catalogue/category/books/food-and-drink_33/index.html)n - [기독교 소설](catalogue/category/books/christian-fiction_34/index.html)n - [비즈니스](catalogue/category/books/business_35/index.html)n - [전기](catalogue/category/books/biography_36/index.html)n - [스릴러](catalogue/category/books/thriller_37/index.html)n - [현대문학](catalogue/category/books/contemporary_38/index.html)n - [영성](catalogue/category/books/spirituality_39/index.html)n - [학술](catalogue/category/books/academic_40/index.html)n - [자기계발](catalogue/category/books/self-help_41/index.html)n - [역사](catalogue/category/books/historical_42/index.html)n - [기독교](catalogue/category/books/christian_43/index.html)n - [서스펜스](catalogue/category/books/suspense_44/index.html)n - [단편 소설](catalogue/category/books/short-stories_45/index.html)n - [소설](catalogue/category/books/novels_46/index.html)n - [건강](catalogue/category/books/health_47/index.html)n - [정치](catalogue/category/books/politics_48/index.html)n - [문화](catalogue/category/books/cultural_49/index.html)n - [에로티카](catalogue/category/books/erotica_50/index.html)n - [범죄](catalogue/category/books/crime_51/index.html)nn# 모든 상품nn**1000**개 결과 - **1**부터 **20**까지 표시 중.nnnnnnn**주의!** 본 웹사이트는 웹 스크래핑을 위한 데모 사이트입니다. 여기에 표시된 가격과 평점은 임의로 할당된 것으로 실제 의미가 없습니다.nn01. [](catalogue/a-light-in-the-attic_1000/index.html)nnnnnnnn ### [다락방의 빛 ...](catalogue/a-light-in-the-attic_1000/index.html "다락방의 빛")nnnnnn £51.77nnnnnn 재고 있음nnnn 장바구니에 담기nn02. [](catalogue/tipping-the-velvet_999/index.html)nnnnnnnn ### [벨벳을 쓰다듬으며](catalogue/tipping-the-velvet_999/index.html "벨벳을 쓰다듬으며")nnnnnn £53.74nnnnnn 재고 있음nnnn 장바구니에 담기nn03. [](catalogue/soumission_998/index.html)nnnnnnnn ### [Soumission](catalogue/soumission_998/index.html "Soumission")nnnnnn £50.10nnnnnn 재고 있음nnnn 장바구니에 담기nn04. [](catalogue/sharp-objects_997/index.html)nnnnnnnn ### [Sharp Objects](catalogue/sharp-objects_997/index.html "Sharp Objects")nnnnnn £47.82nnnnnn 재고 있음nnnn 장바구니에 담기nn05. [](catalogue/sapiens-a-brief-history-of-humankind_996/index.html)nnnnnnnn ### [사피엔스: 인류의 짧은 역사 ...](catalogue/sapiens-a-brief-history-of-humankind_996/index.html "사피엔스: 인류의 짧은 역사")nnnnnn £54.23nnnnnn 재고 있음nnnn 장바구니 담기nn06. [](catalogue/the-requiem-red_995/index.html)nnnnnnnn ### [레퀴엠 레드](catalogue/the-requiem-red_995/index.html "레퀴엠 레드")nnnnnn £22.65nnnnnn 재고 있음nnnn 장바구니 담기nn07. [](catalogue/the-dirty-little-secrets-of-getting-your-dream-job_994/index.html)nnnnnnnn ### [꿈의 직장을 얻는 더러운 작은 비밀 ...](catalogue/the-dirty-little-secrets-of-getting-your-dream-job_994/index.html "꿈의 직장을 얻는 더러운 작은 비밀")nnnnnn £33.34nnnnnn 재고 있음nnnn 장바구니 담기nn08. [](catalogue/the-coming-woman-a-novel-based-on-the-life-of-the-infamous-feminist-victoria-woodhull_993/index.html)nnnnnnnn ### [다가오는 여성: A ...](catalogue/the-coming-woman-a-novel-based-on-the-life-of-the-infamous-feminist-victoria-woodhull_993/index.html "다가오는 여성: 악명 높은 페미니스트 빅토리아 우드헐의 삶을 바탕으로 한 소설")nnnnnn £17.93nnnnnn 재고 있음nnnn 장바구니 담기nn09. [](catalogue/the-boys-in-the-boat-nine-americans-and-their-epic-quest-for-gold-at-the-1936-berlin-olympics_992/index.html)nnnnnnnn ### [보트 위의 소년들](catalogue/the-boys-in-the-boat-nine-americans-and-their-epic-quest-for-gold-at-the-1936-berlin-olympics_992/index.html "보트 위의 소년들: 1936년 베를린 올림픽에서 금메달을 향한 아홉 미국인의 서사시적 도전")nnnnnn £22.60nnnnnn 재고 있음nnnn 장바구니 담기nn10. [](catalogue/the-black-maria_991/index.html)nnnnnnnn ### [블랙 마리아](catalogue/the-black-maria_991/index.html "블랙 마리아")nnnnnn £52.15nnnnnn 재고 있음nnnn 장바구니 담기nn11. [](catalogue/starving-hearts-triangular-trade-trilogy-1_990/index.html)nnnnnnnn ### [굶주린 마음들 (삼각 무역 ...](catalogue/starving-hearts-triangular-trade-trilogy-1_990/index.html "굶주린 마음들 (삼각 무역 3부작, \#1)")nnnnnn £13.99nnnnnn 재고 있음nnnn 장바구니 담기nn12. [](catalogue/shakespeares-sonnets_989/index.html)nnnnnnnn ### [셰익스피어의 소네트](catalogue/shakespeares-sonnets_989/index.html "셰익스피어의 소네트")nnnnnn £20.66nnnnnn 재고 있음nnnn 장바구니 담기nn13. [](catalogue/set-me-free_988/index.html)nnnnnnnn ### [Set Me Free](catalogue/set-me-free_988/index.html "Set Me Free")nnnnnn £17.46nnnnnn 재고 있음nnnn 장바구니에 담기nn14. [](catalogue/scott-pilgrims-precious-little-life-scott-pilgrim-1_987/index.html)nnnnnnnn ### [스캇 필그림의 소중한 작은 ...](catalogue/scott-pilgrims-precious-little-life-scott-pilgrim-1_987/index.html "스캇 필그림의 소중한 작은 삶 (스캇 필그림 #1)")nnnnnn £52.29nnnnnn 재고 있음nnnn 장바구니 담기nn15. [](catalogue/rip-it-up-and-start-again_986/index.html)nnnnnnnn ### [Rip it Up and ...](catalogue/rip-it-up-and-start-again_986/index.html "Rip it Up and Start Again")nnnnnn £35.02nnnnnn 재고 있음nnnn 장바구니에 담기nn16. [](catalogue/our-band-could-be-your-life-scenes-from-the-american-indie-underground-1981-1991_985/index.html)nnnnnnnn ### [우리 밴드가 당신의 인생이 될 수도 있다](catalogue/our-band-could-be-your-life-scenes-from-the-american-indie-underground-1981-1991_985/index.html "우리 밴드는 당신의 인생이 될 수 있다: 1981-1991년 미국 인디 언더그라운드의 풍경")nnnnnn £57.25nnnnnn 재고 있음nnnn 장바구니 담기nn17. [](catalogue/olio_984/index.html)nnnnnnnn ### [올리오](catalogue/olio_984/index.html "올리오")nnnnnn £23.88nnnnnn 재고 있음nnnn 장바구니 담기nn18. [](catalogue/mesaerion-the-best-science-fiction-stories-1800-1849_983/index.html)nnnnnnnn ### [메사에리온: 최고의 과학 ...](catalogue/mesaerion-the-best-science-fiction-stories-1800-1849_983/index.html "메사에리온: 최고의 공상 과학 소설 1800-1849")nnnnnn £37.59nnnnnn 재고 있음nnnn 장바구니 담기nn19. [](catalogue/libertarianism-for-beginners_982/index.html)nnnnnnnn ### [초보자를 위한 자유지상주의](catalogue/libertarianism-for-beginners_982/index.html "초보자를 위한 자유지상주의")nnnnnn £51.33nnnnnn 재고 있음nnnn 장바구니 담기nn20. [](catalogue/its-only-the-himalayas_981/index.html)nnnnnnnn ### [히말라야 산맥일 뿐](catalogue/its-only-the-himalayas_981/index.html "히말라야 산맥일 뿐")nnnnnn £45.17nnnnnn 재고 있음nnnn 장바구니 담기nnn-n50페이지 중 1페이지nnn- [다음](catalogue/page-2.html)",
"metadata": {
"language": "en-us",
"description": "",
"created": "2016년 6월 24일 09:29",
"viewport": "width=device-width",
"title": "n 모든 상품 | 스크래핑 대상 도서 - 샌드박스n",
"robots": "NOARCHIVE,NOCACHE",
"favicon": "https://books.toscrape.com/static/oscar/favicon.ico",
"scrapeId": "aa3667ec-647b-42ab-adb2-9c35e042896d",
"sourceURL": "https://books.toscrape.com",
"url": "https://books.toscrape.com/",
"statusCode": 200,
"contentType": "text/html",
"proxyUsed": "basic",
"creditsUsed": 80
},
"scrape_id": "aa3667ec-647b-42ab-adb2-9c35e042896d"
}일반 Firecrawl은 페이지를 가져오지만, 그 이상은 거의 하지 않습니다. 마크다운 페이지가 조각난 형태로 큰 JSON 객체에 압축되어 제공됩니다. 페이지를 가져올 수는 있지만, 웹 페이지를 사용 가능한 데이터로 변환하려면 많은 작업이 필요합니다.
Firecrawl Extract
추출은 한 단계 업그레이드된 기능입니다. 추출을 사용하면 NLP를 통한 스크래핑을 완벽하게 지원합니다. 모델에 어떤 데이터를 추출할지 지시하면 페이지에서 해당 데이터를 추출합니다. 아래 이미지에서 볼 수 있듯이, 제목, 가격, 재고 상태 필드를 포함한 추천 스키마까지 제공됩니다. 스키마가 만족스럽다면 “실행” 버튼을 클릭하세요.
참고: 웹사이트 주소 끝에 /*가 추가되어 있습니다. 이는 Extract가 사이트 전체를 자동 크롤링하도록 지시합니다. 크레딧을 절약하려면 /*를 제거하세요 .
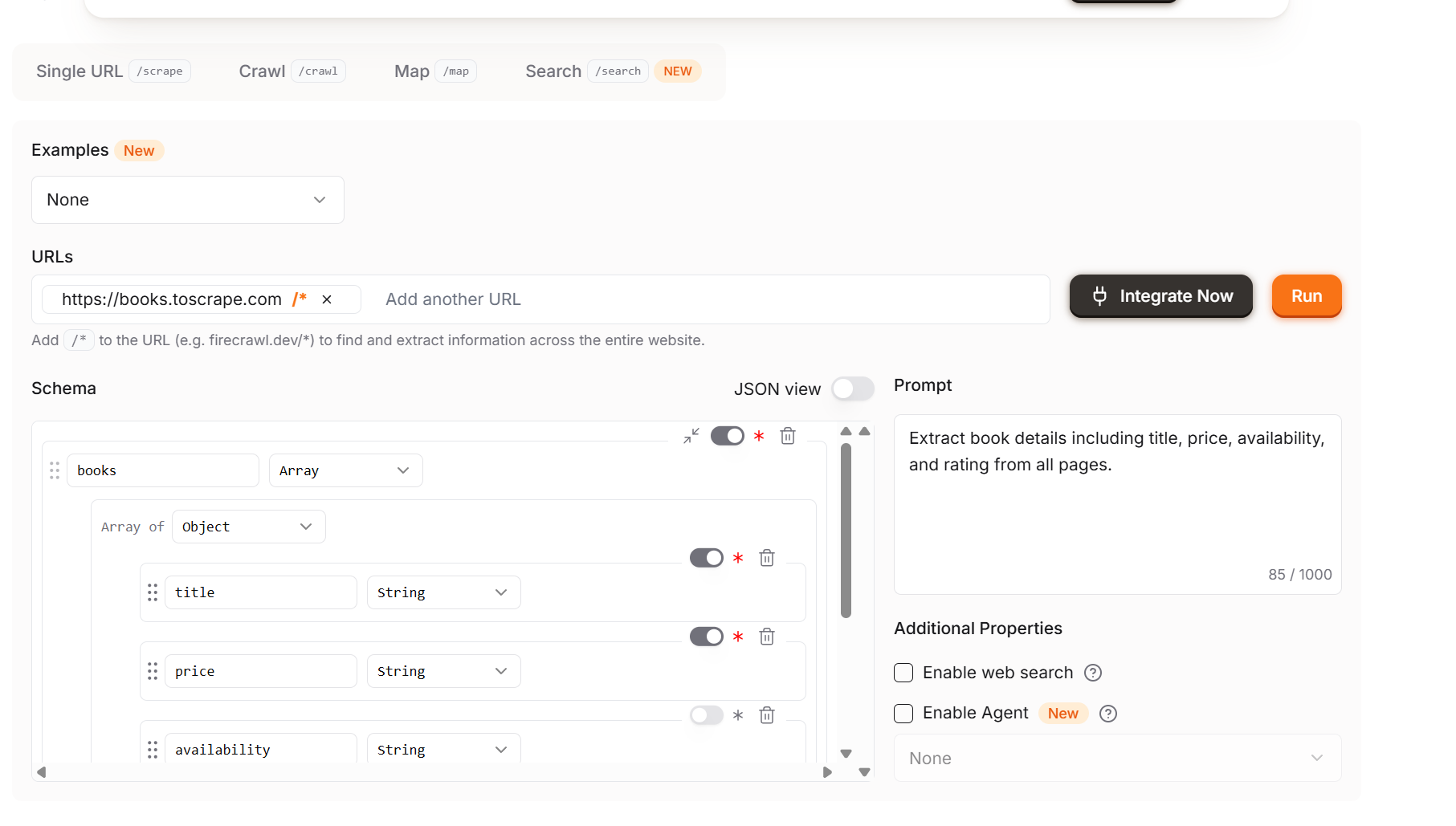
단일 페이지 크롤링을 원한다면 Extract의 기본 설정을 변경하세요. 아래 이미지는 단일 페이지 스크래핑을 위한 구성 예시입니다. /* 연산자는 간과하기 쉬우니, 비용을 절약하고 필요한 경우에만 사용하세요.
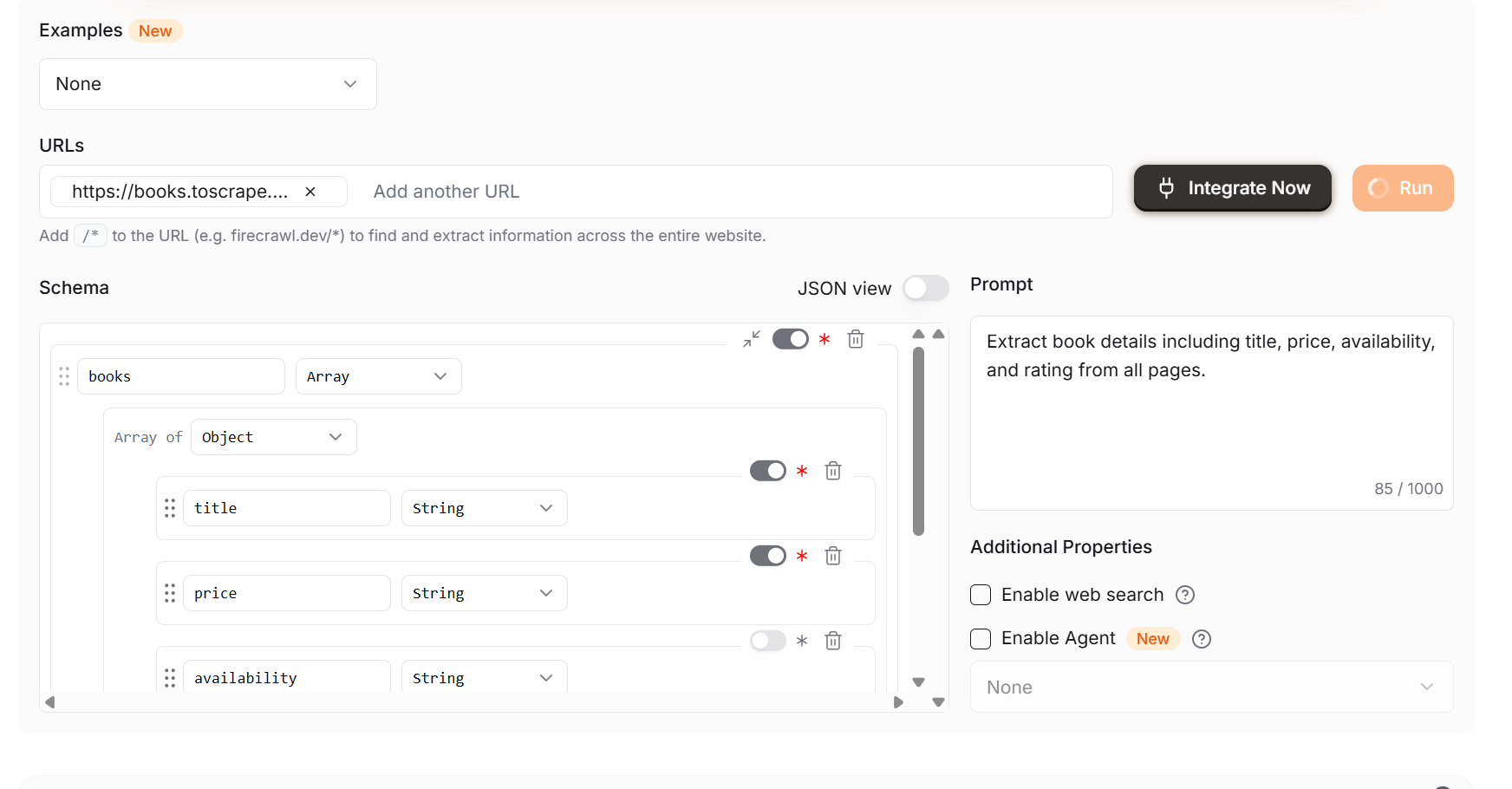
Firecrawl Extract를 사용하면 출력 결과가 깔끔하게 정리되어 바로 사용할 수 있습니다. 보시다시피 다음과 같은 특성을 가진 구조화된 JSON 객체를 얻게 됩니다.
titlepricerating재고 상태
보안 및 규정 준수
Crawl4AI
Crawl4AI는 소프트웨어에 내장된 규정 준수 보장을 제공하지 않습니다. 다만 robots.txt 파일과 같은 규정 준수를 지원할 수 있는 일부 구성 옵션을 제공합니다.
Crawl4AI 사용 시 GDPR 및 CCPA와 같은 법률 준수는 사용자의 책임입니다. Crawl4AI는 법적 및 보안 규정 준수에 거의 도움을 주지 않습니다. 이는 대규모 프로젝트를 실행할 때 적절한 관행을 따르고 있는지 확인하기 위해 추가 인력을 고용해야 할 가능성이 높다는 것을 의미합니다.
Firecrawl
Firecrawl의 문서에 따르면, 해당 서비스는 사용자의 정보를 Google에 처리 목적으로 제공합니다. 이용 약관에는 GDPR 및 CCPA를 준수한다고 명시되어 있으나, 이러한 정책을 직접 이행할 책임은 사용자에게 있다고 명시합니다. 해당 법률 위반 시 책임은 전적으로 사용자에게 있으며, Firecrawl은 도구 오용에 대해 책임을 지지 않습니다.
Firecrawl은 Crawl4AI보다 더 많은 책임 보호를 제공합니다. 그러나 여전히 충분하지 않습니다. 그들의 제품에는 안전장치가 없습니다. 사용자는 규칙을 준수해야 하며, 그렇지 않을 경우 오용에 대한 책임이 있습니다. 자세한 내용은 Firecrawl 이용약관 전문을 참조하십시오.
가격 및 라이선스
Crawl4AI
Crawl4AI는 누구나 무료로 사용할 수 있습니다. 여기서 ‘무료’라는 용어는 상당히 느슨하게 사용됩니다. 따라오시면서 눈치채셨겠지만, 실제 추출 작업에는 LLM(대규모 언어 모델) 통합이 필요합니다. LLM을 직접 호스팅하거나 OpenAI API 같은 서비스에 연결할 수 있습니다. Crawl4AI를 사용할 때도 외부 서비스 비용이나 자체 호스팅 시 인프라 비용을 지불해야 합니다. 이러한 비용은 누적됩니다. Crawl4AI가 운영 비용을 제로로 만들지는 않습니다.
Crawl4AI는 Apache 라이선스 하에 배포됩니다. Crawl4AI 파생물을 수정, 배포, 심지어 상업적으로 판매하는 것도 허용됩니다. 규정 준수 지원이 가능하다면, Crawl4AI의 관대한 라이선스는 개발자와 데이터 팀에게 매우 매력적인 선택지가 됩니다.
Firecrawl
일반 Firecrawl
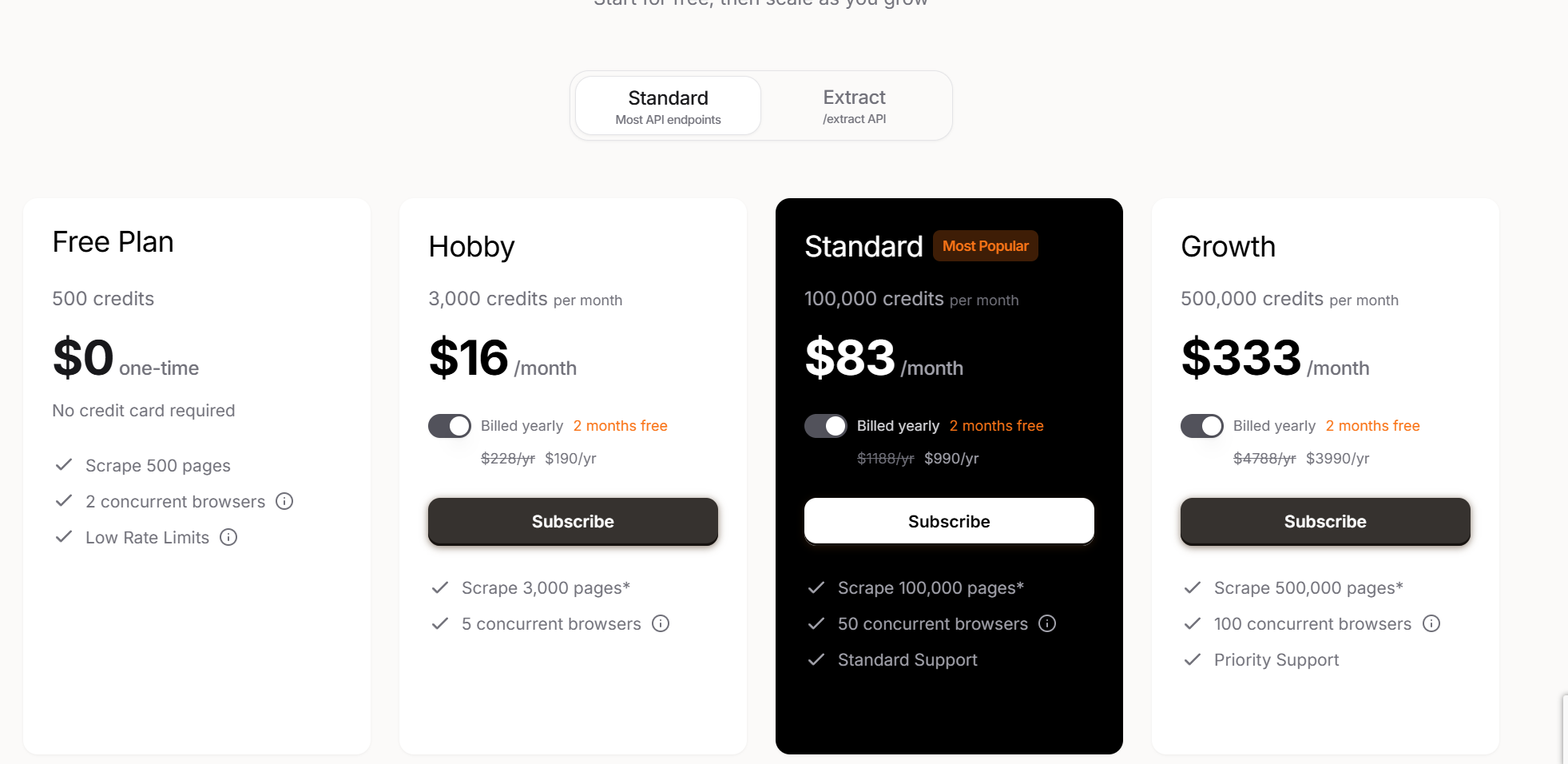
기본형 Firecrawl은 다양한 가격 등급으로 제공됩니다. 무료 플랜을 사용해 볼 수 있습니다. 유료 플랜은 월 16달러(3,000페이지)부터 월 333달러(500,000페이지)까지 다양합니다.
Firecrawl Extract
추출 기능을 사용할 경우, 유료 플랜은 연간 18,000,000개의 토큰에 월 89달러부터 연간 192,000,000개의 API 토큰에 월 719달러까지 다양합니다.

Firecrawl 라이선싱
Firecrawl은 다양한 제품에 대해 서로 다른 라이선스를 사용합니다. 모든 라이선스 유형은 여기에서 확인할 수 있습니다. Firecrawl은 엔터프라이즈급 제품이며, 해당 코드를 재포장하여 자체 제품으로 사용할 수 없다는 점에 유의하십시오. 오픈소스 코드조차 AGPL-3.0 라이선스 하에 배포됩니다. 다른 GNU 소프트웨어 계약과 마찬가지로, 이는 기업 사용에 있어 매우 제한적입니다.
커뮤니티 및 지원
Crawl4AI
오픈소스 프로젝트인 Crawl4AI는 보유한 자원으로 가능한 한 제한된 지원을 제공합니다. 헬프데스크나 SLA는 없습니다. 다만 디스코드 채널을 통해 개발자에게 자유롭게 문의할 수 있습니다. 대기 시간은 달라질 수 있습니다. 문제를 추적하고 신속하게 해결해 줄 전담 팀을 기대하지 마십시오.
Firecrawl
Firecrawl은 대시보드에서 문서, FAQ 페이지, 상태 업데이트 등의 지원 옵션을 제공합니다. “지원 문의” 버튼을 통해 지원팀에 연락할 수 있지만, 지원 우선순위는 요금제 등급에 따라 달라집니다. 커뮤니티 지원을 위해 Discord 채널에 참여하는 것도 언제든지 가능합니다.
실제 사용 사례
Crawl4AI
Crawl4AI는 현대 개발자를 위한 다양한 실제 사용 사례를 제공합니다. 구축할 수 있는 것만으로도 한계가 있습니다.
- 백엔드 지원: 자체 데이터 제품을 만들기로 결정했다면, Crawl4AI를 자체 LLM과 통합하여 제품을 판매할 수 있습니다.
- AI 에이전트: 이 문서 앞부분에서 살펴본 것처럼, 외부 LLM을 Crawl4AI에 직접 연결하여 CSV, JSON, XML 등 LLM이 인식하는 모든 형식으로 사용자 정의 데이터 구조를 출력하는 강력한 추출 작업을 수행할 수 있습니다.
- 취미 프로젝트 및 스타트업: Crawl4AI와 같은 오픈 소스 도구는 실험, 개념 증명 및 파이프라인 프로토타입을 위한 빠른 접근성을 제공합니다.
Firecrawl
Firecrawl은 사내 개발이 거의 없이 대량 스크래핑이 필요한 팀을 위해 구축되었습니다. 많은 작업 없이 아이디어에서 구체적인 제품으로 나아가고 싶다면 Firecrawl이 도움을 줄 수 있습니다.
- 생산 수준 크롤링: Firecrawl은 대규모 크롤링을 위해 설계되었습니다. 기본적으로 전체 웹사이트까지 크롤링하는 기능을 제공합니다.
- 콘텐츠 모니터링: 경쟁사의 가격 및 콘텐츠를 모니터링하기 위해 정기적인 크롤링을 실행하세요.
- 정제되고 즉시 사용 가능한 데이터: Extract를 사용하면 데이터 팀에 거의 또는 전혀 정리 작업 없이 데이터를 바로 전달할 수 있습니다.
장점과 단점
| Crawl4AI | Firecrawl | |
|---|---|---|
| 장점 | – 완전한 오픈 소스 및 투명성. – 관대한 Apache 라이선스 — 빌드, 수정, 재판매 가능. – 유연성: LLM 기반 또는 LLM 미사용 옵션 선택 가능. – 맞춤형 파이프라인을 위한 플러그 앤 플레이 파이썬 라이브러리. |
– 비개발자도 매우 간단하게 사용 가능: GUI, 플레이그라운드, NLP 프롬프트. – 다양한 언어 지원 (Python, JS, Go, Rust). – 일회성 또는 정기 스크래핑에 신속한 배포. – 기업용 가격 및 지원 등급 제공. |
| 단점 | – 실제 구조화된 추출을 위해서는 별도의 LLM이 필요함 — 숨겨진 비용 발생. – 제한된 내장 규정 준수 지원 — GDPR/CCPA는 사용자가 직접 관리해야 함. – 비동기 처리 특성상 셸 환경에서 최적화되며, IDE 사용 시 오류 발생 가능. |
– Extract 없이 기본 출력이 종종 지저분함 — 원시 마크다운은 추가 작업 필요. – 실질적인 규정 준수 가이드라인 부재 — 사용자에게 여전히 책임이 있음. – 폐쇄형 소스 코어, AGPL 제한으로 커스텀 빌드 제약. – 규모 확대 또는 와일드카드 크롤링 시 사용 비용이 급증할 수 있음. |
Bright Data를 고려해야 하는 이유
Crawl4AI와 Firecrawl 모두 장단점이 있습니다. Crawl4AI는 개발자 요구사항과 숨겨진 LLM 비용이 따릅니다. Firecrawl은 사용량 계층과 Firecrawl 생태계에 묶이게 됩니다.
Bright Data는 앞서 언급한 두 도구의 틈새 시장을 모두 채울 수 있는 다양한 제품을 제공합니다.
주요 Bright Data 도구
- 스크레이퍼 API: 깔끔하고 바로 사용 가능한 데이터로 사전 구축된 스크레이퍼를 원할 때 언제든지 실행하세요.
- 웹 언락커 API: 사이트 차단을 우회하고 CAPTCHA를 해결하며, 마크다운으로 스크래핑하고 지리적 위치를 제어할 수도 있습니다.
- 브라우저 API: 프로그래밍 환경에서 통합 프록시 및 CAPTCHA 해결 기능을 갖춘 원격 브라우저를 제어하세요.
- 데이터셋: 수년 전으로 거슬러 올라가는 100개 이상의 도메인에서 방대한 역사적 데이터셋 라이브러리에 접근하세요.
MCP 서버를 통해 LLM 친화적인 패키지로 최고의 Bright Data 제품에 모두 접근할 수 있습니다. LLM에 연결하고 프롬프트를 작성하면 시스템이 작업을 수행합니다.
Bright Data 통합 옵션
현재 AI 및 개발 업계 최고의 도구들과의 통합도 제공합니다. 지속적으로 새로운 통합 기능을 추가하고 있습니다. 최신 목록은 문서를 확인하세요.
결론
Bright Data는 단순한 스크래핑 문제 해결을 넘어, AI 스택을 위한 전체 생태계를 제공합니다. 실시간 데이터 수집부터 훈련을 위한 과거 기록 활용에 이르기까지, 인프라가 아닌 인사이트에 시간을 투자할 수 있도록 지원합니다.
지금 무료 체험을 시작하고 그 차이를 확인해 보세요.





