

웹 데이터로 GPT-OSS를 미세 조정하는 이 가이드에서 다음을 배울 수 있습니다:
- Unsloth란 무엇이며, 왜 미세 조정을 가속화하는지
- Bright Data의 스크래핑 API를 활용한 고품질 훈련 데이터 수집 방법
- 효율적인 미세 조정을 위한 환경 설정 방법
- 완벽한 단계별 튜토리얼로 GPT-OSS를 미세 조정하는 방법
시작해 보겠습니다!
Unsloth란 무엇이며, 왜 미세 조정에 사용해야 할까요?
Unsloth는 Hugging Face 생태계(Hub, transformers, PEFT, TRL)와 완벽하게 호환되면서 LLM 미세 조정을 훨씬 빠르게 만드는 경량 라이브러리입니다. 이 라이브러리는 GTX 1070부터 H100s까지 대부분의 NVIDIA GPU를 지원하며, TRL 라이브러리의 전체 트레이너 제품군과 원활하게 작동합니다.
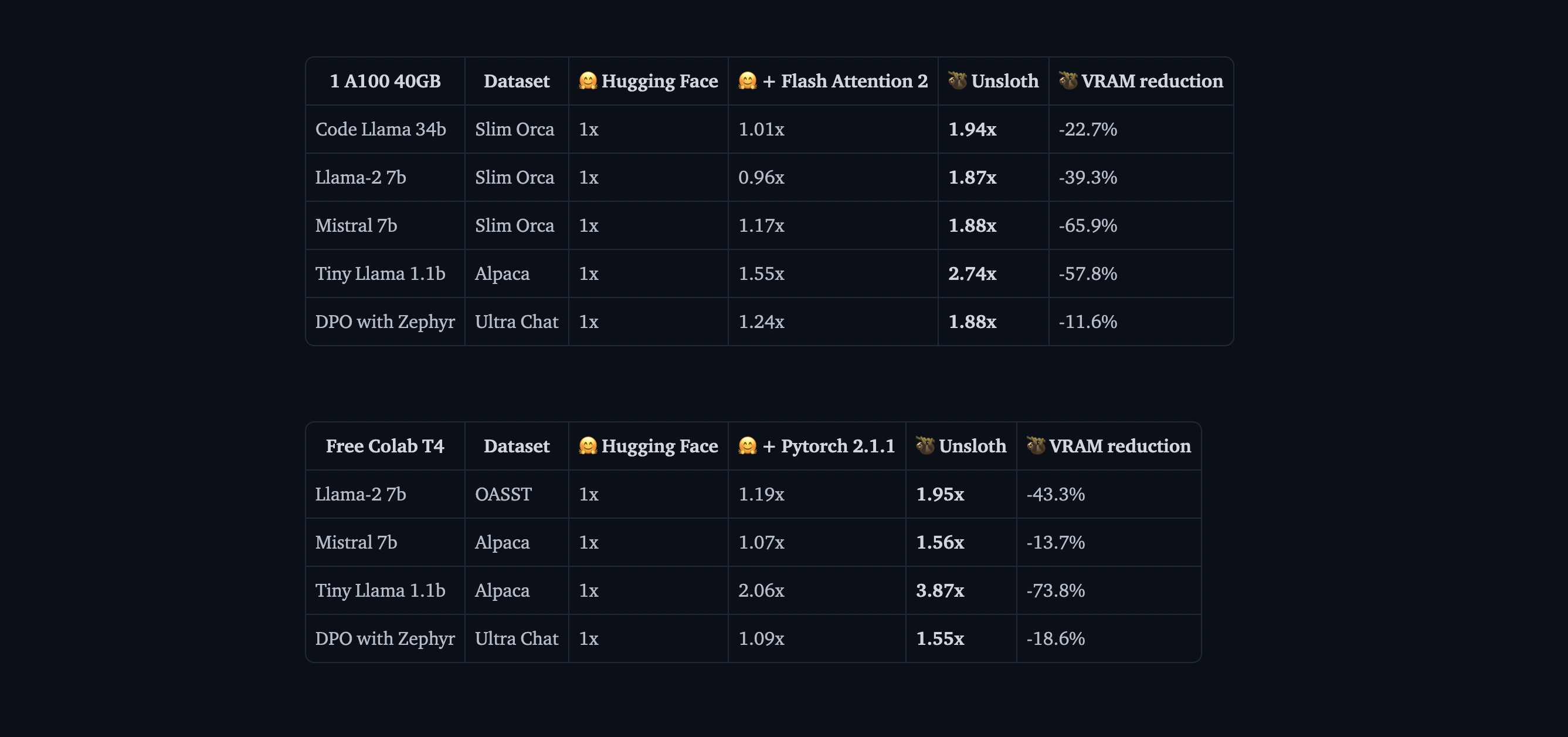
Unsloth가 제공하는 성능 향상은 인상적입니다. 벤치마크에서 표준 Transformer 구현 대비 2배 빠른 훈련 속도를 달성하며, 메모리 사용량은 40% 감소합니다. 이는 동일한 하드웨어에서 더 큰 모델을 훈련하거나 더 큰 배치 크기를 사용할 수 있음을 의미합니다. 가장 중요한 점은 정확도 저하가 전혀 없다는 것입니다. 따라서 모델 품질을 희생하지 않고도 이러한 모든 이점을 얻을 수 있습니다.
GPT-OSS 모델 이해하기
OpenAI의 GPT-OSS 공개는 AI 개발 접근 방식에 있어 중대한 전환점을 의미합니다. API 제한, 사용량 기반 과금, 속도 제한 없이 진정한 GPT 모델에 접근할 수 있게 된 것은 이번이 처음입니다.
GPT-OSS는 두 가지 주요 변형으로 제공됩니다:
- GPT-OSS-120B: 이 더 큰 모델은 GPT-4의 품질과 맞먹지만 최소 80GB의 GPU 메모리가 필요합니다.
- GPT-OSS-20B: GPT-3.5의 성능과 유사하며, 16GB GPU에서 효율적으로 실행됩니다(본 튜토리얼에 적합).
GPT-OSS를 다른 오픈 모델과 차별화하는 독특한 기능은 추론 노력 제어입니다. 추론 수준을 “낮음”, “중간”, “높음”으로 설정하여 모델이 문제를 얼마나 깊이 있게 사고할지 조절할 수 있습니다. 이를 통해 특정 사용 사례에 따라 속도와 정확도 사이의 균형을 맞출 수 있습니다.
정밀 조정에 품질 좋은 데이터가 중요한 이유
파인 튜닝의 품질은 입력 데이터에 달려 있습니다. 아무리 정교한 훈련 환경을 갖춰도 데이터가 잡음이 많거나 일관성이 없거나 형식이 불량하면 모델도 동일한 문제를 학습하게 됩니다. 따라서 깨끗하고 형식이 잘 잡힌 정확한 데이터를 위해 Bright Data의 웹 스크레이퍼 API를 사용할 것입니다.
Bright Data는 웹 스크래핑의 복잡한 부분을 처리하여 맞춤형 솔루션이 자주 실패하는 부분을 해결합니다. IP 로테이션을 관리하여 속도 제한을 피하고, CAPTCHA를 자동으로 해결하며, 동적 JavaScript 렌더링 콘텐츠를 처리하고, 수백만 건의 요청에 걸쳐 일관된 데이터 품질을 유지합니다.
본 튜토리얼에서는 Bright Data의 API를 활용해 Python 문서를 수집한 후, 이를 모델 훈련용 데이터로 변환할 것입니다.
필수 조건 및 환경 설정
시작하기 전에 성공적인 파인 튜닝에 필요한 모든 요소가 준비되었는지 확인합시다. 무료 GPU 접근을 제공하는 Google Colab을 사용하겠지만, 최소 16GB의 VRAM을 갖춘 모든 머신에서도 동일한 프로세스가 작동합니다.
하드웨어 요구 사항
이 튜토리얼을 진행하려면 다음이 필요합니다:
- 최소 16GB VRAM을 갖춘 GPU (T4, V100 이상)
- 모델 가중치 및 체크포인트 저장을 위한 25GB 이상의 여유 디스크 공간
- 모델 및 종속성 다운로드용 안정적인 인터넷 연결
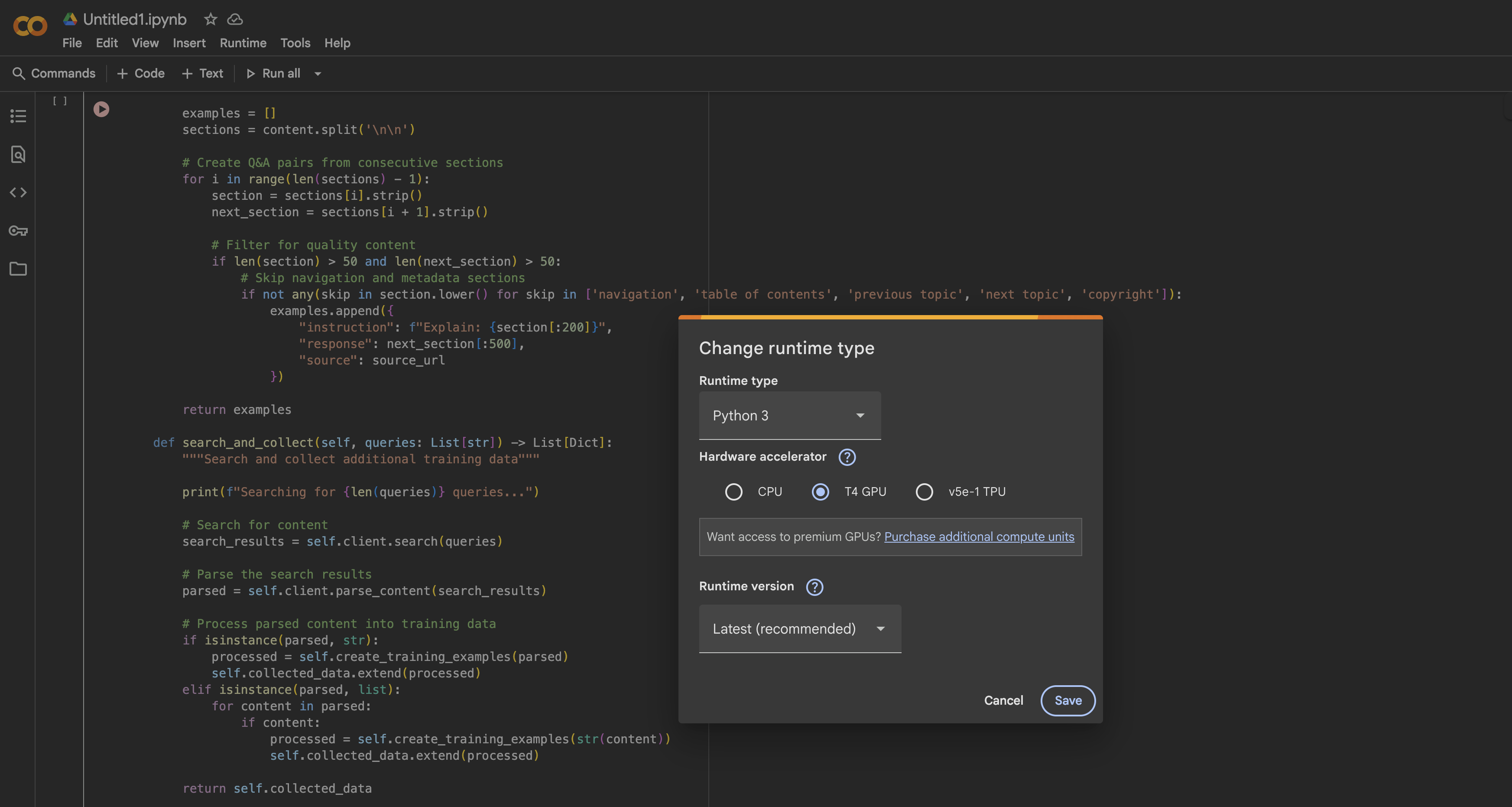
Google Colab에서 T4 GPU를 무료로 이용하려면:
- 새 노트북 열기
- 런타임 → 런타임 유형 변경으로 이동
- 하드웨어 가속기로 GPU 선택
- 변경 사항 적용을 위해 저장 클릭
Unsloth 및 종속성 설치
GPU 런타임이 준비되면 Unsloth와 필요한 모든 종속성을 설치합니다. 설치 과정은 서로 다른 패키지 버전 간의 충돌을 피하도록 최적화되어 있습니다:
%%capture
# Unsloth 및 핵심 종속성 설치
!pip install --upgrade -qqq uv
try: import numpy; get_numpy = f"numpy=={numpy.__version__}"
except: get_numpy = "numpy"
!uv pip install -qqq
"torch>=2.8.0" "triton>=3.4.0" {get_numpy} torchvision bitsandbytes "transformers>=4.55.3"
"unsloth_zoo[base] @ git+https://github.com/unslothai/unsloth-zoo"
"unsloth[base] @ git+https://github.com/unslothai/unsloth"
git+https://github.com/triton-lang/triton.git@05b2c186c1b6c9a08375389d5efe9cb4c401c075#subdirectory=python/triton_kernels
!uv pip install --upgrade --no-deps transformers==4.56.2 tokenizers
!uv pip install --no-deps trl==0.22.2
!pip install -q brightdata-sdk이 설치 스크립트는 몇 가지 중요한 세부 사항을 처리합니다. 먼저, 더 빠른 패키지 해결을 위해 uv를 사용합니다. 또한 호환성 문제를 피하기 위해 특정 버전을 고정하고, 최적의 성능을 위해 Unsloth의 커스텀 Triton 커널을 설치하며, 데이터 수집 단계를 위한 Bright Data SDK를 포함합니다.
GPU 설정 확인
설치 후 GPU가 제대로 감지되었는지, 충분한 메모리를 확보했는지 확인해 보겠습니다:
import torch
# GPU 정보 가져오기
gpu_stats = torch.cuda.get_device_properties(0)
max_memory = round(gpu_stats.total_memory / 1024 / 1024 / 1024, 3)
print(f"GPU = {gpu_stats.name}")
print(f"최대 메모리 = {max_memory} GB")
print(f"CUDA 버전 = {torch.version.cuda}")
print(f"PyTorch 버전 = {torch.__version__}")
# 최소 요구 사항 확인
if max_memory < 15:
print("⚠️ 경고: GPT-OSS-20B에 충분한 메모리가 없을 수 있습니다")
else:
print("✅ 파인 튜닝에 충분한 GPU 메모리 보유")사용 가능한 GPU 메모리가 최소 15GB 이상이어야 합니다. 무료 Colab의 T4 GPU는 16GB를 제공하며, Unsloth의 최적화를 적용하면 우리의 요구사항에 완벽합니다.
Unsloth로 GPT-OSS 로드하기
이제 Unsloth의 최적화된 로더를 사용하여 GPT-OSS 모델을 로드하겠습니다. Unsloth가 모든 최적화 세부 사항을 자동으로 처리하므로 표준 트랜스포머에 비해 이 과정은 매우 간단합니다.
베이스 모델 로드
from unsloth import FastLanguageModel
import torch
# 구성
max_seq_length = 1024 # 데이터에 따라 조정
dtype = None # GPU에 최적화된 데이터 형식 자동 감지
# Unsloth는 더 빠른 로딩을 위한 사전 양자화 모델을 제공합니다
fourbit_models = [
"unsloth/gpt-oss-20b-unsloth-bnb-4bit", # BitsAndBytes 4bit
"unsloth/gpt-oss-120b-unsloth-bnb-4bit",
"unsloth/gpt-oss-20b", # MXFP4 형식
"unsloth/gpt-oss-120b",
]
# 모델 로드
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/gpt-oss-20b",
dtype = dtype,
max_seq_length = max_seq_length,
load_in_4bit = True, # 16GB에 맞추기 위해 필수
full_finetuning = False, # 효율성을 위해 LoRA 사용)
print(f"✅ 모델 로드 성공!")
print(f"모델 크기: {model.num_parameters():,} 파라미터")
print(f"사용 중인 장치: {model.device}")FastLanguageModel.from_pretrained() 메서드는 백그라운드에서 여러 작업을 수행합니다. GPU 성능을 자동으로 감지하여 최적화하고, 메모리 사용량을 75% 줄이기 위해 4비트 양자화를 적용하며, 완전한 미세 조정 대신 LoRA 훈련을 위해 모델을 설정하고, 메모리 효율적인 어텐션 메커니즘을 구성합니다.
LoRA 어댑터 구성
LoRA(저순위 적응)은 소비자용 하드웨어에서 파인 튜닝을 가능하게 하는 핵심 기술입니다. 모든 모델 매개변수를 업데이트하는 대신, 주요 레이어에 삽입되는 소형 어댑터 행렬만 훈련합니다:
model = FastLanguageModel.get_peft_model(
model,
r = 8, # LoRA 순위 - 높을수록 용량은 커지지만 속도는 느려짐
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"],
lora_alpha = 16, # LoRA 스케일링 계수
lora_dropout = 0, # 더 빠른 훈련을 위해 드롭아웃 비활성화
bias = "none", # 바이어스 항 훈련 안 함
use_gradient_checkpointing = "unsloth", # 메모리 절약에 중요
random_state = 3407,
use_rslora = False, # 대부분의 경우 표준 LoRA가 최상
loftq_config = None,)
# 훈련 통계 표시
trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
all_params = sum(p.numel() for p in model.parameters())
trainable_percent = 100 * trainable_params / all_params
print(f"훈련 {trainable_params:,} 매개변수 중 {all_params:,}개")
print(f"전체 매개변수의 {trainable_percent:.2f}%에 불과합니다!")
print(f"절약된 메모리: ~{(1 - trainable_percent/100) * 40:.1f}GB")이 구성은 훈련 효율성과 모델 용량 사이의 균형을 맞춥니다. r=8일 때, 전체 매개변수의 1% 미만을 훈련하면서도 우수한 미세 조정 결과를 달성합니다. 기울기 체크포인트만으로도 약 30%의 메모리를 절약할 수 있으며, 이는 모델을 메모리에 맞출 수 있는지 아니면 OOM(메모리 부족) 오류를 발생시킬지 여부를 가르는 요소가 될 수 있습니다.
GPT-OSS 추론 노력 제어 테스트
정밀 조정을 시작하기 전에 GPT-OSS의 독특한 추론 노력 기능을 살펴보겠습니다. 이 기능은 모델이 응답하기 전에 수행하는 “사고”의 양을 제어할 수 있게 합니다:
from transformers import TextStreamer
# 수학적 추론이 필요한 테스트 문제
messages = [
{"role": "user", "content": "x^5 + 3x^4 - 10 = 3을 풀어보세요. 접근법을 설명하세요."},
]
# 낮은 추론 노력으로 테스트
print("="*60)
print("낮은 추론 (빠르지만 덜 철저함)")
print("="*60)
inputs = tokenizer.apply_chat_template(
messages,
add_generation_prompt = True,
return_tensors = "pt",
return_dict = True,
reasoning_effort = "low",
).to("cuda")
text_streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
_ = model.generate(**inputs, max_new_tokens = 128, streamer = text_streamer)
# HIGH 추론 노력으로 테스트
print("n" + "="*60)
print("HIGH REASONING (더 느리지만 더 정확함)")
print("="*60)
inputs = tokenizer.apply_chat_template(
messages,
add_generation_prompt = True,
return_tensors = "pt",
return_dict = True,
reasoning_effort = "high",
).to("cuda")
_ = model.generate(**inputs, max_new_tokens = 512, streamer = text_streamer)이 코드를 실행하면 “낮음” 추론 시 모델이 빠른 근사값을 제공하는 반면, “높음” 추론 시 단계별 작업 과정을 포함한 더 상세한 해결책을 생성하는 것을 확인할 수 있습니다. 이 기능은 실제 배포 환경에서 속도와 정확도의 균형을 맞추는 데 매우 유용합니다.
Bright Data를 이용한 훈련 데이터 수집
이제 Bright Data의 웹 스크레이퍼 API를 사용하여 고품질 훈련 데이터를 수집하겠습니다. Bright Data가 대규모 웹 스크래핑에 필요한 모든 복잡한 인프라를 처리하므로 자체 스크레이퍼를 구축하는 것보다 이 접근 방식이 훨씬 더 안정적입니다.
데이터 수집기 설정
from brightdata import bdclient
from typing import List, Dict
import re
import json
class DataCollector:
def __init__(self, api_token: str):
"""
웹 스크래핑을 위한 Bright Data 클라이언트 초기화.
인수:
api_token: Bright Data API 토큰
"""
self.client = bdclient(api_token=api_token)
self.collected_data = []
print("✅ Bright Data 클라이언트 초기화 완료")
def collect_documentation(self, urls: List[str]) -> List[Dict]:
"""
문서 페이지를 스크래핑하여 훈련 데이터로 변환합니다.
이 메서드는 일괄 및 개별 URL 스크래핑을 모두 처리하며,
일괄 처리 실패 시 자동으로 개별 요청으로 전환됩니다.
"""
print(f"{len(urls)}개 URL 스크래핑 시작...")
try:
# 효율성을 위해 일괄 스크래핑 시도
results = self.client.scrape(urls, data_format="markdown")
if isinstance(results, str):
# 단일 결과 반환
print("단일 결과 처리 중...")
training_data = self.process_single_result(results)
elif isinstance(results, list):
# 다중 결과 반환
print(f"{len(results)}개 결과 처리 중...")
training_data = []
for i, content in enumerate(results, 1):
if content:
print(f" {i}/{len(results)}번째 결과 처리 중")
examples = self.process_single_result(content)
training_data.extend(examples)
else:
print(f"예상치 못한 결과 유형: {type(results)}")
training_data = []
except Exception as e:
print(f"배치 스크래핑 실패: {e}")
print("개별 URL 스크래핑으로 전환 중...")
# 대체: URL을 하나씩 스크래핑
training_data = []
for url in urls:
try:
print(f" 스크래핑: {url}")
content = self.client.scrape(url, data_format="markdown")
if content:
examples = self.process_single_result(content)
training_data.extend(examples)
print(f" ✓ {len(examples)} 예제 추출 완료")
except Exception as url_error:
print(f" ✗ 실패: {url_error}")
self.collected_data = training_data
print(f"n✅ 수집 완료: {len(self.collected_data)} 훈련 예제")
return self.collected_data이 코드의 역할:
- 지능형 대체 전략: 수집기는 효율성을 위해 먼저 일괄 스크래핑을 시도합니다. 네트워크 문제나 API 제한으로 실패할 경우 자동으로 개별 URL 스크래핑으로 전환됩니다.
- 진행 상황 추적: 스크래핑 과정 중 실시간 업데이트로 정확히 무슨 일이 발생하는지 보여줘 디버깅을 용이하게 합니다.
- 오류 복원력: 각 URL은 자체 try-catch 블록으로 감싸져 있어, 하나의 URL 실패가 전체 수집 과정을 중단시키지 않습니다.
- 마크다운 형식: HTML보다 깔끔하고 훈련 데이터로 처리하기 쉬운 마크다운 형식으로 데이터를 요청합니다.
Bright Data 클라이언트는 다음과 같은 복잡한 작업을 처리합니다:
- 속도 제한을 피하기 위한 IP 주소 순환
- 자동 CAPTCHA 해결
- 자바스크립트 중심 페이지 렌더링
- 실패한 요청을 지수적 백오프로 재시도
스크랩된 콘텐츠를 훈련 데이터로 처리
우수한 미세 조정의 핵심은 깨끗하고 잘 정렬된 데이터입니다. 원시 스크랩 콘텐츠를 질문-답변 쌍으로 처리하는 방법은 다음과 같습니다:
def process_single_result(self, content: str) -> List[Dict]:
"""
스크랩된 콘텐츠를 깨끗한 Q&A 훈련 쌍으로 처리합니다.
이 메서드는 모든 서식 잔여물을 제거하고 자연스러운 예시를 생성하기 위해
강력한 정제 작업을 수행합니다.
"""
examples = []
# 1단계: 모든 HTML 및 마크다운 서식 제거
content = re.sub(r'<[^>]+>', '', content) # HTML 태그
content = re.sub(r'', '', content) # 이미지
content = re.sub(r'[([^]]+)]([^)]+)', r'1', content) # 링크
content = re.sub(r'```[^`]*```', '', content) # 코드 블록
content = re.sub(r'`[^`]+`', '', content) # 인라인 코드
content = re.sub(r'[#*_~>`|-]+', ' ', content) # 마크다운 기호
content = re.sub(r'\(.)', r'1', content) # 이스케이프 시퀀스
content = re.sub(r'https?://[^s]+', '', content) # URL
content = re.sub(r'S+.w+', '', content) # 파일 경로
content = re.sub(r's+', ' ', content) # 공백 정규화
# 2단계: 문장 분할
sentences = re.split(r'(?<=[.!?])s+', content)
# 3단계: 네비게이션 및 상용구 콘텐츠 필터링
clean_sentences = []
skip_patterns = ['navigation', 'copyright', 'index',
'table of contents', 'previous', 'next',
'click here', 'download', 'share']
for 문장이 in 문장들:
문장 = 문장.strip()
# 실질적인 문장만 유지
if (문장.길이 > 30 and
not any(문장.lower() for 패턴 in 패턴_리스트)):
정제된_문장들.append(문장)
# 4단계: 연속된 문장으로 Q&A 쌍 생성
for i in range(0, len(clean_sentences) - 1):
instruction = clean_sentences[i][:200].strip()
response = clean_sentences[i + 1][:300].strip()
# 양쪽 모두 충분한 길이를 갖도록 확인
if len(instruction) > 20 and len(response) > 30:
examples.append({
"instruction": instruction,
"response": response
})
return examples처리 방식:
process_single_result 메서드는 원시 웹 콘텐츠를 다음 네 가지 핵심 단계를 통해 깨끗한 훈련 데이터로 변환합니다:
- 단계 1 – 강력한 정리: 모델을 혼란스럽게 할 수 있는 모든 서식 요소 제거:
- Markdown 변환 과정에서 남아 있을 수 있는 HTML 태그
- 텍스트 이해에 기여하지 않는 이미지 참조 및 링크
- 코드 블록 및 인라인 코드(코드 샘플이 아닌 순수 텍스트를 원함)
- 잡음을 유발하는 특수 문자 및 이스케이프 시퀀스
- 2단계 – 문장 분할: 구두점 마커를 사용하여 콘텐츠를 개별 문장으로 분할합니다. 이를 통해 작업할 수 있는 논리적인 텍스트 단위를 확보합니다.
- 단계 3 – 품질 필터링: 다음을 제거합니다:
- 내용이 빈약한 짧은 문장(30자 미만)
- “여기를 클릭하세요” 또는 “다음 페이지”와 같은 탐색 요소
- 저작권 고지 같은 상용구
- 일반적인 웹 탐색 패턴을 포함하는 모든 문장
- 4단계 – 페어 생성: 연속된 문장을 질문-답변 페어로 처리하여 훈련 페어를 생성합니다. 문서가 개념을 제시한 후 설명하는 패턴을 따르는 경우가 많기 때문에 이 방법이 효과적입니다.
그 결과 모델에 자연스러운 흐름과 응답 패턴을 가르치는 깔끔하고 문맥에 맞는 훈련 데이터가 생성됩니다.
데이터 수집 및 검증
이제 모든 것을 통합하여 훈련 데이터를 수집해 보겠습니다:
# API 토큰으로 수집기 초기화
# 토큰은 /cp/api_tokens에서 획득
BRIGHTDATA_API_TOKEN = "your_brightdata_api_token_here"
collector = DataCollector(api_token=BRIGHTDATA_API_TOKEN)
# 스크래핑할 URL - Python 문서가 훌륭한 훈련 데이터가 됩니다
urls = [
"https://docs.python.org/3/tutorial/introduction.html",
"https://docs.python.org/3/tutorial/controlflow.html",
"https://docs.python.org/3/tutorial/datastructures.html",
"https://docs.python.org/3/tutorial/modules.html",
"https://docs.python.org/3/tutorial/classes.html",
]
print("="*60)
print("데이터 수집 시작")
print("="*60)
training_data = collector.collect_documentation(urls)
# 데이터 수집 확인
if len(training_data) == 0:
print("⚠️ 오류: 훈련 데이터 수집 실패!")
print("n문제 해결 단계:")
print("1. Bright Data API 토큰이 올바른지 확인")
print("2. 계정에 충분한 크레딧이 있는지 확인")
print("3. 연결 상태 테스트를 위해 단일 URL로 먼저 시도")
raise ValueError("훈련 데이터 수집 실패")데이터 수집 설정 이해하기:
- API 토큰: Bright Data 계정에 가입하여 API 토큰을 받아야 합니다. 시작할 수 있도록 크레딧이 제공되는 무료 체험판이 있습니다.
- URL 선택: Python 문서를 사용하는 이유는 다음과 같습니다:
- 구조가 잘 짜여 있고 일관성이 있습니다
- 코딩 어시스턴트 훈련에 적합한 기술적 내용이 포함되어 있음
- 설명 방식이 Q&A 형식에 잘 부합함
- 공개적으로 이용 가능하며 윤리적으로 출처가 확보됨
- 오류 처리: 유효성 검사는 빈 데이터셋으로 진행하는 것을 방지하여 이후 훈련 실패를 막습니다. 문제 해결 단계는 일반적인 문제 진단에 도움이 됩니다.
최종 데이터 검증 및 정리
훈련에 데이터를 사용하기 전에 최종 정리 단계를 수행합니다:
# 최종 검증 및 정리
def final_validation(examples: List[Dict]) -> List[Dict]:
"""
훈련 예제에 대한 최종 검증 및 중복 제거를 수행합니다.
"""
clean_data = []
seen_instructions = set()
for ex in examples:
instruction = ex.get('instruction', '').strip()
response = ex.get('response', '').strip()
# 최종 정리 단계
instruction = re.sub(r'[^a-zA-Z0-9s.,?!]', '', instruction)
response = re.sub(r'[^a-zA-Z0-9s.,?!]', '', response)
# 중복 제거 및 품질 보장
if (len(instruction) > 10 and
len(response) > 20 and
instruction not in seen_instructions):
seen_instructions.add(instruction)
clean_data.append({
"instruction": instruction,
"response": response
})
return clean_data
training_data = final_validation(training_data)
print(f"n✅ 최종 데이터셋: {len(training_data)} 고유 예시")
print("n훈련 예시 샘플:")
print("="*60)
for i, example in enumerate(training_data[:3], 1):
print(f"n예시 {i}:")
print(f"Q: {example['instruction']}")
print(f"A: {example['response']}")검증이 달성하는 것:
- 중복 제거:
seen_instructions집합은 훈련 중 과적합을 유발할 수 있는 중복 질문이 없도록 보장합니다. - 최종 문자 정리: 기본 구두점을 제외한 잔여 특수 문자를 제거하여 텍스트가 깔끔하고 일관되도록 합니다.
- 길이 검증: 예제가 실질적인 내용을 갖도록 최소 길이를 강제 적용합니다:
- 지침은 최소 10자 이상이어야 함
- 응답은 최소 20자 이상이어야 함
- 품질 보증: 샘플 예제를 출력하여 훈련 진행 전 데이터 품질을 시각적으로 확인할 수 있습니다.
최종 출력은 훈련 데이터로 적합한 깔끔하고 가독성 있는 Q&A 쌍을 보여야 합니다. 예제가 무의미하거나 형식이 불량해 보인다면 처리 매개변수를 조정하거나 다른 소스 URL을 선택해야 할 수 있습니다.
프로 팁: 실제 사용 사례에서는 사전 수집된 데이터셋을 위해 Bright Data의 마켓플레이스 사용을 고려하세요. 다양한 분야에 걸쳐 선별된 데이터셋을 제공하여 상당한 시간을 절약하고 일관된 품질을 보장합니다.
GPT-OSS 훈련을 위한 데이터 포맷팅
GPT-OSS는 특정 채팅 형식의 데이터를 요구합니다. 최적의 훈련 결과를 위해 Unsloth의 유틸리티를 활용하여 데이터가 올바르게 포맷되도록 하겠습니다:
from unsloth.chat_templates import standardize_sharegpt
from datasets import Dataset
def prepare_dataset(raw_data: List[Dict]):
"""
원시 Q&A 쌍을 올바르게 포맷된 훈련 데이터셋으로 변환합니다.
이 함수는 다음을 처리합니다:
1. 메시지 형식으로 변환
2. GPT-OSS 채팅 템플릿 적용
3. 모든 형식 문제 수정
"""
print("훈련용 데이터셋 준비 중...")
# 1단계: 채팅 메시지 형식으로 변환
formatted_data = []
for item in raw_data:
formatted_data.append({
"messages": [
{"role": "user", "content": item["instruction"]},
{"role": "assistant", "content": item["response"]}
]
})
# 2단계: HuggingFace 데이터셋 생성
dataset = Dataset.from_list(formatted_data)
print(f"{len(dataset)}개의 예제로 구성된 데이터셋 생성 완료")
# 3단계: ShareGPT 형식으로 표준화
dataset = standardize_sharegpt(dataset)이 첫 부분에서 수행되는 작업:
- 메시지 형식 변환: 간단한 Q&A 쌍을 GPT 모델이 기대하는 대화 형식으로 변환합니다. 각 훈련 예시는 사용자 질문과 어시스턴트 응답으로 구성된 두 차례의 대화로 변환됩니다.
- 데이터셋 생성: HuggingFace의 Dataset 클래스는 다음과 같은 효율적인 데이터 처리를 제공합니다:
- 대용량 데이터셋을 위한 메모리 매핑 접근
- 내장된 배치 및 셔플링
- 전체 HuggingFace 생태계와의 호환성
- ShareGPT 표준화:
standardize_sharegpt함수는 데이터가 채팅 모델 훈련의 사실상의 표준이 된 ShareGPT 형식과 일치하도록 보장합니다. 이는 특수 사례를 처리하고 일관성을 유지합니다.
채팅 템플릿 적용
이제 GPT-OSS의 특정 서식 요구 사항을 적용합니다:
# 4단계: GPT-OSS 전용 채팅 템플릿 적용
def formatting_prompts_func(examples):
"""각 예시에 GPT-OSS 채팅 템플릿을 적용합니다."""
convos = examples["messages"]
texts = []
for convo in convos:
# 생성 프롬프트 없이 템플릿 적용 (훈련 중)
text = tokenizer.apply_chat_template(
convo,
tokenize = False,
add_generation_prompt = False
)
texts.append(text)
return {"text": texts}
dataset = dataset.map(
formatting_prompts_func,
batched = True,
desc = "챗 템플릿 적용 중"
)템플릿 적용 이해:
- 채팅 템플릿 목적: 각 모델 계열은 고유한 특수 토큰과 서식을 가집니다. GPT-OSS는
<|start|>,<|message|>,<|channel|>등의 태그를 사용하여 대화의 각 부분을 구분합니다. - 생성 프롬프트 없음:
add_generation_prompt = False로설정합니다. 생성 작업이 아닌 훈련 중이기 때문입니다. 훈련 중에는 모델이 완성되지 않은 프롬프트가 아닌 완전한 대화를 보도록 해야 합니다. - 배치 처리:
batched = True매개변수는 여러 예시를 동시에 처리하여 대규모 데이터셋의 서식 지정 과정을 크게 가속화합니다. - 텍스트 출력: 이 단계에서는 출력을 텍스트(토큰화되지 않음)로 유지합니다. 트레이너가 자체 설정으로 토큰화를 처리하기 때문입니다.
서식 문제 확인 및 수정
GPT-OSS는 채널 태그에 대한 특정 요구 사항이 있으므로 이를 확인해야 합니다:
# 5단계: 채널 태그 확인 및 필요 시 수정
sample_text = dataset[0]['text']
print("n형식 확인 중...")
print(f"샘플 (첫 200자): {sample_text[:200]}")
if "<|channel|>" not in sample_text:
print("⚠️ 채널 태그 누락, 형식 수정 중...")
def fix_formatting(examples):
"""GPT-OSS 호환성을 위해 채널 태그 추가."""
fixed_texts = []
for text in examples["text"]:
# GPT-OSS는 역할과 메시지 사이에 채널 태그를 요구함
text = text.replace(
"<|start|>assistant<|message|>",
"<|start|>assistant<|channel|>final<|message|>"
)
fixed_texts.append(text)
return {"text": fixed_texts}
dataset = dataset.map(
fix_formatting,
batched = True,
desc = "채널 태그 추가"
)
print("✅ 형식 수정 완료")
print(f"n✅ 데이터셋 준비 완료: {len(dataset)} 개의 형식화된 예시")
return dataset
# 데이터셋 준비
dataset = prepare_dataset(training_data)채널 태그가 중요한 이유:
- 채널 태그 기능:
<|channel|>final태그는 GPT-OSS에게 이것이 중간 추론 단계가 아닌 최종 응답임을 알립니다. 이는 GPT-OSS의 고유한 추론 노력 제어 시스템의 일부입니다. - 형식 검증: 태그 존재 여부를 확인하고 누락 시 추가합니다. 이는 형식 불일치로 인한 훈련 실패를 방지합니다.
- 자동 수정: 대체 작업은 수동 개입 없이 호환성을 보장합니다. 이는 기본 동작이 다를 수 있는 서로 다른 토큰화기 버전을 사용할 때 특히 중요합니다.
데이터셋 통계 및 검증
마지막으로 준비된 데이터셋을 검증해 보겠습니다:
# 통계 표시
print("n데이터셋 통계:")
print(f"예제 수: {len(dataset)}")
print(f"평균 텍스트 길이: {sum(len(x['text']) for x in dataset) / len(dataset):.0f} 문자")
# 완전한 포맷팅 예제 표시
print("n포맷팅된 예제:")
print("="*60)
print(dataset[0]['text'][:500])
print("="*60)
# 모든 예제가 올바른 형식인지 검증
format_checks = {
"has_user_tag": all("<|start|>user" in ex['text'] for ex in dataset),
"has_assistant_tag": all("<|start|>assistant" in ex['text'] for ex in dataset),
"has_channel_tag": all("<|channel|>" in ex['text'] for ex in dataset),
"has_message_tags": all("<|message|>" in ex['text'] for ex in dataset),
}
print("n형식 검증:")
for check, passed in format_checks.items():
status = "✅" if passed else "❌"
print(f"{status} {check}: {passed}")검증 시 확인 사항:
- 길이 통계: 평균 텍스트 길이는 훈련에 적합한 시퀀스 길이를 설정하는 데 도움이 됩니다. 너무 길다면 잘라내거나 더 큰 max_seq_length를 사용해야 할 수 있습니다.
- 형식 완전성: 다음 네 가지 검사가 모두 통과해야 합니다:
- 사용자 태그는 사용자 입력 시작 위치를 표시합니다
- 어시스턴트 태그는 모델 응답을 표시합니다
- 채널 태그는 응답 유형을 지정합니다
- 메시지 태그에는 실제 내용이 포함됩니다
- 시각적 확인: 출력된 예시를 통해 모델이 정확히 무엇을 학습할지 확인할 수 있습니다. 다음과 같은 형식이어야 합니다:
<|start|>사용자<|message|>질문 내용<|end|>
<|start|>어시스턴트<|channel|>final<|message|>응답 내용<|end|>검증에 실패할 경우 훈련이 제대로 진행되지 않거나 모델이 잘못된 패턴을 학습할 수 있습니다. 자동 수정 기능이 대부분의 문제를 처리하지만, 수동 검사는 경계 사례를 포착하는 데 도움이 됩니다.
Unsloth와 TRL을 사용한 훈련 구성
이제 훈련 구성을 설정하겠습니다. Unsloth는 Hugging Face의 TRL 라이브러리와 완벽하게 통합되어 Unsloth의 속도 최적화와 TRL의 검증된 훈련 알고리즘이라는 두 가지 장점을 모두 제공합니다.
from trl import SFTConfig, SFTTrainer
from unsloth.chat_templates import train_on_responses_only
# 훈련 구성 생성
training_config = SFTConfig(
# 기본 설정
per_device_train_batch_size = 2, # GPU 메모리에 따라 조정
gradient_accumulation_steps = 4, # 유효 배치 크기 = 2 * 4 = 8
warmup_steps = 5,
max_steps = 60, # 빠른 테스트용; 실제 운영 시 증가
# 학습률 설정
learning_rate = 2e-4,
lr_scheduler_type = "linear",
# 최적화 설정
optim = "adamw_8bit", # 8비트 최적화로 메모리 절약
weight_decay = 0.01,
# 로깅 및 저장
logging_steps = 1,
save_steps = 20,
output_dir = "outputs",
# 고급 설정
seed = 3407, # 재현성 확보용
fp16 = True, # 혼합 정밀도 훈련
report_to = "none", # 실험 추적을 위해 "wandb"로 설정
)
print("훈련 구성:")
print(f" 실질 배치 크기: {training_config.per_device_train_batch_size * training_config.gradient_accumulation_steps}")
print(f" 총 훈련 단계: {training_config.max_steps}")
print(f" 학습률: {training_config.learning_rate}")트레이너 설정
SFTTrainer(Supervised Fine-Tuning Trainer)는 훈련의 모든 복잡성을 처리합니다:
# 트레이너 초기화
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset,
args = training_config,)
print("✅ 트레이너 초기화 완료")
# 어시스턴트 응답만 훈련하도록 구성
# 중요 - 모델이 사용자 질문을 생성하도록 학습하지 않도록
gpt_oss_kwargs = dict(
instruction_part = "<|start|>user<|message|>",
response_part = "<|start|>assistant<|channel|>final<|message|>")
trainer = train_on_responses_only(
trainer,
**gpt_oss_kwargs,
)
print("✅ 응답 전용 훈련으로 구성됨")트레이너 설정 이해:
- SFTTrainer 통합: 트레이너는 여러 구성 요소를 결합합니다:
- 사용자의 LoRA 구성 모델
- 텍스트 처리를 위한 토큰화기
- 준비된 데이터셋
- 훈련 구성 매개변수
- 응답 전용 훈련: 이는 채팅 모델에 매우 중요합니다.
train_on_responses_only를사용함으로써 다음을 보장합니다:- 모델은 어시스턴트 응답에 대해서만 손실(loss)을 계산합니다
- 사용자 질문 생성을 학습하지 않습니다
- 훈련 효율성 향상 (최적화 대상 토큰 감소)
- 다양한 사용자 입력을 이해하는 모델의 능력 유지
- GPT-OSS 전용 태그: 지시문과 응답 부분은 형식화된 데이터의 내용과 정확히 일치해야 합니다. 이 태그들은 트레이너에게 무시할 부분(사용자 입력)과 훈련할 부분(어시스턴트 응답)을 구분하는 기준을 알려줍니다.
훈련 마스크 검증
사용자의 질문이 아닌 어시스턴트의 응답만 훈련 대상인지 확인하는 것이 중요합니다:
# 훈련 마스크가 올바른지 확인
print("n훈련 마스크 확인 중...")
sample = trainer.train_dataset[0]
# 레이블 디코딩을 통해 훈련 대상 확인
# -100은 훈련 대상이 아닌 토큰(마스크 처리됨)을 나타냄
visible_tokens = []
for token_id, label_id in zip(sample["input_ids"], sample["labels"]):
if label_id != -100:
visible_tokens.append(token_id)(token_id)
if visible_tokens:
decoded = tokenizer.decode(visible_tokens)
print(f"훈련 대상: {decoded[:200]}...")
print("✅ 마스크 확인 완료 - 응답 데이터만 훈련 중")
else:
print("⚠️ 경고: 가시적인 훈련 토큰이 탐지되지 않음")마스크 검증에서 알려주는 내용:
- -100 레이블: PyTorch에서 -100은 손실 함수가 해당 토큰을 무시하도록 지시하는 특수 값입니다. 응답 전용 훈련 구현 방식:
- 사용자 입력 토큰은 -100(무시)로 라벨링됩니다
- 어시스턴트 응답 토큰은 실제 토큰 ID를 유지함 (훈련됨)
- 가시적 토큰 확인: 마스킹되지 않은 토큰만 추출함으로써 모델이 정확히 무엇을 학습할지 확인할 수 있습니다. 사용자의 질문이 아닌 어시스턴트의 응답 텍스트만 표시되어야 합니다.
- 중요성: 적절한 마스킹이 없을 경우:
- 모델이 답변 대신 사용자 질문을 생성하도록 학습할 수 있습니다
- 훈련 효율이 저하됩니다(불필요한 토큰 최적화)
- 사용자 입력을 그대로 반복하는 등 원치 않는 행동을 모델이 학습할 수 있음
- 디버깅 팁: 디코딩된 텍스트에 사용자 입력이 보인다면 다음을 확인하세요:
instruction_part와response_part문자열이 정확히 일치하는지- 데이터셋 포맷팅에 모든 필수 태그가 포함되었는지
- 토큰화기가 채팅 템플릿을 올바르게 적용하고 있는지
훈련 과정 시작
모든 설정이 완료되었으므로 훈련을 시작할 준비가 되었습니다. GPU 메모리 사용량을 모니터링하고 훈련 진행 상황을 추적해 보겠습니다:
import time
import torch
# 훈련 전 GPU 캐시 초기화
torch.cuda.empty_cache()
# 초기 GPU 상태 기록
start_gpu_memory = torch.cuda.max_memory_reserved() / 1024**3
start_time = time.time()
print("="*60)
print("훈련 시작")
print("="*60)
print(f"초기 GPU 메모리 예약량: {start_gpu_memory:.2f} GB")
print(f"{training_config.max_steps} 단계 동안 훈련 중...")
print("n훈련 진행률:")
# 훈련 시작
trainer_stats = trainer.train()
# 훈련 통계 계산
training_time = time.time() - start_time
final_gpu_memory = torch.cuda.max_memory_reserved() / 1024**3
memory_used = final_gpu_memory - start_gpu_memory
print("n" + "="*60)
print("훈련 완료")
print("="*60)
print(f"소요 시간: {training_time/60:.1f} 분")
print(f"최종 손실: {trainer_stats.metrics['train_loss']:.4f}")
print(f"훈련에 사용된 GPU 메모리: {memory_used:.2f} GB")
print(f"최대 GPU 메모리: {final_gpu_memory:.2f} GB")
print(f"훈련 속도: {trainer_stats.metrics.get('train_steps_per_second', 0):.2f} 단계/초")훈련 메트릭 이해하기:
- GPU 메모리 관리:
- 훈련 전 캐시를 지우면 사용되지 않은 메모리를 확보할 수 있습니다
- 메모리 사용량 모니터링은 향후 실행을 위한 배치 크기 최적화에 도움
- 시작과 끝의 차이는 실제 훈련 오버헤드를 보여줍니다
- 최대 메모리 사용량은 OOM(Out Of Memory) 오류 발생 가능성을 알려줍니다
- 훈련 진행률 지표:
- 손실: 시간이 지남에 따라 감소해야 합니다. 조기에 평탄화되면 학습률이 너무 낮을 수 있습니다
- 초당 단계 수: 대규모 데이터셋의 훈련 시간 추정 시 유용합니다
- 소요 시간: T4 GPU 기준 60단계에 약 10~15분 소요
- 훈련 중 주의사항:
- 손실값이 꾸준히 감소하는지 (양호)
- 손실값이 불규칙하게 급등함 (학습률 너무 높음)
- 손실 변화 없음 (학습률 너무 낮거나 데이터 문제)
- 메모리 오류 발생 (배치 크기 또는 시퀀스 길이 감소)
- 성능 기대치:
- T4 GPU: 0.5-1.0 단계/초
- V100: 1.5-2.5 단계/초
- A100: 3-5 단계/초
훈련은 오류 없이 완료되어야 하며, 손실값이 초기 2-3 정도에서 종료 시점에는 1.0 미만으로 감소하는 것을 확인할 수 있어야 합니다.
미세 조정된 모델 테스트
이제 흥미로운 부분인, 우리의 미세 조정이 실제로 효과가 있었는지 테스트해 볼 차례입니다! 포괄적인 테스트 함수를 만들고 다양한 Python 관련 질문에 대해 모델을 평가해 보겠습니다:
from transformers import TextStreamer
def test_model(prompt: str, reasoning_effort: str = "medium", max_length: int = 256):
"""
주어진 프롬프트로 미세 조정된 모델을 테스트합니다.
인수:
prompt: 질문 또는 지시문
reasoning_effort: "low", "medium", 또는 "high"
max_length: 생성할 최대 토큰 수
반환값:
생성된 응답
"""
# 메시지 형식 생성
messages = [
{"role": "system", "content": "당신은 파이썬 전문가 어시스턴트입니다."},
{"role": "user", "content": prompt}
]
# 채팅 템플릿 적용
inputs = tokenizer.apply_chat_template(
messages,
add_generation_prompt = True,
return_tensors = "pt",
return_dict = True,
reasoning_effort = reasoning_effort,
).to("cuda")
# 실시간 출력을 위한 스트리밍 설정
streamer = TextStreamer(
tokenizer,
skip_prompt=True,
skip_special_tokens=True
)
# 응답 생성
outputs = model.generate(
**inputs,
max_new_tokens = max_length,
streamer = streamer,
temperature = 0.7,
top_p = 0.9,
do_sample = True,
)
# 응답 디코딩 및 반환
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
return response
# 다양한 파이썬 주제 테스트
test_questions = [
"파이썬 제너레이터란 무엇이며 언제 사용해야 하나요?",
"파이썬에서 CSV 파일을 읽는 방법은?",
"간단한 예시로 Python의 async/await 설명하기",
"Python에서 리스트와 튜플의 차이점은?",
"Python에서 예외를 올바르게 처리하는 방법은?",
]
print("="*60)
print("TESTING FINE-TUNED MODEL")
print("="*60)
for i, question in enumerate(test_questions, 1):
print(f"n{'='*60}")
print(f"질문 {i}: {question}")
print(f"{'='*60}")
print("응답:")
_ = test_model(question, reasoning_effort="medium")
print()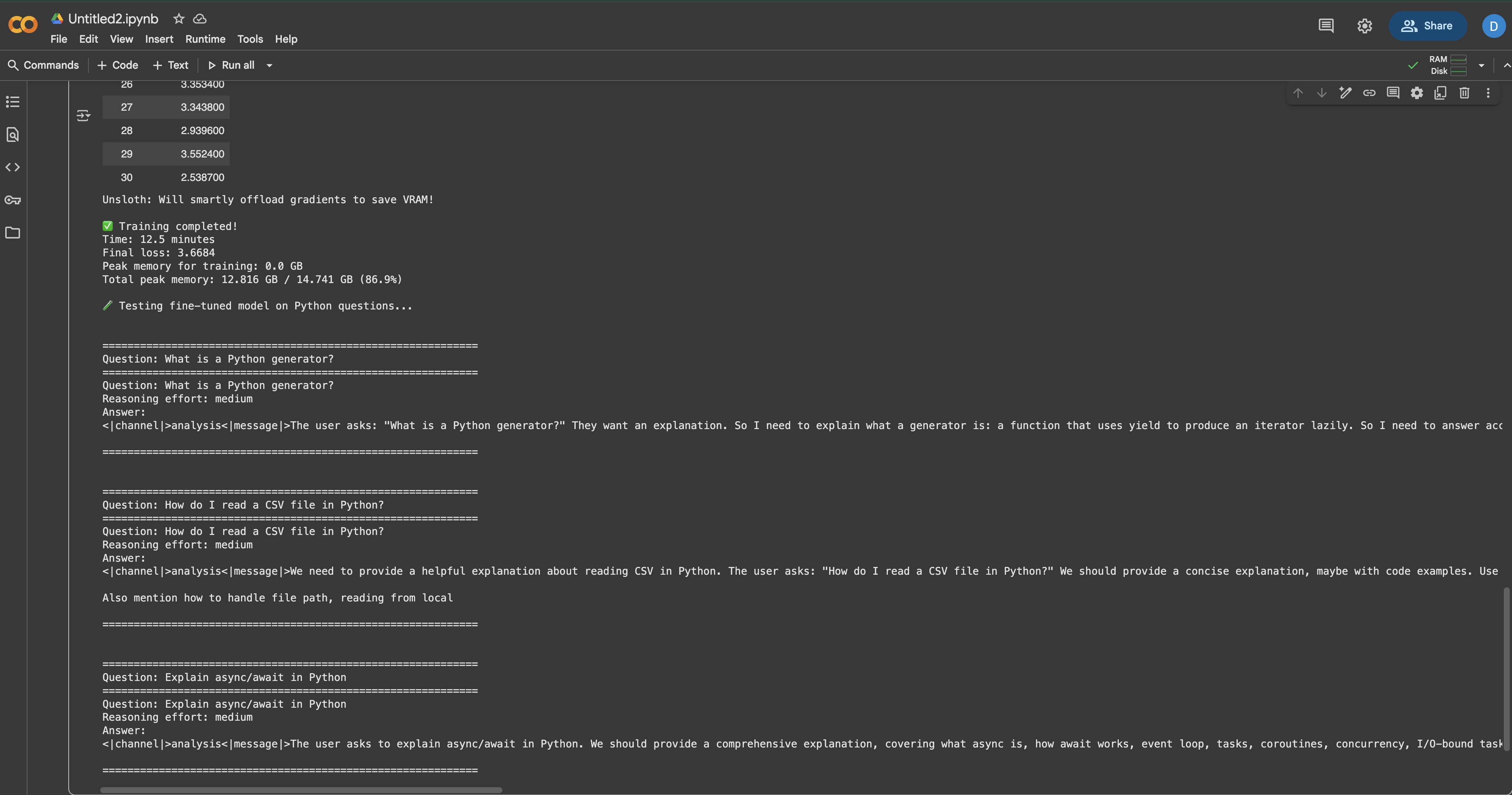
이제 모델이 미세 조정 전보다 더 상세하고 Python 특화된 답변을 제공한다는 점을 확인할 수 있습니다. 응답은 훈련 데이터의 문서 스타일과 기술적 깊이를 반영해야 합니다.
다양한 추론 수준 테스트
추론 노력 수준이 응답에 미치는 영향도 테스트해 보겠습니다:
complex_question = "에라토스테네스의 체를 사용하여 n까지의 모든 소수를 찾는 Python 함수를 작성하세요"
print("="*60)
print("추론 노력 수준 테스트 중")
print("="*60)
for effort in ["low", "medium", "high"]:
print(f"n{'='*40}")
print(f"추론 노력: {effort.upper()}")
print(f"{'='*40}")
_ = test_model(complex_question, reasoning_effort=effort, max_length=300)
print()코드를 실행하면 “low”는 기본 구현을, “medium”은 설명과 코드의 적절한 균형을, “high”는 상세한 설명과 최적화를 제공함을 확인할 수 있습니다.
모델 저장 및 배포
성공적인 미세 조정 후에는 향후 사용을 위해 모델을 저장해야 합니다. 배포 요구 사항에 따라 다음과 같은 여러 옵션이 있습니다:
로컬 저장
import os
# 저장용 디렉터리 생성
save_dir = "gpt-oss-python-expert"
os.makedirs(save_dir, exist_ok=True)
print("모델을 로컬에 저장 중...")
# 옵션 1: LoRA 어댑터만 저장 (작음, ~200MB)
lora_save_dir = f"{save_dir}-lora"
model.save_pretrained(lora_save_dir)
tokenizer.save_pretrained(lora_save_dir)
print(f"✅ LoRA 어댑터 저장됨: {lora_save_dir}")
# 크기 확인
lora_size = sum(
os.path.getsize(os.path.join(lora_save_dir, f))
for f in os.listdir(lora_save_dir))
/ (1024**2)
print(f" Size: {lora_size:.1f} MB")
# 옵션 2: 병합된 모델 저장 (전체 크기, ~20GB)
merged_save_dir = f"{save_dir}-merged"
model.save_pretrained_merged(
merged_save_dir,
tokenizer,
save_method = "merged_16bit" # 옵션: "merged_16bit", "mxfp4"
)
print(f"✅ 병합된 모델이 {merged_save_dir}에 저장되었습니다")Hugging Face Hub에 푸시하기
쉬운 공유 및 배포를 위해 모델을 Hugging Face에 푸시하세요:
from huggingface_hub import login
# Hugging Face 로그인 (토큰 필요)
# 토큰 획득: https://huggingface.co/settings/tokens
login(token="hf_...") # 본인 토큰으로 대체
# LoRA 어댑터 푸시 (공유 권장)
model_name = "your-username/gpt-oss-python-expert-lora"
print(f"{model_name}에 LoRA 어댑터 푸시 중...")
model.push_to_hub(
model_name,
use_auth_token=True,
commit_message="Python 문서 기반 GPT-OSS 미세 조정"
)
tokenizer.push_to_hub(
model_name,
use_auth_token=True)
print(f"✅ 모델 사용 가능 위치: https://huggingface.co/{model_name}")
# 선택적으로 병합된 모델을 푸시합니다 (시간이 더 소요됨)
if False: # 전체 모델을 푸시하려면 True로 설정
merged_model_name = "your-username/gpt-oss-python-expert"
model.push_to_hub_merged(
merged_model_name,
tokenizer,
save_method = "mxfp4", # 4비트 저장 방식으로 용량 감소
use_auth_token=True
)최적화 모델 로드하기
추론 시 모델을 로드하는 방법은 다음과 같습니다:
from unsloth import FastLanguageModel
# 로컬 디렉토리에서 로드
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "gpt-oss-python-expert-lora",
max_seq_length = 1024,
dtype = None,
load_in_4bit = True,
)
# 또는 Hugging Face Hub에서 로드
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "your-username/gpt-oss-python-expert-lora",
max_seq_length = 1024,
dtype = None,
load_in_4bit = True,
)
print("✅ 모델 로드 완료, 추론 준비 완료!")더 나은 결과를 위한 최적화 전략
모델 미세 조정을 최적화하는 데 유용한 몇 가지 전략은 다음과 같습니다:
메모리 최적화 기법
제한된 GPU 메모리로 작업할 때, 다음 기술들은 성공과 OOM(메모리 부족) 오류의 차이를 만들 수 있습니다:
# 1. 기울기 체크포인트링 - 연산량과 메모리 간 교환
model.gradient_checkpointing_enable()
# 2. 데이터가 허용한다면 시퀀스 길이 축소
max_seq_length = 512 # 기존 1024 대신
# 3. 더 많은 누적을 위한 작은 배치 크기 사용
per_device_train_batch_size = 1
gradient_accumulation_steps = 16 # 여전히 효과적인 배치 크기 16
# 4. 메모리 효율적인 어텐션 활성화 (지원 시)
model.config.use_flash_attention_2 = True
# 5. 훈련 중 정기적으로 캐시 정리
import gc
gc.collect()
torch.cuda.empty_cache()훈련 모범 사례
경험상, 다음 관행은 더 나은 파인 튜닝 결과를 가져옵니다:
- 작게 시작하기: 먼저 100개 예제로 테스트하세요. 효과가 있다면 점진적으로 확장하세요.
- 지표 모니터링: 과적합 주의 – 훈련 손실은 감소하지만 검증 손실이 증가하면 조기 종료하세요.
- 데이터 혼합: 특정 도메인 데이터와 일반 지시 데이터 결합하여 재앙적 망각 방지
- 학습률 스케줄: 기본값 2e-4로 시작하되, 실험을 두려워하지 마세요. 소규모 데이터셋에서는 5e-5로도 좋은 결과를 얻었습니다.
- 체크포인트 전략: 최상의 체크포인트에서 복구할 수 있도록 N단계마다 저장하세요:
training_config = SFTConfig(
save_steps = 50,
save_total_limit = 3, # 최상위 3개 체크포인트만 유지
load_best_model_at_end = True,
metric_for_best_model = "loss",
)속도 최적화
훈련 속도 극대화를 위해:
# 더 빠른 훈련을 위해 PyTorch 2.0 컴파일 사용
if hasattr(torch, 'compile'):
model = torch.compile(model)
print("✅ 더 빠른 훈련을 위해 모델 컴파일 완료")
# Ampere GPU(A100, RTX 30xx)에서 TF32 활성화
torch.backends.cuda.matmul.allow_tf32 = True
torch.backends.cudnn.allow_tf32 = True
# 메모리 허용 범위 내에서 더 큰 배치 크기 사용
# 일반적으로 더 큰 배치는 더 빠르게 훈련됨
optimal_batch_size = find_optimal_batch_size(model, max_memory=0.9)생산 환경 배포 옵션
모델이 미세 조정되면 다음과 같은 배포 옵션이 있습니다:
FastAPI를 활용한 빠른 로컬 API
빠른 프로토타이핑을 위해 간단한 API를 생성합니다:
# 저장명: api.py
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
import uvicorn
from unsloth import FastLanguageModel
app = FastAPI()
# 시작 시 모델을 한 번만 로드
model, tokenizer = None, None
@app.on_event("startup")
async def load_model():
global model, tokenizer
model, tokenizer = FastLanguageModel.from_pretrained(
"gpt-oss-python-expert-lora",
max_seq_length = 1024,
load_in_4bit = True,
)
class GenerateRequest(BaseModel):
prompt: str
reasoning_effort: str = "medium"
max_tokens: int = 256
@app.post("/generate")
async def generate(request: GenerateRequest):
if not model:
raise HTTPException(status_code=503, detail="모델이 로드되지 않았습니다")
messages = [{"role": "user", "content": request.prompt}]
inputs = tokenizer.apply_chat_template(
messages,
add_generation_prompt = True,
return_tensors = "pt",
reasoning_effort = request.reasoning_effort,
).to("cuda")
outputs = model.generate(
**inputs,
max_new_tokens = request.max_tokens,
temperature = 0.7,
)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
return {"response": response}
# 실행 명령어: uvicorn api:app --host 0.0.0.0 --port 8000vLLM을 활용한 프로덕션 배포
고처리량 프로덕션 서비스에 vLLM은 탁월한 성능을 제공합니다:
# vLLM 설치
pip install vllm
# 모델 서비스 실행
python -m vllm.entrypoints.openai.api_server
--model gpt-oss-python-expert-merged
--tensor-parallel-size 1
--max-model-len 1024
--dtype float16클라우드 배포 옵션
각 클라우드 플랫폼마다 장점이 있습니다:
- 가장 쉬운 설정 – 푸시하고 배포하기만 하면 됨
- 테스트 및 소규모 운영에 적합
- 자동 확장 기능 지원
- 서버리스 배포에 완벽
- 실제 사용량에 대해서만 지불
- 버스트성 워크로드에 적합
- 24/7 서비스에 가장 비용 효율적
- 환경에 대한 완전한 제어
- 고처리량 애플리케이션에 적합
- AWS 완전 통합을 통한 엔터프라이즈 등급
- 고급 모니터링 및 로깅
- 대규모 프로덕션 배포에 최적
일반적인 문제 해결
Unsloth의 최적화에도 불구하고 일부 문제가 발생할 수 있습니다. 가장 흔한 문제 해결 방법은 다음과 같습니다:
CUDA 메모리 부족 오류
대규모 모델을 미세 조정할 때 가장 흔히 발생하는 문제입니다:
# 해결책 1: 배치 크기 줄이기
training_config = SFTConfig(
per_device_train_batch_size = 1, # 최소 배치 크기
gradient_accumulation_steps = 8, # 누적 처리로 보정)
# 해결책 2: 시퀀스 길이 줄이기
max_seq_length = 512 # 1024 대신
# 해결책 3: 더 공격적인 양자화 사용
model = FastLanguageModel.from_pretrained(
model_name = "unsloth/gpt-oss-20b",
load_in_4bit = True,
use_double_quant = True, # 더 많은 메모리 절약
)
# 해결책 4: 모든 메모리 최적화 활성화
use_gradient_checkpointing = "unsloth"
use_flash_attention = True느린 훈련 속도
훈련 시간이 너무 오래 걸리는 경우:
# Unsloth의 전체 최적화 모음 사용
model = FastLanguageModel.get_peft_model(
model,
use_gradient_checkpointing = "unsloth", # 중요
lora_dropout = 0, # 0은 드롭아웃보다 빠름
bias = "none", # "none"은 바이어스 훈련보다 빠름
use_rslora = False, # 표준 LoRA가 더 빠름)
# 올바른 dtype 사용 확인
torch.set_float32_matmul_precision('medium') # 또는 'high'모델 학습 실패
손실 함수가 감소하지 않는 경우:
- 데이터 형식 확인: 데이터가 GPT-OSS 형식과 정확히 일치하는지 확인
- 응답 마스킹 확인: 응답 데이터만 훈련 중인지 확인
- 학습률 조정: 2e-4 대신 5e-4 또는 1e-4 시도
- 데이터 품질 향상: 저품질 예제 제거
- 데이터 추가: 100개보다 500개 이상의 예제가 일반적으로 더 효과적입니다
일관성 없는 출력
모델이 일관성 없거나 품질이 낮은 출력을 생성하는 경우:
# 더 일관된 출력을 위해 낮은 온도 사용
outputs = model.generate(
temperature = 0.3, # 낮을수록 더 일관됨
top_p = 0.9,
repetition_penalty = 1.1, # 반복 감소
)
# 더 많은 단계로 미세 조정
max_steps = 200 # 기존 60 대신
# 고품질 데이터 필터링 사용
min_response_length = 50 # 기존 30 대신결론
결론
Unsloth의 속도와 최고의 AI 훈련 데이터 기업이 제공하는 고품질 구조화 훈련 데이터를 결합하면 GPT-OSS의 미세 조정이 더 빠르고 쉬워집니다. Bright Data의 AI 솔루션을 사용하면 효과적인 미세 조정에 필요한 신뢰할 수 있는 데이터에 접근할 수 있으므로, 어떤 사용 사례에도 맞춤형 AI 모델을 구축할 수 있습니다.
AI 기반 데이터 추출 전략에 대한 추가 탐구를 위해 다음 자료를 참고하세요:





