
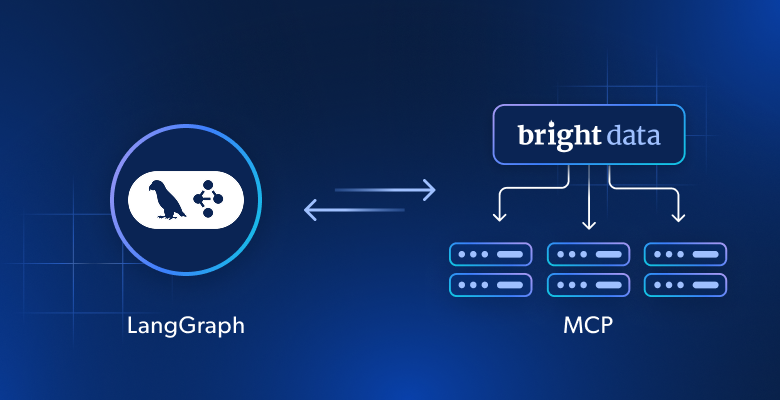
이 가이드는 Bright Data Web MCP를 LangGraph에 연결하여 실시간 웹 데이터를 검색, 스크래핑, 추론할 수 있는 AI 연구 에이전트를 구축하는 방법을 보여줍니다.
이 가이드에서는 다음을 배우게 됩니다:
- 자신의 추론 루프를 제어하는 LangGraph 에이전트 구축
- Bright Data Web MCP 무료 티어를 사용하여 해당 에이전트에 실시간 웹 액세스 권한 부여
- 검색 및 추출 도구를 작동하는 에이전트에 통합하는 방법
- Web MCP 프리미엄 도구를 사용한 브라우저 자동화로 동일한 에이전트 업그레이드
LangGraph 소개
LangGraph는 제어 흐름이 프롬프트나 재시도 내부에 묻히지 않고 명시적이며 쉽게 검사 가능한 LLM 애플리케이션을 구축할 수 있게 합니다. 각 단계는 노드가 되고, 각 전환은 사용자가 정의합니다.
에이전트는 루프로 실행됩니다. LLM 모델은 현재 상태를 읽고 응답하거나 도구를 요청합니다. 도구(웹 검색 등)를 호출하면 결과가 상태에 다시 추가되고 모델이 다시 결정합니다. 충분한 정보를 얻으면 루프가 종료됩니다.
이것이 워크플로우와 에이전트의 핵심 차이점입니다. 워크플로우는 고정된 단계를 따릅니다. 에이전트는 반복합니다: 결정, 실행, 관찰, 재결정. 이 반복 구조는 고정된 시점이 아닌 동적으로 검색이 이루어지는 에이전트 기반 RAG 시스템의 기반과 동일합니다.
LangGraph는 메모리, 도구 호출, 명시적 중지 조건을 통해 이 루프를 구조화하여 구축할 수 있는 방법을 제공합니다. 에이전트가 내리는 모든 결정을 확인하고 중지 시점을 제어할 수 있습니다.
LangGraph와 함께 Bright Data Web MCP를 사용해야 하는 이유
LLM은 추론 능력이 뛰어나지만, 현재 웹에서 일어나는 일을 직접 볼 수는 없습니다. 그들의 지식은 훈련 시점에 멈춰 있습니다. 따라서 에이전트가 최신 데이터가 필요할 때, 모델은 추측으로 그 공백을 메우려는 경향이 있습니다.
Bright Data Web MCP는 검색 및 추출 도구를 통해 에이전트가 실시간 웹 데이터에 직접 접근할 수 있게 합니다. 추측 대신 모델은 실제 최신 출처를 기반으로 답변을 생성합니다.
LangGraph는 이러한 접근을 에이전트 환경에서 활용 가능하게 합니다. 에이전트는 충분한 정보를 확보했는지, 추가 데이터 수집이 필요한지 판단해야 합니다.
Web MCP를 사용하면 에이전트가 질문에 답변할 때 기억에 의존하지 않고 실제로 사용한 출처를 직접 지목할 수 있습니다. 이는 출력 결과의 신뢰성과 디버깅을 용이하게 합니다.
Bright Data Web MCP를 LangGraph 에이전트에 연결하는 방법
LangGraph는 에이전트 루프를 제어합니다. Bright Data Web MCP는 에이전트에게 실시간 웹 데이터 접근 권한을 부여합니다. 남은 과제는 복잡성을 추가하지 않고 이 둘을 연결하는 것입니다.
이 섹션에서는 최소한의 Python 프로젝트를 설정하고, Web MCP 서버에 연결하며, LangGraph 에이전트에 해당 도구를 노출하는 방법을 다룹니다.
필수 조건
이 튜토리얼을 따라하려면 다음이 필요합니다:
- Python 버전 3.11 이상
- Bright Data 계정
- OpenAI 플랫폼 계정
1단계: OpenAI API 키 생성
에이전트가 추론하고 도구 사용 시점을 결정하려면 LLM API 키가 필요합니다. 이 설정에서는 해당 키가 OpenAI에서 제공됩니다.
OpenAI 플랫폼 대시보드에서 API 키를 생성하세요. “API 키” 페이지를 열고 “새 비밀 키 생성”을 클릭하세요.
새 창이 열리면 키를 설정할 수 있습니다.
기본값을 유지하고, 선택적으로 키 이름을 지정한 후 “Create secret key”를 클릭하세요.
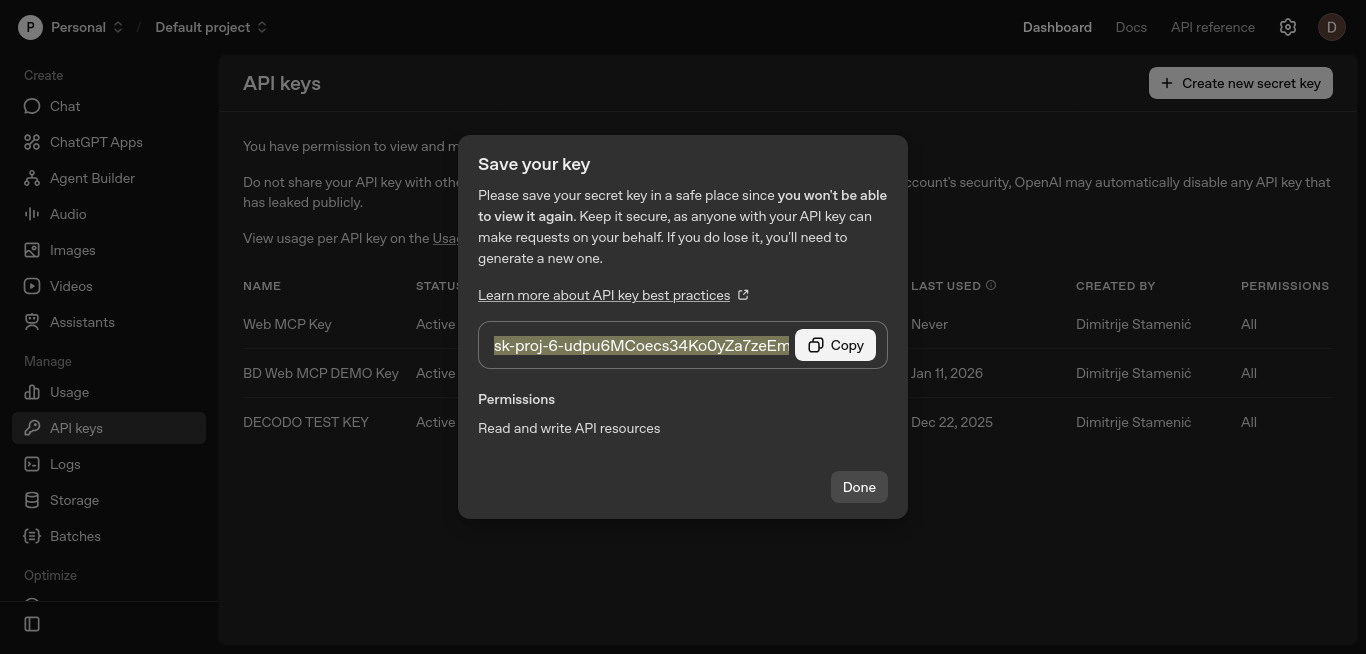
키를 복사하여 안전하게 보관하세요. 다음 단계에서 OPENAI_API_KEY 환경 변수에 이 키를 추가할 것입니다.
이 키를 통해 LangGraph는 LLM 모델을 호출할 수 있으며, 이 모델은 웹 MCP 도구를 언제 호출할지 결정할 수 있습니다.
2단계: Bright Data API 토큰 생성
다음으로 Bright Data의 API 토큰이 필요합니다. 이 토큰은 에이전트를 Web MCP 서버에 인증하고 검색 및 스크래핑 도구를 호출할 수 있게 합니다.
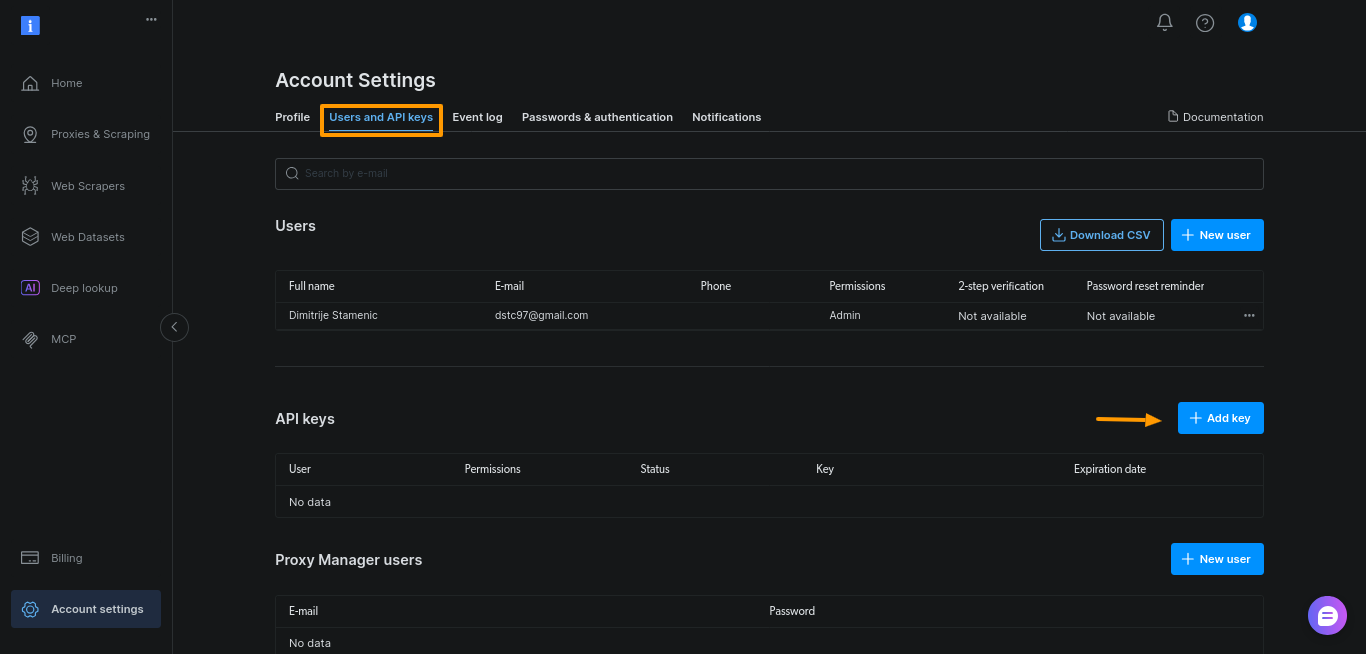
Bright Data 대시보드에서 토큰을 생성하세요. “계정 설정”을 열고 “사용자 및 API 키”로 이동한 후 “+ 키 추가”를 클릭하세요.
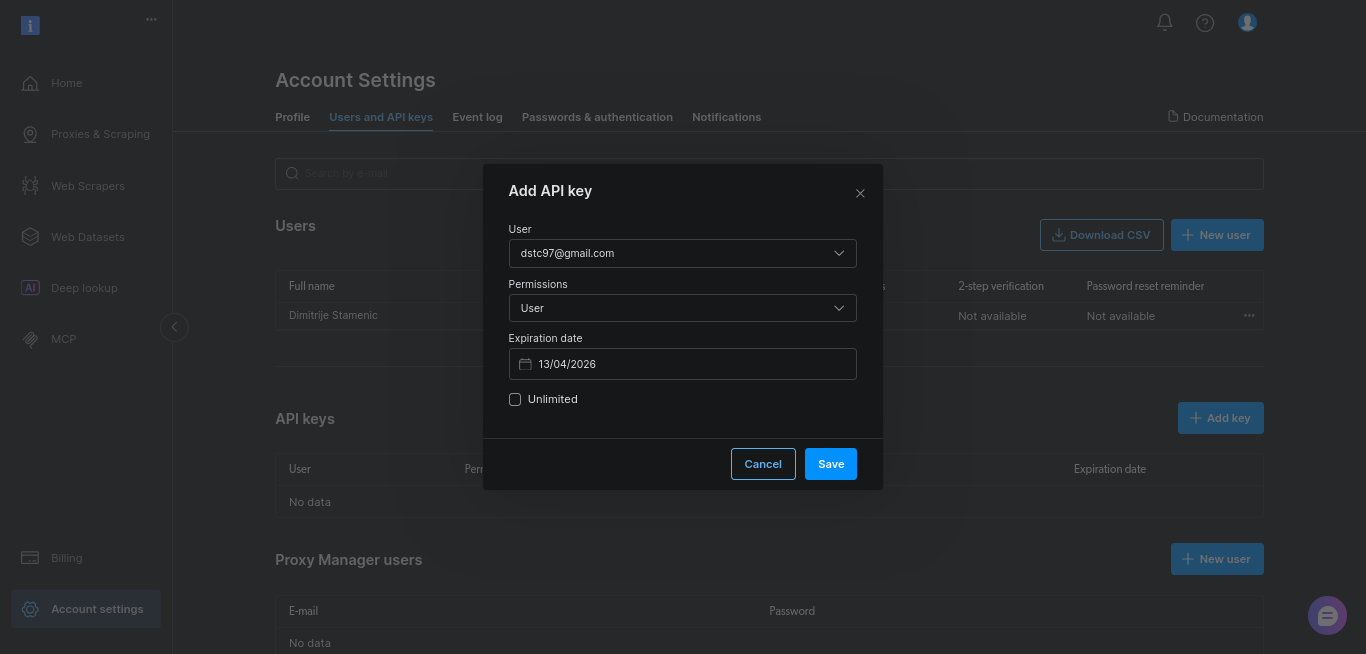
이 가이드에서는 기본값을 유지한 채 “저장”을 클릭하세요:
키를 복사하여 안전하게 보관하세요. 다음 단계에서 BRIGHTDATA_TOKEN 환경 변수에 이 키를 추가할 것입니다.
이 토큰은 에이전트가 Web MCP를 통해 실시간 웹 데이터에 접근할 수 있는 권한을 부여합니다.
단계 #3: 간단한 Python 프로젝트 설정
새 프로젝트 디렉터리와 가상 환경 생성:
mkdir webmcp-langgraph-demo
cd webmcp-langgraph-demo
python3 -m venv webmcp-langgraph-venv 가상 환경 활성화:
source webmcp-langgraph-venv/bin/activate이렇게 하면 종속성이 격리되어 다른 프로젝트와의 충돌을 방지할 수 있습니다. 환경이 활성화된 상태에서 필요한 종속성만 설치하세요. 이는 Bright Data의 LangChain 및 LangGraph 통합 전반에 걸쳐 사용되는 동일한 MCP 어댑터이므로 에이전트가 성장함에 따라 설정은 일관성을 유지합니다:
pip install
langgraph
langchain
langchain-openai
langchain-mcp-adapters
python-dotenvAPI 키를 저장할 .env 파일을 생성하세요:
touch .envOpenAI API 키와 Bright Data 키를 .env 파일에 붙여넣으세요:
OPENAI_API_KEY="your-openai-api-key"
BRIGHTDATA_TOKEN="your-brightdata-api-key"OPENAI_API_KEY 이름은 변경하지 마세요. LangChain이 자동으로 읽으므로 코드에서 키를 전달할 필요가 없습니다.
마지막으로 단일 Python 파일을 생성하고 에이전트의 역할, 경계, 도구 사용 규칙을 정의하는 시스템 프롬프트를 설정하세요:
# webmcp-langgraph-demo.py 파일
SYSTEM_PROMPT = """당신은 웹 리서치 어시스턴트입니다.
작업:
- Google 검색 결과와 몇 가지 출처를 활용해 사용자의 주제를 조사하세요.
- 6~10개의 간단한 글머리 기호 목록을 반환하세요.
- 사용한 URL만 포함된 짧은 "출처:" 목록을 추가하세요.
도구 사용 방법:
- 먼저 검색 도구를 호출하여 Google 결과를 가져옵니다.
- 신뢰할 수 있는 결과 3~5개를 선택하여 스크래핑합니다.
- 스크래핑에 실패하면 다른 결과를 시도합니다.
제약 조건:
- 최대 5개의 출처만 사용합니다.
- 공식 문서나 1차 자료를 우선합니다.
- 신속하게 처리합니다: 심층 크롤링은 금지합니다.
"""4단계: LangGraph 노드 설정
이것이 에이전트의 핵심입니다. 이 루프를 이해하면 나머지는 구현 세부사항에 불과합니다.
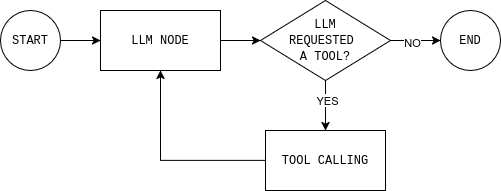
코드를 작성하기 전에 구축할 에이전트 루프를 이해하는 것이 도움이 됩니다. 다이어그램은 간단한 LangGraph 에이전트 루프를 보여줍니다: 모델은 현재 상태를 읽고, 외부 데이터가 필요한지 결정하며, 필요한 경우 도구를 호출하고, 결과를 관찰한 후 답변할 수 있을 때까지 반복합니다.
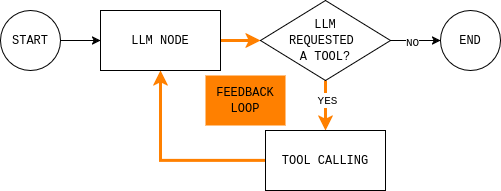
이 루프를 구현하려면 두 개의 노드(LLM 노드와 도구 실행 노드)와 계속 진행할지 종료하고 최종 응답을 제공할지 결정하는 라우팅 함수가 필요합니다.
LLM 노드는 현재 대화 상태와 시스템 규칙을 모델에 전송하고 응답 또는 도구 호출을 반환합니다. 핵심 세부 사항은 모든 모델 응답이 MessagesState에 추가되어 후속 단계에서 모델의 결정 내용과 이유를 확인할 수 있다는 점입니다.
def make_llm_call_node(llm_with_tools):
async def llm_call(state: MessagesState):
messages = [SystemMessage(content=SYSTEM_PROMPT)] + state["messages"]
ai_message = await llm_with_tools.ainvoke(messages)
return {"messages": [ai_message]}
return llm_call도구 실행 노드는 모델이 요청한 도구를 실행하고 그 출력을 관측값으로 기록합니다. 이러한 분리를 통해 추론은 모델에서, 실행은 코드에서 이루어집니다.
def make_tool_node(tools_by_name: dict):
async def tool_node(state: MessagesState):
last_ai_msg = state["messages"][-1]
tool_results = []
for tool_call in last_ai_msg.tool_calls:
tool = tools_by_name.get(tool_call["name"])
if not tool:
tool_results.append(
ToolMessage(
content=f"Tool not found: {tool_call['name']}",
tool_call_id=tool_call["id"],
)
)
continue
# MCP 도구는 일반적으로 비동기적입니다
observation = (
await tool.ainvoke(tool_call["args"])
if hasattr(tool, "ainvoke")
else tool.invoke(tool_call["args"])
)
tool_results.append(
ToolMessage(
content=str(observation),
tool_call_id=tool_call["id"],
)
)
return {"messages": tool_results}
return tool_node마지막으로 라우팅 규칙은 그래프가 계속 순환할지 중단할지를 결정합니다. 실제로는 단 하나의 질문에 답합니다: 모델이 도구를 요청했는가?
def should_continue(state: MessagesState) -> Literal["tool_node", END]:
last_message = state["messages"][-1]
if getattr(last_message, "tool_calls", None):
return "tool_node"
return END단계 #5: 모든 것을 연결하기
이 단계의 모든 작업은 main() 함수 내에서 수행됩니다. 여기서 자격 증명을 구성하고, Web MCP에 연결하고, 도구를 바인딩하고, 그래프를 구축하고, 쿼리를 실행합니다.
환경 변수를 로드하고 BRIGHTDATA_TOKEN을 읽는 것으로 시작합니다. 이렇게 하면 자격 증명을 소스 코드에 포함하지 않고 토큰이 누락된 경우 빠르게 실패합니다.
# .env에서 환경 변수 로드
load_dotenv()
# Bright Data 토큰 읽기
bd_token = os.getenv("BRIGHTDATA_TOKEN")
if not bd_token:
raise ValueError("BRIGHTDATA_TOKEN 누락")다음으로 MultiServerMCPClient를 생성하고 Web MCP 엔드포인트를 지정합니다. 이 클라이언트는 에이전트를 실시간 웹 데이터에 연결합니다.
# Bright Data 웹 MCP 서버에 연결
client = MultiServerMCPClient({
"bright_data": {
"url": f"https://mcp.brightdata.com/mcp?token={bd_token}",
"transport": "streamable_http",
}
})참고: 웹 MCP는 기본 전송 프로토콜로 스트리밍 가능 HTTP(Streamable HTTP)를 사용합니다. 이는 기존 SSE 기반 설정 대비 도구 스트리밍 및 재시도를 간소화합니다. 따라서 대부분의 최신 MCP 통합은 이 전송 방식을 표준으로 채택합니다.
그런 다음 사용 가능한 MCP 도구를 가져와 이름별로 인덱싱합니다. 도구 실행 노드는 이 맵을 사용하여 호출을 라우팅합니다.
# 사용 가능한 모든 MCP 도구(검색, 스크래핑 등) 가져오기
tools = await client.get_tools()
tools_by_name = {tool.name: tool for tool in tools}LLM을 초기화하고 MCP 도구를 바인딩합니다. 이를 통해 도구 호출이 가능해집니다.
# LLM 초기화 및 MCP 도구 호출 허용
llm = ChatOpenAI(model="gpt-4.1-mini", temperature=0)
llm_with_tools = llm.bind_tools(tools)이제 앞서 소개한 LangGraph 에이전트를 구축합니다. StateGraph(MessagesState)를 생성하고, LLM 및 도구 노드를 추가한 후 루프에 맞게 에지를 연결합니다.
# LangGraph 에이전트 구축
graph = StateGraph(MessagesState)
graph.add_node("llm_call", make_llm_call_node(llm_with_tools))
graph.add_node("tool_node", make_tool_node(tools_by_name))
# 그래프 흐름:
# START → LLM → (도구?) → LLM → END
graph.add_edge(START, "llm_call")
graph.add_conditional_edges("llm_call", should_continue, ["tool_node", END])
graph.add_edge("tool_node", "llm_call")
agent = graph.compile()마지막으로 실제 프롬프트로 에이전트를 실행합니다. 무한 루프를 방지하기 위해 recursion_limit를 설정하세요.
# 예시 연구 질의
topic = "Bright Data Web MCP란 무엇인가요?"
# 에이전트 실행
result = await agent.invoke(
{
"messages": [
HumanMessage(content=f"이 주제를 연구하세요:n{topic}")
]
},
# 무한 루프 방지
config={"recursion_limit": 12})
# 최종 응답 출력
print(result["messages"][-1].content)main()에서 실행하면 다음과 같습니다:
async def main():
# .env 파일에서 환경 변수 로드
load_dotenv()
# Bright Data 토큰 읽기
bd_token = os.getenv("BRIGHTDATA_TOKEN")
if not bd_token:
raise ValueError("BRIGHTDATA_TOKEN 누락")
# Bright Data Web MCP 서버에 연결
client = MultiServerMCPClient({
"bright_data": {
"url": f"https://mcp.brightdata.com/mcp?token={bd_token}",
"transport": "streamable_http",
}
})
# 사용 가능한 모든 MCP 도구(검색, 스크래핑 등) 가져오기
tools = await client.get_tools()
tools_by_name = {tool.name: tool for tool in tools}
# LLM 초기화 및 MCP 도구 호출 허용
llm = ChatOpenAI(model="gpt-4.1-mini", temperature=0)
llm_with_tools = llm.bind_tools(tools)
# LangGraph 에이전트 구축
graph = StateGraph(MessagesState)
graph.add_node("llm_call", make_llm_call_node(llm_with_tools))
graph.add_node("tool_node", make_tool_node(tools_by_name))
# 그래프 흐름:
# START → LLM → (도구?) → LLM → END
graph.add_edge(START, "llm_call")
graph.add_conditional_edges("llm_call", should_continue, ["tool_node", END])
graph.add_edge("tool_node", "llm_call")
agent = graph.compile()
# 예시 연구 질의
topic = "모델 컨텍스트 프로토콜(MCP)이란 무엇이며 LangGraph와 어떻게 사용되나요?"
# 에이전트 실행
result = await agent.invoke(
{
"messages": [
HumanMessage(content=f"이 주제를 연구하세요:n{topic}")
]
},
# 무한 루프 방지
config={"recursion_limit": 12}
)
# 최종 응답 출력
print(result["messages"][-1].content)참고: 이 에이전트의 완전한 실행 가능 버전은 이 GitHub 저장소에서 확인할 수 있습니다. 저장소를 복제한 후 API 키를
.env파일에 추가하고 스크립트를 실행하면 LangGraph + Web MCP 루프의 전체 동작을 확인할 수 있습니다.
브라우저 자동화로 스크래핑 문제를 해결하는 Web MCP 유료 도구 활용
서버 렌더링 페이지에서 벗어나 자바스크립트 중심 또는 상호작용 기반 사이트로 넘어가면 정적 스크래핑은 작동하지 않습니다. 이는 원시 HTML 대신 실제 브라우저가 필요한 시점을 결정하는 정적 대 동적 분할과 동일합니다.
또한 실제 사용자 상호작용(무한 스크롤, 버튼 기반 페이지네이션)이 필요한 페이지에서는 실패하며, 이때 브라우저 자동화가 유일한 신뢰할 수 있는 옵션이 됩니다.
Web MCP는 브라우저 자동화 및 고급 스크래핑을 MCP 도구로 제공합니다. 에이전트에게는 단순한 도구가 부족할 때 추가 옵션으로만 인식됩니다.
Web MCP에서 브라우저 자동화 도구 활성화
Web MCP 브라우저 자동화 도구는 무료 계정에 포함되지 않으므로, 먼저 왼쪽 사이드바의 “청구” 메뉴에서 Bright Data 계정에 자금을 충전해야 합니다.
다음으로 MCP 설정에서 브라우저 자동화 도구 그룹을 활성화하세요. “MCP” 섹션을 열고 “편집”을 클릭합니다:
이제 “브라우저 자동화”를 활성화하고 “계속하여 구성”을 클릭하세요:
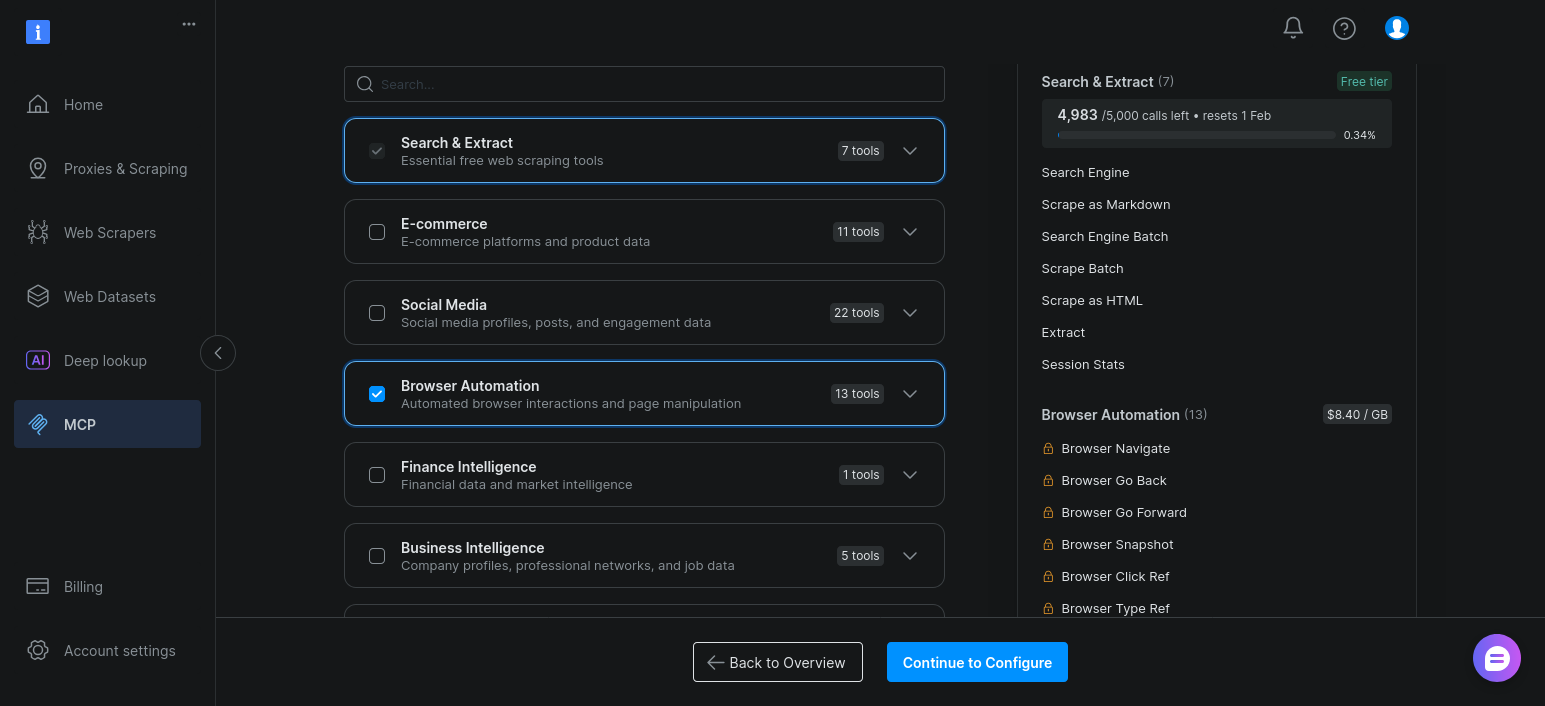
기본 설정을 유지한 상태에서 “복사 및 닫기”를 클릭하세요:
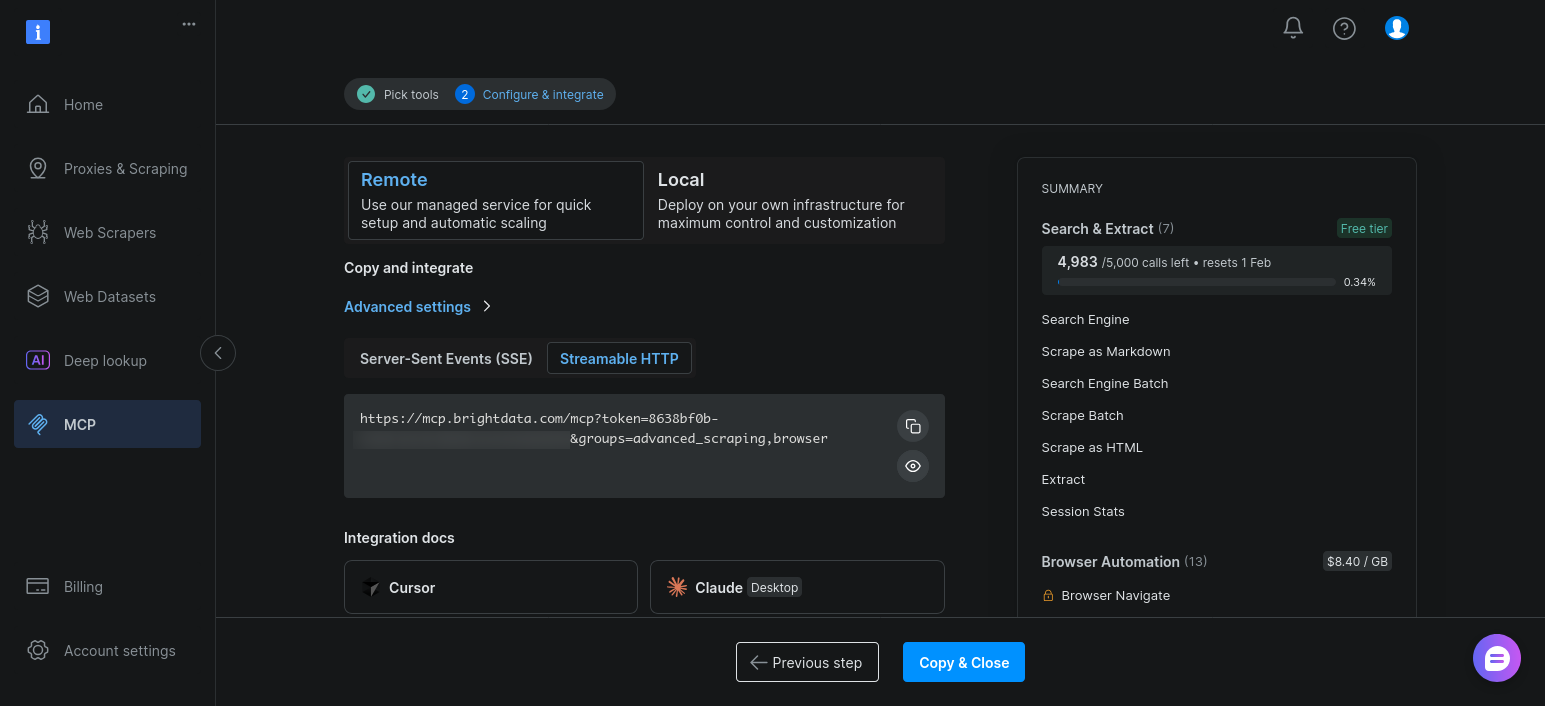
활성화되면 에이전트가 client.get_tools()를 호출할 때 검색 및 스크래핑 도구와 함께 이 도구들이 표시됩니다.
기존 LangGraph 에이전트를 브라우저 자동화 도구용으로 확장하기
핵심은 간단합니다: LangGraph 아키텍처를 변경하지 않습니다.
에이전트는 이미 다음과 같은 기능을 수행합니다:
- 도구를 동적으로 탐색합니다
- 모델에 바인딩
- 동일한
LLM → 도구 → 관찰루프를 통해 실행을 라우팅합니다
브라우저 자동화 도구 추가 시 변경되는 것은 사용 가능한 도구 목록뿐입니다.
실제 변경 사항은 MCP 연결 URL뿐입니다. 기본 엔드포인트 연결 대신 고급 스크래핑 및 브라우저 자동화 도구 그룹을 요청하세요:
# 고급 스크래핑 및 브라우저 자동화 활성화
"url": f"https://mcp.brightdata.com/mcp?token={bd_token}&groups=advanced_scraping,browser"스크립트를 재실행하면 client.get_tools() 가 추가 브라우저 기반 도구를 반환합니다. 정적 스크래핑 결과가 빈약하거나 불완전할 때 모델이 이를 선택할 수 있습니다.
결론
LangGraph는 상태, 라우팅, 중지 조건을 제어할 수 있는 명확하고 검사 가능한 에이전트 루프를 제공합니다. Web MCP는 스크래핑 로직을 프롬프트나 코드에 포함시키지 않고도 해당 루프가 실제 웹 데이터에 안정적으로 접근할 수 있게 합니다.
결과적으로 관심사가 명확하게 분리됩니다. 모델은 무엇을 할지 결정합니다. LangGraph는 루프가 어떻게 실행될지 결정합니다. Bright Data는 검색, 추출 및 차단 문제를 처리합니다. 무언가 실패할 경우, 어디서 왜 실패했는지 확인할 수 있습니다.
동등하게 중요한 점은, 이 설정으로 인해 막다른 길에 갇히지 않는다는 것입니다. 빠른 연구를 위한 기본 Web MCP 도구로 시작하여 정적 스크래핑이 중단될 때 유료 Web MCP 도구로 전환할 수 있습니다. 에이전트 아키텍처는 동일하게 유지됩니다. 단지 에이전트의 접근 범위가 확장될 뿐입니다.





