

이 튜토리얼에서는 다음을 배웁니다:
- AI 기반 LinkedIn 구직 도우미의 작동 방식
- Bright Data의 LinkedIn 채용 정보 데이터를 OpenAI 기반 워크플로와 통합하여 구축하는 방법.
- 이 워크플로를 개선하고 확장하여 강력한 구직 지원 도구를 만드는 방법.
최종 프로젝트 파일은 여기에서 확인할 수 있습니다.
자, 시작해 보겠습니다!
LinkedIn 구직 AI 어시스턴트 워크플로 설명
우선, LinkedIn 채용 공고 데이터에 접근하지 않고서는 LinkedIn 구직 AI 어시스턴트를 구축할 수 없습니다. 바로 여기서 Bright Data가 활용됩니다!
LinkedIn Jobs Scraper를 사용하면 웹 스크래핑을 통해 LinkedIn의 공개 채용 공고 데이터를 가져올 수 있습니다. LinkedIn Jobs 포털에서 검색하는 것과 동일한 경험을 제공합니다. 다만 웹 페이지 대신 구조화된 채용 데이터가 JSON 또는 CSV 형식으로 직접 제공됩니다.
이 데이터를 바탕으로 AI에게 자신의 기술과 원하는 직위를 기준으로 각 채용 공고를 평가하도록 요청할 수 있습니다. 대략적으로 말하면, 이것이 LinkedIn 채용 AI 어시스턴트가 여러분을 위해 수행하는 작업입니다.
기술적 단계
LinkedIn 채용 AI 워크플로우 구현에 필요한 단계는 다음과 같습니다:
- CLI 인수 로드: 명령줄 인수를 파싱하여 런타임 매개변수를 가져옵니다. 이를 통해 코드 변경 없이 유연한 실행과 손쉬운 맞춤 설정이 가능합니다.
- 환경 변수 로드: 환경 변수에서 OpenAI 및 Bright Data API 키를 불러옵니다. 이 AI 워크플로를 구동하는 타사 통합 서비스에 연결하는 데 필요합니다.
- 구성 파일 로드: 구직 검색 매개변수, 후보자 프로필 세부정보, 원하는 직무 설명이 포함된 JSON 구성 파일을 읽습니다. 이 구성 정보는 직무 검색 및 AI 점수 산정을 안내합니다.
- LinkedIn에서 일자리 수집: LinkedIn Jobs Scraper API를 통해 구성에 따라 필터링된 일자리 목록을 가져옵니다.
- AI를 통한 직무 평가: 각 배치의 채용 공고를 OpenAI로 전송합니다. AI는 귀하의 프로필과 원하는 직무를 기준으로
0에서100점까지점수를 매깁니다. 또한 각 점수에 대한 간단한 설명을 추가하여 매칭 품질을 이해하는 데 도움을 줍니다. - AI 점수와 코멘트가 포함된 채용 정보 확장: AI가 생성한 점수와 코멘트를 원본 채용 공고에 병합하여, 각 채용 기록을 이러한 새로운 AI 생성 필드로 보강합니다.
- 점수화된 채용 정보 데이터 내보내기: 보강된 채용 정보를 CSV 파일로 내보내 추가 분석 및 처리를 수행합니다.
- 상위 직무 매칭 결과 출력: 주요 세부 정보와 함께 상위 직무 매칭 결과를 콘솔에 직접 표시하여 가장 관련성 높은 기회를 즉시 파악할 수 있도록 합니다.
이 AI 워크플로를 Python으로 구현하는 방법을 확인하세요!
OpenAI와 Bright Data를 활용하여 LinkedIn 구직 AI 워크플로우 구축 방법
이 튜토리얼에서는 LinkedIn에서 일자리를 찾는 데 도움이 되는 AI 워크플로우 구축 방법을 배웁니다. LinkedIn 채용 데이터는 Bright Data에서 제공되며, AI 기능은 OpenAI가 제공합니다. 다른 대규모 언어 모델(LLM)도 사용할 수 있습니다.
이 섹션을 마치면 명령줄에서 실행 가능한 완전한 Python AI 워크플로우를 갖게 됩니다. 이 워크플로우는 최적의 LinkedIn 채용 공고를 식별하여 지치고 힘든 구직 과정에서 시간과 노력을 절약해 줍니다.
LinkedIn 구직 AI 어시스턴트를 만들어 보겠습니다!
필수 조건
이 튜토리얼을 따라하려면 다음이 준비되어 있어야 합니다:
- 로컬에 설치된 Python 3.8 이상 (최신 버전 사용 권장).
- Bright Data API 키.
- OpenAI API 키.
Bright Data API 키가 아직 없다면 Bright Data 계정을 생성하고 공식 설정 가이드를 따르세요. 마찬가지로 공식 OpenAI 지침을 따라 OpenAI API 키를 획득하세요.
단계 #0: Python 프로젝트 설정
터미널을 열고 LinkedIn 구직 AI 어시스턴트를 위한 새 디렉터리를 생성하세요:
mkdir linkedin-job-hunting-ai-assistant/linked-in-job-hunting-ai-assistant 폴더에는 AI 워크플로우의 모든 Python 코드가 저장됩니다.
다음으로 프로젝트 디렉토리로 이동하여 가상 환경을 초기화합니다:
cd linkedin-job-hunting-ai-assistant/
python -m venv venv이제 선호하는 Python IDE에서 프로젝트를 엽니다. Python 확장 프로그램이 설치된 Visual Studio Code 또는 PyCharm Community Edition을 권장합니다.
프로젝트 폴더 내에서 assistant.py라는 새 파일을 생성하세요. 디렉터리 구조는 다음과 같아야 합니다:
linkedin-job-hunting-ai-assistant/
├── venv/
└── assistant.py터미널에서 가상 환경을 활성화하세요. Linux 또는 macOS에서는 다음 명령을 실행합니다:
source venv/bin/activateWindows에서는 다음 명령을 실행하세요:
venv/Scripts/activate다음 단계에서는 필요한 Python 패키지 설치 과정을 안내합니다. 활성화된 가상 환경에서 모든 패키지를 즉시 설치하려면 다음 명령어를 실행하세요:
pip install python-dotenv requests openai pydantic특히 필요한 라이브러리는 다음과 같습니다:
python-dotenv:.env파일에서 환경 변수를 불러와 API 키를 안전하게 관리할 수 있게 합니다.pydantic: 구성 파일을 검증하고 구조화된 Python 객체로 파싱하는 데 도움을 줍니다.requests: Bright Data와 같은 API 호출 및 데이터 수집을 위한 HTTP 요청을 처리합니다.openai: AI 작업 점수를 매기기 위해 OpenAI의 언어 모델과 상호작용할 수 있는 OpenAI 클라이언트를 제공합니다.
참고: 본 튜토리얼은 언어 모델 제공자로 OpenAI를 사용하므로 openai 라이브러리를 설치합니다. 다른 LLM 제공자를 사용할 계획이라면 해당 SDK 또는 종속성을 설치해야 합니다.
이제 준비가 완료되었습니다! OpenAI와 Bright Data를 사용한 AI 워크플로우 구축을 위한 Python 개발 환경이 준비되었습니다.
1단계: CLI 인수 로드
LinkedIn 구직 AI 스크립트에는 몇 가지 인수가 필요합니다. 코드를 변경하지 않고도 재사용 가능하고 사용자 정의할 수 있도록 CLI를 통해 인수를 읽어와야 합니다.
구체적으로 다음과 같은 CLI 인수가 필요합니다:
--config_file: 구직 검색 매개변수, 후보자 프로필 세부정보, 원하는 직무 설명이 포함된 JSON 구성 파일의 경로. 기본값은config.json입니다.--batch_size: AI에 한 번에 점수를 매기도록 보낼 채용 공고 수. 기본값은5개입니다.--jobs_number: Bright Data LinkedIn Jobs Scraper가 반환해야 하는 최대 구인 목록 수. 기본값은20개입니다.--output_csv: AI 점수와 코멘트가 포함된 보강된 채용 데이터가 담긴 출력 CSV 파일 이름입니다. 기본값은jobs_scored.csv입니다.
다음 함수를 사용하여 명령줄 인터페이스에서 이러한 인수를 읽습니다:
def parse_cli_args():
# 구성 및 런타임 옵션에 대한 명령줄 인수 파싱
parser = argparse.ArgumentParser(description="LinkedIn 구직 어시스턴트")
parser.add_argument("--config_file", type=str, default="config.json", help="구성 JSON 파일 경로")
parser.add_argument("--jobs_number", type=int, default=20, help="Bright Data Scraper API가 반환하는 일자리 수 제한")
parser.add_argument("--batch_size", type=int, default=5, help="각 배치에서 평가할 일자리 수")
parser.add_argument("--output_csv", type=str, default="jobs_scored.csv", help="출력 CSV 파일명")
return parser.parse_args()Python 표준 라이브러리에서 argparse를 반드시 임포트하세요:
import argparse좋습니다! 이제 CLI에서 인수를 사용할 수 있습니다.
2단계: 환경 변수 로드
스크립트가 환경 변수에서 비밀 정보를 읽도록 구성하세요. 환경 변수 로딩을 단순화하려면 python-dotenv 패키지를 사용하세요. 가상 환경을 활성화한 상태에서 다음 명령어로 설치하세요:
pip install python-dotenv다음으로, assistant.py 파일에서 라이브러리를 임포트하고 load_dotenv() 를 호출하여 환경 변수를 로드하세요:
from dotenv import load_dotenv
load_dotenv()이제 어시스턴트가 로컬 .env 파일에서 변수를 읽을 수 있습니다. 따라서 프로젝트 디렉토리 루트에 .env 파일을 추가하세요:
linkedin-job-hunting-ai-assistant/
├── venv/
├── .env # <-----------
└── assistant.py.env 파일을 열고 OPENAI_API_KEY 및 BRIGHT_DATA_API_KEY 환경 변수를 추가하세요:
OPENAI_API_KEY="<YOUR_OPENAI_API_KEY>"
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"<YOUR_OPENAI_API_KEY> 자리 표시자를 실제 OpenAI API 키로 대체하세요. 마찬가지로 <YOUR_BRIGHT_DATA_API_KEY> 자리 표시자를 Bright Data API 키로 대체하세요.
그런 다음, 해당 두 환경 변수를 로드하기 위해 스크립트에 다음 함수를 추가하세요:
def load_env_vars():
# 환경 변수에서 필요한 API 키를 읽고 존재 여부를 확인
openai_api_key = os.getenv("OPENAI_API_KEY")
brightdata_api_key = os.getenv("BRIGHT_DATA_API_KEY")
missing = []
if not openai_api_key:
missing.append("OPENAI_API_KEY")
if not brightdata_api_key:
missing.append("BRIGHT_DATA_API_KEY")
if missing:
raise EnvironmentError(
f"필수 환경 변수가 누락되었습니다: {', '.join(missing)}n"
"해당 변수를 .env 파일이나 환경 변수에 설정해 주세요."
)
return openai_api_key, brightdata_api_keyPython 표준 라이브러리에서 필요한 임포트를 추가하세요:
import os훌륭합니다! 이제 환경 변수를 사용하여 타사 통합 비밀 정보를 안전하게 로드했습니다.
3단계: 구성 파일 로드
이제 관심 있는 직무를 어시스턴트에게 프로그래밍 방식으로 알려야 합니다. 정확한 결과를 얻으려면 어시스턴트가 귀하의 경력 및 구직 유형도 파악해야 합니다.
해당 정보를 코드에 직접 하드코딩하지 않으려면 JSON 구성 파일에서 읽어오는 것이 합리적입니다. 구체적으로 이 파일에는 다음 내용이 포함되어야 합니다:
location: 구직을 원하는 지리적 위치. 구인 목록이 수집될 주요 지역을 정의합니다.keyword: “Python Developer”처럼 원하는 직무명이나 역할과 관련된 특정 단어나 구. 정확한 일치를 강제하려면 따옴표를 사용하세요.country: 특정 국가로 구직 검색을 제한하기 위한 두 글자 국가 코드(예: 미국은US, 프랑스는FR).time_range: 최근 또는 관련성 높은 채용 공고를 필터링하기 위한 게시 기간(예:지난 주,지난 달등).job_type:정규직,파트타임등 고용 형태로 필터링합니다.경력 수준: 요구되는 전문 경력 수준(예:신입,경력직등).remote: 근무지 모드(예:원격,현장,하이브리드)에 따라 채용 공고를 필터링합니다.company: 특정 기업 또는 고용주의 채용 공고로 검색을 집중합니다.selective_search: 활성화 시, 지정된 키워드가 포함되지 않은 제목의 채용 공고를 제외하여 더 타겟팅된 결과를 생성합니다.jobs_to_not_include: 검색 결과에서 제외할 특정 채용 공고 ID 목록으로, 중복 또는 원하지 않는 게시물을 제거하는 데 유용합니다.location_radius: 지정된 위치 주변으로 검색 범위를 확장할 거리(근처 지역 포함)를 정의합니다.profile_summary: 귀하의 전문 프로필 요약입니다. 이 정보는 AI가 각 채용 공고가 귀하와 얼마나 잘 맞는지를 평가하는 데 사용됩니다.desired_job_summary: 구직자가 원하는 직무 유형에 대한 간략한 설명으로, AI가 적합도에 따라 채용 공고를 평가하는 데 도움이 됩니다.
이들은 Bright Data LinkedIn 채용 공고 “키워드 발견” API (LinkedIn Jobs Scraper 솔루션의 일부)에서 요구하는 인자와 정확히 일치합니다:
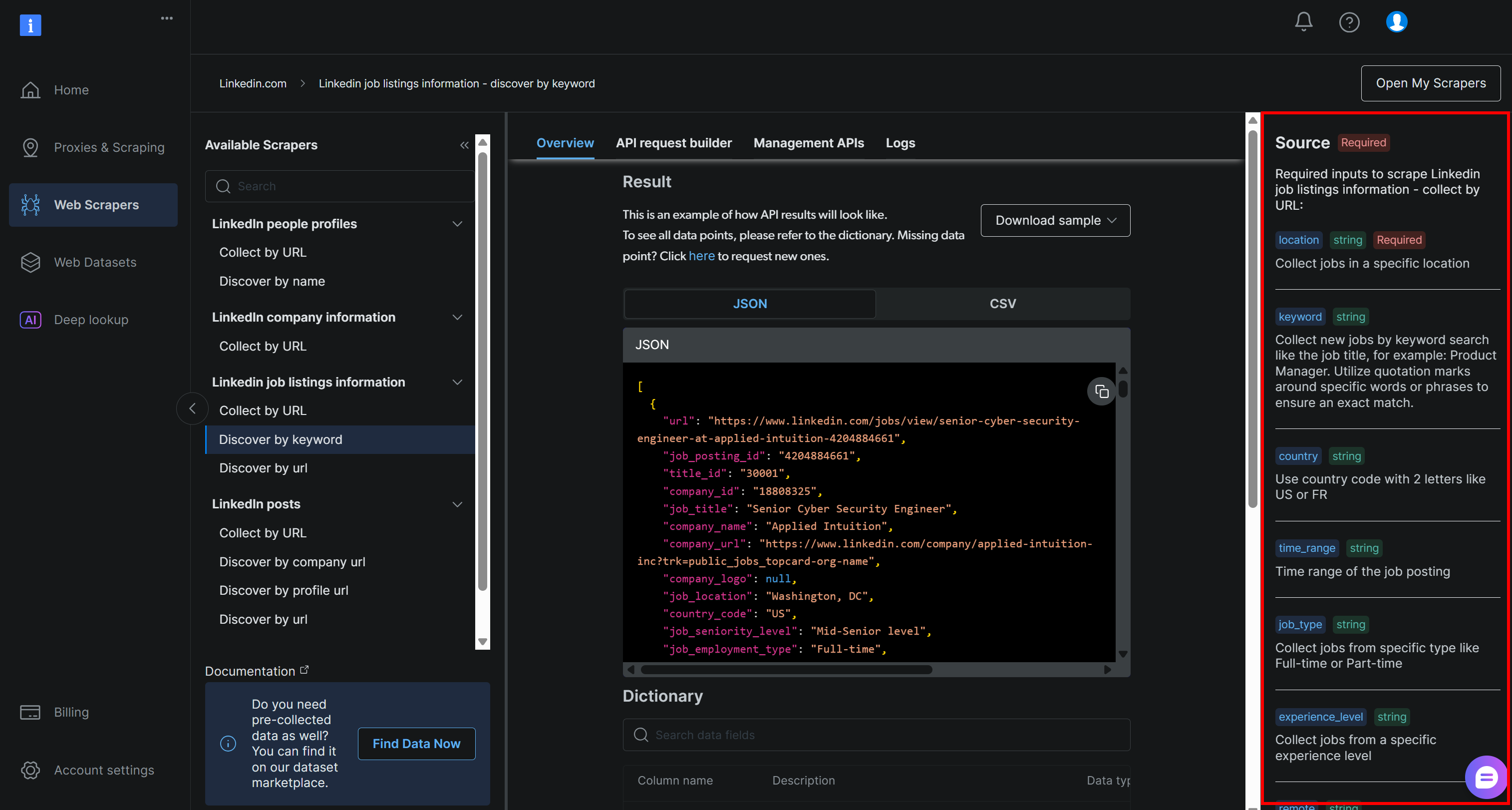
이 필드와 허용되는 값에 대한 자세한 내용은 공식 문서를 참조하십시오.
마지막 두 필드(profile_summary 및 desired_job_summary)는 귀하의 전문적 정체성과 구직 의향을 설명합니다. 이 정보는 Bright Data가 반환하는 각 채용 공고를 평가하기 위해 AI에 전달됩니다.
코드에서 설정 파일을 더 쉽게 처리하려면 Pydantic 모델로 매핑하는 것이 좋습니다. 먼저 가상 환경에 Pydantic을 설치하세요:
pip install pydantic그런 다음 JSON 구성 파일을 매핑하는 Pydantic 모델을 아래와 같이 정의하세요:
class JobSearchConfig(BaseModel):
location: str
keyword: Optional[str] = None
country: Optional[str] = None
time_range: Optional[str] = None
job_type: Optional[str] = None
경력_수준: Optional[str] = None
원격: Optional[str] = None
회사: Optional[str] = None
선택적_검색: Optional[bool] = Field(default=False)
제외_할_직종: Optional[List[str]] = Field(default_factory=list)
위치_반경: Optional[str] = None
# 추가 필드
profile_summary: str # AI 평가용 지원자 프로필 요약
desired_job_summary: str # AI 평가용 희망 직무 설명첫 번째와 마지막 두 개의 구성 필드만 필수임을 유의하십시오.
다음으로 --config_file 파일 경로에서 JSON 설정을 읽어오는 함수를 생성합니다. 이를 JobSearchConfig 인스턴스로 역직렬화합니다:
def load_and_validate_config(filename: str) -> JobSearchConfig:
# JSON 설정 파일 로드
try:
with open(filename, "r", encoding="utf-8") as f:
data = json.load(f)
except FileNotFoundError:
raise FileNotFoundError(f"구성 파일 '{filename}'을(를) 찾을 수 없습니다.")
try:
# 입력 JSON 데이터를 JobSearchConfig 인스턴스로 역직렬화
config = JobSearchConfig(**data)
except ValidationError as e:
raise ValueError(f"구성 역직렬화 오류:n{e}")
return config이번에는 다음 임포트가 필요합니다:
from pydantic import BaseModel, Field, ValidationError
from typing import Optional, List
import json훌륭합니다! 이제 구성 파일이 의도한 대로 제대로 읽히고 역직렬화되었습니다.
4단계: LinkedIn에서 채용 공고 스크래핑하기
이제 앞서 로드한 구성을 사용하여 Bright Data LinkedIn Jobs Scraper API를 호출할 차례입니다.
Bright Data의 웹 스크레이퍼 API 작동 방식에 익숙하지 않다면 먼저 문서를 확인하는 것이 좋습니다.
간단히 말해, 웹 스크레이퍼 API는 특정 도메인에서 공개 데이터를 가져올 수 있는 API 엔드포인트를 제공합니다. 백그라운드에서 Bright Data는 자체 서버에서 미리 준비된 스크레이핑 작업을 초기화하고 실행합니다. 이 API는 IP 로테이션, CAPTCHA 및 기타 조치를 처리하여 웹 페이지에서 공개 데이터를 효과적이고 윤리적으로 수집합니다. 작업이 완료되면 스크레이핑된 데이터는 구조화된 형식으로 파싱되어 스냅샷 형태로 제공됩니다.
따라서 일반적인 작업 흐름은 다음과 같습니다:
- 웹 스크래핑 작업을 시작하기 위해 API 호출을 트리거합니다.
- 스크랩된 데이터가 포함된 스냅샷이 준비되었는지 주기적으로 확인합니다.
- 사용 가능해지면 스냅샷에서 데이터를 가져옵니다.
위 로직은 몇 줄의 코드로 구현 가능합니다:
def trigger_and_poll_linkedin_jobs(config: JobSearchConfig, brightdata_api_key: str, jobs_number: int, polling_timeout=10):
# Bright Data LinkedIn 채용 정보 검색 트리거
url = "https://api.brightdata.com/datasets/v3/trigger"
headers = {
"Authorization": f"Bearer {brightdata_api_key}",
"Content-Type": "application/json",
}
params = {
"dataset_id": "gd_lpfll7v5hcqtkxl6l", # Bright Data "Linkedin job listings information - discover by keyword" 데이터셋 ID
"include_errors": "true",
"type": "discover_new",
"discover_by": "keyword",
"limit_per_input": str(jobs_number),
}
# 사용자 설정에 기반한 Bright Data API 페이로드 준비
data = [{
"location": config.location,
"keyword": config.keyword or "",
"country": config.country or "",
"time_range": config.time_range or "",
"job_type": config.job_type or "",
"experience_level": config.experience_level or "",
"remote": config.remote or "",
"company": config.company or "",
"selective_search": config.selective_search,
"jobs_to_not_include": config.jobs_to_not_include or "",
"location_radius": config.location_radius or "",
}]
response = requests.post(url, headers=headers, params=params, json=data)
if response.status_code != 200:
raise RuntimeError(f"트리거 요청 실패: {response.status_code} - {response.text}")
snapshot_id = response.json().get("snapshot_id")
if not snapshot_id:
raise RuntimeError("Bright Data 트리거에서 snapshot_id가 반환되지 않았습니다.")
print(f"LinkedIn 채용 공고 검색 트리거 완료! 스냅샷 ID: {snapshot_id}")
# 데이터 준비 완료 또는 시간 초과까지 스냅샷 엔드포인트 폴링
snapshot_url = f"https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json"
headers = {"Authorization": f"Bearer {brightdata_api_key}"}
print(f"ID: {snapshot_id} 스냅샷 폴링 중")
while True:
snap_resp = requests.get(snapshot_url, headers=headers)
if snap_resp.status_code == 200:
# 스냅샷 준비 완료: 채용 공고 JSON 데이터 반환
print("스냅샷 준비 완료")
return snap_resp.json()
elif snap_resp.status_code == 202:
# 스냅샷 준비 중: 대기 후 재시도
print(f"스냅샷 준비 중. {polling_timeout} 초 후에 재시도 중...")
time.sleep(polling_timeout)
else:
raise RuntimeError(f"스냅샷 폴링 실패: {snap_resp.status_code} - {snap_resp.text}")이 함수는 구성 파일의 검색 매개변수를 사용하여 Bright Data의 LinkedIn Jobs Scraper를 트리거하여, 지정된 조건에 맞는 목록만 가져오도록 합니다. 이후 데이터 스냅샷이 준비될 때까지 폴링을 수행하며, 준비되면 JSON 형식의 채용 공고 목록을 반환합니다. 인증은 환경 변수에서 미리 로드된 Bright Data API 키를 사용하여 처리됩니다.
LinkedIn Jobs Scraper로 가져온 스냅샷에는 다음과 같은 JSON 형식의 채용 공고 목록이 포함됩니다:
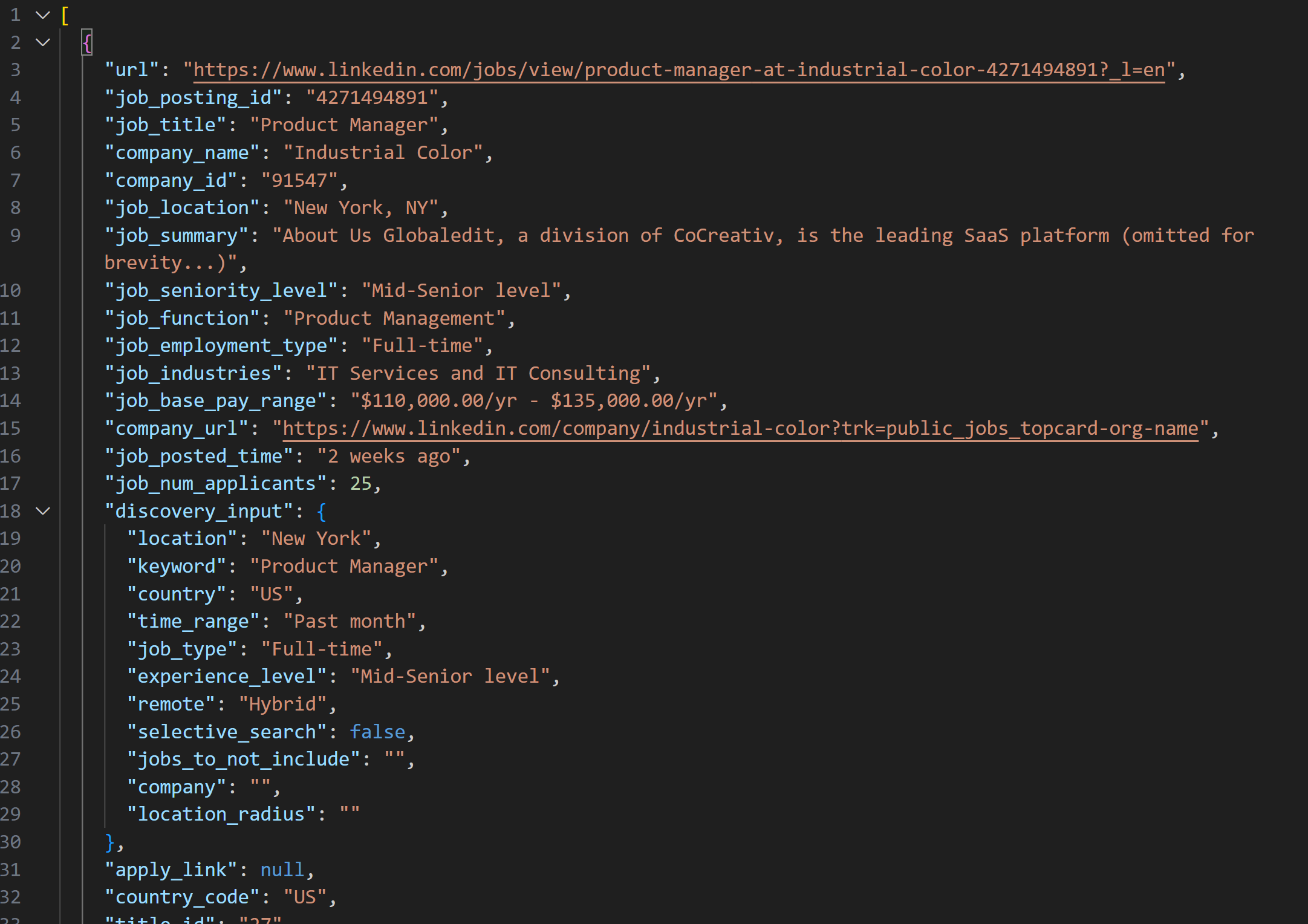
참고: 생성된 JSON 스냅샷에는 정확히 --jobs_number 개까지의 채용 공고가 포함됩니다. 본 예시에서는 20개의 채용 공고가 포함됩니다.
위 함수가 작동하려면 requests를 설치해야 합니다:
pip install requests작동 방식에 대한 자세한 내용은 Python HTTP 요청 고급 가이드를 참조하십시오.
다음으로, Python 표준 라이브러리에서 time 과 함께 requests를 반드시 임포트하세요:
import requests
import time훌륭합니다! 이제 Bright Data와 연동하여 최신 LinkedIn 채용 공고 데이터를 수집할 준비가 되었습니다.
5단계: AI를 통한 채용 공고 평가
이제 OpenAI 모델과 같은 대규모 언어 모델(LLM)에 각 수집된 채용 공고를 평가하도록 요청할 차례입니다.
목표는 직무가 다음 요소와 얼마나 잘 부합하는지에 따라 0에서 100 사이의 점수와 간단한 코멘트를 할당하는 것입니다:
- 귀하의 경력 (
profile_summary) - 희망 직무 (
desired_job_summary)
API 왕복 횟수를 줄이고 속도를 높이기 위해 일자리를 일괄 처리하는 것이 합리적입니다. 특히, 한 번에 --batch_size 개 일자리 수를 평가하게 됩니다.
먼저 openai 패키지를 설치하세요:
pip install openai그런 다음 OpenAI를 임포트하고 클라이언트를 초기화합니다:
from openai import OpenAI
# ...
# OpenAI 클라이언트 초기화
client = OpenAI()OpenAI 생성자에 API 키를 수동으로 전달할 필요가 없습니다. 라이브러리가 이미 설정해 둔 OPENAI_API_KEY 환경 변수에서 자동으로 읽어옵니다.
AI 기반 직무 평가 함수를 생성합니다:
def score_jobs_batch(jobs_batch: List[dict], profile_summary: str, desired_job_summary: str) -> List[JobScore]:
# 후보자 프로필을 기반으로 AI가 직무 매칭을 평가할 프롬프트 생성
prompt = f"""
"당신은 전문 채용 담당자입니다. 다음과 같은 후보자 프로필이 주어졌습니다:n"
"{profile_summary}nn"
"희망 직무 설명:n{desired_job_summary}nn"
"각 채용 공고가 프로필 및 희망 직무와 얼마나 잘 부합하는지 0에서 100 사이의 점수로 정확하게 평가하세요.n"
"각 직무에 대해 점수와 일치 품질을 설명하는 짧은 코멘트(최대 50단어)를 추가하세요.n"
"키 'job_posting_id', 'score', 'comment'를 가진 객체 배열을 반환하세요.nn"
"직무:n{json.dumps(jobs_batch)}n"
"""
messages = [
{"role": "system", "content": "당신은 유용한 채용 공고 평가 보조입니다."},
{"role": "user", "content": prompt},
]
# OpenAI API를 사용하여 구조화된 응답을 JobScoresResponse 모델로 파싱
response = client.responses.parse(
model="gpt-5-mini",
input=messages,
text_format=JobScoresResponse,
)
# 점수화된 채용 공고 목록 반환
return response.output_parsed.scores이 코드는 새로운 gpt-5-mini 모델을 사용하여 OpenAI가 각 스크랩된 채용 공고를 0에서 100점까지 점수화하고 간단한 설명을 함께 제공하도록 합니다.
반환된 응답이 항상 필요한 정확한 형식으로 반환되도록 하기 위해 parse() 메서드를 호출합니다. 이 메서드는 구조화된 출력 모델을 강제 적용하며, 여기서는 다음과 같은 Pydantic 모델로 정의됩니다:
class JobScore(BaseModel):
job_posting_id: str
score: int = Field(..., ge=0, le=100)
comment: str
class JobScoresResponse(BaseModel):
scores: List[JobScore]기본적으로 AI는 아래와 같은 구조화된 JSON 데이터를 반환합니다:
{
"scores": [
{
"job_posting_id": "4271494891",
"score": 80,
"comment": "SaaS 제품에 대한 강한 적합성, 엔드투엔드 소유권, API, 크로스-기능적 업무 수행 능력—귀사의 스타트업 PM 및 고객 중심 경험과 부합합니다. 역할은 2~4년 차를 대상으로 하므로, 7년 경력인 귀하에게는 다소 주니어급입니다."
},
// 생략...
{
"job_posting_id": "4273328527",
"score": 65,
"comment": "데이터/기술적 요소가 강조된 제품 역할; 애자일 및 크로스-기능적 책임은 부합하나, 정량적/기술적 도메인 경험(금융/통계 모델링)을 선호하여 적합도가 다소 낮을 수 있습니다."
}
]
}parse() 메서드는 JSON 응답을 JobScoresResponse 인스턴스로 변환합니다. 이후 코드에서 점수와 코멘트를 프로그래밍 방식으로 모두 접근할 수 있습니다.
참고: 다른 LLM 공급자를 사용하려면 위 코드를 선택한 공급자에 맞게 조정해야 합니다.
자, 이제 AI 직무 평가가 완료되었습니다.
6단계: AI 점수와 코멘트가 포함된 채용 공고 확장
앞서 보여드린 AI가 반환한 원시 JSON 출력을 살펴보세요. 각 직무 점수에는 job_posting_id 필드가 포함되어 있음을 확인할 수 있습니다. 이는 LinkedIn이 직무 목록을 식별하는 데 사용하는 ID와 일치합니다.
이 ID는 Bright Data LinkedIn Jobs Scraper가 생성한 스냅샷 데이터에도 나타나므로 이를 활용하여 다음 작업을 수행할 수 있습니다:
- 스크랩된 채용 공고 배열에서 원본 채용 공고 객체를 찾습니다.
- AI가 생성한 점수와 코멘트를 추가하여 해당 채용 공고 객체를 보강합니다.
다음 함수를 통해 이를 달성할 수 있습니다:
def extend_jobs_with_scores(jobs: List[dict], all_scores: List[JobScore]) -> List[dict]:
# 보강된 데이터 저장 위치
extended_jobs = []
# 원본 채용 공고에 AI 점수 및 코멘트 결합
for score_obj in all_scores:
matched_job = None
for job in jobs:
if job.get("job_posting_id") == score_obj.job_posting_id:
matched_job = job
break
if matched_job:
job_with_score = dict(matched_job)
job_with_score["ai_score"] = score_obj.score
점수_객체["ai_comment"] = 점수_객체.comment
확장_직무.append(점수_객체가 있는 직무)
# AI 점수(높은 순)로 확장 직무 정렬
확장_직무.sort(key=lambda j: j["ai_score"], reverse=True)
return 확장_직무보시다시피, 몇 개의 for 루프만으로도 이 작업을 처리할 수 있습니다. 강화된 데이터를 반환하기 전에 ai_score를 기준으로 내림차순으로 정렬하세요. 이렇게 하면 가장 적합한 직무가 상단에 표시되어 빠르게 찾을 수 있습니다.
멋지네요! 이제 LinkedIn 구직 AI 어시스턴트가 거의 완성되었습니다!
7단계: 점수화된 일자리 데이터 내보내기
스크랩하고 보강한 채용 정보를 CSV 파일로 내보내려면 Python의 내장 csv 패키지를 사용하세요.
def export_extended_jobs(extended_jobs: List[dict], output_csv: str):
# 배열의 첫 번째 요소에서 필드 이름을 동적으로 가져옴
fieldnames = list(extended_jobs[0].keys())
with open(output_csv, mode="w", newline="", encoding="utf-8") as csvfile:
# AI 점수가 포함된 확장된 일자리 데이터를 CSV에 기록
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for job in extended_jobs:
writer.writerow(job)
print(f"{len(extended_jobs)}개의 일자리를 {output_csv}로 내보냈습니다") 위 함수는 output_csv를 --output_csv CLI 인자로 대체하여 호출됩니다.
csv 모듈을 반드시 임포트하세요:
import csv완벽합니다! LinkedIn 구직 AI 어시스턴트가 이제 AI로 보강된 데이터를 출력 CSV 파일로 내보냅니다.
8단계: 상위 구직 매칭 결과 출력
출력 CSV 파일을 열지 않고 터미널에서 즉시 피드백을 받으려면 상위 3개 직무 매칭의 핵심 세부 정보를 출력하는 함수를 작성하세요:
def print_top_jobs(extended_jobs: List[dict], top: int = 3):
print(f"n*** 상위 {top}개 직무 매칭 결과 ***")
for job in extended_jobs[:3]:
print(f"URL: {job.get('url', 'N/A')}")
print(f"Title: {job.get('job_title', 'N/A')}")
print(f"AI Score: {job.get('ai_score')}")
print(f"AI Comment: {job.get('ai_comment', 'N/A')}")
print("-" * 40)9단계: 모든 것을 결합하기
이전 단계의 모든 함수를 LinkedIn 구직 보조 메인 로직에 통합합니다:
# CLI에서 런타임 매개변수 가져오기
args = parse_cli_args()
try:
# 환경 변수에서 API 키 로드
_, brightdata_api_key = load_env_vars()
# 구직 검색 설정 파일 로드
config = load_and_validate_config(args.config_file)
# 채용 정보 가져오기
jobs_data = trigger_and_poll_linkedin_jobs(config, brightdata_api_key, args.jobs_number)
print(f"{len(jobs_data)} 개의 채용 정보 발견!")
except Exception as e:
print(f"[오류] {e}")
return
all_scores = []
# API 과부하 방지 및 대규모 데이터셋 처리를 위해 일괄 처리
for i in range(0, len(jobs_data), args.batch_size):
batch = jobs_data[i : i + args.batch_size]
print(f"{i // args.batch_size + 1} 번째 배치(총 {len(batch)}개 일자리) 점수 계산 중...")
scores = score_jobs_batch(batch, config.profile_summary, config.desired_job_summary)
all_scores.extend(scores)
time.sleep(1) # API 속도 제한을 피하기 위해
# 점수를 스크랩된 작업에 병합
extended_jobs = extend_jobs_with_scores(jobs_data, all_scores)
# 결과를 CSV로 저장
export_extended_jobs(extended_jobs, args.output_csv)
# 주요 정보와 함께 상위 작업 일치 항목 출력하여 빠른 검토 가능
print_top_jobs(extended_jobs)대단합니다! 이제 어시스턴트의 전체 코드를 검토하고 예상대로 작동하는지 확인하기만 하면 됩니다.
단계 #10: 완성된 코드 및 첫 실행
최종적인 assistant.py 파일은 다음과 같아야 합니다:
# pip install python-dotenv requests openai pydantic
import argparse
from dotenv import load_dotenv
import os
from pydantic import BaseModel, Field, ValidationError
from typing import Optional, List
import json
import requests
import time
from openai import OpenAI
import csv
# .env 파일에서 환경 변수 로드
load_dotenv()
# 프로젝트를 지원하는 Pydantic 모델
class JobSearchConfig(BaseModel):
# 출처: https://docs.brightdata.com/api-reference/web-scraper-api/social-media-apis/linkedin#discover-by-keyword
location: str
keyword: Optional[str] = None
country: Optional[str] = None
time_range: Optional[str] = None
job_type: Optional[str] = None
experience_level: Optional[str] = None
remote: Optional[str] = None
company: Optional[str] = None
selective_search: Optional[bool] = Field(기본값=False)
jobs_to_not_include: Optional[List[str]] = Field(default_factory=list)
location_radius: Optional[str] = None
# 추가 필드
profile_summary: str # AI 점수 산정을 위한 지원자 프로필 요약
desired_job_summary: str # AI 점수 산정을 위한 희망 직무 설명
class JobScore(BaseModel):
job_posting_id: str
score: int = Field(..., ge=0, le=100)
comment: str
class JobScoresResponse(BaseModel):
scores: List[JobScore]
def parse_cli_args():
# 설정 및 런타임 옵션에 대한 명령줄 인수 파싱
parser = argparse.ArgumentParser(description="LinkedIn 구직 어시스턴트")
parser.add_argument("--config_file", type=str, default="config.json", help="설정 JSON 파일 경로")
parser.add_argument("--jobs_number", type=int, default=20, help="Bright Data Scraper API에서 반환되는 일자리 수 제한")
parser.add_argument("--batch_size", type=int, default=5, help="각 배치에서 평가할 일자리 수")
parser.add_argument("--output_csv", type=str, default="jobs_scored.csv", help="출력 CSV 파일명")
return parser.parse_args()
def load_env_vars():
# 환경 변수에서 필수 API 키를 읽고 존재 여부 확인
openai_api_key = os.getenv("OPENAI_API_KEY")
brightdata_api_key = os.getenv("BRIGHT_DATA_API_KEY")
missing = []
if not openai_api_key:
missing.append("OPENAI_API_KEY")
if not brightdata_api_key:
missing.append("BRIGHT_DATA_API_KEY")
if missing:
raise EnvironmentError(
f"필수 환경 변수 누락: {', '.join(missing)}n"
"해당 변수를 .env 파일 또는 환경 변수에 설정해 주세요."
)
return openai_api_key, brightdata_api_key
def load_and_validate_config(filename: str) -> JobSearchConfig:
# JSON 설정 파일 로드
try:
with open(filename, "r", encoding="utf-8") as f:
data = json.load(f)
except FileNotFoundError:
raise FileNotFoundError(f"구성 파일 '{filename}'을(를) 찾을 수 없습니다.")
try:
# 입력 JSON 데이터를 JobSearchConfig 인스턴스로 역직렬화
config = JobSearchConfig(**data)
except ValidationError as e:
raise ValueError(f"구성 역직렬화 오류:n{e}")
return config
def trigger_and_poll_linkedin_jobs(config: JobSearchConfig, brightdata_api_key: str, jobs_number: int, polling_timeout=10):
# Bright Data LinkedIn 일자리 검색 트리거
url = "https://api.brightdata.com/datasets/v3/trigger"
headers = {
"Authorization": f"Bearer {brightdata_api_key}",
"Content-Type": "application/json",
}
params = {
"dataset_id": "gd_lpfll7v5hcqtkxl6l", # Bright Data "Linkedin job listings information - discover by keyword" 데이터셋 ID
"include_errors": "true",
"type": "discover_new",
"discover_by": "keyword",
"limit_per_input": str(jobs_number),
}
# 사용자 설정에 기반한 Bright Data API 페이로드 준비
data = [{
"location": config.location,
"keyword": config.keyword or "",
"country": config.country or "",
"time_range": config.time_range or "",
"job_type": config.job_type or "",
"experience_level": config.experience_level or "",
"remote": config.remote or "",
"company": config.company or "",
"selective_search": config.selective_search,
"jobs_to_not_include": config.jobs_to_not_include or "",
"location_radius": config.location_radius or "",
}]
response = requests.post(url, headers=headers, params=params, json=data)
if response.status_code != 200:
raise RuntimeError(f"트리거 요청 실패: {response.status_code} - {response.text}")
snapshot_id = response.json().get("snapshot_id")
if not snapshot_id:
raise RuntimeError("Bright Data 트리거에서 snapshot_id가 반환되지 않았습니다.")
print(f"LinkedIn 채용 검색 트리거 완료! 스냅샷 ID: {snapshot_id}")
# 데이터 준비 완료 또는 타임아웃 시까지 스냅샷 엔드포인트 폴링
snapshot_url = f"https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json"
headers = {"Authorization": f"Bearer {brightdata_api_key}"}
print(f"ID: {snapshot_id} 스냅샷 폴링 중")
while True:
snap_resp = requests.get(snapshot_url, headers=headers)
if snap_resp.status_code == 200:
# 스냅샷 준비 완료: 채용 공고 JSON 데이터 반환
print("스냅샷 준비 완료")
return snap_resp.json()
elif snap_resp.status_code == 202:
# 스냅샷 아직 준비되지 않음: 대기 후 재시도
print(f"스냅샷 아직 준비되지 않음. {polling_timeout} 초 후에 재시도 중...")
time.sleep(polling_timeout)
else:
raise RuntimeError(f"스냅샷 폴링 실패: {snap_resp.status_code} - {snap_resp.text}")
# OpenAI 클라이언트 초기화
client = OpenAI()
def score_jobs_batch(jobs_batch: List[dict], profile_summary: str, desired_job_summary: str) -> List[JobScore]:
# 후보자 프로필을 기반으로 AI가 직무 매칭 점수를 산출하도록 프롬프트 구성
prompt = f"""
"당신은 전문 리크루터입니다. 다음 후보자 프로필을 고려하여:n"
"{profile_summary}nn"
"희망 직무 설명:n{desired_job_summary}nn"
"각 채용 공고가 프로필 및 희망 직무와 얼마나 잘 부합하는지 0에서 100 사이의 점수로 정확하게 평가하세요.n"
"각 직무에 대해 점수와 일치 품질을 설명하는 간단한 코멘트(최대 50단어)를 추가하세요.n"
"키 'job_posting_id', 'score', 'comment'를 가진 객체 배열을 반환하세요.nn"
"직무:n{json.dumps(jobs_batch)}n"
"""
messages = [
{"role": "system", "content": "당신은 유용한 채용 공고 평가 보조입니다."},
{"role": "user", "content": prompt},
]
# OpenAI API를 사용해 구조화된 응답을 JobScoresResponse 모델로 파싱
response = client.responses.parse(
model="gpt-5-mini",
input=messages,
text_format=JobScoresResponse,
)
# 점수화된 작업 목록 반환
return response.output_parsed.scores
def extend_jobs_with_scores(jobs: List[dict], all_scores: List[JobScore]) -> List[dict]:
# 보강된 데이터 저장 위치
extended_jobs = []
# 원본 작업과 AI 점수 및 코멘트 결합
for score_obj in all_scores:
matched_job = None
for job in jobs:
if job.get("job_posting_id") == score_obj.job_posting_id:
matched_job = job
break
if matched_job:
job_with_score = dict(matched_job)
job_with_score["ai_score"] = score_obj.score
job_with_score["ai_comment"] = score_obj.comment
extended_jobs.append(job_with_score)
# 확장된 일자리 목록을 AI 점수 순(높은 점수부터)으로 정렬
extended_jobs.sort(key=lambda j: j["ai_score"], reverse=True)
return extended_jobs
def export_extended_jobs(extended_jobs: List[dict], output_csv: str):
# 배열의 첫 번째 요소에서 필드 이름을 동적으로 가져옴
fieldnames = list(extended_jobs[0].keys())
with open(output_csv, mode="w", newline="", encoding="utf-8") as csvfile:
# AI 점수가 포함된 확장 작업 데이터를 CSV에 기록
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for job in extended_jobs:
writer.writerow(job)
print(f"{len(extended_jobs)}개의 작업을 {output_csv}로 내보냄")
def print_top_jobs(extended_jobs: List[dict], top: int = 3):
print(f"n*** 상위 {top}개 작업 일치 항목 ***")
for job in extended_jobs[:3]:
print(f"URL: {job.get('url', 'N/A')}")
print(f"Title: {job.get('job_title', 'N/A')}")
print(f"AI Score: {job.get('ai_score')}")
print(f"AI 코멘트: {job.get('ai_comment', 'N/A')}")
print("-" * 40)
def main():
# CLI에서 런타임 매개변수 가져오기
args = parse_cli_args()
try:
# 환경 변수에서 API 키 로드
_, brightdata_api_key = load_env_vars()
# 작업 검색 구성 파일 로드
config = load_and_validate_config(args.config_file)
# 작업 가져오기
jobs_data = trigger_and_poll_linkedin_jobs(config, brightdata_api_key, args.jobs_number)
print(f"{len(jobs_data)} 개의 작업 발견!")
except Exception as e:
print(f"[오류] {e}")
return
all_scores = []
# API 과부하 방지 및 대규모 데이터셋 처리를 위해 일괄 처리
for i in range(0, len(jobs_data), args.batch_size):
batch = jobs_data[i : i + args.batch_size]
print(f"{i // args.batch_size + 1} 번째 배치(총 {len(batch)}개 작업) 점수 계산 중...")
scores = score_jobs_batch(batch, config.profile_summary, config.desired_job_summary)
all_scores.extend(scores)
time.sleep(1) # API 속도 제한을 피하기 위해
# 점수를 스크랩된 작업에 병합
extended_jobs = extend_jobs_with_scores(jobs_data, all_scores)
# 결과를 CSV로 저장
export_extended_jobs(extended_jobs, args.output_csv)
# 주요 정보와 함께 상위 일치 직무 출력하여 빠른 검토 가능
print_top_jobs(extended_jobs)
if __name__ == "__main__":
main()7년 경력 제품 관리자로서 뉴욕에서 하이브리드 근무 형태의 직무를 찾는다고 가정합니다. config.json 파일을 다음과 같이 구성하세요:
{
"location": "뉴욕",
"keyword": "제품 매니저",
"country": "미국",
"time_range": "지난 한 달",
"job_type": "정규직",
"experience_level": "중급~상급",
"remote": "하이브리드",
"profile_summary": "기술 스타트업에서 7년 경력을 가진 숙련된 제품 매니저로, 애자일 방법론 및 크로스-기능 팀 리더십에 특화되어 있습니다.",
"desired_job_summary": "SaaS 제품 및 고객 중심 개발에 중점을 둔 정규직 제품 매니저 직책을 찾고 있습니다."
}그런 다음 LinkedIn 구직 도우미를 다음과 같이 실행할 수 있습니다:
python assistant.py선택 사항: 맞춤 실행을 위해 다음과 같이 작성하세요:
python assistant.py --config_file=config.json --batch_size=10 --jobs_number=40 --output_csv=results.csv이 명령어는 지정된 config.json 파일을 사용하여 어시스턴트를 실행합니다. 일자리를 10개씩 배치 처리하고, Bright Data에서 최대 40개의 채용 공고를 검색하며, AI 점수와 코멘트가 포함된 강화된 결과를 results.csv에 저장합니다 .
이제 기본 CLI 인자로 어시스턴트를 실행하면 터미널에 다음과 같은 내용이 표시됩니다:
LinkedIn job search triggered! Snapshot ID: s_me6x0s3qldm9zz0wv
Polling snapshot for ID: s_me6x0s3qldm9zz0wv
Snapshot not ready yet. Retrying in 10 seconds...
# 간결함을 위해 생략...
Snapshot not ready yet. Retrying in 10 seconds...
스냅샷 준비 완료
20개 채용 공고 발견!
5개 채용 공고로 배치 1 점수화 중...
5개 채용 공고로 배치 2 점수화 중...
5개 채용 공고로 배치 3 점수화 중...
5개 채용 공고로 배치 4 점수화 중...
20개 채용 공고를 jobs.csv로 내보냄그런 다음 상위 3개 작업 인사이트 출력은 다음과 같습니다:
*** 상위 3개 직무 매칭 ***
URL: https://www.linkedin.com/jobs/view/product-manager-growth-at-yext-4267903356?_l=en
직무명: 성장 제품 매니저
AI 점수: 92
AI 코멘트: 탁월한 적합도: 고객 중심 목표, 제품 주도 성장, 실험 및 크로스-기능적 협업을 중시하는 SaaS 중심 성장 PM — 후보자의 경험 및 희망 직무와 직접 일치.
----------------------------------------
URL: https://www.linkedin.com/jobs/view/product-manager-at-industrial-color-4271494891?_l=en
직책: 제품 매니저
AI 점수: 90
AI 코멘트: 높은 적합도: SaaS 제품, API/통합, 애자일 및 크로스-기능적 리더십 강조. 유일한 사소한 불일치는 기재된 2~4년 경력 요건(지원자 7년 경력)으로, 과잉 자격일 수 있으나 매우 적합함.
----------------------------------------
URL: https://www.linkedin.com/jobs/view/product-manager-at-resourceful-talent-group-4277945862?_l=en
직책: 제품 매니저
AI 점수: 88
AI 코멘트: 애자일 방식과 고객 중심 반복 프로세스를 적용한 SaaS/통합 직무와 매우 유사합니다. 채용 공고는 2~4년 경력을 요구하지만, 귀하의 7년 스타트업 PM 경험과 크로스-기능적 리더십 역량이 잘 부합합니다.
----------------------------------------생성된 jobs_scored.csv 파일을 열어보세요. 주요 열에는 다음과 같은 정보가 표시됩니다:
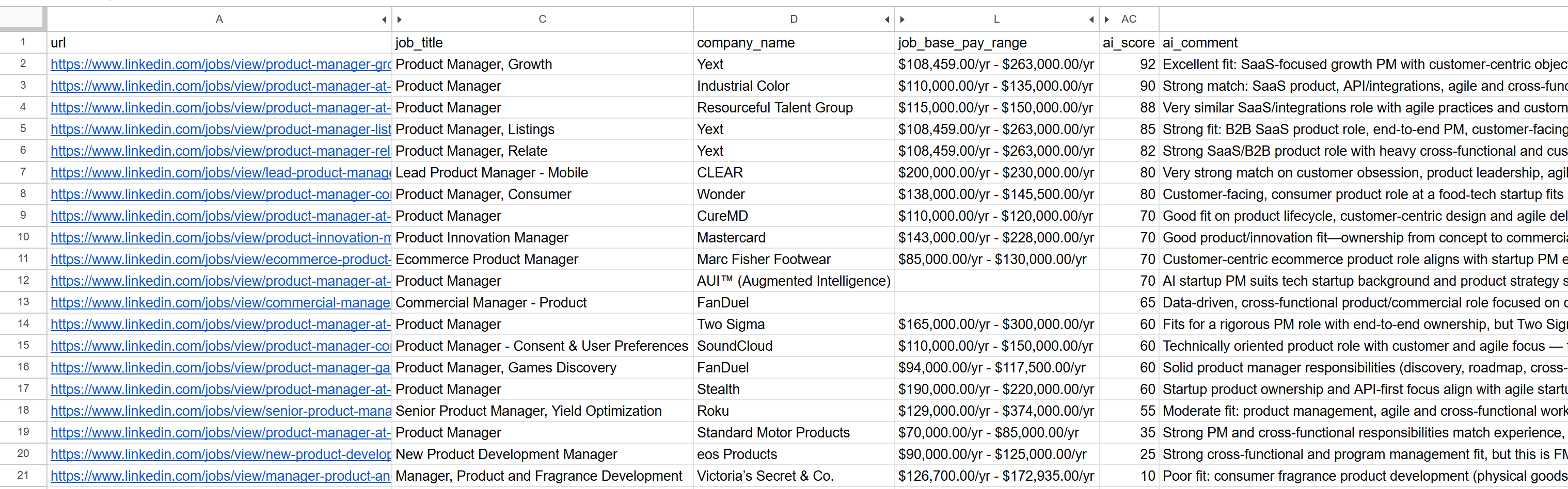
각 직무에 AI가 부여한 점수와 코멘트를 확인하세요. 이를 통해 성공 가능성이 높은 직무에만 집중할 수 있습니다!
자, 이제 끝났습니다! 이 AI 기반 LinkedIn 구직 워크플로우 덕분에 다음 직장을 찾는 일이 그 어느 때보다 쉬워졌습니다.
다음 단계
여기서 구축한 LinkedIn 구직 도우미는 채팅처럼 작동하지만, 몇 가지 개선점을 살펴볼 가치가 있습니다:
- 동일한 직무를 반복 평가하지 않기: 스크립트 실행 시마다 다른 직무를 평가하려면
config.json파일의jobs_to_not_include배열을 설정하세요. 여기에는 어시스턴트가 이미 분석한 직무의job_posting_ids를포함시켜야 합니다. 예를 들어, 현재 스크랩된 직무를 제외하려면 구성은 다음과 같을 수 있습니다:
{
"location": "New York",
"keyword": "Product Manager",
"country": "US",
"time_range": "Past month",
"job_type": "Full-time",
"experience_level": "Mid-Senior level",
"remote": "Hybrid",
"jobs_to_not_include": ["4267903356", "4271494891", "4277945862", "4267906118", "4255405781", "4267537560", "4245709356", "4265355147", "4277751182", "4256914967", "4281336197", "4232207277", "4273328527", "4277435772", "4253823512", "4279286518", "4224506933", "4250788498", "4256023955", "4252894407"], // <--- 참고: 제외할 작업의 ID
"profile_summary": "기술 스타트업에서 7년 경력의 숙련된 제품 매니저로, 애자일 방법론 및 크로스-기능 팀 리더십을 전문으로 합니다.",
"desired_job_summary": "SaaS 제품 및 고객 중심 개발에 초점을 맞춘 정규직 제품 매니저 역할을 찾고 있습니다."
}- 스크립트 주기적 실행 자동화: Cron 같은 도구로 스크립트를 정기적으로(예: 매일) 실행하도록 예약하세요. 이때
time_range인수를 올바르게 설정(예: “지난 24시간”)하고, 이미 평가한 채용 공고를 제외하기 위해jobs_to_not_include목록을 업데이트하는 것을 잊지 마세요. 이렇게 하면 최신 공고에 집중할 수 있습니다. - 전용 AI 평가 모델 사용: 일반적인 GPT-5 모델 대신, 직무 매칭 및 점수 산출에 특화되어 미세 조정된 전용 AI 모델을 사용하는 것을 고려하세요. 이 간단한 변경만으로도 직무 평가의 정확성과 관련성을 크게 향상시킬 수 있습니다.
결론
이 글에서는 Bright Data의 LinkedIn 채용 정보 스크래핑 기능을 활용해 AI 기반 구직 지원 도구를 구축하는 방법을 알아보았습니다.
여기서 구축한 AI 워크플로는 새로운 직장을 찾고 있으며, 최고의 기회에만 집중하여 채용 가능성을 극대화하고자 하는 모든 사람에게 적합합니다. 진정으로 자신의 경력 목표에 부합하고 채용 가능성이 높은 직무에만 지원함으로써 시간과 에너지를 절약할 수 있도록 도와줍니다.
보다 고급 워크플로를 구축하려면 Bright Data AI 인프라에서 실시간 웹 데이터를 수집, 검증, 변환하는 전체 솔루션 범위를 살펴보세요.
무료 Bright Data 계정을 생성하고 AI 지원 데이터 도구로 실험을 시작하세요!
자주 묻는 질문
위 예시는 LinkedIn을 데이터 소스로 사용했지만, 스크립트를 쉽게 확장하여 Indeed 또는 Bright Data를 통해 이용 가능한 다른 구인 목록 소스와도 작동하도록 할 수 있습니다. Indeed 통합에 대한 자세한 내용은 Indeed Jobs Scraper를 참조하세요.
이 AI 워크플로는 광범위한 채택과 인기로 인해 OpenAI에 의존합니다. 그러나 Gemini, Anthropic, Cohere 또는 API를 통해 이용 가능한 다른 대규모 언어 모델과 함께 작동하도록 워크플로를 쉽게 조정할 수 있습니다.
LinkedIn Jobs Scraper가 반환하는 데이터는 매우 고품질이며 구조화되어 있어 LLM을 직접 사용하여 점수화할 수 있습니다. 따라서 추론 및 의사결정 기능을 갖춘 자율 에이전트의 복잡성이 반드시 필요하지 않습니다.
그럼에도 더 진보된 LinkedIn 구직 AI 에이전트를 구축하고 싶다면, 다음과 같은 다중 에이전트 아키텍처를 고려할 수 있습니다:
구직 정보 수집 에이전트: Bright Data 인프라(도구 또는 MCP를 통해)와 통합된 AI 에이전트로, LinkedIn Jobs Scraper API를 호출하여 지속적으로 구직 목록을 수집하고 업데이트합니다.
구직 평가 점수 부여 에이전트: LLM을 활용하여 지원자의 프로필과 선호도에 기반해 구직 정보를 평가하고 점수를 매기는 데 특화된 에이전트입니다.
오케스트레이터 에이전트: 상위 레벨 에이전트로, 다른 두 에이전트를 조정하며 원하는 수의 고득점 관련 채용 공고를 확보할 때까지 데이터 수집 및 점수 부여 사이클을 반복적으로 트리거합니다.
해당 채용 공고에 자동으로 지원하도록 에이전트를 프로그래밍할 수도 있습니다. 이러한 LinkedIn 구직 시스템을 구축할 계획이라면 CrewAI와 같은 멀티 에이전트 플랫폼 사용을 권장합니다.




