이 튜토리얼에서 배울 내용은 다음과 같습니다:
- AI 에이전트 구축 솔루션으로서 Mastra가 무엇이며, 어떤 가치를 제공하는지.
- Mastra AI 에이전트가 웹을 탐색할 수 있을 때 훨씬 강력해지는 이유.
- Bright Data 도구와의 통합을 통해 웹 접근 기능을 갖춘 Mastra AI 에이전트를 구축하는 방법.
- (선택 사항) Mastra를 Bright Data Web MCP에 연결하는 방법.
지금 바로 시작해 보겠습니다!
Mastra란 무엇인가요?
Mastra는 AI 기반 에이전트 및 애플리케이션 구축을 위한 현대적인 TypeScript 프레임워크입니다. 에이전트, 워크플로, RAG, 메모리, MCP, 그리고 관찰 가능성을 하나의 통합 시스템에서 구축하고 관리할 수 있는 API를 제공합니다.
Mastra는 오픈 소스이며 23,800개 이상의 GitHub 스타를 보유할 만큼 널리 채택되어 있습니다. 이는 강력한 커뮤니티 신뢰와 빠른 생태계 성장을 반영합니다.
이 솔루션이 제공하는 주요 기능은 다음과 같습니다:
- 에이전트(Agents): 복잡한 사용자 정의 작업을 완료하기 위해 추론하고, 도구를 사용하며, 반복 처리하는 자율 AI 에이전트를 구축합니다.
- 워크플로(Workflows): 분기, 병렬 단계, 제어된 결정론적 로직을 포함한 구조화된 그래프 기반 실행을 사용하여 다단계 프로세스를 오케스트레이션합니다.
- RAG: 검색 증강 생성 파이프라인을 사용하여 에이전트를 외부 지식 소스에 연결하고 근거 있는 맥락 인식 응답을 제공합니다.
- 메모리(Memory): 단기 및 장기 컨텍스트를 유지하여 에이전트가 대화를 기억하고 상호작용 전반에 걸쳐 연속성을 개선할 수 있도록 합니다.
- 도구(Tools): 외부 API, 함수, 통합으로 에이전트 기능을 확장하여 실제 작업 수행과 동적 데이터 접근을 가능하게 합니다.
- MCP: Model Context Protocol 서버를 통합하여 시스템 전반에 걸쳐 도구, 에이전트, 구조화된 리소스를 노출하고 사용합니다.
- 관찰 가능성(Observability): 로그, 트레이스, 메트릭, 성능 평가 도구를 사용하여 에이전트 동작을 추적, 평가, 디버깅합니다.
공식 문서에서 자세한 내용을 확인하세요.
Mastra AI 에이전트에 웹 검색 및 스크래핑 도구를 확장해야 하는 이유
Mastra는 AI 기반 애플리케이션과 에이전트 구축을 위한 풍부한 프레임워크입니다. 그러나 잘 설계된 AI 시스템도 오래되거나 불완전한 정보에 의존할 경우 품질이 저하되거나 잘못된 출력을 생성할 수 있습니다.
이것은 LLM의 근본적인 한계로, 정적 데이터셋으로 훈련되기 때문에 실시간 인식 능력이 부족합니다. 그 결과, 오래된 컨텍스트를 기반으로 환각을 일으키거나 잘못된 판단을 내릴 수 있어 정확성과 신뢰성이 저하됩니다.
이 문제를 해결하려면 AI 애플리케이션에 실시간 웹 데이터 인프라가 필요합니다. 바로 이 지점에서 Bright Data가 활약합니다!
솔루션: Mastra를 위한 Bright Data 도구
Bright Data는 다음의 공식 도구들을 통해 Mastra를 지원합니다:
webSearch: Google, Bing, Yandex 등 다양한 검색 엔진에서 웹 검색을 수행합니다. AI 에이전트가 바로 활용할 수 있도록 JSON 형식의 구조화된 SERP 결과를 반환합니다. Bright Data의 SERP API를 기반으로 작동합니다.webFetch: Bright Data의 Web Unlocker API를 사용하여 모든 웹 페이지의 콘텐츠를 가져옵니다. 봇 차단 및 CAPTCHA 시스템을 우회하여 모든 도메인의 실시간 웹 데이터에 접근합니다.
이 오픈 소스 통합을 통해 Mastra 애플리케이션은 프로덕션 수준의 웹 데이터 인프라에 접근할 수 있습니다. 덕분에 에이전트는 최신 소스를 발견하고, 실시간 정보를 검색하며, 훈련 데이터와 현재 현실 사이의 간극을 좁힐 수 있습니다.
Bright Data가 두드러지는 이유는 195개국에 걸쳐 4억 개 이상의 주거용 IP로 구성된 광범위한 글로벌 인프라에 있습니다. 99.99%의 가동률과 99.95%의 성공률을 유지하면서 무제한 동시 접속을 지원합니다.
웹 데이터 접근을 위해 Bright Data에 연결된 Mastra AI 에이전트 구축 방법
이 단계별 섹션에서는 Bright Data 도구와 통합된 새로운 Mastra AI 에이전트를 설정하는 과정을 안내합니다.
아래 지침을 따라 진행하세요!
사전 요구 사항
이 튜토리얼을 진행하려면 다음이 필요합니다:
- Git이 로컬에 설치되어 있어야 합니다.
- Node.js v22.13.0 이상 설치 (최신 LTS 버전 권장).
- Mastra가 지원하는 AI 모델 제공업체의 API 키 (이 예제에서는 OpenAI API 키를 사용합니다).
- API 키가 설정된 Bright Data 계정. Bright Data 계정 생성 및 API 키 구성 방법은 공식 문서 가이드를 참고하세요.
1단계: 새 Mastra 프로젝트 초기화
참고: 이미 Mastra 프로젝트가 있는 경우 이 단계를 건너뛸 수 있습니다.
create-mastra 유틸리티를 사용하여 mastra-bright-data-web-access-agent라는 새 Mastra 프로젝트를 생성합니다:
npx create-mastra@latest mastra-bright-data-web-access-agent프롬프트가 표시되면 AI 제공업체를 선택하세요.

이 경우 “OpenAI”를 선택한 후, API 키를 수동으로 입력하는 옵션을 선택합니다. 프롬프트가 표시되면 OpenAI API 키를 붙여넣으세요:

다음으로, Mastra 관찰 가능성 활성화 여부를 선택하라는 메시지가 표시됩니다. 원하는 설정을 선택한 후 나머지 설정 프롬프트를 계속 진행합니다.
설정이 완료되면 프로젝트 디렉토리로 이동합니다:
cd mastra-bright-data-web-access-agent다음과 유사한 프로젝트 구조가 표시됩니다:
mastra-bright-data-web-access-agent/
├── .agents/ # Internal Mastra directory for agent skills, etc.
├── node_modules/
└── src/
│ └── mastra/
│ ├── index.ts # Entry point that initializes the Mastra setup
│ ├── agents/
│ │ └── weather-agent.ts # Defines the default Weather AI agent
│ ├── scorers/
│ │ └── weather-scorer.ts # Scoring logic to evaluate or rank agent outputs
│ ├── tools/
│ │ └── weather-tool.ts # External tool integrations used by the agent
│ └── workflows/
│ └── weather-workflow.ts # Logic combining tools and agents
├── .env # Environment variables (API keys, secrets, etc.)
├── .gitignore
├── AGENTS.md # Docs describing available agents and their behavior
├── package-lock.json
├── package.json
├── README.md # Main project documentation
└── skills-lock.json 이 폴더에는 기본 Mastra 날씨 AI 에이전트 프로젝트가 포함되어 있습니다. 이는 Mastra에서 에이전트, 도구, 스코어러, 워크플로를 구축하는 방법을 시연하기 위해 설계된 최소 템플릿입니다.
파일들을 탐색하고 익숙해지세요. 예를 들어 .env 파일을 열어보면 설정 중에 구성된 OpenAI API 키를 확인할 수 있습니다. 다음 명령어로 에이전트를 실행해 볼 수도 있습니다:
npm run dev수고하셨습니다! Mastra 프로젝트가 설정되었으며 이제 Bright Data 도구로 확장할 준비가 되었습니다.
2단계: Bright Data 도구 설치 및 구성
먼저 Mastra Bright Data 도구와 필요한 zod 의존성을 설치합니다:
npm install @mastra/brightdata zod@mastra/brightdata 패키지는 Bright Data JavaScript SDK를 래핑하여 스크래핑 및 웹 검색 메서드를 Mastra 호환 도구로 노출합니다.
Bright Data JavaScript SDK가 작동하려면 BRIGHTDATA_API_TOKEN 환경 변수가 필요합니다. 이를 .env 파일에 추가합니다:
BRIGHTDATA_API_TOKEN="<YOUR_BRIGHT_DATA_API_KEY>"<YOUR_BRIGHT_DATA_API_KEY> 플레이스홀더를 실제 Bright Data API 키로 교체합니다. API 키는 SDK가 Bright Data API에 대한 요청을 인증하는 데 사용됩니다.
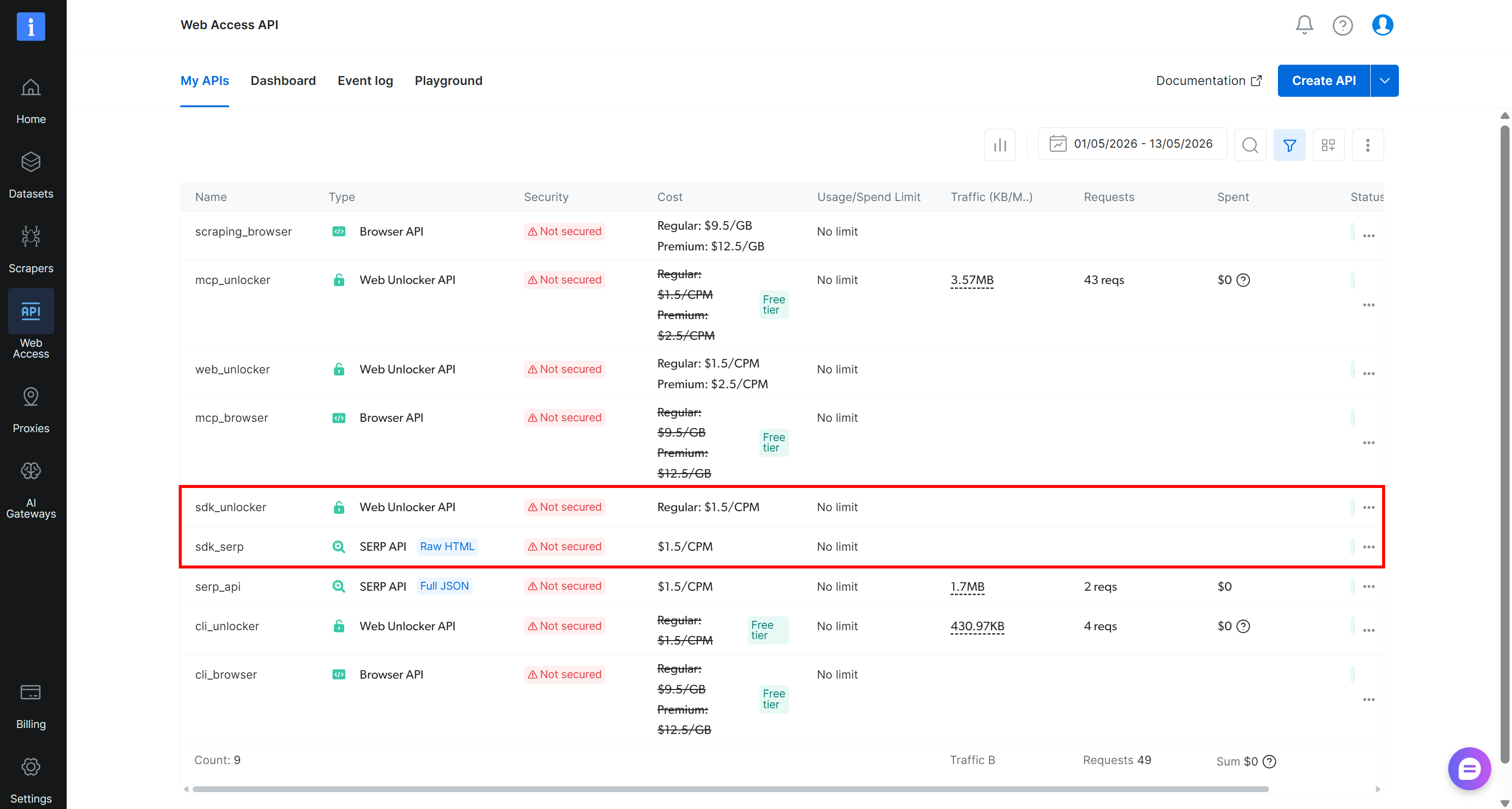
구성이 완료되면 @mastra/brightdata 도구가 Bright Data 계정에 연결됩니다. 처음 사용 시 Bright Data SDK는 Bright Data 대시보드에서 필요한 API를 자동으로 프로비저닝하며, 여기에는 필요한 Web Unlocker API 및 SERP API 존이 포함됩니다:
3단계: Bright Data 도구 추가
이 시점에서 Bright Data Mastra 도구가 설치되었습니다. 이제 이를 구성하여 AI 에이전트에 노출해야 합니다.
이를 위해 src/mastra/tools/ 내에 새 web-access.ts 파일을 생성합니다:
// src/mastra/tools/web-access.ts
import { createBrightDataTools } from '@mastra/brightdata'
// create the web search and web fetch tools using the BrightData client options
export const { webSearch, webFetch } = createBrightDataTools({
verbose: true, // enable verbose logging for debugging purposes
})이 코드는 사용자 정의 구성으로 @mastra/brightdata 패키지에서 createBrightDataTools()를 호출합니다. 필요한 Bright Data API 키는 BRIGHTDATA_API_TOKEN 환경 변수에서 자동으로 읽어옵니다. 마찬가지로 존 이름도 자동으로 유추되거나 기본값으로 생성됩니다. 필요한 경우 createBrightDataTools()의 추가 옵션을 통해 API 키와 존을 명시적으로 구성할 수 있습니다.
createBrightDataTools() 함수는 두 가지 Mastra 호환 도구를 생성합니다:
webSearch: Bright Data의 SERP API를 사용하여 AI 에이전트에 웹 검색 기능을 제공합니다.webFetch: Bright Data의 Web Unlocker API를 호출하여 모든 웹사이트에서 콘텐츠를 가져오고 스크래핑합니다.
참고: 대안으로, createBrightDataSearchTool()과 createBrightDataFetchTool()을 사용하여 이러한 도구를 개별적으로 생성하고 구성할 수도 있습니다. 더 세밀한 제어를 원하는 경우 이 방법이 권장됩니다.
이러한 도구를 내보내면 나중에 에이전트 정의에서 가져와 웹 접근 기능을 활성화할 수 있습니다. 훌륭합니다! Bright Data 도구가 이제 Mastra AI 에이전트에서 사용할 준비가 되었습니다.
4단계: 웹 접근 AI 에이전트 생성
이제 Bright Data 도구에 연결된 Mastra 에이전트를 생성할 차례입니다. 이를 위해 src/mastra/agents/ 경로 아래에 web-access-agent.ts 파일을 추가하고 다음과 같이 작성합니다:
// src/mastra/agents/web-access-agent.ts
import { Agent } from '@mastra/core/agent'
import { Memory } from '@mastra/memory'
import { webFetch, webSearch } from '../tools/web-access'
export const webAccessAgent = new Agent({
id: 'web-access-agent',
name: 'Web Access Agent',
instructions: `
You are a helpful, general-purpose assistant with Bright Data web access capabilities.
Goals:
- Answer user questions by combining reasoning with fresh, tool-based information.
- Prefer tools when information may be outdated or when factual accuracy is required.
- Clearly reference tool outputs so users can trace where information comes from.
Tool usage guidelines:
- Start with the webSearch tool to gather relevant sources and context.
- Use the webFetch tool to retrieve and analyze detailed content from specific pages.
`,
model: 'openai/gpt-5-mini',
tools: {
webFetch,
webSearch,
},
memory: new Memory(),
})이 코드 스니펫은 Bright Data를 기반으로 한 웹 검색 및 스크래핑 기능을 갖춘 Mastra AI 에이전트를 정의합니다. 에이전트가 최신 온라인 정보를 검색하고 웹 페이지를 스크래핑할 수 있도록 합니다. 또한 메모리 지원을 포함하여 에이전트가 상호작용 전반에 걸쳐 컨텍스트를 유지할 수 있습니다.
훌륭합니다! Bright Data 기반의 Mastra AI 에이전트 준비가 완료되었습니다.
5단계: 인덱스에 에이전트 추가
Mastra 애플리케이션을 완성하는 마지막 단계는 src/mastra/index.ts 파일에 webAccessAgent를 등록하는 것입니다:
// src/mastra/index.ts
import { Mastra } from '@mastra/core/mastra'
import { PinoLogger } from '@mastra/loggers'
import { LibSQLStore } from '@mastra/libsql'
import { DuckDBStore } from '@mastra/duckdb'
import { MastraCompositeStore } from '@mastra/core/storage'
import { Observability, MastraStorageExporter, MastraPlatformExporter, SensitiveDataFilter } from '@mastra/observability'
import { webAccessAgent } from './agents/web-access-agent'
export const mastra = new Mastra({
agents: { webAccessAgent },
storage: new MastraCompositeStore({
id: 'composite-storage',
default: new LibSQLStore({
id: 'mastra-storage',
url: 'file:./mastra.db',
}),
domains: {
observability: await new DuckDBStore().getStore('observability'),
}
}),
logger: new PinoLogger({
name: 'Mastra',
level: 'info',
}),
observability: new Observability({
configs: {
default: {
serviceName: 'mastra',
exporters: [
new MastraStorageExporter(),
new MastraPlatformExporter(),
],
spanOutputProcessors: [
new SensitiveDataFilter(),
],
},
},
}),
})위 코드 스니펫은 이전에 정의한 웹 접근 AI 에이전트를 등록하여 Mastra 애플리케이션을 초기화합니다. 그런 다음 에이전트의 메모리가 LibSQL 스토어를 사용하여 로컬 mastra.db 파일에 저장되도록 복합 스토리지를 구성합니다. 또한 Pino를 통한 구조화된 로깅을 활성화하고 모니터링 및 추적 가능성을 위한 내보내기 도구 및 민감한 데이터 필터링으로 관찰 가능성을 설정합니다.
참고: Mastra 애플리케이션을 간결하게 유지하려면 초기 날씨 관련 도구, 워크플로, 스코어러를 제거하는 것을 고려하세요.
6단계: 웹 접근 에이전트 테스트
다음 명령어로 Mastra 애플리케이션을 실행합니다:
npm run dev다음과 유사한 출력이 표시됩니다:
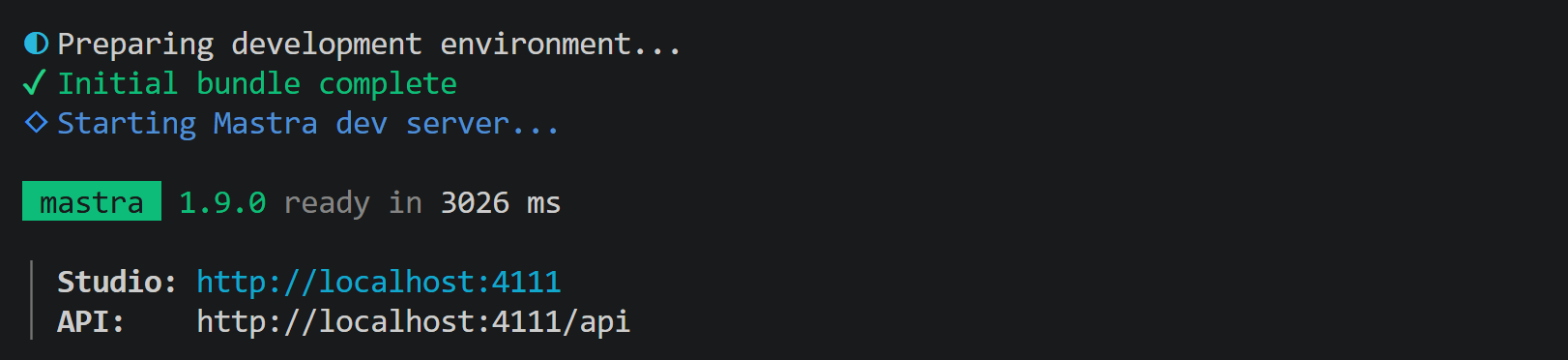
이는 Mastra 로컬 서버가 http://localhost:4111에서 실행 중임을 나타냅니다. 브라우저에서 해당 URL을 열면 Mastra 대시보드가 표시됩니다:
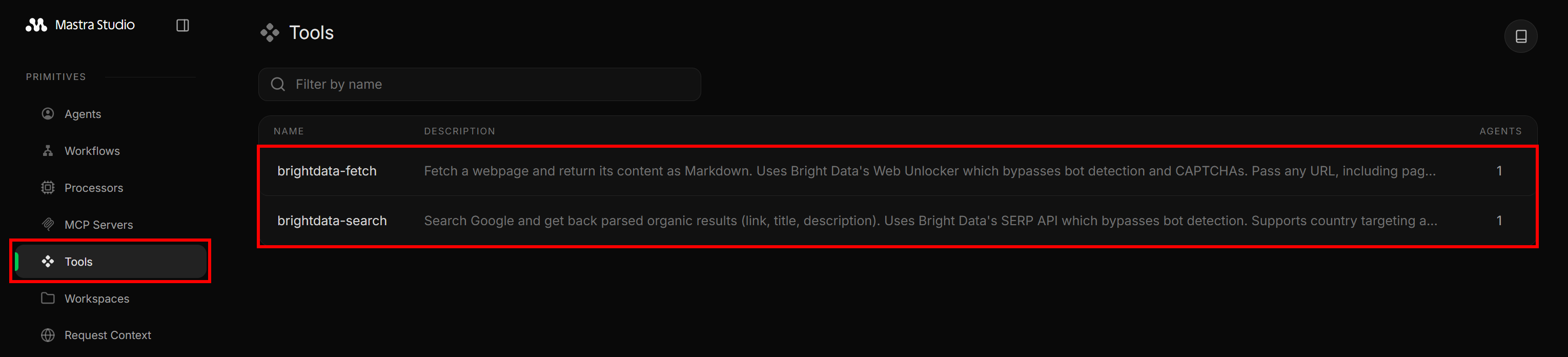
“도구(Tools)” 섹션으로 이동하면 src/mastra/tools/web-access.ts에서 노출된 두 가지 Bright Data 도구를 확인할 수 있습니다:
그런 다음 에이전트 페이지로 이동하여 “Web Access Agent” 항목을 클릭합니다:

에이전트의 프롬프트 UI가 열리며, 여기서 에이전트와 대화할 수 있습니다. 에이전트의 웹 탐색 기능을 확인하려면 다음과 같은 프롬프트를 실행해 보세요:
Search for the latest stock market news on Google. Select the most relevant articles, extract and analyze their content, and return a structured Markdown report summarizing the key information, including links to learn more.실행하면 다음과 같은 출력이 표시됩니다:
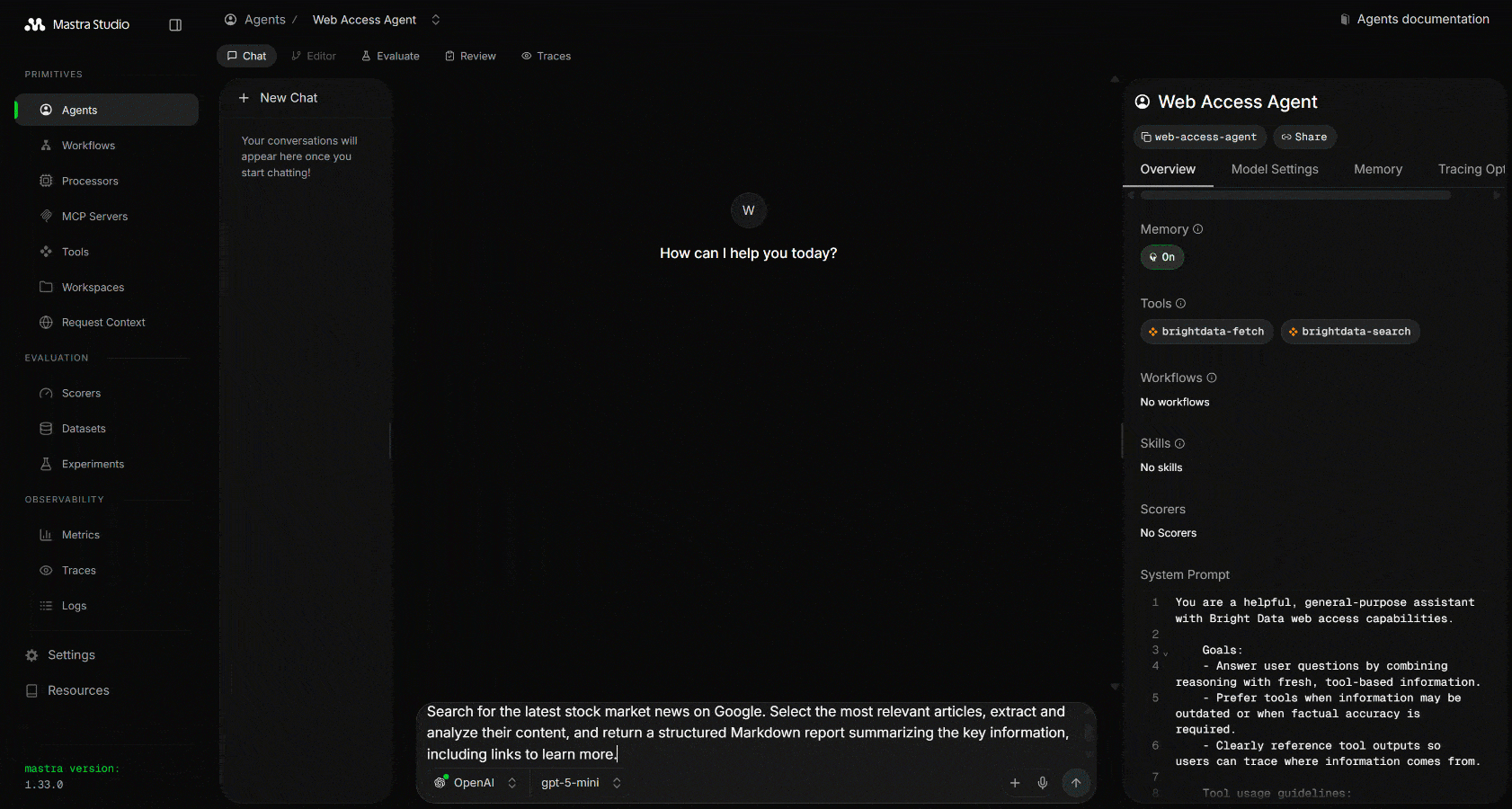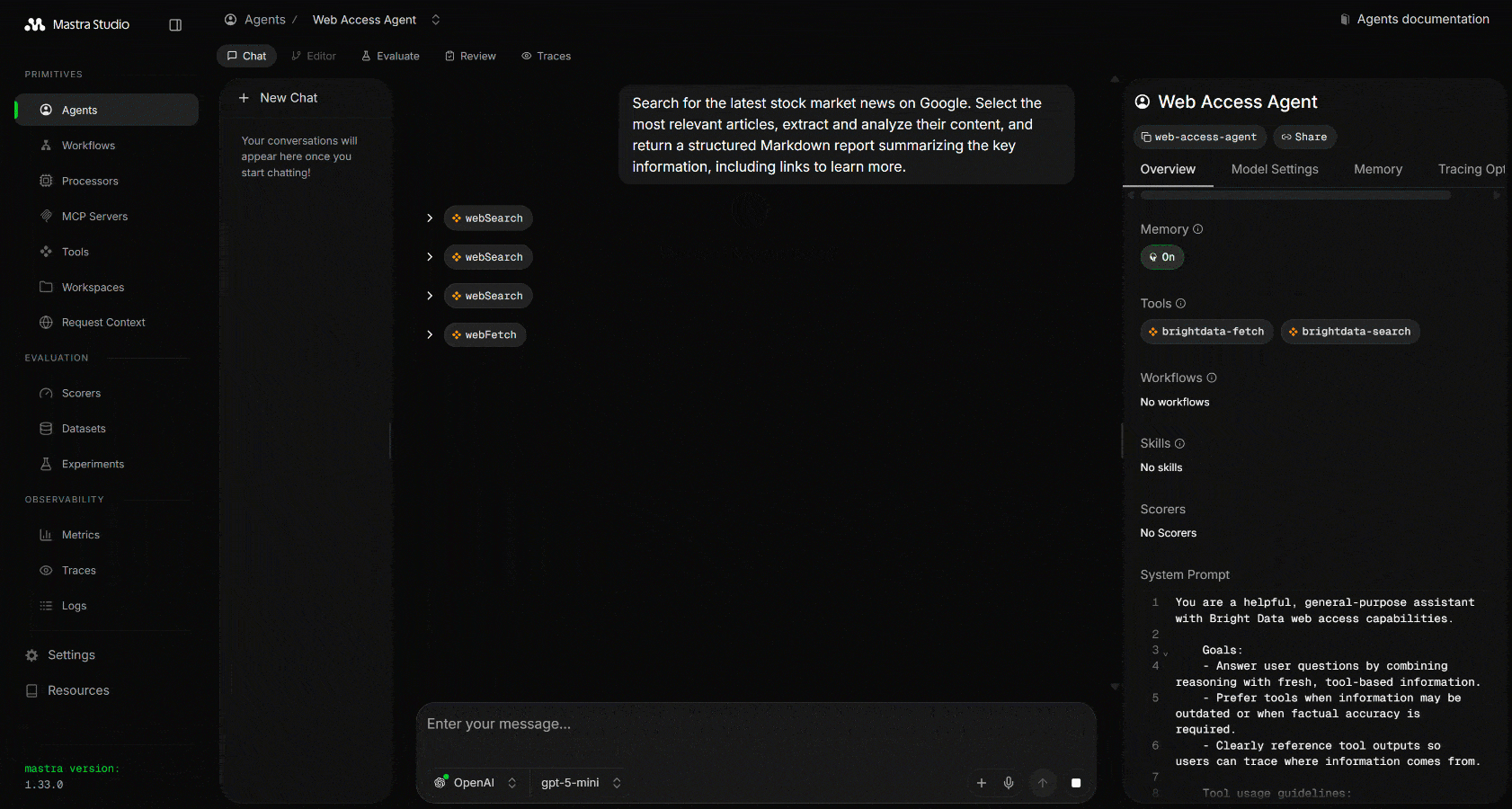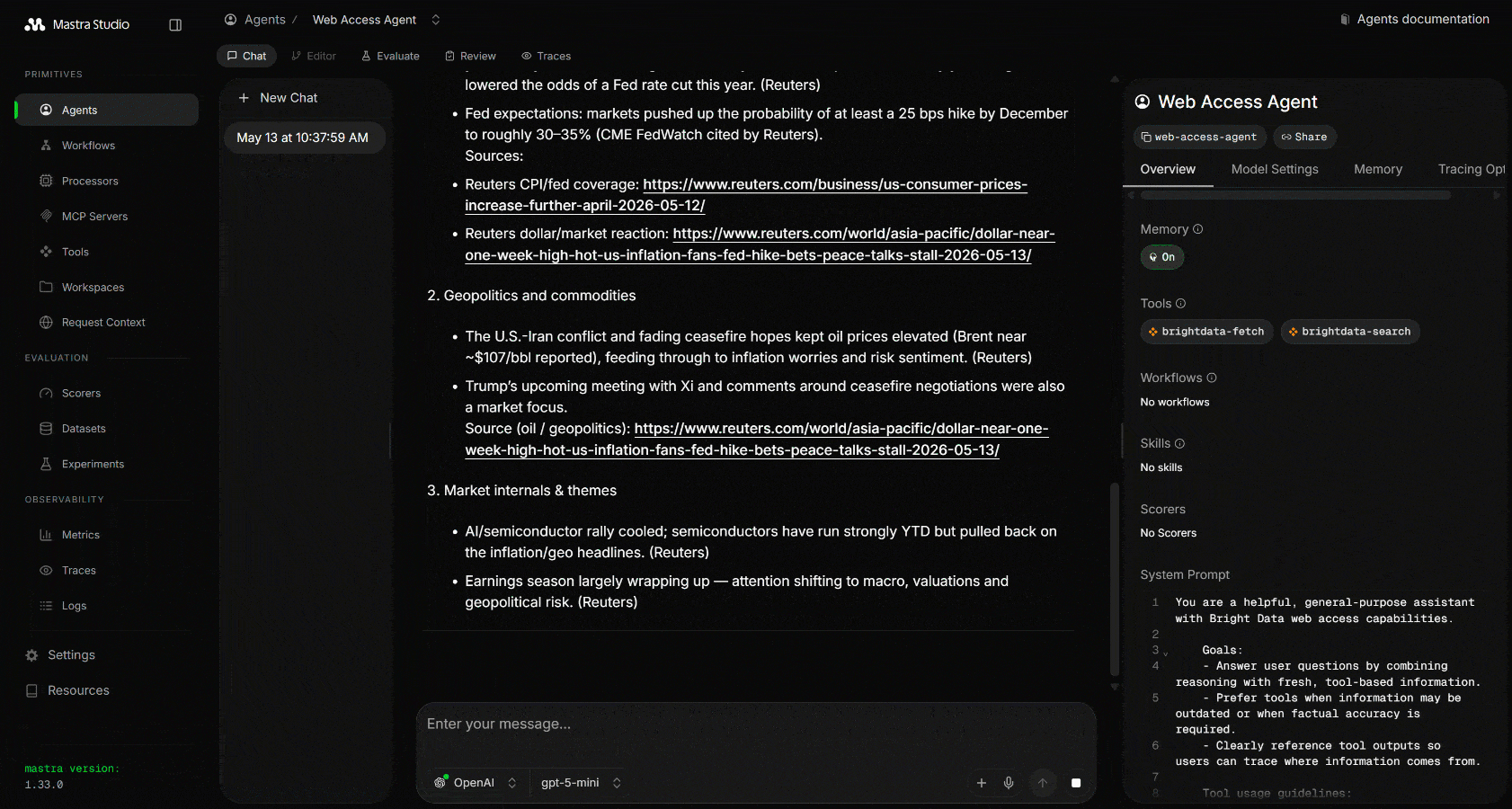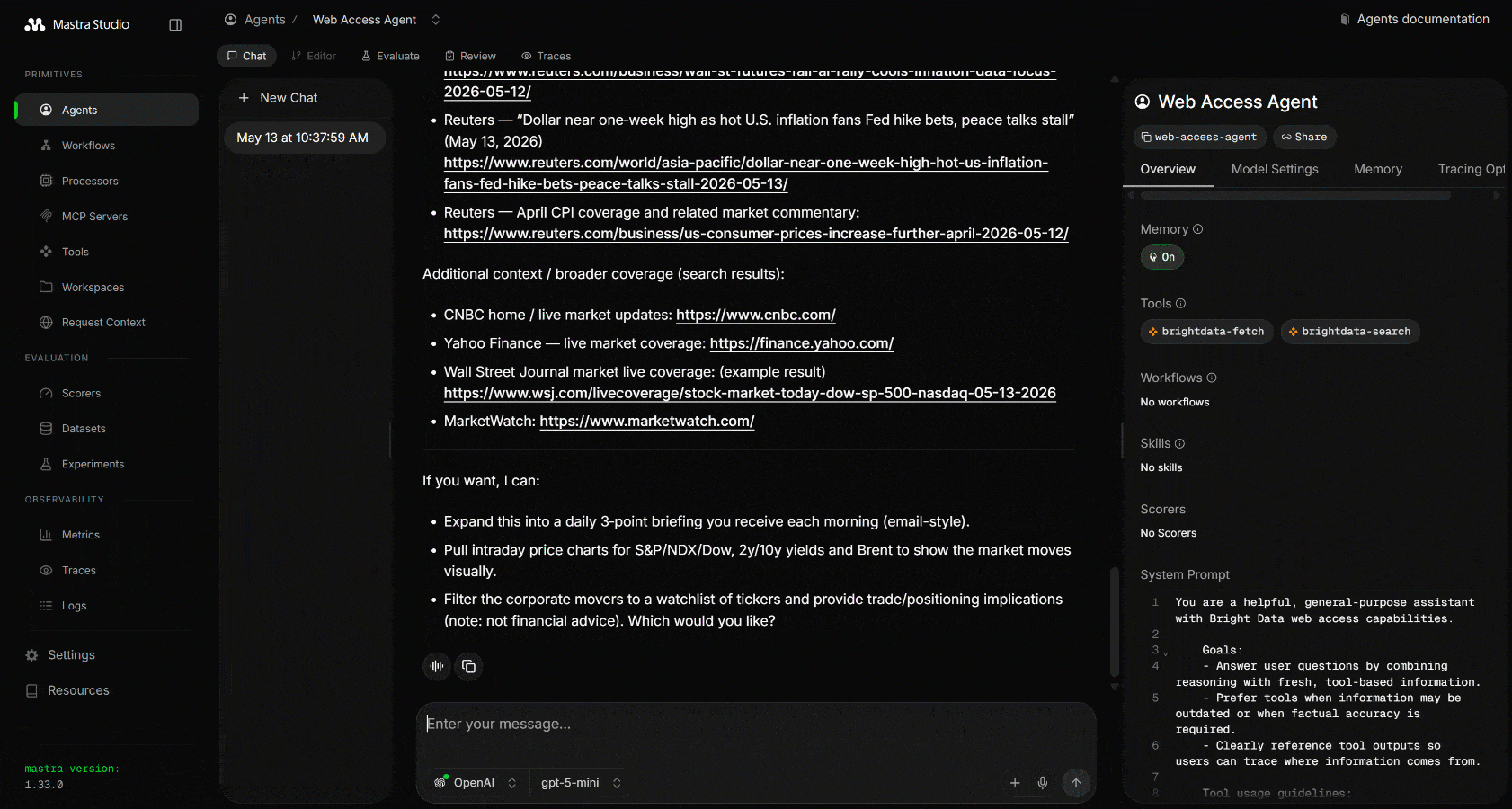
Mastra가 웹 검색 도구를 세 번 호출하여 관련 Google 검색 쿼리를 수행하는 것을 확인할 수 있습니다. 이 도구들은 Google에서 스크래핑된 JSON 형식의 구조화된 SERP 결과를 반환합니다:
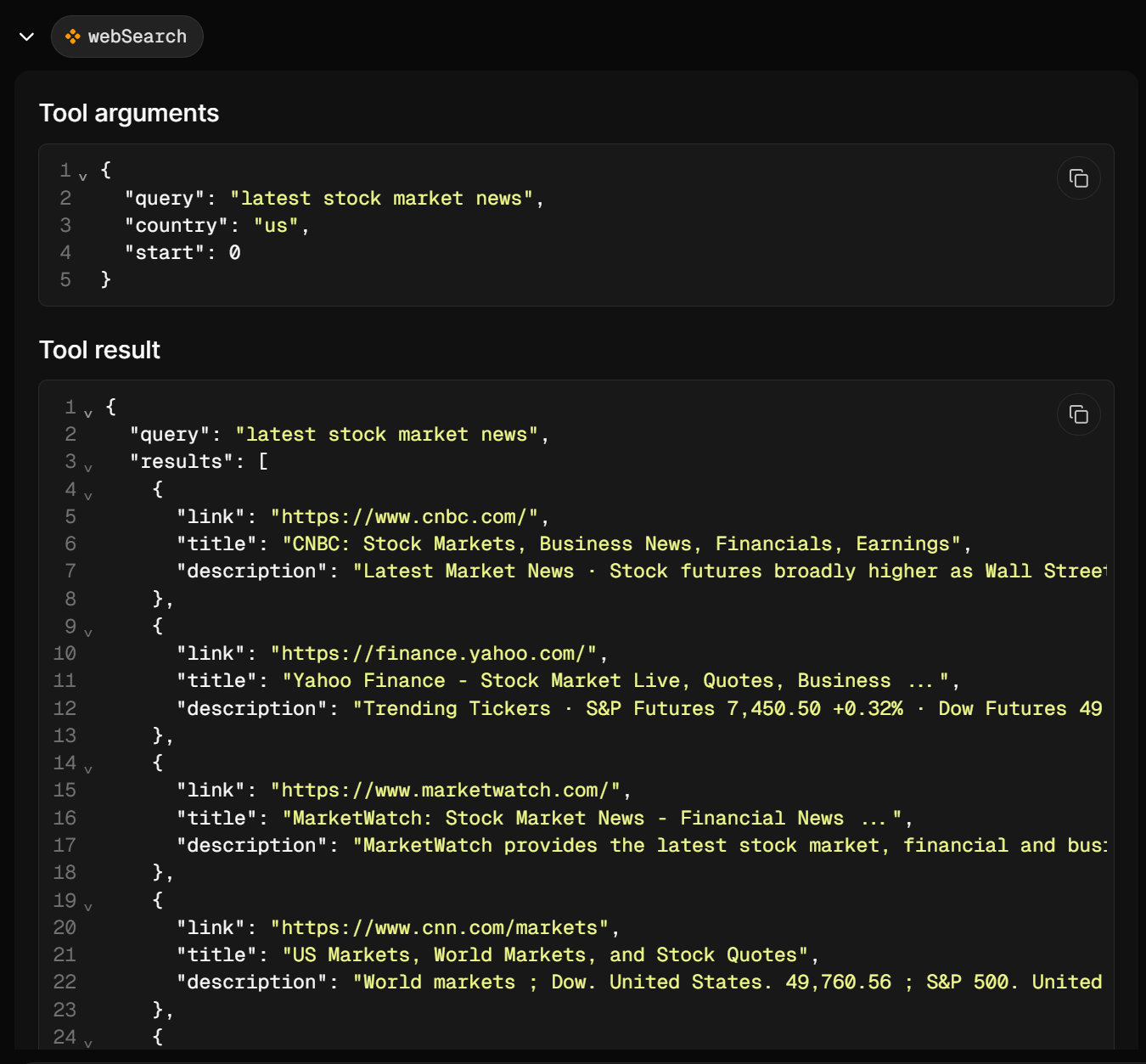
이 결과에서 에이전트는 가장 관련성 높은 링크를 선택하고 webFetch를 사용하여 해당 콘텐츠를 스크래핑합니다. 마지막으로, 오늘의 주식 시장 뉴스를 요약하는 구조화된 Markdown 보고서로 모든 내용을 집약합니다.
Et voilà! Bright Data 통합 덕분에 Mastra AI 에이전트는 이제 엔터프라이즈급 웹 검색 및 스크래핑 기능을 갖추어 더욱 근거 있는 응답을 제공합니다. 다양한 프롬프트를 시도하고 지원되는 모든 시나리오와 사용 사례를 테스트해 보세요!
[추가] Mastra AI 에이전트를 Bright Data Web MCP에 연결하기
Mastra는 MCP 통합도 지원한다는 점을 기억하세요. 따라서 Mastra AI 에이전트를 Bright Data Web MCP에 연결할 수 있습니다.
Web MCP 서버는 웹 검색, 스크래핑, 데이터 추출, 데이터 피드 검색, 브라우저 자동화를 위한 70개 이상의 도구에 대한 접근을 제공합니다. 또한 무료 플랜(월 5,000회 요청)도 제공됩니다.
Mastra에서 MCP를 사용하려면 먼저 필요한 의존성을 설치합니다:
npm install @mastra/mcp@latest그런 다음 다음 내용이 포함된 src/mastra/mcp/bright-data-mcp-client.ts 파일을 추가합니다:
// src/mastra/mcp/bright-data-mcp-client.ts
import { MCPClient } from '@mastra/mcp'
export const brightDataMcpClient = new MCPClient({
id: 'bright-data-mcp-client',
servers: {
'bright-data': {
command: 'npx',
args: ['-y', '@brightdata/mcp'],
env: {
'API_TOKEN': process.env.BRIGHTDATA_API_TOKEN || '',
'PRO_MODE': 'true' // remove to enable free mode
},
},
},
})이 코드는 @brightdata/mcp 패키지를 통해 Bright Data MCP를 실행합니다. 서버는 .env 파일의 BRIGHTDATA_API_TOKEN을 통해 설정된 API_TOKEN 환경 변수를 사용하여 계정 연결을 인증합니다.
'PRO_MODE': 'true' 설정은 선택 사항입니다. 이를 활성화하면 70개 이상의 전체 도구 세트에 접근할 수 있지만, 사용량 기반 요금이 발생할 수 있습니다.
Mastra 에이전트 파일에서 MCP 서버의 도구를 사용하려면 MCPClient를 가져오고 tools 매개변수에서 .listTools()를 호출합니다:
// src/mastra/agents/web-access-agent.ts
import { Agent } from '@mastra/core/agent'
import { Memory } from '@mastra/memory'
import { brightDataMcpClient } from '../mcp/bright-data-mcp-client'
export const webAccessAgent = new Agent({
id: 'web-access-agent',
name: 'Web Access Agent',
// omitted for brevity...
tools: {
...await brightDataMcpClient.listTools(),
},
memory: new Memory(),
})이제 Mastra 애플리케이션을 실행하면 Bright Data Web MCP 도구들을 확인할 수 있습니다:
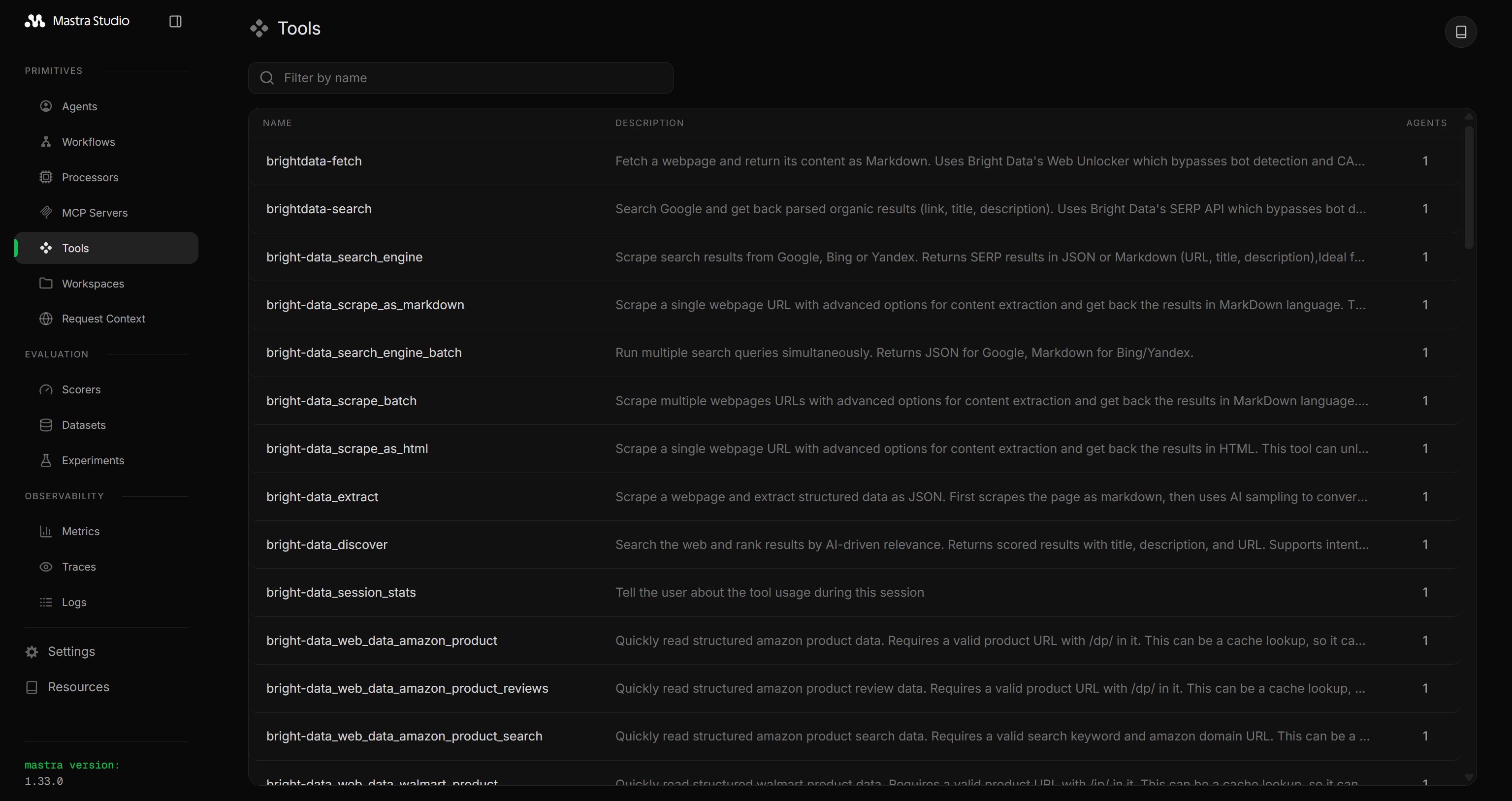
Web MCP는 Pro 모드로 구성된 경우 70개 이상의 도구를, Rapid(무료 티어) 모드에서는 5개의 도구를 노출합니다.
임무 완료! Mastra AI 에이전트가 이제 MCP를 통해 Bright Data 인프라에 연결되었습니다.
결론
이 블로그 게시물에서는 Mastra가 무엇인지, 그리고 제공하는 주요 기능을 이해했습니다. 특히 공식 Bright Data 도구 또는 Web MCP를 통해 이를 확장하는 방법과 이유를 살펴보았습니다.
이 통합은 Mastra 에이전트를 완전히 새로운 수준으로 끌어올립니다. AI 에이전트는 이제 웹 검색을 수행하고, 구조화된 데이터를 발견 및 추출하며, 실제 웹사이트와 상호작용할 수 있습니다.
오늘 무료 Bright Data 계정을 만들고 AI 친화적인 웹 데이터 도구 통합을 시작하세요!