

이 글에서 배울 내용:
- Microsoft TaskWeaver의 정의와 차별화된 특징
- Bright Data 서비스로 TaskWeaver를 확장하면 LLM 한계를 극복할 수 있는 이유.
- – 커스텀 플러그인을 통해 Bright Data를 TaskWeaver에 통합하는 방법.
자, 시작해 보겠습니다!
Microsoft TaskWeaver란 무엇인가요?
Microsoft TaskWeaver는 자연어 요청을 실행 가능한 Python 코드로 변환하는 오픈 소스 코드 우선 에이전트 프레임워크입니다. 궁극적인 목표는 복잡한 작업을 독립적으로 계획하고 실행하는 AI 에이전트를 구동하는 것입니다.
이 기술은 사용자의 프롬프트를 실행 가능한 단계로 분해하는 방식으로 작동합니다. 그런 다음 목표를 달성하기 위해 적절한 플러그인을 선택하고, 계획을 실행할 Python 코드를 생성하며, 안전한 환경에서 코드를 실행한 후 결과를 반환합니다.
TaskWeaver는 오픈소스이며 GitHub에서 6,000개 이상의 스타를 획득했습니다. 차별화된 핵심 기능은 다음과 같습니다:
- 코드 우선 접근 방식: 사용자 요청을 Python 코드로 변환하여 에이전트가 직접 솔루션을 생성하고 실행할 수 있게 합니다.
- 플러그인 생태계: 플러그인을 통해 특수 작업을 지원하여 프레임워크의 확장성을 극대화합니다.
- 풍부한 데이터 처리: DataFrames 같은 Python 데이터 구조를 기본적으로 지원하여 고급 데이터 분석의 문을 엽니다.
- 도메인 적응: 도메인별 지식을 통합하여 더 정밀한 결과를 도출합니다.
- 상태 유지 및 반사적 실행: 컨텍스트를 유지하며 자체 코드 실행을 반성하여 자가 교정할 수 있습니다.
- 안전하고 개방적: 안전한 환경에서 코드를 실행하면서도 오픈소스이며 즉시 사용 가능한 경험을 제공합니다.
자세한 내용은 공식 문서를 참조하십시오.
태스크위버에 웹 데이터 검색 기능을 추가해야 하는 이유
LLM은 훈련된 데이터에 본질적으로 제한됩니다. 텍스트, 코드, 멀티미디어를 생성할 수 있지만 출력은 항상 구식 지식에 기반합니다. 또한 인간 사용자와 같이 실시간 웹 페이지와 상호작용할 수 없습니다. 이 두 가지가 현재 AI 모델의 주요 제약사항입니다.
TaskWeaver는 에이전트가 맞춤형 플러그인과 통합될 수 있도록 하여 이러한 한계를 극복합니다. 플러그인은 LLM이 내장된 기능 이상의 작업을 수행하는 데 사용할 수 있는 특수 도구로 생각할 수 있으며, 효과적으로 그 범위와 실용성을 확장합니다.
이러한 플러그인을 호출함으로써 TaskWeaver 에이전트가 생성한 코드는 외부 환경과 상호작용하고 복잡한 작업을 수행할 수 있습니다. 예를 들어 Bright Data는 다음과 같은 강력한 도구들을 제공합니다:
- 웹 언락커 API: 프록시, 차단 해제, 헤더, CAPTCHA를 자동 처리하며 단일 요청으로 모든 웹사이트를 스크래핑하고 깨끗한 HTML 또는 마크다운을 수신합니다.
- SERP API: 차단에 대한 걱정 없이 Google, Bing 등 검색 엔진의 결과를 대규모로 수집합니다.
- 웹 스크래핑 API: Amazon, Instagram, LinkedIn, Yahoo Finance 등 유명 사이트에서 구조화되고 파싱된 데이터를 추출합니다.
- 기타 Bright Data 솔루션…
이러한 서비스에 연결되는 플러그인에 접근할 수 있는 TaskWeaver 에이전트는 웹을 검색하고 콘텐츠를 추출하며 인기 도메인에서 실시간으로 구조화된 데이터를 가져올 수 있습니다. 이를 통해 AI는 표준 LLM이 단독으로 수행할 수 있는 범위를 훨씬 뛰어넘는 복잡한 엔터프라이즈급 워크플로를 처리할 수 있습니다.
사용자 정의 플러그인을 통한 Bright Data와 TaskWeaver 통합 방법
이 튜토리얼 섹션에서는 웹 데이터 검색을 위해 TaskWeaver 에이전트를 Bright Data와 통합하는 방법을 배웁니다.
구체적으로, Bright Data Web Unlocker API에 연결하는 맞춤형 도구로 TaskWeaver 애플리케이션을 확장하는 방법을 살펴보게 됩니다. 이를 통해 코드 중심 에이전트가 인터넷상의 모든 웹 페이지에서 데이터를 가져와 필요에 따라 처리할 수 있습니다.
참고: 유사한 접근 방식은 다른 코드 우선 AI 기술 에이전트인 smoleagents와의 통합 가이드를 참조하십시오.
아래 지침을 주의 깊게 따르세요!
필수 조건
이 튜토리얼을 따라하려면 다음이 필요합니다:
- 로컬에 설치된Python 3.10 이상: TaskWeaver 및 플러그인 실행에 필수입니다.
- 로컬에 설치된Git: GitHub에서 TaskWeaver 저장소를 복제하는 데 필요합니다.
- Docker 데몬 실행: 코드 검증 기능 (선택 사항)에서 오류가 발생하지 않도록 실행 중이어야 합니다.
- OpenAI API 키 (또는 지원되는 다른 LLM의 API 키).
Bright Data를 사용하려면 다음도 필요합니다:
- API 키가 있는 Bright Data 계정.
- 계정에 구성된 웹 언락커(Web Unlocker) 영역.
Bright Data 설정은 별도의 단계에서 다루므로 당장은 걱정하지 마십시오.
1단계: Microsoft TaskWeaver 프로젝트 생성
터미널에서 TaskWeaver 프로젝트용 폴더를 생성하고 해당 폴더로 이동합니다:
mkdir taskweaver-bright-data-example
cd taskweaver-bright-data-example프로젝트 폴더 내에서 가상 환경을 생성합니다:
python -m venv .venv다음으로 활성화합니다. Linux/macOS에서는 다음 명령어를 실행하세요:
source .venv/bin/activate또는 Windows에서는 다음을 실행하세요:
.venvScriptsactivate이제 다음 명령어로 TaskWeaver를 설치하세요:
git clone https://github.com/microsoft/TaskWeaver.git
cd TaskWeaver
pip install -r requirements.txt이 명령어는 TaskWeaver/를 프로젝트 폴더에 복제하고, 방금 생성한 가상 환경에 pip를 통해 모든 종속성을 설치합니다.
TaskWeaver는 프로세스로 실행되며 플러그인, 구성 파일 및 세션 데이터를 저장할 프로젝트 디렉터리가 필요합니다. 방금 복제한 저장소의 TaskWeaver/project/ 디렉터리에 샘플 프로젝트가 제공됩니다: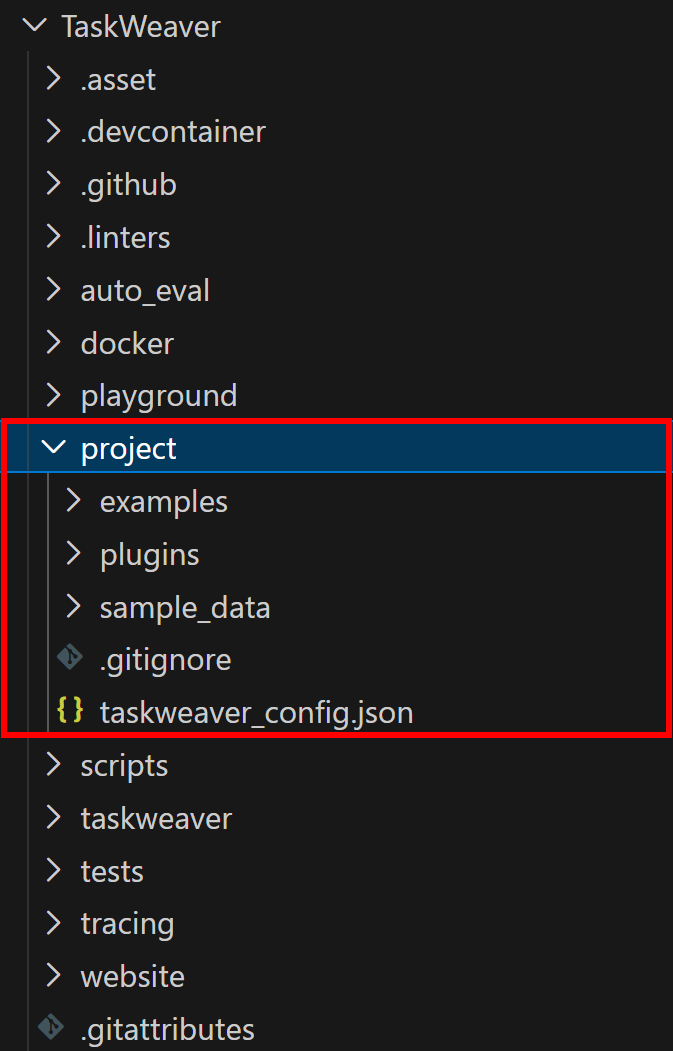
프로젝트 폴더의 내용을 작업 공간으로 복사하세요. 이후 taskweaver-bright-data-example/ 폴더는 다음과 같은 구조가 되어야 합니다:
taskweaver-bright-data-example/
├─ .venv/
├─ TaskWeaver/
├─ plugins/ # 플러그인 저장 폴더
├─ examples/
│ ├─ planner_examples/ # 예제 플래너 스크립트
│ └─ code_generator_examples/ # 예제 코드 생성기 스크립트
├─ sample_data/ # 선택적 샘플 데이터셋
├─ .gitignore
└─ taskweaver_config.json # 프로젝트 구성 파일특히, 일반적인 Microsoft TaskWeaver 프로젝트 디렉토리에는 공식 문서에 설명된 대로 특정 폴더와 파일이 포함됩니다.
Visual Studio Code 나 PyCharm과 같은 선호하는 Python IDE에서 taskweaver-bright-data-example/를 로드하세요.
가상 환경이 활성화된 상태에서 /TaskWeaver 폴더 내에서 다음 명령어로 애플리케이션을 시작하세요:
python -m taskweaver이렇게 하면 /TaskWeaver 폴더에서 TaskWeaver 프로세스가 시작되며, taskweaver-bright-data-example/ 폴더의 프로젝트 파일과 디렉터리를 로드합니다.
모든 것이 정상적으로 작동하면 터미널에 다음과 같은 메시지가 표시됩니다:
성공! Microsoft TaskWeaver가 작동합니다. 애플리케이션을 처음 실행한 후 다음과 같은 폴더가 생성됩니다:
workspace/: 프로젝트 세션 데이터를 저장합니다.logs/: 프로그램에서 생성된 로그 파일을 저장합니다.
참고: 지금 프롬프트를 입력하려고 하면 LLM 연결을 아직 구성하지 않았기 때문에 실패합니다. 다음 단계에서 이를 다룰 것입니다.
단계 #2: TaskWeaver에서 LLM 구성하기
TaskWeaver는 다양한 LLM을 지원합니다. 본 튜토리얼에서는 OpenAI 모델을 통합하지만, 다른 지원 LLM 제공업체에도 동일한 지침을 쉽게 적용할 수 있습니다.
TaskWeaver에서 GPT-4.1 mini 모델을 구성하려면 taskweaver-bright-data-example/ 내부의 taskweaver_config.json 파일에 다음 내용이 포함되어 있는지 확인하세요:
{
"llm.api_key": "<YOUR_OPENAI_API_KEY>",
"llm.model": "gpt-4.1-mini"
}<YOUR_OPENAI_API_KEY> 를 실제 OpenAI API 키로 교체하세요.
참고: 현재 시점에서 TaskWeaver는 GPT-5 모델을 지원하지 않습니다. GPT-5 모델을 구성하려고 하면 아래와 같은 오류가 발생합니다:
{'error': {'message': "Unsupported parameter: 'max_tokens' is not supported with this model. Use 'max_completion_tokens' instead.", 'type': 'invalid_request_error', 'param': 'max_tokens', 'code': 'unsupported_parameter'}}훌륭합니다! 이제 TaskWeaver 프로젝트가 OpenAI GPT-4.1 미니 모델로 구동되며 프롬프트 처리가 가능합니다.
3단계: Bright Data 웹 언락커 API 영역 설정
웹 스크래핑 기능을 위해 TaskWeaver 에이전트를 Bright Data에 연결하려면 먼저 몇 가지 사전 단계를 완료해야 합니다. 구체적으로, Bright Data 계정에 Web Unlocker 존을 구성하여 준비해야 합니다.
아직 계정이 없다면 Bright Data 계정을 생성하세요. 이미 계정이 있다면 로그인하세요. 계정에 접속한 후 “프록시 및 스크래핑” 페이지로 이동하세요. “내 영역” 섹션에서 테이블에 “Web Unlocker API”라고 표시된 행이 있는지 확인하세요: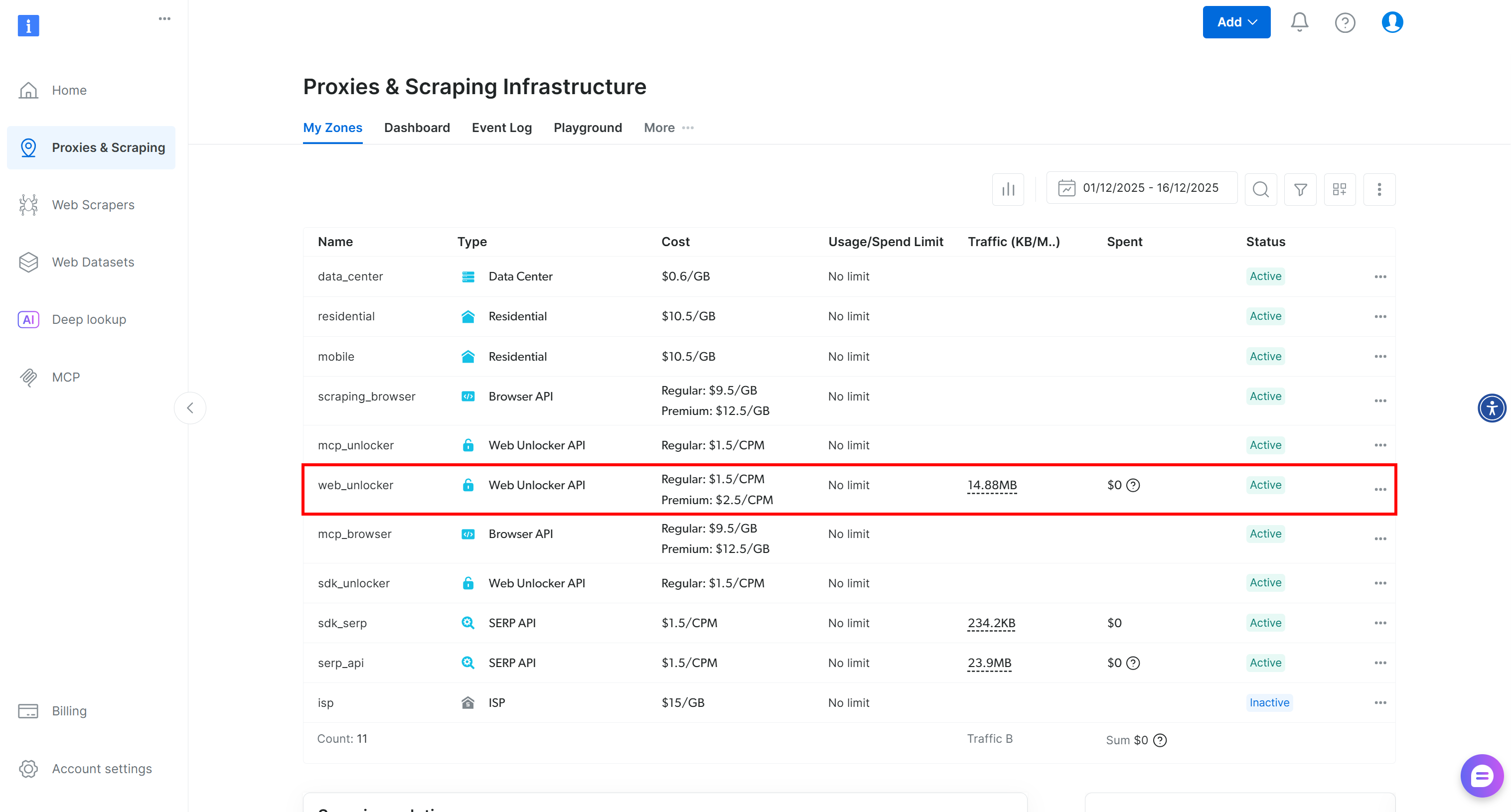
“Web Unlocker API” 라벨이 붙은 행이 보이지 않는다면, 해당 Bright Data 계정에 아직 해당 영역이 설정되지 않았다는 의미입니다. 생성하려면 아래로 스크롤하여 “Unlocker API” 섹션으로 이동한 후 “영역 생성”을 클릭하여 추가하세요: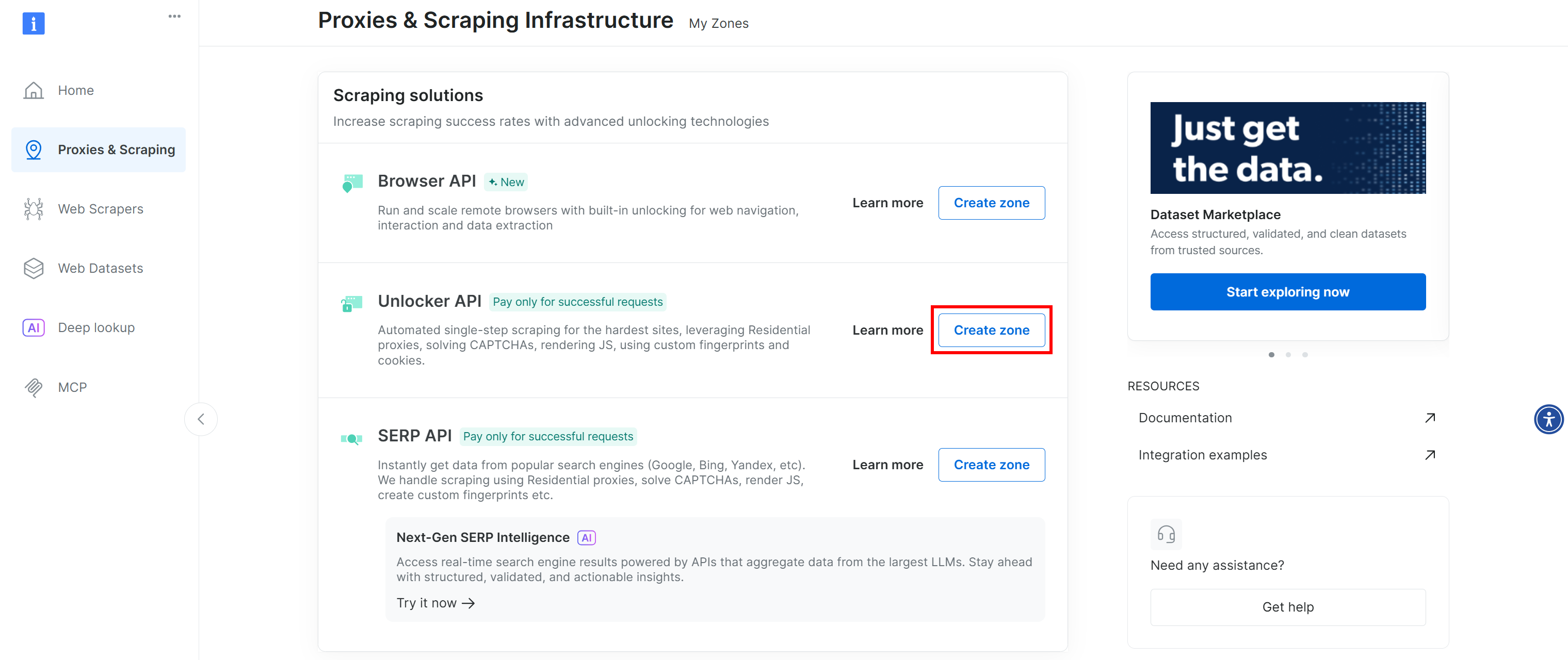
웹 언락커 API 존을 생성하고 web_unlocker (또는 원하는 이름)과 같은 이름을 지정하세요. 사용자 정의 플러그인에서 API를 통해 서비스에 접근할 때 필요하므로 존 이름을 기억해 두세요.
웹 언락커 영역 페이지에서 토글이 “활성”으로 설정되어 있는지 확인하여 영역이 활성화되었는지 확인하세요.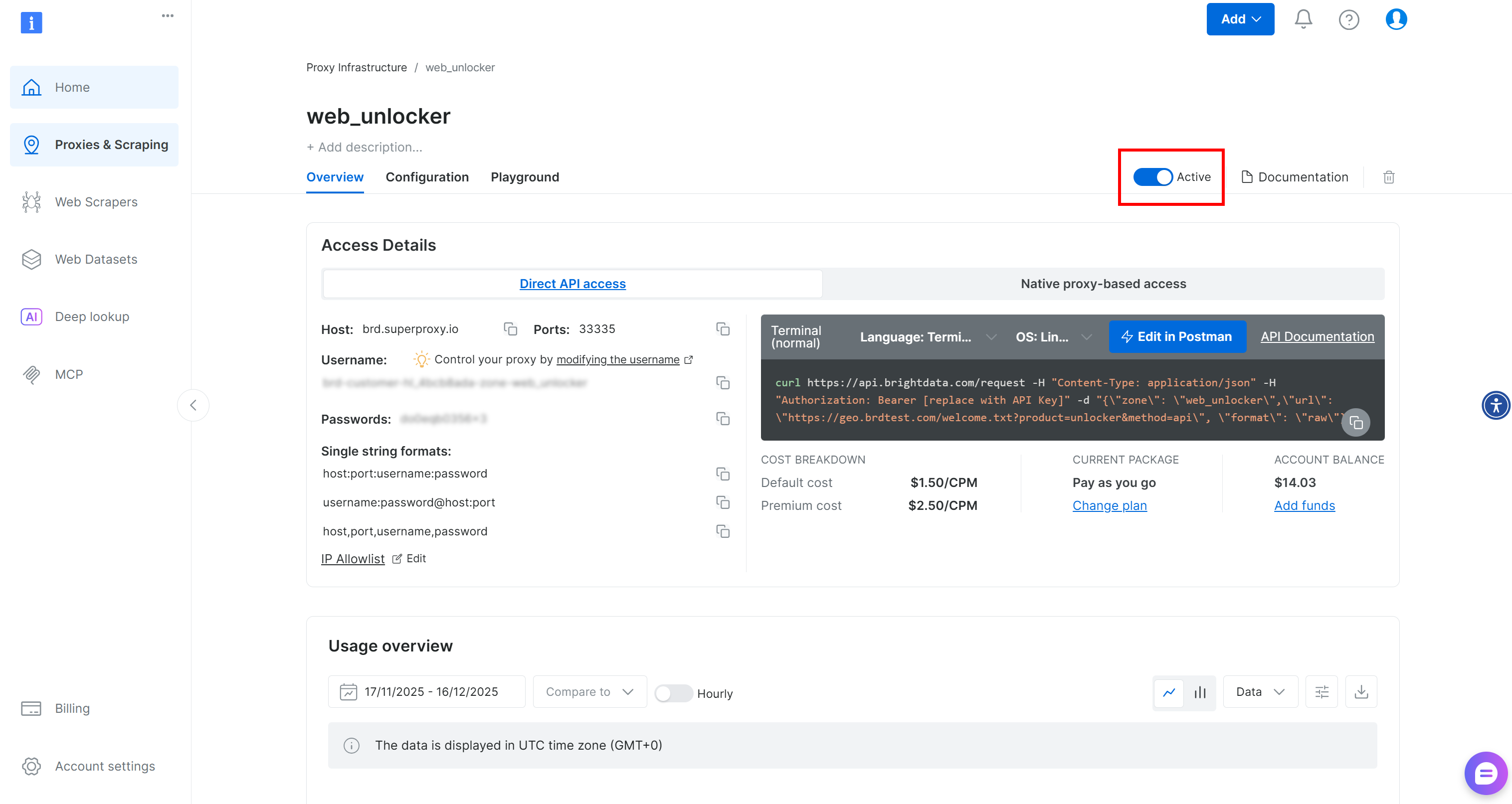
마지막으로 공식 가이드에 따라 Bright Data API 키를 생성하세요. 곧 필요할 수 있으니 안전하게 보관하십시오.
훌륭합니다! 이제 TaskWeaver 애플리케이션에서 Bright Data의 Web Unlocker API 플러그인을 사용하기 위한 모든 설정이 완료되었습니다.
4단계: Bright Data 통합을 위한 TaskWeaver 웹 언락커 플러그인 정의
플러그인은 TaskWeaver의 코드 인터프리터가 조율할 수 있는 단위입니다. 보다 구체적으로, 각 플러그인은 생성된 코드 내에서 호출될 수 있는 Python 함수입니다.
TaskWeaver에서 플러그인은 두 개의 파일로 구성됩니다:
- 플러그인 구현: 플러그인을 정의하는 Python 파일.
- 플러그인 스키마: 플러그인의 입력, 출력 및 메타데이터를 정의하는 YAML 파일.
두 파일 모두 프로젝트 내 plugins/ 하위 폴더에 위치해야 합니다.
이 경우 Bright Data Web Unlocker API를 호출하는 플러그인을 추가해야 합니다. 해당 API 엔드포인트 호출 방법에 대한 자세한 내용은 공식 문서를 참조하십시오.
활성 가상 환경에서 먼저 Requests와 같은 Python HTTP 클라이언트를 설치하세요:
pip install requests그런 다음 plugins/ 폴더 내에 web_unlocker.py 플러그인 파일을 추가합니다. 다음과 같이 정의하세요:
# taskweaver-bright-data-example/plugins/web_unlocker.py
import requests
from taskweaver.plugin import Plugin, register_plugin
@register_plugin
class WebUnlockerPlugin(Plugin):
def __call__(
self,
url: str,
data_format: str = None
):
# API 호출을 위한 구성값 읽기
bright_data_api_key = self.config.get("api_key")
zone = self.config.get("zone", "web_unlocker")
default_format = self.config.get("data_format", "markdown")
# Bright Data API 인증에 필요한 HTTP 헤더
headers = {
"Authorization": f"Bearer {bright_data_api_key}",
"Content-Type": "application/json"
}
# Bright Data Web Unlocker로 전송되는 요청 페이로드
payload = {
"zone": zone,
"url": url,
"format": "raw", # 응답을 본문에서 직접 받기 위해
"data_format": data_format or default_format
}
# Bright Data Web Unlocker API로 요청 전송
response = requests.post(
"https://api.brightdata.com/request",
json=payload,
headers=headers,
)
# 2xx가 아닌 HTTP 응답 시 예외 발생
response.raise_for_status()
# 응답 내용과 HTTP 상태 코드 추출
content = response.text
status = response.status_code
# LLM에 반환할 자연어 요약문
description = (
f"Bright Data Web Unlocker를 사용하여 페이지 성공적으로 가져옴 "
f"(HTTP {status}, {len(content)} 자)."
)
# 가져온 페이지를 세션 작업 공간에 아티팩트로 저장
self.ctx.add_artifact(
name="web_unlocker_page",
file_name="page_content.md",
type="txt",
val=content
)
# 원본 콘텐츠와 사람이 읽을 수 있는 설명을 모두 반환
return content, description이 플러그인은 Bright Data Web Unlocker API를 통해 웹 페이지를 가져옵니다. 먼저 self.config.get()을 사용하여 플러그인의 YAML 구성 섹션(곧 정의될 예정)에서 구성 값을 읽습니다.
그런 다음 HTTP 요청을 전송하고 오류를 확인한 후, 가져온 페이지를 self.ctx.add_artifact()를 통해 작업 공간에 아티팩트로 저장합니다. 이를 통해 실행 중 및 실행 후 결과를 검토할 수 있습니다. 마지막으로 LLM이 사용할 수 있도록 원본 페이지 콘텐츠와 사람이 읽을 수 있는 요약본을 모두 반환합니다.
참고: 기본적으로 Bright Data Web Unlocker API 호출은 웹 페이지 콘텐츠를 마크다운 형식으로 반환하도록 설정되어 있어 LLM 입력에 이상적입니다. 이는 AI 통합을 지원하고 콘텐츠 처리를 간소화하기 위해 Web Unlocker API가 제공하는 유용한 기능입니다.
대단하네요! TaskWeaver 에이전트가 이 플러그인을 사용하려면 플러그인의 YAML 스키마 파일도 지정해야 합니다.
단계 #5: 플러그인 스키마 정의 계속하기
플러그인 스키마는 TaskWeaver 내 LLM이 플러그인을 이해하고 호출하는 방식을 지정합니다. 이는 YAML 형식으로 작성해야 하므로, plugins/ 폴더 내에 다음과 같이 web_unlocker.yaml 파일을 생성하세요:
# taskweaver-bright-data-example/plugins/web_unlocker.yaml
name: web_unlocker
enabled: true
plugin_only: true
description: >-
Bright Data Web Unlocker API를 사용하여 웹 페이지를 가져오고 잠금을 해제합니다.
반봇 보호 기능을 우회하고 깨끗한 페이지 콘텐츠를 반환합니다.
parameters:
- name: url
type: str
required: true
description: 가져올 웹 페이지의 전체 URL.
- name: data_format
type: str
required: false
description: 페이지 콘텐츠의 출력 형식("markdown" 또는 생 HTML, 생략 시 기본값).
returns:
- name: content
type: str
description: 잠금 해제된 페이지 콘텐츠.
- name: description
type: str
description: 가져오기 작업에 대한 자연어 요약.
configurations:
api_key: <YOUR_BRIGHT_DATA_API_KEY> # Bright Data API 키로 대체
zone: web_unlocker # Web Unlocker 영역 이름으로 대체
data_format: markdown위의 YAML 파일은 앞서 정의한 WebUnlockerPlugin 클래스의 __call__() 함수 입력값과 출력값을 설명합니다. 이 스키마 덕분에 TaskWeaver의 LLM은 web_unlocker.py 플러그인의 작동 방식과 생성된 Python 코드에서 이를 호출하는 방법을 이해할 수 있습니다.
구성 섹션에서 Bright Data API 키, Web Unlocker 영역 이름 및 원하는 출력 형식을 지정하세요. api_key 및 zone 필드를 3단계에서 설정한 값으로 대체하세요.
자, 이제 완료되었습니다! TaskWeaver와 Bright Data의 연동이 끝났습니다.
참고: SERP API나 웹 스크래핑 API 등 다른 Bright Data 서비스도 동일한 방식으로 API를 통해 통합할 수 있습니다.
6단계: TaskWeaver 에이전트 테스트
이제 TaskWeaver의 코드 우선 에이전트가 Bright Data 기반 플러그인을 호출할 수 있는지 확인할 차례입니다. 생성된 코드가 플러그인 함수를 호출하고 Web Unlocker API가 제공하는 웹 잠금 해제 기능을 액세스할 수 있어야 합니다.
테스트를 위해 다음과 같은 프롬프트를 시도해 보세요:
"https://modelcontextprotocol.io/specification/2025-11-25/changelog"에서 최신 MCP 변경 로그를 가져와 변경 사항을 나열하세요.일반적인 대규모 언어 모델(LLM)로는 URL로 이동하여 정보를 추출하는 맞춤형 도구가 필요하므로 이 작업은 불가능합니다. 그러나 TaskWeaver와 Bright Data를 함께 사용하면 에이전트가 이를 처리할 수 있습니다!
TaskWeaver 애플리케이션을 다음 명령어로 실행하세요:
python -m taskweaver프롬프트를 붙여넣고 Enter를 누르세요. 다음과 같은 화면이 표시됩니다: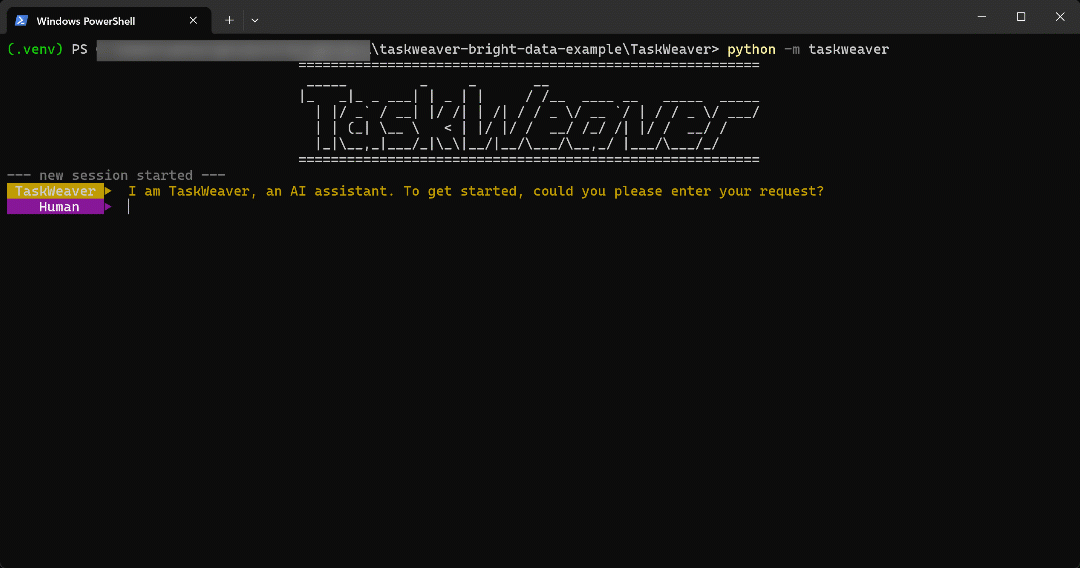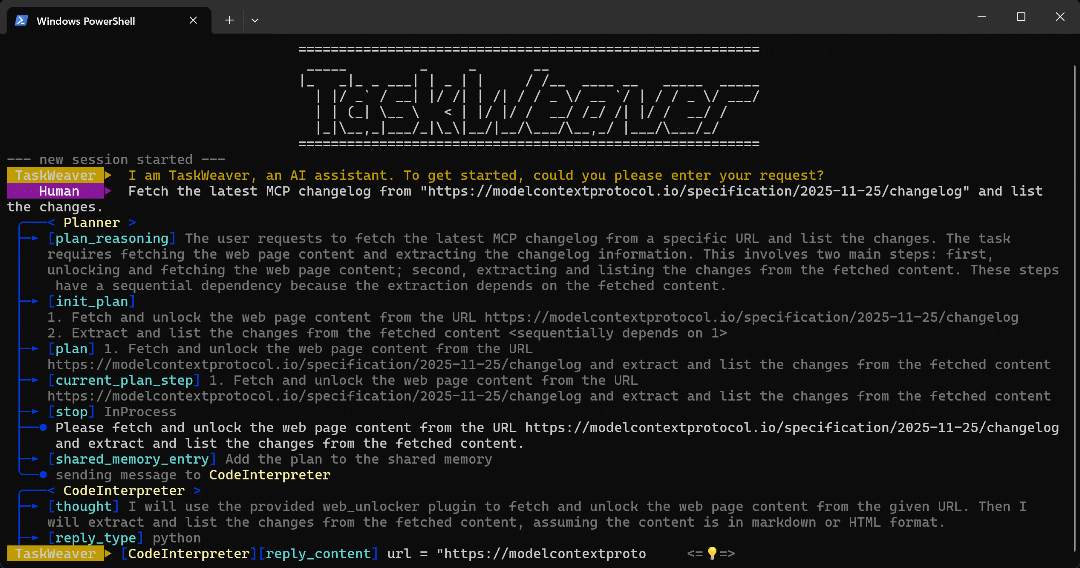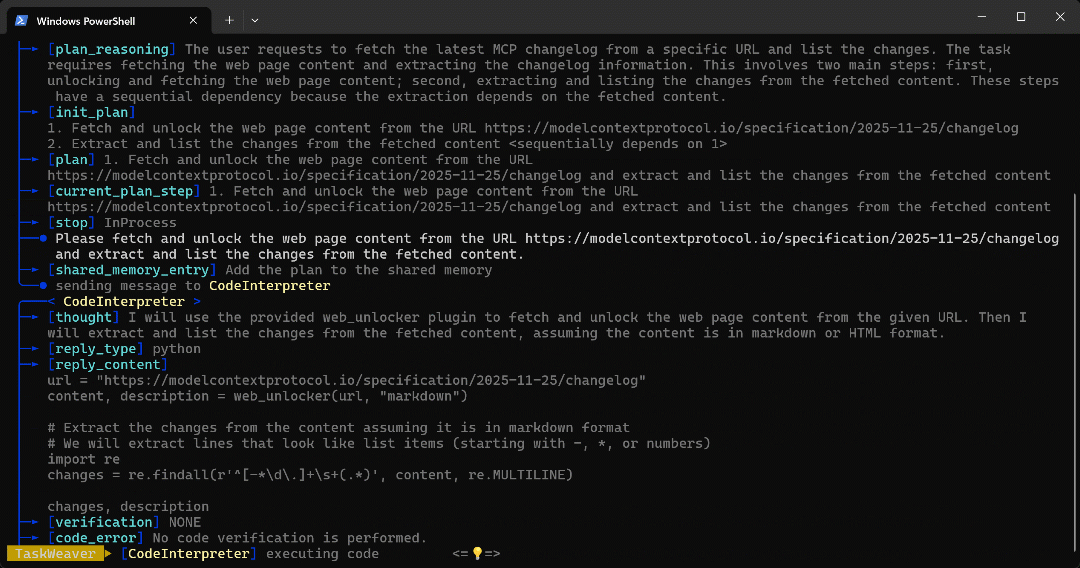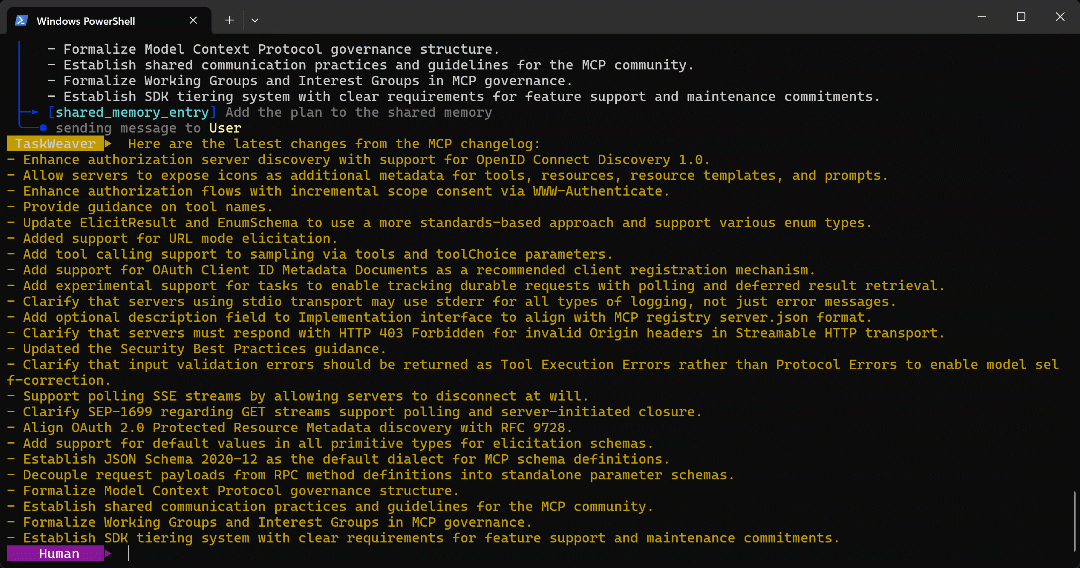
보시다시피 에이전트는:
- TaskWeaver
Planner는작업을 수행하기 위한 계획을 먼저 생성합니다. - 이 계획은 목표 달성을 위한 Python 코드를 생성하는 내부 에이전트인
CodeInterpreter로전송됩니다. - Python 코드는 Web Unlocker API 플러그인을 호출한 후 정규 표현식을 사용하여 문서 내 모든 글머리 기호를 추출합니다.
- 코드가 실행되면 Web Unlocker API를 통해 원하는 데이터를 가져와
self.ctx.add_artifact()로 설정된 작업 공간 폴더에 저장합니다. - URL로 지정된 페이지의 내용을 포함하는 반환된 마크다운 데이터는
플래너로다시 전송되어 다음 단계로 진행됩니다. - 대상 페이지에서 추출된 글머리 기호 목록이 의도한 대로 사용자에게 반환됩니다.
훌륭합니다! TaskWeaver 에이전트가 완벽하게 작동합니다. 생성된 출력을 살펴보는 시간을 가져봅시다.
단계 #7: 출력물 살펴보기
에이전트 실행의 최종 출력은 다음과 같습니다:
대상 페이지에서 확인할 수 있듯이, 이 목록은 MCP 변경 로그에 있는 정보와 정확히 일치합니다: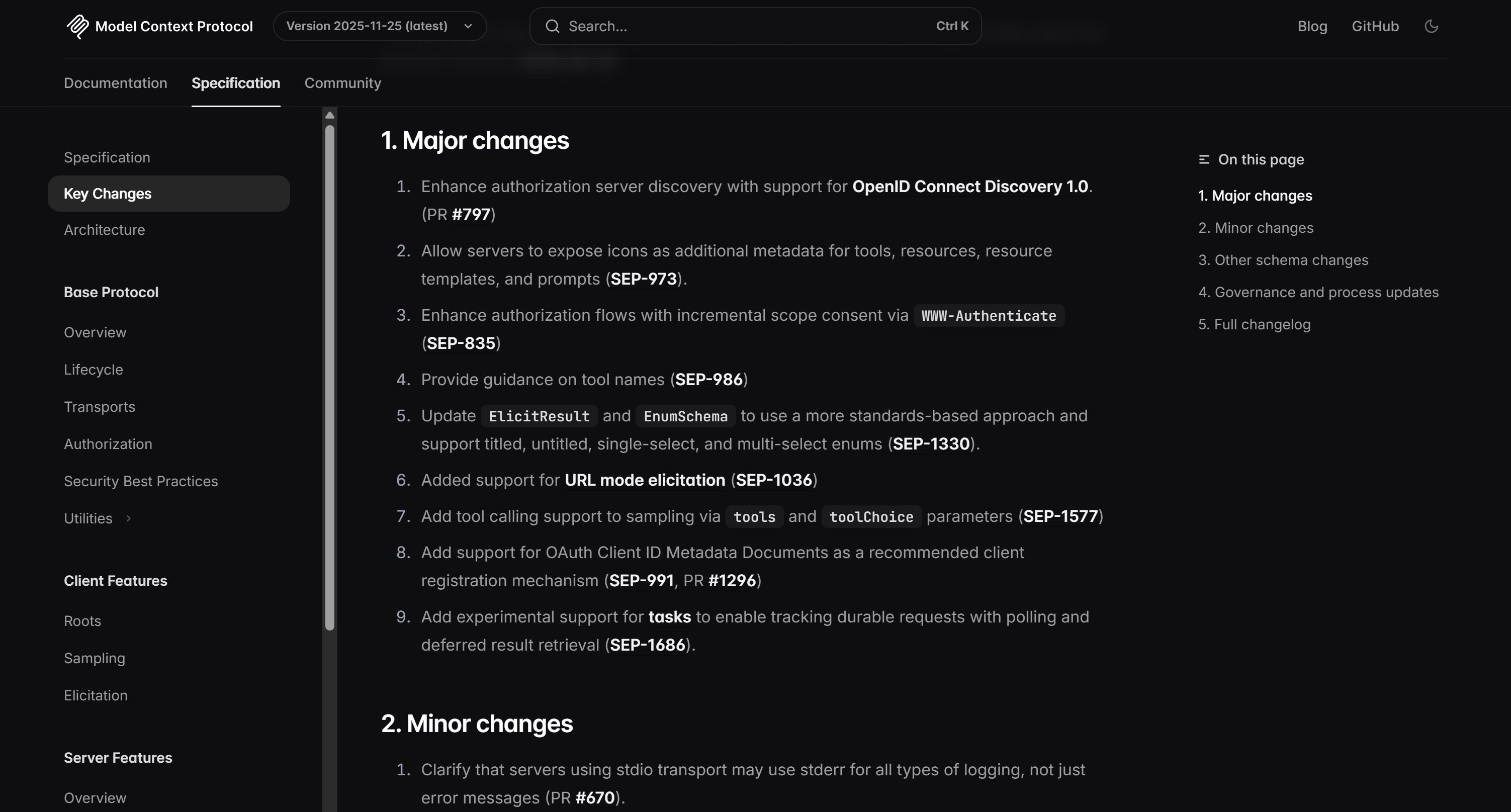
특히 에이전트는 다음 파이썬 코드를 통해 출력을 생성했습니다:
url = "https://modelcontextprotocol.io/specification/2025-11-25/changelog"
content, description = web_unlocker(url, "markdown")
# 콘텐츠가 마크다운 형식이라고 가정하고 변경 사항 추출
# 목록 항목처럼 보이는 줄(-, * 또는 숫자로 시작하는)을 추출합니다
import re
changes = re.findall(r'^[-*d.]+s+(.*)', content, re.MULTILINE)
changes, description생성된 스니펫이 web_unlocker() 함수 플러그인을 호출하여 입력 페이지를 마크다운 형식으로 가져오는 방식을 확인하세요. 그런 다음 간단한 정규 표현식을 사용하여 관련 정보를 추출합니다.
웹 언락커 API가 페이지 콘텐츠를 마크다운 형식으로 반환했는지 확인하려면 workspace/ 폴더 내 파일을 검사하세요. 각 에이전트 실행 시 workspace/sessions/ 하위에 세션 하위 폴더가 생성되며, 해당 실행에 대한 하위 폴더가 포함됩니다.
cwd/ 폴더에서 self.ctx.add_artifact() 호출을 통해 생성된 .md 파일을 찾을 수 있습니다. 이 파일을 열어 Web Unlocker API에서 반환된 내용을 확인하세요: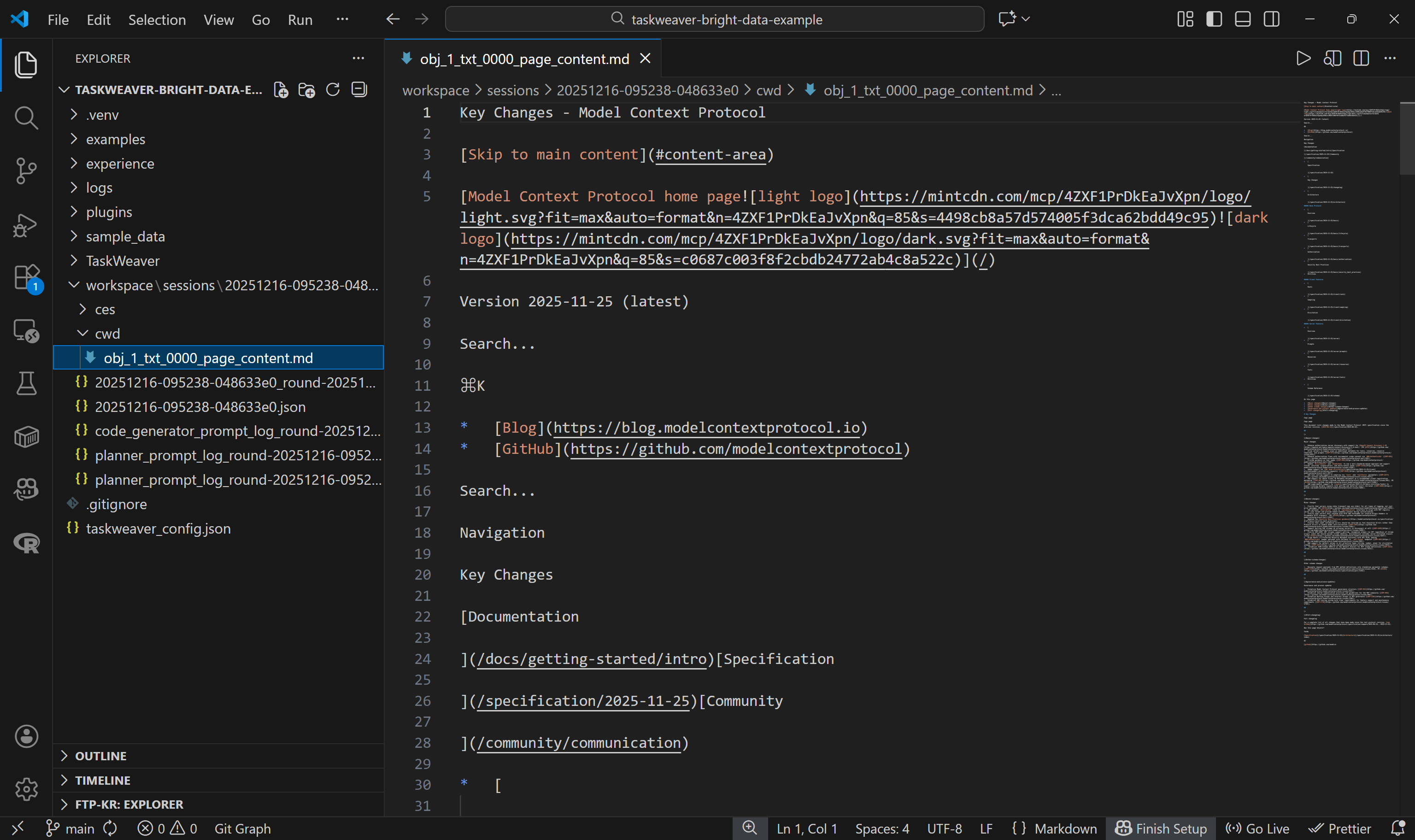
이는 대상 페이지의 마크다운 버전과 정확히 일치하므로, 생성된 Python 코드의 Web Unlocker API 함수가 완벽하게 작동했음을 의미합니다. 와우!
이제 에이전트를 한 단계 발전시켜 보세요. 더 현실적이고 기업 환경에 적합한 시나리오를 처리하기 위해 다양한 프롬프트로 실험해 보십시오.
자, 이제 완성되었습니다! TaskWeaver를 사용하여 Bright Data와 통합된 코드 우선 AI 에이전트를 성공적으로 구축했습니다. 이 에이전트는 모든 웹 페이지에서 AI 활용 가능한 데이터를 안정적으로 추출할 수 있습니다.
다음 단계
여기서 보여준 통합은 기본적인 예시입니다. TaskWeaver 에이전트를 한 단계 업그레이드하여 실제 운영 환경에 적합하게 만들려면 다음 개선 사항을 고려하세요:
- 추가 Bright Data 솔루션(예: SERP API)을 통합하여 에이전트가 웹 검색 및 실시간 데이터 수집 기능을 갖도록 하세요.
- 에이전트의 개발, 테스트, 모니터링을 간소화하기 위한 플레이그라운드로웹 UI를 구성하세요.
- 프롬프트 압축, 자동 플러그인 선택,텔레메트리/관측 가능성 같은 고급 기능을 활성화하여 성능, 확장성 및 유지보수성을 개선하세요.
결론
이 튜토리얼에서는 외부 API에 연결하는 커스텀 플러그인을 통해 Bright Data를 TaskWeaver에 통합하는 방법을 살펴보았습니다.
이 설정을 통해 실시간 웹 검색, 구조화된 데이터 추출, 실시간 웹 피드 액세스 및 자동화된 웹 상호 작용이 가능해집니다. AI를 위한 Bright Data의 전체 서비스 제품군을 활용하면 코드 우선 AI 에이전트의 모든 잠재력을 최대한 활용할 수 있습니다!
지금 바로 Bright Data 계정을 무료로 생성하고 AI 지원 웹 데이터 솔루션을 직접 사용해 보세요.




