

이 가이드 전반에 걸쳐 LlamaIndex를 사용하여 Bright Data 도구로 데이터를 추출할 것입니다. 이 튜토리얼을 완료하면 다음 작업을 모두 수행할 수 있게 됩니다.
- 웹사이트 데이터를 마크다운 형식으로 추출하기
- 웹페이지 스크린샷 촬영
- 애플리케이션 내에서 Google 검색 수행
- 데이터피드와 Bright Data의 웹 스크레이퍼 API를 사용하여 필요 시 컬렉션 트리거
소개: LlamaIndex란 무엇인가?
AI 시대 이전에는 데이터 수집이 취약하고 유지보수가 까다로운 과정이었습니다. 사이트 레이아웃의 단일 변경만으로도 전체 파이프라인이 중단될 수 있었습니다. 현대에는 올바른 도구를 사용한다면 더 이상 그렇지 않습니다.
LlamaIndex는 언어 모델을 외부 도구 및 데이터 소스와 연결합니다. 이러한 도구 세트와 최소한으로 작동하도록 설계된 기본 모델이 미리 포함되어 있습니다. 특히 저희의 경우, LlamaIndex는 Bright Data의 MCP 서버와 통합될 수 있습니다.
다음 몇 섹션에서는 LlamaIndex의 Bright Data 툴셋 기능을 단계별로 살펴보겠습니다. Python이 설치되어 있는지 확인하세요.
필수 조건
여기서 요구되는 조건은 놀라울 정도로 가볍습니다. 간단한 스크래핑 작업에는 LLM조차 필요하지 않습니다. LlamaIndex와 Bright Data API 키만 있으면 됩니다!
LlamaIndex
LlamaIndex는 다음 명령어로 설치할 수 있는 완전한 도구 모음을 제공합니다. 웹 스크래핑만 원한다면 반드시 필요한 것은 아닙니다.
pip install llama-index다음 명령어를 통해 pip로 Bright Data Tools를 설치할 수 있습니다.
pip install llama-index-tools-brightdataBright Data
먼저 Bright Data 계정이 필요합니다. 이 링크를 통해 Unlocker 무료 체험판에 가입할 수 있습니다. 계정을 생성한 후 API 키를 저장하세요.
API 키는 Bright Data의 “프록시” 대시보드 또는 사용자 설정에서 찾을 수 있습니다.

LlamaIndex를 사용한 스크래핑
BrightDataToolSpec: Bright Data MCP로의 연결 다리
LlamaIndex는 BrightDataToolSpec 클래스에 대한 접근 권한을 제공합니다. 아래 코드 조각은 모든 도구 사용을 설정합니다. API 키를 본인 것으로, 존 이름을 개인 존 중 하나로 반드시 교체하세요.
from llama_index.tools.brightdata import BrightDataToolSpec
brightdata = BrightDataToolSpec(
api_key="your-api-key",
zone="your-zone-name")마크다운으로 스크랩하기
아래 코드 조각은 어떤 페이지든 스크랩하여 그 내용을 마크다운 형식으로 반환하도록 설정합니다. scrape_as_markdown() 메서드가 모든 작업을 처리해 줍니다.
from llama_index.tools.brightdata import BrightDataToolSpec
brightdata = BrightDataToolSpec(
api_key="your-api-key",
zone="your-zone-name")
result = brightdata.scrape_as_markdown(url="https://www.amazon.com")
print(result.text)명령어 실행 결과 샘플입니다. 보시다시피 아마존 데이터를 성공적으로 스크랩하여 마크다운으로 변환했습니다.

## 건너뛰기
* [ 메인 콘텐츠](#skippedLink)
---
## 키보드 단축키
* 검색
alt + /
* 장바구니
shift + alt + C
* 홈
shift + alt + H
* 주문
shift + alt + O
* 단축키 표시/숨기기
shift + alt + Z
항목 간 이동 시 키보드의 위/아래 화살표 키를 사용하세요.
[ .us ](/ref=nav%5Flogo)
Bothell 98011 지역 배송 위치 업데이트
전체
검색할 부서를 선택하세요 모든 부서 Alexa Skills 전체 베스트 펫 아마존 오토스 아마존 디바이스 아마존 프레쉬 아마존 글로벌 스토어 아마존 홀 아마존 원 메디컬 아마존 약국 아마존 리셀 가전제품 앱 & 게임 예술, 공예 & 바느질 오디블 도서 & 오리지널 자동차 부품 & 액세서리 베이비 뷰티 & 퍼스널 케어 도서 CD & 바이닐 휴대폰 & 액세서리 의류, 신발 & 주얼리 여성 의류, 신발 & 주얼리 남성 의류, 신발 & 주얼리 여아 의류, 신발 & 주얼리 남아 의류, 신발 & 주얼리 유아 의류, 신발 & 주얼리 수집품 & 미술품 컴퓨터 신용카드 및 결제 카드 디지털 음악 전자제품 정원 & 야외 기프트 카드 식료품 & 고급 식품 수제품 건강, 가정 및 유아용품 가정 및 비즈니스 서비스 가정 및 주방 산업 및 과학 프라임 회원 전용 킨들 스토어 여행 가방 및 여행 용품 럭셔리 스토어 잡지 구독 메트로폴리탄 마켓 영화 및 TV 악기 사무용품 애완동물 용품 프리미엄 뷰티 프라임 비디오 당일 배송 스토어 스마트 홈 소프트웨어 스포츠 및 아웃도어 정기 구독 및 할인 정기 구독 박스 공구 및 주택 개조 장난감 및 게임 10달러 미만 비디오 게임 홀푸드 마켓
아마존 검색
[ EN ](/customer-preferences/edit?ie=UTF8&preferencesReturnUrl=%2F&ref%5F=topnav%5Flang)
[ 안녕하세요, 로그인 계정 및 목록 ](https://www.amazon.com/ap/signin?openid.pape.max%5Fauth%5Fage=0&openid.return%5Fto=https%3A%2F%2Fwww.amazon.com%2F%3F%5Fencoding%3DUTF8%26ref%5F%3Dnav%5Fya%5Fsignin&openid.identity=http%3A%2F%2Fspecs.openid.net%2Fauth%2F2.0%2Fidentifier%5Fselect&openid.assoc%5Fhandle=usflex&openid.mode=checkid%5Fsetup&openid.claimed%5Fid=http%3A%2F%2Fspecs.openid.net%2Fauth%2F2.0%2Fidentifier%5Fselect&openid.ns=http%3A%2F%2Fspecs.openid.net%2Fauth%2F2.0)
[ 반품 및 주문 ](/gp/css/order-history?ref%5F=nav%5Forders%5Ffirst) [ 0 장바구니 ](/gp/cart/view.html?ref%5F=nav%5Fcart)
[ 전체 ](/gp/site-directory?ref%5F=nav%5Fem%5Fjs%5Fdisabled)
* [아마존 구매 내역](/haul/store?ref%5F=nav%5Fcs%5Fhul%5Fdisb)
* [의료용품](https://health.amazon.com/prime?ref%5F=nav%5Fcs%5Fall%5Fhealth%5Fingress%5Fonem%5Fh)
* [삭스](/luxurystores/saks?ref%5F=nav%5Fcs%5Fsaks%5Fdisc)
* [베스트셀러](/gp/bestsellers/?ref%5F=nav%5Fcs%5Fbestsellers)
* [아마존 베이직스](/Amazon%5FBasics?channel=discovbar&field-lbr%5Fbrands%5Fbrowse-bin=AmazonBasics&ref%5F=nav%5Fcs%5Famazonbasics)
* [신규 출시 상품](/gp/new-releases/?ref%5F=nav%5Fcs%5Fnewreleases)
* [레지스트리](/gp/browse.html?node=16115931011&ref%5F=nav%5Fcs%5Fregistry)
* [식료품](/fmc/learn-more?ref%5F=nav%5Fcs%5Fgroceries)
* [오늘의 특가](/deals?ref%5F=nav%5Fcs%5Fgb)
* [기프트 카드](/gift-cards/b/?ie=UTF8&node=2238192011&ref%5F=nav%5Fcs%5Fgc)
* [스마트 홈](/Smart-Home/b/?ie=UTF8&node=6563140011&ref%5F=nav%5Fcs%5Fsmart%5Fhome)
* [음악](/music/player?ref%5F=nav%5Fcs%5Fmusic)
* [프라임](/prime?ref%5F=nav%5Fcs%5Fprimelink%5Fnonmember)
* [고객 서비스](/gp/help/customer/display.html?nodeId=508510&ref%5F=nav%5Fcs%5Ffs%5Fhub%5Fnavbar%5Fc)
* [도서](/books-used-books-textbooks/b/?ie=UTF8&node=283155&ref%5F=nav%5Fcs%5Fbooks)
* [약국](https://pharmacy.amazon.com/?nodl=0&ref%5F=nav%5Fcs%5Fpharmacy)
* [럭셔리 스토어](/luxurystores?ref%5F=nav%5Fcs%5Fluxury)
* [아마존 홈](/home-garden-kitchen-furniture-bedding/b/?ie=UTF8&node=1055398&ref%5F=nav%5Fcs%5Fhome)
* [패션](/amazon-fashion/b/?ie=UTF8&node=7141123011&ref%5F=nav%5Fcs%5Ffashion)
* [완구 & 게임](/toys/b/?ie=UTF8&node=165793011&ref%5F=nav%5Fcs%5Ftoys)
* [뷰티 & 퍼스널 케어](/Beauty-Makeup-Skin-Hair-Products/b/?ie=UTF8&node=3760911&ref%5F=nav%5Fcs%5Fbeauty)
* [판매](/b/?%5Fencoding=UTF8&ld=AZUSSOA-sell&node=12766669011&ref%5F=nav%5Fcs%5Fsell)
* [선물 가게](/gcx/Gifts-for-Everyone/gfhz/?ref%5F=nav%5Fcs%5Fgiftfinder)
* [자동차](/automotive-auto-truck-replacements-parts/b/?ie=UTF8&node=15684181&ref%5F=nav%5Fcs%5Fautomotive)
* [홈 인테리어](/Tools-and-Home-Improvement/b/?ie=UTF8&node=228013&ref%5F=nav%5Fcs%5Fhi)
* [컴퓨터](/computer-pc-hardware-accessories-add-ons/b/?ie=UTF8&node=541966&ref%5F=nav%5Fcs%5Fpc)
* [스포츠 & 아웃도어](/sports-outdoors/b/?ie=UTF8&node=3375251&ref%5F=nav%5Fcs%5Fsports)
[프라임 데이는 7월 8일부터 11일까지입니다](/primeday/?%5Fencoding=UTF8&ref%5F=nav%5Fswm%5FUS%5FPD25%5FLU%5FGW%5FSWM%5FAnnounce&pf%5Frd%5Fp=72020f4f-d636-4d60-9e39-399532eba237&pf%5Frd%5Fs=nav-sitewide-msg-text&pf%5Frd%5Ft=4201&pf%5Frd%5Fi=navbar-4201&pf%5Frd%5Fm=ATVPDKIKX0DER&pf%5Frd%5Fr=JA1EM1AGN54HEE871RFM) 스크린샷 찍기
웹 스크래핑 시 스크린샷은 또 다른 훌륭한 도구입니다. 대부분의 현대적 대규모 언어 모델(LLM)은 이미지를 보고 해석할 수 있습니다. 아래 코드 조각에서는 get_screenshot() 메서드로 페이지의 스크린샷을 찍습니다.
from llama_index.tools.brightdata import BrightDataToolSpec
brightdata = BrightDataToolSpec(
api_key="your-api-key",
zone="your-zone-name")
result = brightdata.get_screenshot(url="https://example.com", output_path="my-screenshot.png")아래 스크린샷은 BrightDataToolSpec에서 생성되었습니다. 이는 파이썬 전체에서 가장 쉬운 스크린샷 생성 방법일 수 있습니다.
검색 엔진
이전 도구들과 마찬가지로, search_engine()이라는 간단한 메서드를 사용하여 검색 엔진을 호출합니다. 기본적으로 Google을 사용하지만 원하는 검색 엔진을 사용할 수 있습니다. SERP 쿼리 매개변수에 대한 자세한 내용은 여기에서 확인할 수 있습니다.
사용 가능한 검색 엔진은 다음과 같습니다.
- Bing
- 얀덱스
- 덕덕고
from llama_index.tools.brightdata import BrightDataToolSpec
brightdata = BrightDataToolSpec(
api_key="your-api-key",
zone="mcp_unlocker")
result = brightdata.search_engine(
query="Top News Articles"
)
with open("output.json", "w") as file:
json.dump(json.loads(result.json()), file, indent=4)데이터를 JSON 파일에 덤프하기 전에 json.loads() 를 호출하는 점에 유의하세요. .json()을 사용하더라도 LlamaIndex는 JSON을 문자열로 출력합니다. 딕셔너리처럼 처리하려면 json.loads() 가 이를 전통적인 JSON 객체로 변환해 줍니다.
스크레이퍼가 작성하는 JSON 파일의 일부를 보여드립니다.
{
"id_": "34bcf1ea-998a-48ce-beb2-0d6feff950e1",
"embedding": null,
"metadata": {
"query": "Top News Articles",
"engine": "google",
"url": "https://www.google.com/search?q=Top%20News%20Articles&num=10"
},
"excluded_embed_metadata_keys": [],
"excluded_llm_metadata_keys": [],
"relationships": {},
"metadata_template": "{key}: {value}",
"metadata_separator": "n",
"text_resource": {
"embeddings": null,
"text": "# 접근성 링크nn메인 콘텐츠로 건너뛰기[접근성 도움말](https://support.google.com/websearch/answer/181196?hl=en)nn접근성 피드백nn[](https://www.google.com/webhp?hl=en&ictx=0&sa=X&ved=0ahUKEwizmMaNvoCOAxUmmYkEHa58MagQpYkNCAo)nn검색 상자로 이동하려면 / 키를 누르세요nn주요 뉴스 기사nn[로그인](https://accounts.google.com/ServiceLogin?hl=en&passive=true&continue=https://www.google.com/search%3Fq%3DTop%2BNews%2BArticles%26num%3D10%26oq%3DTop%2BNews%2BArticles%26uule%3Dw%2BCAIQICINVW5pdGVkIFN0YXRlcw%26hl%3Den%26sourceid%3Dchrome%26ie%3DUTF-8&ec=GAZAAQ)nn# 필터 및 주제nn[AI 모드](/search?q=Top+News+Articles&sca%5Fesv=62890ff6c1b2e448&hl=en&udm=50&웹 스크레이퍼 API
스크래핑 API를 사용하면 필요에 따라 수집을 트리거하는 데이터 피드를 생성할 수 있습니다. 아래 코드에서는 web_data_feed()를 사용하여 스크래퍼 API에서 수집을 트리거합니다.
from llama_index.tools.brightdata import BrightDataToolSpec
brightdata = BrightDataToolSpec(
api_key="your-api-key",
zone="mcp_unlocker")
result = brightdata.web_data_feed(
source_type="linkedin_person_profile",
url="https://www.linkedin.com/in/williamhgates/",
timeout=600,
polling_interval=30)
print(result)잠시 후 로그 페이지로 이동하세요. 모든 컬렉션이 기록되어 버튼 클릭 한 번으로 다운로드할 준비가 된 것을 확인할 수 있습니다.
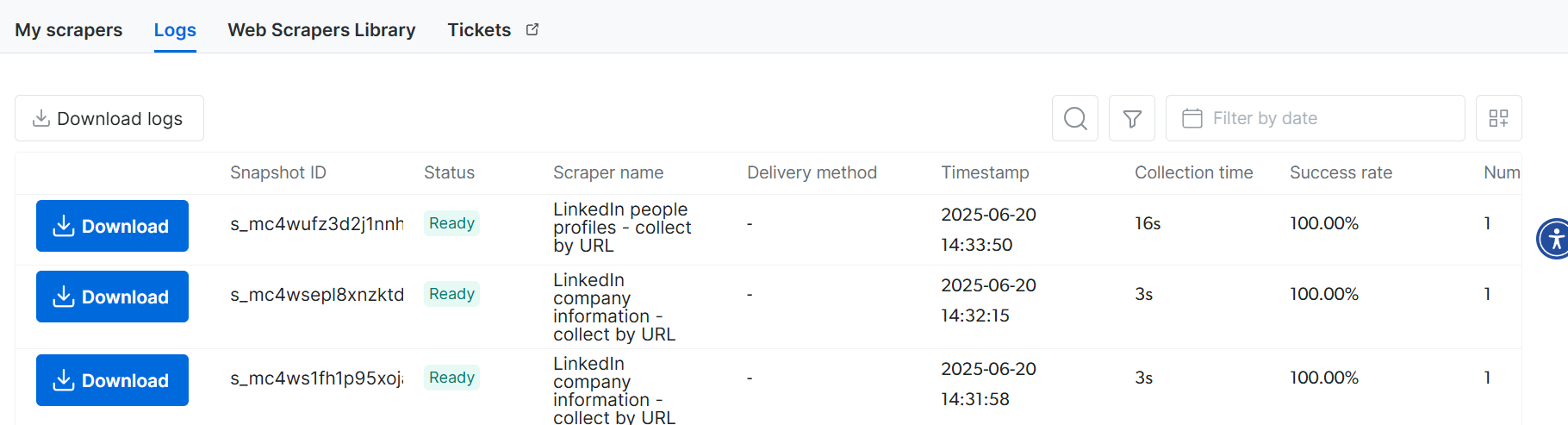
결론
이제 웹 스크래핑 실력이 한 단계 업그레이드되었으며 작업량을 획기적으로 줄였습니다. LlamaIndex, Bright Data, 그리고 몇 줄의 파이썬 코드만으로 웹에서 원하는 거의 모든 데이터를 추출할 수 있습니다.
마크다운 추출, 스크린샷 캡처, Google 검색 실행 또는 전체 스크래핑 작업 실행 등 LlamaIndex와 Bright Data를 통해 귀중한 데이터를 수집할 수 있는 힘을 얻으세요.
다음 단계로 나아가실 준비가 되셨나요? 이 강력한 도구 조합을 실시간 데이터 파이프라인에 연결하거나 AI 에이전트를 구축해 보세요.
지금 무료 체험판에 가입하고 데이터 수집 능력을 한 단계 업그레이드하세요!





