

인터넷상의 데이터 양이 계속 증가함에 따라, 웹 크롤링(웹사이트를 자동으로 탐색하고 정보를 추출하는 과정)은 개발자가 습득해야 할 점점 더 중요한 기술이 되고 있습니다. 이는 웹 서버에 HTTP 요청을 보내고 HTML 응답을 파싱하여 원하는 데이터를 추출하는 방식으로 이루어집니다.
웹 크롤링 과정은 복잡하고 시간이 많이 소요될 수 있지만, 적절한 도구와 기법을 활용하면 도움이 됩니다. 유연성과 사용 편의성 덕분에 파이썬은 웹 크롤러 구축에 널리 쓰이는 언어로 부상했으며, 개발자가 데이터 추출 과정을 자동화하는 스크립트를 신속하게 작성할 수 있게 해줍니다.
이 글에서는 Scrapy 라이브러리를 활용한 파이썬 웹 크롤링의 모든 것을 배울 수 있습니다.
웹 크롤링이 필요한 이유
튜토리얼을 시작하기 전에 웹 스크래핑과 웹 크롤링의 차이점을 명확히 하는 것이 중요합니다. 유사해 보이지만, 웹 스크래핑은 웹 페이지에서 특정 데이터를 추출하는 반면, 웹 크롤링은 색인화를 위해 웹 페이지를 탐색하고 검색 엔진을 위한 정보를 수집합니다.
웹 크롤링은 다음과 같은 다양한 시나리오에서 유용합니다:
- 데이터 추출: 웹 크롤링을 통해 웹사이트에서 특정 데이터를 추출하여 분석이나 연구에 활용할 수 있습니다.
- 웹사이트 색인화: 검색 엔진은 웹사이트를 색인화하여 사용자가 검색할 수 있도록 웹 크롤링을 자주 사용합니다.
- 모니터링: 웹 크롤링은 웹사이트의 변경 사항이나 업데이트를 모니터링하는 데 활용될 수 있습니다. 이 정보는 경쟁사 추적에 유용합니다.
- 콘텐츠 집계: 웹 크롤링을 통해 여러 웹사이트의 콘텐츠를 수집하여 한 곳에 모아 쉽게 접근할 수 있도록 할 수 있습니다.
- 보안 테스트: 웹 크롤링은 웹사이트 및 웹 애플리케이션의 취약점이나 약점을 식별하기 위한 보안 테스트에 활용될 수 있습니다.
파이썬을 이용한 웹 크롤링
파이썬은 코딩의 용이성과 직관적인 구문 덕분에 웹 크롤링에 널리 사용됩니다. 또한 가장 인기 있는 웹 크롤링 프레임워크 중 하나인 Scrapy가 파이썬으로 구축되었습니다. 이 강력하고 유연한 프레임워크는 웹사이트에서 데이터를 추출하고, 링크를 따라가며, 결과를 저장하는 작업을 쉽게 만듭니다.
Scrapy는 대량의 데이터를 처리하도록 설계되었으며 다양한 웹 스크래핑 작업에 활용될 수 있습니다. HTTP 다운로더, 웹사이트 크롤링용 스파이더, 크롤링 빈도 관리용 스케줄러, 스크랩된 데이터 처리용 아이템 파이프라인 등 Scrapy에 포함된 도구들은 다양한 웹 크롤링 작업에 적합합니다.
Python을 사용한 웹 크롤링을 시작하려면 시스템에 Scrapy 프레임워크를 설치해야 합니다.
터미널을 열고 다음 명령어를 실행하세요:
pip install scrapyn
이 명령어를 실행하면 시스템에 스크래피가 설치됩니다. 스크래피는 웹 크롤링 작업 수행 방식을 정의하는 ‘스파이더’라는 클래스를 제공합니다. 이 스파이더들은 웹사이트 탐색, 요청 전송, 웹사이트 HTML에서 데이터 추출을 담당합니다.
Scrapy 프로젝트 생성
이 글에서는 Books to Scrape라는 웹사이트를 크롤링하여 각 책의 이름, 카테고리, 가격을 CSV 파일에 저장하는 방법을 다룹니다. 이 웹사이트는 스크래핑 프로젝트를 위한 샌드박스 역할을 하도록 제작되었습니다.
Scrapy 설치 후 다음 명령어로 새 프로젝트 구조를 생성해야 합니다:
scrapy startproject bookcrawlern
(참고: “command not found” 오류가 발생하면 터미널을 재시작하세요)
기본 디렉터리 구조는 웹 스크래핑 프로세스의 각 구성 요소에 대해 별도의 파일과 디렉터리를 제공하여 명확하고 체계적인 프레임워크를 제공합니다. 이를 통해 스파이더 코드를 작성, 테스트, 유지 관리하고 추출된 데이터를 원하는 방식으로 처리 및 저장하기가 쉬워집니다. 디렉터리 구조는 다음과 같습니다:
bookcrawlernâ scrapy.cfgnânââââbookcrawlern â items.pyn â middlewares.pyn â pipelines.pyn â settings.pyn â __init__.pyn ân ââââspidersn __init__.pynn
Scrapy 프로젝트에서 크롤링 프로세스를 시작하려면 bookcrawler/spiders 디렉터리에 새 스파이더 파일을 생성하는 것이 필수적입니다. 이는 Scrapy가 코드 실행을 위해 스파이더를 찾는 표준 디렉터리이기 때문입니다. 이를 위해 bookcrawler/spiders 디렉터리로 이동하여 bookspider.py라는 새 파일을 생성하세요. 그런 다음 스파이더를 정의하고 동작을 지정하기 위해 다음 코드를 파일에 작성하세요:
from scrapy.spiders import CrawlSpider, Rulenfrom scrapy.linkextractors import LinkExtractornnclass BookCrawler(CrawlSpider):n name = 'bookspider'n start_urls = [n 'https://books.toscrape.com/',n ]n rules = (n Rule(LinkExtractor(allow='/catalogue/category/books/')),n )nn
이 코드는 내장된 CrawlSpider를 상속받은 BookCrawler를 정의하며, 링크 추적 및 데이터 추출 규칙을 편리하게 정의할 수 있는 방법을 제공합니다. start_urls 속성은 크롤링을 시작할 URL 목록을 지정합니다. 이 경우 웹사이트의 홈페이지 URL 하나만 포함됩니다.
rules 속성은 스파이더가 따라야 할 링크를 결정하는 규칙 집합을 지정합니다. 이 경우 scrapy.spiders 모듈의 Rule 클래스를 사용하여 생성된 단일 규칙만 정의되어 있습니다. 이 규칙은 스파이더가 따라야 할 링크 패턴을 지정하는 LinkExtractor 인스턴스로 정의됩니다. LinkExtractor의 allow 매개변수는 /catalogue/category/books/로 설정되어 있어, 스파이더는 URL에 이 문자열이 포함된 링크만 따라가야 함을 의미합니다.
스파이더를 실행하려면 터미널을 열고 다음 명령어를 실행하세요:
scrapy crawl bookspidern
이 명령을 실행하면 Scrapy는 BookCrawler 스파이더 클래스를 초기화하고, start_urls 속성에 있는 각 URL에 대한 요청을 생성하여 Scrapy 스케줄러로 보냅니다. 스케줄러는 요청을 수신하면 해당 요청이 스파이더의 allowed_domains (지정된 경우) 속성에 의해 허용되는지 확인합니다. 도메인이 허용되면 요청은 다운로더로 전달되어 서버에 HTTP 요청을 보내고 응답을 가져옵니다.
이 시점에서 콘솔 창에서 크롤러가 크롤링한 모든 URL을 확인할 수 있습니다:
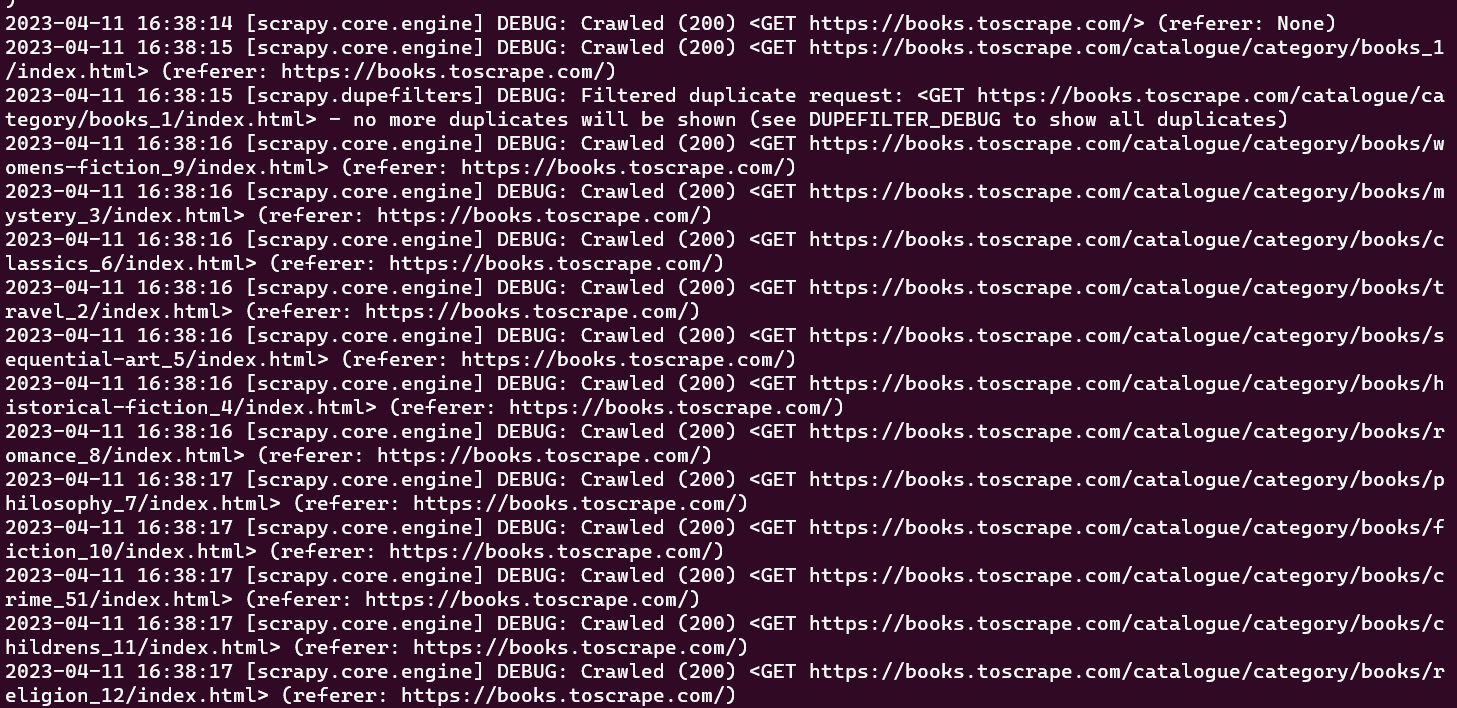
초기 생성된 크롤러는 사전 정의된 URL 집합을 크롤링하는 작업만 수행하며, 어떠한 정보도 추출하지 않습니다. 크롤링 과정에서 데이터를 가져오려면 크롤러 클래스 내에 parse_item 함수를 정의해야 합니다. parse_item 함수는 크롤러가 수행한 각 요청의 응답을 수신하고, 해당 응답에서 얻은 관련 데이터를 반환하는 역할을 합니다.
참고:
parse_item함수는LinkExtractor의callback속성을 설정한 후에만 작동합니다.
Scrapy에서 웹 페이지 크롤링으로 얻은 응답에서 데이터를 추출하려면 CSS 선택자를 사용해야 합니다. 다음 섹션에서는 CSS 선택자에 대해 간략히 소개합니다.
CSS 선택자에 관한 간단한 설명
CSS 선택기는 태그, 클래스, 속성을 지정하여 웹 페이지에서 데이터를 추출하는 방법입니다. 예를 들어, scrapy shell books.toscrape.com으로 초기화된 Scrapy 셸 세션은 다음과 같습니다:
# check if the response was successfulnu003eu003eu003e responsenu003c200 http://books.toscrape.comu003enn#extract the title tagnu003eu003eu003e response.css('title')n[u003cSelector xpath='descendant-or-self::title' data='u003ctitleu003en All products | Books to S...'u003e]n
이 세션에서 css 함수는 태그(예: title)를 받아 Selector 객체를 반환합니다. title 태그 내부의 텍스트를 얻으려면 다음과 같은 쿼리를 작성해야 합니다:
u003eu003eu003e print(response.css('title::text').get())n All products | Books to Scrape - Sandboxn
이 스니펫에서는 텍스트 의사 선택자를 사용하여 둘러싼 title 태그를 제거하고 내부 텍스트만 반환합니다. get 메서드는 데이터 값만 표시하는 데 사용됩니다.
요소의 클래스를 얻으려면 마우스 오른쪽 버튼을 클릭하고 ‘검사’를 선택하여 페이지의 소스 코드를 확인해야 합니다:
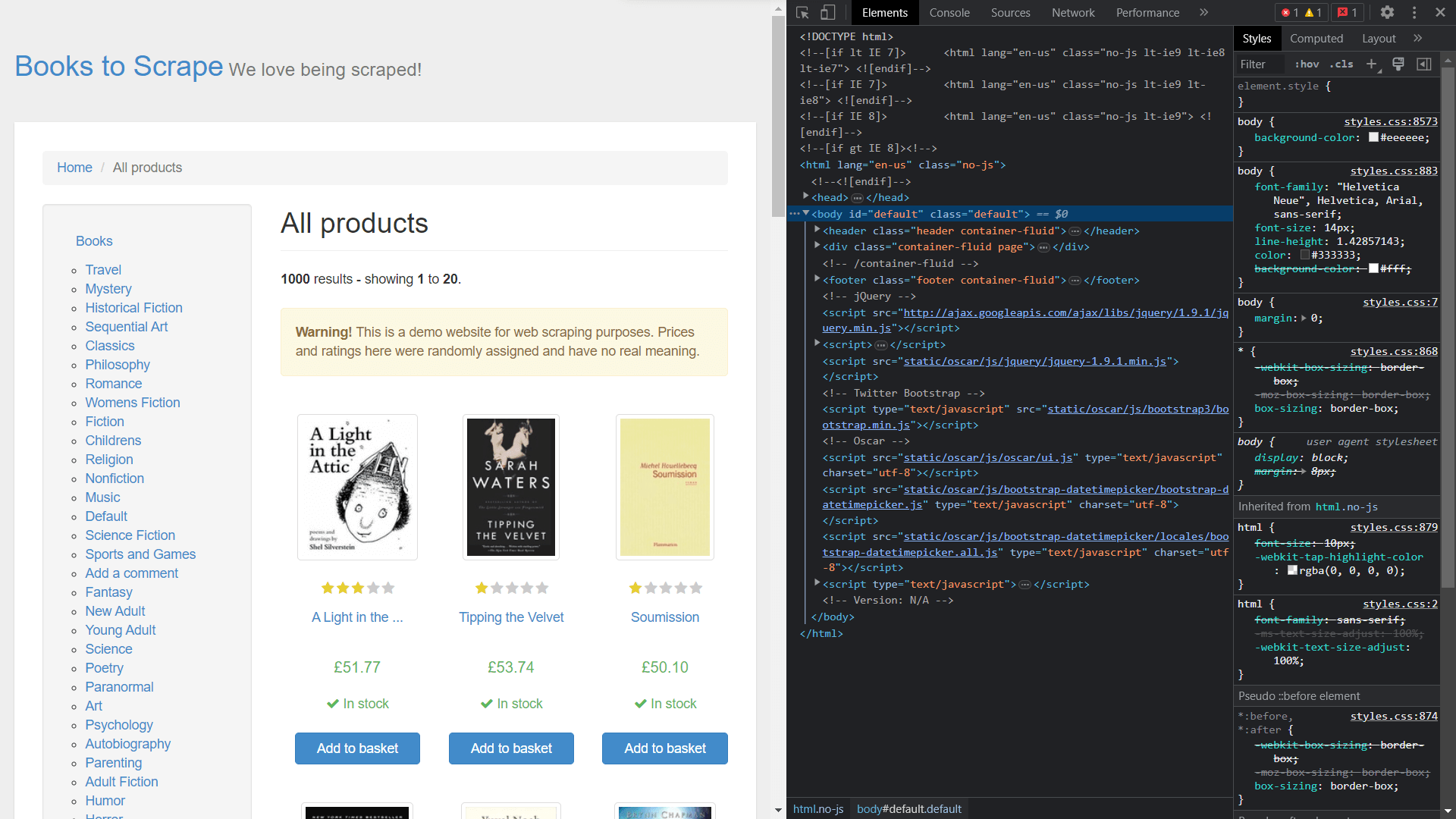
Scrapy를 이용한 데이터 추출
응답 객체에서 요소를 추출하려면 콜백 함수를 정의하고 이를 Rule 클래스의 속성으로 할당해야 합니다.
bookspider.py 파일을 열고 다음 코드를 실행하세요:
from scrapy.spiders import CrawlSpider, Rulenfrom scrapy.linkextractors import LinkExtractornnclass BookCrawler(CrawlSpider):n name = 'bookspider'n start_urls = [n 'https://books.toscrape.com/',n ]nnn rules = (n Rule(LinkExtractor(allow='/catalogue/category/books/'), callback=u0022parse_itemu0022), n n )n def parse_item(self, response):n category = response.css('h1::text').get()n book_titles = response.css('article.product_pod').css('h3').css('a::text').getall()n book_prices = response.css('article.product_pod').css('p.price_color::text').getall()n yield {n u0022categoryu0022: category,n u0022booksu0022:list(zip(book_titles,book_prices))n }nn
BookCrawler 클래스의 parse_item 함수는 추출할 데이터에 대한 로직을 포함하며 이를 콘솔에 출력합니다. yield를 사용하면 Scrapy가 데이터를 아이템 형태로 처리할 수 있으며, 이후 아이템 파이프라인을 통해 추가 처리나 저장이 가능합니다.
카테고리 선택 과정은 단순한 <h1> 태그 내에 코딩되어 있어 직관적입니다. 반면 book_titles 선택은 다단계 선택 프로세스를 통해 이루어지며, 첫 단계는 class product_pod를 가진 <article> 태그를 선택하는 것입니다. 이어서 탐색 과정은 <h3> 태그 내에 중첩된 <a> 태그를 식별하는 단계로 진행됩니다. book_prices 선택 시에도 동일한 접근 방식을 적용하여 웹 페이지에서 필요한 정보를 추출할 수 있습니다.
이제 웹사이트를 크롤링하고 데이터를 추출하는 스파이더를 생성했습니다. 스파이더를 실행하려면 터미널을 열고 다음 명령어를 실행하세요:
scrapy crawl bookspider -o books.jsonn
실행 시 크롤러가 크롤링한 웹 페이지와 해당 데이터가 콘솔에 표시됩니다. -o 플래그 사용은 Scrapy가 검색된 모든 데이터를 books.json이라는 파일로 저장하도록 지시합니다. 스크립트 완료 시 프로젝트 디렉터리에 books.json이라는 새 파일이 생성됩니다. 이 파일에는 크롤러가 검색한 모든 도서 관련 데이터가 포함됩니다:
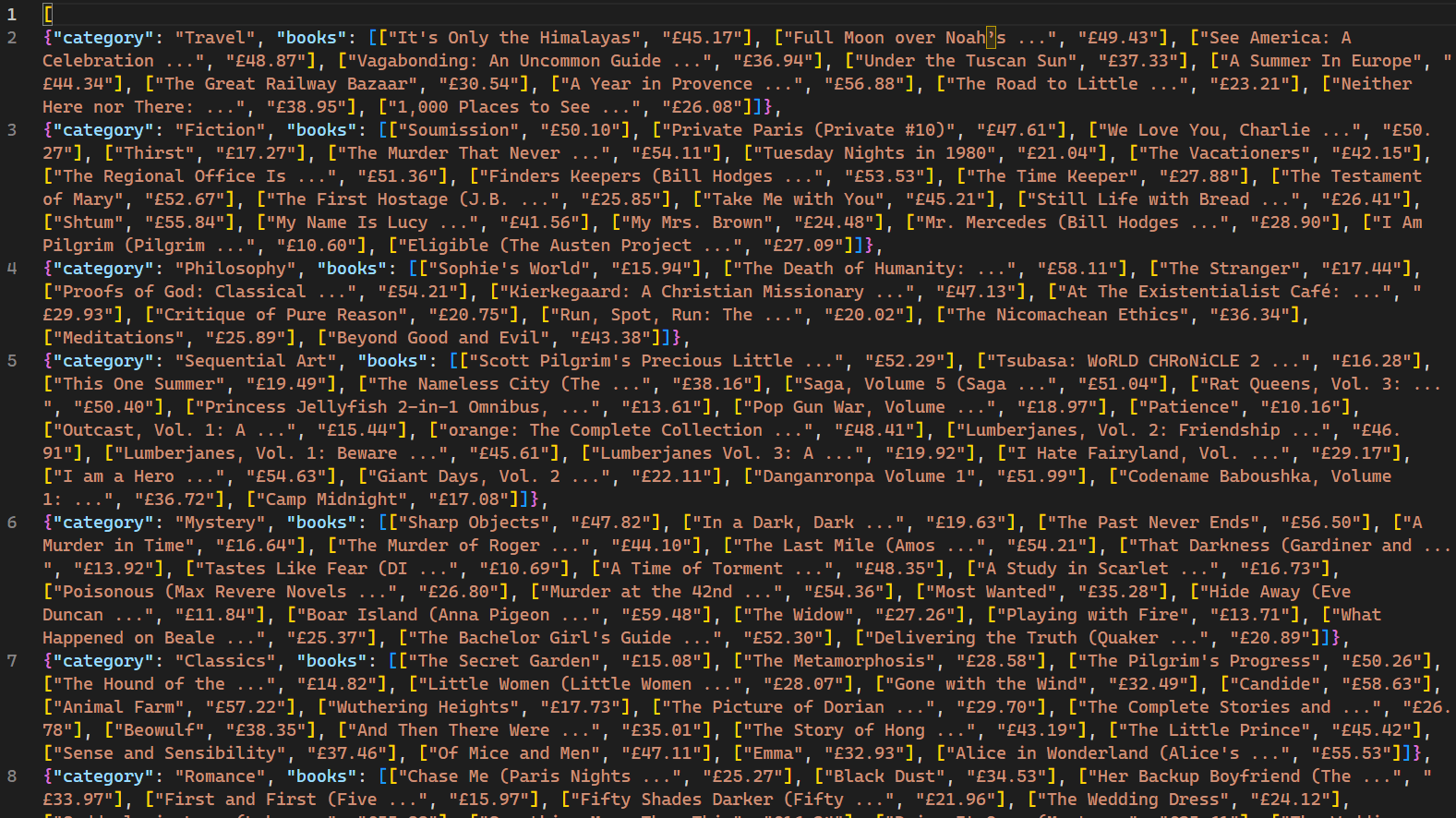
이 웹 크롤러는 다중 요청에 대한 IP 차단 메커니즘을 사용하지 않는 웹사이트에서만 효과적이라는 점을 유의해야 합니다. 웹봇 및 크롤러에 덜 관대한 사이트의 경우, 대규모 데이터 추출을 위해 Bright Data와 같은 프록시 서비스가 필요합니다. Bright Data의 서비스는 IP 차단 및 탐지를 피하면서 다양한 출처에서 웹 데이터를 수집할 수 있도록 지원합니다.
결론
웹 크롤링과 웹 스크래핑을 통합한 기술은 데이터 수집 및 데이터 과학 분야에서 매우 가치 있는 기술입니다. 웹 크롤링을 위해 설계된 프레임워크인 Scrapy는 내장된 크롤러와 스크래퍼를 제공하여 이 과정을 단순화합니다.
본 글에서는 Scrapy 프레임워크를 활용해 웹 크롤러 구축 및 데이터 스크래핑 과정을 안내했습니다. CrawlSpider를 통한 손쉬운 웹 크롤링 방법과 특정 URL 패턴을 크롤링하는 Rule, LinkExtractor 같은 개념을 학습했습니다. 또한 CSS 선택자를 활용한 HTML 요소 선택 개념도 다루었습니다. 이러한 기술을 숙달하면 데이터 과학 및 그 외 분야에서 웹 크롤링과 스크래핑 과제를 해결할 수 있는 역량을 갖추게 될 것입니다.





