

Node.js로 웹 스크래핑을 할 때 인터넷 검열이나 느린 프록시 같은 장애물을 마주칠 수 있습니다. 다행히도 node unblocker 라는 해결책이 있습니다.
언블로커는 개발자가 인터넷 검열을 우회하고 지역 제한 콘텐츠에 접근할 수 있게 해주는 웹 프록시입니다. 빠른 데이터 중계, 쉬운 맞춤 설정 옵션, 다중 프로토콜 지원 등의 장점을 가진 오픈 소스 솔루션입니다. 언블로커를 사용하면 인터넷 제한을 극복하고, 그렇지 않으면 접근할 수 없는 웹사이트에서 효율적으로 데이터를 스크래핑할 수 있습니다.
이 글에서는 웹 스크래핑 프로젝트에서 언블로커의 장점을 포함해 언블로커에 관한 모든 것을 알아봅니다. 또한 지역 제한 콘텐츠를 스크래핑하는 데 사용할 수 있는 프록시를 생성하는 방법도 배울 수 있습니다.
Node Unblocker 사용의 장점
Node Unblocker는 웹 콘텐츠에 대한 제한 없는 접근을 원하는 인터넷 사용자에게 가치 있는 도구로, 다양한 이점과 기능을 제공합니다. 오픈 소스 솔루션이라는 점 외에도 다음과 같은 장점이 있습니다:
- 중개자 역할 수행
- 데이터를 빠르고 효율적으로 전달: 언블로커는 버퍼링 없이 클라이언트에 데이터를 전달하는 데 탁월합니다. 그 결과, 가장 빠른 프록시 솔루션 중 하나입니다.
- 사용이 간편함: 언블로커는 모든 기술 수준의 사용자에게 적합한 사용자 친화적인 인터페이스를 제공합니다. 솔루션을 프로젝트에 통합하려는 경우, 언블로커는 구현이 쉬운 접근 가능한 API를 제공합니다.
- 고도로 맞춤화 가능: 언블로커를 사용하면 개발자가 특정 스크래핑 요구사항에 따라 프록시를 유연하게 맞춤 설정할 수 있습니다. 예를 들어 요청 헤더나 응답 처리와 같은 매개변수를 구성하여 개인화되고 효율적인 스크래핑 프로세스를 구현할 수 있습니다.
- 다양한 프로토콜 지원: Unblocker는 HTTP, HTTPS, WebSockets 등 다양한 프로토콜을 지원합니다. 이러한 다용도성은 다양한 스크래핑 시나리오와의 원활한 통합을 가능하게 하여 개발자가 광범위한 데이터 소스와 유연하고 편리하게 상호작용할 수 있도록 합니다.
언블로커 시작 방법
이제 Unblocker가 제공하는 모든 이점을 알았으니 사용을 시작할 차례입니다. 시작하기 전에 시스템에 Node.js 와 npm이 설치되어 있는지 확인해야 합니다. 또한 프로젝트 테스트를 위한 웹 브라우저와 솔루션을 호스팅할 무료 Render 계정이 필요합니다.
이러한 필수 조건을 완료했다면 웹 프록시를 생성할 차례입니다. 이를 위해 node-unblocker-proxy라는 폴더를 생성하고 터미널에서 해당 폴더를 연 후, 새 Node.js 프로젝트를 초기화하기 위해 다음 명령어를 실행하세요:
npm init -y
그런 다음 필요한 종속성을 설치하기 위해 다음 명령어를 실행하세요:
npm install express unblocker
express는 웹 서버를 설정하는 데 사용하는 웹 애플리케이션 프레임워크입니다. node-unblocker는 웹 프록시 생성 작업을 지원하는 npm 패키지입니다.
프록시 생성 스크립트 작성
모든 종속성이 설정되면 웹 프록시 스크립트를 구현할 차례입니다.
프로젝트 루트 폴더에 index.js 파일을 생성하고 다음 코드를 붙여넣으세요:
// 필요한 종속성 가져오기
const express = require("express");
const Unblocker = require("unblocker");
// express 앱 인스턴스 생성
const app = express();
// 새로운 Unblocker 인스턴스 생성
const unblocker = new Unblocker({ prefix: "/proxy/" });
// 포트 설정
const port = 3000;
// Express 애플리케이션에 언블로커 미들웨어 추가
app.use(unblocker);
// 지정된 포트에서 리스닝
app.listen(port).on("upgrade", unblocker.onUpgrade);
console.log(`http://localhost:${port}/proxy/에서 프록시 실행 중`);
이 코드에서는 필요한 종속성을 임포트하고 Express 앱의 인스턴스를 생성합니다. 또한 다양한 구성 옵션을 허용하는 새로운 Unblocker 인스턴스를 생성합니다. 여기서는 프록시 처리된 URL이 시작해야 하는 경로를 지정하는 접두사 옵션만 설정합니다.
Unblocker는 Express 호환 API를 내보내므로 Express 애플리케이션에 통합하는 것은 간단합니다.
애플리케이션에 통합하는 것은 쉽습니다. Express 앱 인스턴스의 use() 메서드를 호출하고 Unblocker 인스턴스를 전달하기만 하면 됩니다. 그런 다음 listen() 메서드를 사용하여 Express 애플리케이션을 시작합니다. .on("upgrade", unblocker.onUpgrade)는 WebSocket 연결이 unblocker에 의해 올바르게 처리되도록 보장합니다.
로컬에서 프록시 테스트하기
로컬에서 프록시 구현을 테스트하려면 터미널에서 다음 명령을 실행하세요:
node index.js
프록시를 통해 이루어지는 각 요청에 대한 상세 정보를 확인하려면 다음 명령을 사용할 수도 있습니다:
DEBUG=unblocker:* node index.js
다음으로, 임의의 URL 앞에 localhost/proxy/를 붙여(예: localhost/proxy/https://brightdata.com/) 웹 브라우저에서 엽니다.
Bright Data 홈페이지가 표시됩니다. 브라우저의 네트워크 탭을 빠르게 확인하면 모든 요청이 프록시를 통해 전송되는 것을 확인할 수 있습니다( 네트워크 탭의 도메인 열에서 확인 가능):
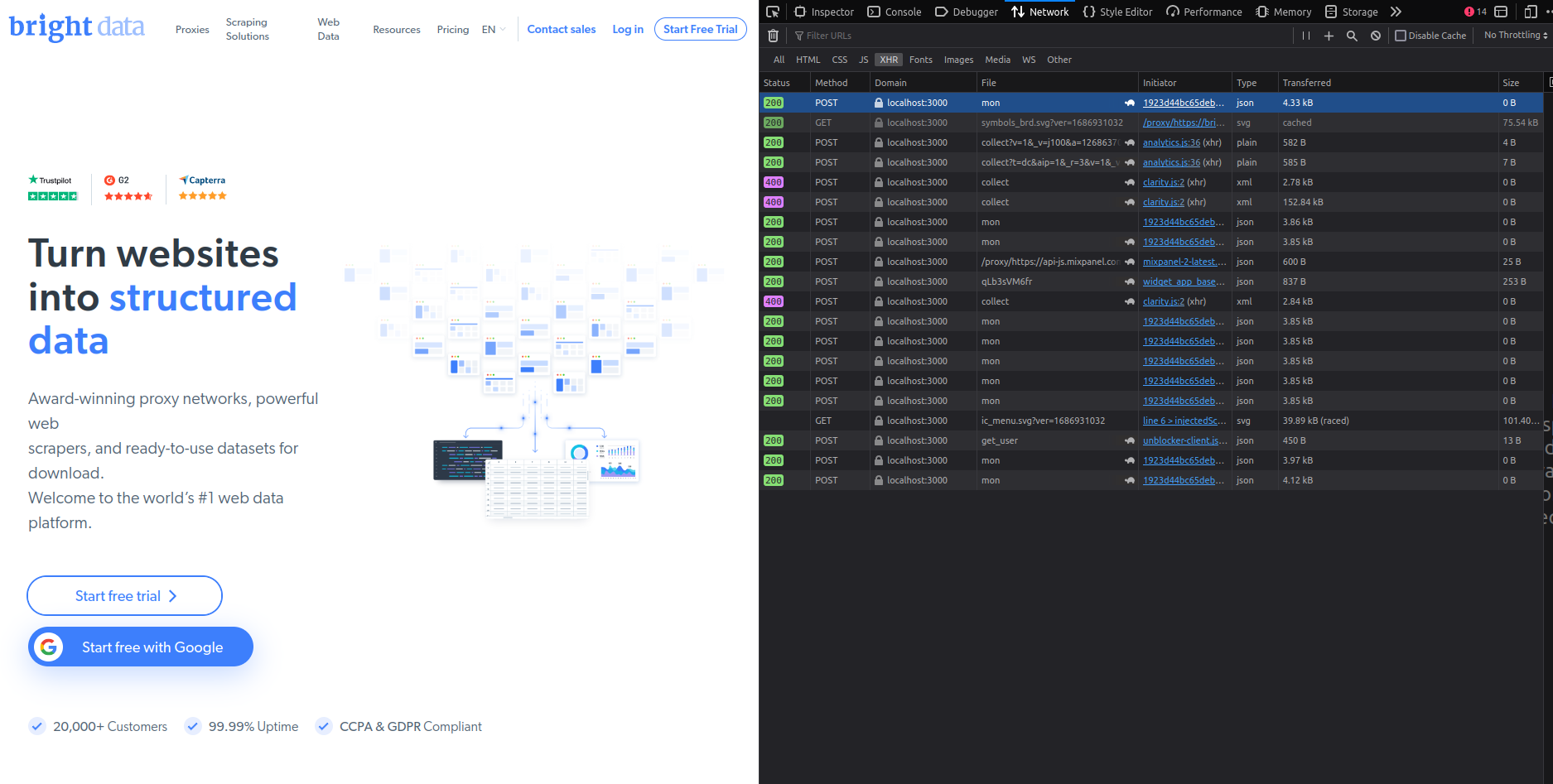
프록시를 Render에 배포하기
프록시 테스트를 마쳤으니 이제 배포할 차례입니다. 배포 전에 프로젝트 루트 폴더의 package.json 파일을 열고 scripts 키-값 쌍을 다음과 같이 수정하세요:
"scripts": {
"start": "node index"
}
이렇게 하면 Render에 호스팅된 후 Express 웹 서버를 시작하는 명령어가 제공됩니다.
웹 프록시를 배포하고 프록시 코드를 GitHub 저장소에 업로드합니다. 그런 다음 Render 계정에 로그인하세요:
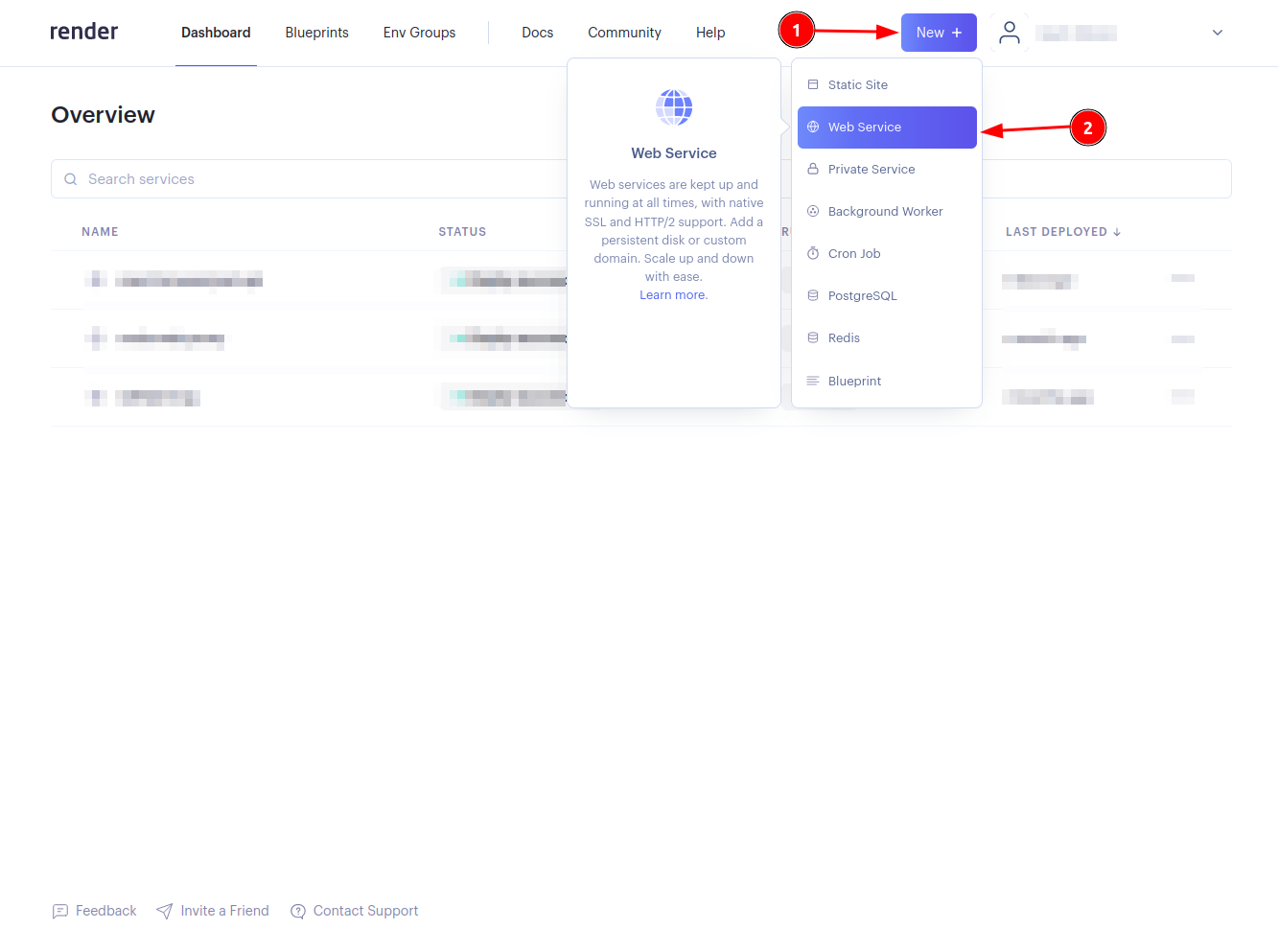
새로 만들기(+ ) 버튼을 클릭하고 웹 서비스를 선택하세요:
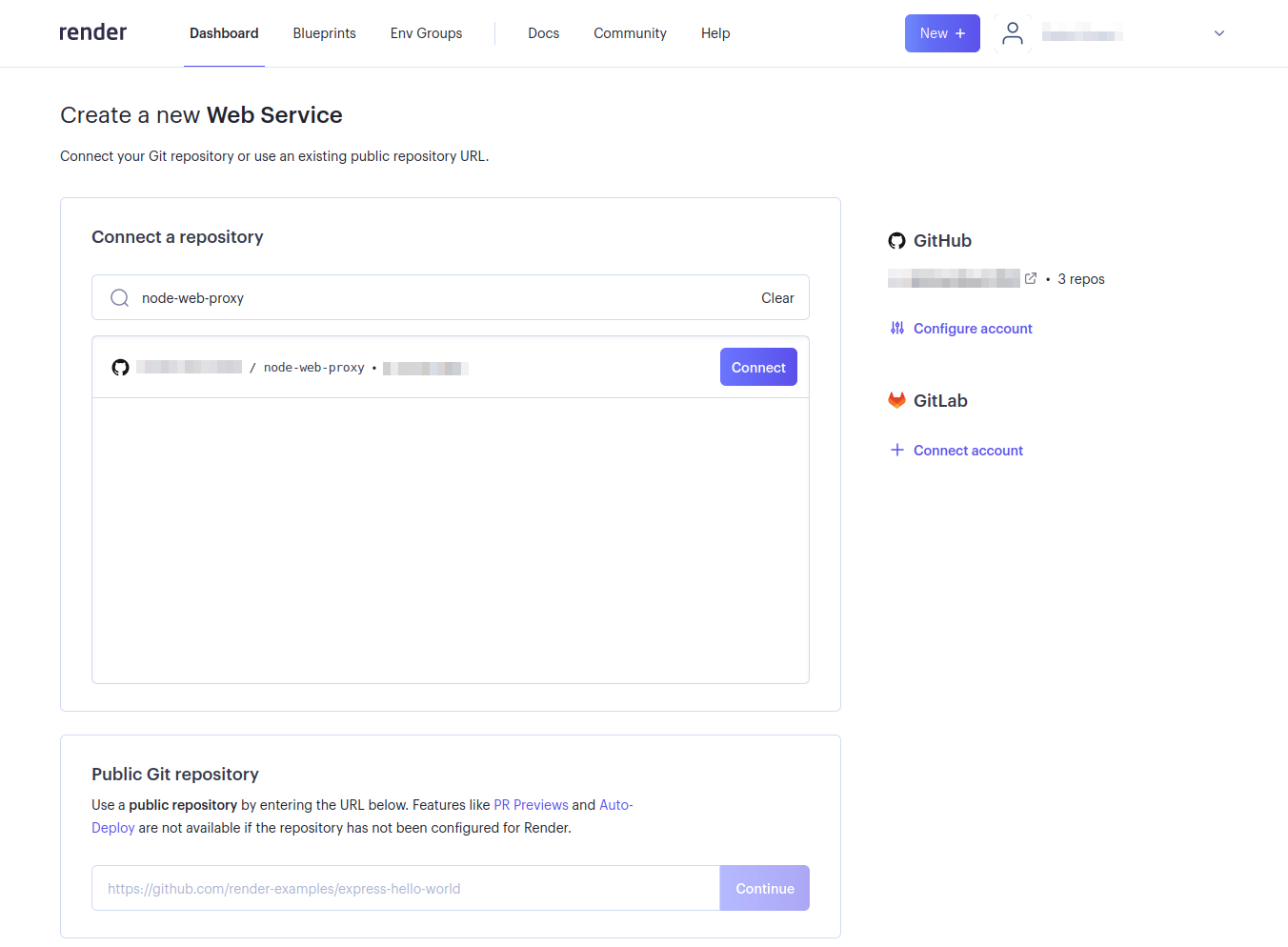
연결 버튼을 선택하여 웹 프록시 저장소를 연결하세요. Render가 저장소에 접근할 수 있도록 계정을 구성해야 할 수 있습니다. 이는 Render가 특정 GitHub 저장소에 접근하도록 구성하지 않은 경우에만 필요합니다:
웹 서비스에 필요한 세부 정보를 입력하고 페이지 하단의 ‘웹 서비스 생성’을 선택하세요:
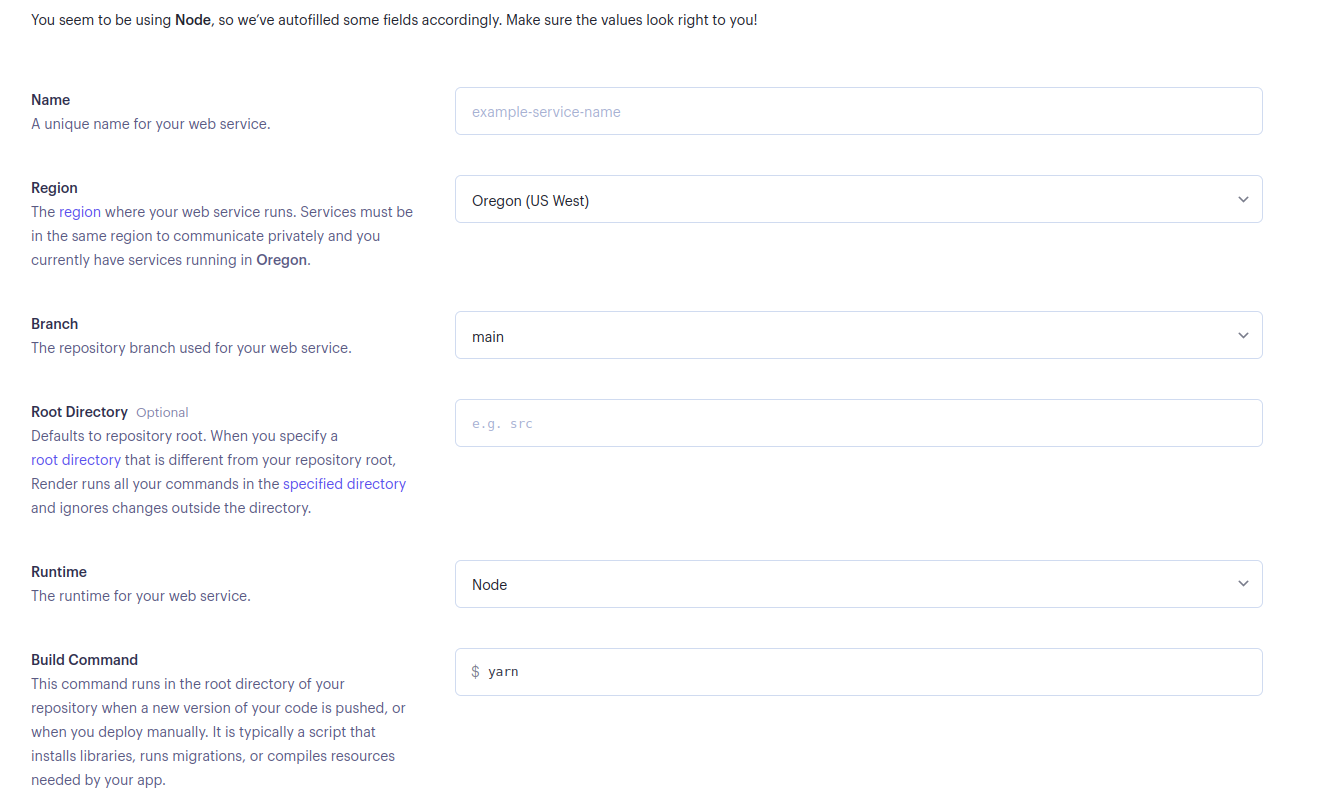
Yarn 사용을 선호한다면 시작 명령어를 그대로 두거나, npm을 사용하려면
npm run start로변경할 수 있습니다.
웹 프록시가 성공적으로 배포된 후에는 테스트할 차례입니다. 임의의 URL 앞에 배포된 <DEPLOYED-APP-URL>/proxy/를 접두사로 붙이세요(예: https://node-web-proxy-gvn6.onrender.com/proxy/https://brightdata.com/). 그런 다음 웹 브라우저에서 해당 URL을 열어보세요.
브라우저의 네트워크 탭을 확인하면 모든 요청이 배포된 프록시를 통해 전송되는 것을 확인할 수 있습니다:
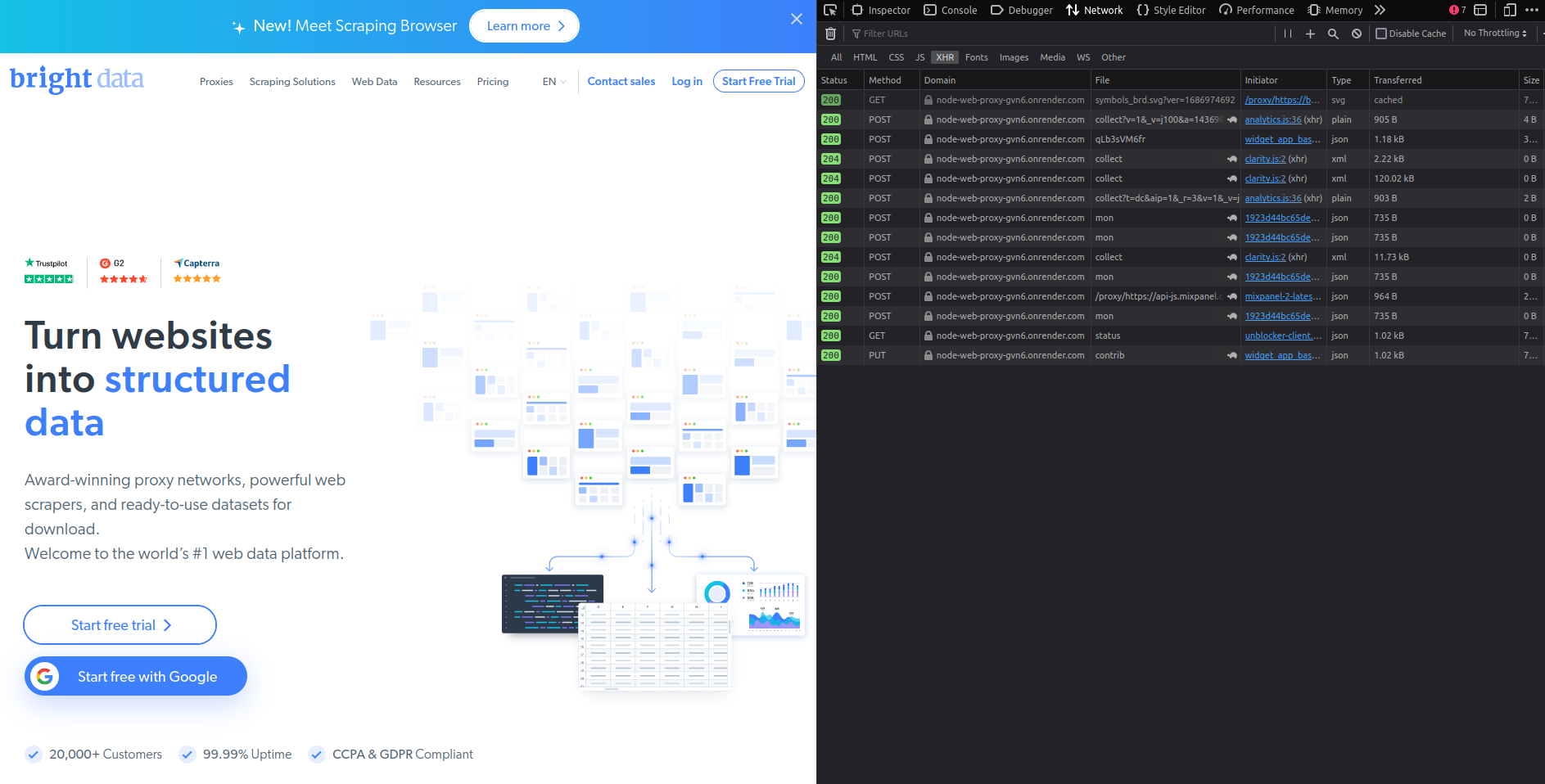
프록시를 이용한 스크래핑 요청 수행
모든 요청이 배포된 프록시를 통과하는지 확인했다면, 이제 스크래핑 요청을 수행할 차례입니다. 이 튜토리얼에서는 Puppeteer 라이브러리를 사용하지만, Cheerio나 Nightmare 같은 다른 테스트 라이브러리도 작동합니다.
Puppeteer가 아직 설치되지 않았다면 npm i puppeteer 명령어로 설치하세요. 그런 다음 프로젝트 루트 폴더에 scrape.js 파일을 생성하고 다음 코드를 추가합니다:
// puppeteer 임포트
const puppeteer = require("puppeteer");
const scrapeData = async () => {
// 브라우저 실행
const browser = await puppeteer.launch({
headless: false,
});
// 새 페이지 열기 및 지정된 URL로 이동
const page = await browser.newPage();
await page.goto("<배포된 앱 URL>/proxy/https://brightdata.com/blog");
// 웹페이지 콘텐츠 가져오기
const data = await page.evaluate(() => {
// 모든 게시물 데이터를 저장할 변수
let blogData = [];
// 지정된 클래스를 가진 모든 요소 추출
const posts = document.querySelectorAll(".post_item");
// 게시물 객체를 순회하며 필요한 데이터를 추출하고 blogData 배열에 추가
for (const post of posts) {
const title = post.querySelector("h5").textContent;
const link = post.href;
const author = post
.querySelector(".author_box")
.querySelector(".author_box__details")
.querySelector("div").textContent;
const article = { title, link, author };
blogData.push(article);
}
return blogData;
});
// 데이터를 콘솔에 출력
console.log(data);
// 브라우저 인스턴스 닫기
await browser.close();
};
// scrapeData 함수 호출
scrapeData();
<DEPLOYED-APP-URL>을Render에 배포한 앱의 URL로 교체해야 합니다.
이 코드 스니펫은 Puppeteer를 설정하고Bright Data 블로그에서 블로그 게시물 데이터를 스크래핑합니다. Bright Data 웹사이트의 모든 블로그 게시물 카드에는.post_item 클래스 이름이 있습니다. 이 코드는 모든 게시물을 가져오고,게시물객체를 순회하며, 각 게시물의 제목, 링크, 작성자를 추출하고, 이 데이터를blogData배열에 추가한 후, 마지막으로 이 모든 정보를 콘솔에 기록합니다.
Node Unblocker에 최적의 프록시를 선택하는 방법?
Node Unblocker에 프록시를 통합할 때는 프로젝트 요구사항과 예상되는 특정 문제에 맞춰 선택하는 것이 중요합니다. 프록시 선택 시 고려해야 할 주요 사항은 다음과 같습니다:
- 성능 및 안정성: 빠른 연결 속도와 높은 가용성으로 알려진 프록시를 선택하여 원활한 데이터 접근과 웹 스크래핑 효율성을 보장하세요.
- 지리적 유연성: 광범위한 지리적 위치를 제공하는 프록시를 선택하세요. 이 기능은 지역적 제한을 우회하고 현지화된 콘텐츠에 접근하는 데 필수적입니다.
- IP 로테이션: 웹사이트 차단 위험을 줄이기 위해 IP 주소를 순환하는 프록시 서비스를 선택하세요. 이 기능은 요청마다 새로운 IP를 제공하여 접근성을 유지하는 데 도움이 됩니다.
- 보안 프로토콜: 특히 민감한 정보를 처리하는 경우 데이터 무결성과 개인 정보 보호를 위해 SSL 암호화와 같은 강력한 보안 조치가 포함된 프록시 서비스를 선택하십시오.
- 확장성: 스크래핑 요구가 증가함에 따라 프로xy 서비스가 수요 증가에 맞춰 확장 가능한지 고려하십시오. 자원 확장 유연성은 더 크거나 복잡한 스크래핑 작업을 지원하기 위해 중요합니다.
- 지원 및 문서: 포괄적인 지원과 상세한 문서는 특히 Node Unblocker로 복잡한 설정을 구성할 때 통합 과정을 크게 용이하게 합니다.
이러한 요소들을 신중하게 평가함으로써, 현재 요구 사항에 부합할 뿐만 아니라 향후 스크래핑 활동의 성장과 변화에도 대응할 수 있는 프록시 서비스를 선택할 수 있습니다.
결론
Node Unblocker는 Node.js 기반 웹 스크래핑을 위한 강력한 솔루션을 제공하여 개발자가 인터넷 검열을 우회하고 지역 제한 콘텐츠에 접근할 수 있게 합니다. 사용자 친화적인 인터페이스, 광범위한 맞춤 설정 옵션, 다양한 프로토콜 지원은 웹사이트에서 데이터를 효율적으로 스크래핑하는 데 유용한 도구입니다. 본 가이드에서는 Unblocker의 모든 기능, 웹 스크래핑 프로젝트에서의 장점, 활용 방법을 알아보았습니다.
데이터 중심의 현대 사회에서 웹 스크래핑은 가치 있는 통찰력과 정보를 수집하는 데 필수적인 도구가 되었습니다. 그러나 IP 차단, 속도 제한, 지역 제한과 같은 웹 스크래핑 고유의 문제점들은 데이터 수집 노력을 방해하고 중요한 데이터 획득을 저해할 수 있습니다.
Bright Data는 이러한 문제점을 해결하는 포괄적인 플랫폼을 제공합니다. 주거용, ISP, 데이터센터, 모바일 IP로 구성된 방대한 네트워크를 통해 Bright Data는 사용자가 전 세계 다양한 IP 주소를 통해 스크래핑 요청을 전송할 수 있도록 합니다. 이는 익명성을 보장할 뿐만 아니라 지역 제한 콘텐츠에 접근하고 데이터 수집 노력을 방해할 수 있는 장애물을 극복할 수 있는 능력을 제공합니다.
어떤 Bright Data 프록시가 필요한지 잘 모르시겠나요? 지금 등록하시고 데이터 전문가와 상담하여 귀하의 요구에 가장 적합한 솔루션을 찾아보세요.





