

분산 웹 크롤링은 웹 스크레이퍼를 여러 대의 머신에 걸쳐 확장하는 전략으로, 단일 노드 크롤러의 한계를 극복합니다. 본 글에서는 다음을 살펴보겠습니다:
- 분산 웹 크롤링 대 단일 노드 웹 크롤링
- 분산 웹 크롤링의 핵심 아키텍처
- 분산 웹 크롤링의 실제 사례
- 구현 전략 및 모범 사례
- 흔히 발생하는 문제점과 해결 방법
요약: 분산 웹 크롤링은 클러스터화된 머신들을 활용해 웹사이트를 병렬로 크롤링함으로써 단일 노드 크롤러가 해결할 수 없는 확장성과 속도 문제를 해결합니다. 추가적인 아키텍처 복잡성과 오버헤드를 대가로 더 높은 처리량과 신뢰성(단일 병목 현상 없음)을 제공합니다.
분산 크롤링 vs 단일 노드 크롤링
대부분의 크롤링 프로젝트는 분산 시스템을 필요로 하지 않음에도, 팀들은 단일 서버로도 충분한 상황에서 복잡한 분산 아키텍처를 구축하는 데 수개월을 낭비하는 경우가 흔합니다.
단일 노드 크롤러에서는 한 대의 머신이 모든 페이지 가져오기, 파싱, 저장을 처리합니다. 이러한 시스템은 개발 및 유지보수가 더 쉽고 비용을 절감해 줍니다. 분당 60~500페이지 가져오기에는 훌륭하지만, 크롤링 수요가 증가하면 CPU, 메모리, 네트워크 제약으로 인해 단일 노드가 병목 현상이 됩니다.
반면 분산 크롤러는 작업을 여러 노드에 분산시켜 대규모 동시 수집, 고속 처리, 향상된 장애 허용성을 가능하게 합니다. 한 작업자가 중단되더라도 다른 노드는 계속 실행되어 신뢰성을 높입니다. 단점은 메시지 큐, URL 프론티어 동기화, 중복 수집이나 대상 사이트 과부하 방지를 위한 세심한 설계가 필요하다는 점입니다.
종합 비교
| 측면 | 단일 노드 | 분산 |
|---|---|---|
| 성능 | 평균 4초/페이지, 분당 60-120페이지 | 30배 더 빠름, 초당 50,000건 이상의 요청 처리 |
| 확장성 | 단일 머신 리소스에 의해 제한됨 | 노드 간 선형 확장 |
| 내결함성 | 단일 장애점 | 자동 장애 조치, 자가 복구 |
| 지리적 분산 | 고정 위치 | 다중 지역 배포 |
| 리소스 활용도 | 수직 확장만 가능 | 수평 확장 최적화 |
| 복잡성 | 간단한 설정, 최소한의 오버헤드 | 복잡한 오케스트레이션, 높은 운영 비용 |
| 비용 | 낮은 초기 투자 비용 | 높은 인프라 비용, 규모 확대 시 더 나은 투자 수익률 |
| 유지 관리 | 운영 부담 최소화 | 분산 시스템 전문성 필요 |
| 데이터 처리 | 로컬 처리만 가능 | 노드 간 병렬 처리 |
| 탐지 방지 | 제한된 IP 로테이션 | 고급 프록시 관리, 지문 인식 |
분산형으로 전환해야 할까요? (결정 트리)
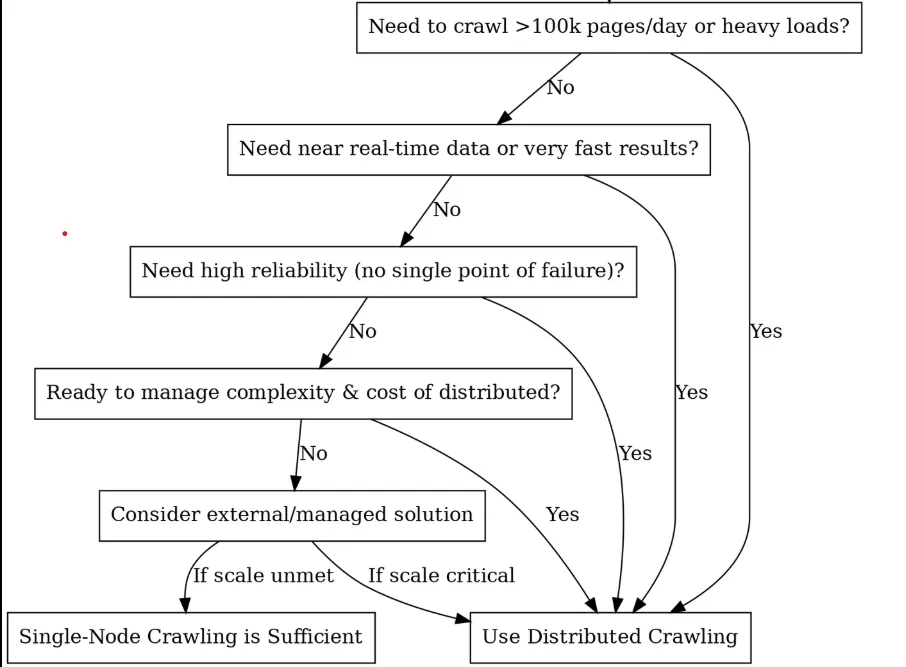
핵심 구성 요소 및 아키텍처
분산 크롤링을 선택했다면, 다음 단계는 구축할 시스템을 구체적으로 분해하는 것입니다. 각 구성 요소가 특정 역할을 맡고 완벽하게 협업해야 하는 고성능 레이싱 팀을 구성하는 것과 유사하다고 생각하세요. 분산 크롤링 시스템을 구축하는 데 필요한 핵심 구성 요소는 다음과 같습니다:
스케줄러/큐 (중추)
분산 크롤러의 핵심은 노드 간 작업을 조정하는 스케줄러 또는 작업 큐입니다. URL은 크롤링되기 전까지 여기에 저장됩니다. 스케줄러 구성 요소는 예의(타이밍) 및 재시도도 처리할 수 있습니다. 예를 들어, 특정 도메인 전용 큐를 구현하여 한 사이트가 모든 작업자에 의해 동시에 접근되지 않도록 할 수 있습니다.
스케줄러에는 각각 고유한 특성을 지닌 세 가지 주요 옵션이 있습니다:
- Kafka: 헤비급 챔피언과 같습니다. 방대한 처리량을 위해 설계되었으며 초당 수백만 개의 메시지를 처리해도 문제없습니다. 로그 기반 설계가 장점으로, URL 프론티어 관리에 완벽합니다. 도메인별로 파티셔닝하여 크롤링 예절을 유지할 수 있습니다.
- RabbitMQ: 스위스 군용 칼 같은 존재입니다. Kafka보다 유연한 라우팅을 제공하며 우선순위 큐 같은 기능을 갖추고 있습니다. RabbitMQ는 인메모리 저장 방식을 사용하므로 소규모 작업 부하에 더 빠릅니다. 콘텐츠 유형별로 다른 크롤링 전략이 필요할 때 탁월합니다.
- Celery: 파이썬 개발자의 든든한 조력자입니다. 다른 옵션들만큼 효율적이진 않지만 사용이 간편합니다. 신속한 프로토타이핑이나 중간 규모 크롤링 작업에 적합합니다.
URL 프론티어 & 중복 제거: 크롤러의 기억력
같은 페이지를 실수로 1,000번 크롤링한 적 있나요? 중복 제거가 바로 이런 상황에서 구원투수 역할을 합니다. 서버 예절을 지키면서 이미 방문한 페이지를 추적해야 동일한 도메인을 반복적으로 공격하지 않습니다.
레디스 세트(Redis Sets)는 완벽한 정확도를 제공하지만 메모리를 많이 소모합니다. 블룸 필터(Bloom Filters)는 메모리 사용량을 90% 줄여줍니다(10억 개 URL 기준 1.2GB vs 12GB 이상). 하지만 가끔 오탐(false positive)이 발생할 수 있습니다(이미 본 URL을 보지 않았다고 판단할 수 있음). 따라서 다음과 같은 레디스 구현을 고려해 볼 수 있습니다:
class DistributedURLFrontier:
def __init__(self, redis_client):
self.redis = redis_client
def add_url(self, url, priority=0):
domain = urlparse(url).netloc
# 이미 본 경우 건너뛰기
if self.redis.sismember("seen_urls", url):
return
# 확인된 것으로 표시하고 도메인별로 큐에 추가
self.redis.sadd("seen_urls", url)
self.redis.lpush(f"queue:{domain}", url)
self.redis.zadd("priority_queue", {url: priority})
def get_next_url(self):
# 최우선순위 URL 가져오기
result = self.redis.zrevrange("priority_queue", 0, 0)
if not result:
return None
url = result[0]
domain = urlparse(url).netloc
# 크롤링 지연 시간 준수 (도메인당 요청 간 1초 간격)
last_crawl = self.redis.get(f"last_crawl:{domain}")
if last_crawl and time.time() - float(last_crawl) < 1.0:
return None
# 큐에서 제거하고 마지막 크롤링 시간 업데이트
self.redis.zrem("priority_queue", url)
self.redis.rpop(f"queue:{domain}")
self.redis.set(f"last_crawl:{domain}", time.time())
return url
워커 노드 (근육)
워커 노드는 크롤링 작업의 주력입니다. URL 가져오기 및 콘텐츠 처리와 같은 실제 크롤링 작업을 수행하는 프로세스 또는 머신입니다. 각 워커는 동일한 크롤링 로직(예: 동일한 Python 스크립트 또는 애플리케이션)을 실행하지만, 큐에서 가져온 서로 다른 URL을 병렬로 처리합니다.
워커를 최대한 활용하려면 상태를 유지하지 않도록 해야 합니다. 즉, 방문한 URL, 결과 등 모든 상태 정보는 공유 저장소에 저장하거나 메시지를 통해 전달해야 합니다. 이렇게 하면 어떤 워커든 어떤 작업이든 가져올 수 있으며, 한 워커가 중단되더라도 다른 워커들이 즉시 그 공백을 메워 작업이 중단되지 않습니다.
class DistributedWorker:
def __init__(self, worker_id, max_concurrent=50):
self.worker_id = worker_id
self.semaphore = asyncio.Semaphore(max_concurrent)
self.session = aiohttp.ClientSession(
timeout=aiohttp.ClientTimeout(total=30),
connector=aiohttp.TCPConnector(limit=100)
)
async def crawl_batch(self, urls):
tasks = [self.crawl_url(url) for url in urls]
return await asyncio.gather(*tasks, return_exceptions=True)
async def crawl_url(self, url):
async with self.semaphore:
try:
async with self.session.get(url) as response:
content = await response.text()
return {'url': url, 'content': content, 'status': response.status}
except Exception as e:
return {'url': url, 'error': str(e)}
프로 팁: 워커를 사용할 때는 모든 작업에 대형 도끼를 휘두르지 않는 것이 중요합니다. 정적 HTML에는 가벼운 HTTP 워커를, 자바스크립트로 렌더링되는 페이지에는 무거운 Puppeteer 워커를 사용해야 합니다. 다른 도구에는 다른 워커 풀이 필요합니다. 포괄적인 프록시 선택 가이드를 통해 워커 군단에 적합한 프록시 유형을 쉽게 선택할 수 있습니다.
저장 계층 (창고)
스토리지 계층은 크롤링된 데이터와 메타데이터를 저장하는 곳으로, 일반적으로 두 부분으로 구성됩니다:
- 콘텐츠 저장소는 대량의 원시 HTML, JSON 응답, 이미지, PDF를 처리합니다. 디지털 창고라고 생각하세요. S3, Google Cloud Storage, HDFS 같은 객체 저장소가 여기에 탁월합니다. 무한히 확장 가능하며 여러 워커의 동시 쓰기를 손쉽게 처리하기 때문입니다.
- 메타데이터 저장소는 추출한 구조화된 핵심 정보(구문 분석된 필드, 엔터티 관계, 크롤링 타임스탬프, 성공/실패 상태)를 보관합니다. 이는 단순 저장 용량이 아닌 쿼리 및 업데이트에 최적화된 데이터베이스에 저장됩니다.
분산 크롤러는 막힘 없이 대규모 동시 쓰기를 처리할 수 있는 스토리지가 필요합니다. S3나 Google Cloud Storage 같은 객체 저장소는 무한한 확장성으로 원시 콘텐츠 처리에 탁월한 반면, NoSQL 데이터베이스(MongoDB, Cassandra)나 SQL은 구조화된 메타데이터를 효과적으로 처리합니다.
모니터링 및 알림
분산 크롤러 운영에는 시스템 성능에 대한 가시성이 필요합니다. Prometheus와 Grafana를 활용해 크롤링 속도, 성공률, 응답 시간, 대기열 깊이를 추적하는 포괄적인 모니터링 대시보드를 구축할 수 있습니다. 주요 지표로는 도메인별 초당 요청 수, 95분위수 응답 시간, 대기열 크기 추세 등이 포함됩니다.
봇 방지 및 회피 계층
대규모 웹 크롤링은 봇 방지 시스템과의 끊임없는 추격전을 의미합니다. 방어에는 세 가지 계층이 필요합니다: 수천 개의 주거용 및 데이터센터 프록시를 통한 IP 로테이션, 사용자 에이전트 및 브라우저 서명의 지문 무작위화, 탐지 패턴 회피를 위한 행동 모방입니다.
Bright Data Web Unlocker는 자동 CAPTCHA 해결, IP 로테이션, 브라우저 지문 인식 기술을 통해 99% 이상의 성공률을 자랑하는 엔터프라이즈급 탐지 회피 기능을 제공합니다. API 기반 접근 방식으로 복잡한 봇 방지 문제를 처리하면서도 통합을 간소화합니다.
class BrightDataWebUnlocker:
def crawl_url(self, url: str, options: Dict = None) -> Dict:
payload = {
"url": url,
"zone": self.zone,
"format": "raw",
"country": "US",
"render_js": True,
"wait_for_selector": ".content"
}
response = requests.post(
self.base_url,
headers={"Authorization": f"Bearer {self.api_key}"},
json=payload,
timeout=60
)
고급 프록시 로테이션은 주거용, 데이터센터, 모바일 프록시 풀 전반에 걸쳐 상태 점검, 지리적 최적화 및 장애 복구를 구현합니다. 성공적인 프록시 관리는 1000개 이상의 IP와 지능형 로테이션 알고리즘을 필요로 합니다.
지문 인식 회피는 사용자 에이전트, 브라우저 지문, 네트워크 특성을 무작위화하여 정교한 봇 방지 시스템의 탐지를 방지합니다. 여기에는 TLS 지문 회전, 캔버스 지문 스푸핑, 행동 패턴 시뮬레이션이 포함됩니다.
코드 예제가 포함된 실제 사용 사례
분산 크롤러의 두 가지 일반적인 사용 사례를 살펴보고, 코드 스니펫을 통해 이를 구현하는 방법을 개요로 제시합니다. 예시에서는 단순화를 위해 Python과 Celery를 사용하지만, 원칙은 일반적으로 적용됩니다.
사용 사례 1: 전자상거래 가격 모니터링
매일 50,000개 상품 페이지의 경쟁사 가격을 추적한다고 가정해 보세요. 단일 머신으로 이 모든 URL을 처리하려 한다면, 아무 문제 없더라도 12시간 이상의 크롤링 시간이 소요됩니다. 게다가 대부분의 전자상거래 사이트는 동일 IP에서 수천 건의 빠른 요청이 발생하면 차단하기 시작합니다.
이때 분산 크롤링이 해결책이 됩니다. 한 대의 과부하된 머신 대신, 50,000개 URL을 서로 다른 IP를 사용하는 수십 대의 워커에 분산합니다. 반나절 걸리던 작업이 2~3시간 만에 완료되며, 반봇 시스템의 감시를 피할 수 있습니다.
설정은 간단합니다. 경쟁사 URL 목록을 관리해야 합니다(사이트맵이나 탐색 크롤링에서 수집). 그런 다음 Celery와 Redis 같은 도구를 사용해 작업을 분배하세요. 매일 아침 50,000개 URL을 모두 대기열에 넣으면 작업자 군단이 작업을 시작합니다. 작업자 1은 나이키 러닝화, 작업자 2는 아디다스 스니커즈, 작업자 3은 푸마 가격 정보를 각각 처리합니다. 모두 동시에, 서로 다른 IP에서 수행됩니다.
from celery import Celery
import requests
from bs4 import BeautifulSoup
import random
import time
import re
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
# Redis를 브로커로 사용하는 Celery 앱 초기화
app = Celery('price_monitor', broker='redis://localhost:6379/0')
# 실제 사용자 에이전트 순환
USER_AGENTS = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:89.0) Gecko/20100101 Firefox/89.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.1.1 Safari/605.1.15"
]
# 프록시 풀 (실제 프록시 서비스로 대체)
PROXY_POOL = [
"<http://proxy1:8080>",
"<http://proxy2:8080>",
"<http://proxy3:8080>",
# 여기에 프록시 엔드포인트 추가
]
def get_session_with_retries():
"""재시도 전략과 무작위 프록시를 사용하여 세션 생성"""
session = requests.Session()
# 복원력을 위한 재시도 전략
retry_strategy = Retry(
total=3,
backoff_factor=1,
status_forcelist=[429, 500, 502, 503, 504],
)
adapter = HTTPAdapter(max_retries=retry_strategy)
session.mount("http://", adapter)
session.mount("https://", adapter)
# 무작위 프록시 로테이션
if PROXY_POOL:
proxy = random.choice(PROXY_POOL)
session.proxies = {"http": proxy, "https": proxy}
return session
@app.task(bind=True, max_retries=3)
def fetch_product_price(self, url, site_config=None):
"""완벽한 탐지 방지 조치와 함께 제품 가격을 가져옵니다."""
# 시작 전 인간과 유사한 지연 시간
time.sleep(random.uniform(2, 8))
# 지문 추적을 피하기 위한 무작위 헤더
headers = {
"User-Agent": random.choice(USER_AGENTS),
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Cache-Control": "max-age=0"
}
try:
session = get_session_with_retries()
resp = session.get(url, headers=headers, timeout=30)
resp.raise_for_status()
# 페이지에서 가격 파싱
soup = BeautifulSoup(resp.text, 'html.parser')
price_value = extract_price(soup, url, site_config)
if price_value:
# 데이터베이스 저장 (저장 로직 구현)
store_price_data(url, price_value, resp.status_code)
return {"url": url, "price": price_value, "status": "success"}
else:
return {"url": url, "error": "가격 정보 미검출", "status": "failed"}
except requests.exceptions.RequestException as e:
print(f"{url} 요청 실패: {e}")
# 지수적 백오프로 재시도
if self.request.retries < self.max_retries:
raise self.retry(countdown=60 * (2 ** self.request.retries))
return {"url": url, "error": str(e), "status": "failed"}
def extract_price(soup, url, site_config=None):
"""여러 전략을 사용하여 가격 추출."""
# 사이트별 선택기 (경쟁사별로 맞춤 설정)
price_selectors = [
".price", ".product-price", ".current-price", ".sale-price",
"[data-price]", ".price-current", ".price-now", ".offer-price"
]
# 설정된 선택자를 우선 시도
if site_config and site_config.get('price_selector'):
price_selectors.insert(0, site_config['price_selector'])
price_text = None
for selector in price_selectors:
price_elem = soup.select_one(selector)
if price_elem:
price_text = price_elem.get_text(strip=True)
break
# 데이터 속성을 대체 수단으로 시도
if not price_text:
price_elem = soup.find(attrs={"data-price": True})
if price_elem:
price_text = price_elem.get("data-price")
if not price_text:
return None
# 가격 정리 및 파싱
return parse_price(price_text)
def parse_price(price_text):
"""다양한 형식의 가격을 파싱합니다."""
# 일반적인 통화 기호 및 공백 제거
cleaned = re.sub(r'[^\d.,]', '', price_text)
# "1,299.99" 또는 "1299.99" 형식 처리
try:
# 콤마 제거 및 부동 소수점 변환
if ',' in cleaned and '.' in cleaned:
# 형식: 1,299.99
price_value = float(cleaned.replace(',', ''))
elif ',' in cleaned:
# 유럽식 형식일 수 있음: 1299,99
if cleaned.count(',') == 1 and len(cleaned.split(',')[1]) == 2:
price_value = float(cleaned.replace(',', '.'))
else:
# 형식: 1,299 (센트 없음)
price_value = float(cleaned.replace(',', ''))
else:
price_value = float(cleaned)
return price_value
except ValueError:
print(f"가격 파싱 실패: {price_text}")
return None
def store_price_data(url, price, status_code):
"""가격 데이터를 데이터베이스에 저장합니다."""
# 저장 로직 구현 (PostgreSQL, MongoDB 등)
# print(f"저장 중: {url} -> ${price} (상태: {status_code})")
# 정확도 향상을 위한 사이트별 설정
SITE_CONFIGS = {
"competitor1.com": {"price_selector": ".price-box .price"},
"competitor2.com": {"price_selector": "[data-testid='price']"},
"competitor3.com": {"price_selector": ".product-price-value"},
}
def get_site_config(url):
"""사이트별 구성 가져오기."""
for domain, config in SITE_CONFIGS.items():
if domain in url:
return config
return None
# 50,000개 제품 URL 로드 (데이터베이스, 파일 또는 API에서)
def load_product_urls():
"""데이터 소스에서 URL을 로드합니다."""
# 실제 데이터 로딩 로직으로 대체하세요
urls = [
"<https://competitor1.com/product/123>",
"<https://competitor2.com/product/456>",
# ... 49,998개의 추가 URL
]
return urls
# 메인 실행: 모든 크롤링 작업 배포
def start_daily_price_monitoring():
"""일일 가격 모니터링 작업 시작."""
product_urls = load_product_urls()
print(f"{len(product_urls)}개 URL 크롤링 시작...")
for url in product_urls:
site_config = get_site_config(url)
fetch_product_price.delay(url, site_config)
print("모든 작업이 성공적으로 대기열에 추가되었습니다!")
# 실행 방법: python -m celery worker -A price_monitor --loglevel=info
# 모니터링 시작: start_daily_price_monitoring()
위 개선된 코드에서 fetch_product_price는 기업 규모 가격 모니터링을 위해 설계된 강력한 Celery 작업입니다. 각 URL에 대해 delay(url, site_config)를 호출함으로써 작업을 Redis에 대기열에 넣고, 100개 이상의 작업자가 즉시 이를 가져올 수 있게 합니다. 이 분산 방식은 12시간이 걸리던 단일 머신 크롤링을 작업자 군집 전체에서 2~3시간 작업으로 전환합니다.
주요 운영 고려사항:
- 프록시 관리가 핵심: 이 예제에는 요청마다 IP를 회전시키는 PROXY_POOL이 포함되어 있으며, 50,000개 URL을 처리할 때 필수적입니다. 이를 적용하지 않으면 단일 IP로 대상 사이트에 DoS 공격을 가하는 것과 같아 차단될 수밖에 없습니다.
- 도메인별 속도 제한: 분산 처리에도 불구하고, 경쟁사 사이트 50,000개 URL이 몇 분 내에 동시에 접속하면 경보가 발생합니다. 인간과 유사한 지연 시간(
time.sleep(random.uniform(2, 8)))을 포함하지만, 도메인별 속도 제한을 고려하세요. - 스케줄링 및 모니터링. 일일 스케줄링에는 Celery Beat를 사용하거나 복잡한 워크플로에는 Airflow와 통합하세요.
start_daily_price_monitoring()함수는 cron 또는 오케스트레이션 플랫폼을 통해 트리거할 수 있습니다. - 데이터 파이프라인 통합. 각 크롤링 후
store_price_data()함수가 결과를 데이터베이스에 저장합니다. - 장애 복원력. 코드에는 지수적 백오프 재시도 로직이 포함되어 있으나, 부분적 장애에 대비하십시오. URL의 5%가 지속적으로 실패할 경우 해당 제품이 단종되었는지, 이동되었는지, 또는 해당 사이트가 더 강력한 봇 방지 조치를 적용하여 다른 접근 방식이 필요한지 조사하십시오.
사용 사례 2: SEO 및 시장 조사
SEO 및 시장 조사는 콘텐츠 분석과 검색 엔진 모니터링이라는 두 가지 핵심 영역에서 수백만 페이지의 크롤링을 요구합니다. 단순한 스크래핑이 아닌, 속도, 은밀성, 정밀성을 요구하는 경쟁 정보 구축 작업입니다.
100만 개의 경쟁사 페이지에서 키워드 언급을 추적하면서 동시에 수백 개의 타겟 키워드에 대한 SERP 순위를 매일 모니터링하려면, 단일 머신으로는 몇 주가 소요되고 몇 시간 내에 차단될 것입니다. 이는 분산형 아키텍처를 절실히 요구합니다.
이를 위한 분산형 웹 크롤링 접근법은 두 가지 스트림으로 나눌 수 있습니다:
- 콘텐츠 인텔리전스: 경쟁사 사이트, 뉴스 매체, 업계 블로그를 크롤링하여 키워드 밀도, 콘텐츠 공백, 시장 동향을 추적
- SERP 감시: 타겟 키워드의 Google/Bing 순위를 모니터링하며 경쟁사 위치 및 SERP 기능 변경 추적
from celery import Celery
import requests
from bs4 import BeautifulSoup
import redis
import hashlib
import json
import time
import random
import re
from urllib.parse import urljoin, urlparse
from dataclasses import dataclass
from typing import List, Dict, Optional
import logging
# Celery 및 Redis 초기화
app = Celery('seo_intelligence', broker='redis://localhost:6379/0')
redis_client = redis.Redis(host='localhost', port=6379, db=1)
# 탐지 방지 설정
USER_AGENTS = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/120.0.0.0 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 Chrome/120.0.0.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:121.0) Gecko/20100101 Firefox/121.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 Safari/605.1.15"
]
PROXY_POOL = [
"<http://user:[email protected]:8080>",
"<http://user:[email protected]:8080>",
# 프록시 엔드포인트 추가
]
@dataclass
class KeywordData:
keyword: str
frequency: int
context: List[str] # 주변 텍스트 스니펫
url: str
domain: str
@dataclass
class SERPResult:
keyword: str
position: int
title: str
url: str
snippet: str
domain: str
class SEOCrawler:
def __init__(self):
self.session = self._create_session()
def _create_session(self):
session = requests.Session()
if PROXY_POOL:
proxy = random.choice(PROXY_POOL)
session.proxies = {"http": proxy, "https": proxy}
return session
def _get_headers(self):
return {
"User-Agent": random.choice(USER_AGENTS),
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Cache-Control": "max-age=0"
}
# 중복 제거 유틸리티
def get_url_hash(url: str) -> str:
"""URL 중복 제거를 위한 일관된 해시 생성."""
return hashlib.md5(url.encode()).hexdigest()
def is_url_processed(url: str) -> bool:
"""해당 URL이 오늘 이미 처리되었는지 확인합니다."""
url_hash = get_url_hash(url)
today = time.strftime("%Y-%m-%d")
return redis_client.exists(f"processed:{today}:{url_hash}")
def mark_url_processed(url: str):
"""URL을 24시간 만료로 처리된 것으로 표시합니다."""
url_hash = get_url_hash(url)
today = time.strftime("%Y-%m-%d")
redis_client.setex(f"processed:{today}:{url_hash}", 86400, 1)
# 스트림 1: 콘텐츠 인텔리전스 크롤링
@app.task(bind=True, max_retries=3)
def crawl_content_for_keywords(self, url: str, target_keywords: List[str]):
"""페이지를 크롤링하고 키워드 인텔리전스를 추출합니다."""
# 오늘 이미 처리된 경우 건너뜁니다
if is_url_processed(url):
return {"status": "skipped", "reason": "already_processed", "url": url}
# 인간과 유사한 지연 시간
time.sleep(random.uniform(3, 7))
try:
crawler = SEOCrawler()
response = crawler.session.get(
url,
headers=crawler._get_headers(),
timeout=30
)
response.raise_for_status()
# 콘텐츠 추출 및 키워드 분석
soup = BeautifulSoup(response.text, 'html.parser')
content_data = extract_keyword_intelligence(soup, url, target_keywords)
# 결과 저장
store_keyword_data(content_data)
mark_url_processed(url)
return {
"status": "success",
"url": url,
"keywords_found": len(content_data),
"total_mentions": sum(kd.frequency for kd in content_data)
}
except Exception as e:
logging.error(f"{url} 콘텐츠 크롤링 실패: {e}")
if self.request.retries < self.max_retries:
raise self.retry(countdown=60 * (2 ** self.request.retries))
return {"status": "failed", "url": url, "error": str(e)}
def extract_keyword_intelligence(soup: BeautifulSoup, url: str, keywords: List[str]) -> List[KeywordData]:
"""페이지 콘텐츠에서 키워드 데이터를 추출합니다."""
# 스크립트 및 스타일 요소 제거
for script in soup(["script", "style", "nav", "footer", "header"]):
script.decompose()
# 깨끗한 텍스트 콘텐츠 가져오기
text = soup.get_text()
text = re.sub(r'\s+', ' ', text).strip().lower()
domain = urlparse(url).netloc
keyword_data = []
for keyword in keywords:
keyword_lower = keyword.lower()
# 모든 발생 위치 찾기
pattern = r'\b' + re.escape(keyword_lower) + r'\b'
matches = list(re.finditer(pattern, text))
if matches:
# 각 일치 항목 주변 문맥 추출
contexts = []
for match in matches[:5]: # 성능을 위해 처음 5개로 제한
start = max(0, match.start() - 100)
end = min(len(text), match.end() + 100)
context = text[start:end].strip()
contexts.append(context)
keyword_data.append(KeywordData(
keyword=keyword,
frequency=len(matches),
context=contexts,
url=url,
domain=domain
))
return keyword_data
# 스트림 2: SERP 추적
@app.task(bind=True, max_retries=3)
def track_serp_rankings(self, keyword: str, search_engine: str = "google"):
"""키워드의 SERP 순위를 추적합니다."""
time.sleep(random.uniform(5, 10)) # 검색 엔진에 대한 긴 지연 시간
try:
crawler = SEOCrawler()
if search_engine == "google":
search_url = f"<https://www.google.com/search?q={keyword}&num=20>"
else: # Bing
search_url = f"<https://www.bing.com/search?q={keyword}&count=20>"
# 검색 엔진 전용 헤더
headers = crawler._get_headers()
headers.update({
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Referer": "<https://www.google.com/>" if search_engine == "google" else "<https://www.bing.com/>"
})
response = crawler.session.get(search_url, headers=headers, timeout=30)
response.raise_for_status()
# SERP 결과 파싱
soup = BeautifulSoup(response.text, 'html.parser')
serp_data = parse_serp_results(soup, keyword, search_engine)
# SERP 데이터 저장
store_serp_data(serp_data)
return {
"status": "success",
"keyword": keyword,
"results_found": len(serp_data),
"search_engine": search_engine
}
except Exception as e:
logging.error(f"SERP 추적 실패: '{keyword}': {e}")
if self.request.retries < self.max_retries:
raise self.retry(countdown=120 * (2 ** self.request.retries))
return {"status": "failed", "keyword": keyword, "error": str(e)}
def parse_serp_results(soup: BeautifulSoup, keyword: str, search_engine: str) -> List[SERPResult]:
"""검색 엔진 결과 페이지 파싱."""
results = []
position = 1
if search_engine == "google":
# Google 결과 선택자
result_elements = soup.select('div.g')
for element in result_elements:
title_elem = element.select_one('h3')
link_elem = element.select_one('a[href]')
snippet_elem = element.select_one('.VwiC3b, .s3v9rd')
if title_elem and link_elem:
url = link_elem.get('href', '')
if url.startswith('/url?q='):
url = url.split('/url?q=')[1].split('&')[0]
results.append(SERPResult(
keyword=keyword,
position=position,
title=title_elem.get_text(strip=True),
url=url,
snippet=snippet_elem.get_text(strip=True) if snippet_elem else "",
domain=urlparse(url).netloc if url else ""
))
position += 1
if position > 20: # 상위 20개로 제한
break
else: # Bing
result_elements = soup.select('.b_algo')
for element in result_elements:
title_elem = element.select_one('h2 a')
snippet_elem = element.select_one('.b_caption p')
if title_elem:
url = title_elem.get('href', '')
results.append(SERPResult(
keyword=keyword,
position=position,
title=title_elem.get_text(strip=True),
url=url,
snippet=snippet_elem.get_text(strip=True) if snippet_elem else "",
domain=urlparse(url).netloc if url else ""
))
position += 1
if position > 20:
break
return results
# 데이터 저장 함수
def store_keyword_data(keyword_data: List[KeywordData]):
"""키워드 인텔리전스를 데이터베이스에 저장합니다."""
for kd in keyword_data:
data = {
"keyword": kd.keyword,
"frequency": kd.frequency,
"context": kd.context,
"url": kd.url,
"domain": kd.domain,
"crawled_at": time.time()
}
# 선호하는 데이터베이스(PostgreSQL, MongoDB 등)에 저장
redis_client.lpush(f"keyword_data:{kd.keyword}", json.dumps(data))
print(f"저장됨: {kd.keyword}가 {kd.domain}에서 {kd.frequency}회 발견됨")
def store_serp_data(serp_data: List[SERPResult]):
"""SERP 추적 데이터를 저장합니다."""
for result in serp_data:
data = {
"keyword": result.keyword,
"position": result.position,
"title": result.title,
"url": result.url,
"snippet": result.snippet,
"domain": result.domain,
"tracked_at": time.time()
}
redis_client.lpush(f"serp_data:{result.keyword}", json.dumps(data))
print(f"SERP: '{result.keyword}' -> #{result.position} {result.domain}")
# 오케스트레이션 함수
def start_content_intelligence_crawl(urls: List[str], keywords: List[str]):
"""100만 개 이상의 URL에 걸쳐 콘텐츠 크롤링을 시작합니다."""
print(f"{len(urls)}개의 URL에 대한 콘텐츠 인텔리전스 크롤링 시작...")
for url in urls:
crawl_content_for_keywords.delay(url, keywords)
print(f"{len(urls)}개의 콘텐츠 크롤링 작업 대기 중")
def start_serp_tracking(keywords: List[str], search_engines: List[str] = ["google", "bing"]):
"""대상 키워드에 대한 SERP 추적 시작."""
print(f"{len(keywords)}개의 키워드에 대한 SERP 추적 시작...")
for keyword in keywords:
for engine in search_engines:
track_serp_rankings.delay(keyword, engine)
print(f"{len(keywords) * len(search_engines)}개의 SERP 추적 작업 대기 중")
# 사용 예시
if __name__ == "__main__":
# 분석 대상 키워드
target_keywords = [
"인공 지능", "머신 러닝", "데이터 사이언스",
"클라우드 컴퓨팅", "사이버 보안", "디지털 전환"
]
# 콘텐츠 인텔리전스 크롤링 대상 URL (데이터베이스에서 로드)
content_urls = [
"<https://techcrunch.com/ai>",
"<https://venturebeat.com/ai>",
"<https://competitor-blog.com/insights>",
# ... 999,997개 추가 URL
]
# SERP에서 추적할 키워드
serp_keywords = [
"best AI tools 2026", "enterprise machine learning",
"data analytics platform", "cloud security solutions"
]
# 두 크롤링 스트림 모두 시작
start_content_intelligence_crawl(content_urls, target_keywords)
start_serp_tracking(serp_keywords)
주요 생산 고려 사항:
- 지능형 중복 제거: 시스템은 동일한 콘텐츠를 매일 재크롤링하지 않도록 24시간 만료 기간을 가진 Redis를 사용합니다. 더 심층적인 중복 제거를 위해 콘텐츠 해싱을 고려하여 URL은 변경되었지만 동일한 콘텐츠를 유지한 페이지를 감지할 수 있습니다.
- 도메인 인식 속도 제한: 검색 엔진이 차단에 더 적극적이기 때문에 SERP 크롤링에는 특별한 주의가 필요합니다. 본 예시에서는 콘텐츠 크롤링(3~7초) 대비 검색 쿼리(5~10초)에 더 긴 지연 시간을 적용합니다.
- SERP 기능 추적: 파서는 Google과 Bing 결과를 모두 처리하지만, 피처드 스니펫, 로컬 팩 및 가시성 전략에 영향을 미치는 기타 SERP 기능을 추적하도록 확장할 수 있습니다.
- 데이터 파이프라인 통합: 선호하는 데이터베이스(관계형 분석용 PostgreSQL, 유연한 스키마용 MongoDB)에 결과를 저장합니다.
모범 사례
robots.txt를 준수하지 않으면 심각한 결과를 초래합니다
URL을 대기열에 추가하기 전에 robots.txt를 파싱하고 crawl-delay 지시어를 철저히 준수하십시오. 이를 무시하면 “분산 크롤러”라고 말하기도 전에 전체 IP 범위가 블랙리스트에 등록될 수 있습니다. URL 프론티어에 robots.txt 검사를 직접 구축하고, 이를 작업자 노드의 책임으로 만들지 마십시오.
robots.txt 준수 외에도, 전체 분산 시스템에 걸쳐 포괄적인 탐지 회피 전략을 구현해야 합니다.
새벽 3시 디버깅을 위한 로그 기록은 필수
자정에 크롤링이 중단되면 메타데이터가 필요합니다: URL, HTTP 상태, 지연 시간, 프록시 ID, 작업자 ID, 그리고 모든 요청의 타임스탬프. JSON 구조의 로그는 정신 건강을 지켜줍니다. 문제는 프로덕션 장애를 디버깅해야 할지 여부가 아니라, 언제 해야 할지입니다.
모든 것을 검증하고, 아무것도 믿지 마십시오
분산 웹 크롤러의 생존을 위해 추출된 데이터에 대한 스키마 검증이 필수적입니다. 단 하나의 잘못된 응답만으로도 전체 데이터셋이 오염될 수 있기 때문입니다. 수집 시 필드 유형, 필수 필드, 데이터 최신성을 확인하세요. 쓰레기를 조기에 포착하지 않으면 몇 달 후 분석을 망가뜨리는 것을 발견하게 될 것입니다.
속도 부채를 무자비하게 처리하라
분산 시스템은 빠르게 부패합니다. 오래된 Redis 키, 실패한 작업 큐, 고아 작업자 프로세스를 매월 정리해야 합니다. 죽은 URL은 쌓이고, 프록시 풀은 차단된 IP로 오염되며, 작업자 메모리 누수는 시간이 지날수록 악화됩니다. 유지보수는 화려하지 않지만 크롤러를 건강하게 유지합니다. 크롤러의 기술적 부채는 기하급수적으로 증가하므로 시스템이 망가지기 전에 해결하세요.
분산 크롤링의 흔한 함정과 회피 방법
분산 웹 크롤링을 사용할 때 사람들이 직면하는 수많은 흔한 함정이 존재하기 때문에, 대부분의 엔지니어들은 Bright Data의 데이터 세트와 같은 대안을 찾습니다. 이러한 함정 중 일부는 다음과 같습니다:
“단일 장애점” 함정
모든 것을 하나의 Redis 인스턴스나 마스터 코디네이터에 의존하는 것은 좋지 않은 생각입니다. 이 인스턴스가 다운되면 전체 크롤링이 완전히 중단됩니다.
해결책: Redis 클러스터 또는 다중 브로커 인스턴스를 사용하세요. 코디네이터가 사라질 수 있도록 설계하여, 작업자가 브로커 중단을 우아하게 처리하고 자동으로 재연결할 수 있도록 해야 합니다.
재시도 죽음의 나선
실패한 URL이 즉시 메인 큐로 재투입되면 무한 루프가 발생하여 고장난 엔드포인트를 계속 공격하고 파이프라인을 막습니다.
해결책: 지수적 백오프를 적용한 별도의 재시도 큐를 분리하세요. 첫 재시도는 1분 후, 다음은 5분 후, 그다음은 30분 후로 설정합니다. 3회 실패 시 수동 검토를 위해 데드 레터 큐로 전송하세요.
모든 작업자가 동등하다는 오류
라운드 로빈 작업 분배는 모든 작업자가 동일한 네트워크 속도, 프록시 품질, 처리 능력을 가질 것이라고 가정합니다. 현실은 종종 더 복잡합니다.
해결책: 성공률, 지연 시간, 처리량을 기반으로 작업자 점수제를 도입하세요. 어려운 작업은 최고 성능 작업자에게 할당하세요.
메모리 누수 시한폭탄
재시작되지 않는 워커는 특히 잘못된 HTML을 파싱하거나 대용량 응답을 처리할 때 메모리 누수를 축적합니다. 방치하면 분산 웹 크롤링 성능이 저하되어 워커가 중단될 수 있습니다.
해결책: 작업자당 1000개 작업 처리 후 또는 4시간마다 재시작합니다. 메모리 사용량을 모니터링하고 서킷 브레이커를 구현하세요.
결론
이제 수백만 페이지까지 확장 가능한 분산 크롤링의 청사진을 확보했습니다. 분산 시스템의 기반이 되는 웹 크롤링 기본 원리를 심층적으로 이해하려면 포괄적인 웹 크롤러 개요를 참고하세요.
아키텍처는 간단하지만, 냉혹한 현실은 분산 웹 크롤링 시스템의 탐지 회피 복잡성을 과소평가하는 탓에 여전히 90%의 팀이 실패한다는 점입니다. 수천 개의 프록시 관리, 지문 회전, CAPTCHA 처리는 가치 있는 데이터 추출에서 주의를 분산시키는 전담 엔지니어링 악몽이 됩니다.
바로 이 때문에 Bright Data의 Web Unlocker API가 존재합니다. 매주 고장 나는 프록시 인프라 구축에 몇 달을 허비하는 대신, 분산된 작업자들이 Web Unlocker의 99% 이상 성공률 API를 통해 요청을 전달하기만 하면 됩니다.
프록시 관리, 지문 회전, CAPTCHA 해결이 필요 없습니다. 대규모로 안정적인 데이터 추출만 가능합니다. 엔지니어링 팀은 비즈니스 로직 구축에 집중하고, Bright Data가 봇 방지 시스템과의 숨바꼭질을 처리합니다.
계산은 간단합니다: 자체 개발한 탐지 방지 시스템은 수개월의 엔지니어링 시간과 지속적인 유지보수 부담을 초래하는 반면, Web Unlocker는 그 일부 비용으로 엔터프라이즈급 안정성을 제공합니다. 따라서 휠을 재발명하는 것을 멈추고 인사이트 추출을 시작하세요. 지금 바로 무료 Bright Data 계정을 생성하고 분산 크롤러를 유지보수 부담에서 경쟁 우위로 전환하십시오.





