

웹 스크래핑은 데이터 분석이나 AI 모델 미세 조정 등의 목적으로 웹사이트에서 데이터를 자동으로 수집하는 과정입니다.
Python은XML 및 HTML 문서 파싱에 사용되는lxml을 비롯한 다양한 스크래핑 라이브러리를 보유하여 웹 스크래핑에 널리 사용됩니다. lxml은 고속 C 라이브러리인libxml2및libxslt를 위한 Python API로 Python의 기능을 확장합니다. 또한 Python의 XML/HTML 트리용 계층적 데이터 구조인ElementTree와 통합되어 효율적이고 신뢰할 수 있는 웹 스크래핑을 위한 선호 도구입니다.
이 글에서는 웹 스크래핑에 lxml을 활용하는 방법을 배울 수 있습니다.
완벽한 대안으로서의 Bright Data 솔루션
웹 스크래핑에 있어 Python과 lxml을 함께 사용하는 것은 강력한 접근 방식이지만, 특히 복잡한 웹사이트나 대량의 데이터를 다룰 때 시간과 비용이 많이 소요될 수 있습니다. Bright Data는 즉시 사용 가능한 데이터셋과 웹 스크래퍼 API를 통해 효율적인 대안을 제공합니다. 이러한 솔루션은 100개 이상의 도메인에서 미리 수집된 데이터와 통합이 쉬운 스크래핑 API를 제공함으로써 데이터 수집에 소요되는 시간과 비용을 크게 줄여줍니다.
Bright Data를 사용하면 수동 스크래핑의 기술적 어려움을 우회할 수 있어 데이터 수집보다 분석에 집중할 수 있습니다. 특정 요구사항에 맞춘 데이터셋이 필요하든, 프록시 관리 및 CAPTCHA 해결을 처리하는 API가 필요하든, Bright Data의 도구는 모든 웹 스크래핑 요구사항에 대해 간소화되고 비용 효율적인 솔루션을 제공합니다.
Python에서 웹 스크래핑을 위한 lxml 사용
웹상에서 구조화되고 계층적인 데이터는 HTML과 XML 두 가지 형식으로 표현될 수 있습니다:
- XML은 사전 정의된 태그나 스타일이 없는 기본 구조입니다. 개발자가 자체 태그를 정의하여 구조를 생성합니다. 태그의 주요 목적은 서로 다른 시스템 간에 이해 가능한 표준 데이터 구조를 만드는 것입니다.
- HTML은 사전 정의된 태그를 가진 웹 마크업 언어입니다. 이러한 태그에는
<h1>태그의글꼴 크기나<img />태그의표시방식과 같은 일부 스타일 속성이 포함됩니다. HTML의 주요 기능은 웹 페이지를 효과적으로 구조화하는 것입니다.
lxml은 HTML 및 XML 문서 모두와 호환됩니다.
필수 조건
lxml로 웹 스크래핑을 시작하기 전에 컴퓨터에 몇 가지 라이브러리를 설치해야 합니다:
pip install lxml requests cssselect
이 명령어는 다음을 설치합니다:
정적 HTML 콘텐츠 파싱
웹 콘텐츠는 크게 정적 콘텐츠와 동적 콘텐츠 두 가지 유형으로 스크래핑할 수 있습니다. 정적 콘텐츠는 웹 페이지가 처음 로드될 때 HTML 문서에 내장되어 있어 스크래핑이 쉽습니다. 반면 동적 콘텐츠는 초기 페이지 로드 후 지속적으로 로드되거나 JavaScript에 의해 트리거됩니다. 동적 콘텐츠를 스크래핑하려면 콘텐츠가 브라우저에서 사용 가능해진 후에만 스크래핑 함수가 실행되도록 타이밍을 맞춰야 합니다.
이 글에서는 테스트용으로 설계된 정적 HTML 콘텐츠를 가진Books to Scrape 웹사이트를 스크래핑하는 것으로 시작합니다. 책의 제목과 가격을 추출하여 해당 정보를 JSON 파일로 저장합니다.
시작하려면 브라우저의 개발자 도구(Dev Tools )를 사용하여 관련 HTML 요소를 식별하세요. 웹 페이지에서 마우스 오른쪽 버튼을 클릭하고 ‘검사(Inspect) ‘ 옵션을 선택하여 개발자 도구를 엽니다. Chrome을 사용하는 경우 F12 키를 눌러 이 메뉴에 접근할 수 있습니다:
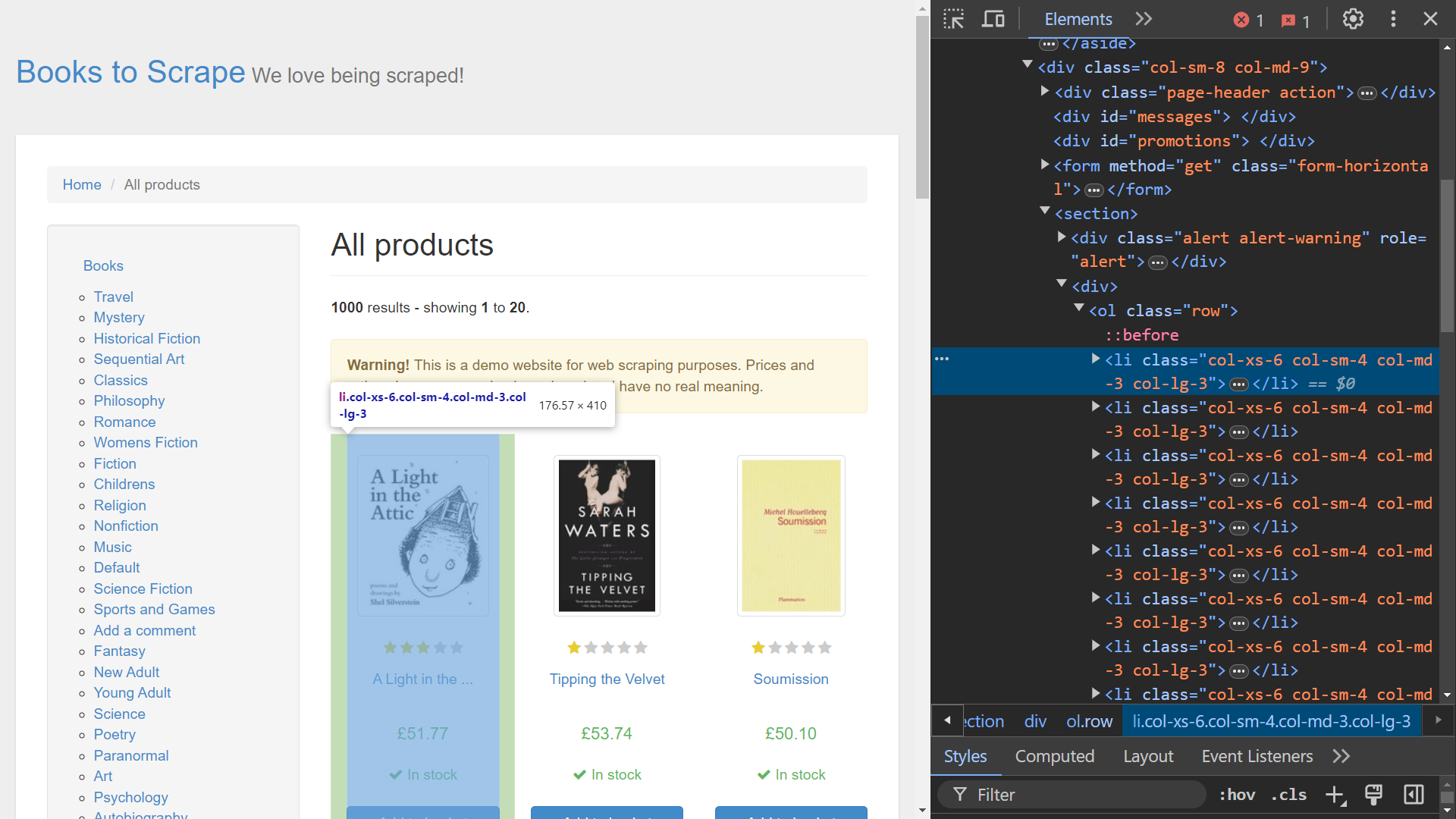
화면 오른쪽에는 페이지 렌더링을 담당하는 코드가 표시됩니다. 각 도서 데이터를 처리하는 특정 HTML 요소를 찾으려면, 마우스를 올려 선택하기 옵션(화면 왼쪽 상단의 화살표)을 사용하여 코드를 검색하세요:
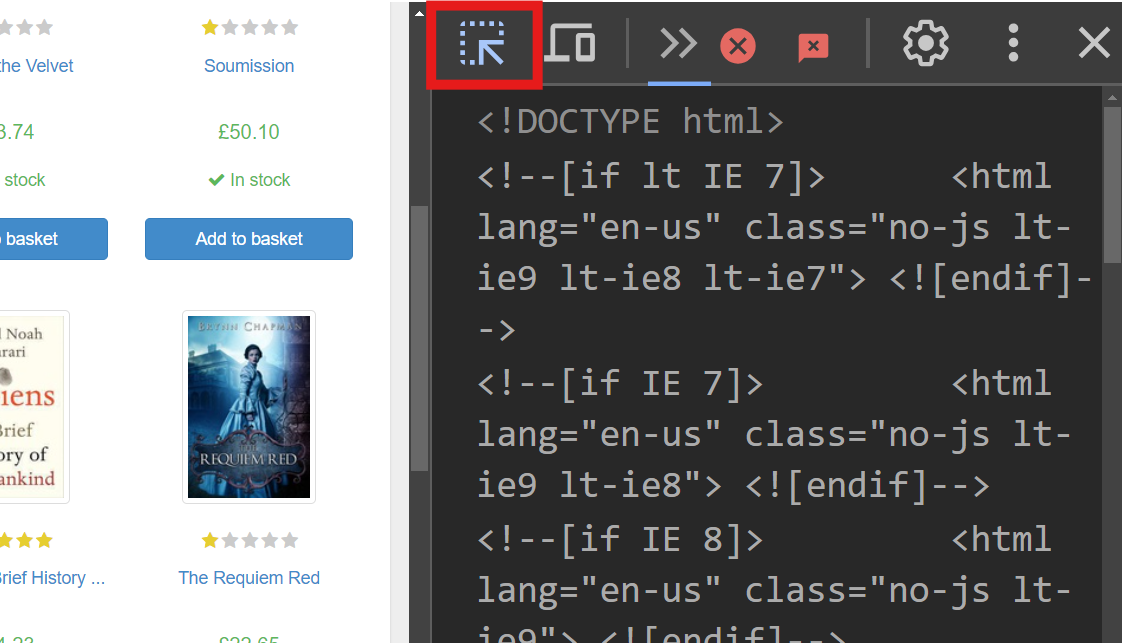
개발자 도구에서 다음과 같은 코드 조각을 확인할 수 있습니다:
<article class="product_pod">
<!-- 코드 생략 -->
<h3><a href="catalogue/a-light-in-the-attic_1000/index.html" title="A Light in the Attic">A Light in the ...</a></h3>
<div class="product_price">
<p class="price_color">£51.77</p>
<!-- 코드 생략 -->
</div>
</article>
이 스니펫에서 각 책은 product_pod 클래스로 표시된 <article> 태그 안에 포함됩니다. 데이터를 추출하기 위해 이 요소를 대상으로 합니다. static_scrape.py라는 새 파일을 생성하고 다음 코드를 입력하세요:
import requests
from lxml import html
import json
URL = "https://books.toscrape.com/"
content = requests.get(URL).text
이 코드는 필요한 라이브러리를 임포트하고 URL 변수를 정의합니다. requests.get() 을 사용하여 지정된 URL로 GET 요청을 보내 웹 페이지의 정적 HTML 콘텐츠를 가져옵니다. 그런 다음 응답의 text 속성을 사용하여 HTML 코드를 추출합니다.
HTML 콘텐츠를 획득한 후, lxml을 사용하여 이를 파싱하고 필요한 데이터를 추출하는 것이 다음 단계입니다. lxml은 추출을 위해 XPath와 CSS 선택기라는 두 가지 방법을 제공합니다. 이 예제에서는 XPath를 사용하여 책 제목을 가져오고, CSS 선택기를 사용하여 책 가격을 가져옵니다.
다음 코드를 스크립트 끝에 추가하세요:
parsed = html.fromstring(content)
all_books = parsed.xpath('//article[@class="product_pod"]')
books = []
이 코드는 html.fromstring(content)를 사용하여 parsed 변수를 초기화합니다. 이 함수는 HTML 콘텐츠를 계층적 트리 구조로 파싱합니다. all_books 변수는 XPath 선택자를 사용하여 웹 페이지에서 class=” product_pod ” 속성을 가진 모든 <article> 태그를 가져옵니다. 이 구문은 XPath 표현식에 특화된 유효한 형식입니다.
다음으로, all_books의 각 책을 순회하며 데이터를 추출하려면 스크립트에 다음을 추가하세요:
for book in all_books:
book_title = book.xpath('.//h3/a/@title')
price = book.cssselect("p.price_color")[0].text_content()
books.append({"title": book_title, "price": price})
book_title 변수는 <h3> 태그 내의 <a> 태그에서 title 속성을 가져오는 XPath 선택자를 사용하여 정의됩니다. XPath 표현식 시작 부분의 점(.)은 기본 시작점이 아닌 <article> 태그부터 검색을 시작하도록 지정합니다. 다음 줄은 cssselect 메서드를 사용하여 price_color 클래스를 가진 <p> 태그에서 가격을 추출합니다. cssselect는 리스트를 반환하므로 인덱싱([0])으로 첫 번째 요소에 접근하고, text_content() 로 요소 내부의 텍스트를 가져옵니다. 추출된 각 제목과 가격 쌍은 사전 형태로 books 리스트에 추가되며, 이는 JSON 파일에 쉽게 저장할 수 있습니다.
웹 스크래핑 과정을 완료했으니 이제 이 데이터를 로컬에 저장할 차례입니다. 스크립트 파일을 열고 다음 코드를 입력하세요:
with open("books.json", "w", encoding="utf-8") as file:
json.dump(books ,file)
이 코드에서는 books.json이라는 새 파일이 생성됩니다. 이 파일은 json.dump 메서드를 사용하여 채워지며, 이 메서드는 books 목록을 소스로, 파일 객체를 대상으로 사용합니다.
터미널을 열고 다음 명령어를 실행하여 이 스크립트를 테스트할 수 있습니다:
python static_scrape.py
이 명령어는 디렉토리에 다음과 같은 출력을 가진 새 파일을 생성합니다:
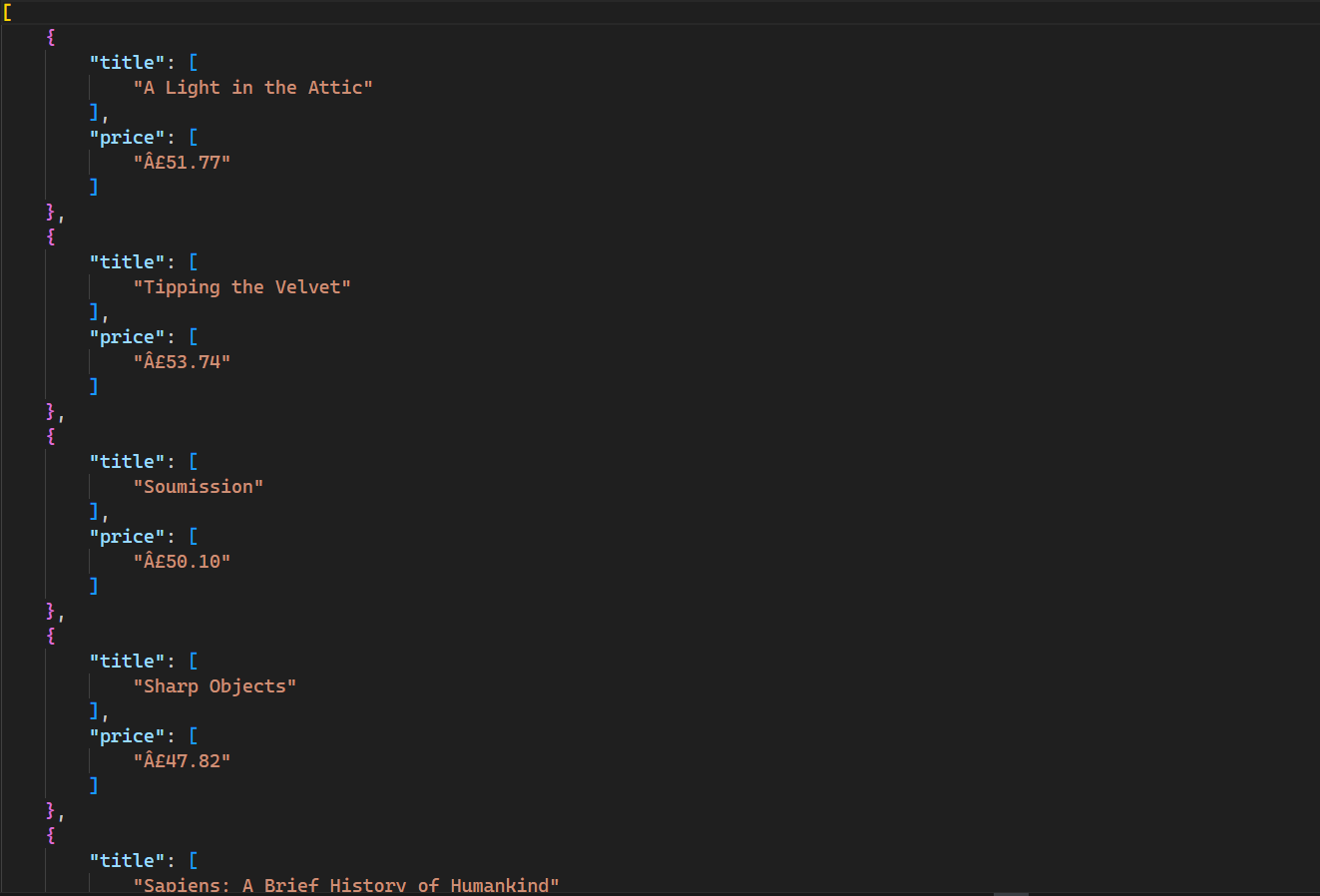
이 스크립트의 전체 코드는GitHub에서 확인할 수 있습니다.
동적 HTML 콘텐츠 파싱
동적 웹 콘텐츠 스크래핑은 정적 콘텐츠 스크래핑보다 까다롭습니다. 자바스크립트가 데이터를 한 번에 렌더링하지 않고 지속적으로 처리하기 때문입니다. 동적 콘텐츠 스크래핑을 지원하기 위해Selenium이라는 브라우저 자동화 도구를 사용합니다. 이 도구를 통해 브라우저 인스턴스를 생성 및 실행하고 프로그래밍 방식으로 제어할 수 있습니다.
Selenium을 설치하려면 터미널을 열고 다음 명령어를 실행하세요:
pip install selenium
YouTube는 자바스크립트를 사용해 렌더링되는 콘텐츠의 훌륭한 예시입니다. 채널을 방문하면 처음에는 제한된 수의 동영상만 로드되고, 아래로 스크롤할수록 더 많은 동영상이 나타납니다. 여기서는freeCodeCamp.org YouTube 채널의상위 100개 동영상 데이터를 스크롤 동작을 키보드 입력으로 에뮬레이션하여 스크래핑합니다.
시작하려면 웹 페이지의 HTML 코드를 검사하세요. 개발자 도구를 열면 다음과 같은 내용을 확인할 수 있습니다:
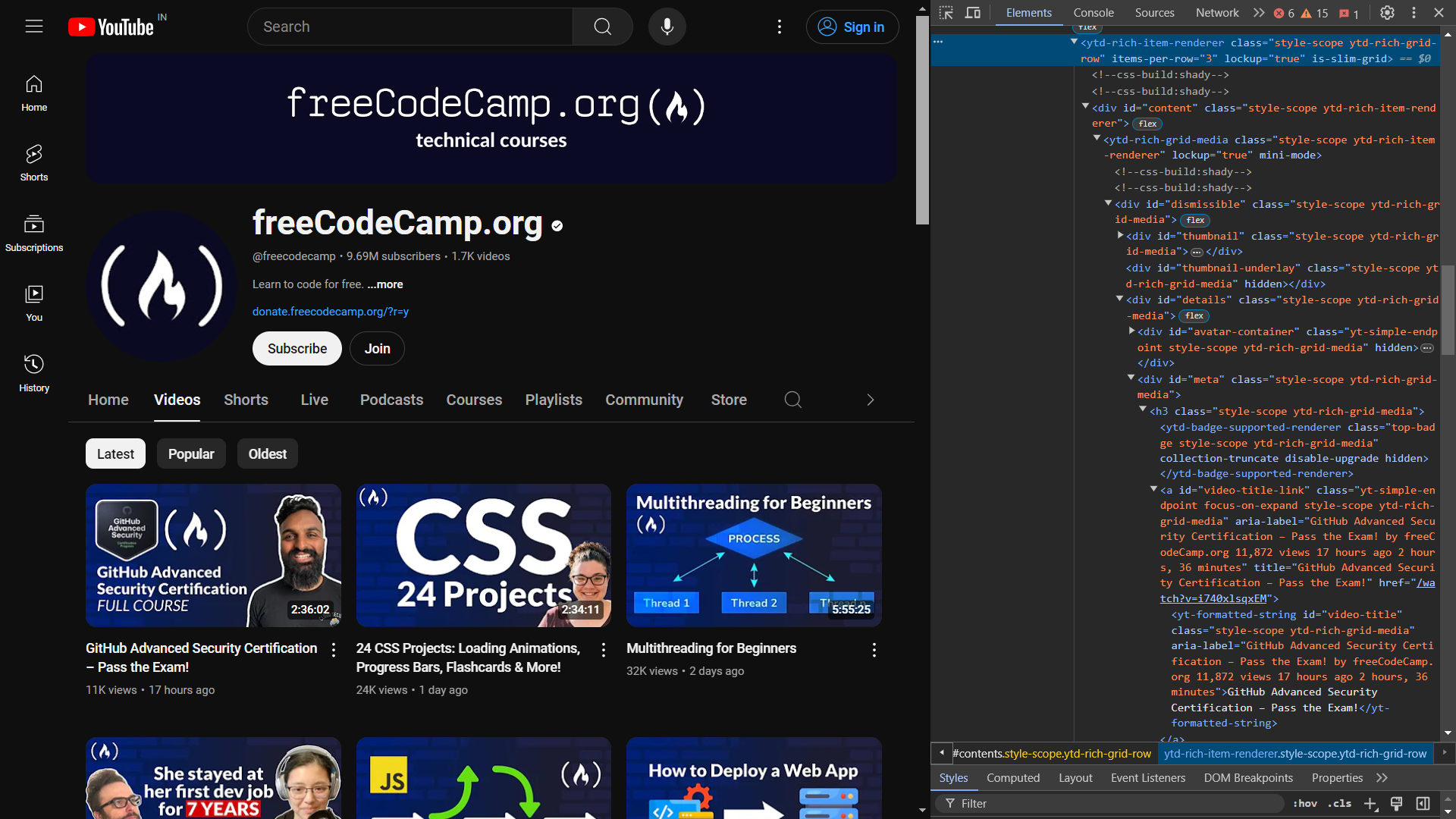
다음 코드는 동영상 제목과 링크를 표시하는 요소를 식별합니다:
<a id="video-title-link" class="yt-simple-endpoint focus-on-expand style-scope ytd-rich-grid-media" href="/watch?v=i740xlsqxEM">
<yt-formatted-string id="video-title" class="style-scope ytd-rich-grid-media">GitHub 고급 보안 인증 – 시험에 합격하세요!
</yt-formatted-string></a>
동영상 제목은 ID가 video-title인 yt-formatted-string 태그 내에 있으며, 동영상 링크는 ID가 video-title-link인 a 태그의 href 속성에 위치합니다.
스크래핑할 대상을 확인한 후, dynamic_scrape.py라는 새 파일을 생성하고 스크립트에 필요한 모든 모듈을 임포트하는 다음 코드를 추가하세요:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from lxml import html
from time import sleep
import json
여기서 먼저 selenium에서 webdriver를 임포트하여 프로그래밍 방식으로 제어할 수 있는 브라우저 인스턴스를 생성합니다. 다음 줄에서는 웹상의 요소를 선택하고 키 입력을 수행하는 By와 Keys를 임포트합니다. sleep 함수는 프로그램 실행을 일시 중지하고 페이지의 JavaScript가 콘텐츠를 렌더링할 때까지 대기하기 위해 임포트됩니다.
모든 임포트가 완료되면 선택한 브라우저의 드라이버 인스턴스를 정의할 수 있습니다. 이 튜토리얼에서는Chrome을 사용하지만, Selenium은Edge,Firefox,Safari도 지원합니다.
브라우저용 드라이버 인스턴스를 정의하려면 스크립트 끝에 다음 코드를 추가하세요:
URL = "https://www.youtube.com/@freecodecamp/videos"
videos = []
driver = webdriver.Chrome()
driver.get(URL)
sleep(3)
이전 스크립트와 유사하게, 스크래핑할 웹 URL을 포함하는 URL 변수와 모든 데이터를 리스트로 저장하는 videos 변수를 선언합니다. 다음으로 브라우저와 상호작용할 때 사용할 드라이버 변수(즉 Chrome 인스턴스)를 선언합니다. get() 함수는 브라우저 인스턴스를 열고 지정된 URL로 요청을 전송합니다. 이후 sleep 함수를 호출하여 웹 페이지의 어떤 요소에도 접근하기 전에 3초간 대기하여 브라우저에 모든 HTML 코드가 로드되도록 합니다.
앞서 언급했듯이 YouTube는 페이지 하단으로 스크롤할 때 JavaScript를 사용하여 더 많은 동영상을 로드합니다. 백 개의 동영상에서 데이터를 스크래핑하려면 브라우저를 연 후 프로그래밍 방식으로 페이지 하단까지 스크롤해야 합니다. 스크립트에 다음 코드를 추가하면 됩니다:
parent = driver.find_element(By.TAG_NAME, 'html')
for i in range(4):
parent.send_keys(Keys.END)
sleep(3)
이 코드에서 find_element 함수를 사용해 <html> 태그를 선택합니다. 이 함수는 주어진 조건(이 경우 html 태그)에 맞는 첫 번째 요소를 반환합니다. send_keys 메서드는 END 키를 눌러 페이지 하단으로 스크롤하는 동작을 시뮬레이션하여 더 많은 동영상이 로드되도록 합니다. 이 작업은 충분한 동영상이 로드되도록 for 루프 내에서 네 번 반복됩니다. sleep 함수는 각 스크롤 후 3초간 대기하여 동영상이 로드된 후 다시 스크롤할 수 있도록 합니다.
이제 스크래핑 프로세스를 시작하는 데 필요한 모든 데이터를 확보했으므로, lxml과 cssselect를 사용하여 추출할 요소를 선택할 차례입니다:
html_data = html.fromstring(driver.page_source)
videos_html = html_data.cssselect("a#video-title-link")
for video in videos_html:
title = video.text_content()
link = "https://www.youtube.com" + video.get("href")
videos.append( {"title": title, "link": link} )
이 코드에서는 드라이버의 page_source 속성에서 가져온 HTML 콘텐츠를 fromstring 메서드에 전달하여 HTML의 계층적 트리를 생성합니다. 그런 다음 CSS 선택자를 사용하여 ID가 video-title-link인 모든 <a> 태그를 선택합니다. 여기서 # 기호는 태그의 ID를 사용하여 선택함을 나타냅니다. 이 선택은 주어진 기준을 충족하는 요소들의 목록을 반환합니다. 그런 다음 코드는 각 요소를 반복하여 제목과 링크를 추출합니다. text_content 메서드는 내부 텍스트(동영상 제목)를 추출하고, get 메서드는 href 속성 값(동영상 링크)을 가져옵니다. 마지막으로 데이터는 videos라는 리스트에 저장됩니다.
여기까지 스크래핑 과정이 완료되었습니다. 다음 단계는 이렇게 추출한 데이터를 시스템에 로컬로 저장하는 것입니다. 데이터를 저장하려면 스크립트에 다음 코드를 추가하세요:
with open('videos.json', 'w') as file:
json.dump(videos, file)
driver.close()
여기서 videos.json 파일을 생성하고 json.dump 메서드를 사용하여 videos 리스트를 JSON 형식으로 직렬화한 후 파일 객체에 기록합니다. 마지막으로 드라이버 객체의 close 메서드를 호출하여 브라우저 인스턴스를 안전하게 닫고 해제합니다.
이제 터미널을 열고 다음 명령어를 실행하여 스크립트를 테스트할 수 있습니다:
python dynamic_scrape.py
스크립트 실행 후 디렉토리에 videos.json이라는 새 파일이 생성됩니다:
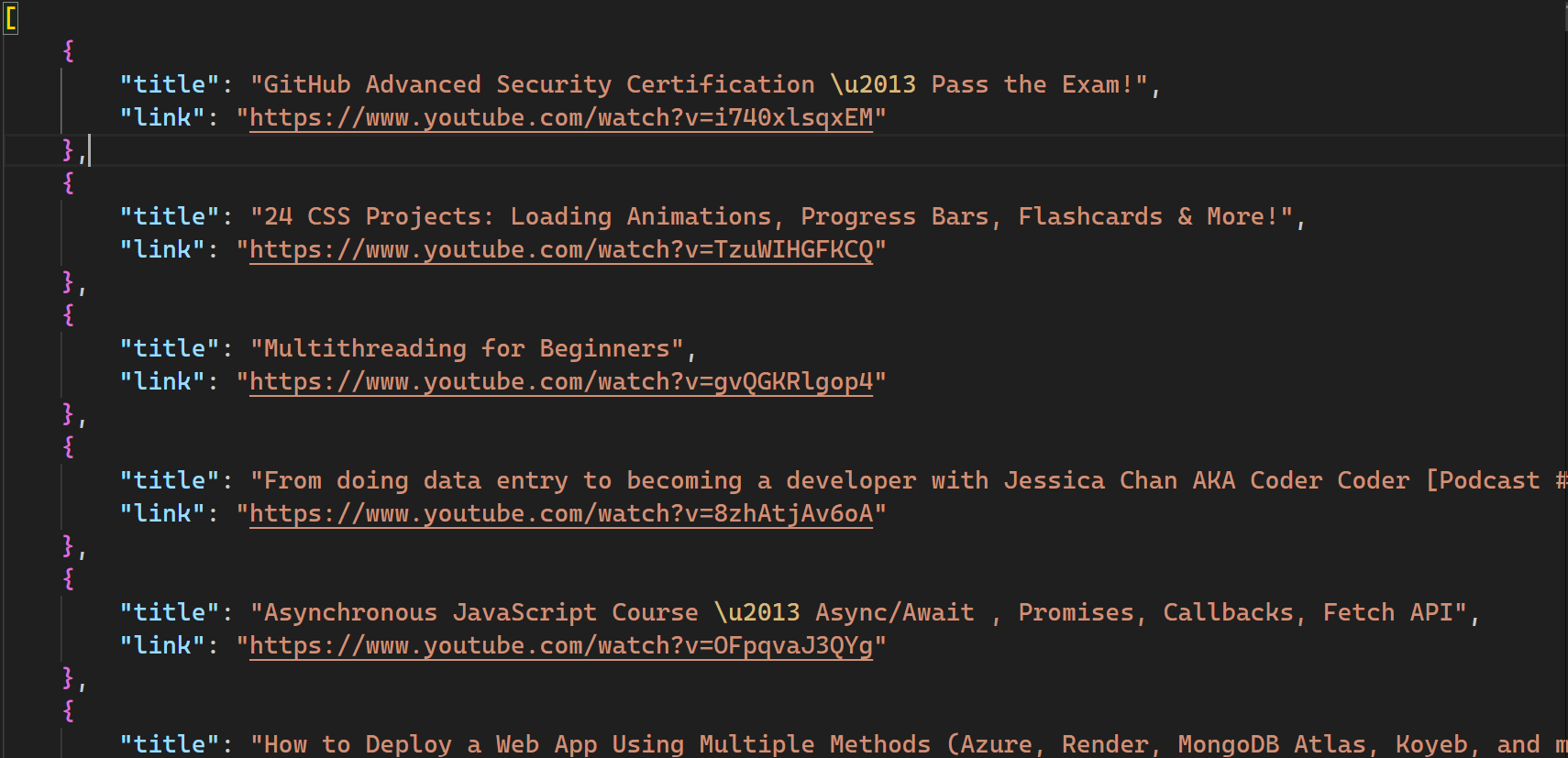
이 스크립트의 전체 코드는GitHub에서도 확인할 수 있습니다.
Bright Data 프록시와 함께 lxml 사용하기
웹 스크래핑은 다양한 소스에서 데이터 수집을 자동화하는 훌륭한 기술이지만, 이 과정에는 어려움이 따릅니다. 웹사이트에서 구현한 스크래핑 방지 도구, 속도 제한, 지역 차단, 익명성 부족 등의 문제를 해결해야 합니다.프록시 서버는사용자의 IP 주소를 숨기는 중개자 역할을 하여 스크래퍼가 제한을 우회하고 탐지되지 않은 상태로 대상 데이터에 접근할 수 있도록 도와줍니다. Bright Data는 신뢰할 수 있는 프록시 서비스의 최상위 선택지입니다.
다음 예시는 Bright Data 프록시 사용이 얼마나 쉬운지 보여줍니다. Books to Scrape 웹사이트를 스크래핑하기 위해 script_scrape.py 파일의 일부 변경을 포함합니다.
시작하려면 무료 체험판에 가입하여 Bright Data에서 프록시를 획득해야 합니다. 무료 체험판은 5달러 상당의 프록시 리소스를 제공합니다. Bright Data 계정을 생성하면 다음과 같은 대시보드가 표시됩니다:
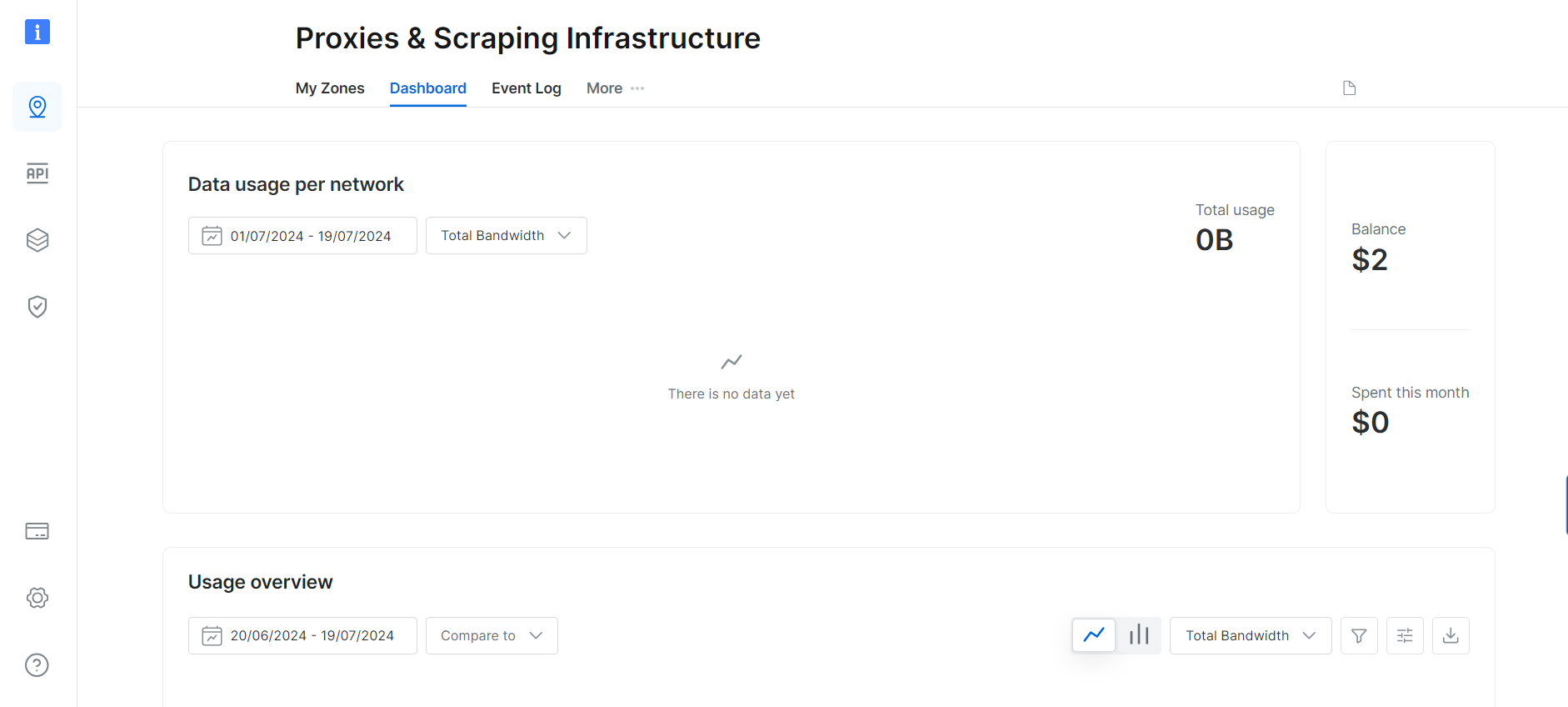
‘My Zones’옵션으로 이동하여 새로운주거용 프록시영역을 생성하세요. 새 영역 생성 시 다음 단계에서 필요한 프록시 사용자 이름, 비밀번호, 호스트가 표시됩니다.
static_scrape.py 파일을 열고 URL 변수 아래에 다음 코드를 추가하세요:
URL = "https://books.toscrape.com/"
# new
username = ""
password = ""
hostname = ""
proxies = {
"http": f"https://{username}:{password}@{hostname}",
"https": f"https://{username}:{password}@{hostname}",
}
content = requests.get(URL, proxies=proxies).text
사용자 이름, 비밀번호, 호스트명 자리 표시자를 프록시 자격 증명 정보로 대체하세요. 이 코드는 requests 라이브러리가 지정된 프록시를 사용하도록 지시합니다. 나머지 스크립트는 변경하지 마세요.
다음 명령어를 실행하여 스크립트를 테스트하세요:
python static_scrape.py
이 스크립트를 실행하면 이전 예제에서 받은 것과 유사한 출력이 표시됩니다.
전체 스크립트는GitHub에서 확인할 수 있습니다.
결론
lxml은 HTML 문서에서 데이터를 추출하기 위한 강력하고 사용하기 쉬운 도구입니다. lxml은 속도에 최적화되어 있으며 XPath 및 CSS 선택자를 지원하여 대규모 XML 및 HTML 문서를 효율적으로 파싱할 수 있습니다.
이 튜토리얼에서는 lxml을 사용한 웹 스크래핑과 동적 및 정적 콘텐츠 스크래핑에 대해 모두 배웠습니다. 또한Bright Data프록시 서버를 사용하여 웹사이트가 스크래퍼에 부과하는 제한을 우회하는 방법도 배웠습니다.
Bright Data는 모든 웹 스크래핑 프로젝트를 위한 원스톱 솔루션입니다. 프록시, 스크래핑 브라우저, reCAPTCHA와 같은 기능을 제공하여 사용자가 웹 스크래핑 문제를 효과적으로 해결할 수 있도록 합니다. Bright Data는 또한 웹 스크래핑 관련 튜토리얼과 모범 사례가 담긴심층적인 블로그를제공합니다.
시작해 보시겠습니까? 지금 가입하고 제품을 무료로 체험해 보세요!





