
웹 스크래핑은 대규모 데이터 수집에서 중요한 역할을 하며, 특히 신속하고 정보에 기반한 의사 결정이 필수적인 경우에 더욱 그렇습니다.
이 튜토리얼에서는 다음을 배웁니다:
- Midscene.js의 정의와 작동 방식,
- Midscene.js 사용의 한계점,
- Bright Data가 이러한 문제를 해결하는 방법
- 효과적인 웹 스크래핑을 위해 Midscene.js를 Bright Data와 통합하는 방법
자, 시작해 보겠습니다!
Midscene.js란 무엇인가요?
Midscene.js는 평이한 영어로 브라우저 상호작용을 자동화할 수 있는 오픈소스 도구입니다. 복잡한 스크립트를 작성하는 대신 “로그인 버튼 클릭”이나 “이메일 필드에 입력”과 같은 명령어를 입력하기만 하면 됩니다. Midscene은 AI 에이전트를 활용해 이러한 지시사항을 자동화 단계로 변환합니다.
또한 Puppeteer 및 Playwright와 같은 최신 브라우저 자동화 도구를 지원하므로 테스트, UI 자동화, 동적 웹사이트 스크래핑과 같은 작업에 특히 유용합니다.
주요 기능은 다음과 같습니다:
- 자연어 제어: 코드 대신 명확한 영어 기반 프롬프트로 작업을 자동화합니다.
- MCP 서버와의 AI 통합: MCP 서버를 통해 AI 모델에 연결하여 자동화 스크립트 생성을 지원합니다.
- 내장된 Puppeteer 및 Playwright 지원: 인기 프레임워크 위에 고수준 레이어로 작동하여 워크플로우를 쉽게 관리하고 확장할 수 있게 합니다.
- 크로스 플랫폼 자동화: 웹(Puppeteer/Playwright를 통해)과 Android(JavaScript SDK를 통해) 모두 지원합니다.
- 노코드 경험: Midscene Chrome 확장 프로그램과 같은 도구를 제공하여 코드 한 줄 작성 없이도 자동화를 구축할 수 있습니다.
- 간결한 API 설계: 페이지 요소와 상호작용하고 콘텐츠를 효율적으로 추출할 수 있도록 깔끔하고 잘 문서화된 API를 제공합니다.
웹 브라우저 자동화에 Midscene 사용 시 제한 사항
Midscene은 GPT-4o 또는 Qwen과 같은 AI 모델을 사용하여 자연어 명령으로 브라우저를 자동화합니다. Puppeteer 및 Playwright와 같은 도구와 함께 작동하지만 주요 제한 사항이 있습니다.
Midscene의 정확도는 사용자의 지시문 명확성과 페이지 기본 구조에 좌우됩니다. “버튼 클릭”과 같은 모호한 프롬프트는 유사한 버튼이 여러 개 있을 경우 실패할 수 있습니다. AI는 스크린샷과 시각적 레이아웃에 의존하므로, 작은 구조 변경이나 레이블 누락으로 오류나 오클릭이 발생할 수 있습니다. 한 웹페이지에서 작동하는 프롬프트가 유사한 외관의 다른 페이지에서는 작동하지 않을 수 있습니다.
오류를 최소화하려면 페이지 구조에 부합하는 명확하고 구체적인 지시문을 작성하세요. 자동화 스크립트에 통합하기 전에 항상 Midscene Chrome 확장 프로그램으로 프롬프트를 테스트하십시오.
또 다른 주요 한계는 높은 리소스 소모입니다. Midscene의 각 자동화 단계는 스크린샷과 프롬프트를 AI 모델로 전송하며, 특히 동적 또는 데이터가 많은 페이지에서 많은 토큰을 사용합니다. 이는 AI API의 속도 제한과 자동화 단계 증가에 따른 사용 비용 상승으로 이어질 수 있습니다.
또한 Midscene은 CAPTCHA, 크로스 오리진 iframe, 인증 벽 뒤의 콘텐츠 등 보호된 브라우저 요소와 상호작용할 수 없습니다. 결과적으로 보안 또는 게이트된 콘텐츠를 스크래핑하는 것은 불가능합니다. Midscene은 접근 가능하고 구조화된 콘텐츠를 가진 정적 또는 중간 수준의 동적 사이트에서 가장 효과적입니다.
Bright Data가 더 효과적인 솔루션인 이유
Bright Data는 웹 스크래핑 작업을 구축, 실행, 확장할 수 있도록 지원하는 강력한 데이터 수집 플랫폼입니다. 기업과 개발자를 위한 강력한 프록시 인프라, 자동화 도구, 데이터 세트를 제공하여 모든 공개 웹사이트에 접근하고, 데이터를 추출하며, 상호작용할 수 있게 합니다.
- 동적 및 자바스크립트 중심 웹사이트 처리 Bright Data는 SERP API, 크롤링 API, 브라우저 API, 언락커 API 등 다양한 도구를 제공하여 동적으로 콘텐츠를 로드하는 복잡한 웹사이트에 접근하고 데이터를 추출하며 상호작용할 수 있게 합니다. 이러한 도구들은 모든 플랫폼에서 데이터를 가져올 수 있도록 하여 전자상거래, 여행, 부동산 플랫폼에 이상적입니다.
- 효율적인 프록시 인프라 Bright Data는 주거용, 데이터센터, ISP, 모바일 네 가지 주요 네트워크를 통해 강력하고 유연한 프록시 인프라를 제공합니다. 이 네트워크들은 전 세계 수백만 개의 IP 주소에 대한 접근을 제공하여 사용자가 차단 위험을 최소화하면서 안정적으로 웹 데이터를 수집할 수 있게 합니다.
- 멀티미디어 콘텐츠 지원 Bright Data는 공개된 출처에서 동영상, 이미지, 오디오, 텍스트 등 다양한 콘텐츠 유형을 추출할 수 있도록 합니다. 대규모 미디어 수집을 처리하고 컴퓨터 비전 모델 훈련, 음성 인식 도구 구축, 자연어 처리 시스템 구동과 같은 고급 사용 사례를 지원하도록 설계된 인프라를 갖추고 있습니다.
- 즉시 사용 가능한데이터셋 제공 Bright Data는 완전히 구조화되고 고품질이며 즉시 사용 가능한 데이터셋을 제공합니다. 이 데이터셋은 전자상거래, 채용 공고, 부동산, 소셜 미디어 등 다양한 분야를 아우르므로 다양한 산업과 사용 사례에 적합합니다.
Midscene. js와 Bright Data 통합 방법
이 튜토리얼 섹션에서는 Midscene과 Bright Data의 브라우저 API를 사용하여 웹사이트에서 데이터를 스크래핑하는 방법과 두 도구를 결합하여 더 나은 웹 스크래핑 기능을 구현하는 방법을 배웁니다.
이를 시연하기 위해 직원 연락처 카드 목록을 표시하는 정적 웹페이지를 스크래핑할 것입니다. 먼저 Midscene과 Bright Data를 개별적으로 사용한 후, Puppeteer를 활용해 두 도구를 통합하여 함께 작동하는 방식을 보여드리겠습니다.
필수 조건
이 튜토리얼을 따라하려면 다음이 준비되어 있어야 합니다:
- Bright Data 계정
- Visual Studio Code, Cursor 등과 같은 코드 에디터
- GPT-4o 모델을 지원하는 OpenAI API 키.
- JavaScript 프로그래밍 언어에 대한 기본적인 이해.
아직 Bright Data 계정이 없더라도 걱정하지 마세요. 아래 단계에서 계정 생성 방법을 안내해 드리겠습니다.
1단계: 프로젝트 설정
터미널을 열고 자동화 스크립트용 새 폴더를 생성하려면 다음 명령어를 실행하세요:
mkdir automation-scripts
cd automation-scripts
다음 코드 스니펫을 사용하여 새로 생성된 폴더에 package.json 파일을 추가하세요:
npm init -y
package.json의 type 값을 commonjs 에서 module로 변경합니다 .
{
"type": "module"
}
다음으로, TypeScript 실행을 활성화하고 Midscene.js 기능을 사용하기 위해 필요한 패키지를 설치합니다:
npm install tsx @midscene/web --save
다음으로, Puppeteer 및 Dotenv 패키지를 설치합니다.
npm install puppeteer dotenv
Puppeteer는 Chrome 또는 Chromium 브라우저를 제어하기 위한 고수준 API를 제공하는 Node.js 라이브러리입니다. Dotenv는 API 키를 안전하게 저장할 수 있게 해줍니다.
이제 필요한 모든 패키지가 설치되었습니다. 자동화 스크립트 작성을 시작할 수 있습니다.
2단계: Midscene.js로 웹 스크래핑 자동화하기
진행하기 전에 automation-scripts 폴더 안에 .env 파일을 생성하고 OpenAI API 키를 환경 변수로 해당 파일에 복사하세요.
OPENAI_API_KEY=<your_openai_key>
Midscene은 OpenAI GPT-4o 모델을 사용하여 사용자의 명령에 기반한 자동화 작업을 수행합니다.
다음으로 폴더 내에 파일을 생성합니다.
cd automation-scripts
touch midscene.ts
파일에 Puppeteer, Midscene Puppeteer Agent 및 dotenv 구성을 임포트하세요:
import puppeteer from "puppeteer";
import { PuppeteerAgent } from "@midscene/web/puppeteer";
import "dotenv/config";
midscene.ts 파일에 다음 코드 조각을 추가하세요:
const sleep = (ms: number) => new Promise((r) => setTimeout(r, ms));
Promise.resolve(
(async () => {
//👇🏻 puppeteer 초기화
const browser = await puppeteer.launch({
headless: false,
});
//👇🏻 페이지 설정
const page = await browser.newPage();
await page.setViewport({
width: 1280,
height: 800,
deviceScaleFactor: 1,
});
/*
----------
👉🏻 자동화 스크립트를 여기에 작성하세요 👈🏼
-----------
*/
})()
);
이 코드 스니펫은 비동기 즉시 호출 함수 표현식(IIFE) 내에서 Puppeteer를 초기화합니다. 이 구조를 사용하면 논리를 여러 함수 호출로 감싸지 않고도 최상위 수준에서 await를 사용할 수 있습니다.
다음으로 IIFE 내에 다음 코드 조각을 추가하세요:
//👇🏻 웹 페이지로 이동
await page.goto(
"<https://lf3-static.bytednsdoc.com/obj/eden-cn/nupipfups/Midscene/contacts3.html>"
);
// 👇🏻 Midscene 에이전트 초기화
const agent = new PuppeteerAgent(page as any);
//👇🏻 AI 모델에 쿼리 전달
const items = await agent.aiQuery(
"화면의 모든 연락처 세부정보 가져오기"
);
//👇🏻 5초 대기
await sleep(5000);
// 👀 결과 출력
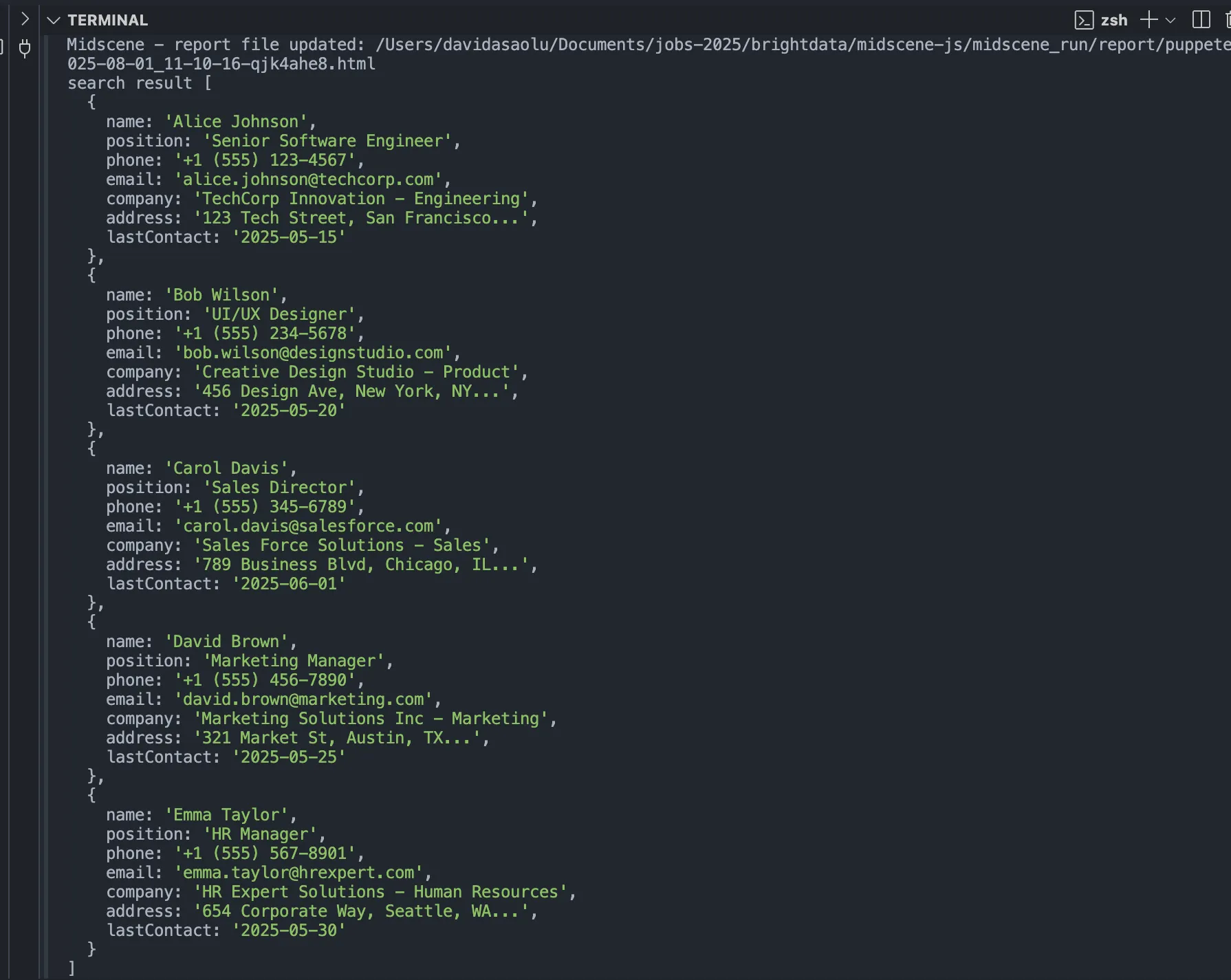
console.log("검색 결과", items);
위의 코드 스니펫은 웹페이지 주소로 이동하여, Puppeteer 에이전트를 초기화하고, 웹페이지에서 모든 연락처 정보를 가져온 후 결과를 기록합니다.
3단계: Bright Data 브라우저 API로 웹 스크래핑 자동화
automation-scripts 폴더 내에 brightdata.ts 파일을 생성합니다.
cd automation-scripts
touch brightdata.ts
Bright Data 홈페이지로 이동하여 계정을 생성합니다.
대시보드에서 Browser API를 선택한 후, 새 브라우저 API를 생성하기 위해 영역 이름과 설명을 입력하세요.
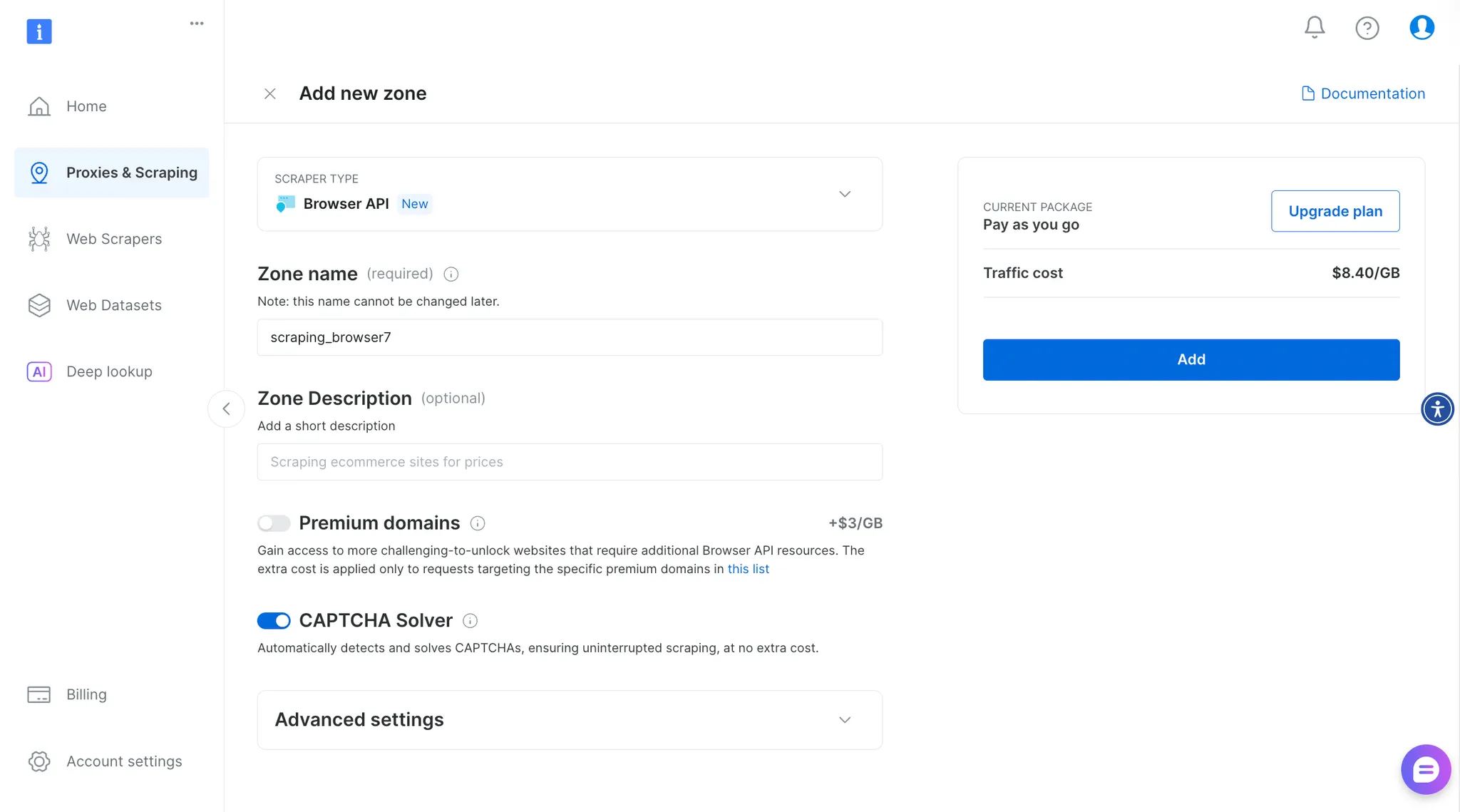
다음으로, Puppeteer 자격 증명을 복사하여 아래와 같이 brightdata.ts 파일에 저장하세요:
const BROWSER_WS = "wss://brd-customer-******";
brightdata.ts 파일을 아래와 같이 수정하세요:
import puppeteer from "puppeteer";
const URL =
"<https://lf3-static.bytednsdoc.com/obj/eden-cn/nupipfups/Midscene/contacts3.html>";
const BROWSER_WS = "wss://brd-customer-******";
run(URL);
async function run(url: string) {
try {
/*
---------------------------
👉🏻 웹 자동화 워크플로 👈🏼
---------------------------
*/
//👇🏻 브라우저 닫기
await browser.close();
} catch (err) {
console.error("데이터 가져오기 오류");
}
}
이 코드 스니펫은 웹페이지 URL과 Bright Data의 브라우저 API 자격 증명을 위한 변수를 선언한 후, URL을 매개변수로 받는 함수를 선언합니다.
웹 자동화 워크플로 자리 표시자 내에 다음 코드 스니펫을 추가하세요:
//👇🏻 Bright Data 브라우저 API에 연결
console.log("브라우저 연결 중...");
const browser = await puppeteer.connect({
browserWSEndpoint: BROWSER_WS,
});
console.log("연결 완료! 사이트로 이동 중...");
const page = await browser.newPage();
//👇🏻 웹페이지 이동
await page.goto(url, { waitUntil: "domcontentloaded", timeout: 60000 });
console.log("이동 완료! 팝업 대기 중...");
아래 코드 스니펫은 API 웹소켓 엔드포인트를 사용하여 Puppeteer를 Bright Data 브라우저에 연결합니다. 연결이 설정되면 새 브라우저 페이지를 열고 run() 함수에 전달된 URL로 이동합니다.
마지막으로, 다음 코드 스니펫을 사용하여 CSS 선택자로 웹페이지의 데이터를 가져옵니다:
//👇🏻 CSS 속성을 사용해 연락처 정보 가져오기
const contacts = await page.evaluate(() => {
const cards = document.querySelectorAll("#contactsGrid .contact-card");
return Array.from(cards).map((card) => {
const nameEl = card.querySelector(".contact-name");
const detailsEl = card.querySelectorAll(
".contact-details .detail-item span:not(.detail-icon)"
);
const metaEl = card.querySelector(".contact-meta");
if (!nameEl || !detailsEl.length || !metaEl) {
return null; // 필수 요소가 하나라도 누락된 경우 건너뛰기
}
const contact = {
name:
(nameEl as HTMLElement)?.dataset.name ||
(nameEl as HTMLElement)?.innerText.trim() ||
null,
jobTitle: (metaEl as HTMLElement)?.innerText.trim() || null,
phone: (detailsEl[0] as HTMLElement)?.innerText.trim() || null,
email: (detailsEl[1] as HTMLElement)?.innerText.trim() || null,
회사: (detailsEl[2] as HTMLElement)?.innerText.trim() || null,
주소: (detailsEl[3] as HTMLElement)?.innerText.trim() || null,
마지막연락: (detailsEl[4] as HTMLElement)?.innerText.trim() || null,
};
return contact;
});
});
console.log("연락처 그리드 발견! 데이터 추출 중...", contacts);
위의 코드 조각은 웹페이지의 각 연락처 카드를 순회하며 이름, 직책, 전화번호, 이메일 주소, 회사, 주소, 마지막 연락일 등의 주요 세부 정보를 추출합니다.
다음은 전체 자동화 스크립트입니다:
import puppeteer from "puppeteer";
const URL =
"<https://lf3-static.bytednsdoc.com/obj/eden-cn/nupipfups/Midscene/contacts3.html>";
const BROWSER_WS ="wss://brd-customer-*******";
run(URL);
async function run(url: string) {
try {
//👇🏻 Bright Data 브라우저 API 연결
console.log("브라우저 연결 중...");
const browser = await puppeteer.connect({
browserWSEndpoint: BROWSER_WS,
});
console.log("연결 완료! 사이트로 이동 중...");
const page = await browser.newPage();
//👇🏻 웹페이지로 이동
await page.goto(url, { waitUntil: "domcontentloaded", timeout: 60000 });
console.log("이동 완료! 팝업 대기 중...");
//👇🏻 CSS 속성으로 연락처 정보 가져오기
const contacts = await page.evaluate(() => {
const cards = document.querySelectorAll("#contactsGrid .contact-card");
return Array.from(cards).map((card) => {
const nameEl = card.querySelector(".contact-name");
const detailsEl = card.querySelectorAll(
".contact-details .detail-item span:not(.detail-icon)"
);
const metaEl = card.querySelector(".contact-meta");
if (!nameEl || !detailsEl.length || !metaEl) {
return null; // 필수 요소 중 하나라도 누락된 경우 건너뜀
}
const contact = {
name: (nameEl as HTMLElement)?.dataset.name || (nameEl as HTMLElement)?.innerText.trim() || null,
jobTitle: (metaEl as HTMLElement)?.innerText.trim() || null,
phone: (detailsEl[0] as HTMLElement)?.innerText.trim() || null,
email: (detailsEl[1] as HTMLElement)?.innerText.trim() || null,
company: (detailsEl[2] as HTMLElement)?.innerText.trim() || null,
address: (detailsEl[3] as HTMLElement)?.innerText.trim() || null,
lastContact: (detailsEl[4] as HTMLElement)?.innerText.trim() || null,
};
return contact;
});
});
console.log("연락처 그리드 발견! 데이터 추출 중...", contacts);
//👇🏻 브라우저 닫기
await browser.close();
} catch (err) {
console.error("데이터 가져오기 중 오류 발생");
}
}
4단계: Midscene과 Bright Data를 활용한 AI 자동화 스크립트
Bright Data는 Midscene과의 연동을 통해 AI 에이전트를 활용한 웹 자동화를 지원합니다. 두 도구 모두 Puppeteer를 지원하므로, 이를 결합하면 간단한 AI 기반 자동화 워크플로를 작성할 수 있습니다. combine.ts 파일을 생성하고 다음 코드 스니펫을 해당 파일에 복사하세요:
import { PuppeteerAgent } from "@midscene/web/puppeteer";
import puppeteer from "puppeteer";
import "dotenv/config";
const URL =
"<https://lf3-static.bytednsdoc.com/obj/eden-cn/nupipfups/Midscene/contacts3.html>";
const BROWSER_WS = "wss://brd-customer-******";
const sleep = (ms: number) => new Promise((r) => setTimeout(r, ms));
Promise.resolve(
(async () => {
/*
---------------------------
👉🏻 웹 자동화 워크플로우 👈🏼
---------------------------
*/
//👇🏻 브라우저 닫기
await browser.close();
})()
);
위 코드 스니펫은 비동기 IIFE(즉시 호출 함수 표현식)를 생성하며, AI 자동화 스크립트 내에서 지연을 추가할 수 있는 sleep 함수를 포함합니다.
다음으로, 웹 자동화 워크플로 자리 표시자에 다음 코드 스니펫을 추가하세요:
//👇🏻 Bright Data 브라우저 API 연결
console.log("브라우저 연결 중...");
const browser = await puppeteer.connect({
browserWSEndpoint: BROWSER_WS,
});
//👇🏻 페이지 선언
console.log("연결 완료! 사이트로 이동...");
const page = await browser.newPage();
//👇🏻 웹사이트로 이동
await page.goto(URL, { waitUntil: "domcontentloaded", timeout: 60000 });
// 👀 Midscene 에이전트 초기화
const agent = new PuppeteerAgent(page as any);
// 👇🏻 AI 에이전트로 연락처 정보 수집
const items = await agent.aiQuery(
"화면의 모든 연락처 정보 가져오기"
);
//👇🏻 5초 대기
await sleep(5000);
//👇🏻 결과 출력
console.log("검색 결과", items);
이 코드 스니펫은 Puppeteer와 에이전트를 초기화하여 웹페이지로 이동하고, 모든 연락처 정보를 가져온 후 결과를 콘솔에 기록합니다. 이는 Midscene이 제공하는 명확한 명령어를 활용하기 위해 Puppeteer AI 에이전트를 Bright Data Browser API와 통합하는 방법을 보여줍니다.
단계 #5: 모든 것 통합하기
이전 섹션에서는 Midscene과 Bright Data Browser API를 통합하는 방법을 배웠습니다. 완성된 자동화 스크립트는 다음과 같습니다:
import { PuppeteerAgent } from "@midscene/web/puppeteer";
import puppeteer from "puppeteer";
import "dotenv/config";
const URL =
"<https://lf3-static.bytednsdoc.com/obj/eden-cn/nupipfups/Midscene/contacts3.html>";
const BROWSER_WS = "wss://brd-customer-*****";
const sleep = (ms: number) => new Promise((r) => setTimeout(r, ms));
Promise.resolve(
(async () => {
//👇🏻 Bright Data 브라우저 API에 연결
console.log("브라우저 연결 중...");
const browser = await puppeteer.connect({
browserWSEndpoint: BROWSER_WS,
});
console.log("연결 완료! 사이트로 이동 중...");
const page = await browser.newPage();
//👇🏻 Booking.com으로 이동
await page.goto(URL, { waitUntil: "domcontentloaded", timeout: 60000 });
// 👀 Midscene 에이전트 초기화
const agent = new PuppeteerAgent(page as any);
const items = await agent.aiQuery(
"화면의 모든 연락처 정보 가져오기"
);
await sleep(5000);
console.log("검색 결과", items);
await browser.close();
})()
);
터미널에서 다음 코드 스니펫을 실행하여 스크립트를 실행하세요:
npx tsx combine.ts
위 코드 스니펫은 자동화 스크립트를 실행하고 연락처 세부 정보를 콘솔에 기록합니다.
[
{
name: 'Alice Johnson',
jobTitle: '수석 소프트웨어 엔지니어',
phone: '+1 (555) 123-4567',
email: '[email protected]',
company: 'TechCorp Innovation - 엔지니어링',
address: '123 Tech Street, San Francisco...',
lastContact: '마지막 연락: 2026-05-15'
},
{
name: 'Bob Wilson',
jobTitle: 'UI/UX 디자이너',
phone: '+1 (555) 234-5678',
email: '[email protected]',
company: 'Creative Design Studio - 제품',
address: '456 Design Ave, New York, NY...',
lastContact: '마지막 연락일: 2026-05-20'
},
{
name: 'Carol Davis',
jobTitle: '영업 이사',
phone: '+1 (555) 345-6789',
email: '[email protected]',
company: '세일즈 포스 솔루션 - 영업',
address: '789 비즈니스 대로, 시카고, IL...',
lastContact: '마지막 연락: 2026-06-01'
},
{
name: '데이비드 브라운',
jobTitle: '마케팅 매니저',
phone: '+1 (555) 456-7890',
email: '[email protected]',
company: '마케팅 솔루션스 - 마케팅',
address: '321 마켓 스트리트, 오스틴, 텍사스...',
lastContact: '마지막 연락일: 2026-05-25'
},
{
name: '엠마 테일러',
jobTitle: '인사 관리자',
phone: '+1 (555) 567-8901',
email: '[email protected]',
company: 'HR Expert Solutions - Human Resources',
address: '654 Corporate Way, Seattle, WA...',
lastContact: '마지막 연락일: 2026-05-30'
}
]
단계 #6: 다음 단계
이 튜토리얼은 Midscene과 Bright Data Browser API를 통합할 때 가능한 작업을 보여줍니다. 이 기반을 바탕으로 더 복잡한 워크플로를 자동화할 수 있습니다.
두 도구를 결합하면 다음과 같은 효율적이고 확장 가능한 브라우저 자동화 작업을 수행할 수 있습니다:
- 동적 또는 자바스크립트 중심 웹사이트에서 구조화된 데이터 스크래핑
- 테스트 또는 데이터 수집을 위한 양식 제출 자동화
- 자연어 명령을 사용한 웹사이트 탐색 및 요소 상호작용
- 프록시 관리 및 CAPTCHA 처리 기능을 활용한 대규모 데이터 추출 작업 실행
결론
지금까지 Midscene과 Bright Data Browser API를 사용하여 웹 스크래핑 프로세스를 자동화하는 방법과 두 도구를 함께 활용해 AI 에이전트를 통한 웹사이트 스크래핑 방법을 배웠습니다.
Midscene은 브라우저 자동화를 위해 AI 모델에 크게 의존하며, Bright Data Scraping Browser와 함께 사용하면 효과적인 웹 스크래핑 기능으로 코드 줄을 줄일 수 있습니다. Browser API는 Bright Data의 도구와 서비스가 어떻게 고급 AI 기반 자동화를 가능하게 하는지 보여주는 한 가지 예에 불과합니다.
지금 가입하여 모든 제품을 살펴보세요.





