

이 글에서 배울 내용:
- HTTP의 정의와 제공하는 기능
- 가이드 섹션에서 웹 스크래핑을 위한 HTTPX 사용법
- 웹 스크래핑을 위한 고급 HTTPX 기능
- 자동화된 요청을 위한 HTTPX와 Requests 비교
자, 시작해 보겠습니다!
HTTPX란 무엇인가?
HTTPX는retryablehttp라이브러리를 기반으로 구축된 Python 3용 완전한 기능의 HTTP 클라이언트입니다. 다수의 스레드에서도 안정적인 결과를 보장하도록 설계되었습니다. HTTPX는 HTTP/1.1 및 HTTP/2 프로토콜을 지원하며 동기식 및 비동기식 API를 모두 제공합니다.
⚙️ 주요 기능
- 간결하고 모듈화된 코드베이스로 기여가 용이합니다.
- 여러 요소를 프로빙하기 위한 빠르고 완전히 구성 가능한 플래그.
- 다양한 HTTP 기반 프로빙 방법 지원.
- 기본적으로 HTTPS에서 HTTP로의 스마트 자동 대체 기능.
- 호스트, URL, CIDR을 입력으로 허용합니다.
- 프록시, 사용자 정의 HTTP 헤더, 사용자 정의 타임아웃, 기본 인증 등을 지원합니다.
👍 장점
httpx[cli]를 사용하여 명령줄에서 사용 가능.- HTTP/2 지원 및 비동기 API를 포함한 다양한 기능이 탑재되어 있습니다.
- 이 프로젝트는 활발하게 개발 중입니다…
👎 단점
- …새로운 릴리스마다 호환성 문제를 일으킬 수 있는 변경 사항이 자주 포함된 업데이트가 이루어집니다.
requests라이브러리보다 인기가 낮습니다.
HTTPX를 사용한 스크래핑: 단계별 가이드
HTTPX는 HTTP 클라이언트로, 페이지의 원시 HTML 콘텐츠를 가져오는 데 도움이 됩니다. 그런 다음 HTML에서 데이터를 파싱하고 추출하려면BeautifulSoup과 같은 HTML 파서가 필요합니다.
사실 HTTPX는 그저 평범한 HTTP 클라이언트가 아닌,웹 스크래핑을 위한 최고의 Python HTTP 클라이언트 중 하나입니다.
이 튜토리얼을 따라 BeautifulSoup과 함께 HTTPX를 사용하여 웹 스크래핑하는 방법을 배워보세요!
주의: HTTPX는 프로세스 초기 단계에서만 사용되지만, 전체 워크플로를 안내해 드리겠습니다. 고급 HTTPX 스크래핑 기법에 관심이 있다면 3단계 이후 다음 장으로 건너뛸 수 있습니다.
1단계: 프로젝트 설정
컴퓨터에 Python 3 이상이 설치되어 있는지 확인하세요.설치되어 있지않다면공식 사이트에서 다운로드하여설치 지침을 따르세요.
이제 다음 명령어로 HTTPX 스크래핑 프로젝트용 디렉터리를 생성하세요:
mkdir httpx-scraper
해당 디렉터리로 이동하여가상 환경을초기화하세요:
cd httpx-scraper
python -m venv env
선호하는 Python IDE로 프로젝트 폴더를 엽니다.Python 확장 프로그램이 설치된 Visual Studio Code나PyCharm Community Edition을사용하면 됩니다.
다음으로 프로젝트 폴더 내에 scraper.py 파일을 생성합니다. 현재 scraper.py는 빈 Python 스크립트이지만 곧 스크래핑 로직이 포함될 것입니다.
IDE 터미널에서 가상 환경을 활성화하세요. Linux 또는 macOS에서는 다음을 실행합니다:
./env/bin/activate
Windows에서는 다음과 같이 실행하세요:
env/Scripts/activate
완벽합니다! 이제 모든 설정이 완료되었습니다.
2단계: 스크래핑 라이브러리 설치
활성화된 가상 환경에서 다음 명령어로 HTTPX와 BeautifulSoup을 설치하세요:
pip install httpx beautifulsoup4
이렇게 하면httpx와beautifulsoup4가프로젝트의 종속성에 추가됩니다.
스크레이퍼 스크립트 (scraper.py )에 임포트하세요:
import httpx
from bs4 import BeautifulSoup
좋습니다! 이제 스크래핑 워크플로의 다음 단계로 진행할 준비가 되었습니다.
3단계: 대상 페이지의 HTML 가져오기
이 예시에서는 “Quotes to Scrape” 사이트를 대상 페이지로 사용하겠습니다:
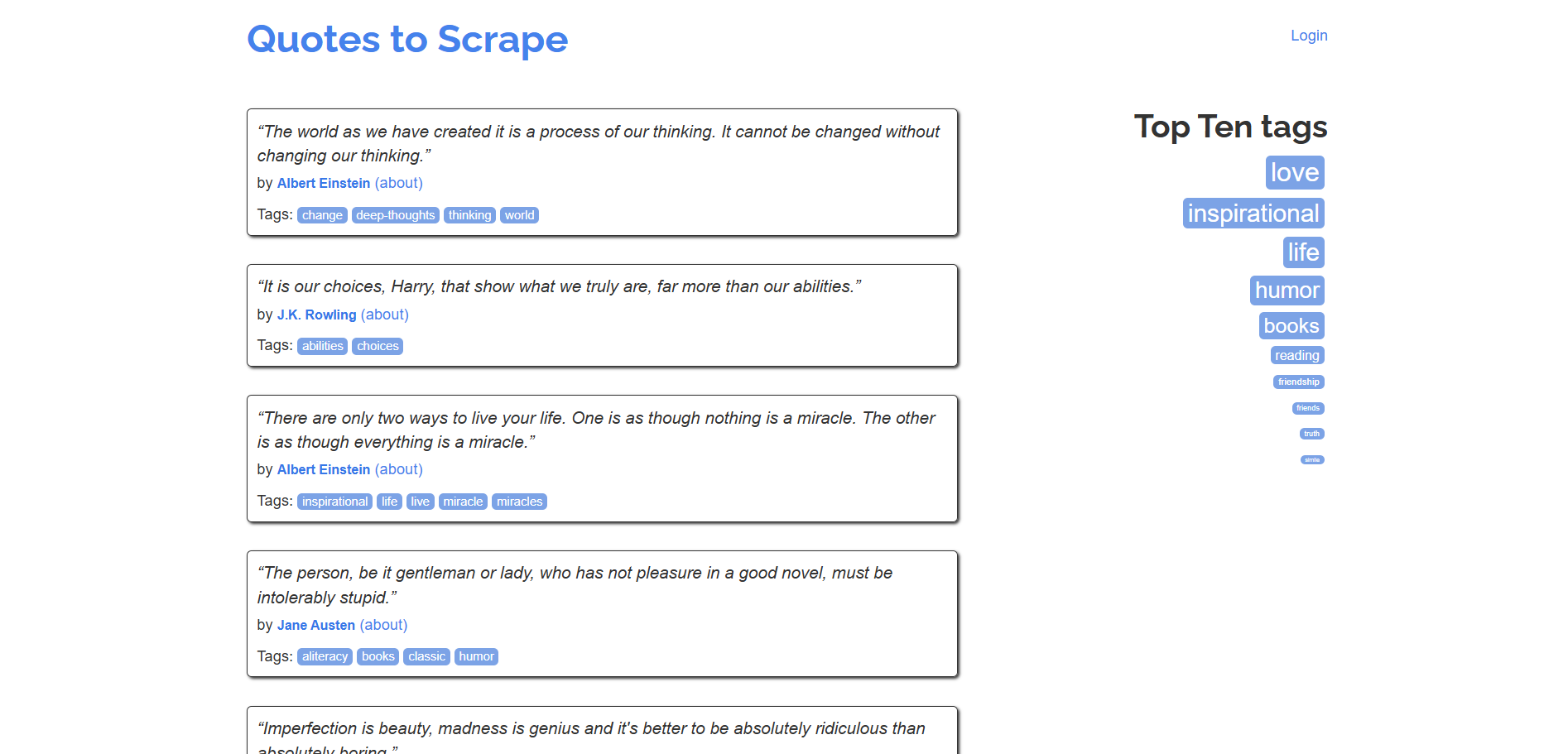
HTTPX의 get() 메서드를 사용하여 홈페이지의 HTML을 가져옵니다:
# 대상 페이지에 HTTP GET 요청 수행
response = httpx.get("http://quotes.toscrape.com")
HTTPX는 백그라운드에서 서버에 HTTP GET 요청을 보내며, 서버는 해당 페이지의 HTML로 응답합니다. response.text 속성을 사용하여 HTML 콘텐츠에 접근할 수 있습니다:
html = response.text
print(html)
이렇게 하면 페이지의 원시 HTML 콘텐츠가 출력됩니다:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>스크래핑할 인용문</title>
<link rel="stylesheet" href="/static/bootstrap.min.css">
<link rel="stylesheet" href="/static/main.css">
</head>
<body>
<!-- 간략화를 위해 생략... -->
</body>
</html>
훌륭합니다! 이제 이 콘텐츠를 파싱하고 필요한 데이터를 추출할 시간입니다.
4단계: HTML 파싱하기
HTML 콘텐츠를 BeautifulSoup 생성자에 전달하여 파싱합니다:
# HTML 콘텐츠를 파싱하기 위해
BeautifulSoup soup = BeautifulSoup(html, "html.parser")
html.parser는콘텐츠를 파싱하는 데 사용될 표준 Python HTML 파서입니다.
soup 변수는 이제 파싱된 HTML을 포함하며 필요한 데이터를 추출할 수 있는 메서드를 제공합니다.
HTTPX는 HTML을 가져오는 작업을 완료했으며, 이제 BeautifulSoup을 사용한 전통적인 데이터 파싱 단계로 넘어갑니다. 자세한 내용은BeautifulSoup 웹 스크래핑 튜토리얼을 참조하세요.
5단계: 데이터 스크래핑
다음 코드 줄로 페이지에서 명언 데이터를 스크래핑할 수 있습니다:
# 스크랩된 데이터 저장 위치
quotes = []
# 페이지에서 모든 인용문 추출
quote_elements = soup.find_all("div", class_="quote")
# 각 명언을 순회하며 텍스트, 저자, 태그 추출
for quote_element in quote_elements:
text = quote_element.find("span", class_="text").get_text().get_text().replace("“", "").replace("”", "")
author = quote_element.find("small", class_="author")
tags = [tag.get_text() for tag in quote_element.find_all("a", class_="tag")]
# 추출한 데이터 저장
quotes.append({
"text": text,
"author": author,
"tags": tags
})
이 코드 조각은 스크랩된 데이터를 저장하기 위해 quotes라는 이름의 리스트를 정의합니다. 그런 다음 모든 인용문 HTML 요소를 선택하고 이를 반복하여 인용문 텍스트, 저자, 태그를 추출합니다. 추출된 각 인용문은 quotes 리스트 내의 사전(dictionary)으로 저장되어, 향후 사용이나 내보내기를 위해 데이터를 체계화합니다.
네! 스크래핑 로직 구현 완료.
6단계: 스크랩된 데이터 내보내기
다음 로직을 사용하여 스크랩한 데이터를 CSV 파일로 내보냅니다:
# 내보낼 파일 이름 지정
with open("quotes.csv", mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=["text", "author", "tags"])
# 헤더 행 작성
writer.writeheader()
# 스크래핑된 명언 데이터 작성
writer.writerows(quotes)
이 코드 조각은 quotes.csv 파일을 쓰기 모드로 열고, 열 헤더(text, author, tags)를 정의한 후 헤더를 파일에 기록합니다. 그런 다음 quotes 리스트의 각 사전(dictionary)을 CSV 파일에 기록합니다. csv.DictWriter는 형식 처리를 담당하여 구조화된 데이터를 쉽게 저장할 수 있게 합니다.
Python 표준 라이브러리에서 csv를 반드시 임포트하세요:
import csv
7단계: 모든 것을 통합하기
최종 HTTPX 웹 스크래핑 스크립트는 다음과 같이 구성됩니다:
import httpx
from bs4 import BeautifulSoup
import csv
# 대상 페이지에 HTTP GET 요청 수행
response = httpx.get("http://quotes.toscrape.com")
# 대상 페이지의 HTML 접근
html = response.text
# BeautifulSoup을 사용하여 HTML 콘텐츠 파싱
soup = BeautifulSoup(html, "html.parser")
# 스크래핑된 데이터 저장 위치
quotes = []
# 페이지에서 모든 인용문 추출
quote_elements = soup.find_all("div", class_="quote")
# 인용문 반복 처리하여 텍스트, 저자, 태그 추출
for quote_element in quote_elements:
text = quote_element.find("span", class_="text").get_text().replace("“", "").replace("”", "")
author = quote_element.find("small", class_="author").get_text()
tags = [tag.get_text() for tag in quote_element.find_all("a", class_="tag")]
# 추출한 데이터 저장
quotes.append({
"text": text,
"author": author,
"tags": tags
})
# 내보낼 파일 이름 지정
with open("quotes.csv", mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=["text", "author", "tags"])
# 헤더 행 작성
writer.writeheader()
# 스크랩한 명언 데이터 작성
writer.writerows(quotes)
다음 명령어로 실행:
python scraper.py
또는 Linux/macOS에서:
python3 scraper.py
프로젝트 루트 폴더에 quotes.csv 파일이 생성됩니다. 파일을 열면 다음과 같은 내용을 확인할 수 있습니다:

자, 이제 HTTPX와 BeautifulSoup을 사용한 웹 스크래핑 방법을 배웠습니다.
HTTPX 웹 스크래핑 고급 기능 및 기법
기본적인 시나리오에서 HTTPX를 사용한 웹 스크래핑 방법을 알게 되었으니, 이제 더 복잡한 사용 사례에서 실제로 작동하는 모습을 볼 준비가 되었습니다.
아래 예시에서는HTTPBin.io의/anything엔드포인트를 대상으로 합니다. 이 특수 API는 호출자가 전송한 IP 주소, 헤더 및 기타 정보를 반환합니다.
웹 스크래핑을 위한 HTTPX를 마스터하세요!
사용자 정의 헤더 설정
헤더인자 덕분에 HTTPX로사용자 정의 헤더를 지정할수 있습니다:
import httpx
# 요청에 대한 커스텀 헤더
headers = {
"accept": "application/json",
"accept-language": "en-US,en;q=0.9,fr-FR;q=0.8,fr;q=0.7,es-US;q=0.6,es;q=0.5,it-IT;q=0.4,it;q=0.3"
}
# 사용자 정의 헤더로 GET 요청 수행
response = httpx.get("https://httpbin.io/anything", headers=headers)
# 응답 처리...
사용자 정의 User Agent 설정
User-Agent는웹 스크래핑에서 가장 중요한HTTP 헤더 중 하나입니다. 기본적으로 HTTPX는 다음과 같은User-Agent를 사용합니다:
python-httpx/<VERSION>
이 값은 요청이 자동화된 것임을 쉽게 드러내어 대상 사이트에 의해 차단될 수 있습니다.
이를 방지하려면 실제 브라우저를 모방하는 사용자 정의 User-Agent 를 설정할 수 있습니다:
import httpx
# 사용자 정의 User-Agent 정의
headers = {
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36"
}
# 사용자 정의 User-Agent로 GET 요청 수행
response = httpx.get("https://httpbin.io/anything", headers=headers)
# 응답 처리...
웹 스크래핑에 최적화된 사용자 에이전트를 찾아보세요!
쿠키 설정
HTTP 헤더와 마찬가지로, HTTPX에서쿠키인수를 사용하여 쿠키를 설정할 수 있습니다:
import httpx
# 쿠키를 사전으로 정의
cookies = {
"session_id": "3126hdsab161hdabg47adgb",
"user_preferences": "dark_mode=true"
}
# 사용자 지정 쿠키로 GET 요청 수행
response = httpx.get("https://httpbin.io/anything", cookies=cookies)
# 응답 처리...
이를 통해 웹 스크래핑 요청에 필요한 세션 데이터를 포함할 수 있습니다.
프록시 통합
웹 스크래핑 수행 시 신원을 보호하고 IP 차단 방지를 위해HTTPX 요청을 프록시를 통해 라우팅할수 있습니다. 이는proxies인수를 사용하여 가능합니다:
import httpx
# 프록시 서버 URL로 대체
proxy = "<YOUR_PROXY_URL>"
# 프록시 서버를 통한 GET 요청 수행
response = httpx.get("https://httpbin.io/anything", proxy=proxy)
# 응답 처리...
프록시와 함께 HTTPX를 사용하는 방법에 대한 가이드에서 자세히 알아보세요.
오류 처리
기본적으로 HTTPX는연결 또는 네트워크 문제에 대해서만 오류를 발생시킵니다.4xx및5xx상태 코드를 가진 HTTP 응답에 대해서도 예외를 발생시키려면 아래와 같이raise_for_status()메서드를 사용하세요:
import httpx
try:
response = httpx.get("https://httpbin.io/anything")
# 4xx 및 5xx 응답에 대해 예외 발생
response.raise_for_status()
# 응답 처리...
except httpx.HTTPStatusError as e:
# HTTP 상태 오류 처리
print(f"HTTP 오류 발생: {e}")
except httpx.RequestError as e:
# 연결 또는 네트워크 오류 처리
print(f"요청 오류 발생: {e}")
세션 처리
HTTPX의 최상위 API를 사용할 때, 각 요청마다 새로운 연결이 설정됩니다. 즉, TCP 연결이 재사용되지 않습니다. 호스트에 대한 요청 수가 증가함에 따라 이 방식은 비효율적이 됩니다.
반면,httpx.Client인스턴스를 사용하면HTTP 연결 풀링이 가능합니다. 이는 동일한 호스트에 대한 여러 요청이 각 요청마다 새 연결을 생성하는 대신 기존 TCP 연결을 재사용할 수 있음을 의미합니다.
최상위 API보다 Client를 사용할 때의 이점은 다음과 같습니다:
- 요청 간 지연 시간 감소 (반복적인 핸드셰이킹 방지)
- CPU 사용량 감소 및 왕복 통신 횟수 감소
- 네트워크 혼잡 감소
또한 Client 인스턴스는 최상위 API에서는 사용할 수 없는 세션 처리 기능을 지원합니다. 여기에는 다음이 포함됩니다:
- 요청 간 쿠키 지속성 유지
- 모든 아웃바운드 요청에 구성 적용
- HTTP 프록시를 통한 요청 전송.
HTTPX에서 클라이언트를 사용하는 권장 방법은 컨텍스트 매니저(with 문)를 활용하는 것입니다:
import httpx
with httpx.Client() as client:
# 클라이언트를 사용한 HTTP 요청 생성
response = client.get("https://httpbin.io/anything")
# JSON 응답 데이터 추출 및 출력
response_data = response.json()
print(response_data)
또는 클라이언트를 수동으로 관리하고 client.close()로 연결 풀을 명시적으로 닫을 수도 있습니다:
import httpx
client = httpx.Client()
try:
# 클라이언트를 사용하여 HTTP 요청 수행
response = client.get("https://httpbin.io/anything")
# JSON 응답 데이터를 추출하여 출력
response_data = response.json()
print(response_data)
except:
# 오류 처리...
pass
finally:
# 클라이언트 연결 종료 및 리소스 해제
client.close()
참고:requests라이브러리에 익숙하다면,httpx.Client()는requests.Session()과 유사한 역할을 합니다.
비동기 API
기본적으로 HTTPX는 표준 동기식 API를 제공합니다. 동시에 필요할 경우비동기 클라이언트도제공합니다.asyncio를 사용하는 경우, 비동기 클라이언트를 사용해야만 아웃바운드 HTTP 요청을 효율적으로 보낼 수 있습니다.
비동기 프로그래밍은 멀티스레딩보다 훨씬 효율적인 동시성 모델입니다. 상당한 성능 향상을 제공하며 웹소켓과 같은 장기 네트워크 연결을 지원합니다. 이는웹 스크래핑 속도를 높이는 핵심 요소입니다.
HTTPX에서 비동기 요청을 수행하려면 AsyncClient가 필요합니다. 아래와 같이 초기화한 후 GET 요청을 수행하세요:
import httpx
import asyncio
async def fetch_data():
async with httpx.AsyncClient() as client:
# 비동기 HTTP 요청 수행
response = await client.get("https://httpbin.io/anything")
# JSON 응답 데이터 추출 및 출력
response_data = response.json()
print(response_data)
# 비동기 함수 실행
asyncio.run(fetch_data())
with문은 블록이 종료될 때 클라이언트가 자동으로 닫히도록 보장합니다. 또는 클라이언트를 수동으로 관리하는 경우await client.close()로 명시적으로 닫을 수 있습니다.
AsyncClient를 사용할 때 모든 HTTPX 요청 메서드(get(), post() 등)는 비동기적입니다. 따라서 응답을 받으려면 해당 메서드 호출 전에 await를 추가해야 합니다.
실패한 요청 재시도
웹 스크래핑 중 네트워크 불안정으로 연결 실패나 시간 초과가 발생할 수 있습니다. HTTPX는HTTPTransport인터페이스를 통해 이러한 문제 처리를 간소화합니다. 이 메커니즘은httpx.ConnectError또는httpx.ConnectTimeout발생 시 요청을 재시도합니다.
다음 예시는 전송을 최대 3회까지 요청 재시도하도록 구성하는 방법을 보여줍니다:
import httpx
# 연결 오류 또는 시간 초과 시 재시도 기능으로 전송 구성
transport = httpx.HTTPTransport(retries=3)
# HTTPX 클라이언트와 함께 전송 사용
with httpx.Client(transport=transport) as client:
# GET 요청 수행
response = client.get("https://httpbin.io/anything")
# 응답 처리...
연결 관련 오류만 재시도를 유발합니다. 읽기/쓰기 오류나 특정 HTTP 상태 코드를 처리하려면tenacity 같은 라이브러리를 사용해 사용자 정의 재시도 로직을 구현해야 합니다.
웹 스크래핑을 위한 HTTPX vs Requests 비교
웹 스크래핑을 위한 HTTPX와Requests 비교 요약표:
| 기능 | HTTPX | Requests |
|---|---|---|
| GitHub 스타 | 8k | 52.4k |
| 비동기 지원 | ✔️ | ❌ |
| 연결 풀링 | ✔️ | ✔️ |
| HTTP/2 지원 | ✔️ | ❌ |
| 사용자 에이전트 사용자 지정 | ✔️ | ✔️ |
| 프록시 지원 | ✔️ | ✔️ |
| 쿠키 처리 | ✔️ | ✔️ |
| 타임아웃 | 연결 및 읽기 시 사용자 정의 가능 | 연결 및 읽기 시 사용자 정의 가능 |
| 재시도 메커니즘 | 전송 계층을 통해 사용 가능 | HTTP 어댑터를통해 사용 가능 |
| 성능 | 높음 | 중간 |
| 커뮤니티 지원 및 인기 | 증가 중 | 크다 |
결론
이 글에서는 웹 스크래핑을 위한 httpx 라이브러리를 살펴보았습니다. 이 라이브러리가 무엇인지, 어떤 기능을 제공하는지, 그리고 그 장점에 대해 이해하셨을 것입니다. HTTPX는 온라인 데이터를 수집할 때 HTTP 요청을 수행하는 빠르고 신뢰할 수 있는 옵션입니다.
문제는 자동화된 HTTP 요청이 공개 IP 주소를 노출시켜 신원과 위치를 드러낼 수 있다는 점입니다. 이는 개인 정보 보호를 위협합니다. 보안과 프라이버시를 강화하는 가장 효과적인 방법 중 하나는 프록시 서버를 사용하여IP 주소를 숨기는 것입니다.
Bright Data는 포춘 500대 기업 및 20,000명 이상의 고객에게 서비스를 제공하는 세계 최고의 프록시 서버를 운영합니다. 다양한 프록시 유형을 제공합니다:
- 데이터센터 프록시– 77만 개 이상의 데이터센터 IP 주소.
- 주거용 프록시– 195개국 이상에서 7,200만 개 이상의 주거용 IP.
- ISP 프록시– 70만 개 이상의 ISP IP 주소.
지금 바로 무료 Bright Data 계정을 생성하여 스크래핑 솔루션과 프록시를 테스트해 보세요!




