

이 글에서 배울 내용:
- Anthropic 웹 페치 도구의 정의와 주요 한계점.
- 작동 방식.
- cURL 및 Python에서 사용 방법.
- 비슷한 목표를 달성하기 위해 Bright Data가 제공하는 솔루션.
- Anthropic 웹 페치 도구와 Bright Data 웹 데이터 도구의 비교.
- 간단한 비교를 위한 요약표.
자, 시작해 보겠습니다!
Anthropic 웹 페치 툴이란?
Anthropic 웹 페치 도구는 Claude 모델이 웹 페이지와 PDF 문서의 콘텐츠를 검색할 수 있게 합니다. 이 도구는 2026-09-10 Claude 베타 릴리스에서 무료로 도입되었습니다.
Claude API 요청에 이 도구를 포함하면, 구성된 LLM이 지정된 웹 페이지 또는 PDF URL의 전체 텍스트를 가져와 분석할 수 있습니다. 이를 통해 Claude는 근거 있는 응답을 위해 최신 출처 기반 정보에 접근할 수 있습니다.
참고 사항 및 제한 사항
Anthropic 웹 페치 도구와 관련된 주요 참고 사항 및 제한 사항은 다음과 같습니다:
- Claude API에서 추가 비용 없이 이용 가능합니다. 대화 컨텍스트에 포함된 가져온 콘텐츠에 대해 표준 토큰 요금만 지불하면 됩니다.
- 지정된 웹 페이지 및 PDF 문서의 전체 콘텐츠를 가져옵니다.
- 현재 베타 버전이며 베타 헤더
web-fetch-2026-09-10이필요합니다. - Claude는 URL을 동적으로 생성할 수 없습니다. 완전한 URL을 명시적으로 제공해야 하며, 이전 웹 검색 또는 Fetch 결과에서 얻은 URL만 사용할 수 있습니다.
- 대화 컨텍스트에 이미 등장한 URL만 가져올 수 있습니다. 여기에는 사용자 메시지, 클라이언트 측 도구 결과, 이전 웹 검색 및 웹 가져오기 결과의 URL이 포함됩니다.
- 다음 모델에서만 작동합니다: Claude Opus 4.1 (
claude-opus-4-1-20260805), Claude Opus 4 (claude-opus-4-20260514), Claude Sonnet 4.5 (claude-sonnet-4-5-20260929), Claude Sonnet 4 (claude-sonnet-4-20260514), Claude Sonnet 3.7 (claude-3-7-sonnet-20260219), Claude Sonnet 3.5 v2 (사용 중단됨) (claude-3-5-sonnet-latest), Claude Haiku 3.5 (claude-3-5-haiku-latest). - 동적으로 렌더링되는 자바스크립트 웹사이트는 지원하지 않습니다.
- 가져온 콘텐츠에 선택적 인용을 포함할 수 있습니다.
- 프롬프트 캐싱과 연동되어 캐시된 결과를 대화 턴 간에 재사용할 수 있습니다.
max_uses,allowed_domains,blocked_domains및max_content_tokens매개 변수를 지원합니다.- 일반적인 오류 코드:
invalid_input,url_too_long,url_not_allowed,url_not_accessible,too_many_requests,unsupported_content_type,max_uses_exceeded,unavailable.
Claude 모델에서 웹 페치 기능의 작동 방식
API 요청에 Anthropic 웹 페치 도구를 추가하면 다음과 같은 작업이 백그라운드에서 수행됩니다:
- Claude는 프롬프트와 제공된 URL을 기반으로 콘텐츠를 가져올 시점을 결정합니다.
- API는 지정된 URL에서 전체 텍스트 콘텐츠를 가져옵니다.
- PDF의 경우 자동 텍스트 추출이 수행됩니다.
- Claude는 가져온 콘텐츠를 분석하여 응답을 생성하며, 선택적으로 인용 정보를 포함합니다.
생성된 응답은 사용자에게 반환되거나 추가 분석을 위해 대화 컨텍스트에 추가됩니다.
Anthropic 웹 가져오기 도구 사용 방법
웹 페치 도구를 사용하는 두 가지 주요 방법은 지원되는 Claude 모델 중 하나에 대한 요청에서 이를 활성화하는 것입니다. 다음 방법 중 하나로 수행할 수 있습니다:
- Anthropic API에 대한 직접 API 호출을 통해.
- Anthropic Python API 라이브러리와 같은 Claude 클라이언트 SDK 중 하나를 통해.
다음 섹션에서 방법을 확인하세요!
두 경우 모두, 아래와 같이 Anthropic 홈페이지를 스크래핑하기 위해 웹 페치 도구를 사용하는 방법을 시연해 보겠습니다:

필수 조건
Anthropic 웹 페치 도구 사용의 주요 요건은 Anthropic API 키에 대한 접근 권한입니다. 여기서는 API 키가 설정된 Anthropic 계정이 있다고 가정합니다.
직접 API 호출을 통해
아래 cURL POST 요청 예시처럼 지원되는 모델 중 하나로 Anthropic API에 직접 호출하여 웹 페치 도구를 활용하세요:
curl https://api.anthropic.com/v1/messages
--header "x-api-key: <YOUR_ANTHROPIC_API_KEY>"
--header "anthropic-version: 2023-06-01"
--header "anthropic-beta: web-fetch-2026-09-10"
--header "content-type: application/json"
--data '{
"model": "claude-sonnet-4-5-20260929",
"max_tokens": 1024,
"messages": [
{
"role": "user",
"content": "Scrape the content from 'https://www.anthropic.com/'"
}
],
"tools": [{
"type": "web_fetch_20260910",
"name": "web_fetch",
"max_uses": 5
}]
}'참고: claude-sonnet-4-5-20260929는 웹 페치 도구에서 지원하는 모델 중 하나입니다.
또한 anthropic-version 및 anthropic-beta라는 두 가지 특수 헤더가 필수임을 유의하십시오.
구성된 모델에서 웹 페치 도구를 활성화하려면 요청 본문의 tools 배열에 다음 항목을 추가해야 합니다:
{
"type": "web_fetch_20260910",
"name": "web_fetch",
"max_uses": 5
}type 및 name 필드가 중요하며, max_uses는 선택 사항으로 단일 반복 내에서 도구를 호출할 수 있는 횟수를 정의합니다.
<YOUR_ANTHROPIC_API_KEY> 자리 표시자를 실제 Anthropic API 키로 대체하세요. 그런 다음 요청을 실행하면 다음과 같은 결과를 얻을 수 있습니다:
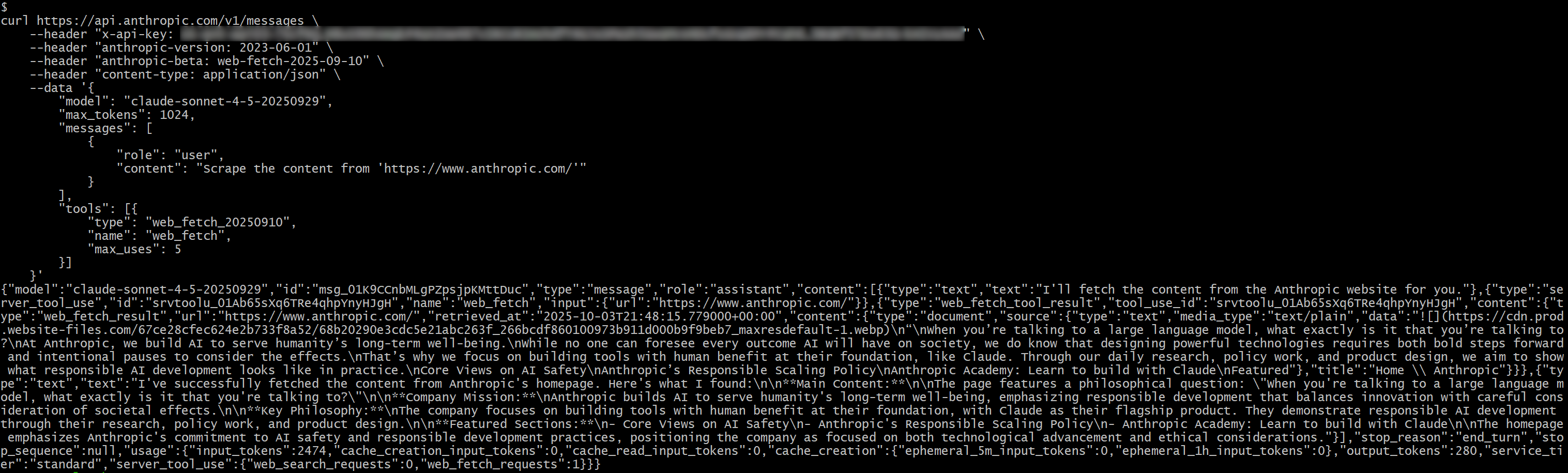
응답에는 다음과 같은 내용이 표시됩니다:
{"type":"server_tool_use","id":"srvtoolu_01Ab65sXq6TRe4qhpYnyHJgH","name":"web_fetch","input":{"url":"https://www.anthropic.com/"}}이는 LLM이 web_fetch 도구를 호출했음을 나타냅니다.
구체적으로, 해당 도구가 생성한 결과는 다음과 같을 것입니다:

“대규모 언어 모델과 대화할 때, 정확히 무엇과 대화하고 있는 걸까요?
Anthropic에서는 인류의 장기적 복지를 위해 AI를 구축합니다.
AI가 사회에 미칠 모든 결과를 예측할 수는 없지만, 강력한 기술을 설계하려면 과감한 진전과 함께 그 영향을 고려하기 위한 의도적인 멈춤이 필요하다는 점은 알고 있습니다.
그래서 우리는 클로드(Claude)처럼 인간에게 이익이 되는 것을 기반으로 한 도구 개발에 집중합니다. 매일의 연구, 정책 작업, 제품 설계를 통해 책임감 있는 AI 개발이 실제로 어떻게 구현되는지 보여주고자 합니다.
AI 안전에 대한 핵심 관점
앤트로픽의 책임 있는 확장 정책
앤트로픽 아카데미: 클로드로 구축하는 법 배우기
추천 콘텐츠
이는 지정된 입력 URL의 홈페이지 내용을 마크다운 형식으로 변환한 것입니다. 일부 링크가 생략되었고 첫 번째 이미지를 제외하면 텍스트 위주로 출력된다는 점에서 ‘일종의’ 마크다운이라 할 수 있습니다. 이는 웹 페치 도구가 반환하도록 설계된 결과물과 정확히 일치합니다.
참고: 전체적으로 결과는 정확하지만, 도구 처리 과정에서 일부 내용이 누락되었을 수 있습니다. 실제로 원본 페이지에는 추출된 내용보다 더 많은 텍스트가 포함되어 있습니다.
Anthropic Python API 라이브러리 사용
대안으로 Anthropic Python API 라이브러리를 사용하여 웹 페치 도구를 호출할 수 있습니다:
# pip install anthropic
import anthropic
# Anthropic API 키로 대체하세요
ANTHROPIC_API_KEY = "<YOUR_ANTHROPIC_API_KEY>"
# Anthropic API 클라이언트 초기화
client = anthropic.Anthropic(api_key=ANTHROPIC_API_KEY)
# 웹 페치 도구 활성화 상태로 Claude에 요청 수행
response = client.messages.create(
model="claude-sonnet-4-5-20260929",
max_tokens=1024,
messages=[
{
"role": "user",
"content": "Scrape the content from 'https://www.anthropic.com/'"
}
],
tools=[
{
"type": "web_fetch_20260910",
"name": "web_fetch",
"max_uses": 5
},
],
extra_headers={
"anthropic-beta": "web-fetch-2026-09-10"
})
# AI가 생성한 결과를 터미널에 출력
print(response.content)
이번에는 결과가 다음과 같습니다:
좋습니다! 이는 앞서 본 내용과 동일합니다.
Bright Data 웹 데이터 도구 소개
Bright Data AI 인프라스트럭처는 AI가 웹을 자유롭게 검색, 크롤링 및 탐색할 수 있도록 풍부한 솔루션을 제공합니다. 여기에는 다음이 포함됩니다:
- Unlocker API: 공개 URL에서 콘텐츠를 안정적으로 가져오며, 자동으로 차단 우회 및 CAPTCHA 해결을 수행합니다.
- 크롤 API: 전체 웹사이트를 손쉽게 크롤링하고 추출하며, 효과적인 추론과 논리를 위한 LLM 준비 완료 형식으로 출력합니다.
- SERP API: 특정 쿼리에 대한 관련 데이터 소스를 발견하기 위해 실시간, 지역별 검색 엔진 결과를 수집합니다.
- 브라우저 API: 원격 스텔스 브라우저를 활용하여 AI가 동적 사이트와 상호작용하고 대규모 에이전트 워크플로를 자동화할 수 있도록 지원합니다.
Bright Data 인프라의 다양한 웹 데이터 수집 도구, 서비스 및 제품 중 Web MCP에 집중합니다. 이는 Bright Data 제품을 기반으로 구축된 AI 통합 준비 도구로, Anthropic이 제공하는 도구와 직접 비교 가능합니다. Web MCP는 Claude MCP로도 기능하며 모든 Anthropic 모델과 완벽하게 통합됩니다.
60개 이상의 사용 가능한 도구 중 scrape_as_markdown 도구가 비교에 가장 적합합니다. 이 도구는 콘텐츠 추출을 위한 고급 옵션과 함께 단일 웹페이지 URL을 스크래핑하고 결과를 마크다운 형식으로 반환합니다. 이 도구는 봇 탐지나 CAPTCHA를 사용하는 웹페이지를 포함해 모든 웹페이지에 접근할 수 있습니다.
중요한 점은 해당 도구가 무료 계층에서도 Web MCP에서 이용 가능하다는 것입니다. 즉, 비용 없이 사용할 수 있습니다. 따라서 Anthropic의 웹 페치 도구와 유사한 웹 데이터 검색 기능을 구현하여 Web MCP를 직접 비교에 이상적인 도구로 만듭니다.
Anthropic 웹 페치 도구 vs Bright Data 웹 데이터 도구
이 섹션에서는 Anthropic 웹 페치 도구와 Bright Data의 웹 데이터 도구를 비교하는 프로세스를 구축합니다. 구체적으로 다음을 수행할 것입니다:
- Anthropic Python API 라이브러리를 통해 웹 페치 도구 사용
- LangChain MCP 어댑터를 사용하여 Bright Data의 Web MCP에 연결합니다( 다른 지원되는 통합 방식도 가능합니다).
다음 네 개의 입력 URL에 대해 동일한 프롬프트와 Claude 모델을 사용하여 두 접근법을 실행합니다:
"https://www.anthropic.com/""https://www.g2.com/products/bright-data/reviews""https://www.amazon.com/Owala-FreeSip-Insulated-Stainless-BPA-Free/dp/B0BZYCJK89/""https://it.linkedin.com/in/antonello-zanini"
이들은 AI가 자동으로 콘텐츠를 수집하기를 원하는 실제 페이지의 좋은 조합을 나타냅니다: 웹사이트 홈페이지, G2 제품 페이지, 아마존 제품 페이지, 공개 LinkedIn 프로필입니다. G2는 Cloudflare 보호로 인해 스크래핑하기가 특히 까다롭기로 유명하므로, 비교에 의도적으로 포함된 점에 유의하세요.
두 도구의 성능을 비교해 보겠습니다!
필수 조건
이 섹션을 진행하기 전에 다음을 준비해야 합니다:
- 로컬에 설치된 Python.
- Anthropic API 키.
- API 키가 있는 Bright Data 계정.
Bright Data 계정 설정 및 API 키 생성은 공식 가이드를 따르십시오. 공식 Web MCP 문서 검토도 권장됩니다.
또한 LangChain 통합 방식에 대한 이해와 Web MCP에서 제공하는 도구에 대한 친숙함이 도움이 될 것입니다.
웹 페치 도구 통합 스크립트
선택한 입력 URL을 통해 Anthropic 웹 페치 도구를 실행하려면 다음과 같은 Python 로직을 작성할 수 있습니다:
# pip install anthropic
import anthropic
Anthropic API 키로 대체하세요
ANTHROPIC_API_KEY = ""
Anthropic API 클라이언트 초기화
client = anthropic.Anthropic(api_key=ANTHROPIC_API_KEY)
def scrape_content_with_anthropic_web_fetch_tool(url):
return client.messages.create( model="claude-sonnet-4-5-20260929",
max_tokens=1024,
messages=[
{
"role": "user",
"content": f"Scrape the content from '{url}'"
}
],
tools=[
{
"type": "web_fetch_20260910",
"name": "web_fetch",
"max_uses": 5
},
],
extra_headers={
"anthropic-beta": "web-fetch-2026-09-10"
}
)
다음으로, 입력 URL에 대해 이 함수를 다음과 같이 호출할 수 있습니다:
scrape_content_with_anthropic_web_fetch_tool("https://www.anthropic.com/")
Bright Data 웹 데이터 도구 통합 스크립트
웹 MCP는 당사 블로그에 설명된 대로 다양한 기술과 통합될 수 있습니다. 여기서는 가장 쉽고 인기 있는 옵션 중 하나인 LangChain과의 통합을 시연해 보겠습니다.
시작하기 전에 가이드 “Bright Data의 Web MCP를 활용한 LangChain MCP 어댑터“를 확인하는 것이 좋습니다.
이 경우 다음과 같은 Python 코드 조각을 얻게 됩니다:
# pip install "langchain[anthropic]" langchain-mcp-adapters langgraph
import asyncio
from langchain_anthropic import ChatAnthropic
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
from langchain_mcp_adapters.tools import load_mcp_tools
from langgraph.prebuilt import create_react_agent
import json
# API 키로 대체하세요
ANTHROPIC_API_KEY = "<YOUR_ANTHROPIC_API_KEY>"
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>"
async def scrape_content_with_bright_data_web_mcp_tools(agent, url):
# 에이전트 작업 설명
input_prompt = f"{url}'의 콘텐츠를 스크랩하세요"
# 에이전트에서 요청 실행, 응답 스트리밍, 문자열로 반환
output = []
async for step in agent.astream({"messages": [input_prompt]}, stream_mode="values"):
content = step["messages"][-1].content
if isinstance(content, list):
output.append(json.dumps(content))
else:
output.append(content)
return "".join(output)
async def main():
# LLM 엔진 초기화
llm = ChatAnthropic(
model="claude-sonnet-4-5-20260929",
api_key=ANTHROPIC_API_KEY
)
# 로컬 Bright Data Web MCP 서버 인스턴스 연결 설정
server_params = StdioServerParameters(
command="npx",
args=["-y", "@brightdata/mcp"],
env={
"API_TOKEN": BRIGHT_DATA_API_KEY,
"PRO_MODE": "false" # Pro 모드 사용 시 선택적으로 "true"로 설정
}
)
# MCP 서버에 연결
async with stdio_client(server_params) as (read, write):
async with ClientSession(read, write) as session:
# MCP 클라이언트 세션 초기화
await session.initialize()
# Web MCP 도구 로드
tools = await load_mcp_tools(session)
# Web MCP 통합 기능이 있는 ReAct 에이전트 생성
agent = create_react_agent(llm, tools)
# scrape_content_with_bright_data_web_mcp_tools(agent, "https://www.anthropic.com/")
if __name__ == "__main__":
asyncio.run(main())
이는 Web MCP 도구에 접근할 수 있는 ReAct 에이전트를 정의합니다.
참고: Web MCP는 프리미엄 도구에 접근할 수 있는 Pro 모드를 제공합니다. 본 사례에서는 Pro 모드 사용이 반드시 필요한 것은 아닙니다. 따라서 무료 계층에서 제공되는 도구만으로도 충분합니다. 무료 도구에는 scrape_as_markdown이 포함되어 있으며, 이는 본 벤치마크에 적합합니다.
간단히 말해, 비용 측면에서 무료 모드로 Web MCP를 사용하는 것은 Claude 모델 자체의 토큰 사용량(두 시나리오 모두 동일)보다 더 많은 비용이 들지 않습니다. 본질적으로 이 설정의 비용 구조는 API를 통해 Claude에 직접 연결할 때와 동일합니다.
벤치마크 결과
이제 다음과 같은 로직으로 AI 웹 데이터 검색의 두 가지 방법을 나타내는 두 함수를 실행합니다:
# 벤치마크 결과 저장 위치
benchmark_results = []
# 두 접근법을 테스트할 입력 URL
urls = [
"https://www.anthropic.com/",
"https://www.g2.com/products/bright-data/reviews",
"https://www.amazon.com/Owala-FreeSip-Insulated-Stainless-BPA-Free/dp/B0BZYCJK89/",
"https://it.linkedin.com/in/antonello-zanini"
]
# 각 URL 테스트
for url in urls:
print(f"다음 URL에서 두 가지 접근 방식 테스트 중: {url}")
anthropic_start_time = time.time()
anthropic_response = scrape_content_with_anthropic_web_fetch_tool(url)
anthropic_end_time = time.time()
bright_data_start_time = time.time()
bright_data_response = await scrape_content_with_bright_data_web_mcp_tools(agent, url)
bright_data_end_time = time.time()
벤치마크_엔트리 = {
"url": url,
"anthropic": {
"execution_time": anthropic_end_time - anthropic_start_time,
"output": anthropic_response.to_json()
},
"bright_data": {
"execution_time": bright_data_end_time - bright_data_start_time,
"output": bright_data_response
}
}
benchmark_results.append(벤치마크 항목)
# 벤치마크 데이터 내보내기
with open("benchmark_results.json", "w", encoding="utf-8") as f:
json.dump(benchmark_results, f, ensure_ascii=False, indent=4)
결과는 다음 표로 요약할 수 있습니다:
| Anthropic 웹 페치 도구 | Bright Data 웹 데이터 도구 | |
|---|---|---|
| Anthropic 홈페이지 | ✔️ (부분 텍스트 정보) | ✔️ (Markdown 형식의 전체 정보) |
| G2 리뷰 페이지 | ❌ (도구가 ~10초 후 실패함) | ✔️ (페이지의 전체 마크다운 버전) |
| Amazon 제품 페이지 | ✔️ (부분 텍스트 정보) | ✔️ (페이지의 전체 마크다운 버전 또는 프로 모드에서 구조화된 JSON 제품 데이터) |
| LinkedIn 프로필 페이지 | ❌ (도구가 즉시 실패함) | ✔️ (페이지의 전체 마크다운 버전 또는 프로 모드에서 구조화된 JSON 프로필 데이터) |
보시다시피, Anthropic 웹 페치 도구는 Bright Data 웹 데이터 도구보다 효율성이 떨어질 뿐만 아니라, 작동할 때조차 덜 완전한 결과를 생성합니다.
Anthropic 도구는 주로 텍스트에 집중하는 반면, scrape_as_markdown과 같은 Web MCP 도구는 페이지의 전체 마크다운 버전을 반환합니다. 또한 web_data_amazon_product와 같은 Pro 도구를 사용하면 Amazon과 같은 인기 사이트에서 구조화된 데이터 피드를 얻을 수 있습니다.
전반적으로 Bright Data 웹 데이터 도구는 정확성과 실행 시간 측면에서 확실한 승자입니다!
요약: 비교표
| Anthropic 웹 페치 도구 | Bright Data 웹 데이터 도구 | |
|---|---|---|
| 콘텐츠 유형 | 웹 페이지, PDF | 웹 페이지 |
| 기능 | 텍스트 추출 | 콘텐츠 추출, 웹 스크래핑, 웹 크롤링 등 |
| 출력 | 주로 일반 텍스트 | 마크다운, JSON 및 기타 LLM 호환 형식 |
| 모델 통합 | 특정 Claude 모델과만 호환 | 모든 LLM 및 70개 이상의 기술과 완벽하게 통합 |
| JavaScript로 렌더링된 사이트 지원 | ❌ | ✔️ |
| 봇 우회 방지/CAPTCHA 처리 | ❌ | ✔️ |
| 견고성 | 베타 | 생산 환경 지원 |
| 일괄 요청 지원 | ✔️ | ✔️ |
| 에이전트 통합 | Claude 솔루션에서만 | ✔️ (MCP 또는 공식 Bright Data 도구를 지원하는 모든 AI 에이전트 구축 솔루션에서 ) |
| 신뢰성과 완전성 | 부분적 콘텐츠; 복잡한 페이지에서는 실패할 수 있음 | 전체 콘텐츠 추출; 봇 보호 기능이 있는 복잡한 사이트 및 페이지 처리 가능 |
| 비용 | 표준 토큰 사용량만 적용 | 무료 모드에서는 표준 토큰 사용만 가능; 프로 모드에서는 추가 비용 발생 |
Web MCP를 Anthropic 기술 및 Claude 모델과 통합하려면 다음 가이드를 참조하십시오:
- Bright Data의 Web MCP와 Claude Code 통합
- Claude를 활용한 웹 스크래핑: Python에서 AI 기반 파싱
- Claude Desktop에서 Pica MCP와 Bright Data 사용 방법
결론
이 비교 블로그 글에서는 Anthropic 웹 페치 도구가 Bright Data가 제공하는 웹 데이터 검색 및 상호작용 기능과 어떻게 비교되는지 살펴보았습니다. 특히 Anthropic 도구를 실제 사례에서 활용하는 방법을 배운 후, Bright Data의 Web MCP와 상호작용하는 동등한 LangChain 에이전트를 사용한 벤치마크 비교를 진행했습니다.
다양한 사용 사례와 시나리오를 지원할 수 있는 다양한 AI 지원 제품 및 서비스를 포함하는 Bright Data의 도구가 확실한 승자였습니다.
지금 바로 Bright Data 계정을 무료로 생성하고 AI 지원 웹 데이터 도구를 탐색해 보세요!




