

이 튜토리얼에서 배우게 될 내용:
- BabyAGI가 무엇이며, 어떻게 진정한 의미에서 독보적인 AI 에이전트 구축 프레임워크가 되는지.
- Bright Data 서비스로 BabyAGI를 확장하면 다양한 흥미로운 시나리오가 가능해지는 이유.
- 커스텀 함수를 통해 Bright Data를 BabyAGI에 통합하는 방법.
자, 시작해 보겠습니다!
BabyAGI란 무엇인가요?
BabyAGI는 사용자 정의 목표를 달성하기 위해 작업을 생성, 우선순위 지정 및 실행할 수 있는 자체 구축 자율 AI 에이전트를 생성하기 위해 설계된 실험적인 Python 프레임워크입니다.
이 프레임워크는 최소한의 기능으로 스스로 개선하는 작업 관리자와 같은 역할을 하며, 추론을 위해 OpenAI 모델과 같은 대규모 언어 모델(LLM)을, 기억을 위해 벡터 데이터베이스를 활용합니다. 일반적으로 복잡한 워크플로를 자동화하기 위해 지능형 루프 방식으로 작동합니다.
핵심적으로 BabyAGI는 데이터베이스에서 함수를 저장, 관리 및 실행하기 위한 functionz라는 함수 기반 프레임워크를 도입합니다. 이 함수들은 코드 생성을 지원하여 AI 에이전트가 새로운 함수를 등록하고 호출하며 자율적으로 진화할 수 있게 합니다.
내장된 대시보드를 통해 함수 관리, 실행 모니터링, 비밀 정보 등록이 가능합니다. 그래프 기반 구조로 임포트, 종속 함수, 인증 비밀 정보를 추적하며 자동 로딩과 상세 로깅 기능을 제공합니다.
BabyAGI가 특히 주목받는 이유는 단순성, 자체 구축 능력, 사용자 친화적인 웹 대시보드 때문입니다. 핵심 아이디어는 최소한의 구조로 스스로를 확장할 수 있는 에이전트가 가장 효과적인 자율 에이전트라는 점입니다.
BabyAGI는 오픈 소스로 활발히 유지 관리되며, GitHub에서 22,000개 이상의 스타를 보유하고 있습니다.
웹 데이터 접근을 통한 더 나은 자가 구축 AI 에이전트 구현
LLM은 훈련에 사용된 정적 데이터에 의해 본질적으로 제한을 받으며, 이는 종종 환각 및 기타 일반적인 LLM 문제로 이어집니다.
BabyAGI는 자체 구축 기능 프레임워크를 통해 이러한 제약을 극복합니다. LLM을 활용하여 맞춤형 함수를 작성한 후, 이를 에이전트의 기능 확장 도구로 다시 전달합니다.
그러나 이러한 함수를 생성하는 로직은 여전히 LLM의 구식 지식에 의해 제한을 받습니다. 이러한 주요 한계를 해결하기 위해 BabyAGI는 웹을 검색하고 정확하고 최신 정보를 검색하여 보다 신뢰할 수 있는 함수를 생성할 수 있는 능력이 필요합니다.
이는 Bright Data 서비스와의 연동을 통해 가능해집니다. 예를 들어:
- SERP API: 차단 없이 대규모로 Google, Bing 등의 검색 엔진 결과를 수집합니다.
- 웹 언락커 API: 프록시, 헤더, CAPTCHA를 자동 처리하며 단일 요청으로 모든 웹사이트에 접근하여 깨끗한 HTML 또는 마크다운을 수신합니다.
- 웹 스크래핑 API: Amazon, LinkedIn, Instagram, Yahoo Finance 등 인기 플랫폼에서 구조화되고 파싱된 데이터를 추출합니다.
- 기타 솔루션…
이러한 통합 기능과 BabyAGI의 자체 구축 아키텍처를 결합하면, AI는 자율적으로 진화하고 새로운 기능을 추가하며 표준 LLM이 단독으로 달성할 수 있는 범위를 훨씬 뛰어넘는 복잡한 워크플로를 처리할 수 있습니다.
웹 데이터 검색 기능을 위해 Bright Data로 BabyAGI 확장하는 방법
이 단계별 섹션에서는 사용자 정의 기능을 통해 Bright Data를 BabyAGI에 통합하는 방법을 안내합니다. 이 기능은 SERP API와 Web Unlocker API라는 두 가지 Bright Data 제품에 연결됩니다.
시작하려면 아래 지침을 따르세요!
필수 조건
이 튜토리얼을 따라하려면 다음이 필요합니다:
- 로컬에 설치된Python 3.10 이상
- OpenAI API 키.
- SERP API 영역, Web Unlocker API 영역 및 활성 API 키로 구성된 Bright Data 계정.
아직 Bright Data 계정이 설정되지 않았더라도 걱정하지 마세요. 전용 단계에서 이 과정을 안내해 드립니다.
1단계: BabyAGI 프로젝트 설정
터미널을 열고 BabyAGI 프로젝트용 새 폴더를 생성하세요. 예를 들어, babyagi-bright-data-app라고 명명합니다:
mkdir babyagi-bright-data-appbabyagi-bright-data-app/ 폴더에는 BabyAGI 대시보드를 실행하고 Bright Data 통합 기능을 정의하는 Python 코드가 포함됩니다.
다음으로 프로젝트 디렉터리로 이동하여 가상 환경을 초기화합니다:
cd babyagi-bright-data-app
python -m venv .venv프로젝트 루트에 main.py라는 새 파일을 추가합니다. 현재 내용은 다음과 같아야 합니다:
babyagi-bright-data-app/
├── .venv/
└── main.pymain.py에는 BabyAGI 실행 및 확장 로직이 포함됩니다.
Visual Studio Code(Python 확장 기능 포함 )나 PyCharm Community Edition 등 선호하는 Python IDE에서 프로젝트 폴더를 로드하세요.
이제 앞서 생성한 가상 환경을 활성화합니다. Linux 또는 macOS에서는 다음 명령을 실행하세요:
source .venv/bin/activateWindows에서는 다음과 같이 실행하세요:
.venv/Scripts/activate가상 환경이 활성화된 상태에서 필요한 PyPI 라이브러리를 설치합니다:
pip install babyagi requests이 애플리케이션의 종속성은 다음과 같습니다:
babyagi: 대시보드를 실행할 수 있도록 BabyAGI와 모든 필수 요소를 설치합니다.requests: Bright Data 서비스에 연결하기 위한 HTTP 요청을 수행하는 데 도움을 줍니다.
완료! 이제 BabyAGI에서 자체 에이전트 개발을 위한 Python 환경이 준비되었습니다.
2단계: BabyAGI 대시보드 실행
main.py 파일에 다음 코드를 추가하여 BabyAGI 대시보드를 초기화하고 실행하세요:
import babyagi
if __name__ == "__main__":
app = babyagi.create_app("/dashboard")
app.run(host="0.0.0.0", port=8080)이 코드는 BabyAGI가 대시보드 애플리케이션을 다음 주소로 노출하도록 지시합니다:
http://localhost:8080/dashboard다음 명령어를 실행하여 애플리케이션이 정상 작동하는지 확인하세요:
python main.py터미널에서 대시보드가 http://localhost:8080/dashboard에서 대기 중임을 나타내는 로그를 확인할 수 있습니다:
브라우저에서 해당 URL을 방문하여 대시보드에 접속하세요: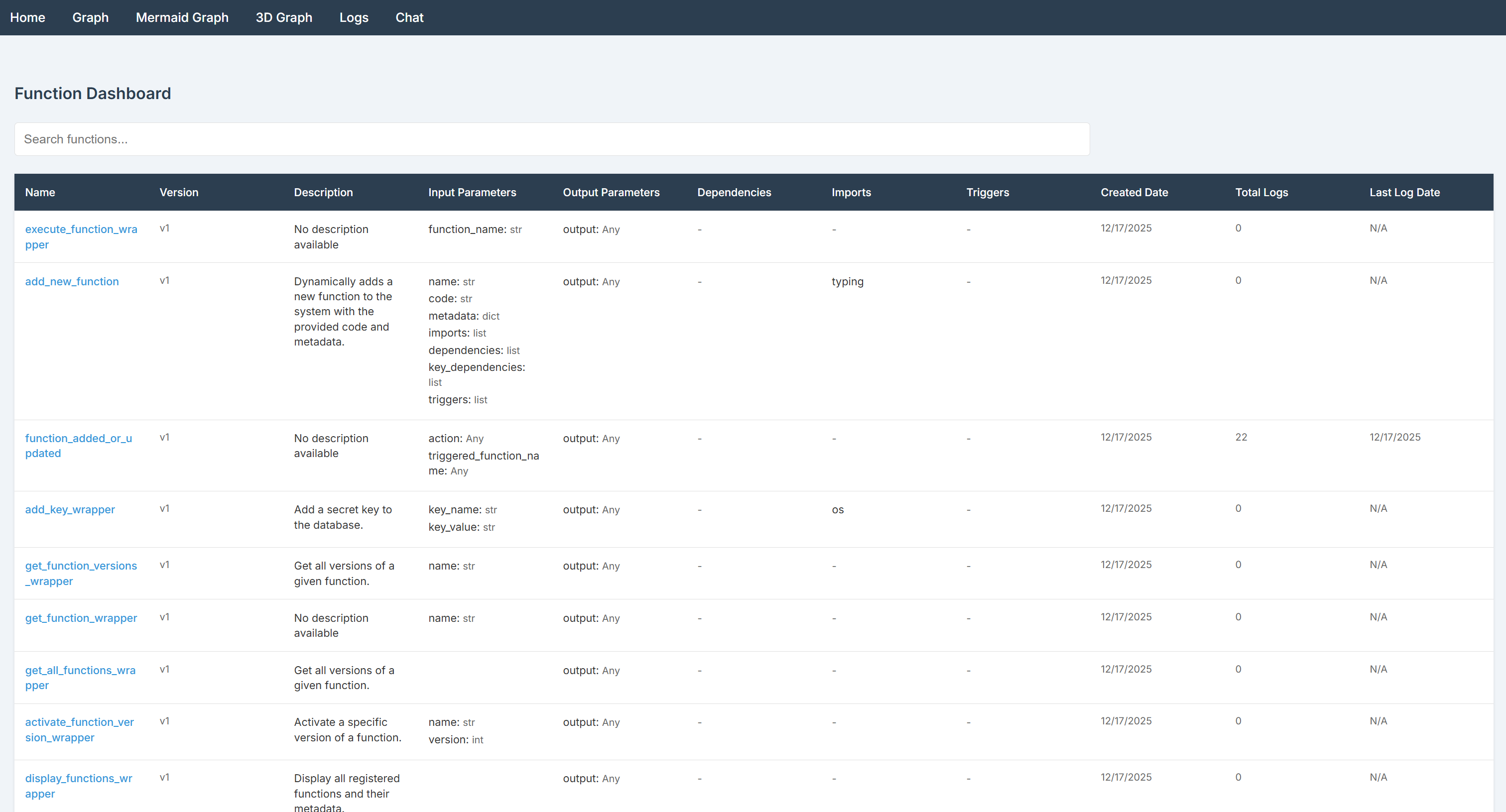
BabyAGI 대시보드 홈페이지는 사용 가능한 모든 함수를 나열합니다. 기본적으로 라이브러리는 두 개의 사전 로드된 함수 팩을 제공합니다:
- 기본 기능:
- 함수 실행: 함수 및 버전 실행, 추가, 업데이트, 검색
- 키 관리: 비밀 키 추가 및 검색.
- 트리거: 다른 함수에 기반하여 함수를 실행하도록 트리거를 구성합니다.
- 로그: 선택적 필터와 함께 실행 로그 조회.
- AI 함수:
- AI 설명 및 임베딩: 함수 설명 및 임베딩을 자동 생성합니다.
- 함수 선택: 프롬프트를 기반으로 유사한 함수를 찾거나 추천합니다.
BabyAGI 대시보드는 기능 관리, 실행 모니터링, 시크릿 처리, 트리거 구성, 종속성 시각화를 위한 사용자 친화적인 인터페이스를 제공합니다. 사용 가능한 페이지를 탐색하여 기능과 옵션을 익혀보세요!
3단계: 비밀 관리 구성
BabyAGI 에이전트는 OpenAI 및 Bright Data와 같은 타사 서비스에 연결됩니다. 이러한 연결은 외부 API 키를 사용하여 인증됩니다. main.py 파일에 API 키를 직접 하드코딩하는 것은 보안 문제로 이어질 수 있으므로 권장되지 않습니다. 대신 환경 변수에서 로드해야 합니다.
BabyAGI는 추가 의존성 없이 환경 변수나 로컬 .env 파일에서 시크릿을 읽을 수 있는 내장 메커니즘을 제공합니다. 이 기능을 사용하려면 프로젝트 디렉터리에 .env 파일을 추가하세요:
babyagi-bright-data-app/
├── .venv/
├── .env # <----
└── main.py.env 파일에 변수를 추가한 후 코드에서 다음과 같이 접근할 수 있습니다:
import os
ENV_VALUE = os.getenv("ENV_NAME")이것으로 끝입니다! 이제 스크립트가 하드코딩된 값 대신 환경 변수에서 제3자 통합 비밀 정보를 안전하게 불러옵니다.
대안으로 대시보드에서 직접 비밀을 설정할 수도 있습니다. 먼저 OpenAI API 키를 구성해야 합니다(다음 단계에서 다룹니다). 완료 후 대시보드의 “채팅” 페이지로 이동하세요. 함수 선택기에서 add_key_wrapper 함수를 선택하고 다음과 같은 메시지로 비밀을 정의하도록 프롬프트하세요:
ENV_NAME 시크릿을 정의하고 그 값을 ENV_VALUE로 설정하세요.프롬프트를 제출하면 다음과 유사한 결과를 확인할 수 있습니다:
보시다시피 시크릿이 성공적으로 생성되었습니다. get_all_secrets_keys 함수를 추가하여 호출함으로써 시크릿이 존재하는지 확인하세요.
4단계: BabyAGI를 OpenAI 모델에 연결하기
BabyAGI 대시보드의 “채팅” 페이지에서는 함수를 선택하고 대화형 인터페이스를 통해 호출할 수 있습니다: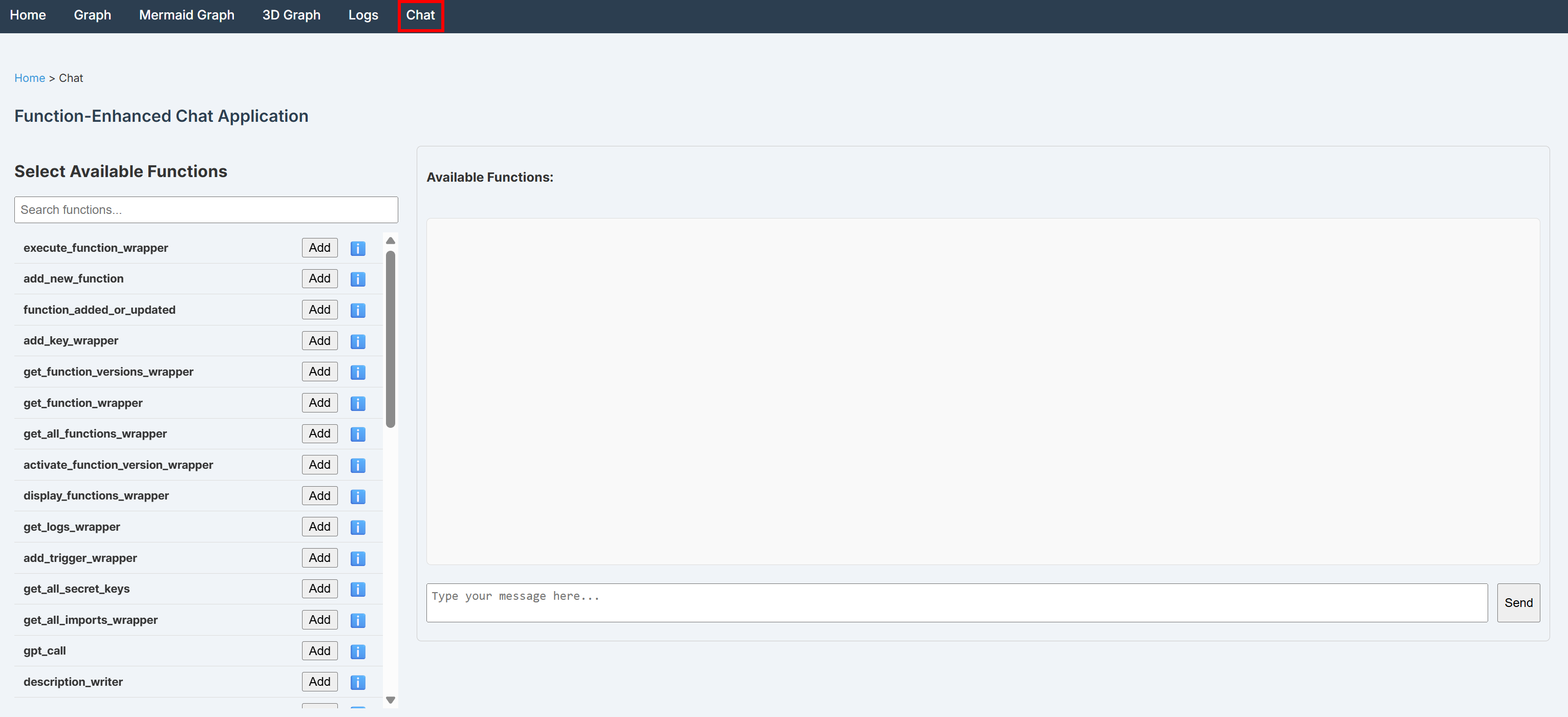
이 인터페이스는 OpenAI 통합을 통해 LiteLLM으로 백엔드 처리됩니다. 따라서 시크릿에 OpenAI API 키를 구성해야 합니다.
OPENAI_API_KEY 시크릿이 누락된 경우, 채팅 페이지를 통해 전송된 모든 메시지는 다음과 유사한 오류로 실패합니다:
{"error":"litellm.AuthenticationError: AuthenticationError: OpenAIException - The api_key client option must be set either by passing api_key to the client or by setting the OPENAI_API_KEY environment variable"}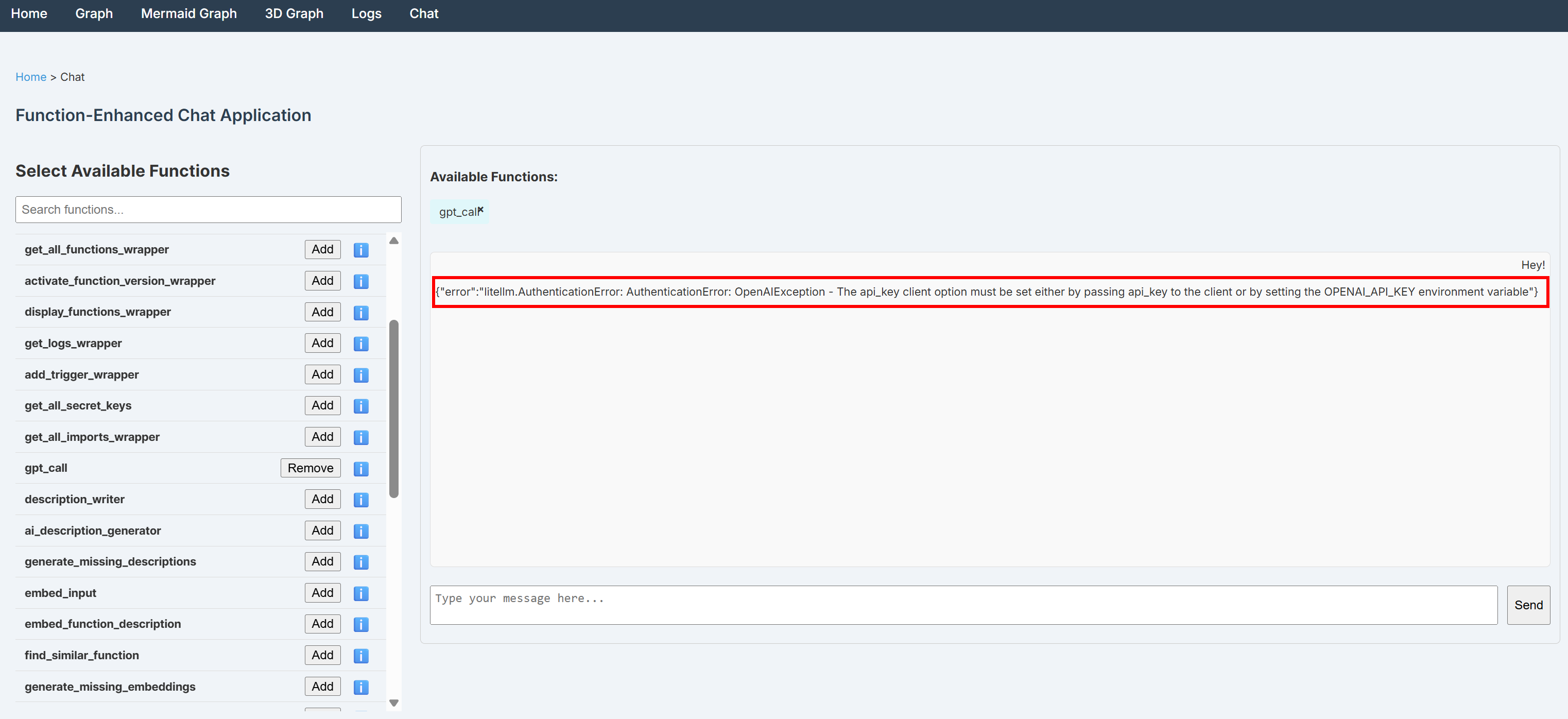
이를 해결하려면 .env 파일에 OPENAI_API_KEY 환경 변수를 추가하세요:
OPENAI_API_KEY="<YOUR_OPENAI_API_KEY>"파일을 저장한 후 BabyAGI를 재시작하세요. 통합이 정상 작동하는지 확인하려면 대시보드의 “채팅” 페이지를 다시 엽니다. 구성된 OpenAI 모델을 직접 호출하는 get_call 함수를 선택하고 “Hey!”와 같은 간단한 메시지를 전송하세요.
아래와 유사한 응답을 받아야 합니다: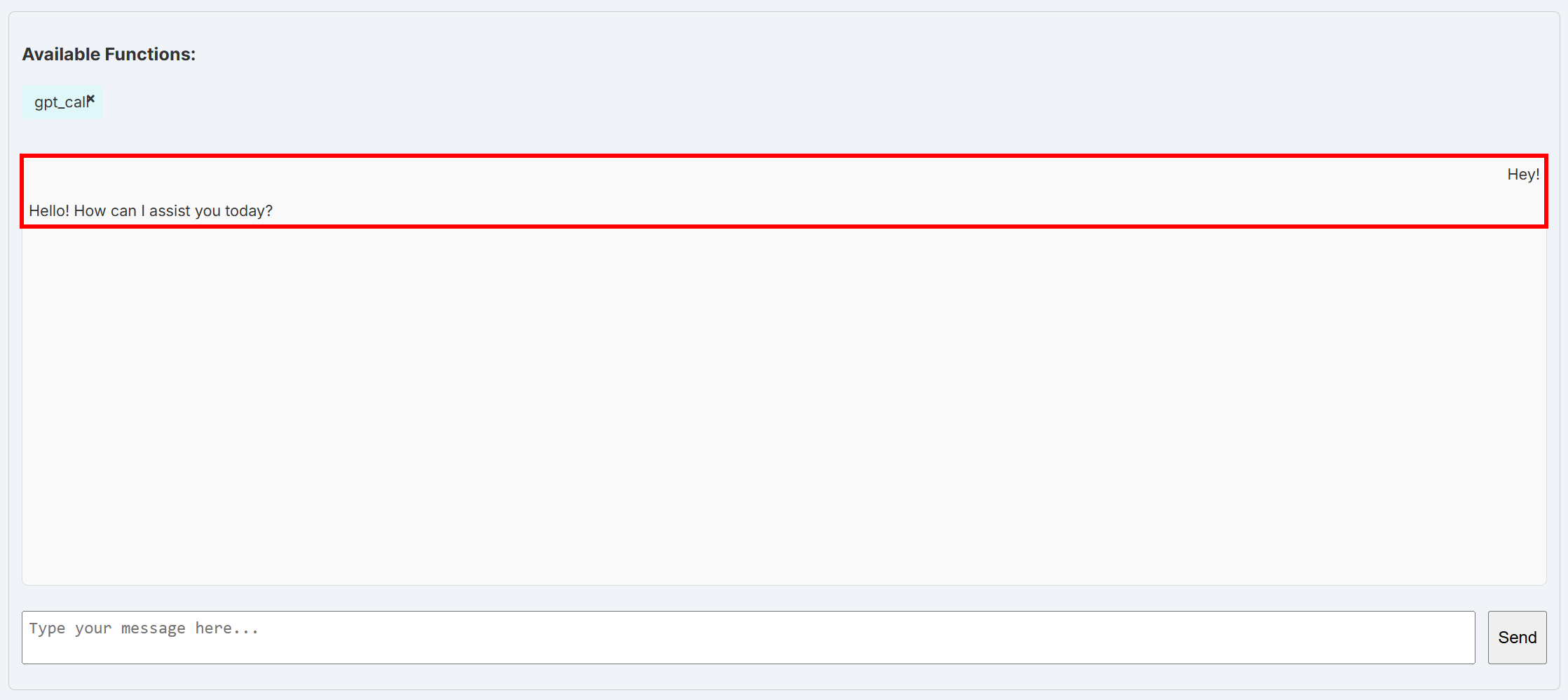
이 시점에서 기본 LiteLLM 레이어가 OpenAI 기본 모델에 성공적으로 연결됩니다. LiteLLM이 OPENAI_API_KEY 환경 변수에서 OpenAI API 키를 자동으로 읽어오기 때문에 작동합니다.
대단합니다! 이제 BabyAGI 애플리케이션이 OpenAI 모델에 정상적으로 연결되었습니다.
또는 코드에서 키를 직접 정의하여 동일한 결과를 얻을 수 있습니다:
babyagi.add_key_wrapper("openai_api_key", "<YOUR_OPENAI_API_KEY>")이는 add_key_wrapper 함수를 호출하는 것으로, 대시보드에서 이를 통해 키를 정의하는 것과 동일합니다. 다만 OpenAI 통합이 구성되기 전에는 대시보드 방식을 사용할 수 없다는 점에 유의하세요. 대시보드 자체도 작동하기 위해 OpenAI 연결에 의존하기 때문입니다.
5단계: Bright Data 시작하기
BabyAGI에서 SERP API 및 Web Unlocker 서비스를 이용하려면, SERP API 영역과 Web Unlocker API 영역이 모두 설정된 Bright Data 계정과 API 키가 필요합니다. 이제 모든 것을 설정해 보겠습니다!
Bright Data 계정이 없다면 새로 생성하세요. 이미 계정이 있다면 로그인 후 대시보드로 이동합니다. 그런 다음 “프록시 및 스크래핑(Proxies & Scraping)” 페이지로 이동하여 “내 영역(My Zones)” 테이블을 확인하세요:
테이블에 이미 Web Unlocker API 영역(이 예시에서는 unlocker)과 SERP API 영역(이 예시에서는 serp)이 존재한다면 바로 시작할 수 있습니다. 이 두 서비스는 사용자 정의 BabyAGI 함수를 통해 Web Unlocker 및 SERP API 서비스를 호출하는 데 사용됩니다.
이 중 하나 또는 둘 다 누락된 경우 생성해야 합니다. “Unblocker API” 및 “SERP API” 카드까지 아래로 스크롤한 후 “존 생성” 버튼을 클릭하세요. 마법사를 따라 두 존을 모두 추가하십시오: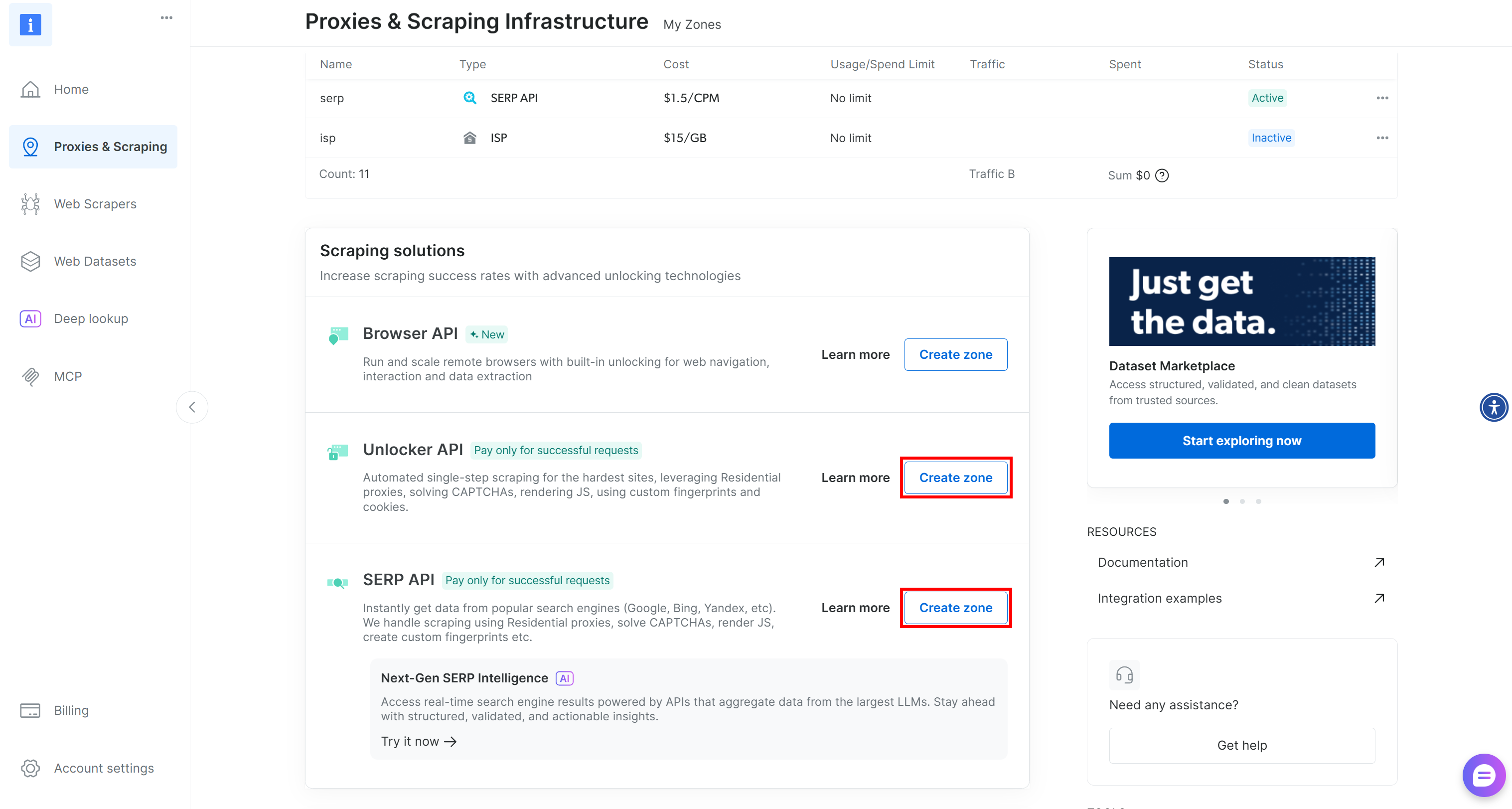
단계별 안내는 다음 문서 페이지를 참조하세요:
다음으로, Web Unlocker API 및 SERP API 영역 이름을 다음과 같이 .env 파일에 추가하세요:
SERP_API_ZONE="serp"
WEB_UNLOCKER_ZONE="unlocker"중요: 본 예시에서는 SERP API 영역명을 "serp", 웹 언락커 API 영역명을 "unlocker"로 가정합니다. 실제 사용 중인 영역명과 다를 경우 해당 값으로 교체하십시오.
마지막으로 Bright Data API 키를 생성하고 .env 파일의 환경 변수로 저장해야 합니다:
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"이 세 가지 환경 변수는 사용자 정의 BabyAGI 함수에서 읽혀 Bright Data 계정의 SERP API 및 Web Unlocker API 서비스에 연결하는 데 사용됩니다. 이제 BabyAGI에서 이를 정의하고 사용할 준비가 되었습니다!
6단계: SERP API 함수 정의
Bright Data SERP API를 사용하여 웹 검색을 수행하는 BabyAGI 함수를 정의하는 것으로 시작합니다:
@babyagi.register_function(
imports=["os", "urllib", "requests"],
key_dependencies=["bright_data_api_key", "serp_api_zone"],
metadata={"description": "Bright Data의 SERP API를 사용하여 주어진 쿼리로 웹 검색을 수행합니다."}
)
def bright_data_serp_api(query: str) -> str:
import requests
import os
import urllib
# 환경 변수에서 Bright Data API 키 읽기
BRIGHT_DATA_API_TOKEN = os.getenv("bright_data_api_key")
# Bright Data SERP API에 요청 전송
url = "https://api.brightdata.com/request"
data = {
"zone": os.getenv("serp_api_zone"),
"url": f"https://www.google.com/search?q={urllib.parse.quote_plus(query)}&brd_json=1",
"format": "raw"
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_TOKEN}",
"Content-Type": "application/json"
}
response = requests.post(url, json=data, headers=headers)
response.raise_for_status()
return response.text해당 함수는 Requests HTTP 클라이언트를 활용하여 SERP API 영역에 POST HTTP 요청을 수행합니다. 구체적으로 Google에 쿼리를 전송하고 Bright Data를 통해 파싱된 SERP 결과를 가져옵니다. 자세한 내용은 Bright Data SERP API 문서를 참조하세요.
BabyAGI 함수는 @babyagi.register_function 데코레이터를 사용하여 등록해야 합니다. 이 데코레이터는 다음 필드를 허용합니다:
imports: 함수가 의존하는 외부 라이브러리 목록입니다. BabyAGI 함수는 격리된 환경에서 실행되므로 이 목록이 필요합니다.dependencies: 이 함수가 의존하는 다른 BabyAGI 함수 목록입니다.key_dependencies: 함수 실행에 필요한 비밀 키 목록입니다. 이 경우 필요한 비밀 키는"bright_data_api_key"와"serp_api_zone"이며, 이는.env파일에서 앞서 정의한BRIGHT_DATA_API_KEY및SERP_API_ZONE환경 변수에 해당합니다.metadata["description"]: 함수의 기능을 사람이 읽을 수 있는 형태로 설명합니다. 이는 OpenAI 모델이 함수의 목적을 이해하는 데 도움이 됩니다.
훌륭합니다! 이제 BabyAGI 애플리케이션에 bright_data_serp_api 함수가 포함되어 Bright Data SERP API를 통해 웹 검색을 수행할 수 있습니다.
7단계: Web Unlocker API 함수 정의
마찬가지로 Web Unlocker API를 호출하는 사용자 정의 함수를 정의합니다:
@babyagi.register_function(
imports=["os", "requests"],
key_dependencies=["bright_data_api_key", "web_unlocker_zone"],
metadata={"description": "Bright Data Web Unlocker API를 통해 웹 페이지 콘텐츠를 가져옵니다."}
)
def bright_data_web_unlocker(page_url: str, data_format: str = "markdown") -> str:
import requests
import os
# 환경 변수에서 Bright Data API 키 읽기
BRIGHT_DATA_API_TOKEN = os.getenv("bright_data_api_key")
# Bright Data Web Unlocker API에 요청 전송
url = "https://api.brightdata.com/request"
data = {
"zone": os.getenv("web_unlocker_zone"),
"url": page_url,
"format": "raw",
"data_format": data_format
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_TOKEN}",
"Content-Type": "application/json"
}
response = requests.post(url, json=data, headers=headers)
response.raise_for_status()
return response.text이 함수는 bright_data_serp_api 함수와 동일하게 작동하며, 주요 차이점은 Web Unlocker API를 호출한다는 점입니다. 해당 API의 사용 가능한 매개변수 및 옵션에 대한 자세한 내용은 Bright Data 문서를 참조하십시오.
이 함수는 5단계에서 정의한 WEB_UNLOCKER_ZONE 환경 변수에 해당하는 web_unlocker_zone 시크릿에 의존합니다. 또한 data_format 인수는 자동으로 markdown으로 설정됩니다. 이는 특수한 “Scrape as Markdown” 기능을 활성화하여 특정 웹 페이지에서 스크랩한 콘텐츠를 LLM 입력에 이상적인 최적화된 마크다운 형식으로 반환합니다.
팁: 유사한 설정을 통해 BabyAGI를 확장하여 웹 스크래핑 API 등 다른 API 기반 Bright Data 솔루션을 통합할 수 있습니다.
미션 완료! 원하는 Bright Data 기반 기능이 BabyAGI에 추가되었습니다.
8단계: 전체 코드
main.py 파일의 최종 코드는 다음과 같습니다:
import babyagi
@babyagi.register_function(
imports=["os", "urllib", "requests"],
key_dependencies=["bright_data_api_key", "serp_api_zone"],
metadata={"description": "Bright Data의 SERP API를 사용하여 주어진 쿼리에 대한 웹 검색을 수행합니다."}
)
def bright_data_serp_api(query: str) -> str:
import requests
import os
import urllib
# 환경 변수에서 Bright Data API 키 읽기
BRIGHT_DATA_API_TOKEN = os.getenv("bright_data_api_key")
# Bright Data SERP API에 요청 전송
url = "https://api.brightdata.com/request"
data = {
"zone": os.getenv("serp_api_zone"),
"url": f"https://www.google.com/search?q={urllib.parse.quote_plus(query)}&brd_json=1",
"format": "raw"
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_TOKEN}",
"Content-Type": "application/json"
}
response = requests.post(url, json=data, headers=headers)
response.raise_for_status()
return response.text
@babyagi.register_function(
imports=["os", "requests"],
key_dependencies=["bright_data_api_key", "web_unlocker_zone"],
metadata={"description": "Bright Data Web Unlocker API를 통해 웹 페이지 콘텐츠를 가져옵니다."}
)
def bright_data_web_unlocker(page_url: str, data_format: str = "markdown") -> str:
import requests
import os
# 환경 변수에서 Bright Data API 키 읽기
BRIGHT_DATA_API_TOKEN = os.getenv("bright_data_api_key")
# Bright Data Web Unlocker API에 요청 전송
url = "https://api.brightdata.com/request"
data = {
"zone": os.getenv("web_unlocker_zone"),
"url": page_url,
"format": "raw",
"data_format": data_format
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_TOKEN}",
"Content-Type": "application/json"
}
response = requests.post(url, json=data, headers=headers)
response.raise_for_status()
return response.text
if __name__ == "__main__":
app = babyagi.create_app("/dashboard")
app.run(host="0.0.0.0", port=8080)대신 .env 파일에는 다음 내용이 포함됩니다:
OPENAI_API_KEY="<YOUR_OPENAI_API_KEY>"
SERP_API_ZONE="<YOUR_SERP_API_ZONE_NAME>"
WEB_UNLOCKER_ZONE="<YOUR_WEB_UNLOCKER_ZONE_NAME>"
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"다음 명령어로 BabyAGI 대시보드를 실행하세요:
python main.py브라우저에서 http://localhost:8080/dashboard을 열고 “채팅” 페이지로 이동한 후 “bright_data”를 검색하세요. Bright Data 통합을 위해 코드에 정의된 두 함수를 확인할 수 있습니다: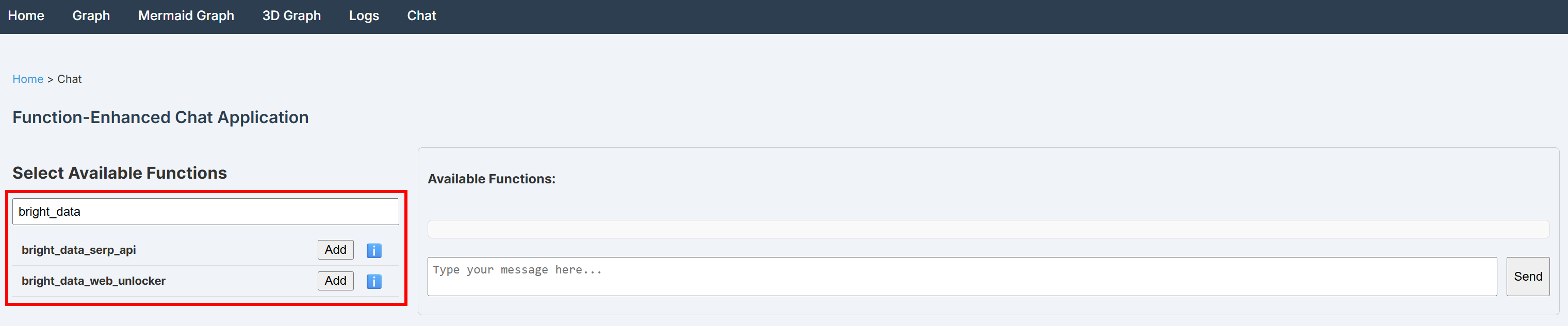
멋지네요! 두 개의 사용자 정의 함수가 올바르게 등록되었습니다.
9단계: BabyAGI + Bright Data 통합 테스트
기본 제공되는 chat_with_functions 함수를 사용하여 Bright Data 함수를 테스트함으로써 BabyAGI 애플리케이션이 정상 작동하는지 확인하세요. 이 기능은 LiteLLM과 연결된 채팅 상호작용을 시작하고 함수 데이터베이스에서 선택한 함수를 실행합니다.
따라서 먼저 bright_data_serp_api 및 bright_data_web_unlocker 함수를 선택하세요. 그런 다음 chat_with_functions를 선택합니다:
다음으로 웹 검색과 데이터 추출을 모두 트리거하는 프롬프트를 사용해야 합니다. 예를 들어 다음과 같이 시도해 보세요:
웹에서 최신 Google AI 발표(2025년)를 검색하고, 신뢰할 수 있는 상위 3개 뉴스 또는 블로그 기사를 선택한 후 각각에 접근하여 Google AI의 미래에 대한 핵심 통찰력을 요약하세요(출처 기사의 URL을 언급하며).참고: 웹 접근을 위한 외부 도구 없이 기본 LLM만으로는 이 작업을 완료할 수 없습니다.
채팅창에서 프롬프트를 실행하면 다음과 유사한 출력이 표시됩니다: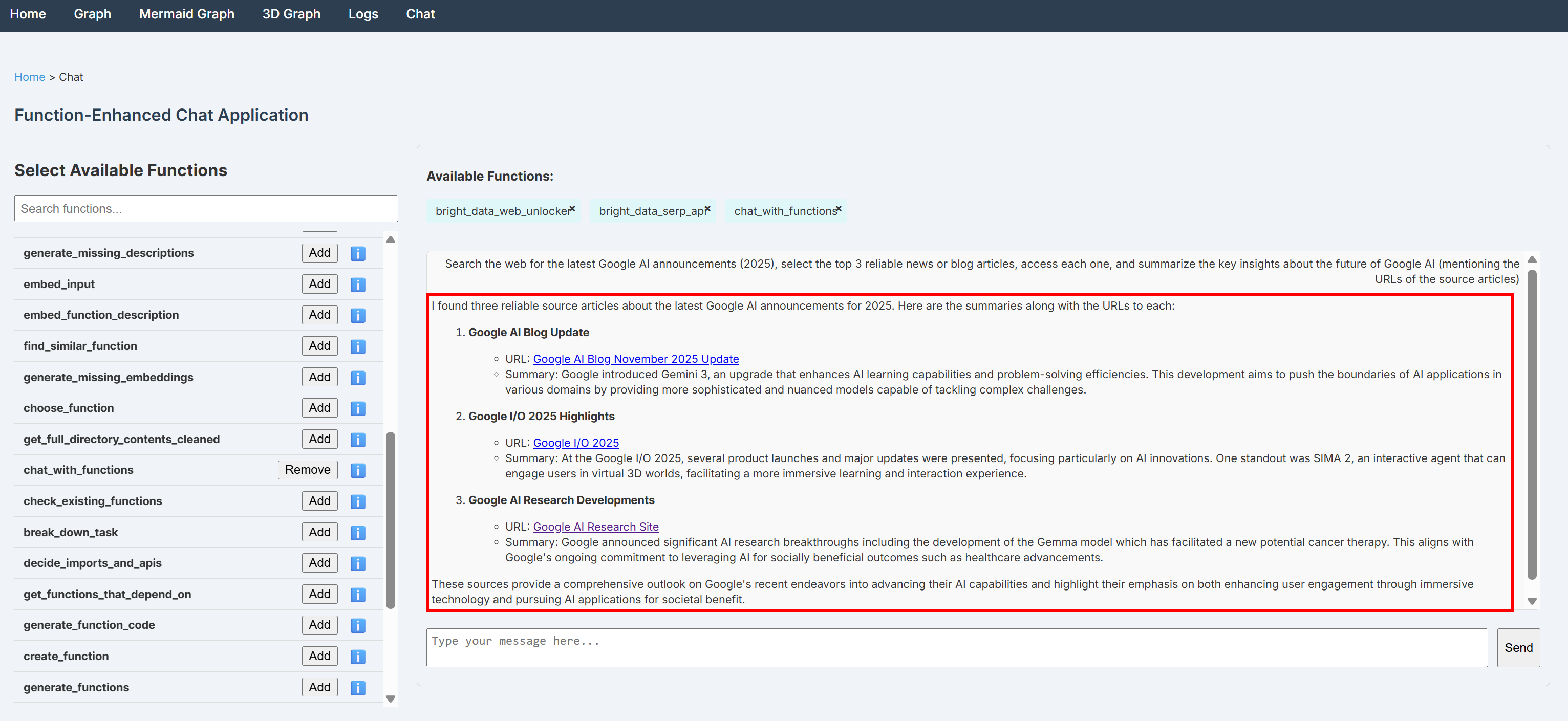
출력 결과에는 SERP API를 통해 구글 검색을 수행하고 Web Unlocker API로 선택된 뉴스 페이지의 정보를 스크래핑하여 확보한 근거 기반 통찰이 포함된다는 점을 확인하세요.
이제 에이전트가 현재 웹 콘텐츠와 상호작용하고 학습할 수 있음을 확인했으므로, 이는 에이전트가 초기에는 알지 못했던 기술적 세부사항을 학습하기 위해 다른 서비스의 문서를 접근하여 상호작용할 수 있는 기능을 자체 구축할 수 있는 능력을 갖췄음을 의미합니다. BabyAGI 문서에 설명된 대로 자체 AI 에이전트 구축을 위한 self_build 기능을 통해 이를 테스트해 보세요.
다양한 입력 프롬프트와 다른 BabyAGI 기능을 자유롭게 실험해 보세요. Bright Data 기능 덕분에 BabyAGI 자체 구축 에이전트는 다양한 실제 사용 사례를 처리할 수 있습니다.
자, 이제 Bright Data와 BabyAGI의 결합이 가진 힘을 경험하셨습니다.
결론
이 블로그 게시물에서는 SERP API 및 Web Unlocker API를 호출하는 사용자 지정 기능을 통해 BabyAGI에서 Bright Data 기능을 활성화하는 방법을 살펴보았습니다.
이를 통해 모든 웹 페이지에서 콘텐츠를 검색하고 실시간 웹 검색을 수행할 수 있습니다. 라이브 웹 피드에 액세스하고 웹 상호 작용을 자동화하는 등 기능을 더욱 확장하려면 BabyAGI를 Bright Data의 AI 서비스 전체 제품군과 통합하세요.
자동 구축 AI 에이전트의 모든 잠재력을 발휘하세요!
지금 바로 Bright Data 계정을 무료로 등록하고 AI 지원 웹 데이터 솔루션을 실험해 보세요!




