
이 가이드에서는 다음을 배우게 됩니다:
- RAG(Retrieval-Augmented Generation)란 무엇이며, 행위자적 기능 추가가 중요한 이유
- – Bright Data가 RAG 시스템을 위한 자율적 실시간 웹 데이터 검색을 어떻게 지원하는지
- 임베딩 생성을 위한 웹 스크래핑 데이터 처리 및 정제 방법
- 벡터 검색과 LLM 텍스트 생성을 조정하는 에이전트 컨트롤러 구현 방법
- 사용자 입력을 포착하고 검색 및 생성을 동적으로 최적화하기 위한 피드백 루프 설계
자, 시작해 보겠습니다!
인공지능(AI)의 부상은 에이전트 기반 RAG를 포함한 새로운 개념을 도입했습니다. 간단히 말해, 에이전트 기반 RAG는 AI 에이전트를 통합한 검색 강화 생성(RAG)입니다 . 이름에서 알 수 있듯이, RAG는 선형 프로세스를 따르는 정보 검색 시스템입니다: 쿼리를 수신하고, 관련 정보를 검색하며, 응답을 생성합니다.
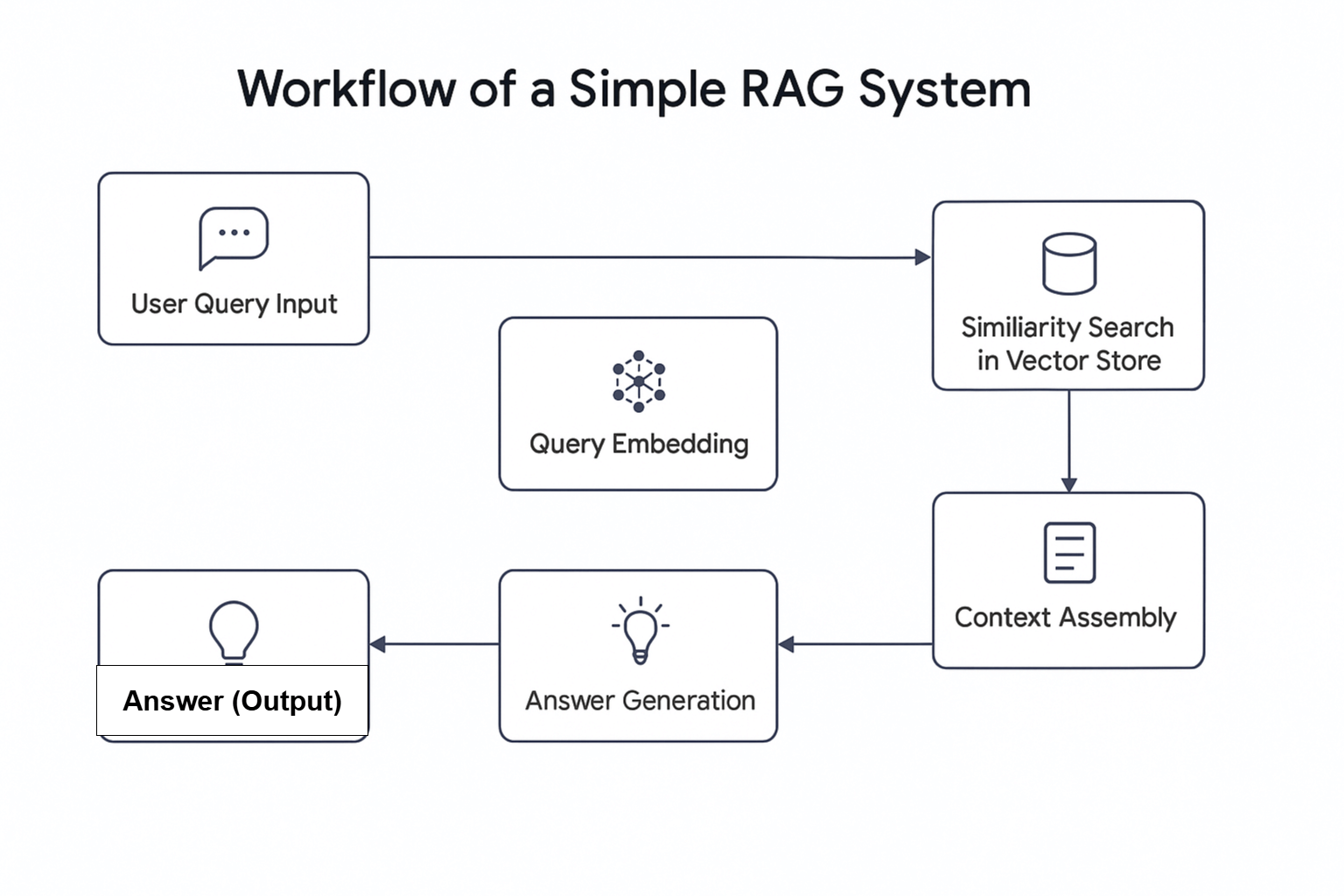
왜 AI 에이전트를 RAG와 결합할까요?
최근 설문조사에 따르면 AI 에이전트를 사용하는 워크플로우의 약 3분의 2가 생산성 향상을 보고했습니다. 또한 약 60%가 비용 절감을 보고했습니다. 이는 AI 에이전트와 RAG의 결합이 현대 검색 워크플로우에 잠재적인 게임 체인저가 될 수 있음을 시사합니다.
에이전트형 RAG는 고급 기능을 제공합니다. 기존 RAG 시스템과 달리 데이터 검색뿐만 아니라 데이터베이스에 내장된 실시간 웹 데이터 등 외부 소스에서 정보를 가져올지 여부를 결정할 수 있습니다.
본 글에서는 웹 데이터 수집을 위한 Bright Data, 벡터 데이터베이스로 Pinecone, 텍스트 생성을 위한 OpenAI, 에이전트 컨트롤러로 Agno를 활용해 뉴스 정보를 검색하는 에이전틱 RAG 시스템 구축 방법을 설명합니다.
Bright Data 개요
실시간 데이터 스트림에서 소싱하든 데이터베이스의 준비된 데이터를 사용하든, 에이전틱 RAG 시스템의 출력 품질은 입력 데이터의 품질에 달려 있습니다. 바로 여기서 Bright Data가 필수적입니다.
Bright Data는 다양한 사용 사례에 신뢰할 수 있고 구조화되며 최신 웹 데이터를 제공합니다. 120개 이상의 도메인에 접근 가능한 Bright Data의 웹 스크레이퍼 API를 통해 웹 스크래핑이 그 어느 때보다 효율적으로 수행됩니다. IP 차단, CAPTCHA, 쿠키, 기타 봇 탐지 방식 등 일반적인 스크래핑 문제를 처리합니다.
시작하려면 무료 체험판에 가입한 후 스크래핑하려는 도메인의 API 키와 dataset_id를 획득하세요. 이 정보만 있으면 바로 시작할 수 있습니다.
BBC 뉴스와 같은 인기 도메인에서 최신 데이터를 가져오는 단계는 다음과 같습니다:
- 아직 계정이 없다면 Bright Data 계정을 생성하세요. 무료 체험판이 제공됩니다.
- 웹 스크레이퍼 페이지로 이동하세요. 웹 스크레이퍼 라이브러리에서 사용 가능한 스크레이퍼 템플릿을 살펴보세요.
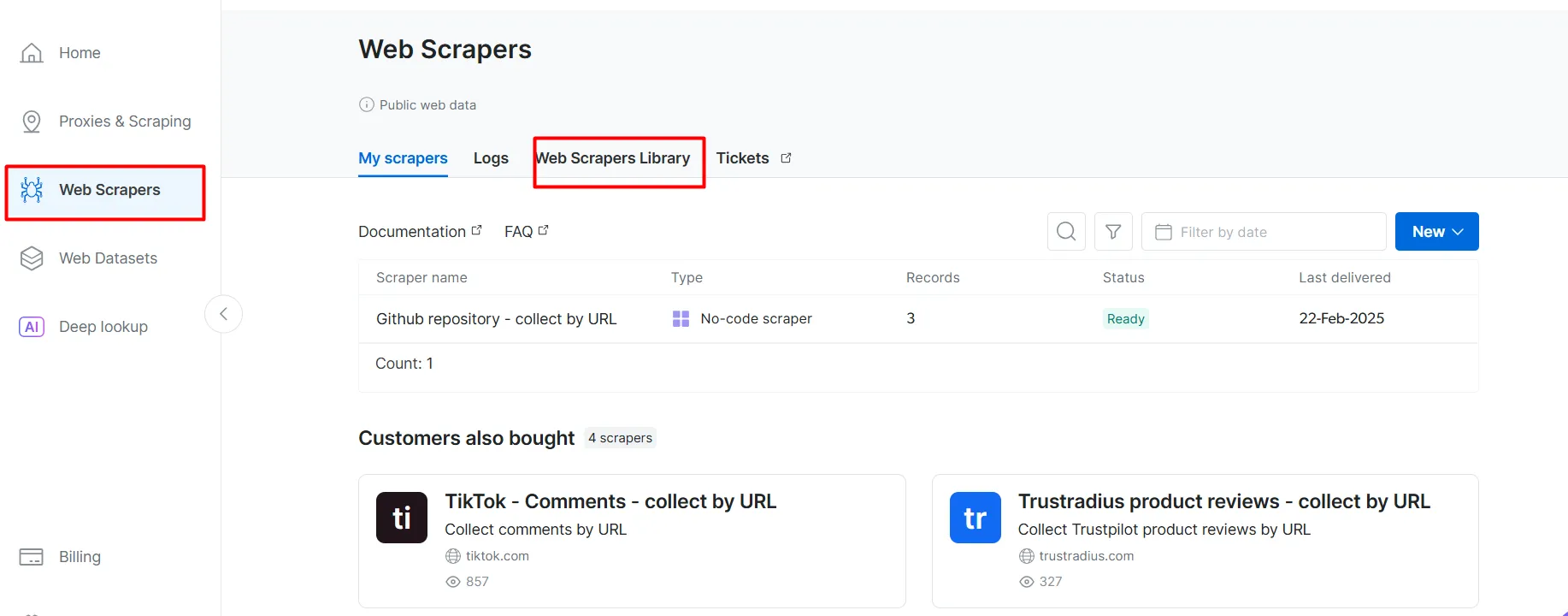
- BBC 뉴스와 같은 대상 도메인을 검색하여 선택하세요.
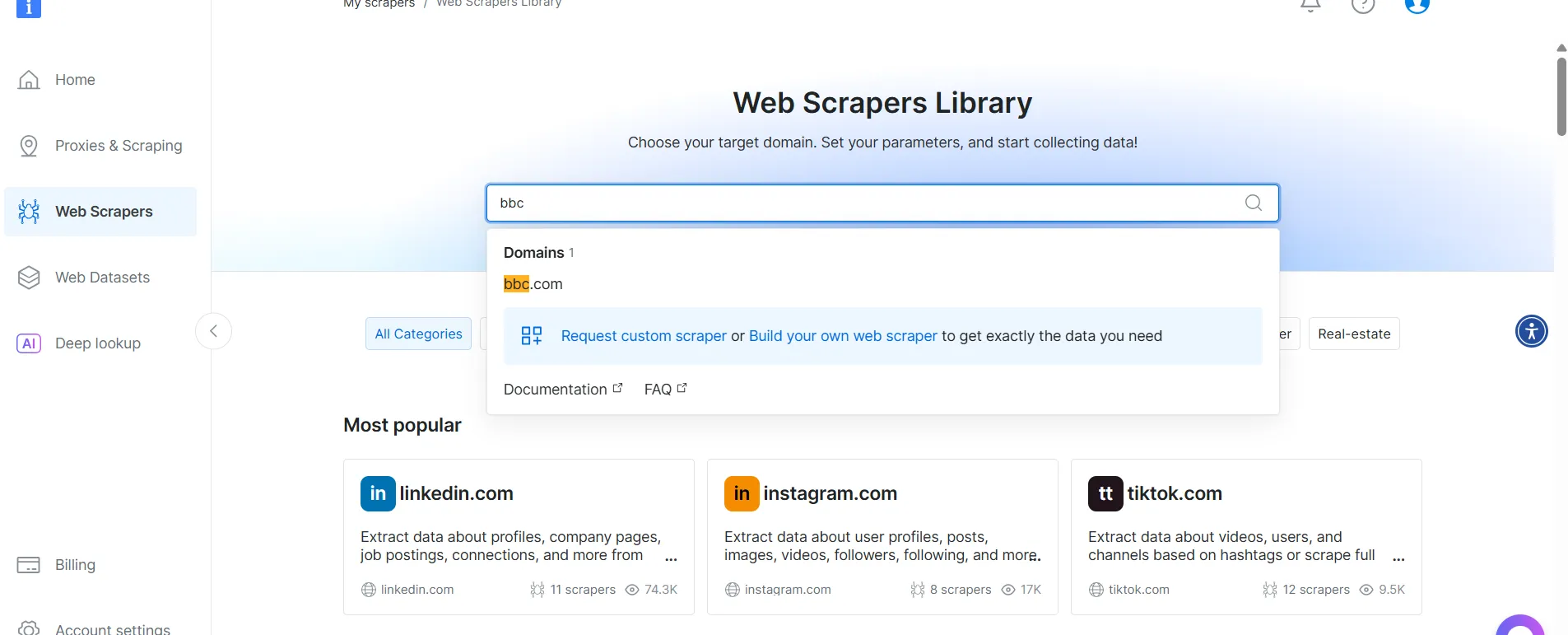
- BBC 뉴스 스크레이퍼 목록에서 ‘BBC 뉴스 — URL로 수집’을 선택하세요. 이 스크레이퍼는 도메인에 로그인하지 않고도 데이터를 가져올 수 있게 해줍니다.
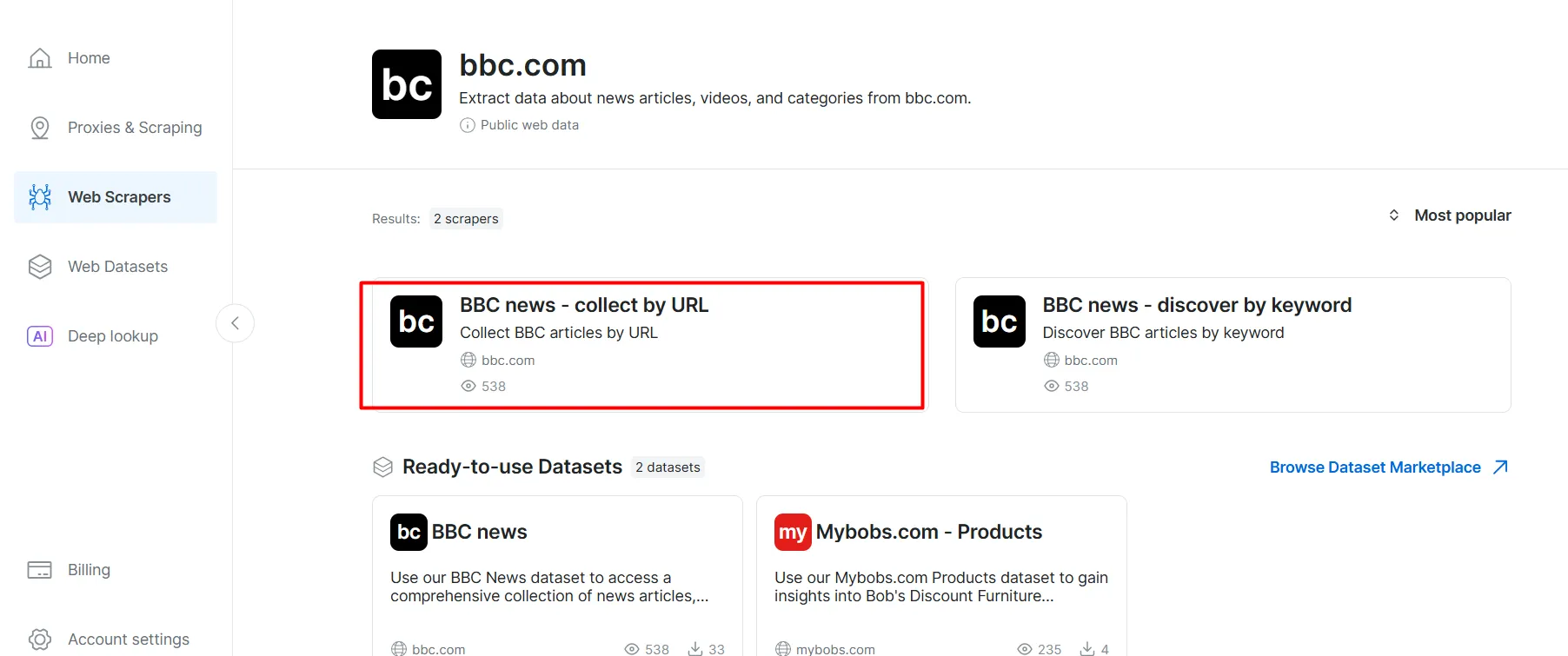
- 스크레이퍼 API 옵션을 선택하세요. 노코드 스크레이퍼는 코드 없이 데이터셋을 가져오는 데 도움이 됩니다.
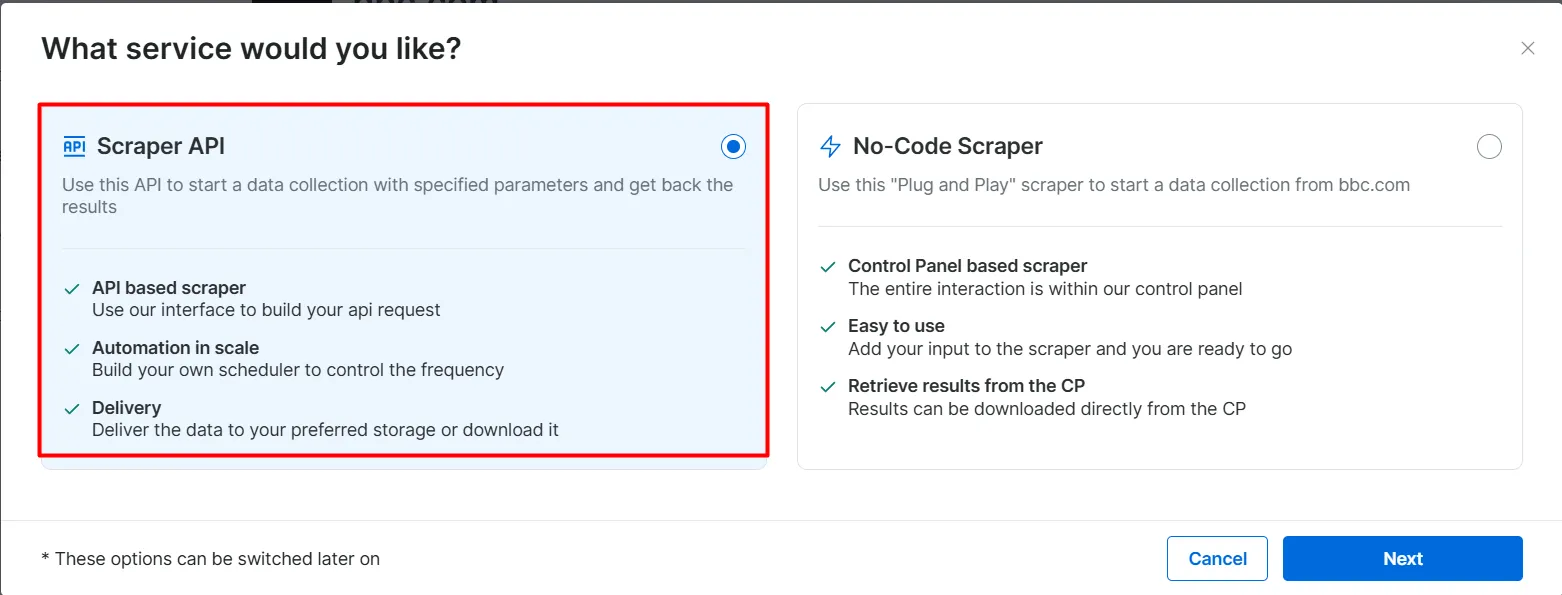
- API 요청 빌더를 클릭한 후
API 키,BBC 데이터셋 URL,dataset_id를복사하세요. 다음 섹션에서 Agentic RAG 워크플로우를 구축할 때 이 정보가 필요합니다.
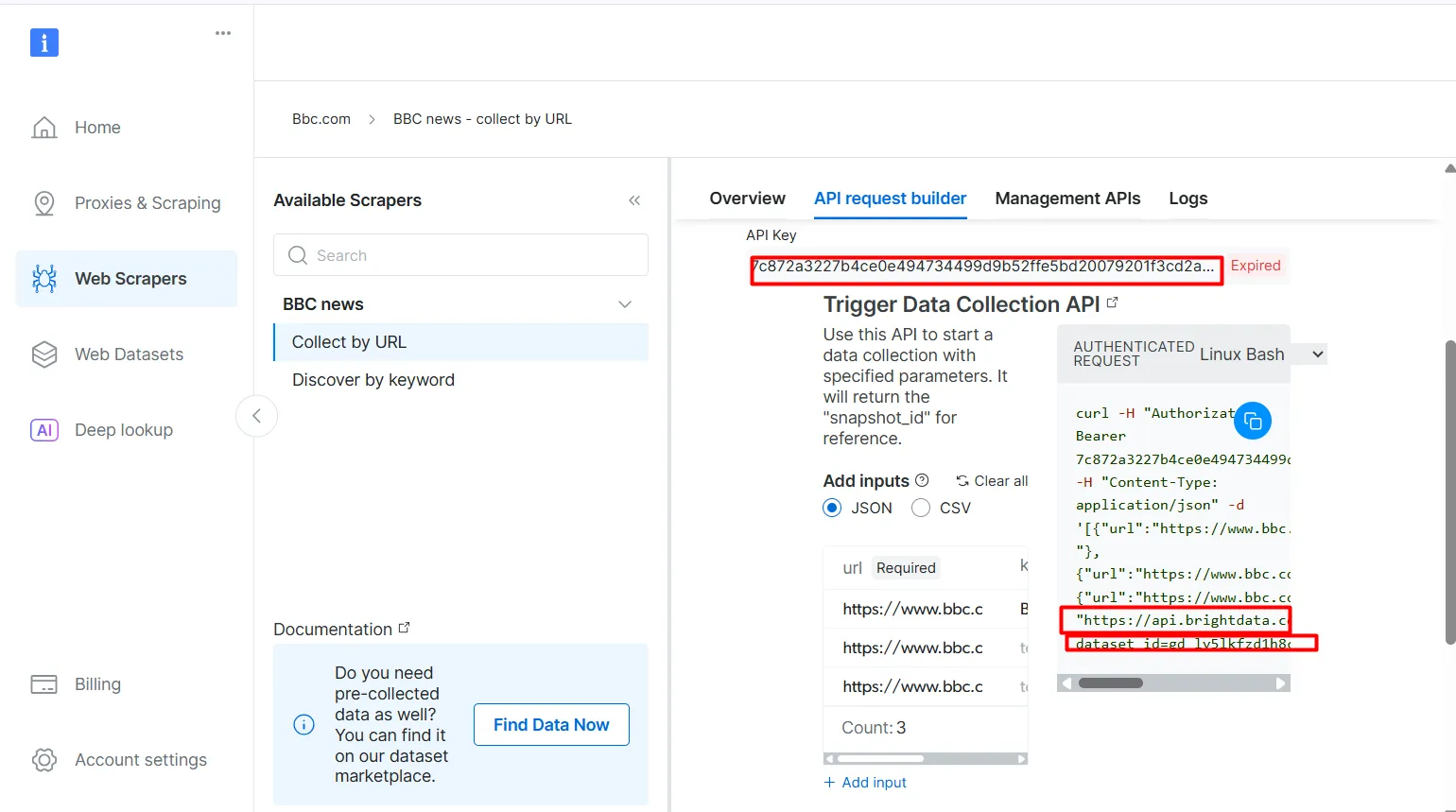
API 키와 dataset_id는 워크플로우에서 에이전틱 기능을 활성화하는 데 필수적입니다. 이를 통해 벡터 데이터베이스에 실시간 데이터를 임베드하고, 검색 쿼리가 사전 색인된 콘텐츠와 직접 일치하지 않더라도 실시간 쿼리를 지원할 수 있습니다.
필수 조건
시작하기 전에 다음을 준비하세요:
- Bright Data 계정
- OpenAI API 키 OpenAI 에 가입하여 API 키를 획득하세요:
- Pinecone API 키 Pinecone 문서의 ‘API 키 받기’ 섹션 지침을 따르세요.
- 파이썬에 대한 기본적인 이해 공식 웹사이트에서 파이썬을 설치할 수 있습니다
- RAG 및 에이전트 개념에 대한 기본적인 이해
에이전트형 RAG 구조
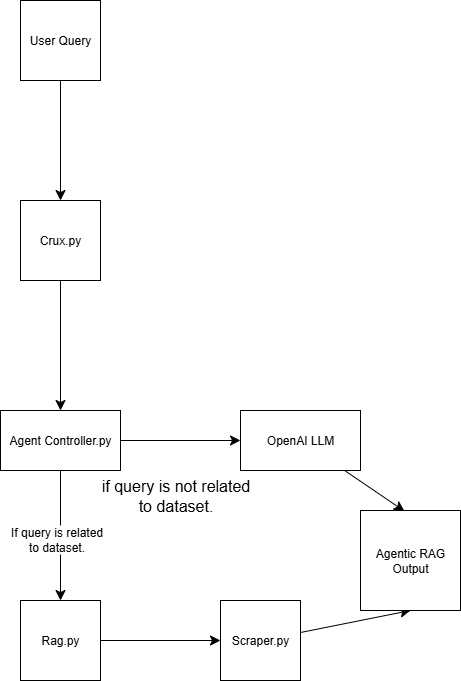
이 에이전틱 RAG 시스템은 네 개의 스크립트로 구성됩니다:
scraper.py: Bright Data를 통해 웹 데이터 수집
rag.py 데이터를 벡터 데이터베이스 (Pinecone)에 임베딩합니다. 참고: 벡터(수치 임베딩) 데이터베이스는 일반적으로 머신러닝 모델에서 생성되는 비정형 데이터를 저장하기 위해 사용됩니다. 이 형식은 검색 작업에서 유사도 검색에 이상적입니다.
agent_controller.py 제어 로직을 포함합니다. 쿼리의 특성에 따라 벡터 데이터베이스의 전처리된 데이터를 사용할지, GPT의 일반 지식을 활용할지 결정합니다.
crux.py Agentic RAG 시스템의 핵심 역할을 수행합니다. API 키를 저장하고 워크플로를 초기화합니다.
데모 종료 시점의 에이전틱 RAG 구조는 다음과 같습니다:
Bright Data를 활용한 Agentic RAG 구축
1단계: 프로젝트 설정
1.1 새 프로젝트 디렉터리 생성
프로젝트용 폴더를 생성하고 해당 폴더로 이동합니다:
mkdir agentic-rag
cd agentic-rag
1.2 Visual Studio Code에서 프로젝트 열기
Visual Studio Code를 실행하고 새로 생성한 디렉터리를 엽니다:
.../Desktop/agentic-rag> code .
1.3 가상 환경 설정 및 활성화
가상 환경을 설정하려면 다음을 실행하세요:
python -m venv venv
또는 Visual Studio Code에서 Python 환경 가이드의 안내에 따라 가상 환경을 생성하세요.
환경 활성화 방법:
- Windows:
.venv\Scripts\activate - macOS 또는 Linux:
source venv/bin/activate
2단계: Bright Data Retriever 구현
2.1 scraper.py 파일에 requests 라이브러리 설치
pip install requests
2.2 다음 모듈을 임포트합니다.
import requests
import json
import time
2.3 자격 증명 설정
이전에 복사한 Bright Data API 키, 데이터셋 URL 및 dataset_id를 사용하세요.
def trigger_bbc_news_articles_scraping(api_key, urls):
# 웹 스크레이퍼 API 작업을 트리거하는 엔드포인트
url = "<https://api.brightdata.com/datasets/v3/trigger>"
params = {
"dataset_id": "gd_ly5lkfzd1h8c85feyh", # BBC 웹 스크레이퍼 ID
"include_errors": "true",
}
# API 호출을 위해 입력 데이터를 원하는 형식으로 변환
data = [{"url": url} for url in urls]
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
}
2.4 응답 로직 설정
스크래핑할 페이지의 URL로 요청을 채우세요. 이 경우 스포츠 관련 기사에 집중합니다.
response = requests.post(url, headers=headers, params=params, json=data)
if response.status_code == 200:
snapshot_id = response.json()["snapshot_id"]
print(f"요청 성공! 응답: {snapshot_id}")
return response.json()["snapshot_id"]
else:
print(f"요청 실패! 오류: {response.status_code}")
print(response.text)
def poll_and_retrieve_snapshot(api_key, snapshot_id, output_file, polling_timeout=20):
snapshot_url = f"<https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json>"
headers = {
"Authorization": f"Bearer {api_key}"
}
print(f"ID: {snapshot_id}에 대한 스냅샷 폴링 중...")
while True:
response = requests.get(snapshot_url, headers=headers)
if response.status_code == 200:
print("스냅샷 준비 완료. 다운로드 중...")
snapshot_data = response.json()
# 스냅샷을 출력 JSON 파일에 기록
with open(output_file, "w", encoding="utf-8") as file:
json.dump(snapshot_data, file, indent=4)
print(f"스냅샷이 {output_file}에 저장되었습니다")
return
elif response.status_code == 202:
print(F"스냅샷이 아직 준비되지 않았습니다. {polling_timeout} 초 후에 재시도 중...")
time.sleep(polling_timeout)
else:
print(f"요청 실패! 오류: {response.status_code}")
print(response.text)
break
if __name__ == "__main__":
BRIGHT_DATA_API_KEY = "BRIGHT DATA KEY" # Bright Data의 웹 스크레이퍼 API 키로 교체하세요
# 데이터를 가져올 BBC 기사 URL
urls = [
"<https://www.bbc.com/sport/formula1/articles/c9dj0elnexyo>",
"<https://www.bbc.com/sport/formula1/articles/cgenqvv9309o>",
"<https://www.bbc.com/sport/formula1/articles/c78jng0q2dxo>",
"<https://www.bbc.com/sport/formula1/articles/cdrgdm4ye53o>",
"<https://www.bbc.com/sport/formula1/articles/czed4jk7eeeo>",
"<https://www.bbc.com/sport/football/articles/c807p94r41do>",
"<https://www.bbc.com/sport/football/articles/crgglxwge10o>",
"<https://www.bbc.com/sport/tennis/articles/cy700xne614o>",
"<https://www.bbc.com/sport/tennis/articles/c787dk9923ro>",
"<https://www.bbc.com/sport/golf/articles/ce3vjjq4dqzo>"
]
snapshot_id = trigger_bbc_news_articles_scraping(BRIGHT_DATA_API_KEY, urls)
poll_and_retrieve_snapshot(BRIGHT_DATA_API_KEY, snapshot_id, "news-data.json")
2.5 코드 실행
스크립트를 실행하면 프로젝트 폴더에 news-data.json이라는 파일이 생성됩니다. 이 파일에는 구조화된 JSON 형식으로 스크랩된 기사 데이터가 포함되어 있습니다.
JSON 파일 내부의 내용 예시는 다음과 같습니다:
[
{
"id": "c9dj0elnexyo",
"url": "<https://www.bbc.com/sport/formula1/articles/c9dj0elnexyo>",
"author": "BBC",
"headline": "맥스 페르스타펜: 레드불 고문 헬무트 마르코, 팀 내 챔피언의 미래에 '큰 우려' 표명",
"topics": [
"포뮬러 1"
],
"publication_date": "2026-04-14T13:42:08.154Z",
"content": "사우디 아라비아 그랑프리장소: 제다일정: 4월 18-20일레이스 시작: 일요일 18:00 BST방송: 연습주행, 예선, 레이스 생중계 라디오 해설 (온라인 및 BBC 5 Sports Extra); BBC 스포츠 웹사이트 및 앱 실시간 텍스트 업데이트; 레드불 모터스포츠 고문 헬무트 마르코는 팀의 현재 부진 속에서 맥스 페르스타펜의 팀 내 미래에 대해 "큰 우려"를 표명했다.광고 4회 챔피언인 베르스타펜은 일요일 바레인 그랑프리에서 6위를 기록했으며, 오스카 피아스트리는 올해 현재까지 4경기 중 3번째 우승을 맥라렌에 안겼다. 네덜란드인 베르스타펜은 드라이버 챔피언십 3위로, 선두 맥라렌의 랜도 노리스에 8점 뒤처져 있다. 마르코는 스카이 독일과의 인터뷰에서 "우려가 크다. 가까운 시일 내에 개선이 이뤄져 그가 다시 우승할 수 있는 차를 갖춰야 한다"고 말했다."우리는 그가 세계 챔피언십을 위해 싸울 수 있는 차를 기반으로 만들어야 합니다." 페르스타펜은 2028년까지 레드불과 계약을 맺고 있다. 하지만 마르코는 이번 달 BBC 스포츠와의 인터뷰에서 계약에 팀을 떠날 수 있는 성과 조항이 포함되어 있다고 밝혔다. 이 조항의 구체적인 문구는 공개되지 않았지만, 사실상 레드불이 페르스타펜에게 우승할 수 있는 차를 제공해야 한다는 내용을 담고 있다.베르스타펜은 바레인 그랑프리 일주일 전 일본 그랑프리에서 우승했으나, 이 승리는 많은 F1 전문가들이 역대 최고 중 하나로 꼽는 폴 포지션 랩을 바탕으로 한 것이었다. 스즈카 서킷에서는 추월이 거의 불가능했기 때문에 베르스타펜은 맥라렌의 노리스와 피아스트리를 막아내며 올해 첫 승을 거둘 수 있었다. 베르스타펜은 호주, 중국, 바레인 그랑프리에서 각각 3위, 4위, 7위로 예선을 마쳤다.올해 모든 예선 세션 평균으로 볼 때 레드불은 두 번째로 빠른 차량이지만, 랩당 0.214초가 맥라렌보다 느리다. 페르스타펜은 코너 진입 시 예측 불가능하고 중간 코너에서 언더스티어가 발생하는 레드불의 밸런스 문제에 대해 시즌 내내 불만을 제기해왔다.레드불 팀의 크리스천 호너 감독은 바레인 레이스 후 차량 밸런스 문제가 지난해 후반 페르스타펜을 고전하게 했던 문제와 근본적으로 유사하다고 인정했다. 그는 지난 시즌 마지막 13경기에서 단 두 번만 승리했으나, 시즌 초 5경기에서 레드불이 압도적인 모습을 보이며 쌓아 올린 막대한 리드 덕분에 네 번째 월드 챔피언 타이틀을 차지할 수 있었다.호너는 또한 팀이 풍동 실험과 실제 트랙 성능 간의 상관관계 파악에 어려움을 겪고 있다고 밝혔다. 본질적으로 차량은 시뮬레이션 도구가 예측한 것과 달리 트랙에서 다른 성능을 보인다는 것이다. 베르스타펜은 바레인에서 두 차례 피트 스톱 모두 지연되는 등 힘든 레이스를 펼쳤다. 한 번은 피트 레인 신호등 시스템 문제로, 다른 한 번은 프론트 휠 장착 문제로 지연됐다.한때 최하위까지 추락했던 그는 마지막 랩에서야 알파인의 피에르 가슬리로부터 간신히 6위를 탈환했다. 베르스타펜은 더운 날씨와 거친 트랙 표면이 레드불의 문제를 악화시켰다고 지적했다. 그는 "여기서는 타맥이 매우 공격적이라 밸런스 문제가 크면 그만큼 더 큰 대가를 치르게 된다"고 말했다.바람도 상당히 강하고 트랙 그립이 매우 낮아서 모든 문제가 더 부각됩니다." 브레이크 감각과 제동력에 주말 내내 고생했고, 그 외에도 그립이 매우 나빴습니다. 셋업에 많은 시도를 했지만 기본적으로 모두 효과가 없었고, 작업 방향을 제시해주지도 못했습니다."베르스타펜은 올해 자신의 미래에 대해 "편안한 마음"이라고 말한 바 있다. 2026년 팀 이적에 관한 어떤 결정도 F1이 스포츠 역사상 가장 큰 규정 변경에 해당하는 새로운 섀시 및 엔진 규정을 도입한다는 사실로 인해 복잡해진다. 어떤 팀이 최상의 상태를 유지할지 예측하는 것은 불가능하다.하지만 2026년 엔진 성능 측면에서 메르세데스가 가장 유력하다는 점은 패독 내에서 널리 인정받고 있다. 메르세데스 F1 팀장 토토 볼프는 베르스타펜 영입 의사를 숨기지 않았다. 양측은 지난 시즌 협상을 진행했으나, 이번 시즌에는 아직 미래에 관한 논의가 없었다.",
"videos": [],
"images": [
{
"image_url": "<https://ichef.bbci.co.uk/ace/branded_sport/1200/cpsprodpb/bfc4/live/d3cc7850-1931-11f0-869a-33b652e8958c.jpg>",
"image_description": "메인 이미지"
},
이제 데이터를 확보했으므로 다음 단계는 이를 임베딩하는 것입니다.
3단계: 임베딩 및 벡터 저장소 설정
3.1 rag.py 파일에 필요한 라이브러리 설치
pip install openai pinecone pandas
3.2 필요한 라이브러리 가져오기
import json
import time
import re
import openai
import pandas as pd
from pinecone import Pinecone, ServerlessSpec
3.3 OpenAI 키 구성
OpenAI를 사용하여 text_for_embedding 필드에서 임베딩을 생성합니다.
# OpenAI API 키를 여기에 설정하거나 함수에 전달
OPENAI_API_KEY = "OPENAI_API_KEY" # 본인의 OpenAI API 키로 대체
3.4 Pinecone API 키 및 인덱스 설정 구성
Pinecone 환경을 설정하고 인덱스 구성을 정의합니다.
pinecone_api_key = "PINECONE_API_KEY" # Pinecone API 키로 교체
index_name = "news-articles"
dimension = 1536 # text-embedding-ada-002용 OpenAI 임베딩 차원 (필요 시 조정)
namespace = "default"
3.5 Pinecone 클라이언트 및 인덱스 초기화
데이터 저장 및 검색을 위해 클라이언트와 인덱스가 올바르게 초기화되었는지 확인합니다.
# Pinecone 클라이언트 및 인덱스 초기화
pc = Pinecone(api_key=pinecone_api_key)
# 인덱스 존재 여부 확인
if index_name not in pc.list_indexes().names():
pc.create_index(
name=index_name,
dimension=dimension,
metric="cosine",
spec=ServerlessSpec(cloud="aws", region="us-east-1")
)
while not pc.describe_index(index_name).status["ready"]:
time.sleep(1)
pinecone_index = pc.Index(index_name)
print(pinecone_index)
3.6 데이터 정리, 로드 및 전처리
# 텍스트 정리 헬퍼
def clean_text(text):
text = re.sub(r"\s+", " ", text)
return text.strip()
# `news-data.json` 로드 및 전처리
def load_and_prepare_data(json_path="news-data.json"):
with open(json_path, "r", encoding="utf-8") as f:
news_data = json.load(f)
df = pd.DataFrame(news_data)
df["text_for_embedding"] = df["headline"].map(clean_text) + ". " + df["content"].map(clean_text)
df["id"] = df["id"].astype(str)
return df
참고: 최신 데이터를 확보하려면
scraper.py를다시 실행하세요.
3.7 OpenAI를 사용한 임베딩 생성
OpenAI 임베딩 모델을 사용하여 전처리된 텍스트로부터 임베딩을 생성합니다.
# OpenAI API를 통한 새 임베딩 생성
def openai_generate_embeddings(texts, model="text-embedding-ada-002"):
openai.api_key = OPENAI_API_KEY
# OpenAI 엔드포인트는 문자열 목록을 받아 임베딩 목록을 반환합니다
response = openai.embeddings.create(
input=texts,
model=model
)
embeddings = [datum.embedding for datum in response.data]
return embeddings
3.8 Pinecone에 임베딩 업데이트
생성된 임베딩을 Pinecone에 푸시하여 벡터 데이터베이스를 최신 상태로 유지합니다.
# Pinecone에 임베딩 및 업서트
def embed_and_upsert(json_path="news-data.json", namespace=namespace):
df = load_and_prepare_data(json_path)
texts = df["text_for_embedding"].tolist()
print(f"OpenAI를 사용하여 {len(texts)} 텍스트에 대한 임베딩 생성 중...")
embeddings = openai_generate_embeddings(texts)
df["embedding"] = embeddings
records = []
for row in df.itertuples():
records.append((
row.id,
row.embedding,
{
"url": getattr(row, "url", ""), # 존재할 경우 안전하게 url 가져옴
"text": row.text_for_embedding
}
))
pinecone_index.upsert(vectors=records, namespace=namespace)
print(f"Pinecone 인덱스 '{index_name}'에 {len(records)}개의 레코드를 업서트했습니다.")
참고: 데이터베이스 초기화 시 이 단계를 한 번만 실행하면 됩니다. 이후에는 해당 코드 부분을 주석 처리해도 됩니다.
3.9 Pinecone 검색 함수 초기화
def pinecone_search(index, query, namespace=namespace, top_k=3, score_threshold=0.8, embedding_model=None):
# OpenAI embedding here
query_embedding = openai_generate_embeddings([query])[0]
results = index.query(
vector=query_embedding,
top_k=top_k,
namespace=namespace,
include_metadata=True,
)
filtered = []
for match in results.matches:
if match.score >= score_threshold:
filtered.append({
"score": match.score,
"url": match.metadata.get("url", ""),
"text": match.metadata.get("text", ""),
})
return filtered
참고:
점수 임계값은 결과가 관련성이 있다고 간주되기 위한 최소 유사도 점수를 정의합니다. 필요에 따라 이 값을 조정할 수 있습니다. 점수가 높을수록 결과의 정확도가 높아집니다.
3.10 OpenAI를 사용한 답변 생성
Pinecone을 통해 검색된 컨텍스트로부터 OpenAI를 사용하여 답변을 생성합니다.
# OpenAI 답변 생성
def openai_generate_answer(openai_api_key, query, context=None):
import openai
openai.api_key = openai_api_key
prompt_context = ""
if context:
prompt_context = "\n\nContext:\n" + "\n\n".join(context)
prompt = f"Answer the following question: {query}" + prompt_context
response = openai.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}],
max_tokens=256,
temperature=0.7,
)
answer = response.choices[0].message.content.strip()
return answer
3.11 (선택 사항) 간단한 테스트 실행으로 결과 조회 및 출력
기본 테스트를 실행할 수 있는 CLI 친화적인 코드를 포함하세요. 이 테스트는 구현이 제대로 작동하는지 확인하고 데이터베이스에 저장된 데이터의 미리보기를 보여줍니다.
def search_news_and_answer(openai_api_key, query):
results = pinecone_search(pinecone_index, query)
if results:
print(f"관련 문서 {len(results)} 개 발견됨.")
print("상위 문서:")
for doc in results:
print(f"점수: {doc['score']:.4f}")
print(f"URL: {doc['url']}")
print(f"텍스트 (발췌): {doc['text'][:250]}...\n")
answer = openai_generate_answer(openai_api_key, query, [r["text"] for r in results])
print("\n생성된 답변:\n", answer)
if __name__ == "__main__":
OPENAI_API_KEY = "OPENAI_API_KEY" # 여기에 OpenAI 키를 입력하거나 인자/환경 변수로 전달
test_query = "맨체스터 시티의 문제점은 무엇인가요?"
search_news_and_answer(OPENAI_API_KEY, test_query)
팁: 결과의 텍스트 길이는 슬라이싱으로 제어할 수 있습니다. 예:
[:250].
이제 데이터가 벡터 데이터베이스에 저장되었습니다. 이는 두 가지 쿼리 옵션이 있음을 의미합니다:
- 데이터베이스에서 검색
- OpenAI가 생성한 일반 응답 사용
4단계: 에이전트 컨트롤러 구축
4.1 agent_controller.py에서
rag.py에서 필요한 기능을 임포트합니다.
from rag import openai_generate_answer, pinecone_search
4.2 Pinecone 검색 구현
Pinecone 벡터 저장소에서 관련 데이터를 검색하는 로직을 추가합니다.
def agent_controller_decide_and_act(
pinecone_api_key,
openai_api_key,
pinecone_index,
query,
namespace="default"
):
print(f"Agent received query: {query}")
try:
print("Pinecone 검색 시도 중...")
results = pinecone_search(pinecone_index, query, namespace=namespace)
if results:
print(f"Pinecone에서 {len(results)}개의 일치하는 문서를 찾았습니다.")
context_texts = [r["text"] for r in results]
answer = openai_generate_answer(openai_api_key, query, context_texts)
return answer
else:
print("Pinecone에서 적합한 일치 항목을 찾지 못했습니다. OpenAI 생성기로 대체합니다.")
except Exception as e:
print(f"Pinecone 검색 실패: {e}")
4.3 대체 OpenAI 응답 구현
관련 컨텍스트를 검색하지 못했을 때 OpenAI를 사용하여 답변을 생성하는 로직을 생성합니다.
try:
print("검색 컨텍스트 없이 OpenAI로 답변 생성 중...")
answer = openai_generate_answer(openai_api_key, query)
return answer
except Exception as e:
print(f"OpenAI 생성 실패: {e}")
return "죄송합니다. 현재 귀하의 질문에 답변할 수 없습니다."
5단계: 모든 것을 통합하기
5.1 crux.py에서
agent_controller.py에서 필요한 모든 함수를 임포트합니다.
from rag import pinecone_index # Pinecone 인덱스 및 임베딩 모델 가져오기
from rag import openai_generate_answer, pinecone_search # 필요한 경우 헬퍼 함수 가져오기
from agent_controller import agent_controller_decide_and_act # 오케스트레이션 함수 가져오기
5.2 API 키 제공
OpenAI 및 Pinecone API 키가 올바르게 설정되었는지 확인하십시오.
# 실제 API 키 입력 - 본인의 키로 대체
PINECONE_API_KEY = "PINECONE_API_KEY"
OPENAI_API_KEY = "OPENAI_API_KEY"
5.3 main() 함수에 프롬프트 입력
main() 함수 내에서 프롬프트 입력을 정의하세요.
def main():
query = "맨체스터 시티의 문제는 무엇인가요?"
answer = agent_controller_decide_and_act(
pinecone_api_key=PINECONE_API_KEY,
openai_api_key=OPENAI_API_KEY,
pinecone_index=pinecone_index,
query=query,
namespace="default"
)
print("\n에이전트의 답변:\n", answer)
if __name__ == "__main__":
main()
5.4 Agentic RAG 호출
Agentic RAG 로직을 실행합니다. 벡터 데이터베이스에 쿼리하기 전에 먼저 관련성을 확인하는 방식으로 쿼리를 처리하는 과정을 확인할 수 있습니다.

에이전트 수신 쿼리: 맨체스터 시티 여자 팀의 정확한 문제점은 무엇인가요?
Pinecone 검색 시도 중...
Pinecone에서 일치하는 문서 1개 발견.
에이전트 답변:
이번 시즌 맨체스터 시티 여자 팀의 문제점으로는 심각한 부상 사태, 감독 교체, 주요 경기에서의 부진한 성적이 있습니다. 비비안 미데마, 카디자 쇼, 로렌 헴프, 알렉스 그린우드 등 핵심 선수들이 부상으로 결장하면서 팀 성적에 심각한 영향을 미쳤고, 선수층의 깊이가 부족하다는 점이 부각되었습니다. 임시 감독 닉 커싱은 부상자 수가 단순히 불운이나 잘못된 관리 때문만은 아니라고 지적하며 상황 분석을 촉구했습니다.
데이터베이스와 일치하지 않는 쿼리로 테스트해 보세요. 예를 들어:
def main():
query = "Why Sleep?"
에이전트는 파인콘에서 적합한 답변을 찾지 못하면 OpenAI를 활용해 일반적인 응답을 생성합니다.

에이전트 수신 쿼리: 왜 잠을 자야 할까?
Pinecone 검색 시도 중...
파인콘에서 적합한 결과 없음. OpenAI 생성기로 전환합니다.
(자동차 사고처럼) 즉각적인 위험을 초래하거나, 시간이 지남에 따라 해를 끼칠 수 있습니다.
예를 들어 지속적인 수면 부족은 일부 만성 건강 문제의 위험을 높일 수 있습니다. 또한 사고력, 반응 속도, 업무 수행 능력, 학습 능력, 대인관계에 영향을 미칠 수 있습니다. (자동차 사고처럼) 즉각적인 위험을 초래하거나, 시간이 지남에 따라 해를 끼칠 수 있습니다.
팁: 각 프롬프트에 대한 관련성 점수(score_threshold)를 출력하여 에이전트의 신뢰도를 파악할 수 있습니다.
이것으로 끝입니다! 에이전트 기반 RAG를 성공적으로 구축했습니다.
6단계(선택 사항): 피드백 루프 및 최적화
시간이 지남에 따라 훈련과 색인 생성을 개선하기 위한 피드백 루프를 구현하여 시스템을 향상시킬 수 있습니다.
6.1 피드백 기능 추가
agent_controller.py에서 응답 표시 후 사용자에게 피드백을 요청하는 함수를 생성하세요. 이 함수는 crux.py의 메인 러너 마지막 부분에서 호출할 수 있습니다.
def collect_user_feedback():
feedback = input("답변이 도움이 되었나요? (예/아니오): ").strip().lower()
comments = input("추가 의견이나 수정 사항이 있나요? (선택 사항): ").strip()
return feedback, comments
6.2 피드백 로직 구현
agent_controller.py에 피드백이 부정적일 경우 검색 프로세스를 재실행하는 새 함수를 생성하세요. 그런 다음 crux.py에서 이 함수를 호출하세요 :
def agent_controller_handle_feedback(
feedback,
comments,
openai_api_key,
pinecone_index,
query,
namespace="default"
):
if feedback == "no":
print("피드백: 답변이 도움이 되지 않았습니다. 검색 매개변수를 완화하여 재시도 중...")
# 완화된 검색 - 문서 수 증가 및 점수 임계값 하향
results = pinecone_search(
pinecone_index,
query,
namespace=namespace,
top_k=5,
score_threshold=0.3
)
if results:
print(f"재시도 후 {len(results)}개의 문서 발견.")
context_texts = [r["text"] for r in results]
answer = openai_generate_answer(openai_api_key, query, context_texts)
print("\n피드백을 기반으로 생성된 새 답변:\n", answer)
return answer
else:
print("재시도 후에도 문서를 찾지 못했습니다. 검색 컨텍스트 없이 답변 생성 중...")
answer = openai_generate_answer(openai_api_key, query)
print("\n검색 없이 생성된 답변:\n", answer)
return answer
else:
print("긍정적인 피드백 감사합니다!")
return None
결론 및 향후 계획
이 글에서는 웹 스크래핑을 위한 Bright Data, 벡터 데이터베이스인 Pinecone, 텍스트 생성을 위한 OpenAI를 결합한 자율적 에이전트형 RAG 시스템을 구축했습니다. 이 시스템은 다음과 같은 다양한 추가 기능을 지원하도록 확장할 수 있는 기반을 제공합니다:
- 벡터 데이터베이스와 관계형 또는 비관계형 데이터베이스 통합
- Streamlit을 활용한 사용자 인터페이스 생성
- 훈련 데이터 최신화를 위한 웹 데이터 자동 수집
- 검색 로직 및 에이전트 추론 능력 향상
시연된 바와 같이, 에이전트형 RAG 시스템의 출력 품질은 입력 데이터의 품질에 크게 좌우됩니다. Bright Data는 효과적인 검색 및 생성에 필수적인 신뢰할 수 있고 최신 웹 데이터를 확보하는 데 핵심적인 역할을 수행했습니다.
향후 프로젝트에서 Bright Data를 활용하여 일관되고 고품질의 입력 데이터를 유지하면서 이 워크플로우의 추가 개선 방안을 모색해 보시기 바랍니다.





