

이 가이드에서는 다음을 배울 수 있습니다:
- 제로샷 분류란 무엇이며 어떻게 작동하는지
- 사용 시 장단점
- 웹 스크래핑에서 이 기법의 관련성
- 웹 스크래핑 시나리오에서 제로샷 분류 구현을 위한 단계별 튜토리얼
자, 시작해 보겠습니다!
제로샷 분류란 무엇인가?
제로샷 분류 (ZSC)는 머신러닝 모델이 훈련 단계에서 본 적 없는 클래스를 예측하는 능력입니다. 클래스는 모델이 데이터 조각에 할당하는 특정 범주 또는 레이블입니다. 예를 들어, 이메일 텍스트에 “스팸” 클래스를 할당하거나, 이미지에 “고양이” 클래스를 할당할 수 있습니다.
ZSC는 전이 학습의 한 유형으로 분류될 수 있습니다. 전이 학습은 한 문제를 해결하며 얻은 지식을 활용하여 서로 다르지만 관련된 다른 문제를 해결하는 머신러닝 기법입니다.
ZSC의 핵심 아이디어는 여러 유형의 신경망과 머신러닝 모델에서 오랫동안 탐구되고 구현되어 왔습니다. 이는 다음과 같은 다양한 모달리티에 적용될 수 있습니다:
- 텍스트: 광범위한 언어 이해를 위해 훈련된 모델이 있지만, “지속 가능한 포장에 대한 제품 리뷰” 예시를 본 적이 없다고 가정해 보십시오. ZSC를 사용하면 텍스트 더미에서 그러한 리뷰를 식별하도록 요청할 수 있습니다. 이는 각 특정 레이블에 대해 미리 학습된 예시에 의존하기보다는 원하는 범주(레이블)의 의미를 이해하고 이를 입력 텍스트와 매칭함으로써 이루어집니다.
- 이미지: 동물 이미지(예: 고양이, 개, 말) 세트로 훈련된 모델은 훈련 중 얼룩말을 본 적이 없더라도 얼룩말 이미지를 “동물” 또는 “줄무늬 말과 유사한 동물”로 분류할 수 있습니다.
- 오디오: 모델은 “자동차 경적”, “사이렌”, “개 짖는 소리”와 같은 일반적인 도시 소리를 인식하도록 훈련될 수 있습니다. ZSC 덕분에 모델은 “잭해머”처럼 명시적으로 훈련받지 않은 소리도 그 음향적 특성을 이해하고 알려진 소리들과 연관지음으로써 식별할 수 있습니다.
- 다중 모달 데이터: ZSC는 서로 다른 유형의 데이터 간에도 작동할 수 있습니다. 예를 들어, 본 적 없는 클래스에 대한 텍스트 설명을 바탕으로 이미지를 분류하거나 그 반대의 경우도 가능합니다.
ZSC는 어떻게 작동할까?
사전 훈련된 대규모 언어 모델(LLM)의 인기로 제로샷 분류에 대한 관심이 높아지고 있습니다. 이러한 모델들은 방대한 양의 AI 중심 데이터로 훈련되어 언어, 의미론, 문맥에 대한 깊은 이해를 발전시킵니다.
ZSC의 경우, 사전 훈련된 모델은 종종 NLI(Natural Language Inference, 자연어 추론)라는 작업에 대해 미세 조정됩니다. NLI는 두 텍스트 조각, 즉 “전제(premise)”와 “가설(hypothesis)” 간의 관계를 판단하는 작업입니다. 모델은 가설이 전제에 의해 함축되는 ( entailment, 참) 것인지, 전제와 모순되는 ( contradiction, 거짓) 것인지, 아니면 중립적인 ( neutral, 무관한) 것인지 결정합니다.
제로샷 분류 설정에서는 입력 텍스트가 전제 역할을 합니다. 후보 범주 레이블은 가설로 취급됩니다. 모델은 “전제”(입력 텍스트)에 의해 가장 유력하게 함축되는 “가설”(레이블)을 계산합니다. 가장 높은 함축 점수를 가진 레이블이 분류 결과로 선택됩니다.
제로샷 분류 사용의 장점과 한계
이제 제로샷 분류의 장단점을 살펴볼 시간입니다.
장점
ZSC는 다음과 같은 여러 운영상의 이점을 제공합니다:
- 새로운 클래스에 대한 적응성: ZSC는 모델 재훈련이나 새로운 클래스에 대한 특정 훈련 예제 수집 없이도 새로운 레이블을 정의함으로써, 데이터가 이전에 보지 못한 범주로 분류될 수 있는 길을 열어줍니다.
- 라벨링 데이터 요구량 감소: 이 방법은 대상 클래스에 대한 방대한 라벨링 데이터셋에 대한 의존도를 낮춥니다. 이는 머신러닝 프로젝트 일정과 비용에서 흔히 발생하는 병목 현상인 데이터 라벨링부담을 완화합니다.
- 효율적인 분류기 구현: 새로운 분류 체계를 신속하게 구성하고 평가할 수 있습니다. 이는 변화하는 요구 사항에 대응하여 더 빠른 반복 주기를 가능하게 합니다.
제한 사항
강력하지만 제로샷 분류에는 다음과 같은 한계가 있습니다:
- 성능 변동성: ZSC 기반 모델은 고정된 클래스 세트로 광범위하게 훈련된 감독형 모델에 비해 정확도가 낮을 수 있습니다. 이는 ZSC가 대상 클래스 예제에 대한 직접 훈련이 아닌 의미적 추론에 의존하기 때문입니다.
- 모델 품질 의존성: ZSC 성능은 기반이 되는 사전 훈련된 언어 모델의 품질과 능력에 달려 있습니다. 강력한 기본 모델일수록 일반적으로 더 나은 ZSC 결과를 도출합니다.
- 라벨 모호성과 표현: 후보 라벨의 명확성과 구별성은 정확도에 영향을 미칩니다. 모호하거나 불명확하게 정의된 라벨은 최적의 성능을 발휘하지 못할 수 있습니다.
웹 스크래핑에서 제로샷 분류의 중요성
웹상의 새로운 정보, 제품, 주제가 지속적으로 등장함에 따라 적응형 데이터 처리 방법이 요구됩니다. 모든 것은 웹 스크래핑, 즉 웹 페이지에서 데이터를 자동으로 추출하는 과정으로부터 시작됩니다.
기존 머신러닝 방법은 스크래핑된 데이터의 새로운 클래스를 처리하기 위해 수동 분류나 빈번한 재훈련을 필요로 하여 대규모에서는 비효율적입니다. 반면 제로샷 분류는 다음과 같은 기능을 통해 웹 콘텐츠의 동적 특성이 제기하는 문제를 해결합니다:
- 이질적 데이터의 동적 분류: 다양한 출처에서 수집된 스크래핑데이터를 현재 분석 목표에 부합하는 사용자 정의 레이블 세트로 실시간 분류할 수 있습니다.
- 진화하는 정보 환경에 대한 적응: 새로운 범주나 주제를 광범위한 모델 재개발 주기 없이 즉시 분류 체계에 통합할 수 있습니다.
따라서 웹 스크래핑에서 전형적인 ZSC 활용 사례는 다음과 같습니다:
- 동적 콘텐츠 분류: 뉴스 기사나 제품 목록과 같은 콘텐츠를 여러 도메인에서 스크래핑할 때, ZSC는 항목을 사전 정의된 또는 새로운 범주로 자동 할당할 수 있습니다.
- 신규 주제에 대한 감정 분석: 신제품에 대한 스크랩된 고객 리뷰나 신생 브랜드 관련 소셜 미디어 데이터의 경우, ZSC는 해당 제품이나 브랜드에 특화된 감정 훈련 데이터 없이도 감정 분석을 수행할 수 있습니다. 이를 통해 시기적절한 브랜드 인식 모니터링과 고객 피드백 평가가 용이해집니다.
- 신규 트렌드 및 주제 식별: 잠재적 신규 트렌드를 나타내는 가설 레이블을 정의함으로써, ZSC는 포럼, 블로그 또는 소셜 미디어에서 스크래핑된 텍스트를 분석하여 이러한 주제의 증가하는 유행을 식별하는 데 활용될 수 있습니다.
제로샷 분류의 실용적 구현
이 튜토리얼 섹션에서는 웹에서 수집한 데이터에 제로샷 분류를 적용하는 과정을 안내합니다. 대상 사이트는 “하키 팀: 양식, 검색 및 페이지네이션“입니다:
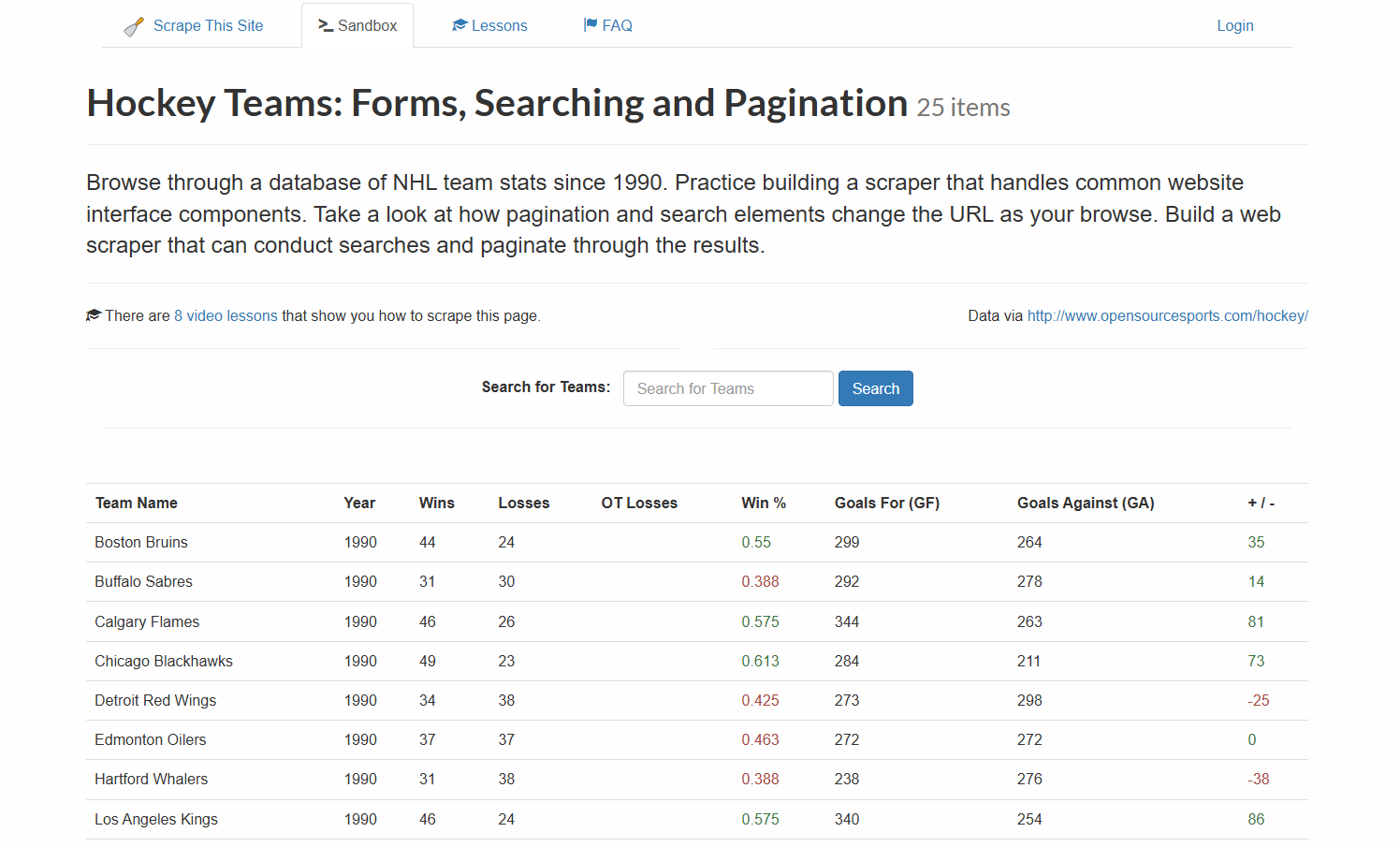
먼저 웹 스크레이퍼가 위 표의 데이터를 추출합니다. 이후 LLM이 ZSC를 활용해 이를 분류합니다. 본 튜토리얼에서는 Hugging Face의 DistilBart-MNLI (BART 계열 경량 LLM)를 사용합니다.
아래 단계를 따라 원하는 ZSC 목표를 달성하는 방법을 확인하세요!
필수 조건 및 종속성
이 튜토리얼을 재현하려면 컴퓨터에 Python 3.10.1 이상이 설치되어 있어야 합니다.
프로젝트의 메인 폴더를 zsc_project/라고 가정합니다 . 이 단계가 완료되면 폴더 구조는 다음과 같아집니다:
zsc_project/
├── zsc_scraper.py
└── venv/여기서:
zsc_scraper.py는코딩 로직을 포함하는 Python 파일입니다.venv/에는가상 환경이 포함됩니다.
venv/ 가상 환경 디렉터리는 다음과 같이 생성할 수 있습니다:
python -m venv venv활성화하려면 Windows에서 다음을 실행하세요:
venvScriptsactivatemacOS 및 Linux에서는 다음과 같이 실행합니다:
source venv/bin/activate활성화된 가상 환경에서 다음 명령어로 종속성을 설치하세요:
pip install requests beautifulsoup4 transformers torch이러한 종속성은 다음과 같습니다:
requests: HTTP 웹 요청을 생성하는 라이브러리입니다.beautifulsoup4: HTML 및 XML 문서를 파싱하고 데이터를 추출하는 라이브러리입니다. BeautifulSoup 웹 스크래핑 가이드에서 자세히 알아보세요.transformers: Hugging Face에서 제공하는 수천 개의 사전 훈련된 모델을 제공하는 라이브러리입니다.torch: 오픈소스 머신러닝 프레임워크인 PyTorch입니다.
훌륭합니다! 이제 대상 웹사이트에서 데이터를 추출하고 ZSC를 수행하는 데 필요한 모든 것을 갖추셨습니다.
1단계: 초기 설정 및 구성
필요한 라이브러리를 임포트하고 변수를 설정하여 zsc_scraper.py 파일을 초기화합니다:
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
from transformers import pipeline
# 스크래핑 시작 URL
BASE_URL = "https://www.scrapethissite.com/pages/forms/"
# 제로샷 분류를 위한 사전 정의된 카테고리
CANDIDATE_LABELS = [
"NHL 팀 시즌 성적 요약",
"선수 약력 및 경력 통계",
"스포츠 뉴스 및 경기 해설",
"하키 리그 규정 및 규칙",
"팬 토론 및 포럼",
"역사적 스포츠 데이터 기록"
]
MAX_PAGES_TO_SCRAPE = 2 # 스크랩할 최대 페이지 수
MAX_TEAMS_PER_PAGE_FOR_ZSC = 2 # 처리할 최대 팀 수 위 코드는 다음을 수행합니다:
BASE_URL로 스크랩할 대상 웹사이트를 정의합니다.CANDIDATES_LABELS는스크랩된 데이터를 분류하기 위해 제로샷 분류 모델이 사용할 범주를 정의하는 문자열 목록을 저장합니다. 모델은 각 팀 데이터를 가장 잘 설명하는 라벨을 결정하려고 시도합니다.- 스크래핑할 최대 페이지 수와 가져올 최대 팀 데이터 수를 정의합니다.
완벽합니다! 이제 Python으로 제로샷 분류를 시작할 준비가 되었습니다.
2단계: 페이지 URL 가져오기
대상 페이지의 페이지네이션 요소를 확인하는 것으로 시작하세요:
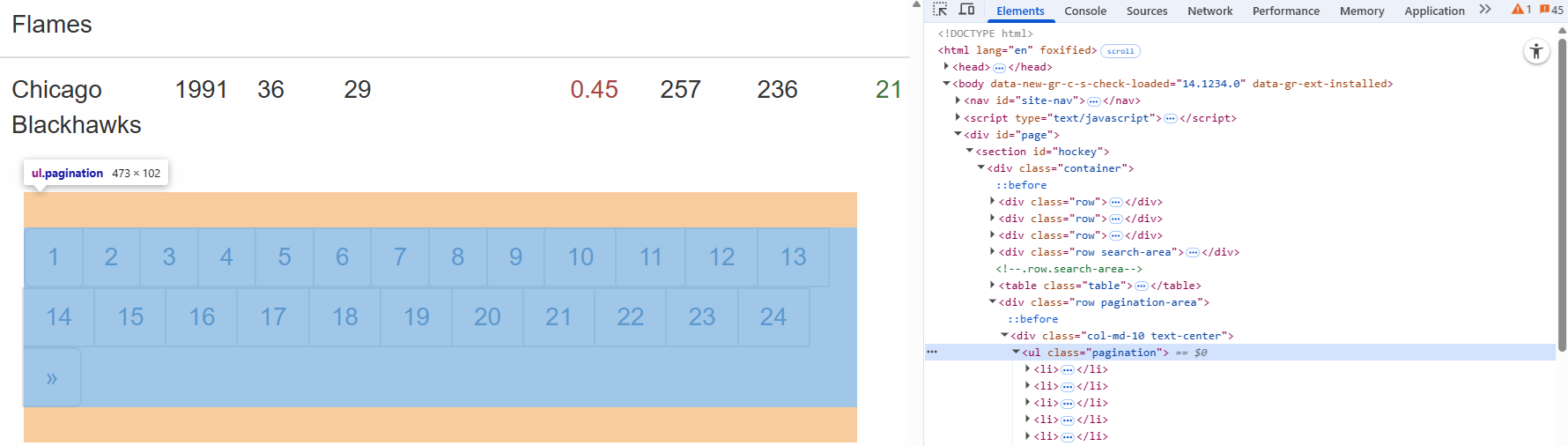
여기서 페이지네이션 URL이 .pagination HTML 노드에 포함되어 있음을 확인할 수 있습니다.
웹사이트의 페이지네이션 섹션에서 모든 고유한 페이지 URL을 찾는 함수를 정의합니다:
def get_all_page_urls(base_url_to_scrape):
page_urls = [base_url_to_scrape] # 기본 URL로 초기화
response = requests.get(base_url_to_scrape) # 기본 URL 콘텐츠 가져오기
soup = BeautifulSoup(response.content, "html.parser") # HTML 콘텐츠 파싱
# 페이지네이션 태그
pagination_links = soup.select("ul.pagination li a")
discovered_urls = set() # 중복을 피하기 위해 고유한 상대 URL 저장
for link_tag in pagination_links:
href = link_tag.get("href")
# 링크가 해당 사이트의 페이지네이션 링크인지 확인
if href and href.startswith("?page_num="):
discovered_urls.add(href)
# 일관된 순서로 정렬하고 완전한 URL 생성
for relative_url in sorted(list(discovered_urls)):
full_url = urljoin(base_url_to_scrape, relative_url) # 절대 URL 생성
# 페이지네이션 URL을 추가하려면 다음 줄의 주석을 해제하세요:
page_urls.append(full_url)
return page_urls이 함수는:
- 대상 웹사이트에
get()메서드로 HTTP 요청을 보냅니다. - BeautifulSoup의
select()메서드로 페이지 매김을 처리합니다. for루프를 통해 각 페이지를 순차적으로 반복하며 일관된 순서를 보장합니다.- 모든 고유한 전체 페이지 URL 목록을 반환합니다.
멋지네요! 데이터를 추출할 웹 페이지의 URL을 가져오는 함수를 만들었습니다.
3단계: 데이터 스크래핑
대상 페이지의 페이지네이션 요소를 검사하는 것으로 시작합니다:

여기서 스크랩할 팀 데이터가 .table HTML 노드에 포함되어 있음을 확인할 수 있습니다.
단일 페이지 URL을 받아 콘텐츠를 가져오고 팀 통계를 추출하는 함수를 만듭니다:
def scrape_page(url):
page_data = [] # 이 페이지에서 스크랩한 데이터를 저장할 리스트
response = requests.get(url) # 페이지 콘텐츠 가져오기
soup = BeautifulSoup(response.content, "html.parser") # HTML 파싱
# "table" 클래스 테이블 내 "team" 클래스 테이블 행 모두 선택
table_rows = soup.select("table.table tr.team")
for row in table_rows:
# 각 행에서 텍스트 추출 (이름, 연도, 승리, 패배)
team_stats = {
"name": row.select_one("td.name").get_text(strip=True),
"year": row.select_one("td.year").get_text(strip=True),
"승리": row.select_one("td.wins").get_text(strip=True),
"패배": row.select_one("td.losses").get_text(strip=True),
}
page_data.append(team_stats) # 추출한 팀 데이터를 리스트에 추가
return page_data이 함수는:
select()메서드를 사용하여 테이블 행에서 데이터를 가져옵니다.for row in table_rows:루프로 각 팀 행을 처리합니다.- 가져온 데이터를 리스트로 반환합니다.
잘하셨습니다! 대상 웹사이트에서 데이터를 가져오는 함수를 만들었습니다.
단계 #4: 프로세스 조정
전체 워크플로를 다음 단계로 조정합니다:
- 분류 모델 로드
- 스크래핑할 페이지의 URL 가져오기
- 각 페이지에서 데이터 스크래핑
- 스크랩된 텍스트를 ZSC로 분류
다음 코드로 이를 구현합니다:
# 제로샷 분류 파이프라인 초기화
classifier = pipeline("zero-shot-classification", model="valhalla/distilbart-mnli-12-3")
# 스크랩할 전체 URL 가져오기 (기본 URL + 페이지별 URL)
all_page_urls = get_all_page_urls(BASE_URL)
all_team_data_for_zsc = [] # 분류를 위해 선택된 팀 데이터를 저장할 리스트
# 페이지 URL을 순회
for page_url in all_page_urls[:MAX_PAGES_TO_SCRAPE]:
current_page_team_data = scrape_page(page_url) # 현재 페이지에서 데이터 스크랩
# 페이지당 스크랩할 최대 팀 수
all_team_data_for_zsc.extend(current_page_team_data[:MAX_TEAMS_PER_PAGE_FOR_ZSC])
# 분류 시작
print(f"n--- {len(all_team_data_for_zsc)}개의 스크랩된 하키 팀 정보 조각 분류 중 ---")
# 수집된 팀 데이터를 순회하며 각각 분류
for i, team_info_dict in enumerate(all_team_data_for_zsc):
name = team_info_dict["name"]
year = team_info_dict["year"]
wins = team_info_dict["wins"]
losses = team_info_dict["losses"]
# 분류를 위한 팀 데이터로 텍스트 스니펫 생성
text_snippet = f"팀: {name}, 연도: {year}, 승리: {wins}, 패배: {losses}."
print(f"n데이터 스니펫 {i+1}: "{text_snippet}"")
# 제로샷 분류 수행
result = classifier(text_snippet, CANDIDATE_LABELS, multi_label=False)
# 예측된 범주와 신뢰도 점수 출력
print(f"Predicted Category: {result['labels'][0]}")
print(f"Confidence Score: {result['scores'][0]:.4f}")이 코드는:
pipeline()메서드로 사전 훈련된 모델을 로드하고"zero-shot-classification"으로 작업을 지정합니다.- 이전 함수를 호출하여 실제 ZSC(제로샷 분류)를 수행합니다.
완벽합니다! 이전 모든 단계를 조율하고 실제 제로샷 분류를 수행하는 함수를 만들었습니다.
단계 #5: 모든 것을 통합하고 코드 실행하기
아래는 zsc_scraper.py 파일에 포함되어야 할 내용입니다:
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
from transformers import pipeline
# 스크래핑 시작 URL
BASE_URL = "https://www.scrapethissite.com/pages/forms/"
# 제로샷 분류를 위한 사전 정의된 카테고리
CANDIDATE_LABELS = [
"NHL 팀 시즌 성적 요약",
"선수 약력 및 커리어 통계",
"스포츠 뉴스 및 경기 해설",
"하키 리그 규정 및 규칙",
"팬 토론 및 포럼",
"역사적 스포츠 데이터 기록"
]
MAX_PAGES_TO_SCRAPE = 2 # 스크래핑할 최대 페이지 수
MAX_TEAMS_PER_PAGE_FOR_ZSC = 2 # 페이지당 처리할 최대 팀 수
# 페이지 URL 가져오기
def get_all_page_urls(base_url_to_scrape):
page_urls = [base_url_to_scrape] # 기본 URL로 초기화
response = requests.get(base_url_to_scrape) # 기본 URL 콘텐츠 가져오기
soup = BeautifulSoup(response.content, "html.parser") # HTML 콘텐츠 파싱
# 페이지네이션 태그
pagination_links = soup.select("ul.pagination li a")
discovered_urls = set() # 중복 방지 위해 고유한 상대 URL 저장
for link_tag in pagination_links:
href = link_tag.get("href")
# 해당 사이트의 페이지네이션 링크인지 확인
if href and href.startswith("?page_num="):
discovered_urls.add(href)
# 일관된 순서로 정렬하고 전체 URL 생성
for relative_url in sorted(list(discovered_urls)):
full_url = urljoin(base_url_to_scrape, relative_url) # 절대 URL 생성
# 페이지네이션 URL을 추가하려면 다음 줄의 주석을 해제하세요:
page_urls.append(full_url)
return page_urls
def scrape_page(url):
page_data = [] # 이 페이지에서 스크랩한 데이터를 저장할 리스트
response = requests.get(url) # 페이지 콘텐츠 가져오기
soup = BeautifulSoup(response.content, "html.parser") # HTML 파싱
# "table" 클래스 테이블 내 "team" 클래스 테이블 행 모두 선택
table_rows = soup.select("table.table tr.team")
for row in table_rows:
# 각 행에서 텍스트 추출 (이름, 연도, 승리, 패배)
team_stats = {
"name": row.select_one("td.name").get_text(strip=True),
"year": row.select_one("td.year").get_text(strip=True),
"승리": row.select_one("td.wins").get_text(strip=True),
"패배": row.select_one("td.losses").get_text(strip=True),
}
page_data.append(team_stats) # 추출한 팀 데이터를 리스트에 추가
return page_data
# 제로샷 분류 파이프라인 초기화
classifier = pipeline("zero-shot-classification", model="valhalla/distilbart-mnli-12-3")
# 스크랩할 모든 URL 가져오기 (기본 URL + 페이지별 URL)
all_page_urls = get_all_page_urls(BASE_URL)
all_team_data_for_zsc = [] # 분류를 위해 선택된 팀 데이터를 저장할 리스트
# 페이지 URL을 순회
for page_url in all_page_urls[:MAX_PAGES_TO_SCRAPE]:
current_page_team_data = scrape_page(page_url) # 현재 페이지에서 데이터 스크랩
# 페이지당 스크랩할 최대 팀 수
all_team_data_for_zsc.extend(current_page_team_data[:MAX_TEAMS_PER_PAGE_FOR_ZSC])
# 분류 시작
print(f"n--- {len(all_team_data_for_zsc)}개 스크랩된 하키 팀 정보 조각 분류 중 ---")
# 수집된 팀 데이터를 순회하며 각각 분류
for i, team_info_dict in enumerate(all_team_data_for_zsc):
name = team_info_dict["name"]
year = team_info_dict["year"]
wins = team_info_dict["wins"]
losses = team_info_dict["losses"]
# 분류를 위한 팀 데이터로 텍스트 스니펫 생성
text_snippet = f"팀: {name}, 연도: {year}, 승리: {wins}, 패배: {losses}."
print(f"n데이터 스니펫 {i+1}: "{text_snippet}"")
# 제로샷 분류 수행
result = classifier(text_snippet, CANDIDATE_LABELS, multi_label=False)
# 예측된 카테고리와 신뢰도 점수 출력
print(f"Predicted Category: {result['labels'][0]}")
print(f"Confidence Score: {result['scores'][0]:.4f}")아주 잘하셨습니다! 첫 번째 ZSC 프로젝트를 완료하셨습니다.
다음 명령어로 코드를 실행하세요:
python zsc_scraper.py예상 결과는 다음과 같습니다:
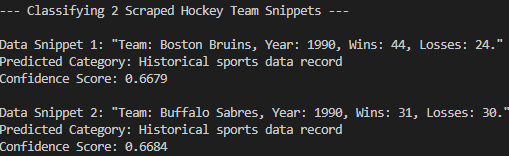
보시다시피 모델은 스크랩된 데이터를 “역사적 스포츠 데이터 기록”으로 정확히 분류했습니다. 제로샷 분류 없이는 불가능했을 것입니다. 미션 완료!
결론
이 글에서는 제로샷 분류가 무엇이며 웹 스크래핑 환경에서 이를 적용하는 방법을 배웠습니다. 웹 데이터는 끊임없이 변화하며, 사전 훈련된 LLM이 모든 것을 미리 알기를 기대할 수 없습니다. ZSC는 재훈련 없이 새로운 정보를 동적으로 분류함으로써 이러한 격차를 해소하는 데 도움을 줍니다.
그러나 진정한 도전은 신선한 데이터를 확보하는 데 있습니다.모든 웹사이트가 쉽게 스크래핑되는 것은 아니기 때문입니다. 바로 여기서 Bright Data가 등장합니다. 스크래핑 장애물을 극복하도록 설계된 강력한 도구 및 서비스 제품군을 제공합니다. 여기에는 다음이 포함됩니다.
- 웹 언락커(Web Unlocker): 스크래핑 방지 장치를 우회하여 최소한의 노력으로 모든 웹페이지의 깨끗한 HTML을 제공하는 API입니다.
- Scraping Browser: 자바스크립트 렌더링이 가능한 클라우드 기반 제어형 브라우저입니다. CAPTCHA, 브라우저 지문 인식, 재시도 등을 자동으로 처리해 줍니다. Panther 또는 Selenium PHP와 원활하게 통합됩니다.
- 웹 스크레이퍼 API: 수십 개의 인기 도메인에서 구조화된 웹 데이터에 프로그래매틱하게 접근할 수 있는 엔드포인트입니다.
머신 러닝 시나리오를 위해 AI 허브도 살펴보세요.
지금 Bright Data에 가입하고 무료 체험을 시작하여 스크래핑 솔루션을 테스트해 보세요!





