

이 가이드에서는 다음을 배울 수 있습니다:
- 데이터셋의 정의
- 데이터셋 생성 최적 방법
- 파이썬에서 데이터셋 생성 방법
- R에서 데이터셋 생성 방법
자, 시작해 보겠습니다!
데이터셋이란 무엇인가?
데이터 세트(데이터 집합)는 특정 주제, 주제 또는 산업과 관련된 데이터 모음입니다. 데이터 세트는 숫자, 텍스트, 이미지, 비디오 및 오디오를 포함한 다양한 유형의 정보를 포함할 수 있으며 CSV, JSON, XLS, XLSX 또는 SQL과 같은 형식으로 저장할 수 있습니다.
기본적으로 데이터 세트는 특정 목적을 위해 구성된 구조화된 데이터로 구성됩니다.
데이터셋 생성 5가지 핵심 전략
데이터셋을 생성하는 5가지 최고의 전략을 살펴보고, 그 작동 방식과 장단점을 분석해 보세요.
전략 #1: 작업 아웃소싱
데이터셋 생성을 위한 사업부 설립 및 운영이 현실적이지 않을 수 있습니다. 특히 내부 자원이나 시간이 부족한 경우 더욱 그렇습니다. 이러한 상황에서는 데이터셋 생성 작업을 아웃소싱하는 것이 효과적인 전략입니다.
아웃소싱은 데이터셋 생성 과정을 사내에서 처리하는 대신 외부 전문가나 전문 기관에 위임하는 것을 의미합니다. 이 접근 방식은 데이터 수집, 정리, 형식화 경험이 풍부한 전문가나 조직의 역량을 활용할 수 있게 합니다.
데이터셋 생성을 어디에 아웃소싱해야 할까요? 많은 기업들이 즉시 사용 가능한 데이터셋이나 맞춤형 데이터 수집 서비스를 제공합니다. 자세한 내용은 최고의 데이터셋 웹사이트 가이드를 참조하세요.
이러한 제공업체들은 고급 기술을 활용하여 수집된 데이터가 정확하고 귀사의 사양에 맞게 포맷되도록 보장합니다. 아웃소싱을 통해 비즈니스의 다른 중요한 측면에 집중할 수 있지만, 품질 기대치를 충족하는 신뢰할 수 있는 파트너를 선택하는 것이 필수적입니다.
장점:
- 모든 것을 걱정할 필요가 없습니다
- 어떤 사이트의 어떤 형식 데이터셋도 제공
- 과거 데이터 또는 최신 데이터
단점:
- 데이터 수집 과정을 완전히 통제할 수 없음
- GDPR 및 CCPA 규정 준수 관련 잠재적 문제
- 가장 비용 효율적인 솔루션이 아닐 수 있음
전략 #2: 공개 API를 통한 데이터 수집
소셜 미디어 네트워크부터 전자상거래 사이트에 이르기까지 많은 플랫폼이 풍부한 데이터를 노출하는 공개 API를 제공합니다. 예를 들어, X의 API는 공개 계정, 게시물 및 답글에 대한 정보에 대한 접근을 제공합니다.
공개 API에서 데이터를 검색하는 것은 데이터 세트를 생성하는 효과적인 기법입니다. 그 이유는 해당 엔드포인트가 구조화된 형식으로 데이터를 반환하여 응답에서 데이터 세트를 생성하기 쉽기 때문입니다. 당연히 API는 데이터 소싱을 위한 최고의 전략 중 하나입니다.
이러한 API를 활용하면 기존 플랫폼에서 직접 방대한 양의 신뢰할 수 있는 데이터를 신속하게 수집할 수 있습니다. 주요 단점은 API 사용 제한 및 서비스 약관을 준수해야 한다는 점입니다.
장점:
- 공식 데이터 접근 가능
- 모든 프로그래밍 언어에서의 간편한 통합
- 원본에서 직접 구조화된 데이터 획득
단점:
- 모든 플랫폼이 공개 API를 제공하는 것은 아님
- API 제공자가 부과하는 제한 사항을 준수해야 함
- 해당 API가 반환하는 데이터는 시간이 지남에 따라 변경될 수 있음
전략 #3: 공개 데이터 찾기
오픈 데이터란 대중에게 무료로 공개적으로 공유되는 데이터 세트를 의미합니다. 이 데이터는 주로 연구 및 학술 논문에서 활용되지만, 시장 분석과 같은 비즈니스 요구에도 부응할 수 있습니다.
오픈 데이터는 정부, 비영리 단체, 학술 기관 등 신뢰할 수 있는 출처에서 제공되므로 신뢰할 수 있습니다. 이러한 기관들은 사회 동향, 건강 통계, 경제 지표, 환경 데이터 등 다양한 주제를 다루는 오픈 데이터 저장소를 제공합니다.
오픈 데이터를 얻을 수 있는 대표적인 사이트는 다음과 같습니다:
- Data.gov: 미국 연방 데이터의 포괄적인 저장소입니다.
- 유럽연합 오픈 데이터 포털: 유럽 전역의 데이터셋을 제공합니다.
- World Bank Open Data: 글로벌 경제 및 개발 데이터를 제공합니다.
- UN Data: 글로벌 사회·경제 지표에 관한 다양한 데이터셋을 제공합니다.
- AWS 오픈 데이터 레지스트리: AWS 리소스를 통해 이용 가능한 데이터 세트를 발견하고 공유하는 플랫폼입니다.
오픈 데이터는 자유롭게 이용 가능한 데이터를 제공함으로써 데이터 수집의 필요성을 없애기 때문에 데이터셋을 생성하는 인기 있는 방법입니다. 그러나 프로젝트 요구 사항을 충족하는지 확인하기 위해 데이터의 품질, 완전성 및 라이선스 조건을 검토해야 합니다.
장점:
- 무료 데이터
- 즉시 사용 가능한 대규모 완전한 데이터셋
- 정부 기관과 같은 신뢰할 수 있는 출처에서 제공하는 데이터 세트
단점:
- 일반적으로 과거 데이터만 접근 가능
- 비즈니스에 유용한 인사이트를 얻기 위해 일부 작업이 필요함
- 관심 있는 데이터를 찾지 못할 수도 있음
전략 #4: GitHub에서 데이터셋 다운로드
GitHub에는 머신러닝, 데이터 사이언스부터 소프트웨어 개발 및 연구에 이르기까지 다양한 목적을 위한 데이터셋을 포함한 수많은 저장소가 호스팅됩니다. 이러한 데이터셋은 피드백을 받고 커뮤니티에 기여하기 위해 개인 및 조직이 공유합니다.
경우에 따라 이러한 GitHub 저장소에는 데이터 처리, 분석 및 탐색을 위한 코드도 포함되어 있습니다.
데이터셋을 얻을 수 있는 주목할 만한 저장소로는 다음과 같습니다:
- Awesome Public Datasets: 금융, 기후, 스포츠 등 다양한 분야의 고품질 데이터셋을 선별하여 모아둔 컬렉션입니다. 특정 주제나 산업과 관련된 데이터셋을 찾는 허브 역할을 합니다.
- Kaggle 데이터셋: 데이터 과학 경연의 주요 플랫폼인 Kaggle은 일부 데이터셋을 GitHub에 호스팅합니다. 사용자는 GitHub 저장소에서 시작하여 몇 번의 클릭만으로 Kaggle 데이터셋을 생성할 수 있습니다.
- 기타 오픈 데이터 저장소: 여러 기관 및 연구 그룹이 GitHub를 활용해 오픈 데이터셋을 호스팅합니다.
이러한 저장소는 기존 데이터셋을 제공하여 필요에 따라 바로 사용하거나 수정할 수 있습니다. 접근은 단일 git clone 명령어나 “다운로드” 버튼 클릭만으로 가능합니다.
장점:
- 즉시 사용 가능한 데이터셋
- 데이터 분석 및 상호작용을 위한 코드
- 다양한 범주의 데이터 선택 가능
단점:
- 잠재적인 라이선스 문제
- 대부분의 저장소가 최신 상태가 아님
- 일반적인 데이터로 특정 요구사항에 맞지 않음
전략 #5: 웹 스크래핑으로 자체 데이터셋 생성하기
웹 스크래핑은 웹 페이지에서 데이터를 추출하여 사용 가능한 형식으로 변환하는 과정입니다.
웹 스크래핑을 통한 데이터셋 생성은 다음과 같은 이유로 널리 사용되는 접근 방식입니다:
- 방대한 데이터 접근성: 웹은 세계 최대의 데이터 원천입니다. 스크래핑을 통해 이 방대한 자원을 활용하여 다른 방법으로는 얻을 수 없는 정보를 수집할 수 있습니다.
- 유연성: 수집할 데이터, 데이터셋 생성 형식, 데이터 업데이트 주기 등을 자유롭게 선택할 수 있습니다.
- 맞춤화: 공개 데이터셋에서 다루지 않는 틈새 시장이나 전문 주제의 데이터 추출과 같이 특정 요구 사항에 맞게 데이터 추출을 조정할 수 있습니다.
웹 스크래핑의 일반적인 작동 방식은 다음과 같습니다:
- 대상 사이트 식별
- 웹 페이지를 분석하여 데이터 추출 전략 수립
- 대상 페이지에 연결할 스크립트 생성
- 페이지의 HTML 콘텐츠를 파싱합니다
- 관심 데이터가 포함된 DOM 요소 선택
- 해당 요소에서 데이터를 추출합니다
- 수집한 데이터를 JSON, CSV, XLSX 등 원하는 형식으로 내보내기
웹 스크래핑 스크립트는 Python, JavaScript, Ruby 등 거의 모든 프로그래밍 언어로 작성할 수 있습니다. 웹 스크래핑에 가장 적합한 언어에 대한 자세한 내용은 당사 기사에서 확인하세요. 또한 웹 스크래핑에 가장 적합한 도구도 살펴보시기 바랍니다.
대부분의 기업은 자사 사이트에서 공개적으로 접근 가능하더라도 데이터의 가치를 잘 알고 있으므로, 봇 방지 기술로 이를 보호합니다. 이러한 솔루션은 스크립트가 생성하는 자동화된 요청을 차단할 수 있습니다. 차단되지 않고 웹 스크래핑을 수행하는 방법에 대한 튜토리얼에서 이러한 조치를 우회하는 방법을 확인하세요.
또한 웹 스크래핑이 공개 API를 통한 데이터 수집과 어떻게 다른지 궁금하다면, 웹 스크래핑 대 API 비교 글을 확인해 보세요.
장점:
- 모든 사이트의 공개 데이터
- 데이터 추출 과정을 직접 제어 가능
- 대부분의 프로그래밍 언어로 작동하는 비용 효율적인 솔루션
단점:
- 봇 방지 및 스크래핑 방지 솔루션으로 인해 차단될 수 있음
- 일부 유지 관리가 필요함
- 사용자 정의 데이터 집계 로직이 필요할 수 있음
파이썬에서 데이터셋 생성 방법
파이썬은 데이터 과학 분야의 선도적인 언어로, 데이터셋 생성에도 널리 사용됩니다. 곧 보시게 될 것처럼 파이썬에서 데이터셋을 만드는 데는 몇 줄의 코드만으로도 충분합니다.
여기서는 Bright Data 데이터셋 마켓플레이스에서 이용 가능한 모든 데이터셋에 대한 정보를 스크래핑하는 방법에 집중하겠습니다:
목표를 달성하기 위해 단계별 튜토리얼을 따라가 보세요!
더 자세한 방법론은 Python 웹 스크래핑 가이드를 참고하세요.
1단계: 설치 및 설정
사용자의 컴퓨터에 Python 3 이상이 설치되어 있고 Python 프로젝트가 설정되어 있다고 가정합니다.
먼저, 이 프로젝트에 필요한 라이브러리를 설치해야 합니다:
- requests: HTTP 요청을 보내고 웹 페이지와 관련된 HTML 문서를 가져오기 위한 라이브러리입니다.
- Beautiful Soup: HTML 및 XML 문서 파싱과 웹 페이지에서 데이터 추출을 위한 라이브러리입니다.
- pandas: 데이터 조작 및 CSV 데이터셋으로 내보내기.
프로젝트 폴더 내 활성화된 가상 환경에서 터미널을 열고 다음 명령어를 실행하세요:
pip install requests beautifulsoup4 pandas설치가 완료되면 Python 스크립트에 다음 라이브러리를 임포트할 수 있습니다:
import requests
from bs4 import BeautifulSoup
import pandas as pd2단계: 대상 사이트에 연결
데이터를 추출하려는 페이지의 HTML을 가져옵니다. requests 라이브러리를 사용하여 대상 사이트에 HTTP 요청을 보내 HTML 콘텐츠를 가져옵니다:
url = 'https://brightdata.com/products/datasets'
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36' }
response = requests.get(url=url, headers=headers)자세한 내용은 Python requests에서 사용자 에이전트 설정 방법 가이드를 참조하세요.
3단계: 스크래핑 로직 구현
HTML 콘텐츠를 확보한 후 BeautifulSoup을 사용하여 파싱하고 필요한 데이터를 추출합니다. 관심 데이터가 포함된 HTML 요소를 선택하고 해당 데이터들을 가져옵니다:
# 가져온 HTML 파싱
soup = BeautifulSoup(response.text, 'html.parser')
# 스크래핑된 데이터 저장 위치
data = []
# 스크래핑 로직
dataset_elements = soup.select('.datasets__loop .datasets__item--wrapper')
for dataset_element in dataset_elements:
dataset_item = dataset_element.select_one('.datasets__item')
title = dataset_item.select_one('.datasets__item--title').text.strip()
url_item = dataset_item.select_one('.datasets__item--title a')
if (url_item is not None):
url = url_item['href']
else:
url = None
type = dataset_item.get('aria-label', 'regular').lower()
data.append({
'title': title,
'url': url,
'type': type
})4단계: CSV로 내보내기
pandas를 사용하여 스크랩한 데이터를 DataFrame 으로 변환하고 CSV 파일로 내보냅니다.
df = pd.DataFrame(data, columns=data[0].keys())
df.to_csv('dataset.csv', index=False)5단계: 스크립트 실행
최종 Python 스크립트에는 다음 코드 줄이 포함됩니다:
import requests
from bs4 import BeautifulSoup
import pandas as pd
# 사용자 정의 사용자 에이전트로 대상 사이트에 GET 요청 수행
url = 'https://brightdata.com/products/datasets'
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36' }
response = requests.get(url=url, headers=headers)
# 가져온 HTML 파싱
soup = BeautifulSoup(response.text, 'html.parser')
# 스크래핑된 데이터 저장 위치
data = []
# 스크래핑 로직
dataset_elements = soup.select('.datasets__loop .datasets__item--wrapper')
for dataset_element in dataset_elements:
dataset_item = dataset_element.select_one('.datasets__item')
title = dataset_item.select_one('.datasets__item--title').text.strip()
url_item = dataset_item.select_one('.datasets__item--title a')
if (url_item is not None):
url = url_item['href']
else:
url = None
type = dataset_item.get('aria-label', 'regular').lower()
data.append({
'title': title,
'url': url,
'type': type
})
# CSV로 내보내기
df = pd.DataFrame(data, columns=data[0].keys())
df.to_csv('dataset.csv', index=False)실행하면 프로젝트 폴더에 다음과 같은 dataset.csv 파일이 생성됩니다:
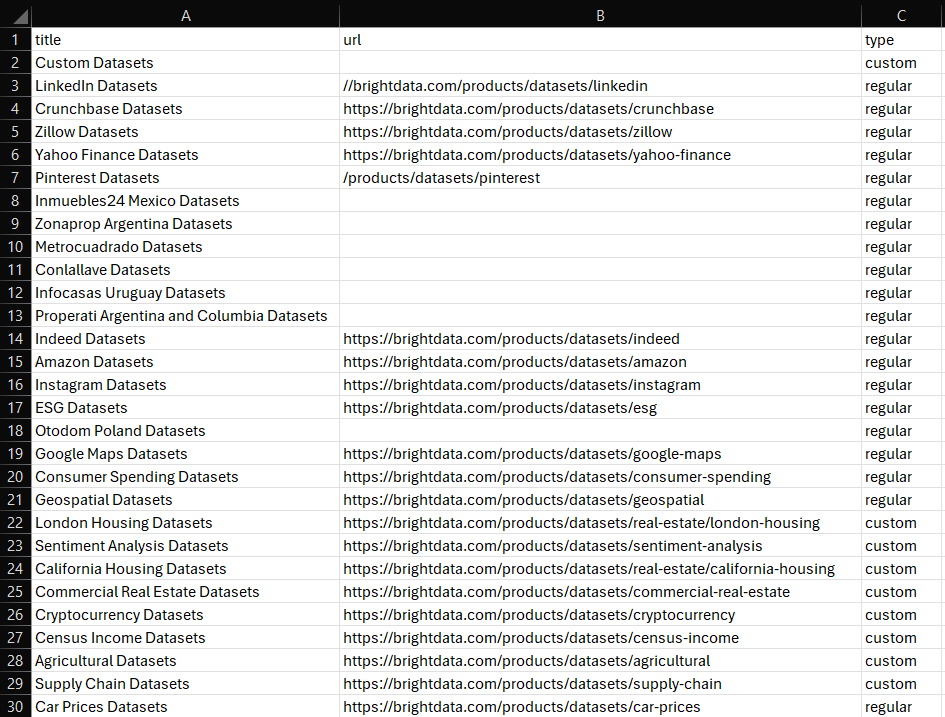
자, 이제 Python으로 데이터셋을 만드는 방법을 알게 되었습니다.
R에서 데이터셋 생성 방법
R은 연구자와 데이터 과학자들이 널리 사용하는 또 다른 언어입니다. 아래는 앞서 Python에서 본 것과 동등한 R 데이터셋 생성 스크립트입니다:
library(httr)
library(rvest)
library(dplyr)
library(readr)
# 사용자 지정 에이전트로 대상 사이트에 GET 요청 수행
url <- "https://brightdata.com/products/datasets"
headers <- add_headers(`User-Agent` = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36")
response <- GET(url, headers)
# 가져온 HTML 파싱
page <- read_html(response)
# 스크랩된 데이터 저장 위치
data <- tibble()
# 스크래핑 로직
dataset_elements <- page %>%
html_nodes(".datasets__loop .datasets__item--wrapper")
for (dataset_element in dataset_elements) {
title <- dataset_element %>%
html_node(".datasets__item .datasets__item--title") %>%
html_text(trim = TRUE)
url_item <- dataset_element %>%
html_node(".datasets__item .datasets__item--title a")
url <- if (!is.null(url_item)) {
html_attr(url_item, "href")
} else {
""
}
type <- dataset_element %>%
html_attr("aria-label", "regular") %>%
tolower()
data <- bind_rows(data, tibble(
title = title,
url = url,
type = type
))
}
# CSV로 내보내기
write_csv(data, "dataset.csv")더 자세한 안내는 R을 이용한 웹 스크래핑 튜토리얼을 참고하세요.
결론
이 블로그 글에서는 데이터셋 생성 방법을 배웠습니다. 데이터셋의 개념을 이해하고 생성 전략을 탐구했으며, Python과 R에서 웹 스크래핑 전략을 적용하는 방법도 살펴보았습니다.
Bright Data는 포춘 500대 기업 및 20,000명 이상의 고객사가 이용하는 대규모, 고속, 안정적인 프록시 네트워크를 운영합니다. 이 네트워크는 웹에서 윤리적으로 데이터를 수집하여 방대한 데이터셋 마켓플레이스에 제공하는 데 활용되며, 여기에는 다음이 포함됩니다:
- 비즈니스 데이터셋: LinkedIn, CrunchBase, Owler, Indeed 등 주요 출처의 데이터.
- 이커머스 데이터셋: Amazon, Walmart, Target, Zara, Zalando, Asos 등 다양한 플랫폼의 데이터.
- 부동산 데이터셋: 질로우(Zillow), MLS 등 웹사이트의 데이터.
- 소셜 미디어 데이터셋: Facebook, Instagram, YouTube, Reddit 등에서 수집한 데이터.
- 금융 데이터셋: 야후 파이낸스, 마켓워치, 인베스토피디아 등에서 수집한 데이터.
이러한 사전 제작된 옵션이 귀하의 요구를 충족하지 못하는 경우, 당사의 맞춤형 데이터 수집 서비스를 고려해 보십시오.
또한 Bright Data는 웹 스크레이퍼 API 및 스크레이핑 브라우저를 비롯한 다양한 강력한 스크레이핑 도구를 제공합니다.
지금 가입하여 Bright Data의 제품과 서비스 중 귀하의 요구에 가장 적합한 것을 확인해 보십시오.




