

웹 스크래핑 시 HTML 파싱은 사용하는 도구에 관계없이 필수적입니다.자바를 이용한 웹 스크래핑도 예외는 아닙니다. 파이썬에서는Requests나BeautifulSoup 같은 도구를 사용합니다. 자바에서는jsoup을 활용해 HTTP 요청을 전송하고 HTML을 파싱할 수 있습니다. 본 튜토리얼에서는Books to Scrape를사용하겠습니다.
시작하기
이 튜토리얼에서는 의존성 관리를 위해 Maven을 사용할 것입니다. 아직 설치하지 않았다면여기에서 Maven을 설치할 수 있습니다.
Maven 설치 후 새 Java 프로젝트를 생성해야 합니다. 아래 명령어로 jsoup-scraper 프로젝트를 생성합니다.
mvn archetype:generate -DgroupId=com.example -DartifactId=jsoup-scraper -DarchetypeArtifactId=maven-archetype-quickstart -DinteractiveMode=false
다음으로 관련 종속성을 추가해야 합니다.pom.xml의코드를 아래 코드로 교체하세요. 이는Rust의Cargo 종속성 관리와 유사합니다.
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.example</groupId>
<artifactId>jsoup-scraper</artifactId>
<packaging>jar</packaging>
<version>1.0-SNAPSHOT</version>
<name>jsoup-scraper</name>
<url>http://maven.apache.org</url>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.16.1</version>
</dependency>
</dependencies>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
</properties>
</project>
다음 코드를 App.java에 붙여넣으세요. 많지는 않지만, 우리가 만들 기본 스크레이퍼입니다.
package com.example;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class App {
public static void main(String[] args) {
String url = "https://books.toscrape.com";
int pageCount = 1;
while (pageCount <= 1) {
try {
System.out.println("---------------------PAGE "+pageCount+"--------------------------");
//웹사이트에 연결하여 HTML 가져오기
Document doc = Jsoup.connect(url).get();
//제목 출력
System.out.println("페이지 제목: " + doc.title());
} catch (Exception e) {
e.printStackTrace();
}
}
System.out.println("스크랩된 총 페이지 수: "+(pageCount-1));
}
}
Jsoup.connect("https://books.toscrape.com").get(): 이 줄은 페이지를 가져와 조작 가능한Document객체를 반환합니다.doc.title()은 HTML 문서의 제목을 반환합니다. 이 경우:All products | Books to Scrape - Sandbox.
Jsoup을 사용한 DOM 메서드 활용
jsoup에는 DOM(문서 객체 모델)에서 요소를 찾는 다양한 메서드가 포함되어 있습니다. 다음 중 어떤 것을 사용해도 페이지 요소를 쉽게 찾을 수 있습니다.
getElementById():ID를사용하여 요소를 찾습니다.getElementsByClass(): CSS 클래스를 사용하여 모든 요소를 찾습니다.getElementsByTag(): HTML 태그를 사용하여 모든 요소를 찾습니다.getElementsByAttribute(): 특정 속성을 포함하는 모든 요소 찾기.
getElementById
대상 사이트에서 사이드바에는 promotions_left라는 ID를 가진 div가 포함되어 있습니다. 아래 이미지에서 확인할 수 있습니다.
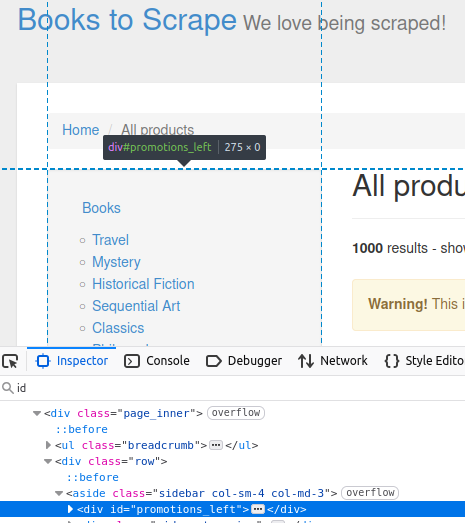
//ID로 가져오기
Element sidebar = doc.getElementById("promotions_left");
System.out.println("사이드바: " + sidebar);
이 코드는 페이지 검사기에서 볼 수 있는 HTML 요소를 출력합니다.
사이드바: <div id="promotions_left">
</div>
getElementsByTag()
getElementsByTag() 는 특정 태그를 가진 페이지의 모든 요소를 찾을 수 있게 합니다. 이 페이지의 책을 살펴보겠습니다.
각 책은 고유한 article 태그에 포함되어 있습니다.
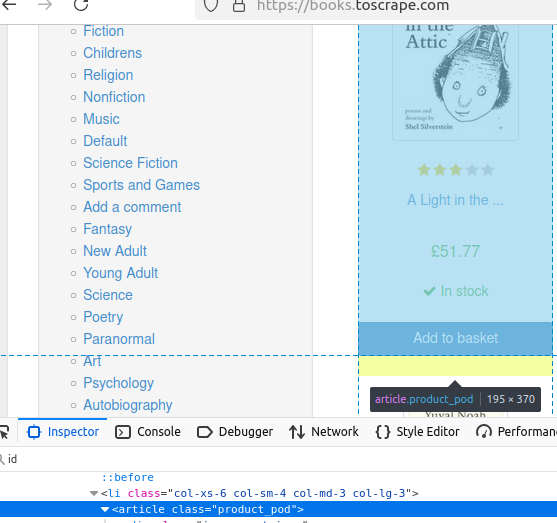
아래 코드는 아무것도 출력하지 않지만, 책들의 배열을 반환합니다. 이 책들은 나머지 데이터의 기반이 될 것입니다.
//태그로 가져오기
Elements books = doc.getElementsByTag("article");
getElementsByClass
책의 가격을 살펴보겠습니다. 강조 표시된 대로, 해당 클래스는 price_color입니다.
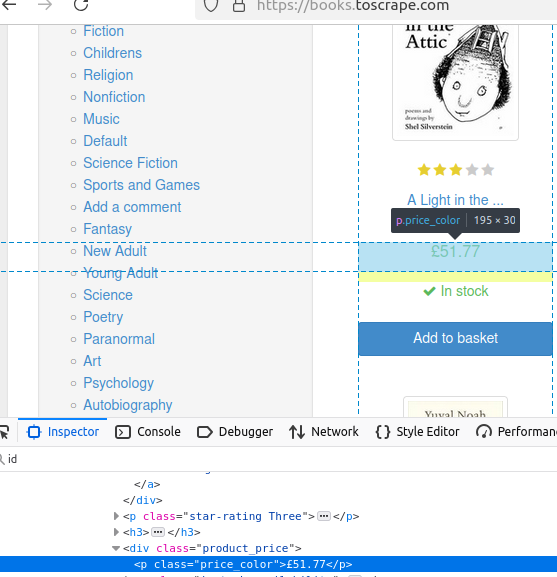
이 코드 조각에서는 price_color 클래스의 모든 요소를 찾습니다. 그런 다음 .first().text()를 사용하여 첫 번째 요소의 텍스트를 출력합니다.
System.out.println("가격: " + book.getElementsByClass("price_color").first().text());
getElementsByAttribute
아시다시피 모든 a 요소는 href 속성이 필요합니다. 아래 코드에서는 getElementsByAttribute("href") 를 사용해 href 속성이 있는 모든 요소를 찾습니다. .first().attr("href") 를 사용해 해당 href를 반환합니다.
//속성으로 가져오기
Elements hrefs = book.getElementsByAttribute("href");
System.out.println("링크: https://books.toscrape.com/" + hrefs.first().attr("href"));
고급 기법
CSS 선택자
여러 기준을 사용하여 요소를 찾으려면select()메서드에 CSS 선택자를전달할 수 있습니다. 이 메서드는 선택자와 일치하는 모든 객체의 배열을 반환합니다. 아래에서는li[class='next']를사용하여next클래스를 가진 모든li항목을 찾습니다.
Elements nextPage = doc.select("li[class='next']");
페이지네이션 처리
페이지 매김을 처리하기 위해 nextPage.first()를 사용하여 배열에서 반환된 첫 번째 요소에 대해 getElementsByAttribute("href").attr("href")를 호출하고 href를 추출합니다. 흥미롭게도 2페이지 이후부터는 링크에서 'catalogue' 단어가 제거되므로, href에 이 단어가 포함되어 있지 않으면 다시 추가합니다. 그런 다음 이 링크를 기본 URL과 결합하여 다음 페이지 링크를 얻습니다.
if (!nextPage.isEmpty()) {
String nextUrl = nextPage.first().getElementsByAttribute("href").attr("href");
if (!nextUrl.contains("catalogue")) {
nextUrl = "catalogue/"+nextUrl;
}
url = "https://books.toscrape.com/" + nextUrl;
pageCount++;
}
모든 것을 합치기
다음은 최종 코드입니다. 여러 페이지를 스크래핑하려면 while (pageCount <= 1) 내부의 1을 원하는 목표 수치로 변경하세요. 4페이지를 스크래핑하려면 while (pageCount <= 4)를 사용하세요.
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class App {
public static void main(String[] args) {
String url = "https://books.toscrape.com";
int pageCount = 1;
while (pageCount <= 1) {
try {
System.out.println("---------------------PAGE "+pageCount+"--------------------------");
//웹사이트 연결 및 HTML 가져오기
Document doc = Jsoup.connect(url).get();
//제목 출력
System.out.println("페이지 제목: " + doc.title());
//ID로 요소 가져오기
Element sidebar = doc.getElementById("promotions_left");
System.out.println("사이드바: " + sidebar);
// 태그로 가져옴
Elements books = doc.getElementsByTag("article");
for (Element book : books) {
System.out.println("------책------");
System.out.println("제목: " + book.getElementsByTag("img").first().attr("alt"));
System.out.println("가격: " + book.getElementsByClass("price_color").first().text());
System.out.println("재고 상태: " + book.getElementsByClass("instock availability").first().text());
// 속성으로 가져오기
Elements hrefs = book.getElementsByAttribute("href");
System.out.println("링크: https://books.toscrape.com/" + hrefs.first().attr("href"));
}
// CSS 선택자로 다음 버튼 찾기
Elements nextPage = doc.select("li[class='next']");
if (!nextPage.isEmpty()) {
String nextUrl = nextPage.first().getElementsByAttribute("href").attr("href");
if (!nextUrl.contains("catalogue")) {
nextUrl = "catalogue/"+nextUrl;
}
url = "https://books.toscrape.com/" + nextUrl;
pageCount++;
}
} catch (Exception e) {
e.printStackTrace();
}
}
System.out.println("총 스크랩된 페이지 수: "+(pageCount-1));
}
}
코드를 실행하기 전에 컴파일하는 것을 잊지 마세요.
mvn package
다음 명령어로 실행하세요.
mvn exec:java -Dexec.mainClass="com.example.App"
첫 페이지의 출력 결과입니다.
---------------------PAGE 1--------------------------
페이지 제목: 모든 상품 | 스크래핑 대상 도서 - 샌드박스
사이드바: <div id="promotions_left">
</div>
------도서------
제목: 다락방의 빛
가격: £51.77
재고 상태: 재고 있음
링크: https://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html
------도서------
제목: 벨벳을 뒤집다
가격: £53.74
재고 상태: 재고 있음
링크: https://books.toscrape.com/catalogue/tipping-the-velvet_999/index.html
------도서------
제목: 복종
가격: £50.10
재고 상태: 재고 있음
링크: https://books.toscrape.com/catalogue/soumission_998/index.html
------도서------
제목: 날카로운 물건들
가격: £47.82
재고 상태: 재고 있음
링크: https://books.toscrape.com/catalogue/sharp-objects_997/index.html
------도서------
제목: 사피엔스: 인류의 짧은 역사
가격: £54.23
재고 상태: 재고 있음
링크: https://books.toscrape.com/catalogue/sapiens-a-brief-history-of-humankind_996/index.html
------도서------
제목: 레퀴엠 레드
가격: £22.65
재고 상태: 재고 있음
링크: https://books.toscrape.com/catalogue/the-requiem-red_995/index.html
------도서------
제목: 꿈의 직장을 얻는 더러운 작은 비밀들
가격: £33.34
재고 상태: 재고 있음
링크: https://books.toscrape.com/catalogue/the-dirty-little-secrets-of-getting-your-dream-job_994/index.html
------도서------
제목: 다가오는 여성: 악명 높은 페미니스트 빅토리아 우드헐의 삶을 바탕으로 한 소설
가격: £17.93
재고 상태: 재고 있음
링크: https://books.toscrape.com/catalogue/the-coming-woman-a-novel-based-on-the-life-of-the-infamous-feminist-victoria-woodhull_993/index.html
------도서------
제목: 보트 위의 소년들: 1936년 베를린 올림픽에서 금메달을 향한 아홉 미국인의 위대한 도전
가격: £22.60
재고 상태: 재고 있음
링크: https://books.toscrape.com/catalogue/the-boys-in-the-boat-nine-americans-and-their-epic-quest-for-gold-at-the-1936-berlin-olympics_992/index.html
------도서------
제목: 검은 마리아
가격: £52.15
재고 상태: 재고 있음
링크: https://books.toscrape.com/catalogue/the-black-maria_991/index.html
------도서------
제목: 굶주린 심장들 (삼각 무역 3부작, #1)
가격: £13.99
재고 상태: 재고 있음
링크: https://books.toscrape.com/catalogue/starving-hearts-triangular-trade-trilogy-1_990/index.html
------도서------
제목: 셰익스피어의 소네트
가격: £20.66
재고 상태: 재고 있음
링크: https://books.toscrape.com/catalogue/shakespeares-sonnets_989/index.html
------도서------
제목: 나를 자유롭게 해줘
가격: £17.46
재고 상태: 재고 있음
링크: https://books.toscrape.com/catalogue/set-me-free_988/index.html
------도서------
제목: 스캇 필그림의 소중한 작은 인생 (스캇 필그림 #1)
가격: £52.29
재고 상태: 재고 있음
링크: https://books.toscrape.com/catalogue/scott-pilgrims-precious-little-life-scott-pilgrim-1_987/index.html
------도서------
제목: 찢어버리고 다시 시작해
가격: £35.02
재고 상태: 재고 있음
링크: https://books.toscrape.com/catalogue/rip-it-up-and-start-again_986/index.html
------책------
제목: 우리 밴드가 당신의 인생이 될 수 있다: 미국 인디 언더그라운드의 풍경, 1981-1991
가격: £57.25
재고 상태: 재고 있음
링크: https://books.toscrape.com/catalogue/our-band-could-be-your-life-scenes-from-the-american-indie-underground-1981-1991_985/index.html
------도서------
제목: 올리오
가격: £23.88
재고 상태: 재고 있음
링크: https://books.toscrape.com/catalogue/olio_984/index.html
------도서------
제목: 메사리온: 최고의 공상과학 소설 선집 1800-1849
가격: £37.59
재고 상태: 재고 있음
링크: https://books.toscrape.com/catalogue/mesaerion-the-best-science-fiction-stories-1800-1849_983/index.html
------도서------
제목: 초보자를 위한 자유지상주의
가격: £51.33
재고 상태: 재고 있음
링크: https://books.toscrape.com/catalogue/libertarianism-for-beginners_982/index.html
------도서------
제목: 히말라야 산맥일 뿐이야
가격: £45.17
재고 상태: 재고 있음
링크: https://books.toscrape.com/catalogue/its-only-the-himalayas_981/index.html
스크랩된 총 페이지 수: 1
결론
jsoup을 사용해 HTML 데이터를 추출하는 방법을 배웠으니, 이제 더 고급 웹 스크레이퍼를 구축할 수 있습니다. 제품 목록, 뉴스 기사, 연구 데이터를 스크레이핑하든, 동적 콘텐츠 처리와 차단 회피가 핵심 과제입니다.
스크래핑 작업을 효율적으로 확장하려면 Bright Data의 도구를 활용해 보세요:
- 주거용 프록시 – IP 차단 회피 및 지역 제한 콘텐츠 접근.
- 스크래핑 브라우저 – 자바스크립트 중심 사이트를 손쉽게 렌더링합니다.
- 즉시 사용 가능한 데이터셋 – 스크래핑 과정 없이 구조화된 데이터를 즉시 확보하세요.
jsoup을 적절한 인프라와 결합하면 탐지 위험을 최소화하면서 대규모 데이터 추출이 가능합니다. 웹 스크래핑을 한 단계 업그레이드할 준비가 되셨나요? 지금 가입하여 무료 체험을 시작하세요.





