이 Scrapy 대 Requests 가이드에서는 다음을 확인할 수 있습니다:
- Scrapy와 Requests의 정의
- 웹 스크래핑을 위한 Scrapy와 Requests 비교
- 페이지네이션 시나리오에서의 Scrapy와 Requests 비교
- 웹 스크래핑 시나리오에서 Scrapy와 Requests의 공통적 한계점
자, 시작해 보겠습니다!
Requests란 무엇인가?
Requests는HTTP 요청을 보내는 파이썬 라이브러리입니다. 일반적으로BeautifulSoup과 같은 HTML 파싱 라이브러리와 함께 웹 스크래핑에 널리 사용됩니다.
웹 스크래핑을 위한 Requests의 주요 기능은 다음과 같습니다:
- HTTP 메서드 지원: 웹 페이지 및 API와 상호작용하는 데 필수적인
GET,POST,PUT,PATCH,DELETE등 주요 HTTP 메서드를 모두 사용할 수 있습니다. - 사용자 정의 헤더: 사용자 정의 헤더(예:
User-Agent등)를 설정하여 실제 브라우저를 모방하거나 기본 인증을 처리할 수 있습니다. - 세션 관리:
requests.Session()객체를 사용하면 여러 요청에 걸쳐 쿠키와 헤더를 유지할 수 있습니다. 이는 로그인이 필요한 웹사이트를 스크래핑하거나 세션 상태를 유지하는 데 유용합니다. - 타임아웃 및 오류 처리: 요청이 멈추는 것을 방지하기 위해 타임아웃을 설정하고, 견고한 스크래핑을 위해 예외를 처리할 수 있습니다.
- 프록시 지원: 프록시를 통해 요청을 라우팅할 수 있어 IP 차단 우회 및 지역 제한 콘텐츠 접근에 유용합니다.
Scrapy란 무엇인가요?
Scrapy는파이썬으로 작성된 오픈소스 웹 스크래핑 프레임워크입니다. 웹사이트에서 데이터를 빠르고 효율적이며 확장 가능한 방식으로 추출하기 위해 설계되었습니다.
Scrapy는 웹사이트 크롤링, 데이터 추출 및 다양한 형식(예: JSON, CSV 등)으로 저장하기 위한 완벽한 프레임워크를 제공합니다. 크롤링 규칙을 준수하면서 복잡한 크롤링 작업과 동시 요청을 처리할 수 있으므로 대규모 웹 스크래핑 프로젝트에 특히 유용합니다.
웹 스크래핑을 위한 Scrapy의 주요 기능은 다음과 같습니다:
- 내장형 웹 크롤링: Scrapy는웹 크롤러로 설계되었습니다. 이는 웹페이지의 링크를 자동으로 따라갈 수 있어 최소한의 노력으로 여러 페이지나 전체 사이트를 스크래핑할 수 있음을 의미합니다.
- 비동기 요청: 비동기 아키텍처를 사용하여 여러 요청을 동시에 처리합니다. 이로 인해
requests와같은Python HTTP 클라이언트보다훨씬 빠릅니다. - 데이터 추출을 위한 선택기: Scrapy는 XPath 및 CSS 선택기를 사용하여 HTML에서 데이터를 추출할 수 있는 기능을 제공합니다.
- 사용자 정의용 미들웨어: 요청 및 응답 처리 방식을 맞춤 설정할 수 있는 미들웨어를 지원합니다.
- 자동 스로틀링: 대상 서버의 과부하를 방지하기 위해 요청을 자동으로 스로틀링할 수 있습니다. 즉, 서버 응답 시간과 부하에 따라 크롤링 속도를 조정할 수 있습니다.
robots.txt처리:웹 스크래핑 시robots.txt파일을 준수하여 스크래핑 활동이 사이트 규칙을 따르도록 보장합니다.- 프록시 및 사용자 에이전트 로테이션: Scrapy는 미들웨어를 통해프록시 로테이션과
사용자 에이전트로테이션을지원하여 IP 차단 및 탐지를 방지합니다.
Scrapy vs Requests: 웹 스크래핑 기능 비교
Requests와 Scrapy가 무엇인지 알아보았으니, 이제 웹 스크래핑에서의 활용 방식을 심층 비교해 보겠습니다:
| 기능 | Scrapy | Requests |
|---|---|---|
| 사용 사례 | 대규모 및 복잡한 스크래핑 프로젝트 | 간단한 웹 스크래핑 작업 및 프로토타입 |
| 비동기 요청 | 비동기 요청에 대한 내장 지원 | 내장 지원 없음 |
| 크롤링 | 링크를 자동으로 추적하고 여러 페이지를 크롤링 | 크롤링을 위한 수동 구현 필요 |
| 데이터 추출 | XPath 및 CSS 선택자에 대한 내장 지원 | 데이터 추출 관리를 위한 외부 라이브러리 필요 |
| 동시성 | 기본적으로 여러 요청을 동시에 처리 | 동시성 요청 관리를 위해 외부 통합 필요 |
| 미들웨어 | 프록시, 재시도 및 헤더 처리를 위한 사용자 정의 가능한 미들웨어 | 내장 미들웨어 없음 |
| 스로틀링 | 서버 과부하 방지를 위한 내장 자동 스로틀링 | 내장된 스로틀링 없음 |
| 프록시 로테이션 | 미들웨어를 통한 프록시 로테이션 지원 | 수동 구현 필요 |
| 오류 처리 | 실패한 요청에 대한 내장 재시도 메커니즘 | 수동 구현 필요 |
| 파일 다운로드 | 파일 다운로드를 지원하지만 추가 설정이 필요합니다 | 간단하고 직관적인 파일 다운로드 지원 |
사용 사례
Scrapy는 대규모 및 복잡한 스크래핑 프로젝트를 위한 완전한 웹 스크래핑 프레임워크입니다. 여러 페이지 크롤링, 동시 요청, 구조화된 형식의 데이터 내보내기가 포함된 작업에 이상적입니다.
반면 Requests는 HTTP 요청을 관리하는 라이브러리입니다. 따라서 단일 웹페이지 가져오기, API 상호작용, 파일 다운로드와 같은 간단한 작업에 더 적합합니다.
비동기 요청과 동시성
Scrapy는 Python용 이벤트 기반 네트워킹 프레임워크인Twisted를 기반으로 구축되었습니다. 이는 비동기 및 다중 요청을 동시에 처리할 수 있어 대규모 스크래핑에 훨씬 빠릅니다.
반면 Requests는 기본적으로 비동기 또는 동시 요청을 지원하지 않습니다. 비동기 HTTP 요청을 수행하려면GRequests와 통합할 수 있습니다.
크롤링
ROBOTSTXT_OBEY설정이True로 설정된 경우, Scrapy는robots.txt파일을 읽고, 웹 페이지에서 허용된 링크를 자동으로 따라가며, 허용된 페이지를 크롤링합니다.
Requests에는 내장된 크롤링 기능이 없으므로 링크를 수동으로 정의하고 추가 요청을 수행해야 합니다.
데이터 추출
Scrapy는XPath 및 CSS 선택기를 사용한 데이터 추출을 기본적으로 지원하므로 HTML 및 XML을 쉽게 파싱할 수 있습니다.
Requests에는 데이터 추출 기능이 포함되어 있지 않습니다.데이터를 파싱하고 추출하려면 BeautifulSoup과 같은 외부 라이브러리를 사용해야 합니다.
미들웨어
Scrapy는프록시,재시도,헤더 등을 처리하기 위한 사용자 정의 가능한 미들웨어를 제공합니다. 이를 통해 고급 스크래핑 작업에 대한 확장성이 매우 뛰어납니다.
반면 Requests는 미들웨어를 지원하지 않으므로프록시 로테이션이나재시도 같은 기능을 수동으로 구현해야 합니다.
스로틀링
Scrapy에는 서버 응답 시간과 부하에 따라 크롤링 속도를 조정하는 자동 스로틀링 기능이 내장되어 있습니다. 이를 통해 대상 서버에 HTTP 요청이 과도하게 유입되는 것을 방지할 수 있습니다.
Requests에는 스로틀링 기능이 내장되어 있지 않습니다. 스로틀링을 구현하려면 요청 사이에 수동으로 지연을 추가해야 합니다(예: time.sleep() 메서드 사용).
프록시 로테이션
Scrapy는 미들웨어를 통해 프록시 로테이션을 지원하므로 IP 차단 방지와 익명 사이트 스크래핑이 용이합니다.
Requests는 기본적으로 프록시 로테이션 기능을 제공하지 않습니다.Requests로 프록시를 관리하려면가이드에 설명된 대로 프록시를 수동으로 구성하고 사용자 정의 로직을 작성해야 합니다.
오류 처리
Scrapy는실패한 요청에 대한 재시도 메커니즘을 내장하여 네트워크 오류나 서버 문제를 처리하는 데 견고합니다.
반대로 Requests는try-except블록을 사용하는 등 오류와 예외를 수동으로 처리해야 합니다.retry-requests와 같은 라이브러리도 고려해 보세요.
파일 다운로드
Scrapy는FilesPipeline을통한 파일 다운로드를 지원하지만, 대용량 파일이나 스트리밍을 처리하려면 추가 설정이 필요합니다.
Requests는 requests.get() 메서드에 stream=True 매개 변수를 사용하여 간단하고 직관적인 파일 다운로드 기능을 제공합니다.
Scrapy vs Requests: 페이지네이션 시나리오에서 두 라이브러리 비교
이제 Requests와 Scrapy가 무엇인지 알게 되었습니다. 특정 웹 스크래핑 시나리오에 대한 단계별 튜토리얼 비교를 볼 준비를 하세요!
이 두 라이브러리를 페이지네이션 시나리오에서 비교하는 데 초점을 맞출 것입니다.웹 스크래핑에서 페이지네이션을 처리하려면여러 페이지에서 링크를 추적하고 데이터를 추출하기 위한 맞춤형 로직이 필요합니다.
대상 사이트는Quotes to Scrape로, 유명 작가들의 명언을 여러 페이지에 걸쳐 제공합니다:

이 튜토리얼의 목표는 Scrapy와 Requests를 사용해 모든 페이지의 명언을 추출하는 방법을 보여주는 것입니다. Requests가 Scrapy보다 사용법이 복잡할 수 있으므로 먼저 Requests부터 시작하겠습니다.
필요 사항
Scrapy 및 Requests 튜토리얼을 재현하려면 컴퓨터에Python 3.7 이상이설치되어 있어야 합니다.
웹 스크래핑을 위한 Requests 사용법
이 장에서는 Requests를 사용하여 대상 사이트의 모든 명언을 스크래핑하는 방법을 배웁니다.
단독으로 Requests만으로는 웹 페이지에서 직접 데이터를 스크래핑할 수 없다는 점을 명심하세요.BeautifulSoup과 같은 HTML 파서도 필요합니다.
1단계: 환경 설정 및 종속성 설치
프로젝트의 메인 폴더를 requests_scraper/라고 가정합니다 . 이 단계가 완료되면 폴더 구조는 다음과 같아집니다:
requests_scraper/
├── requests_scraper.py
└── venv/
여기서:
requests_scraper.py: 모든 코드가 포함된 Python 파일venv/가상 환경 디렉터리입니다
다음과 같이venv/가상 환경디렉터리를 생성할 수 있습니다:
python -m venv venv
활성화하려면 Windows에서 다음을 실행하세요:
venvScriptsactivate
macOS 및 Linux에서는 다음과 같이 실행합니다:
source venv/bin/activate
이제 필요한 라이브러리를 설치할 수 있습니다:
pip install requests beautifulsoup4
단계 #2: 변수 설정
이제 requests_scraper.py 파일에 코드 작성을 시작할 준비가 되었습니다.
먼저 다음과 같이 변수를 설정하세요:
base_url = "https://quotes.toscrape.com"
all_quotes = []
여기서 정의한 내용은 다음과 같습니다:
base_url: 스크래핑할 웹사이트의 시작 URLall_quotes: 스크랩된 모든 인용문을 저장할 빈 리스트
3단계: 스크래핑 로직 생성
다음 코드로 스크래핑 및 크롤링 로직을 구현할 수 있습니다:
url = base_url
while url:
# 현재 페이지에 GET 요청 전송
response = requests.get(url)
# 페이지 HTML 코드 파싱
soup = BeautifulSoup(response.text, "html.parser")
# 모든 인용문 블록 찾기
quotes = soup.select(".quote")
for quote in quotes:
text = quote.select_one(".text").get_text(strip=True)
author = quote.select_one(".author").get_text(strip=True)
tags = [tag.get_text(strip=True) for tag in quote.select(".tag")]
all_quotes.append({
"text": text,
"author": author,
"tags": ",".join(tags)
})
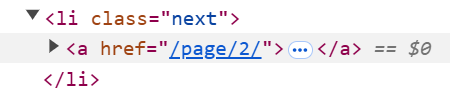
# "다음" 버튼 확인
next_button = soup.select_one("li.next")
if next_button:
# "다음" 버튼에서 URL 추출 및
# 다음 스크래핑 페이지로 설정
next_page = next_button.select_one("a")["href"]
url = base_url + next_page
else:
url = None
이 코드는:
- 모든 페이지가 스크래핑될 때까지 계속 실행되는
while루프를 생성합니다 while루프 내부:soup.``select``()는페이지의 모든 인용문 HTML 요소를 가로챕니다. 페이지의 HTML 구조는 각 인용문 요소가'quote'라는클래스를 가질 수 있도록 되어 있습니다.for루프는quote클래스를 모두 반복하며 Beautiful Soup의 스크래핑 메서드를 사용해 각 quote에서 텍스트, 저자, 태그를 추출합니다. 여기서 각 quote 요소가 하나 이상의 태그를 포함할 수 있으므로 태그에 대한 맞춤형 로직이 필요합니다.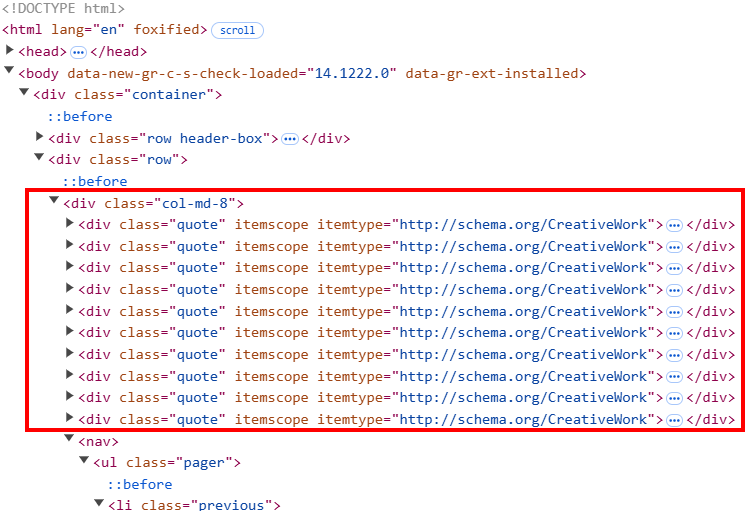
- 전체 페이지 스크래핑 후, 스크립트는
다음버튼을 검색합니다. 버튼이 존재하면 다음 페이지 링크를 추출합니다. 그런 다음 변수url = base_url + next_page를 통해 기본 URL을 다음 페이지로 업데이트합니다. 프로세스가 마지막 페이지에 도달하면 다음 URL을None으로설정하고 프로세스를 종료합니다.
단계 #4: 데이터를 CSV 파일에 추가하기
이제 모든 데이터를 스크래핑했으므로 아래와 같이 CSV 파일에 추가할 수 있습니다:
with open("quotes.csv", mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=["text", "author", "tags"])
writer.writeheader()
writer.writerows(all_quotes)
이 스크립트 부분은csv라이브러리를 사용하여:
- 출력 CSV 파일 이름을
quotes.csv로지정합니다. - CSV를 쓰기 모드(
mode="w")로 열고:- 헤더 행을 CSV에 기록합니다.
- 스크랩한 모든 인용문을 파일에 기록합니다.
단계 #5: 모든 것을 통합하기
이 튜토리얼의 Scrapy 대 Requests 부분 전체 코드는 다음과 같습니다:
import requests
from bs4 import BeautifulSoup
import csv
# 웹사이트 URL
base_url = "https://quotes.toscrape.com"
# 모든 명언을 저장할 리스트
all_quotes = []
# 첫 페이지부터 스크래핑 시작
url = base_url
while url:
# 현재 페이지에 GET 요청 전송
response = requests.get(url)
# 페이지 HTML 코드 파싱
soup = BeautifulSoup(response.text, "html.parser")
# 모든 인용문 블록 찾기
quotes = soup.select(".quote")
for quote in quotes:
text = quote.select_one(".text").get_text(strip=True)
author = quote.select_one(".author").get_text(strip=True)
tags = [tag.get_text(strip=True) for tag in quote.select(".tag")]
all_quotes.append({
"text": text,
"author": author,
"tags": ",".join(tags)
})
# "다음" 버튼 확인
next_button = soup.select_one("li.next")
if next_button:
# "다음" 버튼에서 URL 추출 및
# 다음 스크랩 대상 페이지 설정
next_page = next_button.select_one("a")["href"]
url = base_url + next_page
else:
url = None
# 인용문을 CSV 파일로 저장
with open("quotes.csv", mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=["text", "author", "tags"])
writer.writeheader()
writer.writerows(all_quotes)
위 스크립트 실행:
python requests_scraper.py
프로젝트 폴더에quotes.csv파일이 생성됩니다:

웹 스크래핑을 위한 Scrapy 사용법
웹 스크래핑을 위해 Requests 사용법을 배웠으니, 동일한 대상 페이지와 목표를 가지고 Scrapy를 사용하는 방법을 살펴볼 준비가 되었습니다.
1단계: 환경 설정 및 종속성 설치
프로젝트의 메인 폴더를 scrapy_scraper/라고 가정합니다 .
먼저 이전에 설명한 대로 가상 환경을 생성하고 활성화한 후 Scrapy를 설치합니다:
pip install scrapy
다음 명령어로 Scrapy를 실행하여 quotes_scraper/ 폴더 내에 미리 정의된 파일을 생성합니다:
scrapy startproject quotes_scraper
프로젝트 구조는 다음과 같습니다:
scrapy_scraper/
├── quotes_scraper/ # 메인 Scrapy 프로젝트 폴더
│ ├── __init__.py
│ ├── items.py # 스크랩된 항목의 데이터 구조 정의
│ ├── middlewares.py # 커스텀 미들웨어
│ ├── pipelines.py # 스크랩된 데이터의 후처리 처리
│ ├── settings.py # 프로젝트 설정
│ └── spiders/ # 모든 스파이더 폴더
├── venv/
└── scrapy.cfg # Scrapy 구성 파일
단계 #2: 아이템 정의하기
items.py 파일은 스크랩할 데이터의 구조를 정의합니다. 인용문, 저자, 태그를 추출하려면 다음과 같이 정의하세요:
import scrapy
class QuotesScraperItem(scrapy.Item):
quote = scrapy.Field()
author = scrapy.Field()
tags = scrapy.Field()
단계 #3: 메인 스파이더 정의
spiders/ 폴더 내에 다음 Python 파일을 생성합니다:
__init__.py: 디렉터리를 Python 패키지로 표시합니다quotes_spider.py
quotes_spider.py 에는 실제 스크래핑 로직이 포함됩니다:
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from ..items import QuotesScraperItem
class QuotesSpider(CrawlSpider):
name = "quotes"
allowed_domains = ["quotes.toscrape.com"]
start_urls = ["https://quotes.toscrape.com/"]
# 페이지네이션 링크 추적 규칙 정의
rules = (
Rule(LinkExtractor(restrict_css="li.next a"), callback="parse_item", follow=True),
)
def parse_item(self, response):
# 명언, 저자, 태그 추출
for quote in response.css("div.quote"):
item = QuotesScraperItem()
item["quote"] = quote.css("span.text::text").get()
item["author"] = quote.css("small.author::text").get()
item["tags"] = quote.css("div.tags a.tag::text").getall()
yield item
위의 코드 조각은 QuotesSpider() 클래스를 정의하며, 이 클래스는 다음을 수행합니다:
- 스크래핑할 URL을 정의합니다.
Rule()클래스로 페이지네이션 규칙을 정의하여 크롤러가 모든 다음 페이지를 추적할 수 있도록 합니다.parse_item()메서드로 인용문, 저자, 태그를 추출합니다.
4단계: 설정 정의
데이터를 CSV에 추가하려면 Scrapy에서 특별한 설정이 필요합니다. 설정 파일( settings.py )을 열고 다음 변수를 추가하세요:
FEED_FORMAT = "csv"
FEED_URI = "quotes.csv"
이 설정들의 역할은 다음과 같습니다:
FEED_FORMAT은파일의 출력 형식을 정의합니다(다양한 유형이 가능함).FEED_URI는출력 파일의 이름을 정의합니다
단계 #5: 크롤러 실행
이전 단계에서 언급되지 않은 Python 파일들은 이 튜토리얼에 필요하지 않으므로 기본값 그대로 두셔도 됩니다.
크롤러를 실행하려면 quotes_scraper/ 폴더로 이동하세요:
cd quotes_scraper
그런 다음 크롤러를 실행하세요:
scrapy crawl quotes
이 명령어는 quotes_spider.py 파일 내 QuotesSpider() 클래스를 인스턴스화하여 크롤러를 실행합니다. 최종적으로 얻는 CSV 파일은 Requests와 BeautifulSoup을 사용했을 때와 동일합니다!
따라서 이 예제는 다음과 같은 점을 보여줍니다:
- Scrapy의 특성상 대규모 프로젝트에 더 적합한 이유
- Scrapy를 사용하면 페이지네이션 관리가 더 쉬워집니다. 이전 사례처럼 맞춤형 로직을 작성할 필요 없이 규칙 하나만 관리하면 되기 때문입니다.
- Scrapy를 사용하면 CSV 파일에 데이터를 추가하는 작업이 더 간단합니다. 이는 Python 스크립트로 해당 작업을 수행할 때 작성해야 하는 전통적인 커스텀 로직 대신, 단지 두 가지 설정만 추가하면 되기 때문입니다.
Scrapy와 Requests의 공통적인 한계점
Scrapy와 Requests는 웹 스크래핑 프로젝트에서 널리 사용되지만 몇 가지 단점이 있습니다.
구체적으로, 모든 스크래핑 라이브러리나 프레임워크가 겪는 공통적인 한계 중 하나는IP 차단입니다. Scrapy가 서버 요청 속도를 조절하는 데 도움이 되는 스로틀링 기능을 제공한다는 점을 배웠습니다. 하지만 IP가 차단되지 않도록 하기에 종종 충분하지 않습니다.
IP 차단 방지를 위한 해결책은 코드에 프록시를 구현하는 것입니다. 그 방법을 살펴보겠습니다!
Requests에서 프록시 사용하기
Requests에서 단일 프록시를 사용하려면 다음 로직을 적용하세요:
proxy = {
"http": "<HTTP_PROXY_URL>",
"https": "<HTTPs_PROXY_URL>"
}
response = requests.get(url, proxies=proxy)
Requests에서 프록시 및 프록시 로테이션에 대해 자세히 알아보려면 저희 블로그의 가이드를 참고하세요:
Scrapy에서 프록시 사용하기
코드를 통해 단일 프록시를 구현하려면 settings.py 파일에 다음 설정을 추가하세요:
# 단일 프록시 구성
HTTP_PROXY = "<PROXY_URL>"
# HttpProxyMiddleware 활성화 및 기본 UserAgentMiddleware 비활성화
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 110,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
}
이 설정은 모든 요청을 지정된 프록시를 통해 라우팅합니다. 자세한 내용은Scrapy 프록시 통합 가이드를 참조하세요.
대신 회전 프록시를 구현하려면scrapy-rotating-proxies라이브러리를 사용할 수 있습니다. 마찬가지로 자동 회전 주거용 프록시를 사용할 수도 있습니다.
신뢰할 수 있는 프록시를 찾고 계시다면, Bright Data의 프록시 네트워크가 포춘 500대 기업과 전 세계 20,000명 이상의 고객으로부터 신뢰받고 있다는 점을 기억하세요. 이 광범위한 네트워크에는 다음이 포함됩니다:
- 주거용 프록시: 195개 이상의 국가에서 7,200만 개 이상의 주거용 IP.
- 데이터센터 프록시: 77만 개 이상의 데이터센터 IP.
- ISP 프록시: 70만 개 이상의 ISP IP.
결론
이 Scrapy 대 Requests 블로그 글에서는 웹 스크래핑에서 두 라이브러리의 역할을 알아보았습니다. 페이지 검색 및 데이터 추출 기능을 살펴보고 실제 페이지네이션 시나리오에서 성능을 비교했습니다.
Requests는 수동 로직이 더 많이 필요하지만 맞춤형 사용 사례에 더 큰 유연성을 제공하는 반면, Scrapy는 약간 적응성이 떨어지지만 구조화된 스크래핑에 필요한 대부분의 도구를 제공합니다.
또한 잠재적인 IP 차단 및 지역 제한 콘텐츠와 같은 두 라이브러리의 한계점도 발견했습니다. 다행히도 이러한 문제들은프록시나Bright Data의웹 스크레이퍼와 같은 전용 웹 스크래핑 솔루션을사용하여극복할 수 있습니다.
Web Scrapers는 Scrapy와 Requests 모두와 원활하게 통합되어 주요 웹사이트에서 제한 없이 공개 데이터를 추출할 수 있게 해줍니다.
지금 바로 무료 Bright Data 계정을 생성하여 프록시 및 스크레이퍼 API를 살펴보고 무료 체험을 시작하세요!