

이 가이드에서 배우게 될 내용:
- Gospider의 정의와 작동 방식
- 제공하는 기능
- 웹 크롤링에 활용하는 방법
- 웹 스크래핑을 위해 Colly와 통합하는 방법
- 주요 제한 사항과 이를 우회하는 방법
자, 시작해 보겠습니다!
Gospider란 무엇인가요?
Gospider는 Go 언어로 작성된 빠르고 효율적인 웹 크롤링 CLI 도구입니다. 웹사이트를 스캔하고 URL을 병렬로 추출하도록 설계되어 여러 요청과 도메인을 동시에 처리합니다. 또한 robots.txt를 준수하며 JavaScript 파일 내 링크도 발견할 수 있습니다.
Gospider는 크롤링 깊이, 요청 지연 시간 등을 제어하기 위한 여러 사용자 지정 플래그를 제공합니다. 또한 프록시 통합을 지원하며, 크롤링 프로세스를 더욱 세밀하게 제어할 수 있는 다양한 옵션을 제공합니다.
웹 크롤링에서 Gospider의 차별점은 무엇인가요?
웹 크롤링에서 Gospider가 특별한 이유를 더 잘 이해하기 위해, 그 기능을 자세히 살펴보고 지원되는 플래그를 검토해 보겠습니다.
주요 기능
웹 크롤링과 관련하여 Gospider가 제공하는 주요 기능은 다음과 같습니다:
- 빠른 웹 크롤링: 단일 웹사이트를 고속으로 효율적으로 크롤링합니다.
- 병렬 크롤링: 데이터 수집 속도 향상을 위해 여러 사이트를 동시에 크롤링합니다.
sitemap.xml파싱: 향상된 크롤링을 위해 사이트맵 파일을 자동으로 처리합니다.robots.txt파싱: 윤리적인 크롤링을 위해robots.txt지침을 준수합니다.- JavaScript 링크 파싱: JavaScript 파일에서 링크를 추출합니다.
- 사용자 정의 가능한 크롤링 옵션: 유연한 플래그로 크롤링 깊이, 동시성, 지연, 타임아웃 등을 조정합니다.
사용자 에이전트무작위화: 모바일 및 웹 사용자 에이전트를 무작위로 전환하여 보다 현실적인 요청을 수행합니다. 웹 크롤링에 가장 적합한사용자 에이전트를찾아보세요.- 쿠키 및 헤더 사용자 지정: 사용자 지정 쿠키 및 HTTP 헤더를 허용합니다.
- 링크 찾기: 사이트에서 URL 및 기타 리소스를 식별합니다.
- AWS S3 버킷 찾기: 응답 소스에서 AWS S3 버킷을 감지합니다.
- 하위 도메인 찾기: 응답 소스에서 하위 도메인을 발견합니다.
- 타사 소스: Wayback Machine, Common Crawl, VirusTotal, Alien Vault 등의 서비스에서 URL을 추출합니다.
- 쉬운 출력 형식 지정:
grep및 분석하기 쉬운 형식으로 결과를 출력합니다. - Burp Suite 지원: Burp Suite와 통합되어 테스트 및 크롤링을 더 쉽게 수행합니다.
- 고급 필터링: 도메인 수준 필터링을 포함한 URL 블랙리스트 및 화이트리스트.
- 서브도메인 지원: 대상 사이트 및 타사 소스에서 크롤링 시 서브도메인을 포함합니다.
- 디버그 및 상세 모드: 문제 해결을 용이하게 하기 위한 디버깅 및 상세 로깅을 활성화합니다.
명령줄 옵션
일반적인 Gospider 명령어 형식은 다음과 같습니다:
gospider [플래그]특히, 지원되는 플래그는 다음과 같습니다:
-s, --site: 크롤링할 사이트.-S, --sites: 크롤링할 사이트 목록.-p, --proxy: 프록시 URL.-o, --output: 출력 폴더.-u, --user-agent: 사용할 사용자 에이전트 (예:web,mobi또는 사용자 정의 사용자 에이전트).--cookie: 사용할 쿠키 (예:testA=a; testB=b).-H, --header: 사용할 헤더 (여러 헤더를 지정하려면 플래그를 여러 번 반복).--burp string: Burp Suite의 원시 HTTP 요청에서 헤더와 쿠키를 불러옵니다.--blacklist: 차단할 URL 정규 표현식.--whitelist: 허용 URL 정규 표현식.--whitelist-domain: 도메인 화이트리스트.-t, --threads: 병렬로 실행할 스레드 수 (기본값:1).-c, --concurrent: 일치하는 도메인에 대한 최대 동시 요청 수 (기본값:5).-d, --depth: URL에 대한 최대 재귀 깊이 (무한 재귀를 위해0으로 설정, 기본값:1).-k, --delay int: 요청 간 지연 시간 (초 단위).-K, --random-delay int: 요청 전 추가 무작위 지연 시간(초).-m, --timeout int: 요청 시간 초과(초, 기본값:10).-B, --base: 모든 기능을 비활성화하고 HTML 콘텐츠만 사용합니다.--js: 자바스크립트 파일 내 링크 찾기 활성화 (기본값:true).--subs: 하위 도메인 포함.--sitemap:sitemap.xml크롤링.--robots:robots.txt크롤링 (기본값:true).-a, --other-source: Archive.org, CommonCrawl, VirusTotal, AlienVault와 같은 제3자 소스에서 URL을 찾습니다.-w, --include-subs: 제3자 소스에서 크롤링된 서브도메인 포함 (기본값: 메인 도메인만).-r, --include-other-source: 제3자 소스의 URL을 포함하되 여전히 크롤링합니다.--debug: 디버그 모드 활성화.--json: JSON 출력 활성화.-v, --verbose: 자세한 출력 활성화.-l, --length: URL 길이를 표시합니다.-L, --filter-length: 길이로 URL 필터링합니다.-R, --raw: 원시 출력 표시.-q, --quiet: 모든 출력을 억제하고 URL만 표시합니다.--no-redirect: 리디렉션을 비활성화합니다.--version: 버전을 확인합니다.-h, --help: 도움말 표시.
Gospider를 이용한 웹 크롤링: 단계별 가이드
이 섹션에서는 Gospider를 사용하여 다중 페이지 사이트의 링크를 크롤링하는 방법을 배웁니다. 구체적으로 대상 사이트는 Books to Scrape입니다:
해당 사이트에는 50개 페이지에 걸쳐 제품 목록이 있습니다. 이 목록 페이지의 각 제품 항목에는 전용 제품 페이지도 존재합니다. 아래 단계는 Gospider를 사용하여 모든 제품 페이지 URL을 추출하는 과정을 안내합니다!
사전 준비 및 프로젝트 설정
시작하기 전에 다음 사항을 확인하세요:
- 컴퓨터에 Go 설치: 아직 Go를 설치하지 않았다면 공식 웹사이트에서 다운로드하여 설치 안내를 따르세요.
- Go IDE: Go 확장 프로그램이 설치된 Visual Studio Code를 권장합니다.
Go 설치 여부를 확인하려면 다음 명령어를 실행하세요:
go versionGo가 올바르게 설치되었다면 다음과 유사한 출력이 표시됩니다(Windows 기준):
go version go1.24.1 windows/amd64좋습니다! Go가 설정되어 사용 준비가 완료되었습니다.
터미널에서 새 프로젝트 폴더를 생성하고 해당 폴더로 이동하세요:
mkdir gospider-project
cd gospider-project 이제 Gospider를 설치하고 웹 크롤링에 사용할 준비가 되었습니다!
1단계: Gospider 설치
다음 go install 명령어를 실행하여 Gospider를 컴파일하고 전역적으로 설치하세요:
go install github.com/jaeles-project/gospider@latest설치 후 다음 명령어로 Gospider 설치 여부를 확인하세요:
gospider -h아래와 같은 Gospider 사용법 안내가 출력됩니다:
Go로 작성된 빠른 웹 크롤러 - v1.1.6 by @thebl4ckturtle & @j3ssiejjj
사용법:
gospider [플래그]
플래그:
-s, --site 문자열 크롤링할 사이트
-S, --sites 문자열 크롤링할 사이트 목록
-p, --proxy 문자열 프록시 (예: http://127.0.0.1:8080)
-o, --output 문자열 출력 폴더
-u, --user-agent 문자열 사용할 사용자 에이전트
web: 무작위 웹 사용자 에이전트
mobi: 무작위 모바일 사용자 에이전트
또는 특수 사용자 에이전트 설정 가능 (기본값 "web")
--cookie 문자열 사용할 쿠키 (testA=a; testB=b)
-H, --header 문자열배열 사용할 헤더 (여러 헤더 설정 시 여러 플래그 사용)
--burp 문자열 Burp의 원시 HTTP 요청에서 헤더 및 쿠키 로드
--blacklist 문자열 차단 URL 정규 표현식
--whitelist 문자열 허용 URL 정규 표현식
--whitelist-domain 문자열 허용 도메인
-L, --filter-length 문자열 길이 필터 활성화
-t, --threads 정수 스레드 수 (사이트 병렬 실행) (기본값 1)
-c, --concurrent int 일치하는 도메인의 최대 동시 요청 허용 수 (기본값 5)
-d, --depth int MaxDepth는 방문 URL의 재귀 깊이를 제한합니다. (무한 재귀를 위해 0으로 설정) (기본값 1)
-k, --delay int 지연 시간은 일치하는 도메인에 새 요청을 생성하기 전에 대기할 시간(초)
-K, --random-delay int 무작위 지연은 새 요청 생성 전에 Delay에 추가되는 무작위 대기 시간(초)
-m, --timeout int 요청 시간 초과(초) (기본값 10)
-B, --base 모든 기능을 비활성화하고 HTML 콘텐츠만 사용
--js 자바스크립트 파일에서 링크파인더 활성화 (기본값 true)
--sitemap sitemap.xml 크롤링 시도
--robots robots.txt 크롤링 시도 (기본값 true)
-a, --other-source 타사(Archive.org, CommonCrawl.org, VirusTotal.com, AlienVault.com)에서 URL 찾기
-w, --include-subs 타사에서 크롤링한 서브도메인 포함. 기본값은 메인 도메인
-r, --include-other-source 기타 소스의 URL도 포함 (여전히 크롤링 및 요청)
--subs 서브도메인 포함
--debug 디버그 모드 활성화
--json JSON 출력 활성화
-v, --verbose 상세 출력 활성화
-q, --quiet 모든 출력을 억제하고 URL만 표시
--no-redirect 리디렉션 비활성화
--version 버전 확인
-l, --length 길이 활성화
-R, --raw 원시 출력 활성화
-h, --help gospider 도움말대단합니다! Gospider가 설치되었으며, 이제 하나 이상의 웹사이트를 크롤링하는 데 사용할 수 있습니다.
2단계: 대상 페이지의 URL 크롤링
대상 페이지의 모든 링크를 크롤링하려면 다음 명령을 실행하세요:
gospider -s "https://books.toscrape.com/" -o output -d 1사용된 Gospider 플래그 설명:
-s "https://books.toscrape.com/": 대상 URL을 지정합니다.-o output: 크롤링 결과를output폴더에 저장합니다.-d 1: 크롤링 깊이를1로설정합니다. 즉, Gospider는 현재 페이지의 URL만 탐지합니다. 더 깊은 링크 발견을 위해 발견된 URL을 따라가지 않습니다.
위 명령어는 다음과 같은 구조를 생성합니다:
gospider-project/
└── output/
└── books_toscrape_com출력 폴더 내 books_toscrape_com 파일을 열면 다음과 유사한 출력을 확인할 수 있습니다:
[url] - [code-200] - https://books.toscrape.com/
[href] - https://books.toscrape.com/static/oscar/favicon.ico
# 간결함을 위해 생략...
[href] - https://books.toscrape.com/catalogue/page-2.html
[javascript] - http://ajax.googleapis.com/ajax/libs/jquery/1.9.1/jquery.min.js
# 생략...
[javascript] - https://books.toscrape.com/static/oscar/js/bootstrap-datetimepicker/locales/bootstrap-datetimepicker.all.js
[url] - [code-200] - http://ajax.googleapis.com/ajax/libs/jquery/1.9.1/jquery.min.js
# 생략...
[linkfinder] - [from: https://books.toscrape.com/static/oscar/js/bootstrap-datetimepicker/locales/bootstrap-datetimepicker.all.js] - dd/mm/yyyy
# 생략...
[url] - [code-200] - https://books.toscrape.com/static/oscar/js/bootstrap-datetimepicker/bootstrap-datetimepicker.js생성된 파일에는 탐지된 다양한 유형의 링크가 포함됩니다:
[url]: 크롤링된 페이지/리소스.[href]: 페이지에서 발견된 모든<a href>링크.[javascript]: 자바스크립트 파일의 URL.[linkfinder]: 자바스크립트 코드에 내장된 추출된 링크.
3단계: 전체 사이트 크롤링
위의 출력에서 Gospider가 첫 번째 페이지네이션 페이지에서 중단했음을 확인할 수 있습니다. 두 번째 페이지 링크를 감지했지만 방문하지 않았습니다.
books_toscrape_com 파일에 다음 내용이 포함되어 있으므로 이를 확인할 수 있습니다:
[href] - https://books.toscrape.com/catalogue/page-2.html[href] 태그는 링크가 발견되었음을 나타냅니다. 그러나 동일한 URL을 가진 대응하는 [url] 항목이 없으므로 링크는 발견되었지만 방문되지 않았습니다.
대상 페이지를 확인하면 위 URL이 두 번째 페이지네이션 페이지에 해당함을 알 수 있습니다:
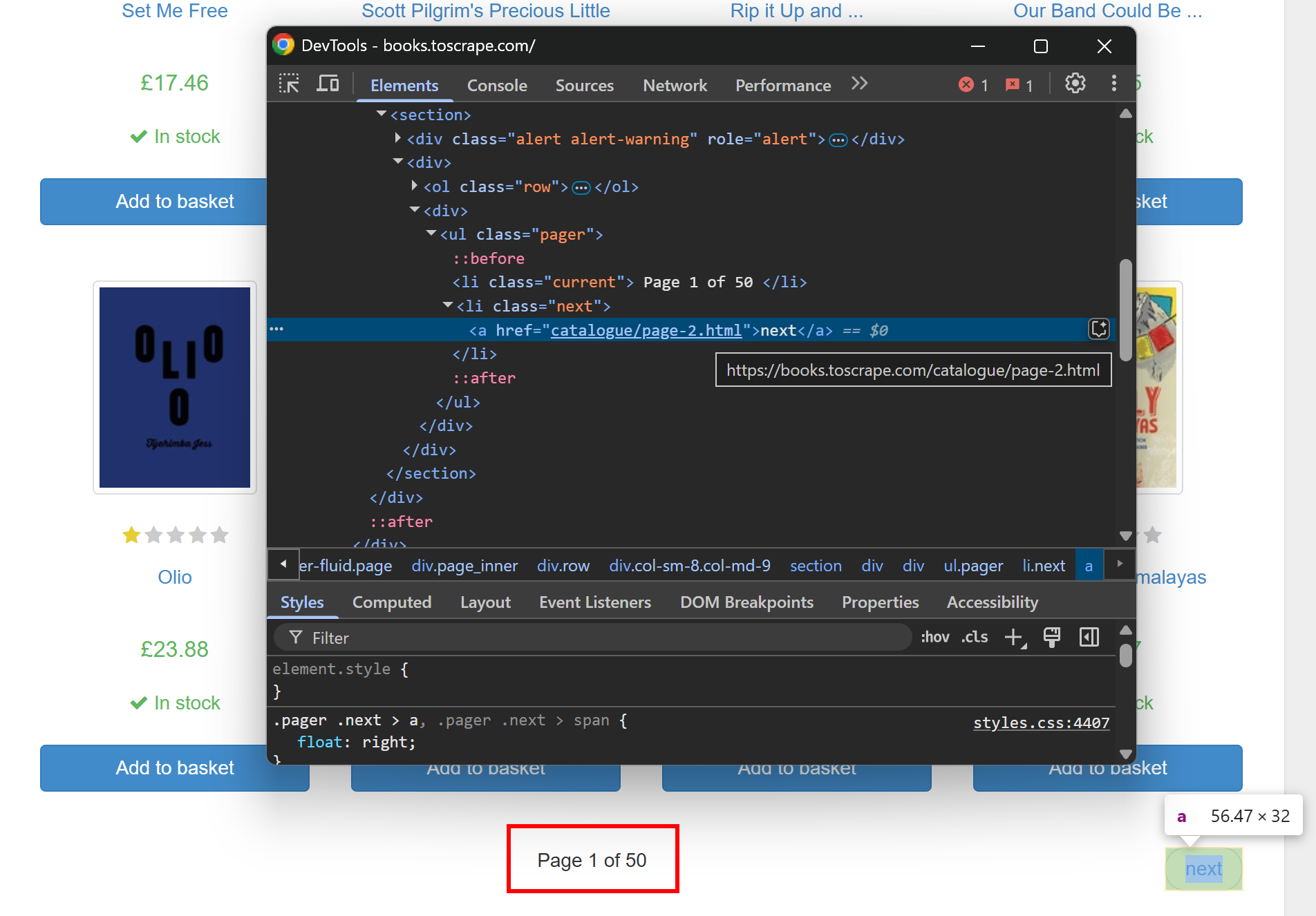
전체 웹사이트를 크롤링하려면 모든 페이지네이션 링크를 따라가야 합니다. 위 이미지에서 볼 수 있듯이 대상 사이트에는 50개의 제품 페이지가 있습니다(“Page 1 of 50” 텍스트 참고). 모든 페이지에 도달하도록 Gospider의 깊이( depth )를 50으로 설정하세요.
대량의 페이지 크롤링이 필요하므로 동시 요청 수(즉, 동시 요청 횟수)를 늘리는 것도 좋은 방법입니다. 기본적으로 Gospider는 동시성 수준 5를 사용하지만, 10으로 늘리면 실행 속도가 빨라집니다.
모든 상품 페이지를 크롤링하는 최종 명령어는 다음과 같습니다:
gospider -s "https://books.toscrape.com/" -o output -d 50 -c 10이번에는 Gospider 실행 시간이 더 오래 걸리며 수천 개의 URL을 생성합니다. 출력 결과에는 다음과 같은 항목이 포함됩니다:
[url] - [code-200] - https://books.toscrape.com/
[href] - https://books.toscrape.com/static/oscar/favicon.ico
[href] - https://books.toscrape.com/static/oscar/css/styles.css
# 간결함을 위해 생략...
[href] - https://books.toscrape.com/catalogue/page-50.html
[url] - [code-200] - https://books.toscrape.com/catalogue/page-50.html출력에서 확인해야 할 핵심 사항은 마지막 페이지네이션 페이지의 URL이 존재하는지 여부입니다:
[url] - [code-200] - https://books.toscrape.com/catalogue/page-50.html훌륭합니다! 이는 Gospider가 모든 페이지네이션 링크를 성공적으로 따라가 의도한 대로 전체 제품 카탈로그를 크롤링했음을 확인시켜 줍니다.
4단계: 제품 페이지만 추출하기
단 몇 초 만에 Gospider가 전체 사이트의 모든 URL을 수집했습니다. 여기서 튜토리얼을 마칠 수도 있지만, 한 단계 더 나아가 보겠습니다.
제품 페이지 URL만 추출하고 싶다면 어떻게 해야 할까요? 대상 페이지에서 제품 요소를 검사하여 URL 구조를 파악해 보세요:
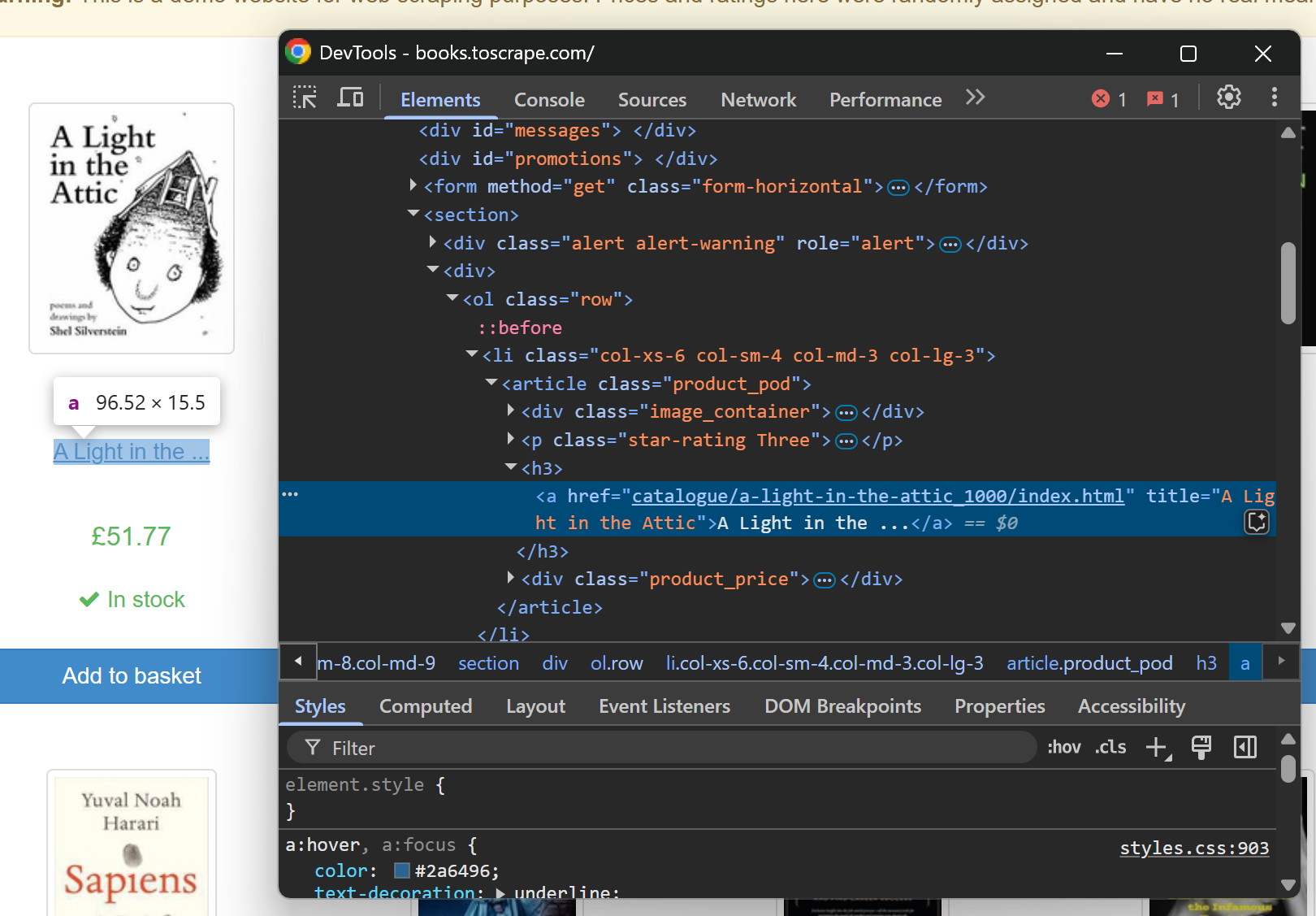
이 분석을 통해 제품 페이지 URL이 다음과 같은 형식을 따르는 것을 알 수 있습니다:
https://books.toscrape.com/catalogue/<product_slug>/index.html크롤링된 원시 URL에서 제품 페이지만 걸러내려면 커스텀 Go 스크립트를 사용할 수 있습니다.
먼저 Gospider 프로젝트 디렉터리 내에 Go 모듈을 생성하세요:
go mod init crawler다음으로 프로젝트 디렉터리 내에 crawler 폴더를 생성하고 crawler.go 파일을 추가합니다. 그런 다음 IDE에서 프로젝트 폴더를 엽니다. 이제 폴더 구조는 다음과 같아야 합니다:
gospider-project/
├── crawler/
│ └── crawler.go
└── output/
└── books_toscrape_comcrawler.go 스크립트는 다음을 수행해야 합니다:
- 깨끗한 상태에서 Gospider 명령어를 실행합니다.
- 출력 파일에서 모든 URL을 읽습니다.
- 정규 표현식 패턴을 사용하여 제품 페이지 URL만 필터링합니다.
- 필터링된 제품 URL을 .txt 파일로 내보내야 합니다.
목표를 달성하기 위한 Go 코드는 다음과 같습니다:
package main
import (
"bufio"
"fmt"
"os"
"os/exec"
"regexp"
"slices"
"path/filepath"
)
func main() {
// 깨끗한 실행을 위해 출력 폴더가 존재하면 삭제
outputDir := "output"
os.RemoveAll(outputDir)
// "books.toscrape.com" 사이트 크롤링을 위한 Gospider CLI 명령 생성
fmt.Println("Gospider 실행 중...")
cmd := exec.Command("gospider", "-s", "https://books.toscrape.com/", "-o", outputDir, "-d", "50", "-c", "10")
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
// Gospider 명령 실행 및 완료 대기
cmd.Run()
fmt.Println("Gospider 완료")
// 크롤링된 URL이 포함된 생성된 출력 파일 열기
fmt.Println("nGospider 출력 파일 읽기 중...")
inputFile := filepath.Join(outputDir, "books_toscrape_com")
file, _ := os.Open(inputFile)
defer file.Close()
// 정규식을 사용하여 개별 상품 페이지로 연결되는 URL을 필터링하며 파일에서 상품 페이지 URL 추출
// (https://books.toscrape.com/catalogue/[^/]+/index.html) 정규식 컴파일
urlRegex := regexp.MustCompile(`(https://books.toscrape.com/catalogue/[^/]+/index.html)`)
var productURLs []string
// 파일의 각 줄을 읽고 일치하는 URL을 확인
scanner := bufio.NewScanner(file)
for scanner.Scan() {
line := scanner.Text()
// 줄에서 모든 URL 추출
matches := urlRegex.FindAllString(line, -1)
for _, url := range matches {
// 중복을 피하기 위해 URL이 이미 추가되지 않았는지 확인
if !slices.Contains(productURLs, url) {
productURLs = append(productURLs, url)
}
}
}
fmt.Printf("%d개의 제품 페이지 URL을 찾았습니다", len(productURLs))
// 제품 페이지 URL을 새 파일로 내보내기
fmt.Println("n필터링된 제품 페이지 URL 내보내기 중...")
outputFile := "product_urls.txt"
out, _ := os.Create(outputFile)
defer out.Close()
writer := bufio.NewWriter(out)
for _, url := range productURLs {
_, _ = writer.WriteString(url + "n")
}
writer.Flush()
fmt.Printf("제품 페이지 URL 저장됨: %sn", outputFile)
}이 Go 프로그램은 다음을 활용하여 웹 크롤링을 자동화합니다:
- 출력 디렉터리(
output/)가 이미 존재할 경우os.RemoveAll()을 사용하여 삭제함으로써 깨끗한 시작을 보장합니다. exec.Command()및cmd.Run()을 사용하여 대상 웹사이트를 크롤링할 Gospider 명령줄 프로세스를 구성하고 실행합니다.os.Open()및bufio.NewScanner()를 사용하여 Gospider가 생성한 출력 파일(books_toscrape_com)을 열고 줄 단위로 읽습니다.regexp.MustCompile()및FindAllString()을 사용하여 정규 표현식으로 각 줄에서 제품 페이지 URL을 추출합니다.중복을 방지하기 위해slices.Contains()를 활용합니다.os.Create()및bufio.NewWriter()를 사용하여 필터링된 제품 페이지 URL을product_urls.txt파일에 기록합니다. 5단계: 크롤링 스크립트 실행 다음 명령어로crawler.go스크립트를 실행합니다:
go run crawler/crawler.go스크립트는 터미널에 다음과 같이 기록합니다:
Running Gospider...
# 간결함을 위해 Gospider 출력 생략...
Gospider finished
Reading the Gospider output file...
1000 product page URLs found
Exporting filtered product page URLs...
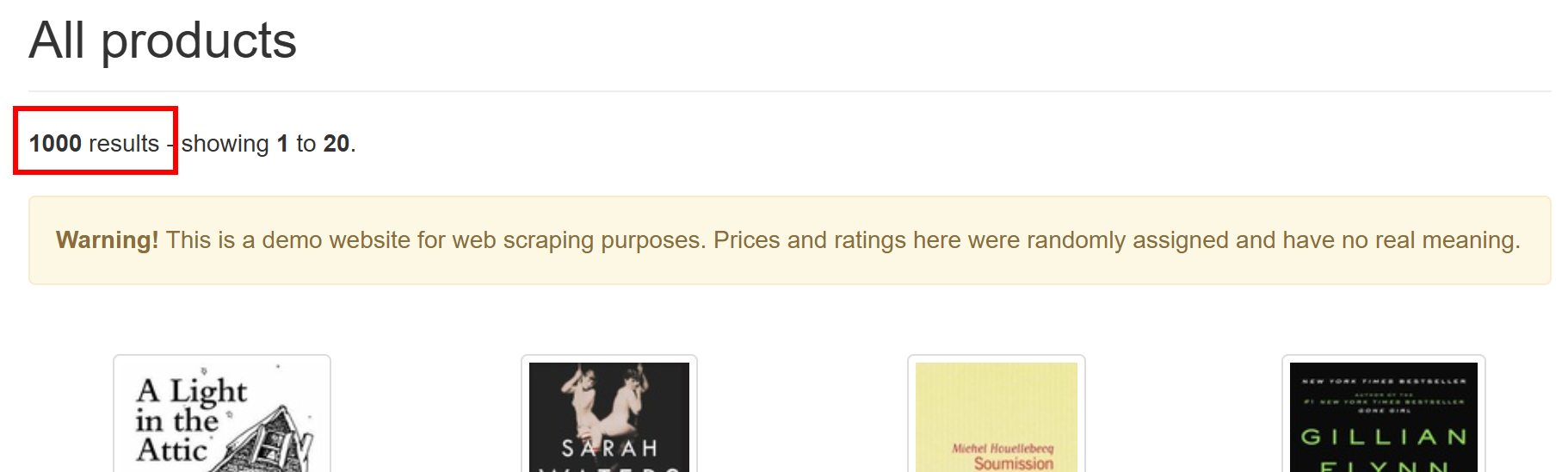
Product page URLs saved to product_urls.txtGospider 크롤링 스크립트가 1,000개의 상품 페이지 URL을 성공적으로 찾았습니다. 대상 사이트에서 쉽게 확인할 수 있듯이, 이는 정확히 이용 가능한 상품 페이지 수와 일치합니다:
해당 URL들은 프로젝트 폴더에 생성된 product_urls.txt 파일에 저장됩니다. 해당 파일을 열면 다음과 같은 내용을 확인할 수 있습니다:
https://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html
# 간결함을 위해 생략...
https://books.toscrape.com/catalogue/frankenstein_20/index.html축하합니다! 방금 Go로 웹 크롤링을 수행하는 Gospider 스크립트를 구축했습니다.
[추가] Gospider 크롤러에 스크래핑 로직 추가하기
웹 크롤링은 일반적으로 더 큰 웹 스크래핑 프로젝트의 한 단계에 불과합니다. 웹 크롤링과 웹 스크래핑의 차이점에 대해 자세히 알아보려면 저희 가이드를 참고하세요.
이 튜토리얼을 더욱 완성도 있게 만들기 위해, 크롤링된 링크를 웹 스크래핑에 활용하는 방법도 시연해 보겠습니다. 지금부터 구축할 Go 스크래핑 스크립트는 다음과 같은 작업을 수행합니다:
- Gospider와 사용자 정의 로직을 사용하여 이전에 생성한
product_urls.txt파일에서 제품 페이지 URL을 읽습니다. - 각 제품 페이지를 방문하여 제품 데이터를 스크래핑합니다.
- 스크래핑된 제품 데이터를 CSV 파일로 내보냅니다.
이제 Gospider 설정에 웹 스크래핑 로직을 추가할 시간입니다!
1단계: Colly 설치
웹 스크래핑에 사용되는 라이브러리는 Golang용 우아한 스크래퍼 및 크롤러 프레임워크인 Colly입니다. API에 익숙하지 않다면 Go를 사용한 웹 스크래핑 튜토리얼을 확인하세요.
Colly 설치 명령어 실행:
go get -u github.com/gocolly/colly/...다음으로 프로젝트 디렉토리 내 scraper 폴더에 scraper.go 파일을 생성하세요. 프로젝트 구조는 다음과 같아야 합니다:
gospider-project/
├── crawler/
│ └── crawler.go
├── output/
│ └── books_toscrape_com
└── scraper/
└── scraper.goscraper.go 파일을 열고 Colly를 임포트합니다:
import (
"bufio"
"encoding/csv"
"os"
"strings"
"github.com/gocolly/colly"
)훌륭합니다! 크롤링된 제품 페이지에서 데이터를 스크래핑하기 위해 Colly를 사용하는 방법은 아래 단계를 따르세요.
단계 #2: 스크래핑할 URL 읽기
다음 코드를 사용하여 crawler.go에서 생성된 filtered_urls.txt 파일에서 스크래핑할 제품 페이지의 URL을 가져옵니다:
// 크롤링된 URL이 포함된 입력 파일 열기
file, _ := os.Open("product_urls.txt")
defer file.Close()
// 입력 파일에서 페이지 URL 읽기
var urls []string
scanner := bufio.NewScanner(file)
for scanner.Scan() {
urls = append(urls, scanner.Text())
}위 코드 조각이 작동하도록 하려면 파일 시작 부분에 다음 임포트를 포함하세요:
import (
"bufio"
"os"
)훌륭합니다! 이제 urls 슬라이스에는 스크래핑 준비가 된 모든 제품 페이지 URL이 포함됩니다.
3단계: 데이터 추출 로직 구현
데이터 추출 로직을 구현하기 전에 제품 페이지 HTML 구조를 이해해야 합니다.
이를 위해 새 세션을 보장하기 위해 브라우저의 시크릿 모드에서 제품 페이지를 방문하세요. 개발자 도구(DevTools)를 열고 제품 이미지 HTML 노드부터 시작하여 페이지 요소를 검사하세요:
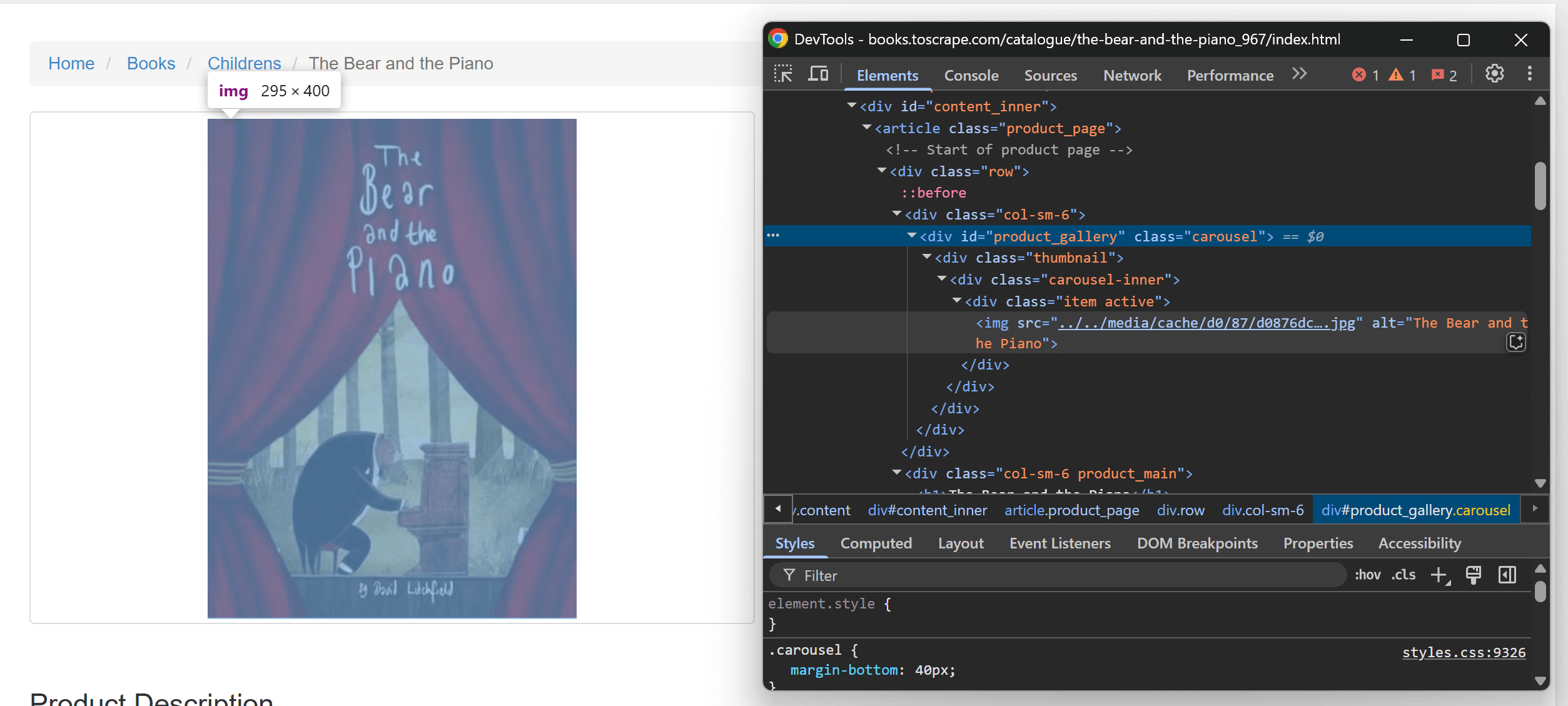
다음으로 제품 정보 섹션을 검사하세요:
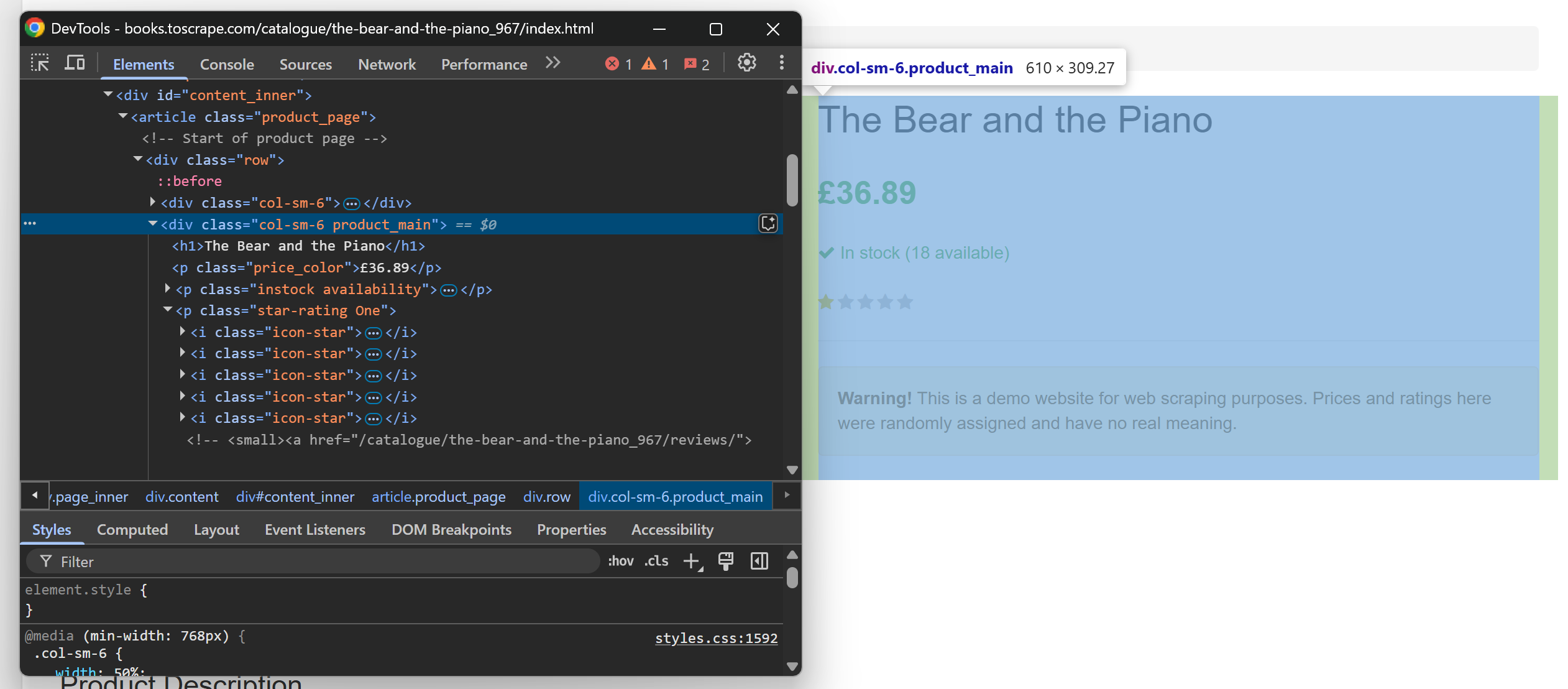
검사한 요소에서 다음을 추출할 수 있습니다:
<h1>태그에서 제품 제목.- 페이지의 첫 번째
.price_color노드에서 제품 가격을 추출합니다. .star-rating클래스에서 제품 평점(별점).#product_gallery img요소에서 제품 이미지 URL.
이러한 속성을 바탕으로 스크랩된 데이터를 표현하기 위해 다음 Go 구조체를 정의합니다:
type Product struct {
Title string
Price string
Stars string
ImageURL string
}여러 상품 페이지가 스크랩될 것이므로 추출된 상품을 저장할 슬라이스를 정의합니다:
var products []Product데이터를 스크랩하려면 먼저 Colly Collector를 초기화합니다:
c := colly.NewCollector()Colly의 OnHTML() 콜백을 사용하여 스크래핑 로직을 정의합니다:
c.OnHTML("html", func(e *colly.HTMLElement) {
// 스크래핑 로직
title := e.ChildText("h1")
price := e.DOM.Find(".price_color").First().Text()
stars := ""
e.ForEach(".star-rating", func(_ int, el *colly.HTMLElement) {
class := el.Attr("class")
if strings.Contains(class, "One") {
stars = "1"
} else if strings.Contains(class, "Two") {
stars = "2"
} else if strings.Contains(class, "Three") {
stars = "3"
} else if strings.Contains(class, "Four") {
stars = "4"
} else if strings.Contains(class, "Five") {
stars = "5"
}
})
imageURL := e.ChildAttr("#product_gallery img", "src")
// 상대 이미지 경로 조정
imageURL = strings.Replace(imageURL, "../../", "https://books.toscrape.com/", 1)
// 스크랩된 데이터로 새 제품 객체 생성
product := Product{
Title: title,
Price: price,
Stars: stars,
ImageURL: imageURL,
}
// 제품을 products 슬라이스에 추가
products = append(products, product)
})별점 등급을 .star-rating 클래스 속성에 따라 가져오기 위해 else if 구조를 사용했음을 참고하세요. 또한 strings.Replace()를 사용하여 상대 이미지 URL을 절대 URL로 변환하는 방법을 확인하세요.
다음 필수 임포트를 추가하세요:
import (
"strings"
)이제 Go 스크레이퍼가 원하는 대로 제품 데이터를 추출할 준비가 되었습니다!
4단계: 대상 페이지 연결
Colly는 특정 콜백 라이프사이클을 가진 콜백 기반 웹 스크래핑 프레임워크입니다. 즉, HTML을 가져오기 전에 스크래핑 로직을 정의할 수 있는데, 이는 흔하지 않지만 강력한 접근 방식입니다.
이제 데이터 추출 로직이 마련되었으니, Colly가 각 제품 페이지를 방문하도록 지시하세요:
pageLimit := 50
for _, url := range urls[:pageLimit] {
c.Visit(url)
}참고: 대상 웹사이트에 과도한 요청이 발생하지 않도록 URL 수를 50개로 제한했습니다. 실제 운영 스크립트에서는 필요에 따라 이 제한을 제거하거나 조정할 수 있습니다.
이제 Colly는:
- 목록의 각 URL을 방문합니다.
OnHTML()콜백을 적용하여 제품 데이터를 추출합니다.- 추출된 데이터를
products슬라이스에 저장합니다.
훌륭합니다! 이제 남은 작업은 추출한 데이터를 CSV와 같은 사람이 읽을 수 있는 형식으로 내보내는 것입니다.
5단계: 스크랩된 데이터 내보내기
다음 로직을 사용하여 products 슬라이스를 CSV 파일로 내보냅니다:
outputFile := "products.csv"
csvFile, _ := os.Create(outputFile)
defer csvFile.Close()
// 새 CSV 라이터 초기화
writer := csv.NewWriter(csvFile)
defer writer.Flush()
// CSV 헤더 작성
writer.Write([]string{"Title", "Price", "Stars", "Image URL"})
// 각 제품 데이터를 CSV에 작성
for _, product := range products {
writer.Write([]string{product.Title, product.Price, product.Stars, product.ImageURL})
}위의 코드 조각은 products.csv 파일을 생성하고 스크랩한 데이터로 채웁니다.
Go 표준 라이브러리에서 CSV 패키지를 반드시 임포트하세요:
import (
"encoding/csv"
)이것으로 끝입니다! Gospider 크롤링 및 스크래핑 프로젝트가 완전히 구현되었습니다.
6단계: 모든 것을 통합하기
이제scraper.go 파일은 다음과 같아야 합니다:
package main
import (
"bufio"
"encoding/csv"
"os"
"strings"
"github.com/gocolly/colly")
// 스크래핑할 데이터의 데이터 타입 정의
type Product struct {
Title string
Price string
Stars string
ImageURL string
}
func main() {
// 크롤링된 URL이 포함된 입력 파일 열기
file, _ := os.Open("product_urls.txt")
defer file.Close()
// 입력 파일에서 페이지 URL 읽기
var urls []string
scanner := bufio.NewScanner(file)
for scanner.Scan() {
urls = append(urls, scanner.Text())
}
// 스크랩된 데이터를 저장할 배열 생성
var products []Product
// Colly 수집기 설정
c := colly.NewCollector()
c.OnHTML("html", func(e *colly.HTMLElement) {
// 스크래핑 로직
title := e.ChildText("h1")
price := e.DOM.Find(".price_color").First().Text()
stars := ""
e.ForEach(".star-rating", func(_ int, el *colly.HTMLElement) {
class := el.Attr("class")
if strings.Contains(class, "One") {
stars = "1"
} else if strings.Contains(class, "Two") {
stars = "2"
} else if strings.Contains(class, "Three") {
stars = "3"
} else if strings.Contains(class, "Four") {
stars = "4"
} else if strings.Contains(class, "Five") {
stars = "5"
}
})
imageURL := e.ChildAttr("#product_gallery img", "src")
// 상대 이미지 경로 조정
imageURL = strings.Replace(imageURL, "../../", "https://books.toscrape.com/", 1)
// 스크랩된 데이터로 새 제품 객체 생성
product := Product{
Title: title,
Price: price,
Stars: stars,
ImageURL: imageURL,
}
// 제품을 products 슬라이스에 추가
products = append(products, product)
})
// 처음 50개 URL을 반복하여 모두 스크랩
pageLimit := 50 // 대상 서버에 과도한 요청이 발생하지 않도록 제한
for _, url := range urls[:pageLimit] {
c.Visit(url)
}
// 스크랩한 제품 데이터를 CSV로 내보내기
outputFile := "products.csv"
csvFile, _ := os.Create(outputFile)
defer csvFile.Close()
// 새 CSV 라이터 초기화
writer := csv.NewWriter(csvFile)
defer writer.Flush()
// CSV 헤더 작성
writer.Write([]string{"Title", "Price", "Stars", "Image URL"})
// 각 상품 데이터를 CSV에 작성
for _, product := range products {
writer.Write([]string{product.Title, product.Price, product.Stars, product.ImageURL})
}
}아래 명령어로 스크레이퍼 실행:
go run scraper/scraper.go실행에 시간이 다소 소요될 수 있으니 기다려 주세요. 완료되면 프로젝트 폴더에 products.csv 파일이 생성됩니다. 파일을 열면 스크래핑된 데이터가 표 형식으로 깔끔하게 정리된 것을 확인할 수 있습니다:
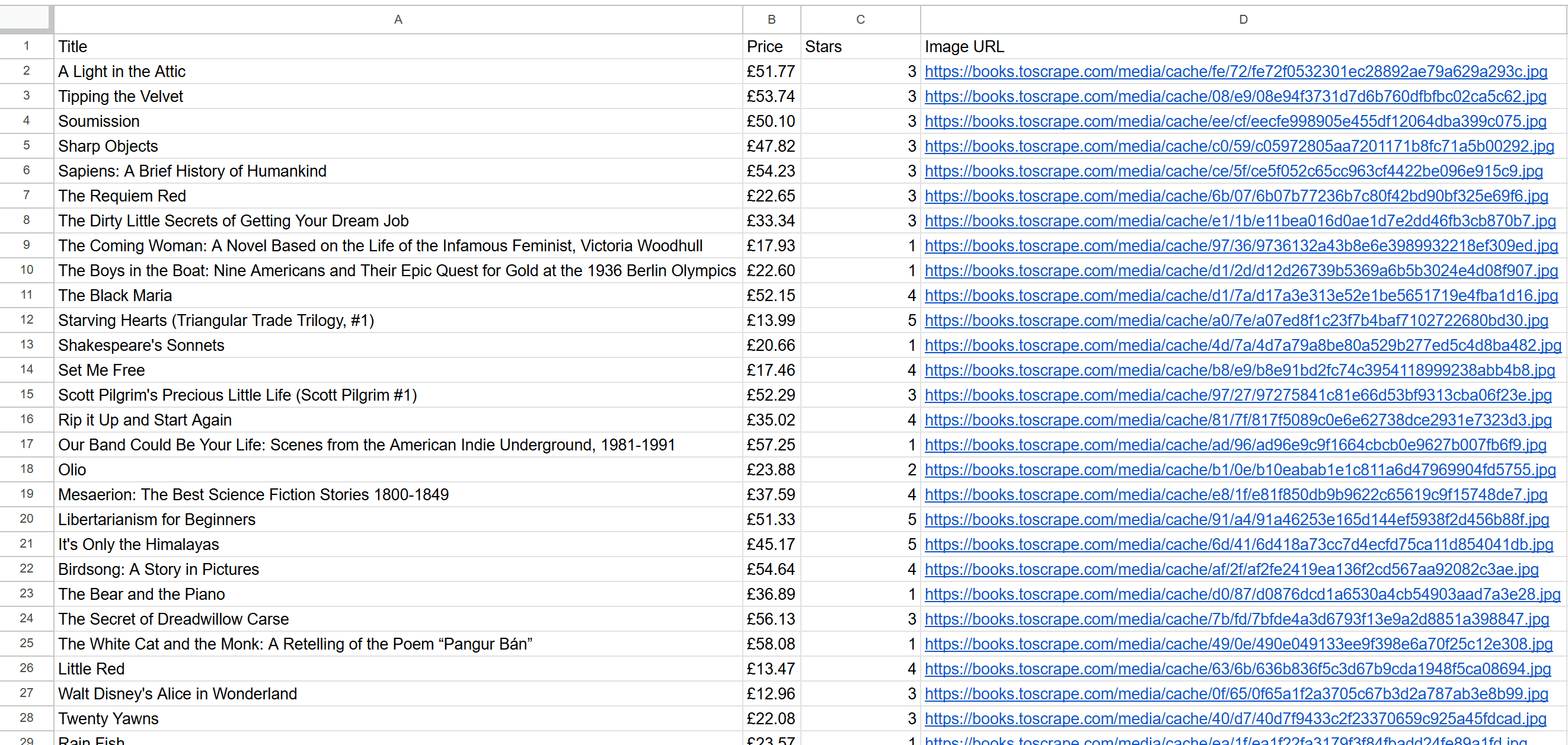
자, 이제 완성되었습니다! 크롤링용 Gospider와 스크래핑용 Colly는 환상의 조합입니다.
Gospider의 웹 크롤링 접근 방식의 한계점
Gospider 크롤링 방식의 가장 큰 한계는 다음과 같습니다:
- 과도한 요청으로 인한 IP 차단.
- 웹사이트가 크롤링 봇을 차단하기 위해 사용하는 크롤링 방지 기술.
두 가지 모두 해결하는 방법을 알아봅시다!
IP 차단 방지
동일한 기기에서 너무 많은 요청을 보내면 대상 서버에 의해 IP 주소가 차단될 수 있습니다. 이는 웹 크롤링에서 흔히 발생하는 문제로, 특히 설정이 부적절하거나 윤리적으로 계획되지 않은 경우에 더욱 그렇습니다.
기본적으로 Gospider는 robots.txt를 준수하여 이러한 위험을 최소화합니다. 그러나 모든 웹사이트에 robots.txt 파일이 있는 것은 아닙니다. 또한 해당 파일이 있더라도 크롤러에 대한 유효한 속도 제한 규칙을 명시하지 않을 수 있습니다.
IP 차단 위험을 줄이려면 Gospider의 내장된 --delay, --random-delay, --timeout 플래그를 사용하여 요청 속도를 늦출 수 있습니다. 하지만 적절한 조합을 찾는 데 시간이 많이 소요될 수 있으며 항상 효과적이지는 않을 수 있습니다.
보다 효과적인 해결책은 로테이팅 프록시를 사용하는 것입니다. 이는 Gospider의 각 요청이 서로 다른 IP 주소에서 발생하도록 보장하여 대상 사이트가 크롤링 시도를 탐지하고 차단하는 것을 방지합니다.
Gospider에서 로테이팅 프록시를 사용하려면 -p (또는 --proxy) 플래그와 함께 프록시 URL을 전달하세요:
gospider -s "https://example.com" -o output -p "<PROXY_URL>"회전 프록시 URL이 없다면 무료로 하나를 가져오세요!
크롤링 방지 기술 우회
회전 프록시를 사용하더라도 일부 웹사이트는 강력한 스크래핑 및 크롤링 방지 조치를 시행합니다. 예를 들어, Cloudflare로 보호된 웹사이트에 대해 다음 Gospider 명령을 실행하면:
gospider -s "https://community.cloudflare.com/" -o output결과는 다음과 같습니다:
[url] - [code-403] - https://community.cloudflare.com/보시다시피 대상 서버는 403 Forbidden 응답을 반환했습니다. 이는 서버가 Gospider의 요청을 성공적으로 탐지하여 차단했음을 의미하며, 페이지 내 모든 URL 크롤링을 방지한 것입니다.
이러한 차단을 피하려면 올인원 웹 언락킹 API가 필요합니다. 해당 서비스는 안티봇 및 안티스크래핑 시스템을 우회하여 모든 웹페이지의 차단되지 않은 HTML에 접근할 수 있게 해줍니다.
참고: Bright Data의 웹 언락커는 이러한 문제를 해결할 뿐만 아니라 프록시 역할도 수행할 수 있습니다. 따라서 설정 후에는 앞서 보여드린 구문으로 Gospider와 함께 일반 프록시처럼 사용할 수 있습니다.
결론
이 블로그 글에서는 Gospider가 무엇인지, 어떤 기능을 제공하는지, 그리고 Go에서 웹 크롤링에 활용하는 방법을 알아보았습니다. 또한 Colly와 결합하여 완전한 크롤링 및 스크래핑 튜토리얼을 구현하는 방법도 살펴보았습니다.
웹 스크래핑에서 가장 큰 과제 중 하나는 IP 차단이나 스크래핑 방지 솔루션으로 인한 차단 위험입니다. 이러한 문제를 극복하는 최선의 방법은 웹 프록시나 Web Unlocker 같은 스크래핑 API를 사용하는 것입니다.
Gospider와의 통합은 Bright Data의 제품 및 서비스가 지원하는 수많은 시나리오 중 하나에 불과합니다. 당사의 다른 웹 스크래핑 도구도 살펴보세요:
- 웹 스크레이퍼 API: 100개 이상의 인기 도메인에서 최신 구조화된 웹 데이터를 추출하기 위한 전용 엔드포인트.
- SERP API: SERP의 지속적인 잠금 해제 관리를 처리하고 한 페이지를 추출하는 API.
- 스크래핑 함수: 서버리스 함수로 스크레이퍼를 실행할 수 있는 완벽한 스크래핑 인터페이스.
- 스크래핑 브라우저: 내장된 잠금 해제 기능을 갖춘 Puppeteer, Selenium, Playwright 호환 브라우저
지금 Bright Data에 가입하여 프록시 서비스와 스크래핑 제품을 무료로 테스트해 보세요!




