

이 가이드에서는 다음을 확인할 수 있습니다:
- 크런치베이스 스크레이퍼란 무엇이며 어떻게 작동하는지
- Crunchbase에서 자동으로 수집 가능한 데이터
- 파이썬으로 크런치베이스 스크래핑 스크립트 구축 방법
- 사이트 스크래핑을 위해 더 고급 솔루션이 필요한 이유
자, 시작해 보겠습니다!
크런치베이스 스크레이퍼란 무엇인가요?
크런치베이스 스크레이퍼는 크런치베이스 웹 페이지에서 데이터를 추출하도록 설계된 자동화 도구입니다. 사이트를 탐색하며 원하는 정보를 식별하고 웹 스크래핑을 통해 수집합니다.
Crunchbase는 데이터 보호를 위해 고급 봇 방지 및 스크래핑 방지 조치를 사용합니다. 따라서 효과적인 Crunchbase 스크래퍼는 JavaScript 렌더링, CAPTCHA 해결, 브라우저 지문 스푸핑과 같은 기능을 포함해야 합니다.
크런치베이스에서 스크래핑할 데이터
웹 스크래핑을 통해 Crunchbase에서 자동으로 추출할 수 있는 데이터 목록은 다음과 같습니다:
- 기업 정보: 이름, 설명, 업종, 본사 위치, 설립일, 상태(예: 운영 중, 인수됨) 등
- 자금 조달 데이터: 총 자금 조달액, 자금 조달 라운드, 투자자 등
- 핵심 인물: 창업자, 임원진, 구성원, 역할 및 직함 등
- 제품 및 서비스: 제품 설명, 제공되는 제품 또는 서비스의 범주 등
- 인수 및 합병: 인수된 기업 상세 정보, 인수 날짜 및 조건 등
- 시장 및 재무 데이터: 매출 추정액, 직원 수 등
- 뉴스 및 이벤트: 보도 자료, 주요 이정표 또는 이벤트 등
- 경쟁사: 경쟁 기업 목록 등
파이썬으로 Crunchbase 스크래퍼 구축 방법
이 튜토리얼 섹션에서는 Python을 사용하여 Crunchbase 스크레이퍼를 만드는 방법을 배웁니다. 목표는 Bright Data Crunchbase 페이지에서 데이터를 자동으로 수집할 수 있는 스크립트를 개발하는 것입니다:
Python으로 Crunchbase를 스크래핑하는 방법을 알아보려면 아래 단계를 따르세요!
1단계: Python 프로젝트 생성
먼저, 컴퓨터에 Python 3 이상이 설치되어 있는지 확인하세요. 설치되어 있지 않다면 공식 사이트에서 다운로드하고 안내에 따라 설치하세요 .
Python Crunchbase 스크레이퍼용 디렉터리를 생성하세요:
mkdir crunchbase-scrapercrunchbase-scraper 폴더에는 스크래핑 봇이 포함됩니다.
PyCharm Community Edition 이나 Python 확장 프로그램이 설치된 Visual Studio Code 등 선호하는 Python IDE로 프로젝트 폴더를 엽니다.
다음으로 프로젝트 폴더 내에 scraper.py 파일을 생성하세요. 이 파일에 Crunchbase 스크래핑 로직이 포함됩니다.
이제 Python 가상 환경을 초기화합니다. macOS 또는 Linux 사용자의 경우 다음 명령을 실행하세요:
python3 -m venv envWindows에서는 동일하게 다음 명령을 실행하세요:
python -m venv env이렇게 하면 프로젝트에 env 디렉터리가 추가됩니다.
현재 프로젝트 구조는 다음과 같아야 합니다:

다음 명령어로 가상 환경을 활성화하세요:
source env/bin/activate또는 Windows에서는:
envScriptsactivate좋습니다! 이제 로컬 종속성을 설치할 수 있는 Python 프로젝트가 준비되었습니다.
스크립트를 실행하려면 다음을 사용하세요:
python3 scraper.py또는 Windows에서는:
python scraper.py2단계: 스크래핑 라이브러리 확인 및 설치
이제 Crunchbase에서 데이터를 추출하는 데 가장 적합한 스크래핑 라이브러리를 찾아야 합니다. 먼저 데스크톱 HTTP 클라이언트를 사용하여 대상 웹페이지에 GET HTTP 요청을 보내보세요. 다음과 같은 결과를 얻을 수 있습니다:
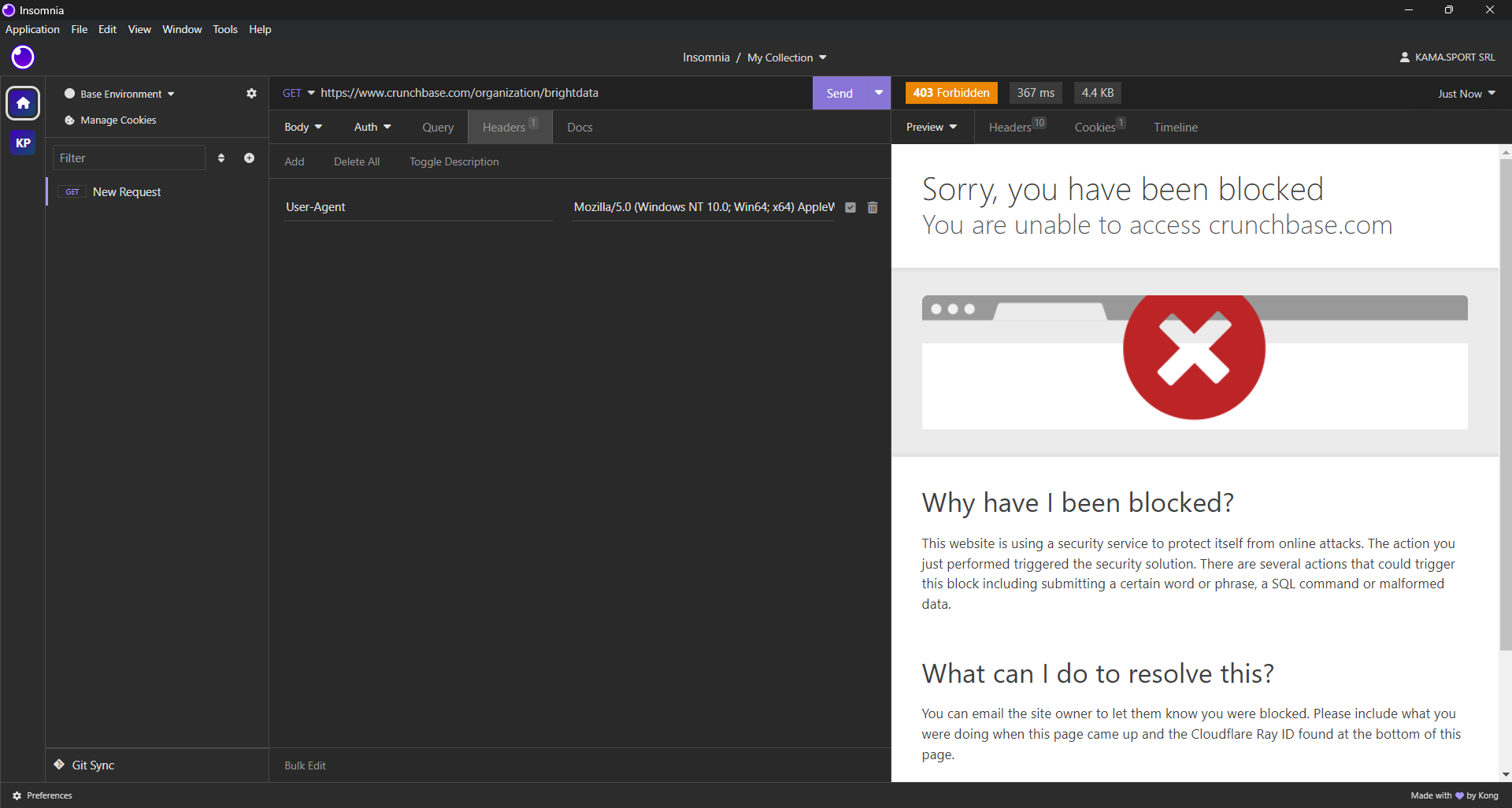
보시다시피, Crunchbase는 현실적인 브라우저 헤더를 사용하더라도 요청을 차단합니다. 즉, Crunchbase를 효과적으로 스크래핑하려면 브라우저 자동화 도구가 필요합니다. 최고의 헤드리스 브라우저에 대한 저희 기사에서 자세히 알아보세요.
파이썬의 경우, 셀레니움(Selenium )이 가장 널리 쓰이는 헤드리스 브라우저 자동화 도구 중 하나입니다. 구체적으로, 브라우저가 특정 상호작용을 수행하고 동적 페이지에서 데이터를 스크래핑하도록 지시할 수 있게 해줍니다.
Selenium을 설치하려면 selenium pip 패키지를 사용하세요. 활성화된 Python 가상 환경에서 다음 명령어를 실행합니다:
pip install -U selenium그런 다음 scraper.py 파일에서 다음 줄로 Selenium을 임포트하세요:
from selenium import webdriver훌륭합니다! 이제 Crunchbase에서 웹 스크래핑을 수행하는 데 필요한 모든 준비가 완료되었습니다.
3단계: 대상 페이지 방문
Chrome WebDriver 인스턴스를 초기화하고 get() 메서드를 사용하여 제어되는 브라우저가 원하는 페이지를 방문하도록 지시합니다:
driver = webdriver.Chrome()
url = "https://www.crunchbase.com/organization/brightdata"
driver.get(url)그런 다음 WebDriver를 닫고 브라우저 리소스를 해제하는 것을 잊지 마세요:
driver.quit()현재 Crunchbase 스크래퍼 스크립트는 다음과 같이 구성됩니다:
from selenium import webdriver
# Chrome 인스턴스를 제어하기 위한 드라이버 초기화
# 헤더 모드에서 실행
driver = webdriver.Chrome()
# 원하는 Crunchbase 페이지로 이동
url = "https://www.crunchbase.com/organization/brightdata"
driver.get(url)
# 스크래핑 로직...
# 드라이버 종료 및 브라우저 리소스 해제
driver.quit()실행하면 스크립트가 종료되기 직전 다음과 같은 페이지가 순간적으로 표시됩니다:
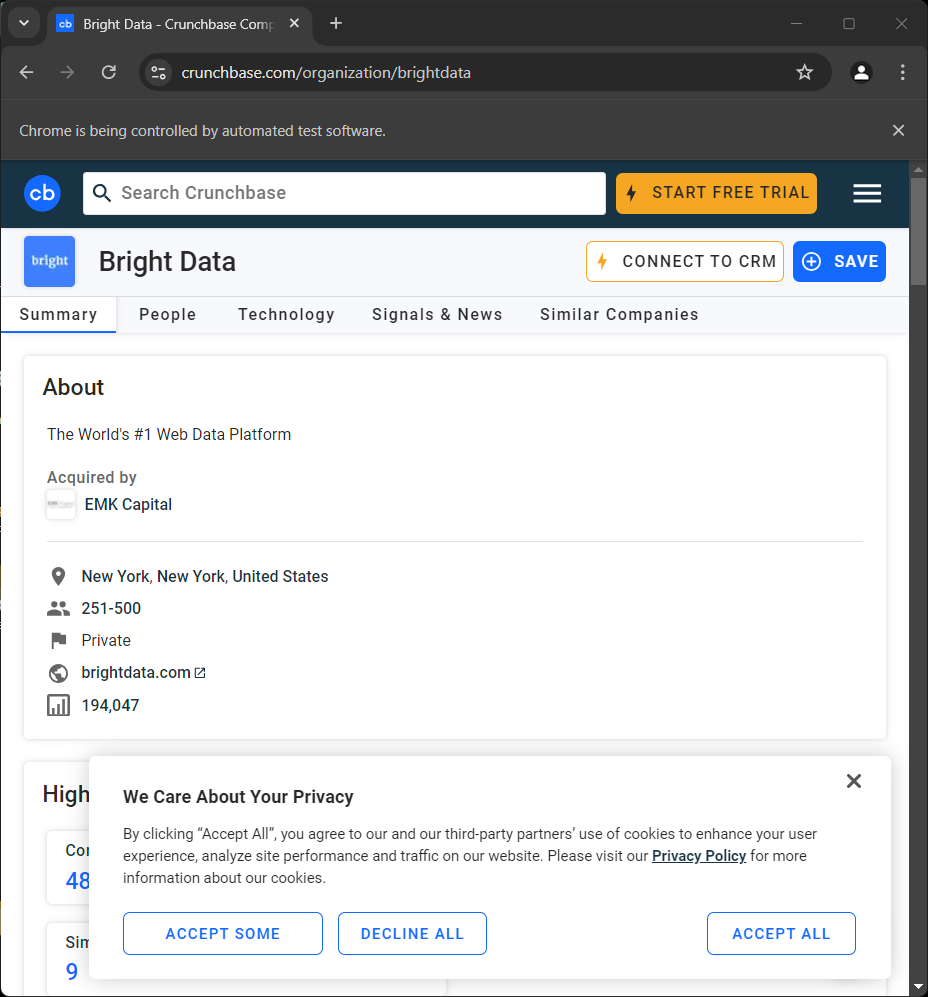
“Chrome이 테스트 소프트웨어에 의해 제어되고 있습니다”라는 메시지는 Selenium이 의도한 대로 Chrome에서 작동하고 있음을 나타냅니다.
일반적으로 Selenium 스크래핑 스크립트에서 브라우저는 리소스 절약을 위해 헤드리스 모드로 실행됩니다. 안타깝게도 Crunchbase는 헤드리스 브라우저를 차단하는 고급 봇 탐지 시스템을 갖추고 있습니다. 따라서 브라우저를 헤드드 모드로 유지해야 합니다. 또는 Playwright Stealth를 사용하여 이러한 탐지 메커니즘을 우회해 볼 수도 있습니다.
단계 #4: 쿠키 팝업 처리
유럽 사용자의 경우, 페이지가 몇 초 후 다음과 같은 쿠키 팝업을 표시합니다:
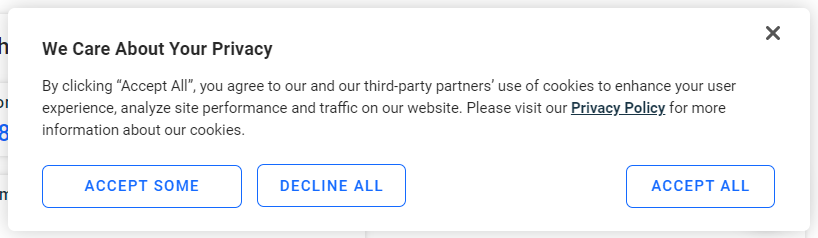
“모두 수락” 버튼을 클릭하지 않으면 페이지와 상호작용할 수 없습니다. 버튼을 검사해 보세요:
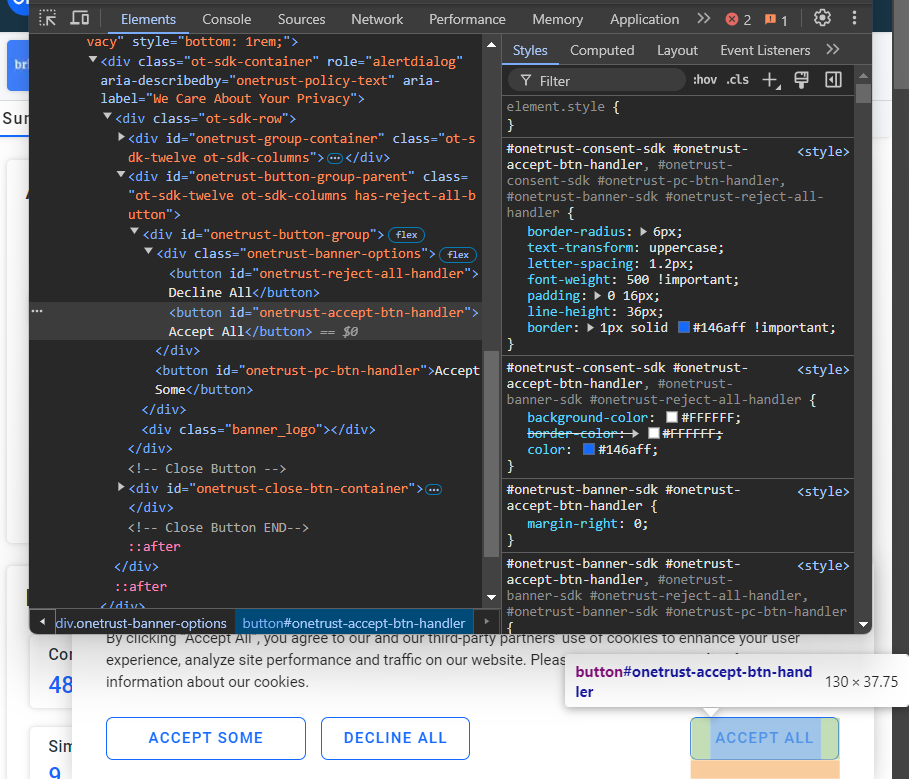
#onetrust-accept-btn-handler CSS 선택자로 선택할 수 있음을 확인하세요.
이제 “모두 수락” 버튼이 페이지에 표시되고 클릭 가능한 상태가 될 때까지 최대 60초 동안 대기한 후 클릭하는 함수를 작성하세요:
def handle_cookie_banner(driver, seconds=60):
try:
# 쿠키 배너의 "모두 수락" 버튼이 페이지에 나타날 때까지
# 지정된 초 수만큼 대기
accept_button = WebDriverWait(driver, seconds).until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "#onetrust-accept-btn-handler"))
)
# ElementClickInterceptedException 오류를 피하기 위해
# JavaScript를 통해 배너 클릭
driver.execute_script("arguments[0].click();", accept_button)
print("'Accept All' 버튼 클릭됨")
except:
print("{seconds}초 이내에 'Accept All' 버튼을 찾지 못함")참고:
- 쿠키 팝업이 페이지에 표시되지 않을 수 있으므로
try ... except블록이 필요합니다. 이 경우WebDriverWait는NoSuchElementException을발생시키며, 이는except에의해 처리됩니다. - “Accept All”은
click()메서드가 아닌 JavaScript를 통해 클릭됩니다. HTML 버튼이 페이드 인 애니메이션과 함께 서서히 나타나기 때문입니다. 따라서click()으로 클릭을 시도하면ElementClickInterceptedException이발생할 수 있습니다.
위 함수가 작동하려면 다음 임포트가 필요합니다:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By이제 쿠키 팝업을 다음과 같이 호출하여 처리할 수 있습니다:
handle_cookie_banner(driver)훌륭합니다! 이제 페이지에서 데이터 스크래핑을 시작할 준비가 되었습니다.
5단계: 회사 정보 스크래핑
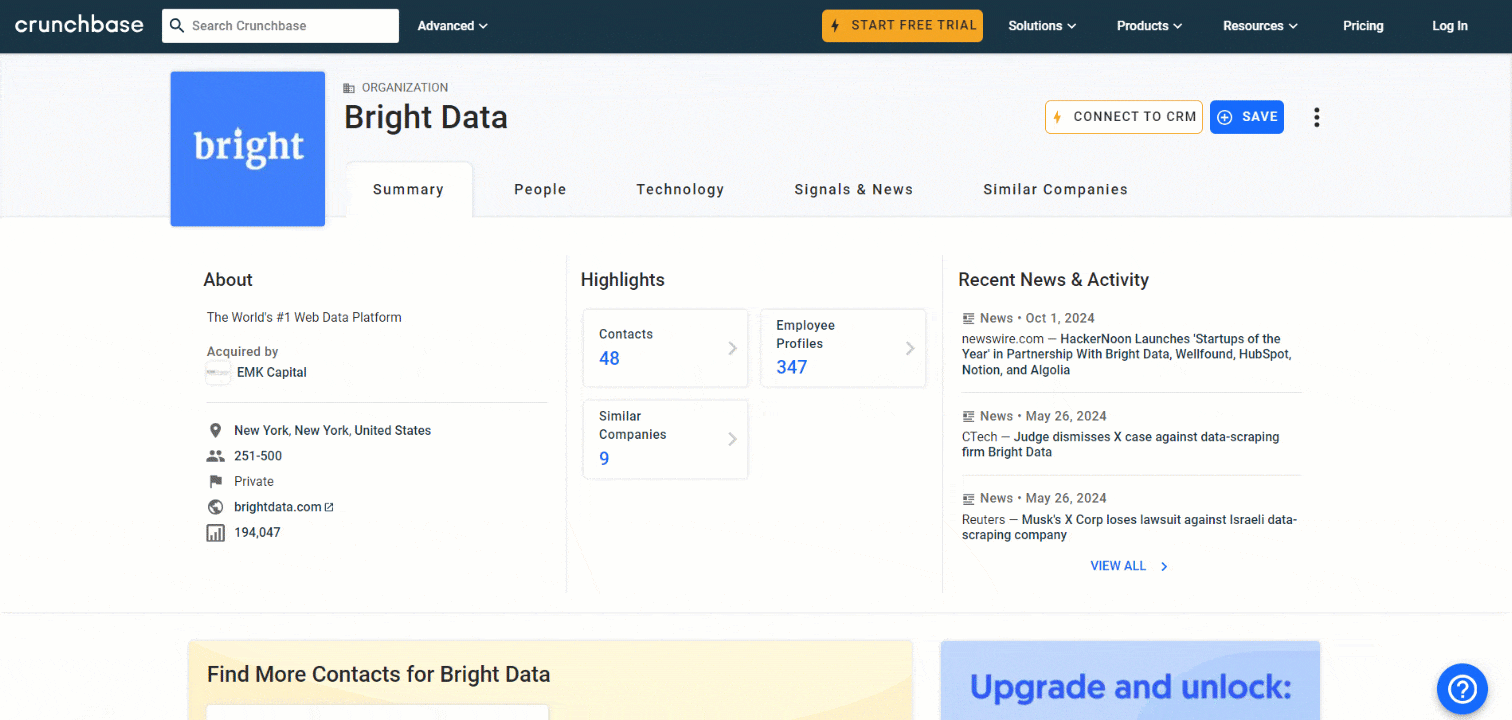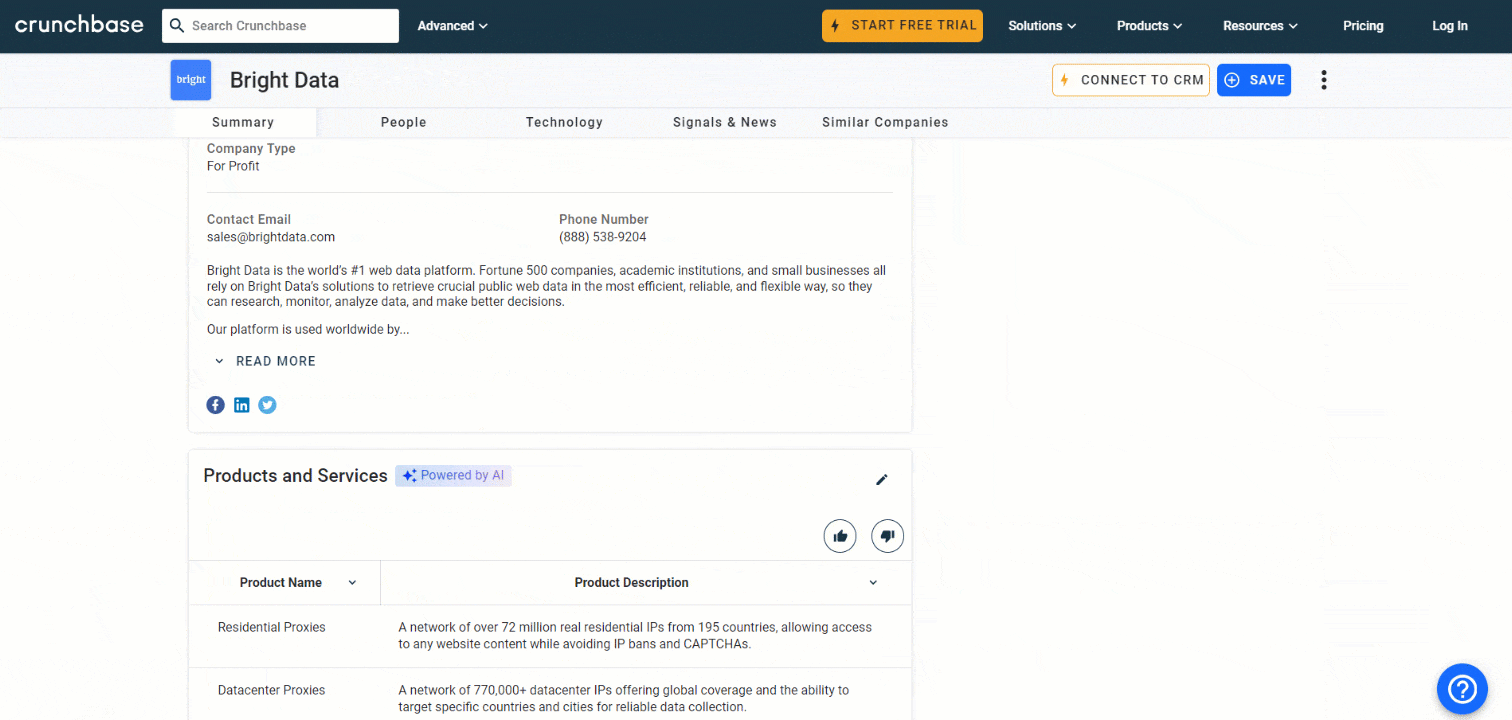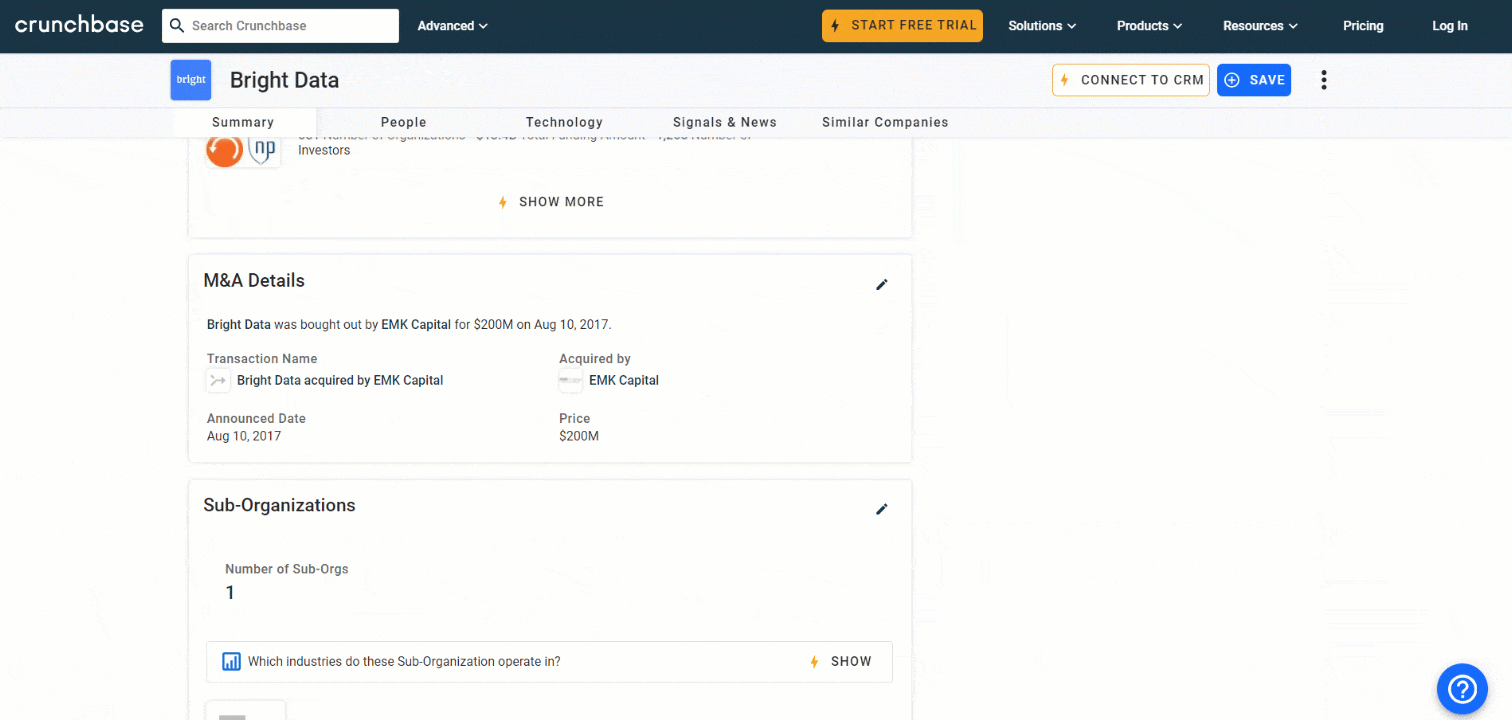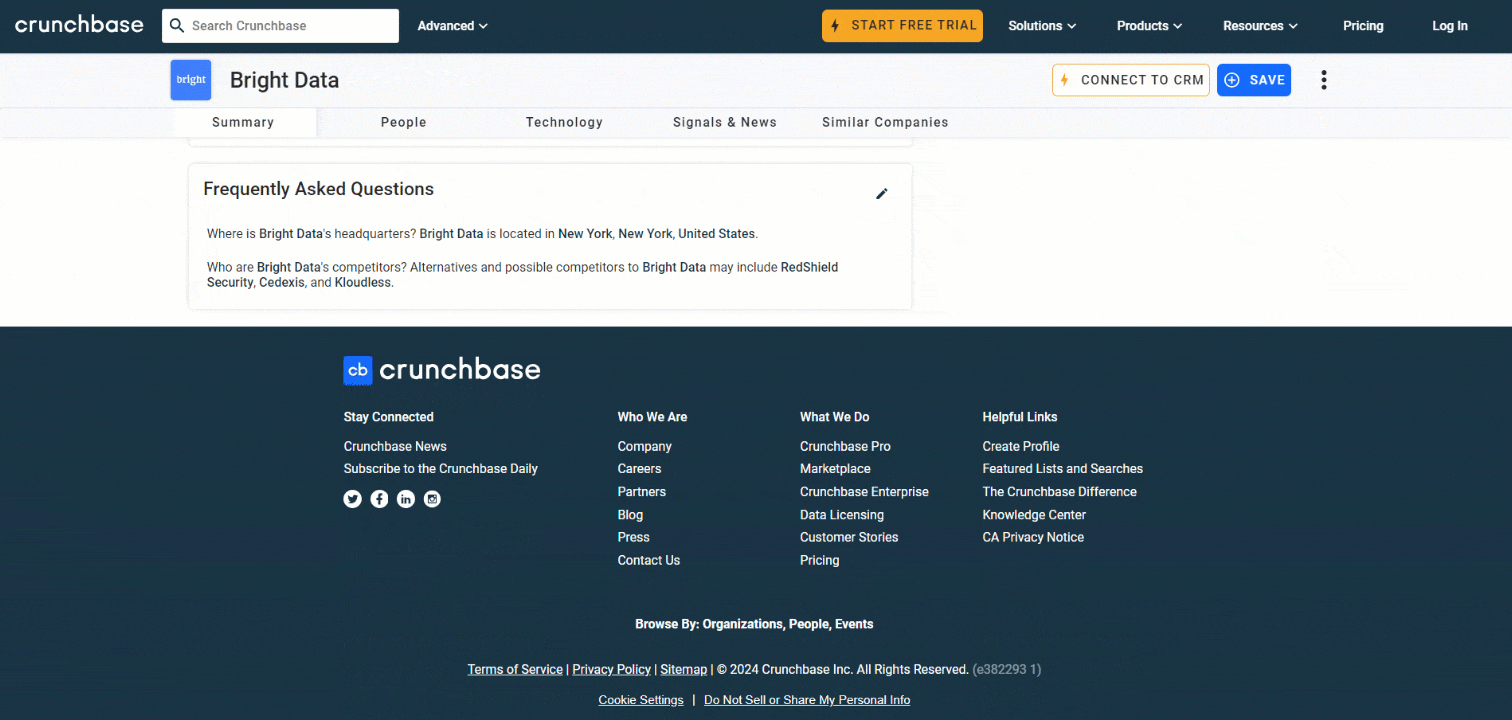
“요약” 카드에서 스크래핑할 첫 번째 정보는 회사의 “회사 소개” 설명입니다:
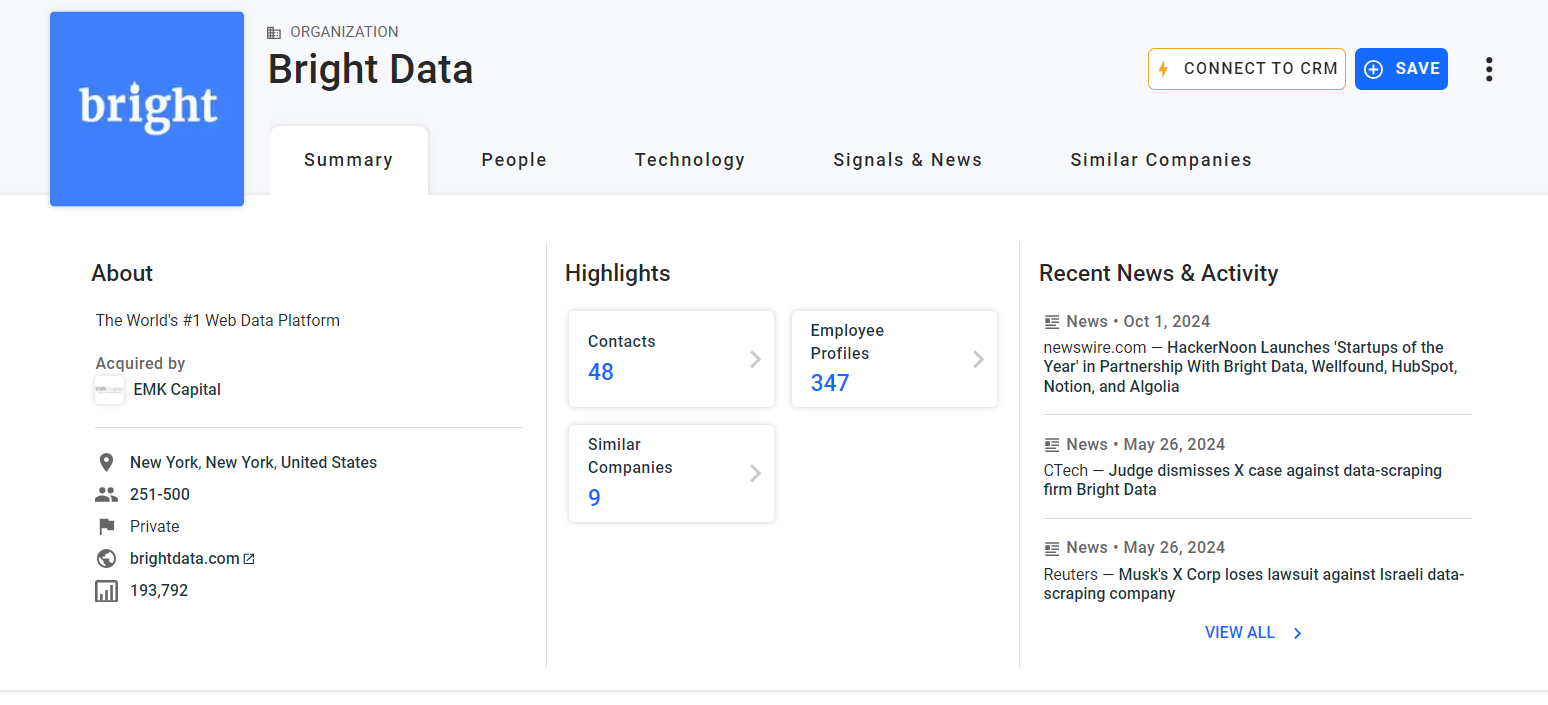
“About” HTML 요소를 검사하세요:
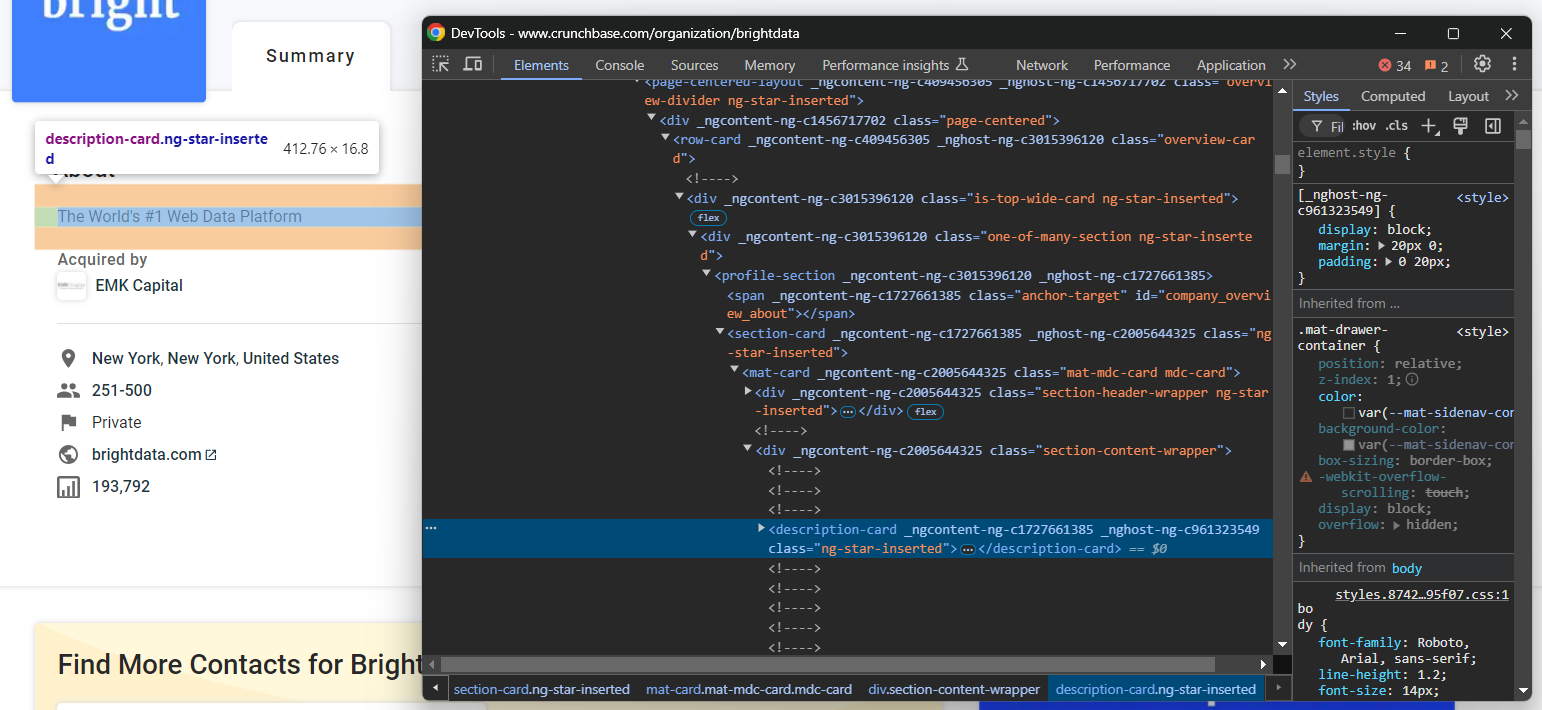
아래 CSS 선택자로 선택할 수 있습니다:
profile-section description-cardfind_element() 메서드를 사용하여 페이지에 CSS 선택기를 적용합니다. 그런 다음 text 속성을 사용하여 노드 내부의 텍스트를 추출합니다:
about_node = driver.find_element(By.CSS_SELECTOR, "profile-section description-card")
about = about_node.text이제 about 변수에는 다음 내용이 포함됩니다:
'세계 최고의 웹 데이터 플랫폼'시작해 보겠습니다!
6단계: 페이지 구조 검사
이제 페이지의 “Details” 카드에 포함된 정보에 집중하세요:
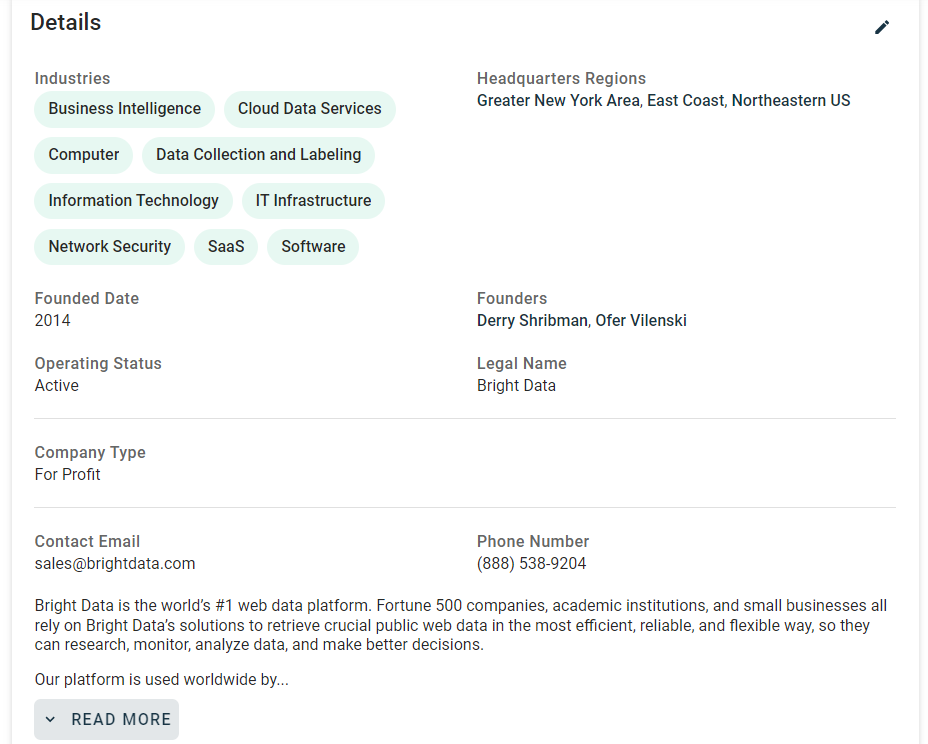
이 부분을 살펴보면, 데이터를 추출할 HTML 요소를 선택하기가 쉽지 않다는 점을 알 수 있습니다:
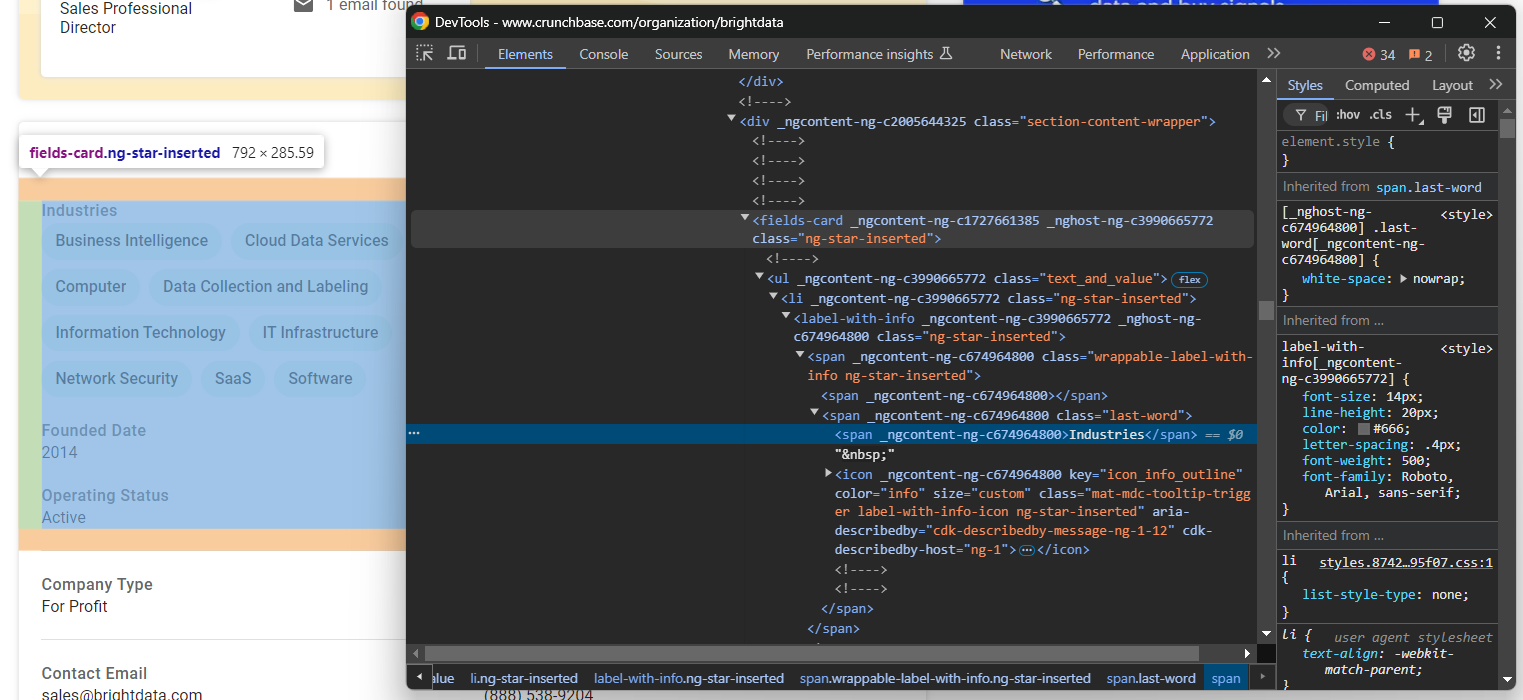
대부분의 노드에는 빌드 시점에 생성된 것으로 보이는 임의의 HTML 속성이 있습니다. 이러한 속성은 배포 후마다 변경되므로 노드 선택에 의존할 수 없습니다. 또한 많은 요소가 고유한 클래스나 ID로 표시되지 않습니다.
관심 요소를 선택하는 효과적인 접근법은 해당 레이블에 집중하는 것입니다. 예를 들어, “산업” 문자열을 포함하는 label-with-info 노드를 가진 fields-card를 식별함으로써 산업 정보를 포함하는 fields-card 노드를 선택할 수 있습니다.
이 기법은 해당 섹션의 데이터 스크래핑에 사용될 것입니다. 따라서 관련 로직을 함수에 집중시키는 것이 합리적입니다:
def find_parent_node_based_on_child_node_text(parent_nodes_selector, child_node_selector, text):
# 모든 부모 노드 선택
parent_nodes = driver.find_elements(By.CSS_SELECTOR, parent_nodes_selector)
# 원하는 텍스트를 포함하는 특정 자식 노드를 가진 부모 노드를 찾기 위해 반복
for parent_node in parent_nodes:
try:
# 현재 부모 노드 내 특정 자식 노드 획득
child_node = parent_node.find_element(By.CSS_SELECTOR, child_node_selector)
# 원하는 텍스트 포함 여부 확인
if text.upper() in child_node.text.upper():
return parent_node
except:
continue
return None위의 함수를 사용하여 “산업” 필드 카드 노드를 선택합니다:
industries_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Industries")훌륭합니다! 이제 Crunchbase 스크래핑이 훨씬 쉬워질 것입니다.
7단계: 회사 정보 스크래핑
“산업” 노드를 검사해 보세요:
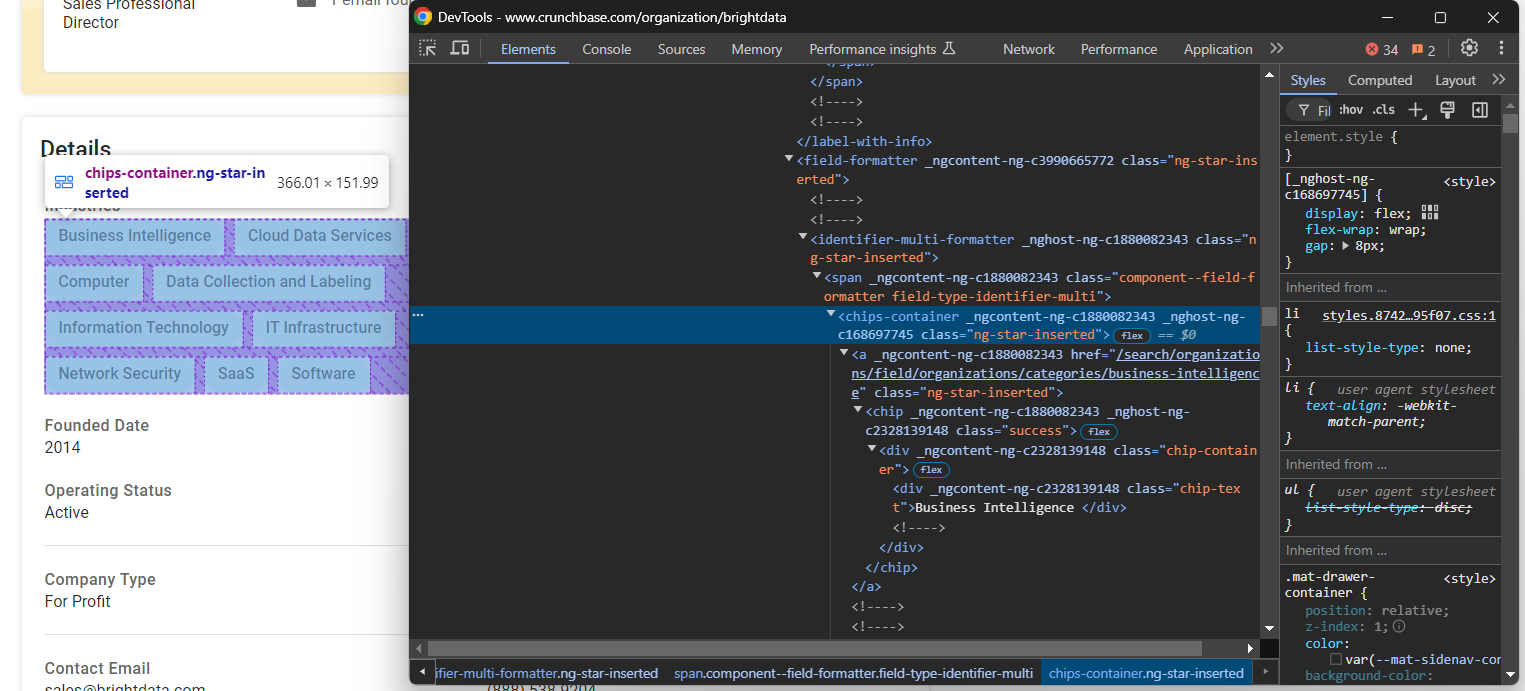
해당 노드에는 회사가 운영하는 산업 분야가 chips-container a 노드에 저장되어 있습니다. 모두 선택하고 반복 처리하여 데이터를 추출하세요:
industries_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Industries")
industries_nodes = industries_parent_node.find_elements(By.CSS_SELECTOR, "chips-container a")
industries = []
for industry_node in industries_nodes:
industries.append(industry_node.text)이제 “설립일” 요소에 집중해 보겠습니다:
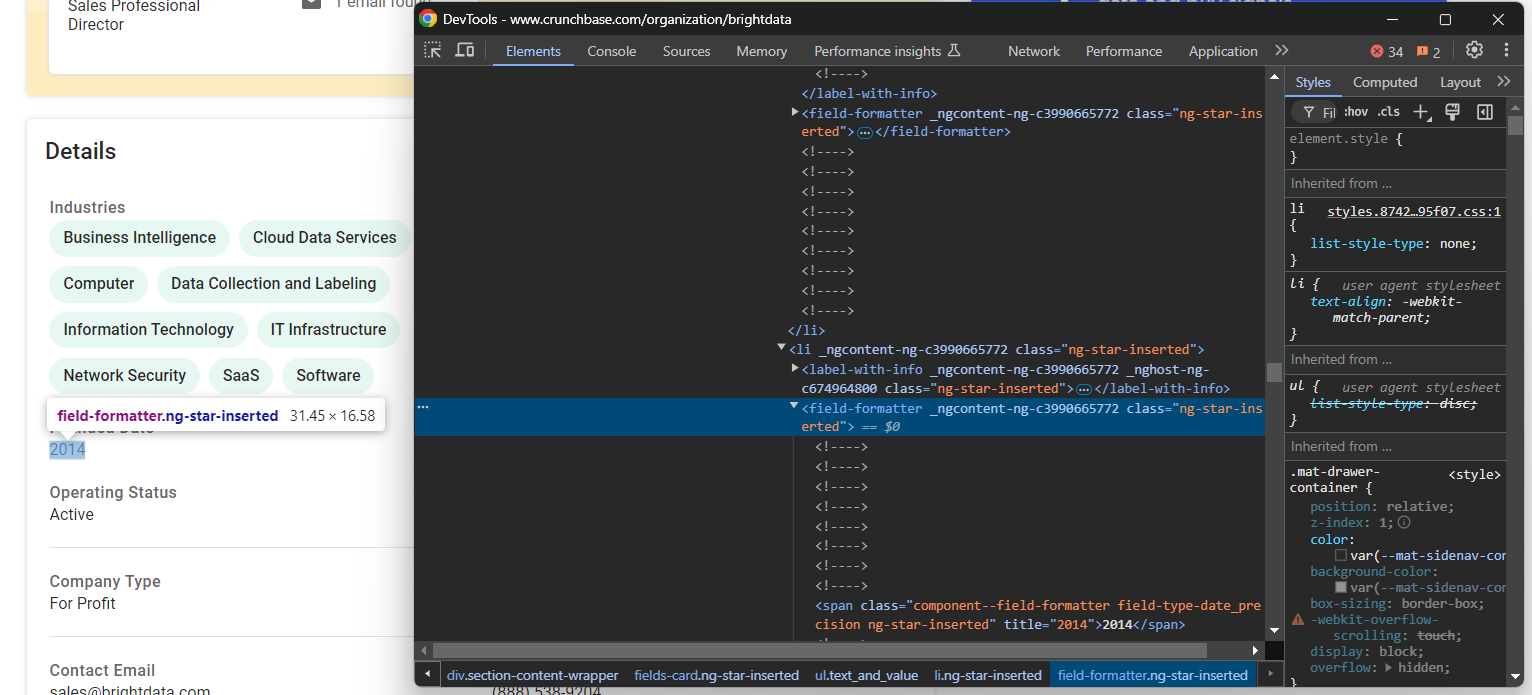
이 경우, 부모 fields-card li 노드 내 field-formatter 요소에서 텍스트만 추출하면 되므로 스크래핑 로직이 더 간단합니다:
founded_date_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Founded Date")
founded_date_node = founded_date_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
founded_date = founded_date_node.text동일한 논리를 대부분의 다른 회사 세부 정보 요소에도 적용할 수 있습니다:
회사_유형_부모_노드 = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "회사 유형")
회사_유형_노드 = 회사_유형_부모_노드.find_element(By.CSS_SELECTOR, "field-formatter")
회사_유형 = 회사_유형_노드.text
operating_status_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "운영 상태")
operating_status_node = operating_status_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
operating_status = operating_status_node.text
headquarters_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "본사 소재 지역")
headquarters_node = headquarters_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
headquarters = headquarters_node.text
legal_name_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Legal Name")
legal_name_node = legal_name_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
legal_name = legal_name_node.text
contact_email_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Contact Email")
contact_email_node = contact_email_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
contact_email = contact_email_node.text
phone_number_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "전화번호")
phone_number_node = phone_number_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
phone_number = phone_number_node.text특별한 주의가 필요한 또 다른 노드는 “창립자(Founders)” 요소입니다:
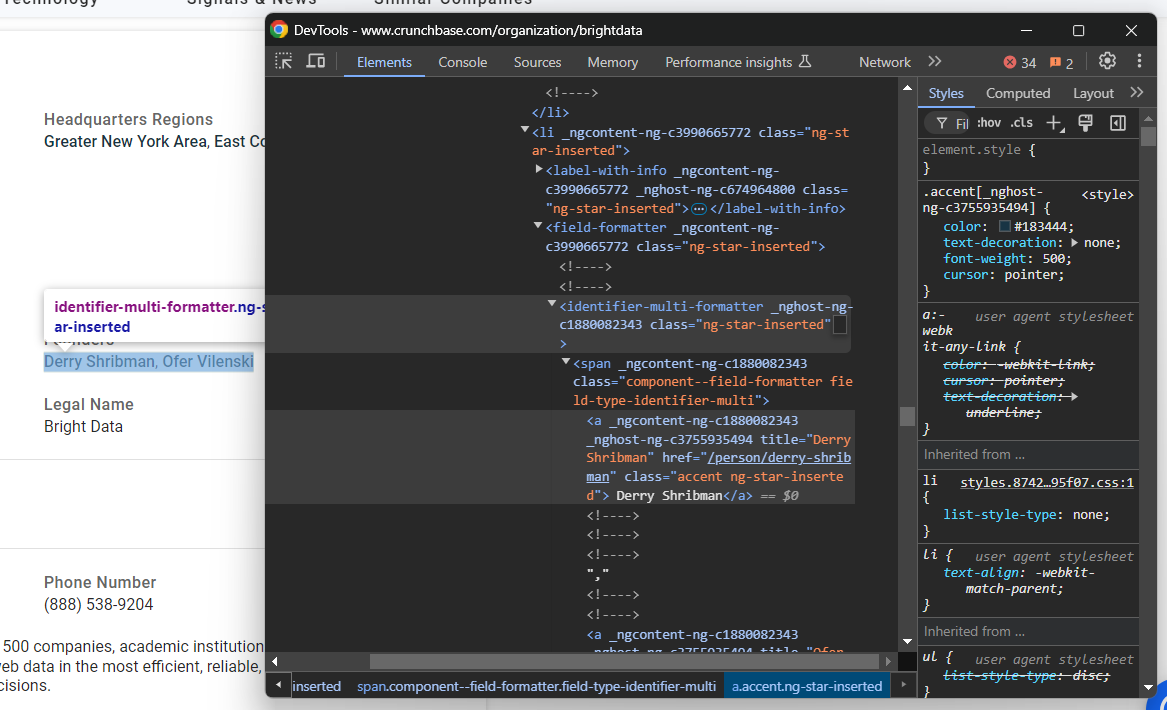
이 경우, identifier-multi-formatter a 노드를 반복 처리하여 데이터를 추출해야 합니다:
founders_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Founders")
founders_nodes = founders_parent_node.find_elements(By.CSS_SELECTOR, "identifier-multi-formatter a")
founders = []
for founders_node in founders_nodes:
founders.append(founders_node.text)마지막으로, “Details” 섹션 끝에 있는 설명 노드를 살펴보세요:
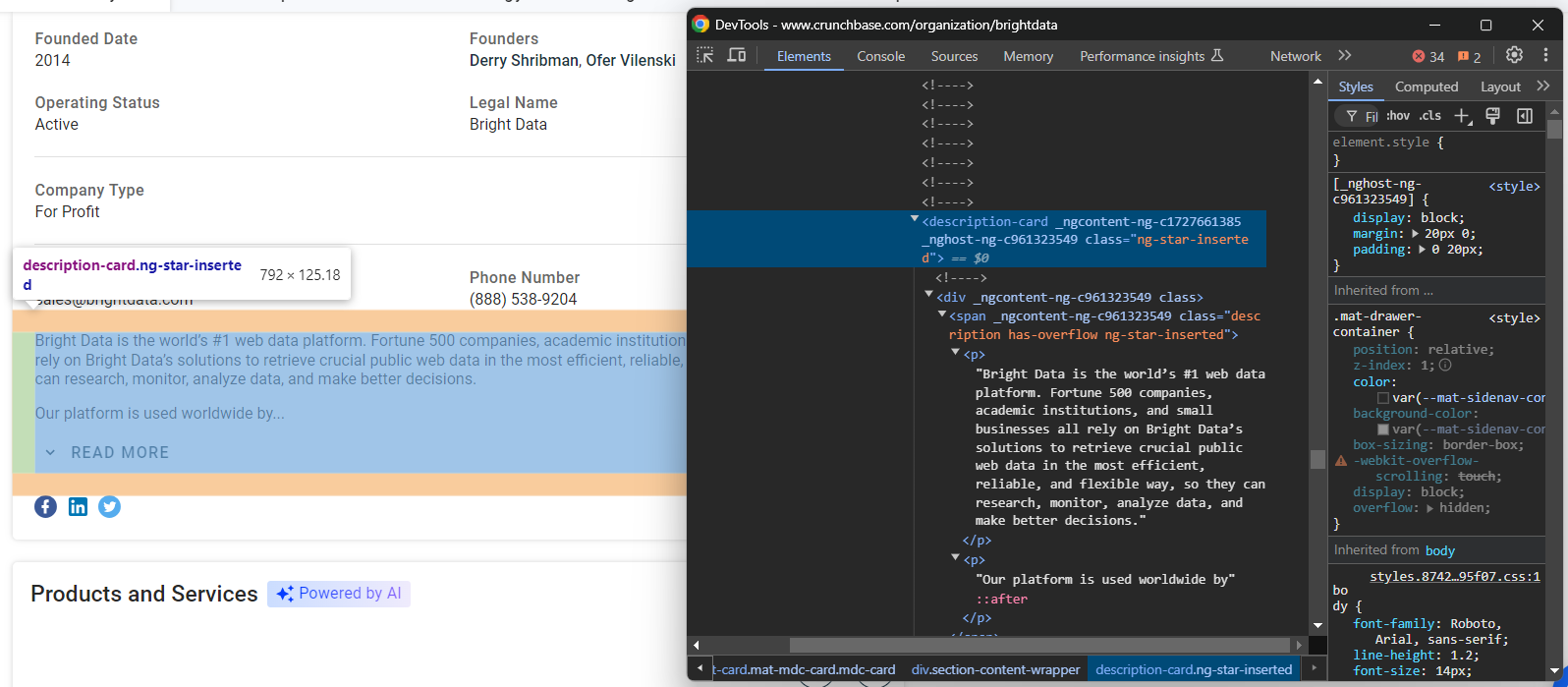
다음 코드로 이 데이터를 추출하세요:
description_node = driver.find_element(By.CSS_SELECTOR, "section-card description-card")
description = description_node.text대단합니다! 크런치베이스 스크레이퍼가 거의 완성되었습니다.
8단계: 제품 및 서비스 테이블 스크래핑
수집할 가치가 있는 다른 정보는 회사가 제공하는 제품 및 서비스 목록입니다:
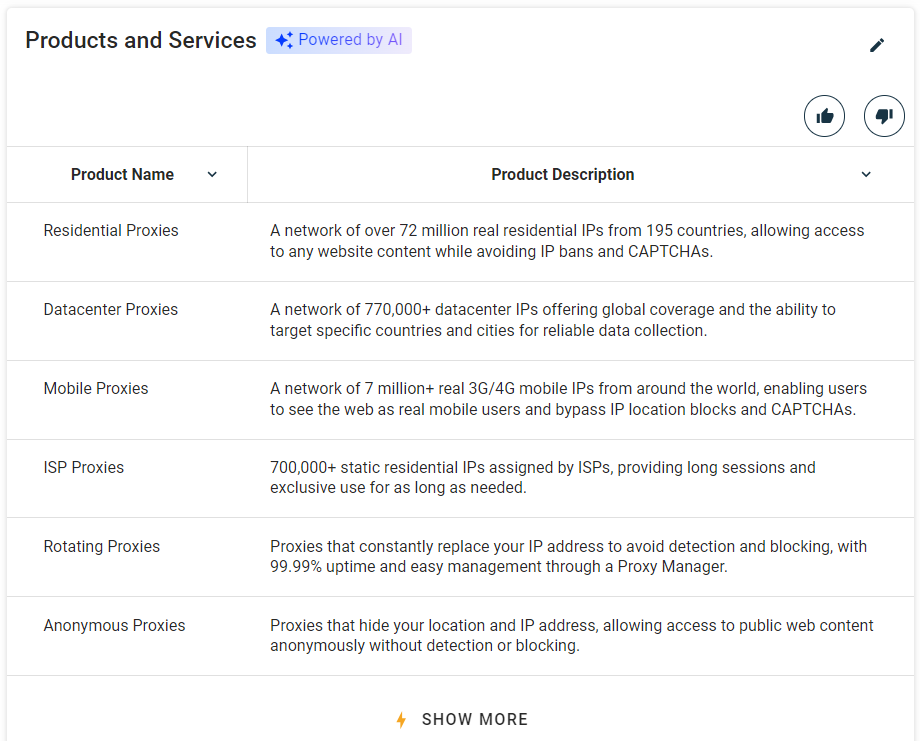
앞서 정의한 함수를 사용하여 “제품 및 서비스” 섹션을 선택하세요:
products_parent_node = find_parent_node_based_on_child_node_text("profile-section", ".section-title", "Products and Services")그런 다음 테이블에서 데이터를 스크래핑합니다:
products = []
for row in products_table_rows:
# 각 행의 열에서 이름과 설명 추출
name = row.find_element(By.CSS_SELECTOR, "td:nth-child(1)").text
description = row.find_element(By.CSS_SELECTOR, "td:nth-child(2)").text
product = {
"name": name,
"description": description
}
products.append(product)대단하네요! Crunchbase 스크래핑 로직이 완료되었습니다.
단계 #9: 스크랩된 데이터 내보내기
스크래핑된 데이터로 회사 사전 채우기:
company = {
"about": about,
"industries": industries,
"founded_date": founded_date,
"company_type": company_type,
"operating_status": operating_status,
"headquarters": headquarters,
"founders": founders,
"email": contact_email,
"phone": phone_number,
"description": description,
"products": products
}다음으로 company.json 파일로 내보내기:
with open("company.json", "w") as json_file:
json.dump(company, json_file, indent=4)먼저 open() 이 company.json 출력 파일을 생성합니다. 그런 다음 json.dump() 가 company를 JSON 표현으로 변환하여 출력 파일에 기록합니다.
Python 표준 라이브러리에서 json을 임포트하는 것을 잊지 마세요:
import json10단계: 모든 것을 통합하기
다음은 최종 scraper.py 파일입니다:
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import json
def find_parent_node_based_on_child_node_text(parent_nodes_selector, child_node_selector, text):
# 모든 부모 노드 선택
parent_nodes = driver.find_elements(By.CSS_SELECTOR, parent_nodes_selector)
# 원하는 텍스트를 포함하는 특정 자식 노드를 가진 부모 노드 찾기
for parent_node in parent_nodes:
try:
# 현재 부모 노드 내 특정 자식 노드 가져오기
child_node = parent_node.find_element(By.CSS_SELECTOR, child_node_selector)
# 원하는 텍스트 포함 여부 확인
if text.upper() in child_node.text.upper():
return parent_node
except:
continue
return None
def handle_cookie_popup(driver, seconds=60):
try:
# 쿠키 팝업의 "모두 수락" 버튼이 페이지에 나타날 때까지
# 지정된 초 동안 대기
accept_button = WebDriverWait(driver, seconds).until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "#onetrust-accept-btn-handler"))
)
# ElementClickInterceptedException 오류 방지 위해
# JavaScript로 팝업 클릭
driver.execute_script("arguments[0].click();", accept_button)
print("'모두 수락' 버튼 클릭됨")
except:
print("{seconds}초 내에 '모두 수락' 버튼을 찾지 못함")
# Chrome 인스턴스를 헤더 모드로 제어하기 위해 드라이버 초기화
driver = webdriver.Chrome()
# 원하는 Crunchbase 페이지로 이동
url = "https://www.crunchbase.com/organization/brightdata"
driver.get(url)
# 쿠키 팝업이 있을 경우 처리
handle_cookie_popup(driver)
# 스크래핑 로직
about_node = driver.find_element(By.CSS_SELECTOR, "profile-section description-card")
about = about_node.text
industries_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Industries")
industries_nodes = industries_parent_node.find_elements(By.CSS_SELECTOR, "chips-container a")
industries = []
for industry_node in industries_nodes:
industries.append(industry_node.text)
founded_date_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "설립일")
founded_date_node = founded_date_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
founded_date = founded_date_node.text
company_type_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "회사 유형")
company_type_node = company_type_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
company_type = company_type_node.text
operating_status_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "운영 상태")
operating_status_node = operating_status_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
operating_status = operating_status_node.text
headquarters_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "본사 지역")
headquarters_node = headquarters_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
headquarters = headquarters_node.text
창립자_상위_노드 = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "창립자")
창립자_노드 = 창립자_상위_노드.find_elements(By.CSS_SELECTOR, "identifier-multi-formatter a")
창립자 = []
for founders_node in founders_nodes:
founders.append(founders_node.text)
legal_name_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Legal Name")
legal_name_node = legal_name_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
legal_name = legal_name_node.text
contact_email_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Contact Email")
contact_email_node = contact_email_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
contact_email = contact_email_node.text
phone_number_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Phone Number")
phone_number_node = phone_number_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
phone_number = phone_number_node.text
description_node = driver.find_element(By.CSS_SELECTOR, "section-card description-card")
description = description_node.text
products_parent_node = find_parent_node_based_on_child_node_text("profile-section", ".section-title", "제품 및 서비스")
products_table_rows = products_parent_node.find_elements(By.CSS_SELECTOR, "table tbody tr")
# 제품 테이블 스크래핑
products = []
for row in products_table_rows:
# 각 행의 열에서 이름과 설명 추출
name = row.find_element(By.CSS_SELECTOR, "td:nth-child(1)").text
description = row.find_element(By.CSS_SELECTOR, "td:nth-child(2)").text
product = {
"name": name,
"description": description
}
products.append(product)
# 스크랩한 데이터로 사전 채우기
company = {
"about": about,
"industries": industries,
"founded_date": founded_date,
"company_type": company_type,
"operating_status": operating_status,
"headquarters": headquarters,
"founders": founders,
"email": contact_email,
"phone": phone_number,
"description": description,
"products": products
}
# 스크랩한 데이터를 JSON 파일로 내보내기
with open("company.json", "w") as json_file:
json.dump(company, json_file, indent=4)
# 드라이버 종료 및 브라우저 리소스 해제
driver.quit()100줄이 조금 넘는 코드로 Python으로 Crunchbase 스크래퍼를 만들었습니다!
다음 명령어로 스크립트를 실행하세요:
python3 script.pyWindows에서는:
python script.py프로젝트 폴더에 company.json 파일이 생성됩니다. 열면 다음과 같은 내용을 확인할 수 있습니다:
{
"about": "세계 최고의 웹 데이터 플랫폼",
"industries": [
"비즈니스 인텔리전스",
"클라우드 데이터 서비스",
"컴퓨터",
"데이터 수집 및 라벨링",
"정보 기술",
"IT 인프라",
"네트워크 보안",
"SaaS",
"소프트웨어"
],
"founded_date": "2014",
"회사_유형": "영리",
"운영_상태": "운영 중",
"본사": "뉴욕 광역권, 동부 해안, 미국 북동부",
"설립자": [
"데리 슈리브먼",
"오퍼 빌렌스키"
],
"email": "[email protected]",
"phone": "(888) 538-9204",
"description": "사용자의 위치와 IP 주소를 숨겨 감지나 차단 없이 익명으로 공개 웹 콘텐츠에 접근할 수 있게 해주는 프록시 서비스입니다.",
"products": [
{
"name": "주거용 프록시",
"description": "400M+ monthly개의 실제 주거용 IP로 구성된 네트워크로, 195개국에서 운영되며 IP 차단 및 CAPTCHA를 회피하면서 모든 웹사이트 콘텐츠에 접근할 수 있습니다."
},
{
"name": "데이터센터 프록시",
"description": "770,000개 이상의 데이터센터 IP 네트워크로 전 세계 커버리지를 제공하며, 특정 국가 및 도시를 대상으로 안정적인 데이터 수집이 가능합니다."
},
{
"name": "모바일 프록시",
"description": "전 세계 7백만 개 이상의 실제 3G/4G 모바일 IP 네트워크로, 사용자가 실제 모바일 사용자로 웹을 탐색하고 IP 위치 차단 및 CAPTCHA를 우회할 수 있게 합니다."
},
{
"name": "ISP 프록시",
"description": "ISP에서 할당된 70만 개 이상의 고정형 주거용 IP로, 장시간 세션 유지 및 필요 기간 동안 독점 사용이 가능합니다."
},
{
"name": "회전 프록시",
"description": "탐지 및 차단을 피하기 위해 지속적으로 IP 주소를 교체하는 프록시로, 99.99% 가동률과 프록시 매니저를 통한 간편한 관리를 제공합니다."
},
{
"name": "익명 프록시",
"description": "위치와 IP 주소를 숨겨 감지나 차단 없이 공개 웹 콘텐츠에 익명으로 접근할 수 있게 해주는 프록시입니다."
}
]
}이것이 Bright Data의 Crunchbase 회사 페이지에 있는 데이터입니다.
자, 이제 Python을 사용해 Crunchbase에서 웹 스크래핑을 수행하는 방법을 배웠습니다.
크런치베이스 데이터 손쉽게 활용하기
Crunchbase는 풍부한 가치 있는 데이터를 제공하지만, 스크래퍼와 자동화된 봇으로부터 이를 보호하기 위해 광범위한 조치를 취하고 있습니다. 헤드리스 브라우저를 사용해 사이트와 상호작용하거나 특정 작업을 수행할 때 403 Forbidden 페이지나 CAPTCHA를 마주칠 수 있습니다.
첫 단계로, Python에서 CAPTCHA를 우회하는 방법에 대한 가이드를 참고할 수 있습니다. 그러나 Crunchbase는 추가적인 고급 스크래핑 방지 솔루션을 사용하므로 여전히 차단될 수 있습니다.
적절한 도구 없이는 Crunchbase 스크래핑이 느리고 좌절스러운 경험으로 변할 수 있습니다. 최적의 해결책은 Bright Data의 전용 Crunchbase 스크래퍼 API입니다. 차단당하지 않고 Crunchbase 데이터를 추출하세요!
결론
이 단계별 튜토리얼에서 Crunchbase 스크레이퍼의 정의와 수집 가능한 데이터 유형을 학습했습니다. 또한 약 150줄의 코드만으로 Crunchbase의 기업 개요 데이터를 스크레이핑하는 Python 스크립트 구축 방법을 확인했습니다.
문제는 Crunchbase가 봇과 자동화 스크립트에 대해 엄격한 방어 조치를 취한다는 점입니다. CAPTCHA, 브라우저 지문 인식, IP 차단 등은 스크래핑을 방지하기 위해 사용되는 방어 수단의 일부에 불과합니다. 저희 Crunchbase 스크래퍼 API를 사용하면 이러한 모든 어려움을 잊으셔도 됩니다.
웹 스크래핑은 원하지 않지만 Crunchbase 데이터에 관심이 있으시다면, 저희 Crunchbase 데이터셋을 살펴보세요!
Bright Data의 솔루션 중 귀사의 요구사항에 가장 적합한 것이 무엇인지 알아보려면 전문가와 상담하세요.




