
이 튜토리얼에서는 다음을 다룹니다:
- Bright Data의 SERP API를 사용한 네이버 검색 결과 스크래핑 방법
- Bright Data 프록시를 활용한 맞춤형 네이버 스크래퍼 구축
- 노코드 워크플로우로 Bright Data Scraper Studio(AI 스크레이퍼)를 활용한 네이버 스크래핑
시작해 보겠습니다!
네이버를 스크래핑해야 하는 이유
네이버는 한국을 대표하는 플랫폼으로, 검색, 뉴스, 쇼핑, 사용자 생성 콘텐츠의 주요 소스입니다. 글로벌 검색 엔진과 달리, 네이버는 자체 서비스를 검색 결과에 직접 노출하기 때문에 한국 시장을 타겟팅하는 기업들에게 중요한 데이터 소스입니다.
네이버 스크래핑을 통해 공개 API로는 접근할 수 없고 대규모 수동 수집이 어려운 구조화 및 비구조화 데이터에 접근할 수 있습니다.
수집 가능한 데이터는 무엇인가요?
- 검색 결과(SERP): 순위, 제목, 스니펫, URL
- 뉴스: 발행처, 헤드라인, 타임스탬프
- 쇼핑: 상품 목록, 가격, 판매자, 리뷰
- 블로그 및 카페: 사용자 생성 콘텐츠 및 트렌드
주요 사용 사례
- 한국 시장을 위한 SEO 및 키워드 추적
- 뉴스 및 사용자 콘텐츠 전반에 걸친 브랜드 및 평판 모니터링
- 네이버 쇼핑을 활용한 전자상거래 및 가격 분석
- 블로그 및 포럼을 통한 시장 및 트렌드 조사
이러한 맥락을 바탕으로, 첫 번째 접근법을 살펴보고 Bright Data의 SERP API를 사용하여 네이버 검색 결과를 스크래핑하는 방법을 알아보겠습니다.
Bright Data의 SERP API를 사용한 네이버 스크래핑
이 접근 방식은 프록시, CAPTCHA 또는 브라우저 설정을 관리하지 않고 네이버 SERP 데이터를 원할 때 이상적입니다.
필수 조건
이 튜토리얼을 따라하려면 다음이 필요합니다:
- Bright Data 계정
- Bright Data 대시보드에서 SERP API, 프록시 또는 Scraper Studio 에 대한 접근 권한
- Python 3.9 이상 설치
- Python 및 웹 스크래핑 개념에 대한 기본적인 이해
사용자 정의 스크레이퍼 예제를 위해 다음도 필요합니다:
- 로컬에 설치 및 설정된Playwright
- Playwright를 통해 설치된 크로미움
Bright Data에서 SERP API 영역 생성
Bright Data에서 SERP API는 전용 존이 필요합니다. 설정 방법은 다음과 같습니다:
- Bright Data에 로그인합니다.
- 대시보드에서 SERP API로 이동하여 새 SERP API 영역을 생성합니다.
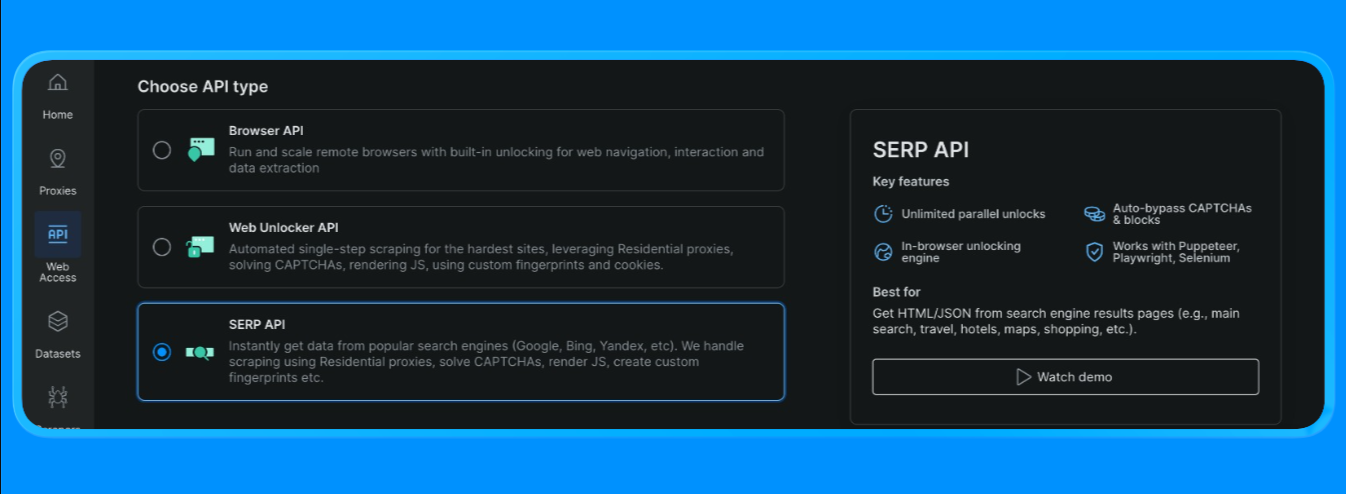
- API 키를 복사합니다.
네이버 검색 URL 생성
네이버 SERP는 표준 검색 URL 형식으로 요청할 수 있습니다:
- 기본 엔드포인트:
https://search.naver.com/search.naver - 쿼리 매개변수:
query=<키워드>
쿼리는 quote_plus()를 사용하여 URL 인코딩되므로 여러 단어로 구성된 키워드(예: “machine learning tutorials”)가 올바르게 형식화됩니다.
SERP API 요청 전송 (Bright Data 요청 엔드포인트)
Bright Data의 빠른 시작 절차는 단일 엔드포인트 (https://api.brightdata.com/request) 를 사용하며, 다음을 전달합니다:
zone:SERP API 영역 이름url:Bright Data가 가져올 네이버 SERP URLformat:HTML을 반환하려면 raw로 설정
Bright Data는 파싱된 출력 모드(예: brd_json=1을 통한 JSON 구조 또는 data_format 옵션을 통한 더 빠른 “상위 결과”)도 지원하지만, 이 튜토리얼 섹션에서는 HTML 파싱 흐름을 사용할 것입니다
이제 Python 파일을 생성하고 다음 코드를 포함하세요.
import asyncio
import re
from urllib.parse import quote_plus, urlparse
from bs4 import BeautifulSoup
from playwright.async_api import async_playwright, TimeoutError as PwTimeout
BRIGHTDATA_USERNAME = "your_brightdata_username"
BRIGHTDATA_PASSWORD = "your_brightdata password"
PROXY_SERVER = "your_proxy_host"
def clean_text(text: str) -> str:
return re.sub(r"s+", " ", (text or "")).strip()
def blocked_link(href: str) -> bool:
"""광고/유틸리티 링크 차단; 블로그 결과를 원하므로 blog.naver.com 허용"""
if not href or not href.startswith(("http://", "https://")):
return True
netloc = urlparse(href).netloc.lower()
# 광고 리다이렉트 + 명백한 비콘텐츠 유틸리티 차단
blocked_domains = [
"ader.naver.com",
"adcr.naver.com",
"help.naver.com",
"keep.naver.com",
"nid.naver.com",
"pay.naver.com",
"m.pay.naver.com",
]
if any(netloc == d or netloc.endswith("." + d) for d in blocked_domains):
return True
# 블로그 모드에서는 다음 중 하나를 선택할 수 있습니다:
# (A) 네이버 블로그/게시물 도메인만 허용 (더 "네이버스러운" 방식)
allowed = ["blog.naver.com", "m.blog.naver.com", "post.naver.com"]
return not any(netloc == d or netloc.endswith("." + d) for d in allowed)
def pick_snippet(container) -> str:
"""
휴리스틱: 제목 근처의 문장 형태 텍스트 블록 선택
"""
best = ""
for tag in container.find_all(["div", "span", "p"], limit=60):
txt = clean_text(tag.get_text(" ", strip=True))
if 40 <= len(txt) <= 280:
# 브레드크럼 형태의 줄은 제외
if "›" in txt:
continue
best = txt
break
return best
def extract_blog_results(html: str, limit: int = 10):
soup = BeautifulSoup(html, "html.parser")
results = []
seen = set()
# 블로그 SERP 레이아웃 변경; 여러 대체 방법 사용
selectors = [
"a.api_txt_lines", # 공통 제목 링크 래퍼
"a.link_tit",
"a.total_tit",
"a[href][target='_blank']",
]
for sel in selectors:
for a in soup.select(sel):
if a.name != "a":
continue
href = a.get("href", "")
title = clean_text(a.get_text(" ", strip=True))
if len(title) < 5:
continue
if blocked_link(href):
continue
if href in seen:
continue
seen.add(href)
container = a.find_parent(["li", "article", "div", "section"]) or a.parent
snippet = pick_snippet(container) if container else ""
results.append({"title": title, "link": href, "snippet": snippet})
if len(results) >= limit:
return results
return results
async def scrape_naver_blog(query: str) -> tuple[str, str]:
# 네이버 블로그 검색
url = f"https://search.naver.com/search.naver?where=blog&query={quote_plus(query)}"
async with async_playwright() as p:
browser = await p.chromium.launch(
headless=True,
proxy={
"server": PROXY_SERVER,
"username": BRIGHTDATA_USERNAME,
"password": BRIGHTDATA_PASSWORD,
},
)
page = await browser.new_page()
# 프록시 호환 타임아웃 설정
page.set_default_navigation_timeout(90_000)
page.set_default_timeout(60_000)
# 속도 향상 및 중단 감소 위해 무거운 리소스 차단
async def block_resources(route):
if route.request.resource_type in ("image", "media", "font"):
return await route.abort()
await route.continue_()
await page.route("**/*", block_resources)
# 한 번 재시도 (네이버는 가끔 불안정할 수 있음)
for attempt in (1, 2):
try:
await page.goto(url, wait_until="domcontentloaded", timeout=90_000)
await page.wait_for_selector("body", timeout=30_000)
html = await page.content()
await browser.close()
return url, html
except PwTimeout:
if attempt == 2:
await browser.close()
raise
await page.wait_for_timeout(1500)
if __name__ == "__main__":
query = "machine learning tutorial"
scraped_url, html = asyncio.run(scrape_naver_blog(query))
print("Scraped from:", scraped_url)
print("HTML length:", len(html))
print(html[:200])
results = extract_blog_results(html, limit=10)
print("n추출된 네이버 블로그 결과:")
for i, r in enumerate(results, 1):
print(f"n{i}. {r['title']}n {r['link']}n {r['snippet']}")fetch_naver_html() 함수를 사용하여 네이버 검색 URL을 Bright Data의 요청 엔드포인트로 전송하고 완전히 렌더링된 SERP 페이지를 가져왔습니다. Bright Data는 IP 로테이션과 접근을 자동으로 처리하여 차단이나 속도 제한에 걸리지 않고 요청이 성공하도록 했습니다.
그런 다음 BeautifulSoup을 사용하여 HTML을 파싱하고, 광고와 네이버 내부 모듈을 제거하기 위한 맞춤형 필터링 로직을 적용했습니다. extract_web_results() 함수는 페이지에서 유효한 결과 제목, 링크 및 인접 텍스트 블록을 스캔하고 중복을 제거한 후 깨끗한 검색 결과 목록을 반환했습니다.
스크립트를 실행하면 다음과 같은 출력을 얻을 수 있습니다: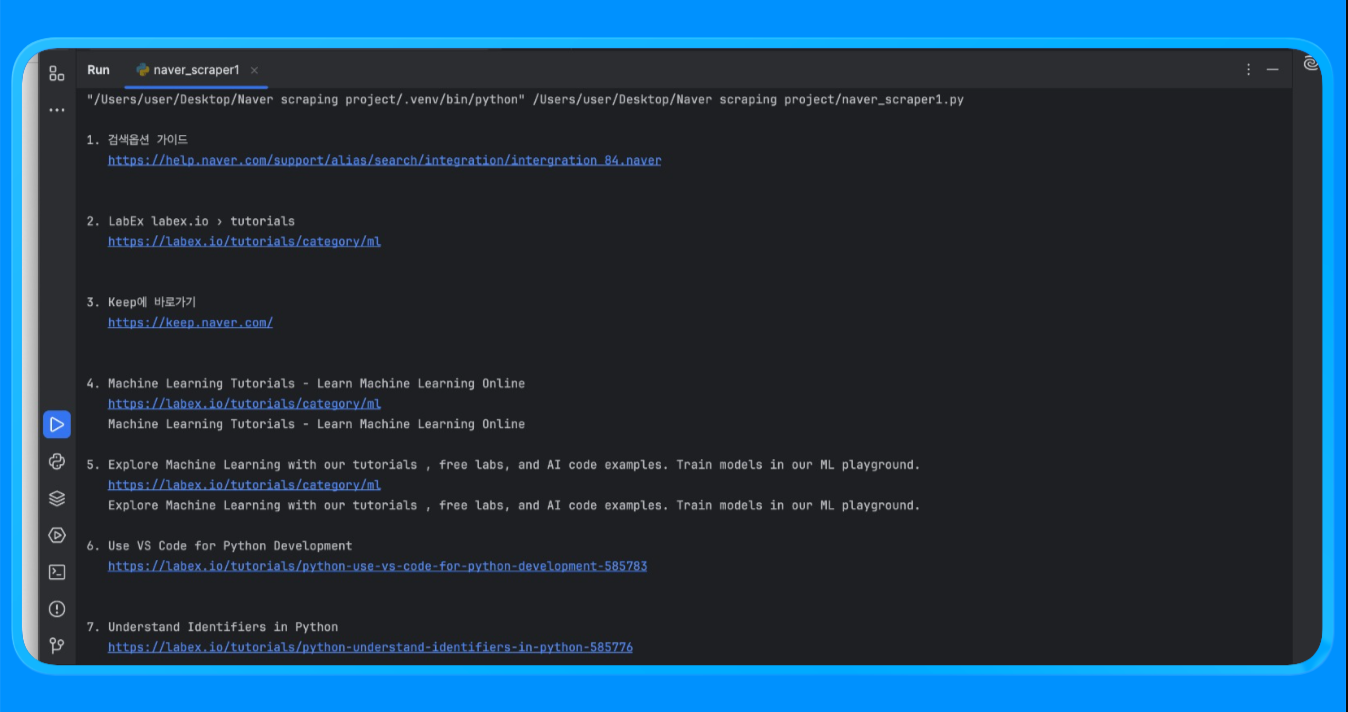
이 방법은 맞춤형 스크레이퍼를 구축하거나 유지 관리하지 않고도 구조화된 네이버 검색 결과를 수집하는 데 사용됩니다.
주요 활용 사례
- 네이버 키워드 순위 및 노출 추적
- 한국 시장 대상 SEO 성과 모니터링
- 뉴스, 쇼핑, 블로그 배치 등 SERP 기능 분석
이 접근 방식은 최소한의 설정으로 일관된 출력 스키마와 높은 요청량을 필요로 할 때 가장 효과적입니다.
SERP 수준의 스크래핑을 다루었으니, 이제 Bright Data 프록시를 사용하여 더 깊이 있는 크롤링과 더 큰 유연성을 갖춘 맞춤형 네이버 스크래퍼를 구축해 보겠습니다.
Bright Data 프록시를 사용한 맞춤형 네이버 스크레이퍼 구축
이 접근 방식은 Bright Data 프록시를 통해 트래픽을 라우팅하면서 실제 브라우저를 사용하여 네이버 페이지를 렌더링합니다. SERP를 넘어 요청, 자바스크립트 렌더링 및 페이지 수준 데이터 추출을 완벽하게 제어해야 할 때 유용합니다.
코드를 작성하기 전에 먼저 Bright Data 대시보드에서 프록시 영역을 생성하고 프록시 자격 증명을 획득해야 합니다.
이 스크립트에 사용되는 프록시 자격 증명을 얻으려면:
- Bright Data 계정에 로그인하세요
- 대시보드에서 프록시(Proxies)로 이동하여 “프록시 생성(Create Proxy)”을 클릭하세요
- 데이터센터 프록시 선택 (본 프로젝트에서는 이 옵션을 선택합니다. 프로젝트 범위 및 사용 사례에 따라 옵션이 달라질 수 있음)
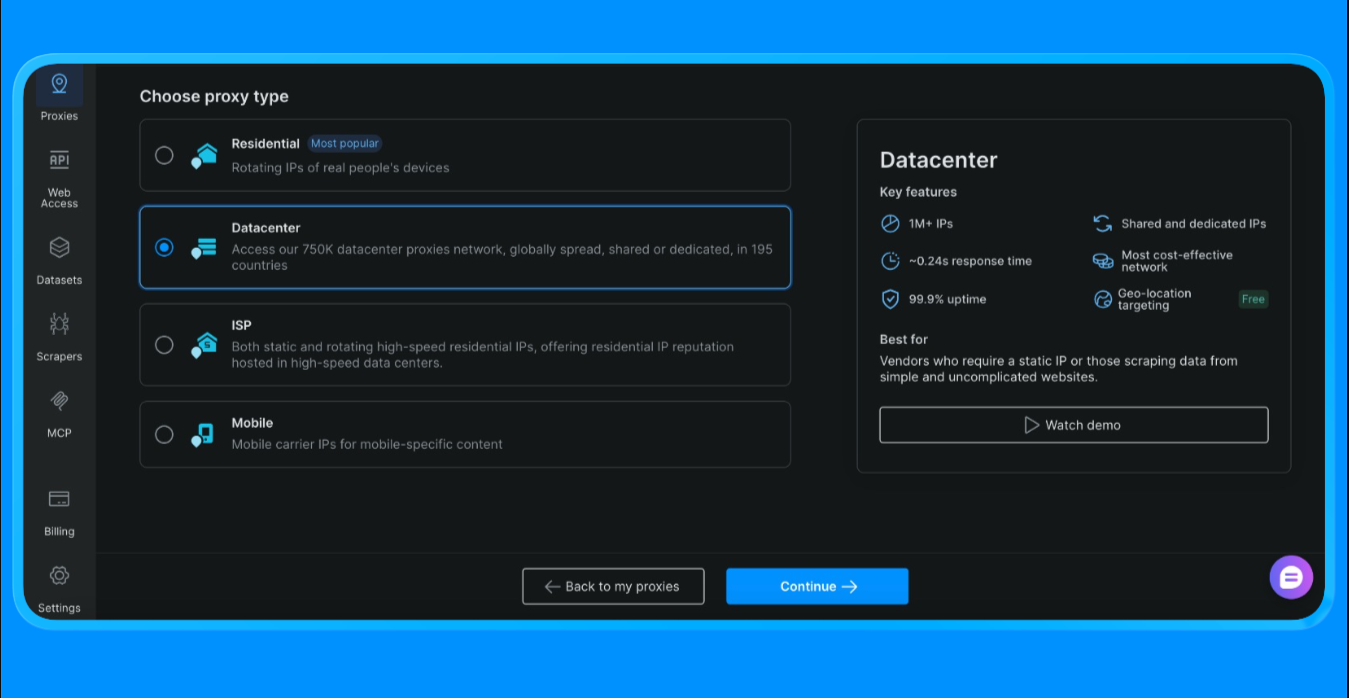
- 새 프록시 영역 생성
- 존 설정을 열고 다음 값을 복사하세요:
- 프록시 사용자 이름
- 프록시 비밀번호
- 프록시 엔드포인트 및 포트
이 값들은 Bright Data 프록시 네트워크를 통해 라우팅되는 요청을 인증하는 데 필요합니다.
스크립트에 Bright Data 프록시 자격 증명 추가
프록시 영역을 생성한 후, 대시보드에서 복사한 자격 증명으로 스크립트를 업데이트하세요.
BRIGHTDATA_USERNAME에는고객 ID와 프록시 영역 이름이 포함됩니다.BRIGHTDATA_PASSWORD에는프록시 영역의 비밀번호가 포함됩니다PROXY_SERVER는Bright Data의 슈퍼 프록시 엔드포인트를 가리킵니다.
이 값들이 설정되면 Playwright에서 시작하는 모든 브라우저 트래픽이 자동으로 Bright Data를 통해 라우팅됩니다.
이제 다음 코드로 스크래핑을 진행할 수 있습니다:
import asyncio
import re
from bs4 import BeautifulSoup
from urllib.parse import quote_plus
from playwright.async_api import async_playwright
BRIGHTDATA_USERNAME = "your_username"
BRIGHTDATA_PASSWORD = "your_password"
PROXY_SERVER = "your_proxy_host"
def clean_text(s: str) -> str:
return re.sub(r"s+", " ", (s or "")).strip()
async def run(query: str):
url = f"https://search.naver.com/search.naver?query={quote_plus(query)}"
async with async_playwright() as p:
browser = await p.chromium.launch(
headless=True,
proxy={
"server": PROXY_SERVER,
"username": BRIGHTDATA_USERNAME,
"password": BRIGHTDATA_PASSWORD,
},
)
page = await browser.new_page()
await page.goto(url, wait_until="networkidle")
html = await page.content()
await browser.close()
soup = BeautifulSoup(html, "html.parser")
results = []
seen = set()
for a in soup.select("a[href]"):
href = a.get("href", "")
title = clean_text(a.get_text(" ", strip=True))
if len(title) < 8:
continue
if not href.startswith(("http://", "https://")):
continue
if any(x in href for x in ["ader.naver.com", "adcr.naver.com", "help.naver.com", "keep.naver.com"]):
continue
if href in seen:
continue
seen.add(href)
results.append({"title": title, "link": href})
if len(results) >= 10:
break
for i, r in enumerate(results, 1):
print(f"{i}. {r['title']}n {r['link']}n")
if __name__ == "__main__":
asyncio.run(run("machine learning tutorial"))scrape_naver_blog() 함수는 네이버 블로그 채널을 열고, 이미지, 미디어, 폰트 등 무거운 자산을 차단하여 로드 시간을 줄이며, 타임아웃 발생 시 네비게이션을 재시도합니다. 페이지가 완전히 로드되면 렌더링된 HTML을 가져옵니다.
extract_blog_results() 함수는 BeautifulSoup으로 HTML을 파싱하고, 네이버 블로그 도메인을 허용하면서 광고 및 유틸리티 페이지를 제외하는 블로그 전용 필터링 규칙을 적용하여 블로그 제목, 링크 및 인접 텍스트 스니펫의 깨끗한 목록을 추출합니다.
이 스크립트를 실행하면 다음과 같은 결과가 출력됩니다:
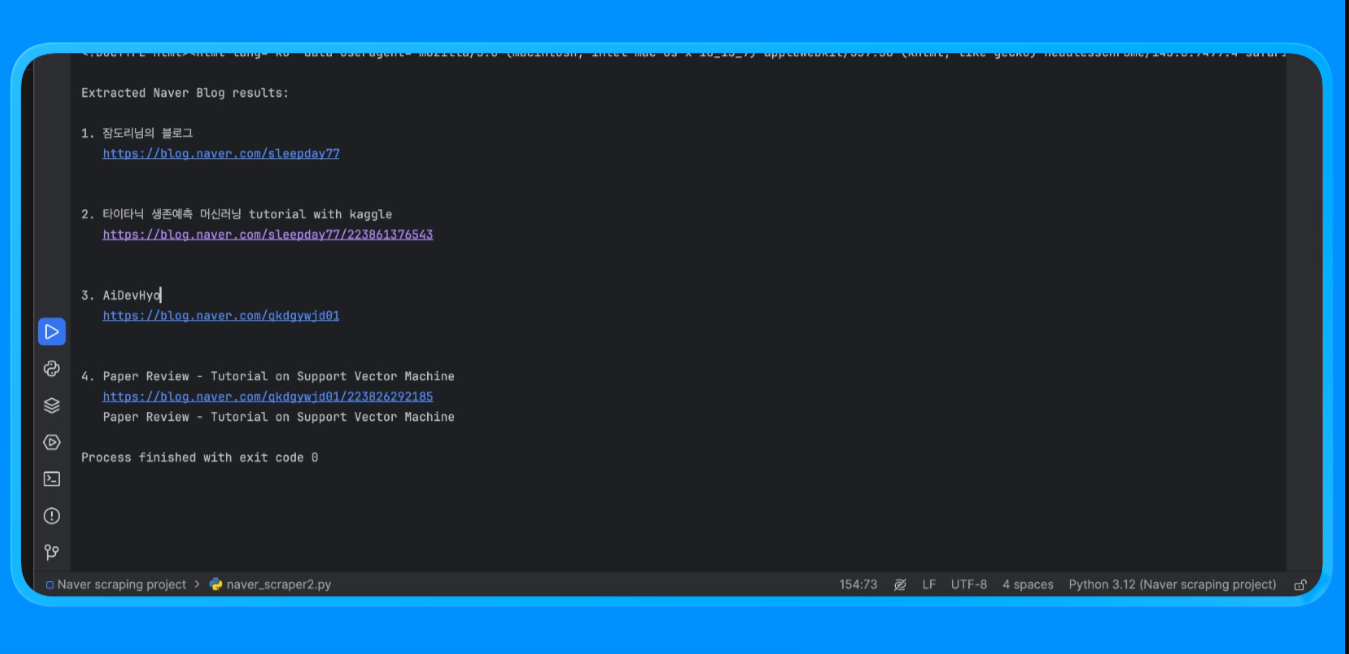
이 방법은 브라우저 렌더링과 맞춤형 파싱 로직이 필요한 네이버 페이지에서 콘텐츠를 추출하는 데 사용됩니다.
일반적인 사용 사례
- 네이버 블로그 및 카페 콘텐츠 스크래핑
- 장문 기사, 댓글 및 사용자 콘텐츠 수집
- 자바스크립트 비중이 높은 페이지에서 데이터 추출
이 방법은 페이지 렌더링, 재시도 및 세밀한 필터링이 필요한 경우에 이상적입니다.
이제 Bright Data 프록시를 통해 실행되는 맞춤형 스크레이퍼를 확보했으니, 코드 작성 없이 데이터를 추출하는 가장 빠른 옵션으로 넘어가 보겠습니다. 다음 섹션에서는 동일한 인프라를 기반으로 구축된 노코드 AI 기반 워크플로인 Bright Data Scraper Studio를 사용하여 네이버를 스크레이핑할 것입니다.
Bright Data Scraper Studio(노코드 AI 스크레이퍼)로 네이버 스크레이핑하기
스크래핑 코드를 작성하거나 유지 관리하고 싶지 않다면, Bright Data Scraper Studio를 통해 SERP API 및 프록시 네트워크와 동일한 기반 인프라를 활용하여 네이버 데이터를 추출하는 코드 없는 방법을 제공합니다.
시작하려면:
- Bright Data 계정에 로그인하세요
- 대시보드에서 왼쪽 메뉴의 “스크레이퍼” 옵션을 열고 “스크레이퍼 스튜디오”를 클릭하세요. 다음과 같은 대시보드가 표시됩니다:
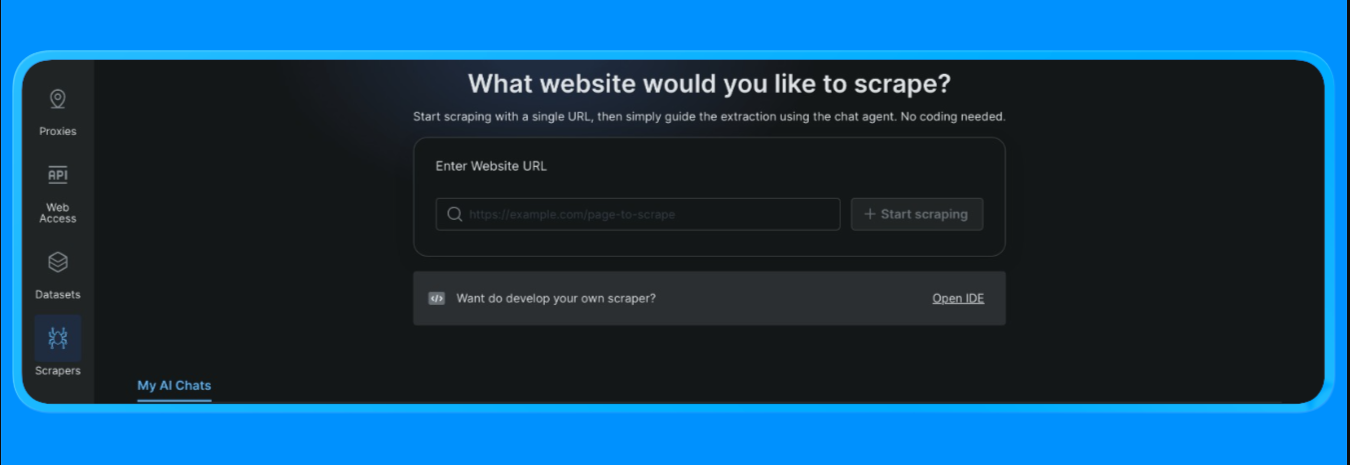
스크래핑할 대상 URL을 입력한 후 “스크래핑 시작” 버튼을 클릭하세요
스크레이퍼 스튜디오는 사이트를 스크래핑하여 필요한 정보를 제공합니다.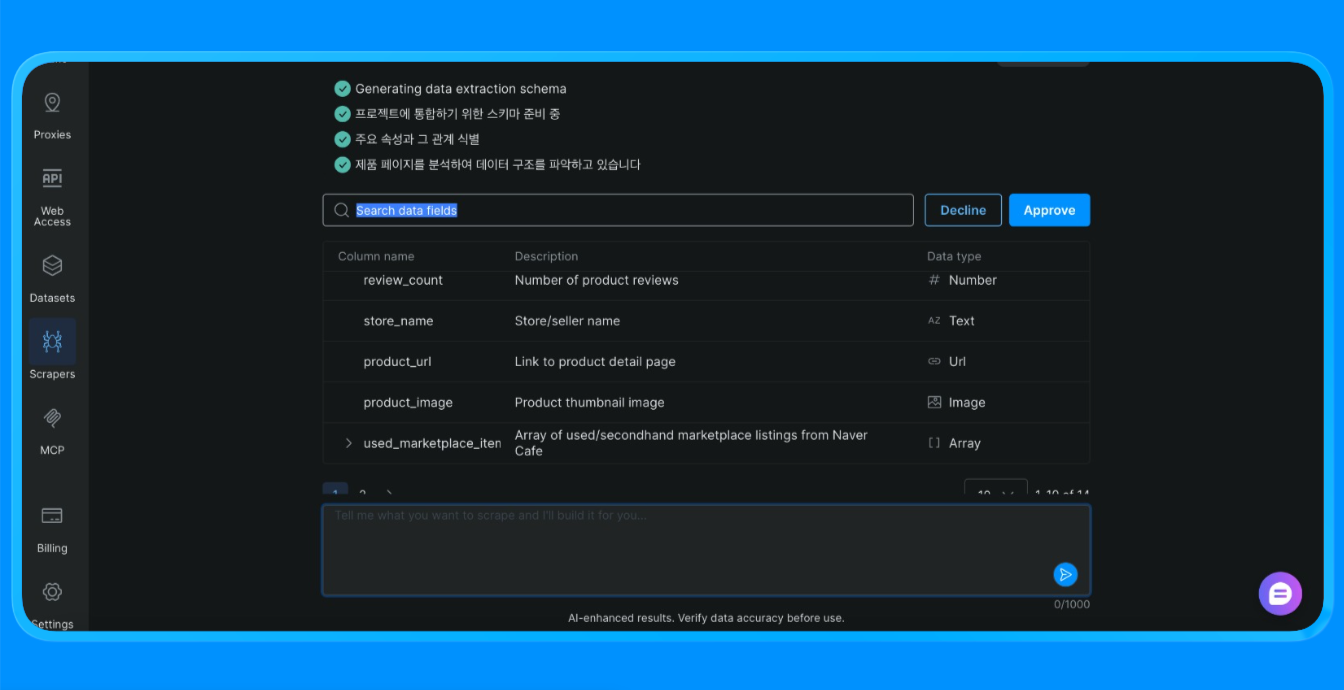
스크레이퍼 스튜디오는 Bright Data 인프라를 통해 네이버 페이지를 로드하고, 시각적 추출 규칙을 적용하여 구조화된 데이터를 반환합니다. 이는 맞춤형 스크레이퍼나 브라우저 자동화가 필요했던 작업을 대체합니다.
일반적인 사용 사례
- 일회성 데이터 수집
- 개념 증명 프로젝트
- 웹 데이터를 수집하는 비기술 팀
Scraper Studio는 속도와 단순성이 맞춤 설정보다 더 중요한 경우에 적합한 선택입니다.
세 가지 네이버 스크래핑 접근법 비교
| 접근 방식 | 설정 노력 | 제어 수준 | 확장성 | 최적 적용 분야 |
|---|---|---|---|---|
| Bright Data SERP API | 낮음 | 중간 | 높음 | SEO 추적, 키워드 모니터링, 구조화된 SERP 데이터 |
| Bright Data 프록시를 사용한 맞춤형 스크레이퍼 | 높음 | 매우 높음 | 매우 높음 | 블로그 스크래핑, 동적 페이지, 맞춤형 워크플로 |
| Bright Data 스크레이퍼 스튜디오 | 매우 낮음 | 낮음에서 중간 | 중간 | 빠른 추출, 코딩이 필요 없는 팀, 프로토타이핑 |
선택 방법:
- 대규모로 안정적이고 구조화된 검색 결과가 필요할 때는 SERP API를 사용하세요.
- 렌더링, 재시도 및 추출 로직에 대한 완전한 제어가 필요할 때는 프록시와 맞춤형 스크레이퍼를 사용하세요.
- 속도와 간편성이 맞춤 설정보다 중요할 때는 Scraper Studio를 사용하세요.
마무리
이 튜토리얼에서는 Bright Data를 사용해 네이버를 스크래핑하는 세 가지 생산 환경에 적합한 방법을 다루었습니다:
- 구조화된 검색 데이터를 위한 관리형 SERP API
- 완벽한 유연성과 제어를 위한 프록시 기반 맞춤형 스크레이퍼
- 빠른 데이터 추출을 위한 노코드 스크레이퍼 스튜디오 워크플로
각 옵션은 동일한 Bright Data 인프라를 기반으로 구축됩니다. 적합한 선택은 필요한 제어 수준, 스크래핑 빈도, 코드 작성 의향에 따라 달라집니다.
SERP API, 프록시 인프라, 코드 없는 스크레이퍼 스튜디오에 접근하려면 Bright Data를 살펴보고 여러분의 워크플로에 맞는 접근 방식을 선택하세요.
추가 웹 스크래핑 가이드 및 튜토리얼:





