

이 가이드에서는 다음을 배우게 됩니다:
- Gemini가 AI 기반 웹 스크래핑에 탁월한 솔루션인 이유
- 자동화된 튜토리얼을 통해 Python으로 사이트를 스크래핑하는 방법
- 이 방식의 웹 스크래핑 최대 한계점과 극복 방법
자, 시작해 보겠습니다!
웹 스크래핑에 Gemini를 사용해야 하는 이유
Gemini는 Google이 개발한 다중 모달 AI 모델 제품군으로, 텍스트, 이미지, 오디오, 비디오, 코드를 분석하고 해석할 수 있습니다. 웹 스크래핑에 Gemini를 사용하면 비정형 콘텐츠의 해석과 구조화를 자동화하여 데이터 추출을 단순화합니다. 이는 특히 데이터 파싱과 관련하여 수동 작업의 필요성을 제거합니다.
웹 스크래핑에서 Gemini의 가장 일반적인 활용 사례는 다음과 같습니다:
- 구조가 자주 변경되는 페이지: 아마존과 같은 전자상거래 사이트처럼 레이아웃이나 데이터 요소가 자주 바뀌는 동적 페이지를 처리할 수 있습니다.
- 다량의 비정형 데이터가 있는 페이지: 방대한 양의 체계적이지 않은 텍스트에서 유용한 정보를 추출하는 데 탁월합니다.
- 맞춤형 파싱 로직 작성의 어려움이 있는 페이지: 복잡하거나 예측 불가능한 구조를 가진 페이지의 경우, Gemini는 복잡한 파싱 규칙 없이도 프로세스를 자동화할 수 있습니다.
웹 스크래핑에서 Gemini의 일반적인 사용 시나리오는 다음과 같습니다:
- RAG(검색 강화 생성): 실시간 데이터 스크래핑을 결합하여 AI 인사이트를 강화합니다. 유사한 AI 기술을 활용한 완전한 예시는 SERP 데이터를 활용한 RAG 챗봇 생성 튜토리얼을 참조하세요.
- 소셜 미디어 스크래핑: 동적 콘텐츠가 있는 플랫폼에서 구조화된 데이터를 수집합니다.
- 콘텐츠 집계: 요약이나 분석을 위해 여러 출처의 뉴스, 기사 또는 블로그 게시물을 수집합니다.
자세한 내용은 웹 스크래핑에 AI를 활용하는 가이드를 참조하세요.
Python에서 Gemini를 활용한 웹 스크래핑: 단계별 가이드
이 섹션의 대상 사이트로 “웹 스크래핑 학습용 전자상거래 테스트 사이트” 샌드박스의 특정 제품 페이지를 사용하겠습니다:
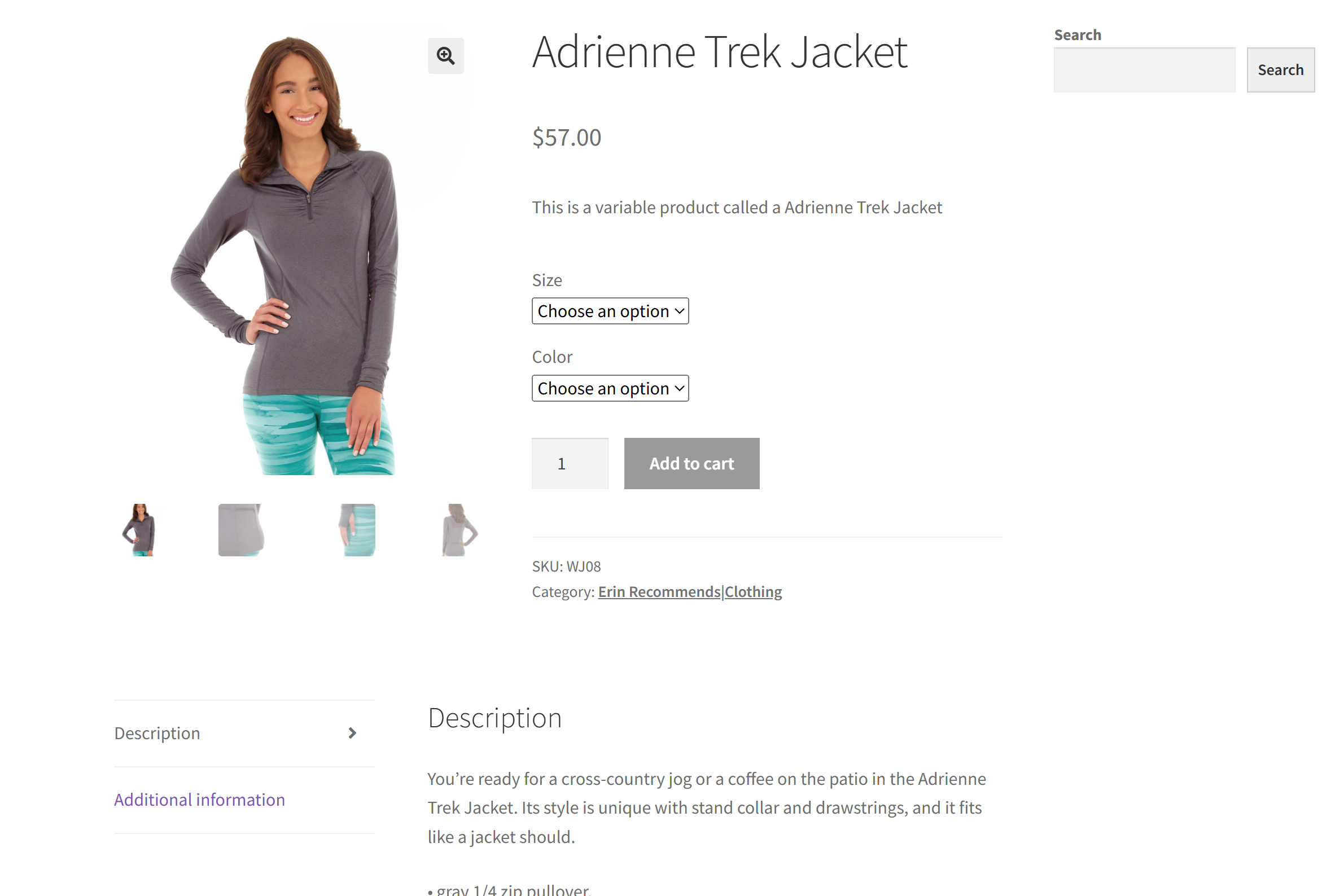
대부분의 전자상거래 제품 페이지가 다양한 유형의 데이터를 표시하거나 구조가 다르기 때문에 이 페이지가 훌륭한 예시입니다. 바로 이 점이 전자상거래 웹 스크래핑을 어렵게 만드는 요소이며, AI가 도움을 줄 수 있는 부분입니다.
Gemini 기반 스크레이퍼의 목표는 수동 파싱 로직 작성 없이 AI를 활용해 페이지에서 제품 세부 정보를 추출하는 것입니다. AI를 통해 검색된 제품 데이터에는 다음이 포함됩니다:
- SKU
- 이름
- 이미지
- 가격
- 설명
- 사이즈
- 색상
- 카테고리
Gemini로 웹 스크래핑을 수행하는 방법을 알아보려면 아래 단계를 따르세요!
1단계: 프로젝트 설정
시작하기 전에 컴퓨터에 Python 3이 설치되어 있는지 확인하세요. 설치되어 있지 않다면 다운로드하여 설치 마법사를 따라 설치하세요.
이제 스크래핑 프로젝트용 폴더를 생성하기 위해 다음 명령어를 실행하세요:
mkdir gemini-scrapergemini-scraper는 Python 기반 Gemini 웹 스크레이퍼의 프로젝트 폴더를 나타냅니다.
터미널에서 해당 폴더로 이동한 후 가상 환경을 초기화하세요:
cd gemini-scraper
python -m venv venv선호하는 Python IDE에서 프로젝트 폴더를 로드하세요. Python 확장 기능이 설치된 Visual Studio Code 또는 PyCharm Community Edition이 두 가지 훌륭한 옵션입니다.
프로젝트 폴더 내에 scraper.py 파일을 생성하세요. 현재 폴더 구조는 다음과 같아야 합니다:

현재 scraper.py는 빈 Python 스크립트이지만 곧 원하는 LLM 스크래핑 로직이 포함될 것입니다.
IDE 터미널에서 가상 환경을 활성화합니다. Linux 또는 macOS에서는 다음 명령어를 실행하세요:
source venv/bin/activateWindows에서는 동일하게 다음을 실행하세요:
venv/Scripts/activate훌륭합니다! 이제 Gemini를 활용한 웹 스크래핑을 위한 Python 환경이 준비되었습니다.
2단계: Gemini 구성
Gemini는 requests를 포함한 모든 HTTP 클라이언트로 호출 가능한 API를 제공합니다. 하지만 Gemini API에는 공식 Google AI Python SDK를 통해 연결하는 것이 가장 좋습니다. 설치하려면 활성화된 가상 환경에서 다음 명령어를 실행하세요:
pip install google-generativeai그런 다음 scraper.py 파일에 이를 임포트하세요:
import google.generativeai as genaiSDK를 사용하려면 Gemini API 키가 필요합니다. 아직 API 키를 발급받지 않았다면
Google 공식 문서를 따라 진행하세요. 구체적으로 Google 계정에 로그인한 후 Google AI Studio에 가입합니다. “API 키 받기” 페이지로 이동하면 다음과 같은 모달이 표시됩니다:
“API 키 받기” 버튼을 클릭하면 다음 섹션이 나타납니다:
이제 “Create API key”를 눌러 Gemini API 키를 생성하세요:
키를 복사하여 안전한 장소에 보관하세요.
참고: 본 예제에는 Gemini 무료 계층으로 충분합니다. 유료 계층은 더 높은 속도 제한이 필요하거나 프롬프트 및 응답이 Google 제품 개선에 사용되지 않도록 보장하려는 경우에만 필요합니다. 자세한 내용은 Gemini 요금 페이지를 참조하세요.
Python에서 Gemini API 키를 사용하려면 환경 변수로 설정할 수 있습니다:
export GEMINI_API_KEY=<YOUR_GEMINI_API_KEY>또는 Python 스크립트에 상수로 직접 저장할 수도 있습니다:
GEMINI_API_KEY="<YOUR_GEMINI_API_KEY>"다음과 같이 genai 에 구성값으로 전달하세요:
genai.configure(api_key=GEMINI_API_KEY)이 경우 두 번째 방법을 따를 것입니다. 다만, 수동으로 전달하지 않을 경우 google-generativeai가 자동으로 GEMINI_API_KEY에서 API 키를 읽어오므로 두 방법 모두 작동한다는 점을 유의하세요.
대단합니다! 이제 Python에서 Gemini SDK를 사용해 LLM에 API 요청을 보낼 수 있습니다.
3단계: 대상 페이지의 HTML 가져오기
대상 서버에 연결하여 웹 페이지의 HTML을 가져오기 위해 Python에서 가장 널리 사용되는 HTTP 클라이언트인 Requests를 사용할 것입니다. 활성화된 가상 환경에서 다음 명령어로 설치하세요:
pip install requests그런 다음 scraper.py에서 다음과 같이 임포트합니다:
import requests이 라이브러리를 사용하여 대상 페이지에 GET 요청을 보내 HTML 문서를 가져옵니다:
url = "https://www.scrapingcourse.com/ecommerce/product/adrienne-trek-jacket/"
response = requests.get(url)이제response.content에는 페이지의 원시 HTML이 저장됩니다. 이제 이를 파싱하고 데이터를 추출할 준비를 하세요!
4단계: HTML을 마크다운으로 변환하기
Crawl4AI 같은 다른 AI 스크래핑 기술을 비교해 보면, CSS 선택자를 사용해 HTML 요소를 지정할 수 있다는 점을 알 수 있습니다. 그런 다음 이 라이브러리들은 선택된 요소의 HTML을 마크다운 텍스트로 변환합니다. 마지막으로 그 텍스트를 LLM으로 처리합니다.
왜 그럴까요? 두 가지 핵심 이유가 있습니다:
- AI로 전송되는 토큰 수를 줄여 비용을 절감하기 위함입니다(Gemini처럼 무료인 LLM 제공업체가 모두 있는 것은 아니기 때문입니다).
- AI 처리 속도를 높이기 위함입니다. 입력 데이터가 적을수록 계산 비용이 낮아지고 응답 속도가 빨라지기 때문입니다.
전체적인 진행 과정은 CrawlAI와 DeepSeek를 활용한 웹 스크래핑 가이드를 참고하세요.
이 논리를 재현해보고 실제로 타당한지 확인해봅시다. 먼저 시크릿 창(새 세션 시작)에서 대상 페이지를 열어 검사합니다. 그런 다음 페이지 아무 곳이나 마우스 오른쪽 버튼으로 클릭하고 “검사” 옵션을 선택하세요.
페이지 구조를 살펴보세요. 모든 관련 데이터가 CSS 선택자 #main으로 식별되는 HTML 요소 내에 포함되어 있음을 확인할 수 있습니다:
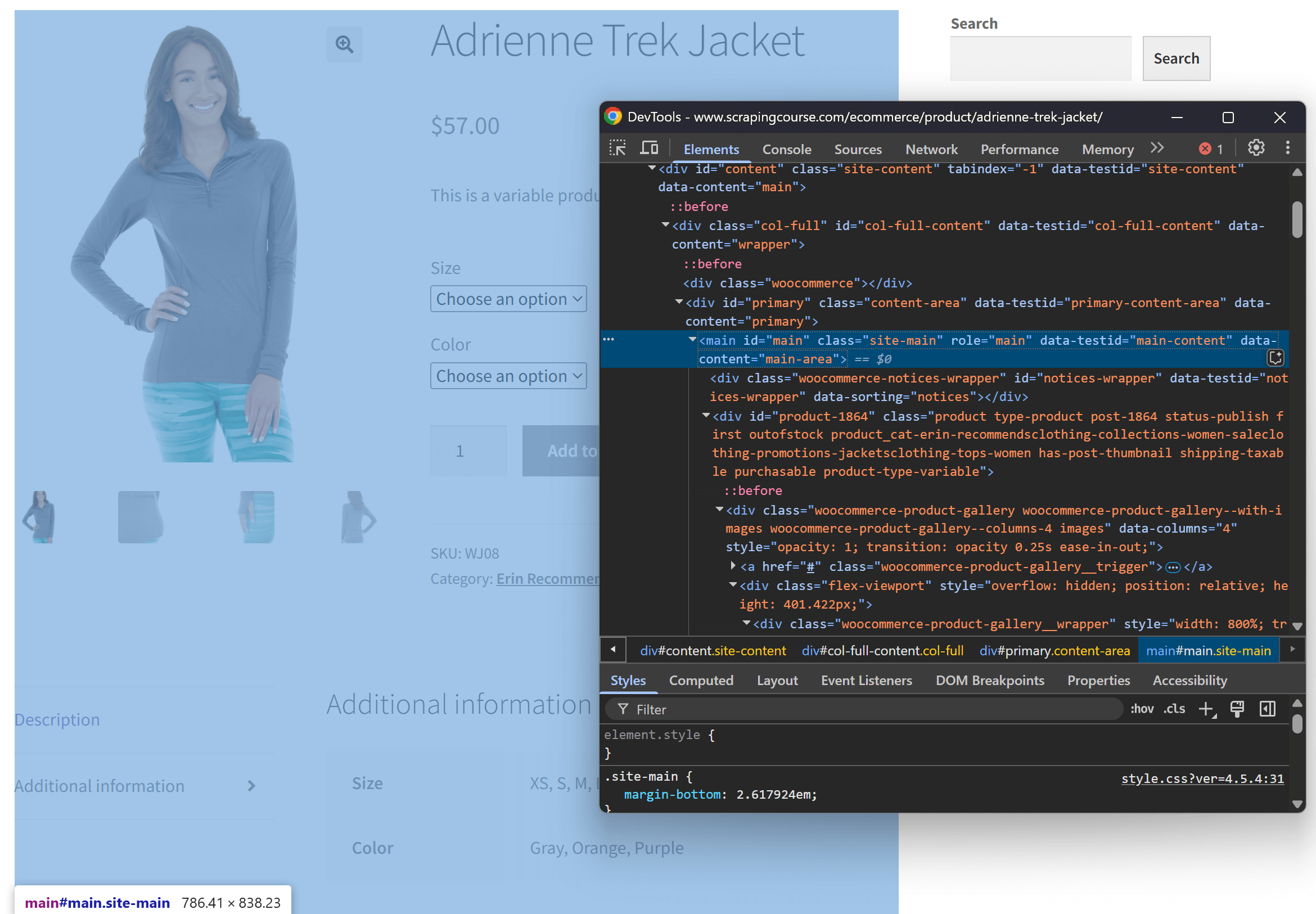
전체 원시 HTML을 Gemini에 전송할 수도 있지만, 이는 헤더나 푸터 같은 불필요한 정보를 대량으로 포함하게 됩니다. 대신 #main 콘텐츠만 전달하면 잡음을 줄이고 AI 환각 현상을 방지할 수 있습니다.
#main만 선택하려면 Beautiful Soup 같은 Python HTML 파싱 도구가 필요합니다. 따라서 다음 명령어로 설치하세요:
pip install beautifulsoup4구문에 익숙하지 않다면 Beautiful Soup 웹 스크래핑 가이드를 참고하세요.
이제 scraper.py에서 임포트하세요:
from bs4 import BeautifulSoupRequests로 가져온 원시 HTML을 Beautiful Soup으로 파싱하고, #main 요소를 선택하여 HTML을 추출합니다:
# BeautifulSoup로 HTML 파싱
soup = BeautifulSoup(response.content, "html.parser")
# #main 요소 추출
main_element = soup.select_one("#main")
# 외부 HTML 가져오기
main_html = str(main_element)main_html을 출력하면 다음과 같은 내용이 표시됩니다:
<main id="main" class="site-main" role="main" data-testid="main-content" data-content="main-area">
<!-- 생략... -->
</main>이제 이 HTML이 생성할 토큰 수를 확인하고 Gemini 유료 요금제를 사용할 경우 비용을 추정해 보세요. 이를 위해 Token Calculator 같은 도구를 사용하세요:
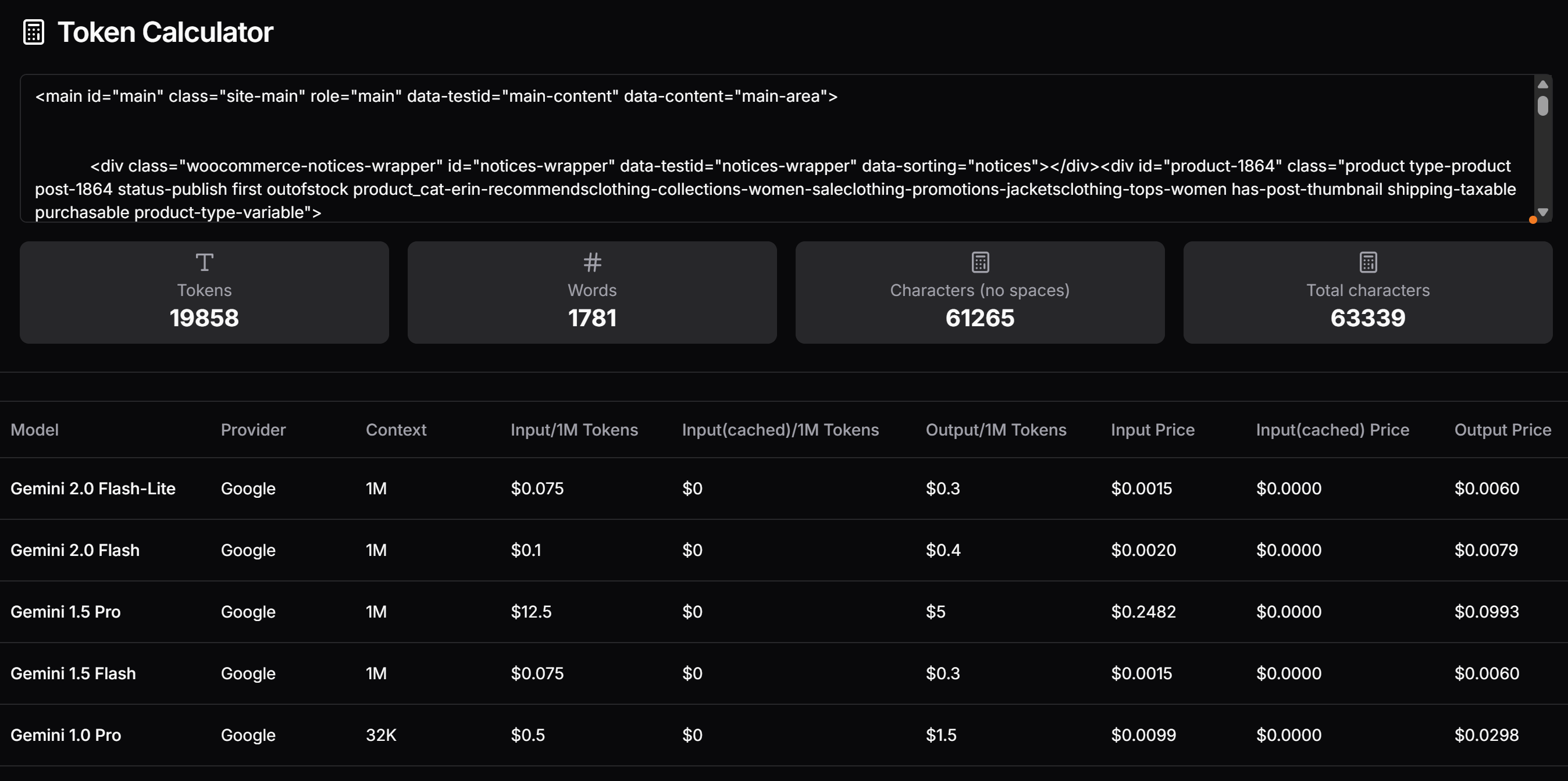
알 수 있듯이, 이 접근 방식은 거의 20,000 토큰에 해당하며 Gemini 1.5 Pro 기준 요청당 약 $0.25의 비용이 듭니다. 대규모 스크래핑 프로젝트에서는 이 비용이 쉽게 문제가 될 수 있습니다!
추출한 HTML을 Markdown으로 변환해 보세요—Crawl4AI가 하는 방식과 유사합니다. 먼저 markdownify 같은 HTML-to-Markdown 라이브러리를 설치하세요:
pip install markdownifyscraper.py에서 markdownify를 임포트하세요:
from markdownify import markdownify다음으로 markdownify를 사용해 추출된 HTML을 마크다운으로 변환하세요:
main_markdown = markdownify(main_html)결과 main_markdown 문자열은 다음과 같은 내용을 포함합니다:
[](https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_main.jpg)
[](https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_alt1.jpg)
[](https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_alternate.jpg)
[](https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_back.jpg)
아드리엔 트렉 재킷
====================
$57.00
이 제품은 아드리엔 트렉 재킷이라는 변형 상품입니다.
| | |
| --- | --- |
| 사이즈 | 선택하세요XSSMLXL |
| 색상 | 선택하세요회색주황색보라색[선택 취소](#) |
아드리엔 트렉 자켓 수량
장바구니 담기
SKU: WJ08
카테고리: [에린 추천|의류](https://www.scrapingcourse.com/ecommerce/product-category/clothing/women/tops-women/jacketsclothing-tops-women/promotions-jacketsclothing-tops-women/women-saleclothing-promotions-jacketsclothing-tops-women/collections-women-saleclothing-promotions-jacketsclothing-tops-women/erin-recommendsclothing-collections-women-saleclothing-promotions-jacketsclothing-tops-women/)
* [상품 설명](#tab-description)
* [추가 정보](#tab-additional_information)
상품 설명
-----------
아드리엔 트렉 재킷을 입고 크로스컨트리 조깅을 하거나 파티오에서 커피를 즐기기에 완벽합니다. 스탠드 칼라와 드로스트링으로 독특한 스타일을 자랑하며, 재킷이 갖춰야 할 핏을 구현했습니다.
* 그레이 컬러 1/4 지퍼 풀오버.
* 편안하고 여유로운 핏.
* 통풍을 위한 전면 지퍼.
* 넉넉한 캥거루 포켓.
* 27인치(약 69cm) 바디 길이.
* 95% 오가닉 코튼 / 5% 스판덱스.
추가 정보
----------------------
| | |
| --- | --- |
| 사이즈 | XS, S, M, L, XL |
| 컬러 | 그레이, 오렌지, 퍼플 |이 마크다운 형식의 입력 데이터는 원본 #main HTML보다 훨씬 작으면서도 스크래핑에 필요한 모든 핵심 데이터를 포함하고 있습니다.
토큰 계산기를 다시 사용해 새 입력값이 소비할 토큰 수를 확인하세요:
와, 19,858 토큰을 765 토큰으로 줄였습니다—95% 감소입니다!
단계 #5: LLM을 사용하여 데이터 추출하기
Gemini로 웹 스크래핑을 수행하려면 다음 단계를 따르세요:
- Markdown 입력에서 원하는 데이터를 추출하기 위해 잘 구조화된 프롬프트를 작성하세요. 결과에 포함될 속성을 반드시 정의해야 합니다.
genai를사용하여 Gemini LLM 모델에 요청을 전송하고, 요청이 JSON 형식의 데이터를 반환하도록 구성하세요.- 반환된 JSON을 파싱합니다.
위의 논리를 다음 코드 줄로 구현하세요:
# Gemini를 사용한 구조화된 데이터 추출
prompt = f"""아래 콘텐츠에서 데이터를 추출하세요. 스크래핑된 데이터를 지정된 속성으로 포함한 JSON 형식의 원시 문자열로 응답하세요:nn
JSON 속성: n
sku, name, images, price, description, sizes, colors, category
콘텐츠:n
{main_markdown}
"""
model = genai.GenerativeModel("gemini-2.0-flash-lite", generation_config={"response_mime_type": "application/json"})
response = model.generate_content(prompt)
# 응답을 가져와 JSON에서 파싱
product_raw_string = response.text
product_data = json.loads(product_raw_string)프롬프트 변수는 Gemini가 main_markdown 콘텐츠에서 구조화된 데이터를 추출하도록 지시합니다. 그런 다음 genai.GenerativeModel() 은 LLM 요청을 수행하기 위해 "gemini-2.0-flash-lite" 모델을 설정합니다. 마지막으로 JSON 형식의 원시 응답 문자열은 json.loads()를 사용하여 사용 가능한 Python 사전으로 변환됩니다.
Gemini가 JSON 데이터를 반환하도록 지시하는 "application/json" 구성을 유의하십시오.
Python 표준 라이브러리에서 json을 반드시 임포트하세요:
import json스크래핑된 데이터를 product_data 사전으로 확보했으므로, 아래 예시처럼 추가 데이터 처리를 위해 해당 필드에 접근할 수 있습니다:
price = product_data["price"]
price_eur = price * USD_EUR
# ...훌륭합니다! 방금 Gemini를 웹 스크래핑에 활용했습니다. 이제 스크랩한 데이터를 내보내기만 하면 됩니다.
6단계: 스크랩한 데이터 내보내기
현재 스크랩된 데이터는 Python 사전(dictionary)에 저장되어 있습니다. 이를 JSON 파일로 내보내려면 다음 코드를 사용하세요:
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product_data, json_file, indent=4)이렇게 하면 스크랩된 데이터가 JSON 형식으로 담긴 product.json 파일이 생성됩니다.
축하합니다! Gemini 기반 웹 스크래퍼가 완성되었습니다.
7단계: 모든 것을 통합하기
다음은 완성된 Gemini 스크래핑 스크립트의 전체 코드입니다:
import google.generativeai as genai
import requests
from bs4 import BeautifulSoup
from markdownify import markdownify
import json
# 귀하의 Gemini API 키
GEMINI_API_KEY = "<YOUR_GEMINI_API_KEY>"
# Google Gemini API 설정
genai.configure(api_key=GEMINI_API_KEY)
# 대상 페이지의 HTML 콘텐츠 가져오기
url = "https://www.scrapingcourse.com/ecommerce/product/adrienne-trek-jacket/"
response = requests.get(url)
# BeautifulSoup으로 대상 페이지 HTML 파싱
soup = BeautifulSoup(response.content, "html.parser")
# #main 요소 선택
main_element = soup.select_one("#main")
# 해당 요소의 외부 HTML을 가져와 마크다운으로 변환
main_html = str(main_element)
main_markdown = markdownify(main_html)
# Gemini를 사용해 구조화된 데이터 추출
prompt = f"""아래 콘텐츠에서 데이터를 추출하세요. 지정된 속성에 스크랩된 데이터를 포함한 JSON 형식의 원시 문자열로 응답하세요:nn
JSON 속성: n
sku, name, images, price, description, sizes, colors, category
콘텐츠:n
{main_markdown}
"""
model = genai.GenerativeModel("gemini-2.0-flash-lite", generation_config={"response_mime_type": "application/json"})
response = model.generate_content(prompt)
# 응답을 가져와 JSON에서 파싱
product_raw_string = response.text
product_data = json.loads(product_raw_string)
# 추가 데이터 처리... (선택 사항)
# 추출한 데이터를 JSON으로 내보내기
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product_data, json_file, indent=4)스크립트 실행:
python scraper.py실행 후 프로젝트 폴더에 product.json 파일이 생성됩니다. 파일을 열면 다음과 같은 구조화된 데이터를 확인할 수 있습니다:
{
"sku": "WJ08",
"name": "Adrienne Trek Jacket",
"images": [
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_main-416x516.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_alt1-416x516.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_alternate-416x516.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_back-416x516.jpg"
],
"price": "$57.00",
"description": "아드리엔 트렉 재킷으로 크로스컨트리 조깅이나 파티오에서의 커피 타임을 준비하세요. 스탠드 칼라와 드로스트링으로 독특한 스타일을 자랑하며, 재킷이 갖춰야 할 핏을 선사합니다. • 그레이 컬러의 1/4 지퍼 풀오버 • 편안하고 여유로운 핏 nu2022 통풍을 위한 전면 지퍼. nu2022 넉넉한 캥거루 포켓. nu2022 27인치(약 69cm) 바디 길이. nu2022 95% 유기농 코튼 / 5% 스판덱스.",
"sizes": [
"XS",
"S",
"M",
"L",
"XL"
],
"colors": [
"Gray",
"Orange",
"Purple"
],
"category": "Erin Recommends|Clothing"
}자, 이제 보세요! HTML 페이지의 비정형 데이터에서 시작하여 Gemini 기반 웹 스크래핑 덕분에 구조화된 JSON 파일로 변환했습니다.
다음 단계
Gemini 기반 스크레이퍼를 한 단계 업그레이드하려면 다음 개선 사항을 고려하세요:
- 재사용 가능하게 만들기: 스크립트를 수정하여 프롬프트와 대상 URL을 명령줄 인수로 받아들이도록 합니다. 이렇게 하면 범용적으로 사용할 수 있고 다양한 사용 시나리오에 적용할 수 있습니다.
- 웹 크롤링 구현: 크롤링 및 페이지네이션 로직을 추가하여 다중 페이지 웹사이트를 처리할 수 있도록 스크레이퍼를 확장하세요.
- API 자격 증명 보안: Gemini API 키를
.env파일에 저장하고python-dotenv를사용하여 로드하세요. 이렇게 하면 코드에 API 키가 노출되는 것을 방지할 수 있습니다.
이 웹 스크래핑 접근법의 주요 한계 극복
이 웹 스크래핑 접근법의 가장 큰 한계는 무엇일까요? 바로 requests 모듈이 생성하는 HTTP 요청입니다!
물론 위 예제에서는 완벽하게 작동했습니다. 하지만 이는 대상 사이트가 단순한 웹 스크래핑 연습장일 뿐이기 때문입니다. 실제로 기업과 웹사이트 소유자는 데이터가 공개적으로 접근 가능하더라도 그 가치를 잘 알고 있습니다. 이를 보호하기 위해 자동화된 HTTP 요청을 쉽게 차단할 수 있는 스크래핑 방지 조치를 구현합니다.
또한 위 접근법은 자바스크립트에 의존하여 데이터를 비동기적으로 렌더링하거나 가져오는 동적 사이트에서는 작동하지 않습니다. 따라서 사이트는 고급 스크래핑 방지 프레임워크 없이도 스크레이퍼를 차단할 수 있습니다. 자바스크립트 기반 콘텐츠 로딩만으로도 충분합니다.
이 모든 문제의 해결책은? 웹 언락킹 API입니다!
웹 언락커 API는 모든 HTTP 클라이언트에서 호출 가능한 HTTP 엔드포인트입니다. 핵심 차이점은? 전달된 URL의 완전히 언락된 HTML을 반환하여 모든 스크래핑 방지 장치를 우회한다는 점입니다. 대상 사이트가 아무리 많은 보호 장치를 갖추고 있더라도, 웹 언락커에 간단한 요청만 하면 해당 페이지의 HTML을 가져올 수 있습니다.
이 도구를 시작하고 API 키를 받으려면 공식 웹 언락커 문서를 따르세요. 그런 다음 “3단계”의 기존 요청 코드를 다음 줄로 교체하세요:
WEB_UNLOCKER_API_KEY = "<YOUR_WEB_UNLOCKER_API_KEY>"
# Web Unlocker 인증 헤더 설정
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {WEB_UNLOCKER_API_KEY}"
}
# 요청 페이로드 정의
payload = {
"zone": "unblocker",
"url": "https://www.scrapingcourse.com/ecommerce/product/adrienne-trek-jacket/", # 대상 URL로 교체
"format": "raw"
}
# 대상 페이지의 차단 해제된 HTML 가져오기
response = requests.post("https://api.brightdata.com/request", json=payload, headers=headers)이렇게 간단합니다—더 이상 차단도, 제한도 없습니다! 이제 Gemini를 사용해 웹 스크래핑을 할 때 차단될까 걱정하지 않아도 됩니다.
결론
이 블로그 글에서는 Gemini를 Requests 및 기타 도구와 결합하여 AI 기반 스크레이퍼를 구축하는 방법을 배웠습니다. 웹 스크래핑의 주요 과제 중 하나는 차단될 위험이지만, Bright Data의 Web Unlocker API를 사용하여 해결했습니다.
여기서 설명한 바와 같이, Gemini와 Web Unlocker API를 결합하면 맞춤형 파싱 로직 없이도 모든 사이트에서 데이터를 추출할 수 있습니다. 이는 Bright Data의 제품과 서비스가 지원하는 수많은 시나리오 중 하나로, 효과적인 AI 기반 웹 스크래핑 구현을 돕습니다.
다른 웹 스크래핑 도구도 살펴보세요:
- 프록시 서비스: 지역 제한을 우회하는 4가지 유형의 프록시(1억 5천만 개 이상의 주거용 IP 포함)
- 웹 스크레이퍼 API: 100개 이상의 인기 도메인에서 최신 구조화된 웹 데이터를 추출하기 위한 전용 엔드포인트
- SERP API: SERP의 지속적인 잠금 해제 관리를 처리하고 한 페이지를 추출하는 API
- 스크래핑 브라우저: 내장된 잠금 해제 기능을 갖춘 Puppeteer, Selenium, Playwright 호환 브라우저
지금 Bright Data에 가입하여 프록시 서비스와 스크래핑 제품을 무료로 테스트해 보세요!




