

대규모 언어 모델(LLM)은 정보 접근 방식과 지능형 애플리케이션 구축 방식을 혁신하고 있습니다. 특히 도메인별 지식이나 독점 데이터를 활용할 때 LLM의 잠재력을 최대한 발휘하려면 고품질의 구조화된 벡터 데이터셋을 구축하는 것이 중요합니다. LLM의 성능과 정확도는 입력 데이터의 품질과 직결됩니다. 부실하게 준비된 데이터셋은 저조한 결과를 초래할 수 있는 반면, 잘 관리된 데이터셋은 LLM을 진정한 도메인 전문가로 탈바꿈시킬 수 있습니다.
이 가이드에서는 AI 활용이 가능한 벡터 데이터셋을 생성하기 위한 자동화 파이프라인 구축 방법을 단계별로 안내합니다.
과제: LLM용 데이터 확보 및 준비
LLM은 방대한 범용 텍스트 코퍼스로 훈련되지만, 제품 관련 질의 응답, 산업 뉴스 분석, 고객 피드백 해석과 같은 특정 작업이나 도메인에 적용할 때는 종종 한계가 있습니다. 이를 진정으로 유용하게 만들려면 사용 사례에 맞춤화된 고품질 데이터가 필요합니다.
이러한 데이터는 일반적으로 웹에 흩어져 있거나, 복잡한 사이트 구조 뒤에 숨겨져 있거나, 봇 방지 조치로 보호되어 있습니다.
당사의 자동화된 워크플로는 데이터 세트 생성의 가장 어려운 부분을 처리하는 간소화된 파이프라인으로 이 문제를 해결합니다.
- 웹 데이터 추출. Bright Data를 활용하여 대규모 데이터 추출을 수행하며, AI 중심 인프라를 통해 CAPTCHA 및 IP 차단과 같은 문제를 우회합니다.
- 데이터 구조화. Google Gemini를 활용하여 원시 콘텐츠를 분석, 정리하고 잘 구조화된 JSON으로 변환합니다.
- 의미 임베딩. 텍스트를 풍부한 문맥적 의미를 포착하는 벡터 임베딩으로 변환합니다.
- 저장 및 검색. 빠르고 확장 가능한 시맨틱 검색 데이터베이스인 Pinecone에서 벡터를 인덱싱합니다.
- AI 적용 준비 완료 출력. 파인 튜닝, RAG(질문-답변-추론) 또는 기타 도메인 특화 AI 애플리케이션에 바로 활용 가능한 고품질 데이터셋 생성.
핵심 기술 개요
파이프라인 구축에 앞서, 관련된 핵심 기술과 각 기술이 워크플로우를 어떻게 지원하는지 간단히 살펴보겠습니다.
Bright Data: 확장 가능한 웹 데이터 수집
AI에 적합한 벡터 데이터 세트를 만드는 첫 번째 단계는 관련성이 높고 고품질의 소스 데이터를 수집하는 것입니다. 일부는 지식 기반이나 문서와 같은 내부 시스템에서 가져올 수 있지만, 상당 부분은 공개 웹에서 가져오는 경우가 많습니다.
그러나 현대 웹사이트는 CAPTCHA, IP 속도 제한, 브라우저 지문 인식 등 정교한 봇 방지 메커니즘을 사용하기 때문에 대규모 스크래핑이 어렵습니다.
Bright Data는 데이터 수집의 복잡성을 추상화하는 Web Unlocker API로 이러한 과제를 해결합니다. 프록시 로테이션, CAPTCHA 해결, 브라우저 에뮬레이션을 자동으로 처리하므로 데이터 접근 방법보다 데이터 자체에 전적으로 집중할 수 있습니다.
Google Gemini: 지능형 콘텐츠 변환
Gemini는 Google이 개발한 강력한 다중 모드 AI 모델 제품군으로, 다양한 유형의 콘텐츠를 이해하고 처리하는 데 탁월합니다. 데이터 추출 파이프라인에서 Gemini는 세 가지 핵심 기능을 수행합니다:
- 콘텐츠 파싱: 원시 HTML 또는 정제된 마크다운 콘텐츠를 처리합니다.
- 정보 추출: 사전 정의된 스키마에 기반하여 특정 데이터 포인트를 식별하고 추출합니다.
- 데이터 구조화: 추출된 정보를 깔끔하고 구조화된 JSON 형식으로 변환합니다.
이 AI 기반 접근 방식은 취약한 CSS 선택자나 불안정한 정규 표현식에 의존하는 기존 방법에 비해 주요 이점을 제공하며, 특히 다음과 같은 사용 사례에서 효과적입니다:
- 동적 웹 페이지 – 레이아웃이나 DOM이 빈번히 변경되는 페이지( 전자상거래 사이트, 뉴스 포털 및 기타 고속 도메인에서 흔함).
- 구조화되지 않은 콘텐츠: 장문 또는 체계적이지 않은 텍스트 블록에서 구조화된 데이터를 추출합니다.
- 복잡한 파싱 로직: 사이트나 콘텐츠 변형마다 맞춤형 스크래핑 규칙을 유지 관리하고 디버깅할 필요가 없습니다.
AI가 데이터 추출 프로세스를 어떻게 혁신하는지 자세히 알아보려면 ‘웹 스크래핑을 위한 AI 활용’을 살펴보세요. 스크래핑 워크플로우에 Gemini를 구현하는 과정을 단계별로 안내하는 실습 튜토리얼을 원하신다면 포괄적인 가이드인 ‘Gemini를 활용한 웹 스크래핑’을 확인해 보세요.
문장 변환기: 의미적 임베딩 생성
임베딩은 고차원 공간에서 텍스트(또는 기타 데이터 유형)를 표현하는 밀집 벡터입니다. 이러한 벡터는 의미적 의미를 포착하여 유사한 텍스트 조각이 코사인 유사도나 유클리드 거리 같은 지표로 측정할 때 서로 가까운 벡터로 표현되도록 합니다. 이 특성은 의미적 검색, 클러스터링, 검색 강화 생성(RAG)과 같이 관련성 있는 콘텐츠 찾기가 의미적 근접성에 의존하는 애플리케이션에 중요합니다.
Sentence Transformers 라이브러리는 고품질 문장 및 단락 임베딩 생성을 위한 사용하기 쉬운 인터페이스를 제공합니다. Hugging Face Transformers를 기반으로 구축되어 의미적 작업에 미세 조정된 다양한 사전 훈련 모델을 지원합니다.
이 생태계에서 가장 인기 있고 효과적인 모델 중 하나는 all-MiniLM-L6-v2입니다. 이 모델이 두드러지는 이유는 다음과 같습니다:
- 아키텍처: MiniLM 아키텍처를 기반으로 하며, 강력한 성능을 유지하면서 속도와 크기를 최적화했습니다.
- 임베딩 차원: 입력을 384차원 벡터 공간에 매핑하여 효율성과 컴팩트함을 동시에 실현합니다.
- 훈련 목표: 의미 이해를 강화하기 위해 대조적 학습 접근법을 사용하여 10억 개 이상의 문장 쌍으로 미세 조정됨.
- 성능: 문장 유사도, 의미 클러스터링, 정보 검색과 같은 작업에서 최첨단 또는 최첨단에 근접한 결과를 제공합니다.
- 입력 길이: 최대 256개의 단어 조각(토큰)을 처리하며, 더 긴 텍스트는 자동으로 잘립니다. 이는 텍스트 청킹 과정에서 중요한 고려 사항입니다.
더 큰 모델이 약간 더 미묘한 임베딩을 제공할 수 있지만, all-MiniLM-L6-v2는 성능, 효율성, 비용 간의 탁월한 균형을 제공합니다. 384차원 벡터는 다음과 같은 장점이 있습니다:
- 계산 속도가 빠릅니다.
- 리소스 소모가 적습니다.
- 저장 및 인덱싱이 용이합니다.
대부분의 실용적인 사용 사례, 특히 초기 개발 단계나 리소스가 제한된 환경에서는 이 모델로도 충분합니다. 극단적인 사례에서 정확도가 약간 떨어지더라도 속도와 확장성 측면에서 얻는 상당한 이점이 이를 상쇄합니다. 따라서 AI 애플리케이션의 첫 번째 버전을 구축하거나 제한된 인프라에서 성능을 최적화할 때는 all-MiniLM-L6-v2를 사용하는 것이 좋습니다.
Pinecone: 벡터 임베딩 저장 및 검색
텍스트가 벡터 임베딩으로 변환되면 이를 효율적으로 저장, 관리 및 쿼리하기 위한 전용 데이터베이스가 필요합니다. 기존 데이터베이스는 이를 위해 설계되지 않았습니다.벡터 데이터베이스는 임베딩 데이터의 고차원적 특성을 처리하도록 특별히 제작되어 RAG 파이프라인, 시맨틱 검색, 개인화 및 기타 AI 기반 애플리케이션에 필수적인 실시간 유사도 검색을 가능하게 합니다.
파인콘은 개발자 친화적 인터페이스, 저지연 검색 성능, 완전 관리형 인프라로 유명한 벡터 데이터베이스입니다. 대규모 벡터 인덱싱 및 검색의 복잡성을 효율적으로 관리하며, 벡터 검색 인프라의 복잡성을 추상화합니다. 주요 구성 요소는 다음과 같습니다:
- 인덱스: 벡터를 저장하는 컨테이너입니다.
- 벡터: 관련 메타데이터가 포함된 실제 임베딩.
- 컬렉션: 백업 및 버전 관리를 위한 인덱스의 정적 스냅샷.
- 네임스페이스: 다중 테넌시를 위한 인덱스 내 데이터 분할.
Pinecone은 서버리스 ( Serverless )와 포드 기반(Pod-Based) 두 가지 배포 아키텍처를 제공합니다. 대부분의 사용 사례, 특히 시작 단계나 동적 부하를 처리할 때는 단순성과 비용 효율성으로 인해 서버리스가 권장 옵션입니다.
설정 및 필수 조건
파이프라인 구축 전에 다음 구성 요소가 올바르게 설정되었는지 확인하십시오.
필수 사항
- 시스템에Python 3.9 이상이 설치되어 있어야 합니다.
- 다음 API 자격 증명을 수집하십시오:
- Bright Data API 키 및 웹 언락커 영역 이름
- Google Gemini API 키
- Pinecone API 키
각 API 키 생성 방법은 아래 도구별 설정 섹션을 참조하십시오.
필수 라이브러리 설치
이 프로젝트에 필요한 핵심 Python 라이브러리를 설치하세요:
pip install requests python-dotenv google-generativeai sentence-transformers pinecone이 라이브러리들은 다음을 제공합니다:
requests: API 상호작용을 위한 널리 사용되는 HTTP 클라이언트 (requests 가이드)python-dotenv: 환경 변수에서 API 키를 안전하게 로드합니다google-generativeai: Google의 공식 Gemini SDK ( JavaScript, Go 및 기타 언어 지원)sentence-transformers: 의미 벡터 임베딩 생성을 위한 사전 훈련된 모델pinecone: Pinecone 벡터 데이터베이스용 SDK (Python, Node.js, Go 등언어별 SDK 제공)
환경 변수 구성
프로젝트 루트 디렉터리에 .env 파일을 생성하고 API 키를 추가하세요:
BRIGHT_DATA_API_KEY="your_bright_data_api_key_here"
GEMINI_API_KEY="your_gemini_api_key_here"
PINECONE_API_KEY="your_pinecone_api_key_here"Bright Data 설정
Bright Data의 Web Unlocker를 사용하려면:
- API 토큰 생성
- Bright Data 대시보드에서Web Unlocker 영역 설정
구현 예시 및 통합 코드는 Web Unlocker GitHub 저장소에서 확인하세요.
아직 솔루션을 비교 중이라면, 이 AI 스크래핑 도구 비교를 통해 Bright Data가 다른 플랫폼과 비교하여 어떻게 평가되는지 알아보세요.
Gemini 설정
Gemini API 키 생성 방법:
- Google AI Studio로 이동하세요
- “+ API 키 생성”을 클릭하세요
- 키를 복사하여 안전하게 보관하세요
팁: 개발 및 소규모 테스트에는 무료 티어가 충분합니다. 더 높은 처리량(RPM/RPD), 더 큰 토큰 창(TPM), 또는 엔터프라이즈급 프라이버시 및 고급 모델 접근이 필요한 프로덕션 환경에서는 속도 제한 및 요금제를 참조하세요.
Pinecone 설정
- Pinecone.io에서 가입하세요
- 대시보드에서 API 키 복사
- 새 인덱스 생성:
- 인덱스 → 인덱스 생성 클릭
- 다음 항목 설정:
- 인덱스 이름: 명확한 이름 선택 (예:
semantic-search-index) - 벡터 유형: Dense 선택
- 차원: 임베딩 모델의 출력 차원과 일치시킵니다(예:
all-MiniLM-L6-v2의경우384). - 메트릭: cosine 선택 (대안:
euclidean,dotproduct) - 용량 모드: 서버리스 사용
- 클라우드 및 지역: 선호하는 공급자와 위치를 선택하세요(예: AWS
us-east-1)
- 인덱스 이름: 명확한 이름 선택 (예:
- 인덱스 생성 클릭
설정이 완료되면 상태가 녹색이고 초기 레코드 수가 0인 인덱스가 표시됩니다.

파이프라인 구축: 단계별 구현
필수 조건이 설정되었으므로, Walmart의 MacBook Air M1 제품 리뷰를 실용적인 예시로 사용하여 데이터 파이프라인을 구축해 보겠습니다.
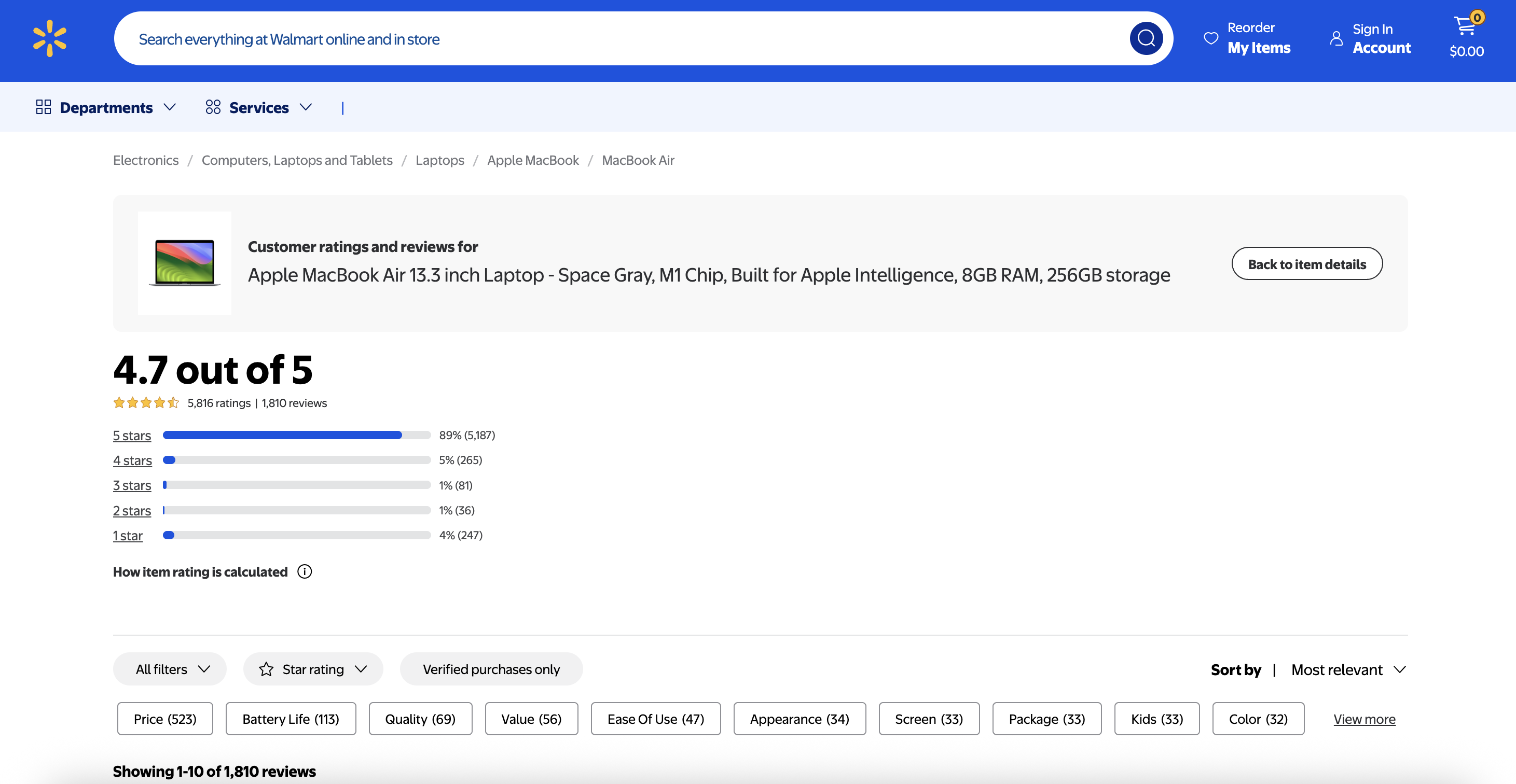
1단계: Bright Data Web Unlocker를 통한 데이터 수집
파이프라인의 기초는 대상 URL에서 원시 HTML 콘텐츠를 가져오는 것입니다. Bright Data의 Web Unlocker는 Walmart와 같은 전자상거래 사이트에서 흔히 사용하는 정교한 스크래핑 방지 조치를 우회하는 데 탁월합니다.
웹페이지 콘텐츠 수집을 위한 구현은 다음과 같습니다:
import requests
import os
from dotenv import load_dotenv
# 환경 변수에서 API 키 로드
load_dotenv()
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")
def fetch_page(url: str) -> str:
"""Bright Data Web Unlocker를 사용해 페이지 콘텐츠 가져오기 (Markdown 형식)"""
try:
response = requests.post(
"https://api.brightdata.com/request",
headers={
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json",
},
json={
"zone": "web_unlocker2",
"url": url,
"format": "raw",
"data_format": "markdown", # HTML을 직접 마크다운으로 변환
},
timeout=60,
)
if response.status_code == 200 and len(response.text) > 1000:
return response.text
except Exception as e:
print(f"요청 실패: {str(e)}")
return None
# 사용 예시
walmart_url = "https://www.walmart.com/reviews/product/609040889?page=1"
page_content = fetch_page(walmart_url)
if page_content:
print(f"성공! {len(page_content)} 자를 가져왔습니다")
else:
print("페이지 가져오기 실패")왜 원시 HTML 대신 마크다운을 사용할까? 우리 파이프라인에서는 몇 가지 중요한 이유로 콘텐츠를 마크다운 형식(data_format: 'markdown')으로 요청합니다. 마크다운은 HTML 태그, 스타일링 및 기타 잡음을 제거하여 복잡성을 줄이고 필수 콘텐츠만 남깁니다. 이로 인해 토큰 수가 크게 감소하여 LLM 처리가 더 효율적으로 이루어집니다. 또한 의미 구조를 더 깔끔하고 가독성 높은 형식으로 보존하여 명확성과 처리 속도를 모두 향상시킵니다. 임베딩 생성 및 벡터 인덱싱과 같은 작업이 더 빠르고 가벼워집니다.
현대 AI 에이전트가 마크다운을 선호하는 이유에 대한 자세한 내용은 ‘새로운 AI 에이전트가 HTML 대신 마크다운을 선택하는 이유’를 참고하세요.
2단계: 페이지 분할 처리
월마트는 제품 리뷰를 여러 페이지에 걸쳐 분산합니다. 완전한 데이터 세트를 확보하려면 페이지 매김 처리를 구현해야 합니다. 다음을 수행해야 합니다:
- 올바른 페이지 URL 생성 (
?page=1,?page=2등) - 각 페이지의 콘텐츠 가져오기
- “다음 페이지” 존재 여부 감지
- 더 이상 페이지가 없을 때까지 반복
다음은 page=n+1 참조가 더 이상 발견되지 않을 때까지 콘텐츠를 가져오는 간단한 페이지네이션 루프입니다:
current_page = 1
while True:
url = f"https://www.walmart.com/reviews/product/609040889?page={current_page}"
page_content = fetch_page(url)
if not page_content:
print(f"페이지 {current_page}에서 중지: 콘텐츠 가져오기 실패 또는 콘텐츠 없음.")
break
# 여기서 가져온 콘텐츠로 작업 수행
print(f"페이지 {current_page} 가져옴")
# 다음 페이지 참조 존재 여부 확인
if f"page={current_page + 1}" not in page_content:
print("다음 페이지 없음. 페이지네이션 종료.")
break
current_page += 13단계: Google Gemini를 활용한 구조화된 데이터 추출
이전 단계에서 얻은 깔끔한 마크다운 콘텐츠를 바탕으로, 이제 Google Gemini를 활용해 리뷰에서 특정 정보를 추출하고 JSON 형식으로 구조화할 것입니다. 이를 통해 비정형 텍스트를 벡터 데이터베이스가 효율적으로 색인할 수 있는 체계적인 데이터로 변환합니다.
우리 사용 사례에 적합한 뛰어난 사양을 제공하는 gemini-2.0-flash 모델을 사용합니다:
- 입력 컨텍스트: 1,048,576 토큰
- 출력 제한: 8,192 토큰
- 다중 모드 지원: 텍스트, 코드, 이미지, 오디오, 비디오
월마트 리뷰 페이지의 마크다운 텍스트는 일반적으로 약 3,000개의 토큰을 포함하며, 이는 모델의 제한 범위 내에 있습니다. 따라서 페이지를 작은 조각으로 분할하지 않고 한 번에 전체를 전송할 수 있습니다.
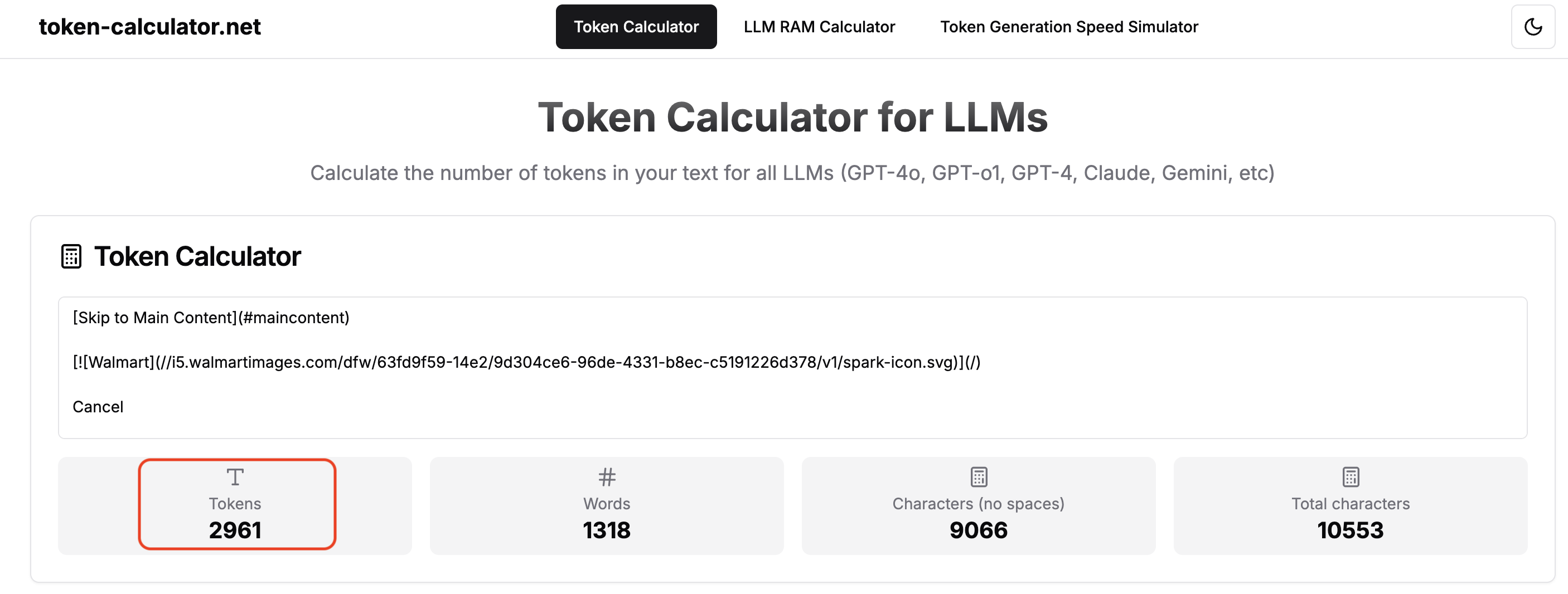
문서가 컨텍스트 창을 초과하는 경우 분할 전략을 구현해야 합니다. 하지만 일반적인 웹 페이지의 경우 Gemini의 용량 덕분에 이 작업이 불필요합니다.
다음은 Gemini를 사용하여 구조화된 JSON 형식으로 리뷰를 추출하는 샘플 Python 함수입니다:
import google.generativeai as genai
import json
# JSON 출력 구성으로 Gemini 초기화
model = genai.GenerativeModel(
model_name="gemini-2.0-flash",
generation_config={"response_mime_type": "application/json"},
)
def extract_reviews(markdown: str) -> list[dict]:
"""Gemini를 사용하여 Markdown에서 구조화된 리뷰 데이터를 추출합니다."""
prompt = f"""
이 Walmart 제품 페이지 콘텐츠에서 모든 고객 리뷰를 추출하세요.
다음 구조를 가진 리뷰 객체의 JSON 배열을 반환하세요:
{{
"reviews": [
{{
"date": "YYYY-MM-DD 또는 원본 날짜 형식(사용 가능한 경우)",
"title": "리뷰 제목/헤드라인",
"description": "리뷰 본문 내용",
"rating": <1–5 사이의 정수>
}}
]
}}
규칙:
- 페이지에 있는 모든 리뷰 포함
- 누락된 필드는 null로 처리
- 평점은 정수(1–5)로 변환
- 리뷰 텍스트 전체를 추출할 것 (단편이 아닌)
- 요약하지 않고 원본 리뷰 텍스트를 보존할 것
페이지 콘텐츠는 다음과 같습니다:
{markdown}
"""
response = model.generate_content(prompt)
result = json.loads(response.text)
# 결과 정규화 및 정리
return [
{
"date": review.get("date"),
"title": review.get("title"),
"description": review.get("description", "").strip(),
"rating": review.get("rating"),
}
for review in result.get("reviews", [])
]LLM 작업 시 프롬프트 엔지니어링이 핵심입니다. 본 구현에서는 Gemini가 유효한 JSON을 반환하도록 response_mime_type: "application/json"을 설정하여 복잡한 텍스트 파싱을 생략했습니다. 프롬프트 자체는 Gemini가 제공된 콘텐츠에만 의존하도록 지시하여 환각 현상을 줄이도록 세심하게 설계되었습니다. 또한 구조적 일관성을 위한 엄격한 JSON 스키마를 강제하고, 요약 없이 전체 리뷰 텍스트를 보존하며, 누락된 필드를 우아하게 처리합니다.
월마트 리뷰 페이지를 처리한 후 다음과 같은 구조화된 데이터를 받게 됩니다:
[
{
"date": "Apr 13, 2026",
"title": "OPEN BOX 구매보다 낫다",
"description": "다른 웹사이트에서 오래된 제품 OPEN BOX(제가 보기엔 미사용 상태)를 구매했습니다. 배터리가 방전되어 있었죠. 월마트는 더 저렴한 가격에 새 제품을 제공했습니다. 와우!!!!",
"rating": 5
},
{
"date": "2024년 12월 8일",
"title": "지원 없음",
"description": "노트북을 배달해 준 젊은 직원이 영수증이나 설명서 없이 노트북만 건넸습니다. 영수증과 설명서가 어디 있냐고 물었더니, '구매 내역에서 확인하실 수 있다'고만 했습니다. 도움과 지원을 받을 수 있는 곳이 어디인지 알았다면 기꺼이 이 리뷰를 수정했을 것입니다. 다음 날 전자제품 매장에 도움을 요청하러 갔지만, 직원도 전혀 알지 못했습니다.",
"rating": 3
}
// ... 더 많은 리뷰
]모든 단계(데이터 가져오기, 처리, 추출)를 결합한 작동 예시는 GitHub의 완성된 구현을 확인하세요.
4단계: Sentence Transformers를 이용한 벡터 임베딩 생성
JSON 형식의 깔끔하고 구조화된 리뷰 데이터를 확보했으니, 이제 각 리뷰에 대한 의미적 벡터 임베딩을 생성합니다. 이 임베딩은 의미적 검색이나 Pinecone 같은 벡터 데이터베이스에서의 인덱싱과 같은 후속 작업에 사용될 것입니다.
고객 리뷰의 전체 맥락을 포착하기 위해, 임베딩 전에 리뷰 제목과 설명을 하나의 문자열로 결합합니다. 이는 모델이 감정과 주제 모두를 더 효과적으로 인코딩하는 데 도움이 됩니다.
다음은 샘플 코드입니다:
from sentence_transformers import SentenceTransformer
# 임베딩 모델 로드
model = SentenceTransformer("all-MiniLM-L6-v2")
def generate_embeddings(reviews):
"""리뷰 제목과 설명으로부터 384차원 벡터 임베딩 생성"""
texts = []
valid_indices = []
# 제목과 설명을 임베딩용 단일 문자열로 결합
for idx, review in enumerate(reviews):
text_parts = []
if review.get("title"):
text_parts.append(f"리뷰 제목: {review['title']}")
if review.get("description"):
text_parts.append(f"리뷰 설명: {review['description']}")
if text_parts:
texts.append(". ".join(text_parts))
valid_indices.append(idx)
# 배치 처리로 임베딩 생성
embeddings = model.encode(
texts, show_progress_bar=True, batch_size=32, convert_to_numpy=True
).tolist()
# 임베딩을 원래 리뷰 객체에 다시 연결
for emb_idx, review_idx in enumerate(valid_indices):
reviews[review_idx]["embedding"] = embeddings[emb_idx]
return reviews이 코드의 역할:
- 모델 초기화: 384차원 덴스 임베딩을 반환하는
all-MiniLM-L6-v2모델을 로드합니다. - 입력 준비: 각 리뷰의
제목과설명을하나의 문자열로 결합합니다. - 배치 인코딩: 효율적인 처리를 위해 배치 처리와 함께
model.encode()를 사용합니다:batch_size=32: 속도와 메모리 사용량 최적화show_progress_bar=True: 인코딩 중 진행률 표시줄을 표시합니다convert_to_numpy=True: 출력을 NumPy 배열로 변환하여 조작 용이성 확보
- 임베딩 주입: 각 벡터를
"embedding"키 아래 해당 리뷰 객체에 다시 연결합니다.
중요 참고: Pinecone은 메타데이터 내 null 값을 지원하지 않습니다. 필드가 누락된 경우 Pinecone에 업로드 시 해당 키를 완전히 생략해야 합니다. 필터링 로직에서 특별한 의미를 가지지 않는 한 "N/A" 나 빈 문자열을 사용하지 마십시오.
(코드 가독성을 위해) 여기에는 정제 함수가 표시되지 않지만, 최종 구현에서는 수집 전 메타데이터 정리가 포함됩니다.
임베딩 생성 후, 각 리뷰 객체에는 384차원 벡터가 포함됩니다:
{
"date": "Apr 9, 2024",
"title": "Amazing Laptop!",
"description": "This M1 MacBook Air is incredibly fast and the battery lasts forever.",
"rating": 5,
"embedding": [0.0123, -0.0456, 0.0789, ..., 0.0345] // 384차원
}임베딩이 생성되면, 리뷰는 Pinecone에 벡터 저장소로 준비됩니다.
5단계: Pinecone에 임베딩 및 메타데이터 저장
파이프라인의 마지막 단계는 임베딩된 리뷰를 Pinecone에 업로드하는 것입니다.
다음은 Pinecone에 데이터를 업로드/삽입하는 Python 코드입니다:
import uuid
from pinecone import Pinecone, Index
# API 키로 Pinecone 클라이언트 초기화
pc = Pinecone(api_key="PINECONE_API_KEY")
index = pc.Index("brightdata-ai-dataset") # 실제 인덱스 이름으로 대체
# 임베딩이 이미 첨부된 리뷰 데이터 샘플
reviews_with_embeddings = [
{
"date": "Apr 9, 2024",
"title": "Amazing Laptop!",
"description": "This M1 MacBook Air is incredibly fast and the battery lasts forever.",
"rating": 5,
"embedding": [0.0123, -0.0456, ..., 0.0789], # 384차원 벡터
}
# ... 추가 리뷰
]
# 업로드용 벡터 레코드 준비
vectors = []
for review in reviews_with_embeddings:
if "embedding" not in review:
continue # 임베딩이 없는 항목 건너뛰기
vectors.append(
{
"id": str(uuid.uuid4()), # 고유 벡터 ID
"values": review["embedding"],
"metadata": {
"title": review.get("title"),
"description": review.get("description"),
"rating": review.get("rating"),
# 필요한 경우 메타데이터 필드 추가
},
}
)
# Pinecone에 일괄 업로드 (요청당 100개 벡터)
for i in range(0, len(vectors), 100):
batch = vectors[i : i + 100]
index.upsert(vectors=batch)Pinecone에 업서트하는 각 벡터에는 다음이 포함되어야 합니다:
id: 고유한 문자열 식별자 (필수)values: 벡터 자체 (부동 소수점 목록, 예: 384차원)metadata: 필터링 및 컨텍스트를 위한 선택적 키-값 쌍 (JSON 호환)
벡터 구조 예시:
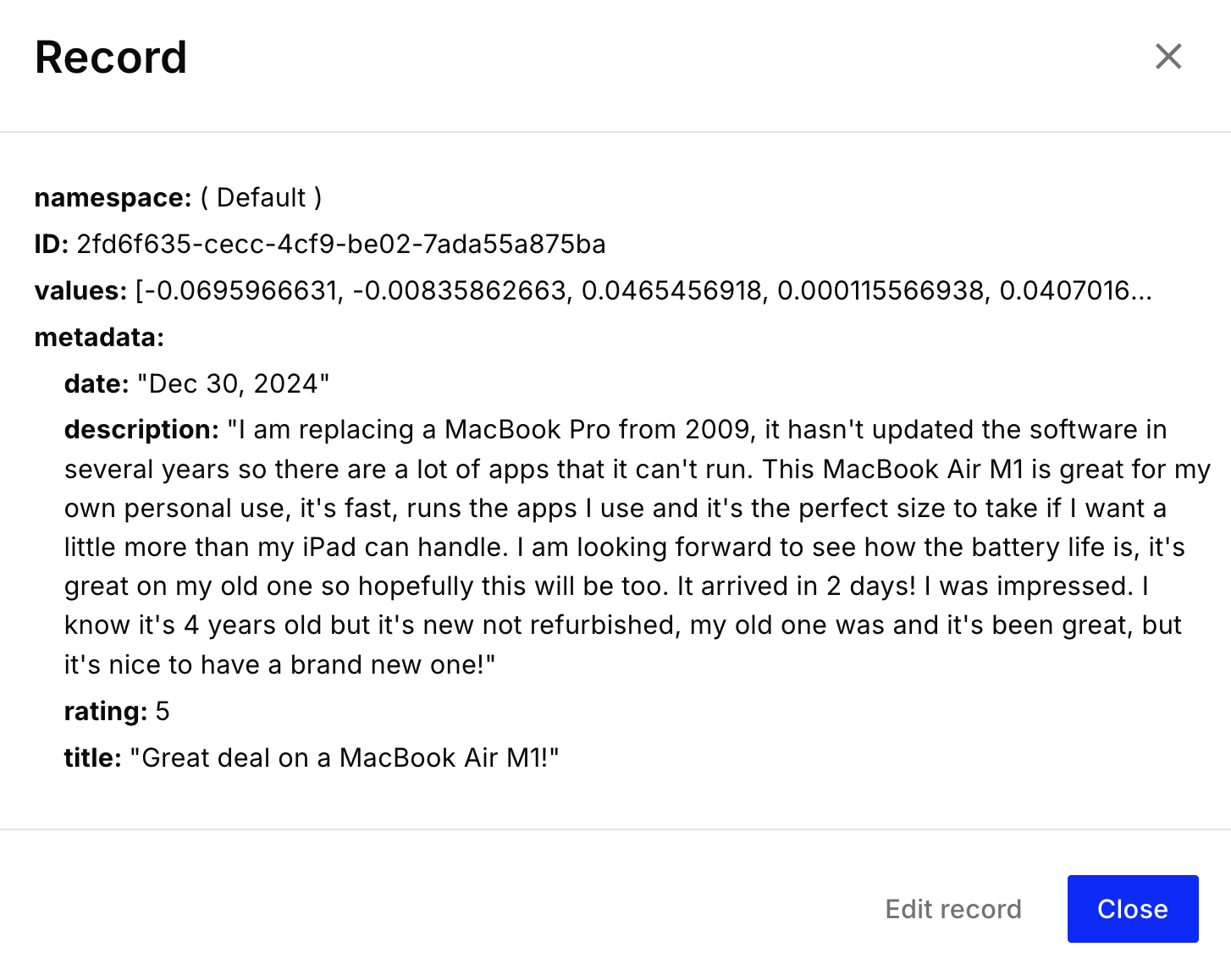
업로드가 완료되면 Pinecone 인덱스에 리뷰 벡터가 채워집니다:
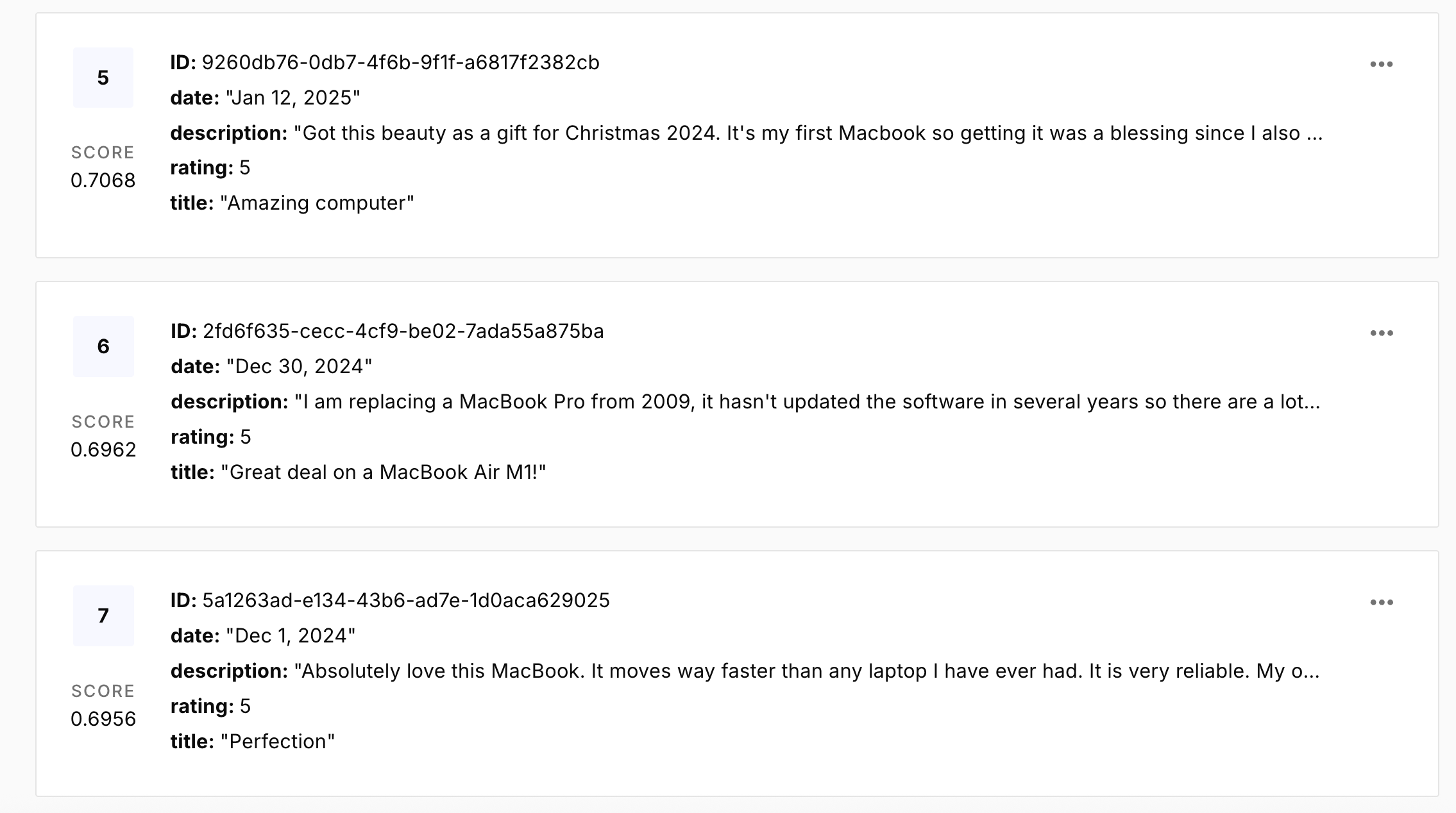
이제 AI 활용이 가능한 벡터 데이터셋이 Pinecone에 저장되어 다음 단계를 진행할 준비가 되었습니다 🔥
모든 단계(벡터 생성, Pinecone 업로드)를 결합한 작동 예제는 GitHub의 완전한 구현을 참조하세요.
(선택 사항이지만 권장) AI 활용 가능 데이터셋 활용
임베딩이 Pinecone에 인덱싱되면 시맨틱 검색 및 RAG 시스템과 같은 애플리케이션을 구동할 수 있습니다. 이 단계에서는 벡터 데이터베이스를 쿼리하고 지능형 응답을 생성하는 방법을 보여줍니다.
시맨틱 검색
벡터화된 데이터셋을 활용하는 가장 간단한 방법은 시맨틱 검색입니다. 키워드 검색과 달리 시맨틱 검색은 사용자가 자연어로 질의하여 동일한 단어를 공유하지 않더라도 개념적으로 유사한 콘텐츠를 검색할 수 있게 합니다.
자연어 쿼리로 시스템을 테스트해 보겠습니다:
queries = [
"학생에게 좋은 가격",
"가볍고 여행에 적합한",
]“학생에게 좋은 가격”이라는 쿼리에 대해 다음과 같은 결과를 볼 수 있습니다:
#1 (점수: 0.6201)
ID: 75878bdc-8d96-416a-8292-484971c3bd61
날짜: 2024년 8월 3일
평점: 5.0
설명: 딸이 대학 생활에 딱 필요한 물건이었고 가격도 완벽했어요
#2 (점수: 0.5868)
ID: 758963ae-0927-4e82-bece-d098991f5a73
날짜: 2024년 6월 13일
평점: 5.0
설명: 가격이 적당했어요. 손자에게 완벽한 졸업 선물이었습니다🙌 정말 잘 작동합니다! 자연어 쿼리로 매우 관련성 높은 결과를 반환합니다.
의미 기반 검색은 이렇게 작동합니다:
- 쿼리 임베딩: 검색 쿼리는 인덱싱에 사용된 것과 동일한
all-MiniLM-L6-v2모델을 사용하여 벡터로 변환됩니다. - 벡터 검색: Pinecone은 코사인 유사도를 사용하여 가장 유사한 벡터를 찾습니다.
- 메타데이터 검색: 결과에는 유사도 점수와 연관된 메타데이터가 모두 포함됩니다.
완전한 구현 예제는 다음을 참조하세요: 시맨틱 검색 클라이언트 Python 파일.
검색을 넘어: 검색 강화 생성(RAG)
시맨틱 검색이 작동하면 LLM 기반 RAG 시스템 구축까지 한 걸음 남았습니다. 검색 강화 생성(RAG)을 통해 LLM은 벡터화된 데이터 세트와 같은 외부 컨텍스트를 사용하여 근거 있는 응답을 생성할 수 있습니다.
RAG 흐름:
- 사용자가 질문을 합니다(예: “이 맥북은 대학생에게 좋은가요?”).
- 시맨틱 검색이 Pinecone에서 관련 문서를 검색합니다.
- 검색된 컨텍스트 + 질문이 Google Gemini 같은 LLM으로 전송됩니다.
- LLM이 데이터셋의 사실들을 바탕으로 답변합니다.
RAG 응답 예시:
🤔 사용자: 배터리 수명이 대학 생활에 적합한가요?
🤖 어시스턴트: 네, 사용자들은 긴 배터리 수명을 보고합니다—하루 종일 수업과 공부를 버틸 만큼 충분합니다.
🤔 사용자: 크롬북과 비교하면 어때요?
🤖 어시스턴트: 한 리뷰에 따르면 맥북 에어는 "크롬북에 비해 매우 부드럽게 작동한다"고 합니다.RAG 및 시맨틱 검색에 사용된 전체 코드 보기: RAG 챗봇 구현.
다음 단계
AI 준비 벡터 데이터셋 생성을 위한 완전한 파이프라인 구축에 성공하셨습니다. 구현을 확장하고 최적화하는 방법은 다음과 같습니다:
- 데이터 수집 확장: 더 방대한 데이터가 필요한 경우, Bright Data의 AI 모델 및 에이전트에 최적화된 무제한의 규정 준수 웹 데이터 접근을 위한 완전한 AI 준비 웹 데이터 인프라를 살펴보세요.
- 임베딩 모델 실험:
all-MiniLM-L6-v2가효율적이지만, 더 큰 모델이나 다국어 모델로 전환하면 특정 사용 사례에서 더 나은 결과를 얻을 수 있습니다. Google Gemini 및 OpenAI의 임베딩 API도 시도해 볼 수 있습니다. - 추출 프롬프트 개선: 추출해야 하는 웹사이트 구조나 데이터 스키마에 맞춰 Gemini 프롬프트를 맞춤 설정하세요.
- 고급 Pinecone 기능 활용: 공식 Pinecone 문서를 참고하여 필터링, 네임스페이스, 메타데이터 인덱싱, 하이브리드 검색 기능을 탐색하세요.
- 파이프라인 자동화: Apache Airflow 또는 Prefect와 같은 오케스트레이션 도구, AWS Step Functions 또는 Google Cloud Workflows와 같은 클라우드 네이티브 스케줄링 도구를 사용하여 이 파이프라인을 프로덕션 워크플로에 통합하세요.
- AI 기반 애플리케이션 구축: 시맨틱 검색 또는 RAG 구성 요소를 사용하여 고객 지원 챗봇, 지식 기반 검색, 추천 엔진과 같은 실제 도구를 만드세요.
결론
원시 웹 데이터를 대규모 언어 모델을 위한 가치 있는 자산으로 변환하는 AI 준비 벡터 데이터셋을 생성하고 관리하는 완전하고 강력한 파이프라인을 성공적으로 구축했습니다. 확장 가능한 웹 스크래핑을 위한 Bright Data, 지능형 구조화 추출을 위한 Google Gemini, 의미적 임베딩 생성을 위한 Sentence Transformers, 벡터 저장 및 검색을 위한 Pinecone을 결합함으로써 LLM 애플리케이션을 향상시키기 위한 맞춤형 데이터를 효과적으로 준비했습니다.
이러한 접근 방식은 LLM을 특정 도메인 지식에 기반하여 더 정확하고 관련성 높으며 가치 있는 AI 기반 솔루션을 제공합니다.
추가 자료 및 리소스
AI, 대규모 언어 모델(LLM), 웹 데이터 추출에 대한 이해를 심화시키려면 다음 자료를 참고하세요:
- RAG 및 챗봇:
- AI 및 웹 스크래핑 기법:
- 의 파인 튜닝 및 데이터셋
- 핵심 개념:





