

이 튜토리얼에서는 다음을 살펴보게 됩니다:
- Qwen3의 정의 및 LLM으로서의 차별점
- 웹 스크래핑 작업에 적합한 이유
- Hugging Face를 통해 로컬에서 Qwen3을 웹 스크래핑에 활용하는 방법
- 주요 한계점과 해결 방법
- AI 기반 스크래핑을 위한 Qwen3의 몇 가지 대안
자, 시작해 보겠습니다!
Qwen3란 무엇인가?
Qwen3는 알리바바 클라우드의 Qwen 팀이 개발한 최신 세대 대규모 언어 모델(LLM)입니다. 이 모델은 오픈소스로 GitHub에서 자유롭게 탐색할수 있으며, Apache 2.0 라이선스 하에 제공됩니다. 이는 연구 및 개발에 매우 적합합니다.
Qwen3의 주요 특징은 다음과 같습니다:
- 하이브리드 추론: 복잡한 논리적 추론(수학이나 코딩 등)을 위한 “사고 모드”와 더 빠르고 범용적인 응답을 위한 “비사고 모드” 사이를 전환할 수 있습니다. 이를 통해 최적의 성능과 비용 효율성을 위해 추론의 깊이를 제어할 수 있습니다.
- 다양한 모델: Qwen3은 0.6B에서 32B 매개변수 범위의 고밀도 모델과 30B, 235B 변형과 같은 전문가 혼합(MoE) 모델을 포함한 포괄적인 모델 제품군을 제공합니다.
- 향상된 기능: 추론, 지시 따르기, 에이전트 기능, 다국어 지원(100개 이상의 언어 및 방언 지원)에서 상당한 발전을 보입니다.
- 훈련 데이터: Qwen3은 약 36조 토큰에 달하는 방대한 데이터 세트로 훈련되었으며, 이는 이전 버전인 Qwen2.5의 거의 두 배에 달합니다.
웹 스크래핑에 Qwen3를 사용해야 하는 이유
Qwen3는 HTML 페이지의 비정형 콘텐츠 해석 및 구조화를 자동화하여 웹 스크래핑을 용이하게 합니다. 이는 수동 데이터 파싱의 필요성을 제거합니다. 데이터를 추출하기 위해 복잡한 로직을 작성하는 대신, 모델이 페이지 구조를 자동으로 이해합니다.
Qwen3을 웹 데이터 파싱에 활용하는 것은 다음과 같은 일반적인 웹 스크래핑 과제 처리 시 특히 유용합니다:
- 자주 변경되는 페이지 레이아웃: 아마존과 같이 각 제품 페이지마다 다른 데이터를 표시하는 경우가 대표적입니다.
- 구조화되지 않은 데이터: Qwen3은 하드코딩된 선택자나 정규 표현식 로직 없이도 복잡하고 자유 형식의 텍스트에서 유용한 정보를 추출할 수 있습니다.
- 구문 분석이 어려운 콘텐츠: 일관성 없거나 복잡한 구조의 페이지에서 Qwen3과 같은 대규모 언어 모델(LLM)은 맞춤형 파싱 로직을 필요로 하지 않습니다.
더 자세한 내용은 웹 스크래핑에 AI를 활용하는 가이드를 참고하세요.
또 다른 주요 장점은 Qwen3이 오픈소스라는 점입니다. 즉, 타사 API에 의존하거나 OpenAI와 같은 프리미엄 LLM에 비용을 지불하지 않고도 자신의 컴퓨터에서 무료로 로컬 실행이 가능합니다. 이를 통해 스크래핑 아키텍처를 완전히 제어할 수 있습니다.
Python에서 Qwen3을 사용한 웹 스크래핑 수행 방법
이 섹션에서는 “웹 스크래핑 학습용 전자상거래 테스트 사이트” 샌드박스의 “Affirm Water Bottle” 제품 페이지를 대상으로 합니다:
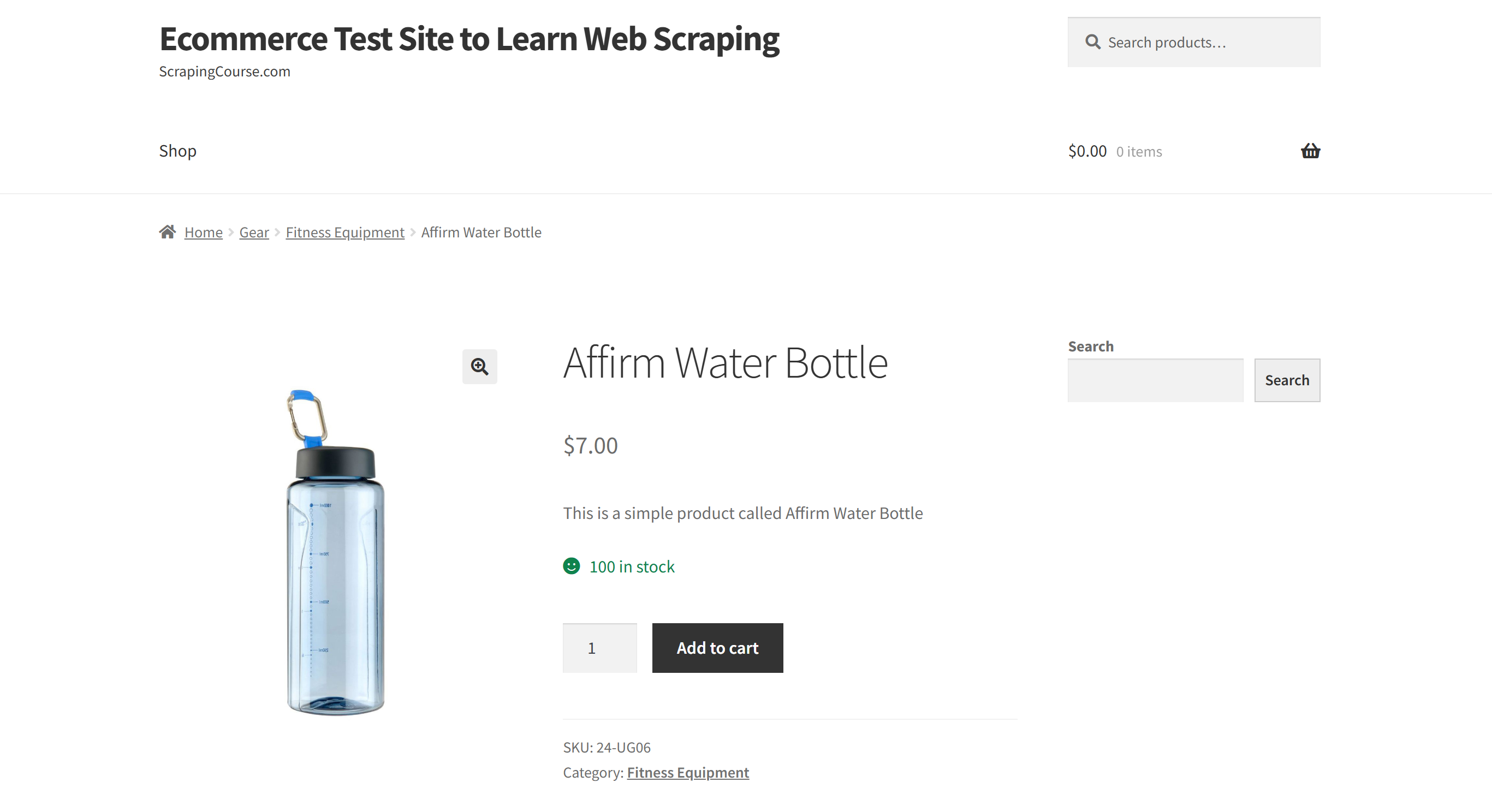
이 페이지는 전자상거래 제품 페이지가 일반적으로 일관성 없는 구조를 가지며 다양한 유형의 데이터를 표시하기 때문에 훌륭한 예시가 됩니다. 이러한 변동성이 바로 전자상거래 웹 스크래핑을 특히 어렵게 만드는 요소이며, 동시에 AI가 큰 차이를 만들 수 있는 부분이기도 합니다.
여기서는 수동 파싱 규칙 작성 없이 Qwen3 기반 스크레이퍼를 활용해 제품 정보를 지능적으로 추출할 것입니다.
참고: 이 튜토리얼은 Hugging Face를 사용하여 Qwen3 모델을 로컬에서 무료로 실행하는 방법을 보여줍니다. 현재는 Qwen3 모델을 호스팅하는 LLM 제공업체에 연결하거나 Ollama 같은 솔루션을 활용하는 등 다른 실행 가능한 옵션도 존재합니다.
Qwen3을 사용하여 웹 데이터 스크래핑을 시작하려면 아래 단계를 따르세요!
1단계: 프로젝트 설정
시작하기 전에 컴퓨터에 Python 3.10 이상이 설치되어 있는지 확인하세요. 설치되어 있지 않다면 다운로드하여 설치 지침을 따르세요.
다음으로, 스크래핑 프로젝트용 폴더를 생성하기 위해 아래 명령어를 실행하세요:
mkdir qwen3-scraperqwen3-scraper 디렉터리는 Qwen3을 사용한 웹 스크래핑 프로젝트 폴더로 사용됩니다.
터미널에서 해당 폴더로 이동한 후 내부에서 Python 가상 환경을 초기화하세요:
cd qwen3-scraper
python -m venv venv선호하는 Python IDE에서 프로젝트 폴더를 로드하세요. Python 확장 기능이 설치된 Visual Studio Code나 PyCharm Community Edition이 모두 훌륭한 선택입니다.
프로젝트 폴더 내에 scraper.py 파일을 생성합니다. 현재 이 파일에는 다음 내용이 포함되어야 합니다:
현재 scraper.py는 빈 Python 스크립트이지만, 곧 LLM 웹 스크래핑 로직이 포함될 것입니다.
그런 다음 가상 환경을 활성화하세요. Linux 또는 macOS에서는 다음을 실행합니다:
source venv/bin/activateWindows에서는 다음과 같이 실행하세요:
venv/Scripts/activate참고: 다음 단계에서는 필요한 모든 라이브러리를 설치하는 방법을 안내합니다. 한 번에 모두 설치하려면 지금 아래 명령어를 사용하세요:
pip install transformers torch accelerate requests beautifulsoup4 markdownify완료! Qwen3을 활용한 웹 스크래핑을 위한 Python 환경이 완벽하게 설정되었습니다.
2단계: Hugging Face에서 Qwen3 구성
본 섹션 시작 부분에서 언급했듯이, 로컬에서 Qwen3 모델을 실행하기 위해 Hugging Face를 사용할 것입니다. 최근 Hugging Face가 Qwen3 모델 지원을 추가했기 때문에 이제 가능합니다.
먼저 활성화된 가상 환경에 있는지 확인하세요. 그런 다음 다음 명령을 실행하여 필요한 Hugging Face 종속성을 설치하세요:
pip install transformers torch accelerate다음으로, scraper.py 파일에서 Hugging Face의 transformers 라이브러리에서 필요한 클래스를 임포트하세요:
from transformers import AutoModelForCausalLM, AutoTokenizer이제 해당 클래스를 사용하여 토큰화기와 Qwen3 모델을 로드합니다:
model_name = "Qwen/Qwen3-0.6B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)이 예시에서는 Qwen/Qwen3-0.6B 모델을 사용하지만, Hugging Face에서 제공하는 40개 이상의 다른 Qwen3 모델 중에서 선택할 수 있습니다.
훌륭합니다! 이제 Python 스크립트에서 Qwen3을 활용할 모든 준비가 완료되었습니다.
3단계: 대상 페이지의 HTML 가져오기
이제 대상 페이지의 HTML 콘텐츠를 가져올 차례입니다. Requests와 같은 강력한 Python HTTP 클라이언트를 사용하면 됩니다.
가동 중인 가상 환경에서 Requests 라이브러리를 설치하세요:
pip install requests그런 다음 scraper.py 파일에서 라이브러리를 임포트하세요:
import requestsget() 메서드를 사용하여 페이지 URL로 HTTP GET 요청을 전송합니다:
url = "https://www.scrapingcourse.com/ecommerce/product/ajax-full-zip-sweatshirt/"
response = requests.get(url)서버는 페이지의 원시 HTML로 응답합니다. 전체 HTML 콘텐츠를 보려면 response.content를 출력하세요:
print(response.content)결과는 다음과 같은 HTML 문자열이어야 합니다:
<!DOCTYPE html>
<html lang="en-US">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<link rel="profile" href="https://gmpg.org/xfn/11">
<link rel="pingback" href="https://www.scrapingcourse.com/ecommerce/xmlrpc.php">
<!-- 생략... -->
<title>Affirm Water Bottle – 웹 스크래핑 학습용 전자상거래 테스트 사이트</title>
<!-- 생략... -->
</head>
<body>
<!-- 생략... -->
</body>
</html>이제 대상 페이지의 전체 HTML을 Python에서 사용할 수 있습니다. Qwen3을 사용하여 이를 파싱하고 필요한 데이터를 추출해 보겠습니다!
단계 #4: 페이지 HTML을 마크다운으로 변환하기 (선택 사항이지만 권장)
참고: 이 단계는 반드시 필요한 것은 아닙니다. 하지만 로컬 환경에서 상당한 시간을 절약할 수 있으며(유료 Qwen3 제공자를 사용하는 경우 비용도 절감됩니다), 고려해 볼 가치가 충분합니다.
Crawl4AI나 ScrapeGraphAI 같은 다른 AI 기반 웹 스크래핑 도구들이 원시 HTML을 어떻게 처리하는지 살펴보세요. 두 도구 모두 HTML을 마크다운으로 변환한 후 설정된 LLM에 콘텐츠를 전달하는 옵션을 제공한다는 점을 알 수 있을 것입니다.
왜 그럴까요? 두 가지 주요 이유가 있습니다:
- 비용 효율성: 마크다운 변환은 AI로 전송되는 토큰 수를 줄여 비용을 절감합니다.
- 더 빠른 처리: 입력 데이터가 적을수록 계산 비용이 낮아지고 응답 속도가 빨라집니다.
자세한 내용은 새로운 AI 에이전트가 HTML보다 마크다운을 선택하는 이유에 대한 가이드를 참고하세요.
이 경우 Qwen3이 로컬에서 실행되므로, 제3자 LLM 공급자와 연결되지 않았기에 비용 효율성은 중요하지 않습니다. 여기서 진짜 중요한 것은 더 빠른 처리입니다. 왜냐하면 선택한 Qwen3 모델(참고로 사용 가능한 모델 중 작은 편에 속함)에 HTML 페이지 전체를 처리하도록 요청하면 i7 CPU 사용률이 몇 분 동안 100%까지 치솟을 수 있기 때문입니다.
노트북이나 PC가 과열되거나 멈추는 것을 원치 않는다면 이는 지나친 부담입니다. 따라서 마크다운으로 변환하여 입력 크기를 줄이는 것은 완벽한 해결책입니다.
이제 HTML-Markdown 변환 로직을 재현하고 토큰 사용량을 줄일 차례입니다!
먼저, 새 세션을 보장하기 위해 대상 웹페이지를 시크릿 모드로 엽니다. 그런 다음 페이지 아무 곳이나 마우스 오른쪽 버튼으로 클릭하고 “검사”를 선택하여 개발자 도구를 엽니다. 이제 페이지 구조를 살펴보세요. 모든 관련 데이터가 CSS 선택자 #main으로 식별되는 HTML 요소 내에 포함되어 있음을 확인할 수 있습니다:
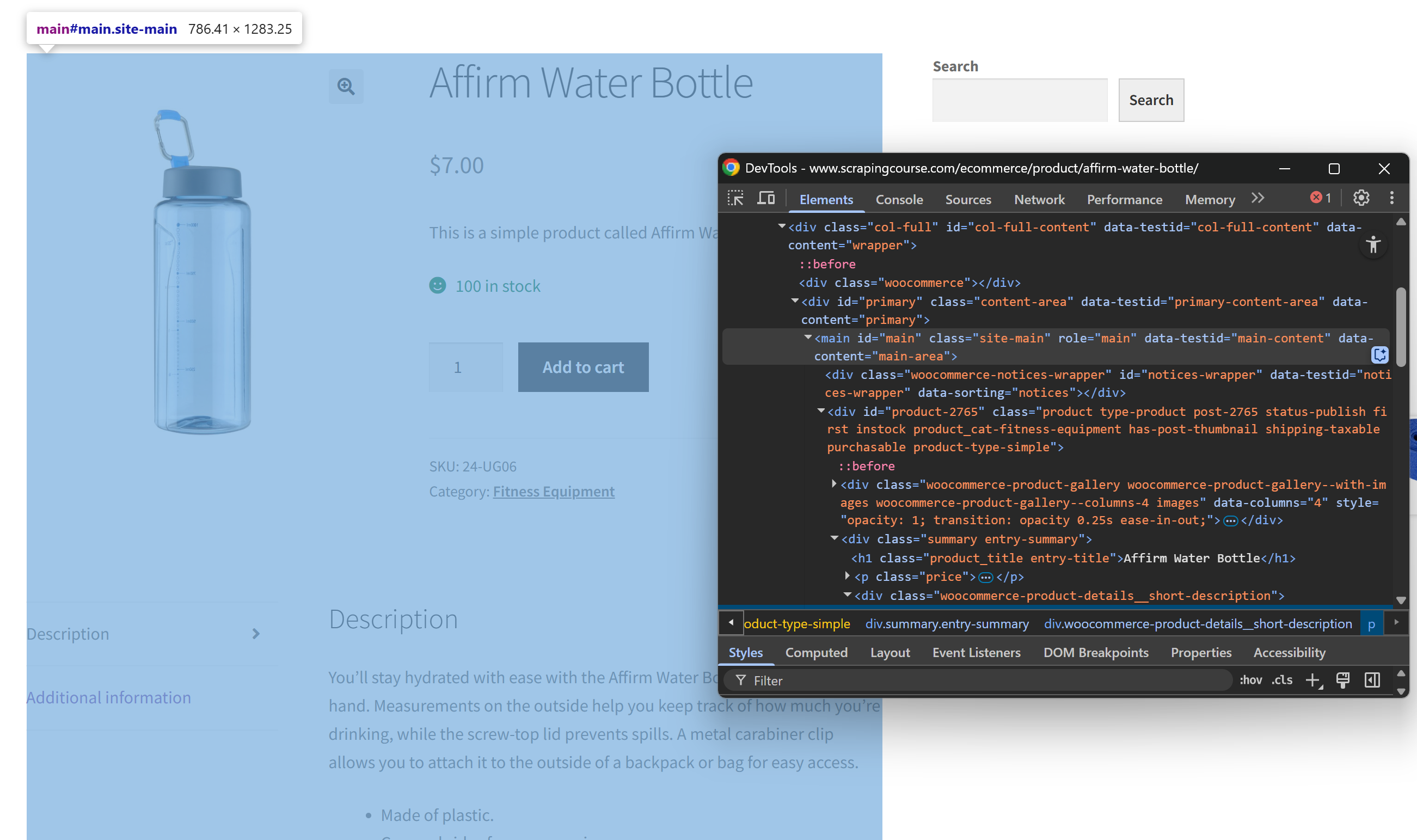
HTML-to-Markdown 변환 과정에서 #main 내부의 콘텐츠에 집중함으로써, 관련 데이터가 포함된 페이지 부분만 추출합니다. 이렇게 하면 헤더, 푸터 및 관심 없는 다른 섹션을 포함하지 않게 됩니다. 이로 인해 최종 Markdown 출력이 훨씬 짧아집니다.
#main 요소 내 HTML만 선택하려면 Beautiful Soup 같은 Python HTML 파싱 라이브러리가 필요합니다. 활성화된 가상 환경에서 다음 명령어로 설치하세요:
pip install beautifulsoup4API 사용법에 익숙하지 않다면 Beautiful Soup 웹 스크래핑 가이드를 참고하세요.
그런 다음 scraper.py에서 다음과 같이 임포트하세요:
from bs4 import BeautifulSoup이제 Beautiful Soup을 사용하여:
- Requests로 가져온 원시 HTML 파싱
#main요소를 선택합니다- 해당 HTML 콘텐츠 추출
위의 세 가지 미세 단계를 다음 스니펫으로 구현합니다:
# BeautifulSoup으로 페이지 HTML 파싱
soup = BeautifulSoup(response.content, "html.parser")
# #main 요소 선택
main_element = soup.select_one("#main")
# 선택된 요소의 외부 HTML 가져오기
main_html = str(main_element)main_html을 출력하면 다음과 같은 결과가 표시됩니다:
<main id="main" class="site-main" role="main" data-testid="main-content" data-content="main-area">
<!-- 생략... -->
<div id="product-2765" class="product type-product post-2765 status-publish first instock product_cat-fitness-equipment has-post-thumbnail shipping-taxable purchasable product-type-simple">
<!-- 생략... -->
</div>
</main>이 문자열은 전체 HTML 페이지보다 훨씬 작지만 여전히 약 13,402자를 포함합니다.
중요한 데이터를 잃지 않으면서 크기를 더 줄이려면 추출한 HTML을 마크다운으로 변환하세요. 먼저 markdownify 라이브러리를 설치합니다:
pip install markdownifyscraper.py에서 markdownify를 임포트하세요:
from markdownify import markdownify그런 다음 #main 부분의 HTML을 마크다운으로 변환합니다:
main_markdown = markdownify(main_html)데이터 변환 과정은 아래와 같은 결과를 생성해야 합니다:
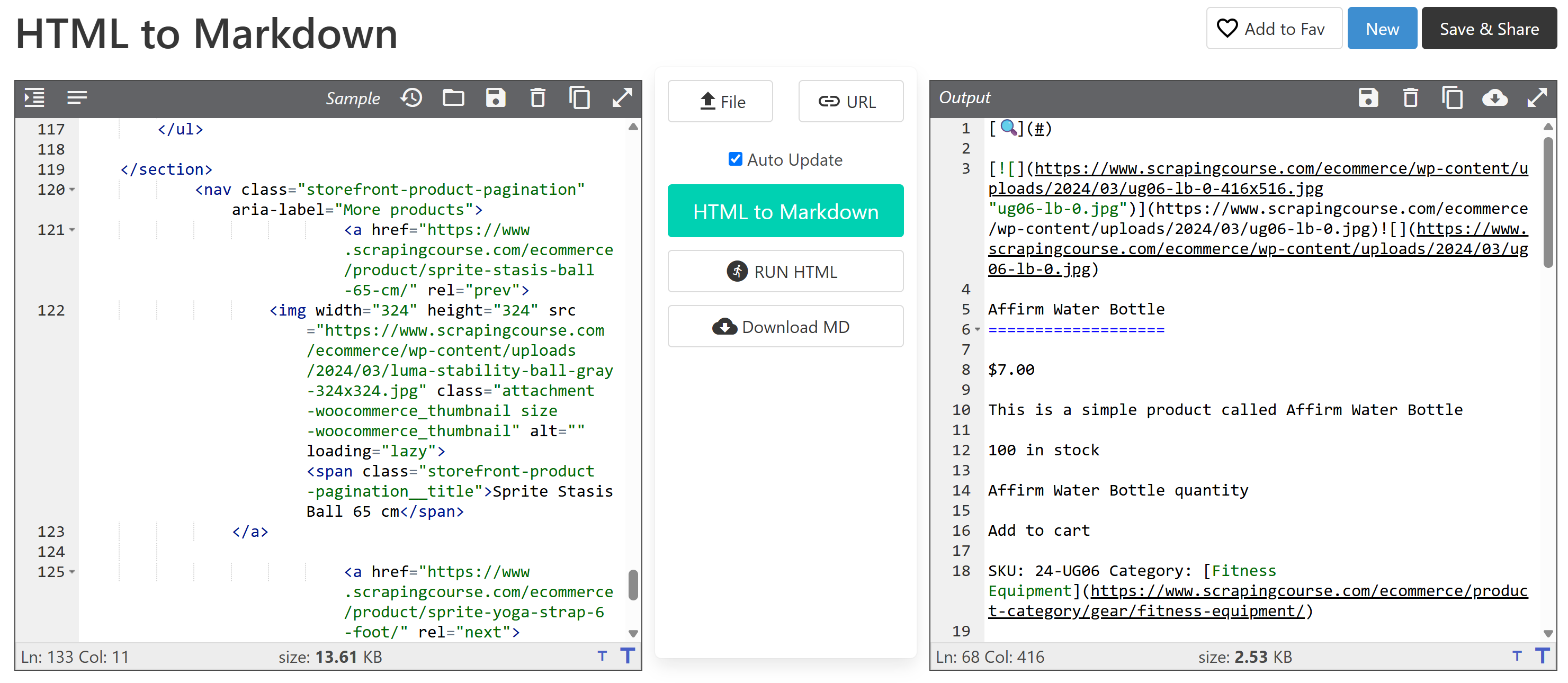
마크다운 버전은 약 2.53KB로, 원본 #main HTML의 13.61KB에 비해 크기가 81% 감소했습니다! 무엇보다 중요한 것은 마크다운 버전이 스크래핑에 필요한 모든 핵심 데이터를 유지한다는 점입니다.
이 간단한 방법으로 부피 큰 HTML 스니펫을 간결한 마크다운 문자열로 축소했습니다. 이는 Qwen3을 통한 로컬 LLM 데이터 파싱 속도를 크게 향상시킬 것입니다!
단계 #5: Qwen3을 활용한 데이터 파싱
Qwen3이 데이터를 정확히 스크래핑하도록 하려면 효과적인 프롬프트를 작성해야 합니다. 먼저 대상 페이지의 구조를 분석하세요:
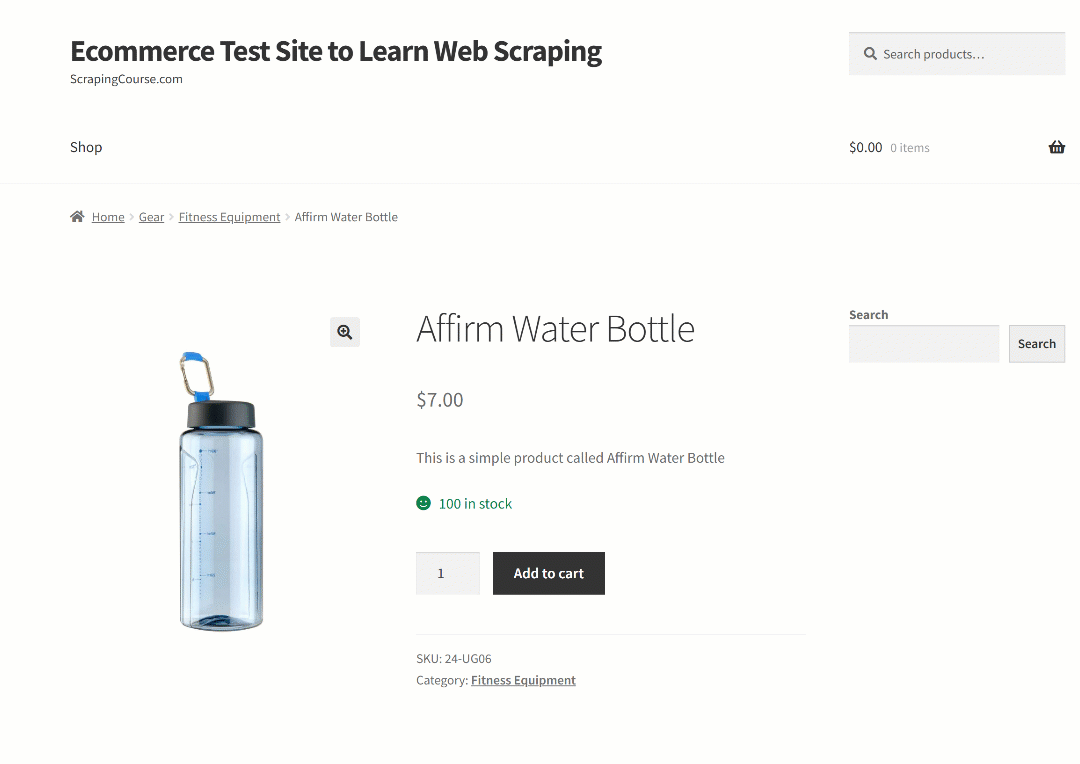
페이지 상단 섹션은 모든 제품에서 동일합니다. 반면 “추가 정보” 테이블은 제품별로 달라집니다. 플랫폼의 모든 제품 페이지에서 프롬프트가 작동하도록 하려면 다음과 같이 일반적인 용어로 작업을 설명할 수 있습니다:
아래 HTML 콘텐츠에서 주요 제품 데이터를 추출하세요. 스크랩된 데이터를 아래와 같은 제품 속성으로 JSON 형식의 원시 문자열로 응답하세요:nn
JSON 속성 예시: n
sku, name, images, price, description, category + "추가 정보" 섹션에서 추출된 필드
콘텐츠:n
<MARKDOWN_PRODUCT_CONTENT>이 프롬프트는 Qwen3에게 main_markdown 콘텐츠에서 구조화된 데이터를 추출하도록 지시합니다. 신뢰할 수 있는 결과를 얻으려면 프롬프트를 가능한 한 명확하고 구체적으로 작성하는 것이 좋습니다. 이는 모델이 정확히 무엇을 기대하는지 이해하는 데 도움이 됩니다.
이제 공식 문서에 설명된 대로 Hugging Face를 사용하여 프롬프트를 실행하세요:
# 데이터 추출 프롬프트 정의
prompt = f"""아래 HTML 콘텐츠에서 주요 제품 데이터를 추출하세요. 추출된 데이터를 아래와 같은 제품 속성 JSON 형식의 원시 문자열로 응답하세요:nn
샘플 JSON 속성: n
sku, name, images, price, description, category + "추가 정보" 섹션에서 추출된 필드
콘텐츠:n
{main_markdown}
"""
# 프롬프트 실행
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# 텍스트 형식으로 출력값 가져오기
product_raw_string = tokenizer.decode(output_ids, skip_special_tokens=True).strip("n")위 코드는 apply_chat_template() 을 사용하여 입력 메시지를 형식화하고 구성된 Qwen3 모델로부터 응답을 생성합니다.
참고: 핵심 세부 사항은 apply_chat_template()에서 enable_thinking=False를 설정하는 것입니다. 기본적으로 이 옵션은 True로 설정되어 모델의 내부 “추론” 모드를 활성화합니다. 이 기능은 복잡한 문제 해결에는 유용하지만 웹 스크래핑과 같은 단순한 작업에는 불필요하고 오히려 역효과를 낼 수 있습니다. 이를 비활성화하면 모델이 설명이나 가정을 추가하지 않고 순수하게 추출에만 집중하도록 보장합니다.
훌륭합니다! 방금 Qwen3에게 대상 페이지의 웹 스크래핑을 수행하도록 지시했습니다.
이제 남은 작업은 출력을 조정하고 JSON으로 내보내는 것입니다.
6단계: Qwen3 출력 변환
Qwen3-0.6B 모델이 생성하는 출력은 실행마다 약간씩 다를 수 있습니다. 이는 대규모 언어 모델(LLM), 특히 여기서 사용한 것과 같은 소규모 모델의 일반적인 특성입니다.
따라서 변수 product_raw_string이 원하는 데이터를 일반 JSON 문자열로 포함하는 경우도 있지만, 다음과 같이 JSON을 마크다운 코드 블록 안에 감싸는 경우도 있습니다:
```jsonn{n "sku": "24-UG06",n "name": "Affirm Water Bottle",n "images": ["https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/ug06-lb-0.jpg"],n "price": "$7.00",n "description": "Affirm 물병을 곁에 두거나 손에 들고 있으면 수분 보충이 쉬워집니다. 외부의 눈금으로 섭취량을 확인하기 쉽고, 나사식 뚜껑으로 흘림을 방지합니다. 금속 카라비너 클립으로 백팩이나 가방 외부에 부착해 편리하게 사용할 수 있습니다.",n "category": "피트니스 장비",n "추가 정보": {n "활동": "요가, 레크리에이션, 스포츠, 체육관",n "성별": "남성, 여성, 소년, 소녀, 유니섹스",n "재질": "플라스틱"n }n}n```두 경우 모두 처리하려면 정규 표현식을 사용해 마크다운 블록 내부에 JSON 콘텐츠가 나타날 때 이를 추출할 수 있습니다. 그렇지 않으면 문자열을 원시 JSON으로 처리하세요. 그런 다음 결과 JSON 데이터를 파이썬 사전 json.loads()로 파싱할 수 있습니다:
# 문자열에 "```json"이 포함되어 있는지 확인하고 존재할 경우 원시 JSON 추출
match = re.search(r'```jsonn(.*?)n```', product_raw_string, re.DOTALL)
if match:
# 일치하는 그룹에서 JSON 문자열 추출
json_string = match.group(1)
else:
# 반환된 데이터가 이미 JSON 형식이라고 가정
json_string = product_raw_string
# 추출된 JSON 문자열을 Python 사전으로 파싱
product_data = json.loads(json_string)자, 이제 시작입니다! 이 시점에서 스크랩한 데이터를 사용 가능한 Python 객체로 파싱했습니다. 마지막 단계는 스크랩한 데이터를 더 사용자 친화적인 형식으로 내보내는 것입니다.
7단계: 스크랩한 데이터 내보내기
이제 제품 데이터를 Python 사전으로 확보했으므로 다음과 같이 JSON 파일로 저장할 수 있습니다:
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product_data, json_file, indent=4)이렇게 하면 구조화된 제품 데이터가 담긴 product.json 파일이 생성됩니다.
잘하셨습니다! Qwen3 웹 스크래퍼가 완성되었습니다.
8단계: 모든 것을 통합하기
다음은 scraper.py Qwen3 스크래핑 스크립트의 최종 코드입니다:
from transformers import AutoModelForCausalLM, AutoTokenizer
import requests
from bs4 import BeautifulSoup
from markdownify import markdownify
import json
import re
# 웹 스크래핑에 사용할 Qwen3 모델
model_name = "Qwen/Qwen3-0.6B"
# 토큰화기 및 Qwen3 모델 로드
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# 대상 페이지의 HTML 콘텐츠 가져오기
url = "https://www.scrapingcourse.com/ecommerce/product/affirm-water-bottle/"
response = requests.get(url)
# BeautifulSoup으로 대상 페이지 HTML 파싱
soup = BeautifulSoup(response.content, "html.parser")
# #main 요소 선택
main_element = soup.select_one("#main")
# 선택된 요소의 외부 HTML 가져와 Markdown으로 변환
main_html = str(main_element)
main_markdown = markdownify(main_html)
# 데이터 추출 프롬프트 정의
prompt = f"""아래 HTML 콘텐츠에서 주요 제품 데이터를 추출하세요. 추출된 데이터를 아래와 같은 JSON 형식의 원시 문자열로 응답하십시오:nn
샘플 JSON 속성:n
sku, name, images, price, description, category + "추가 정보" 섹션에서 추출된 필드
콘텐츠:n
{main_markdown}
"""
# 프롬프트 실행
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# 텍스트 형식으로 출력값 가져오기
product_raw_string = tokenizer.decode(output_ids, skip_special_tokens=True).strip("n")
# 문자열에 "```json" 포함 여부 확인 및 존재 시 원시 JSON 추출
match = re.search(r'```jsonn(.*?)n```', product_raw_string, re.DOTALL)
if match:
# 일치하는 그룹에서 JSON 문자열 추출
json_string = match.group(1)
else:
# 반환된 데이터가 이미 JSON 형식이라고 가정
json_string = product_raw_string
# 추출된 JSON 문자열을 Python 사전으로 파싱
product_data = json.loads(json_string)
# 스크랩한 데이터를 JSON으로 내보내기
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product_data, json_file, indent=4)스크립트 실행 방법:
python scraper.py스크립트를 처음 실행하면 Hugging Face에서 선택한 Qwen3 모델을 자동으로 다운로드합니다. 이 모델은 약 1.5GB 크기이므로 인터넷 속도에 따라 다운로드 시간이 다소 소요될 수 있습니다. 터미널에는 다음과 같은 출력이 표시됩니다:
model.safetensors: 100%|██████████████████████████████████████████████████████████| 1.50G/1.50G [00:49<00:00, 30.2MB/s]
generation_config.json: 100%|█████████████████████████████████████████████████████████████████| 239/239 [00:00<?, ?B/s]스크립트 완료에는 시간이 다소 소요될 수 있습니다. PyTorch가 모델을 로드하고 실행하는 과정에서 CPU에 부하가 발생하기 때문입니다.
스크립트가 완료되면 프로젝트 폴더에 product.json이라는 파일이 생성됩니다. 이 파일을 열면 다음과 같은 구조화된 제품 데이터를 확인할 수 있습니다:
{
"sku": "24-UG06",
"name": "Affirm Water Bottle",
"images": [
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/ug06-lb-0.jpg"
],
"price": "$7.00",
"description": "Affirm 물병을 옆에 두거나 손에 들고 다니면 수분 보충이 간편해집니다. 외부에 표시된 눈금으로 섭취량을 쉽게 확인할 수 있으며, 나사식 뚜껑이 내용물 유출을 방지합니다. 금속 카라비너 클립으로 백팩이나 가방 외부에 부착해 쉽게 꺼낼 수 있습니다.",
"category": "Fitness Equipment",
"additional_information": {
"Activity": "Yoga, Recreation, Sports, Gym",
"Gender": "Men, Women, Boys, Girls, Unisex",
"Material": "Plastic"
}
}참고: LLM의 특성상 스크랩된 콘텐츠를 다르게 구조화할 수 있으므로 정확한 출력 결과는 약간 다를 수 있습니다.
자, 이제 스크립트가 원시 HTML 콘텐츠를 깔끔하고 구조화된 JSON으로 변환했습니다. Qwen3 웹 스크래핑 덕분입니다.
이 웹 스크래핑 접근법의 주요 한계 극복하기
물론, 우리의 예시에서는 모든 것이 원활하게 작동했습니다. 하지만 이는 해당 목적을 위해 특별히 구축된 데모 사이트를 스크래핑했기 때문입니다.
현실 세계에서는 대부분의 웹사이트가 공개 데이터의 가치를 잘 알고 있습니다. 따라서 requests 같은 도구로 자동화된 HTTP 요청을 차단하는 반스크래핑 기술을 자주 구현합니다.
게다가 이 접근법은 자바스크립트 중심 사이트에서는 작동하지 않습니다. requests와 BeautifulSoup의 조합은 정적 페이지에는 효과적이지만 동적 콘텐츠를 처리할 수 없기 때문입니다. 차이점이 낯설다면 정적 콘텐츠와 동적 콘텐츠 비교 글을 참고하세요.
다른 잠재적 차단 요소로는 IP 차단, 속도 제한기, TLS 지문 인식, CAPTCHA 등이 있습니다. 요컨대 웹 스크래핑은 쉽지 않습니다—특히 대부분의 웹사이트가 AI 크롤러와 봇을 탐지하고 차단할 수 있는 장비를 갖추고 있는 지금은 더욱 그렇습니다.
해결책은 요청(requests)을 활용한 현대적 웹 스크래핑을 위해 설계된 웹 언락커(Web Unlocker) API를 사용하는 것입니다. 이러한 서비스는 IP 회전, CAPTCHA 해결, 자바스크립트 렌더링, 봇 보호 우회 등 모든 어려운 작업을 대신 처리해 줍니다.
사용자가 해야 할 일은 대상 페이지의 URL을 웹 언락커 API 엔드포인트에 전달하는 것뿐입니다. 해당 API는 페이지가 자바스크립트에 의존하거나 고급 봇 방지 시스템으로 보호되는 경우에도 완전히 언락된 HTML을 반환합니다.
스크립트에 통합하려면 3단계의 requests.get() 라인을 다음 코드로 교체하세요:
WEB_UNLOCKER_API_KEY = "<YOUR_WEB_UNLOCKER_API_KEY>"
# 인증 헤더 설정
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {WEB_UNLOCKER_API_KEY}"
}
# 대상 URL을 포함한 페이로드 정의
payload = {
"zone": "unblocker",
"url": "https://www.scrapingcourse.com/ecommerce/product/affirm-water-bottle/", # 다른 스크래핑 시나리오에서는 대상 URL로 대체
"format": "raw"
}
# 요청 전송
response = requests.post("https://api.brightdata.com/request", json=payload, headers=headers)
# 잠금 해제된 HTML 가져오기
html_content = response.text자세한 내용은 공식 Web Unlocker 문서를 참조하세요.
웹 언락커를 활용하면 Qwen3으로 어떤 웹사이트에서든 구조화된 데이터를 자신 있게 추출할 수 있습니다. 더 이상 차단, 렌더링 문제, 누락된 콘텐츠에 대한 걱정은 없습니다.
웹 스크래핑을 위한 Qwen3 대안
자동화된 웹 데이터 파싱에 활용할 수 있는 대규모 언어 모델(LLM)은 Qwen3만이 아닙니다. 다음 가이드에서 대체 접근법을 살펴보세요:
- Gemini를 활용한 웹 스크래핑: 완전한 튜토리얼
- Perplexity를 이용한 웹 스크래핑: 단계별 가이드
- ScrapeGraphAI를 활용한 LLM 웹 스크래핑
- Crawl4AI와 DeepSeek로 AI 스크레이퍼 구축하기
- LLaMA 3를 활용한 웹 스크래핑: 모든 웹사이트를 구조화된 JSON으로 변환하기
결론
이 튜토리얼에서는 Hugging Face를 사용하여 Qwen3을 로컬에서 실행하고 AI 기반 웹 스크레이퍼를 구축하는 방법을 배웠습니다. 웹 스크레이핑에서 가장 큰 장애물 중 하나는 차단되는 것이지만, Bright Data의 Web Unlocker API를 사용하여 해결했습니다.
앞서 다룬 바와 같이, Qwen3과 Web Unlocker API를 결합하면 사실상 모든 웹사이트에서 데이터를 추출할 수 있습니다. 맞춤형 파싱 로직 없이도 가능합니다. 이 설정은 Bright Data 인프라가 가능하게 하는 수많은 강력한 사용 사례 중 하나를 보여줍니다. 확장 가능한 AI 기반 웹 데이터 파이프라인 구축을 지원합니다.
그렇다면 여기서 멈출 이유가 있을까요? 120개 이상의 인기 웹사이트에서 최신, 구조화되고 완전히 규정을 준수하는 웹 데이터를 추출하기 위한 전용 엔드포인트인 웹 스크레이퍼 API를살펴보세요.
지금 바로 Bright Data 무료 계정에 가입하고 AI 지원 스크래핑 솔루션으로 구축을 시작하세요!




