

이 가이드에서는 다음을 배울 수 있습니다:
- Scrapy란 무엇인가
- Playwright란 무엇인가
- 웹 스크래핑을 위한 기능 및 비교 분석
- 두 도구를 활용한 웹 스크래핑 입문
- Playwright로 스크레이퍼 구축 방법
- Scrapy로 웹 스크래핑 스크립트 구축 방법
- 웹 스크래핑에 더 적합한 도구는 무엇인가
- 공통적인 한계점과 이를 극복하는 방법
자, 시작해 보겠습니다!
Scrapy란 무엇인가?
Scrapy는 효율적인 데이터 추출을 위해 개발된 Python 기반 오픈소스 웹 스크래핑 프레임워크입니다. 병렬 요청, 링크 추적, JSON 및 CSV 형식의 데이터 내보내기 등의 기능을 기본 지원합니다. 또한 미들웨어, 프록시 통합, 자동 요청 재시도 기능을 갖추고 있습니다. Scrapy는 비동기 방식으로 작동하며 정적 HTML 페이지에서 작동합니다.
Playwright란?
Playwright는 브라우저 내 E2E 테스트 및 웹 스크래핑을 위한 오픈소스 자동화 프레임워크입니다. Chrome, Firefox, WebKit 등 다양한 브라우저를 헤드드 모드와 헤드리스 모드 모두에서 지원합니다. 또한 TypeScript/JavaScript, Python, Java, C# 등 여러 프로그래밍 언어로 브라우저 자동화 API를 제공합니다.
Scrapy vs Playwright: 웹 스크래핑을 위한 직접 비교 기능
Scrapy와 Playwright가 훌륭한 웹 스크래핑 도구로 자리매김하는 데 기여하는 다섯 가지 측면을 비교해 보겠습니다.
다른 직접 비교 블로그 글은 다음을 참조하세요:
- Scrapy vs. Beautiful Soup
- Scrapy vs Pyspider: 웹 스크래핑에 더 적합한 도구는?
- 웹 스크래핑을 위한 Scrapy vs Selenium
- 웹 스크래핑을 위한 Scrapy vs. Puppeteer
- Scrapy vs. Requests: 웹 스크래핑에 더 적합한 도구는?
이제 Scrapy와 Playwright의 비교를 시작해 보겠습니다!
설정 및 구성의 용이성
Scrapy는 최소한의 설정만으로 간편한 설치를 제공합니다. 내장된 CLI 덕분에 프로젝트 생성, 스파이더 정의, 데이터 내보내기를 빠르게 수행할 수 있습니다. 반면 Playwright는 브라우저 종속성 설치 및 올바른 설정 확인이 필요하여 더 많은 설정이 필요합니다.
학습 곡선
모듈식 구조, 방대한 기능, 독특한 구성 방식 때문에 초보자에게 Scrapy의 학습 곡선은 가파릅니다. 스파이더, 미들웨어, 파이프라인 같은 개념을 이해하는 데 시간이 걸릴 수 있습니다. Playwright는 브라우저 자동화 지식이 있는 사람에게 익숙한 API를 제공하므로 시작하기 훨씬 쉽습니다.
동적 콘텐츠 처리
Scrapy는 정적 HTML 문서만 처리할 수 있기 때문에 JavaScript를 사용하는 웹사이트에는 취약합니다. 동적 콘텐츠 처리는 가능하지만 Splash 또는 유사 도구와의 통합이 필요합니다. Playwright는 브라우저 내에서 페이지를 기본적으로 렌더링하기 때문에 동적 또는 JavaScript로 렌더링된 콘텐츠 처리에 탁월합니다. 즉, React, Angular, Vue와 같은 클라이언트 프레임워크에 의존하는 페이지도 스크래핑할 수 있습니다.
사용자 정의 및 확장성
Scrapy는 미들웨어, 확장 기능, 파이프라인 지원을 통해 높은 수준의 커스터마이징 옵션을 제공합니다. 또한 다양한 플러그인과 애드온을 사용할 수 있습니다. 반면 Playwright는 기본적으로 확장성이 없습니다. 다행히 커뮤니티가 Playwright Extra 프로젝트를 통해 이 한계를 해결했습니다.
기타 스크래핑 기능
Scrapy는 프록시 통합, 자동 재시도, 구성 가능한 데이터 내보내기 같은 내장 기능을 제공합니다. IP 로테이션 및 기타 고급 시나리오를 위한 통합 방법도 지원합니다. Playwright도 프록시 통합 및 기타 핵심 스크래핑 기능을 지원하지만, 동일한 결과를 얻으려면 Scrapy에 비해 더 많은 수동 작업이 필요합니다.
Playwright vs Scrapy: 스크래핑 스크립트 비교
다음 두 섹션에서는 Playwright와 Scrapy를 사용하여 동일한 사이트를 스크래핑하는 방법을 알아봅니다. Playwright는 Scrapy처럼 웹 스크래핑에 특화되지 않아 시간이 다소 더 소요될 수 있으므로 Playwright부터 시작하겠습니다.
대상 사이트는 Books to Scrape 스크래핑 샌드박스입니다:
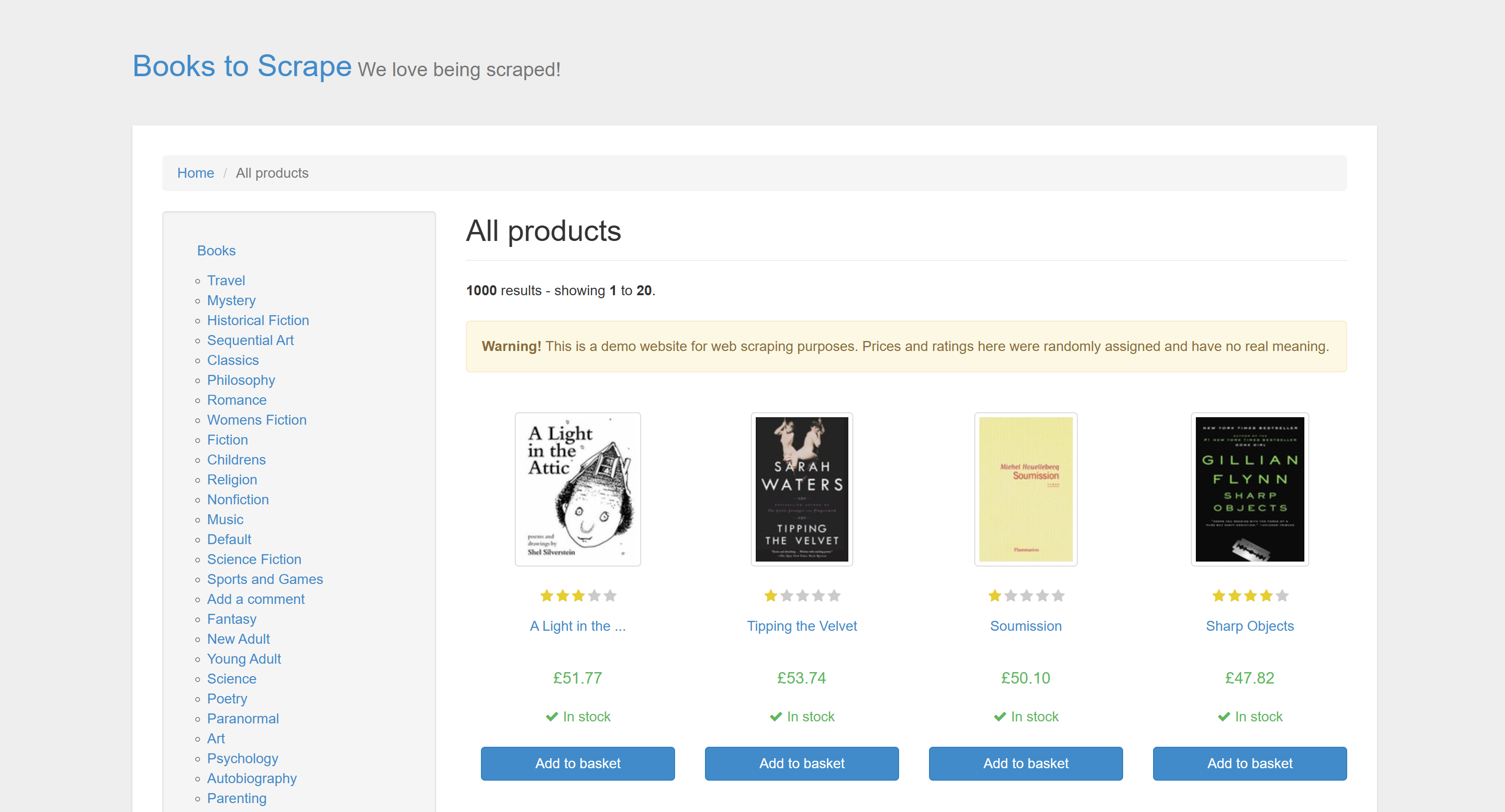
두 스크레이퍼의 목표는 사이트에서 판타지 장르의 모든 책을 추출하는 것이며, 이를 위해서는 페이지네이션 처리가 필요합니다.
Scrapy는 페이지를 정적 콘텐츠로 간주하고 HTML 문서를 직접 파싱합니다. 반면 Playwright는 브라우저에서 페이지를 렌더링하고 페이지 내 요소와 상호작용하며 사용자 동작을 시뮬레이션합니다.
Scrapy 스크립트는 Python으로 작성되며, Playwright 스크립트는 JavaScript로 작성됩니다. 두 도구 모두 주로 지원하는 두 언어입니다. 그러나 동일한 기본 API를 노출하는 playwright-python 라이브러리를 사용하면 Playwright JavaScript 스크립트를 Python으로 쉽게 변환할 수 있습니다.
두 경우 모두 스크립트 마지막에는 Books to Scrape의 모든 판타지 도서 정보가 담긴 CSV 파일이 생성됩니다.
이제 Playwright와 Scrapy의 스크래핑 비교를 살펴보겠습니다!
웹 스크래핑에 Playwright 사용 방법
Playwright를 사용하여 JavaScript로 간단한 웹 스크래핑 스크립트를 작성하려면 아래 단계를 따르세요. 이 과정에 익숙하지 않다면 먼저 Playwright 웹 스크래핑 가이드를 읽어보세요.
1단계: 프로젝트 설정
시작하기 전에 로컬에 최신 버전의 Node.js가 설치되어 있는지 확인하세요. 설치되어 있지 않다면 다운로드하여 설치 마법사를 따라 설치하세요.
다음으로 Playwright 스크레이퍼용 폴더를 생성하고 터미널에서 해당 폴더로 이동하세요:
mkdir playwright-scraper
cd playwright-scraperplaywright-scraper 폴더 내에서 다음 명령을 실행하여 npm 프로젝트를 초기화하세요:
npm init -y이제 선호하는 JavaScript IDE(예: IntelliJ IDEA 또는 Visual Studio Code )에서 playwright-scraper 폴더를 엽니다. 폴더 내부에 스크래핑 로직을 담을 script.js 파일을 생성하세요:
잘하셨습니다! 이제 Playwright를 사용한 Node.js 웹 스크래핑 환경이 완전히 준비되었습니다.
2단계: Playwright 설치 및 구성
프로젝트 폴더에서 다음 명령어를 실행하여 Playwright를 설치하세요:
npm install playwright다음으로 브라우저와 추가 종속성을 설치하려면 다음을 실행하세요:
npx playwright install이제 script.js 파일을 열고 Playwright를 임포트하고 Chromium 브라우저 인스턴스를 실행하는 다음 코드를 추가하세요:
const { chromium } = require("playwright");
(async () => {
// 크로미움 브라우저 초기화
const browser = await chromium.launch({
headless: false, // 프로덕션 환경에서는 주석 처리
});
// 스크래핑 로직을 여기에 작성...
// 브라우저 닫기 및 리소스 해제
await browser.close();
})();headless: false 옵션은 헤더드 모드로 브라우저를 실행합니다. 이를 통해 스크립트의 동작을 확인할 수 있어 개발 중 디버깅에 유용합니다.
3단계: 대상 페이지에 연결하기
브라우저에서 새 페이지를 초기화하고 goto() 함수를 사용하여 대상 페이지로 이동합니다:
const page = await browser.newPage();
await page.goto("https://books.toscrape.com/catalogue/category/books/fantasy_19/index.html");close() 함수 앞에 중단점을 설정하고 디버거에서 스크립트를 실행하면 브라우저가 열리고 대상 페이지로 이동하는 것을 확인할 수 있습니다:
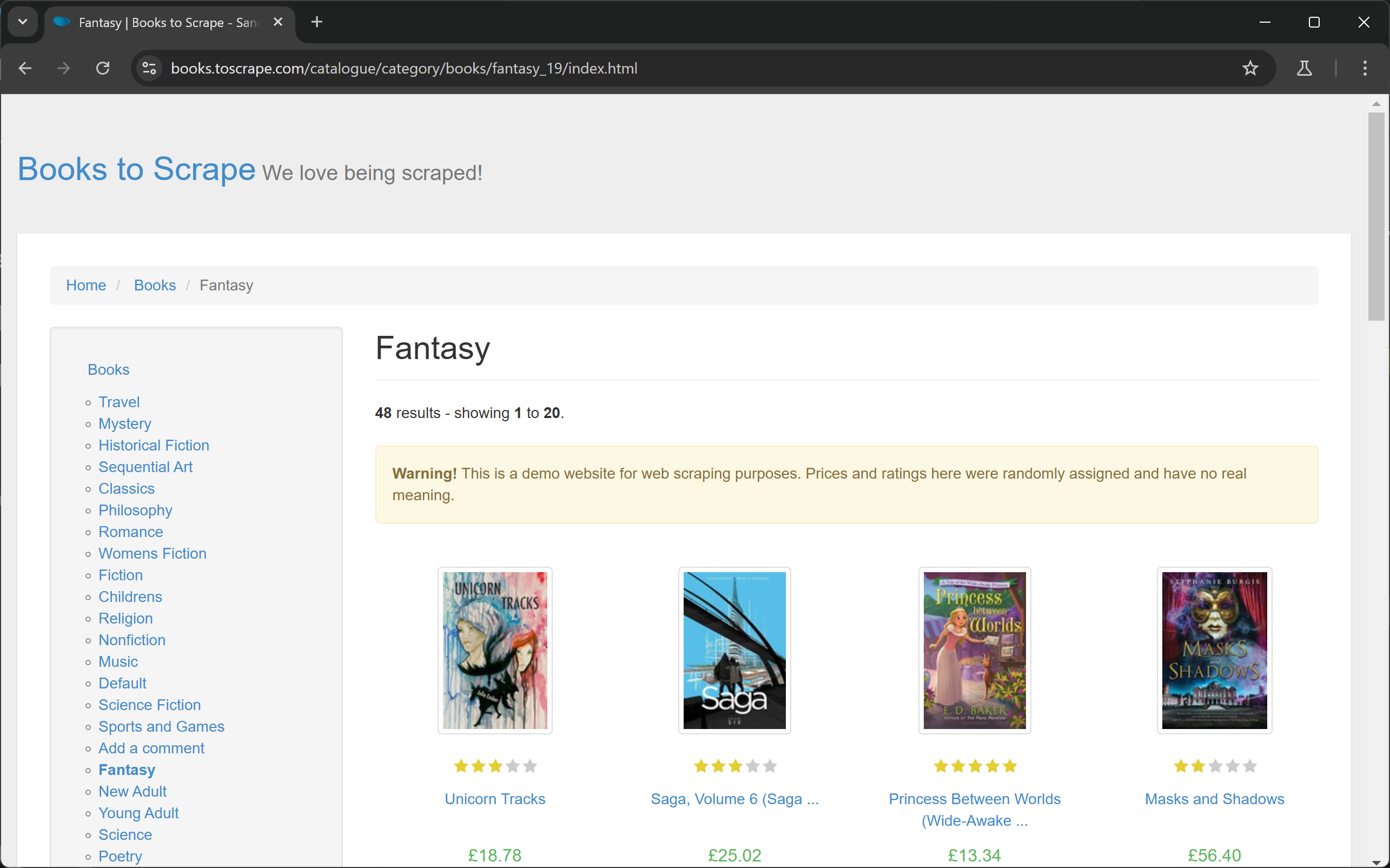
대단하네요! Playwright가 예상대로 브라우저를 제어하고 있습니다.
4단계: 데이터 파싱 로직 구현
스크래핑 로직을 작성하기 전에 페이지 구조를 이해해야 합니다. 이를 위해 브라우저의 시크릿 창에서 대상 사이트를 엽니다. 그런 다음 책 요소(book element)를 마우스 오른쪽 버튼으로 클릭하고 “검사(Inspect)” 옵션을 선택합니다.
개발자 도구에서 다음과 같은 내용을 확인해야 합니다:
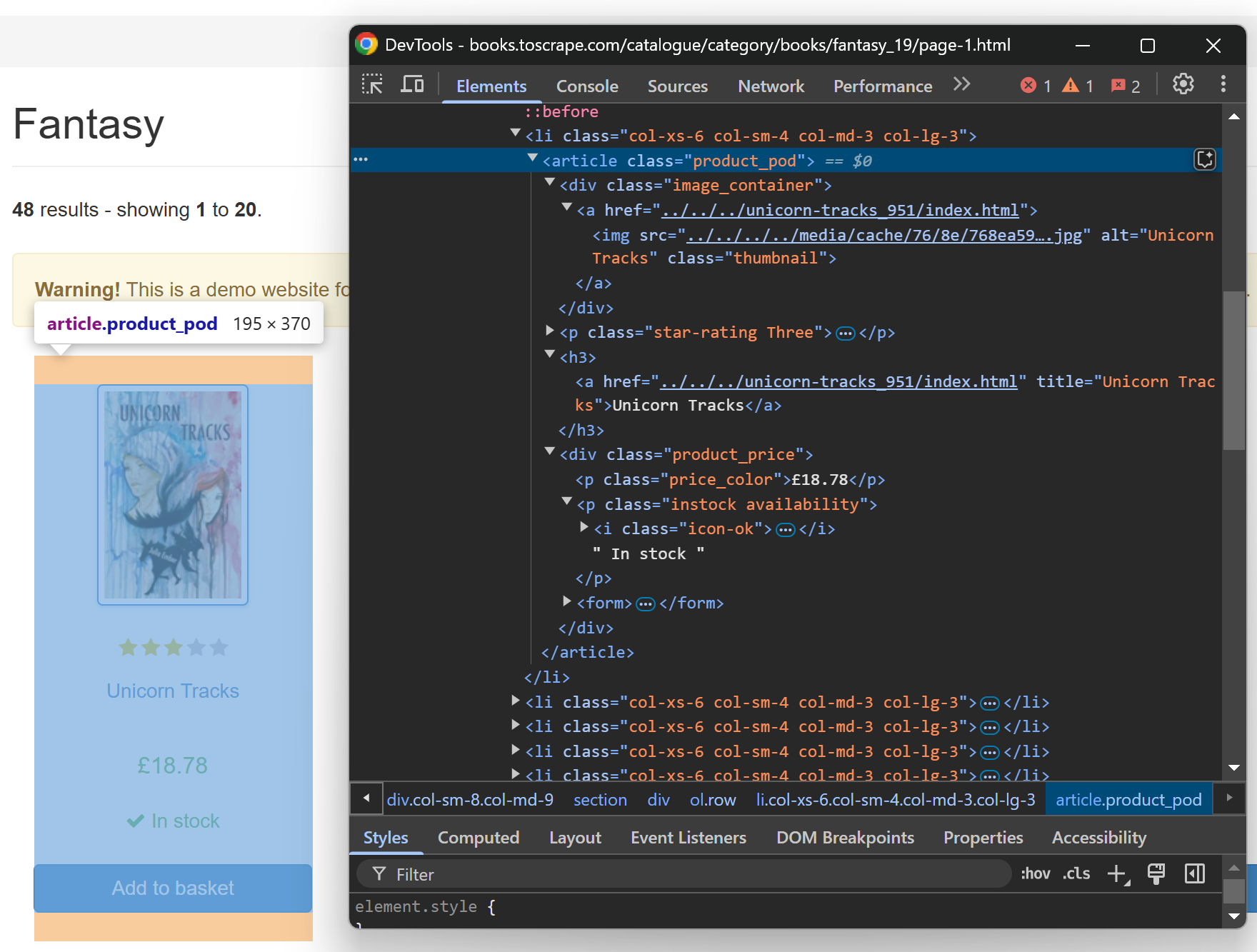
위에서 각 책 요소는 .product_pod CSS 선택자로 선택할 수 있음을 알 수 있습니다.
페이지에 여러 책이 포함되어 있으므로, 먼저 스크래핑된 데이터를 저장할 배열을 초기화합니다:
books = []모든 책을 선택하고 아래와 같이 반복 처리합니다:
const bookElements = await page.locator(".product_pod").all();
for (const bookElement of bookElements) {
// 책 상세 정보 추출...
}위 이미지에서 볼 수 있듯이 각 책 요소에서 다음을 추출할 수 있습니다:
<a>태그에서 책 URLh3 a노드에서 책 제목.thumbnail요소에서 책 이미지.star-rating요소에서 책 평점.product_price .price_color요소에서 상품 가격.availability요소에서 가져온 제품 재고 상태
이제 루프 내에서 스크래핑 로직을 구현합니다:
const urlElement = await bookElement.locator("a").first();
const url = makeAbsoluteURL(
await urlElement.getAttribute("href"),
"https://books.toscrape.com/catalogue/"
);
const titleElement = await bookElement.locator("h3 a");
const title = await titleElement.getAttribute("title");
const imageElement = await bookElement.locator(".thumbnail");
const image = makeAbsoluteURL(
await imageElement.getAttribute("src"),
"https://books.toscrape.com/"
);
const ratingElement = await bookElement.locator(".star-rating");
const ratingClass = await ratingElement.getAttribute("class");
let rating;
switch (true) {
case ratingClass.includes("One"):
rating = 1;
break;
case ratingClass.includes("Two"):
rating = 2;
break;
case ratingClass.includes("Three"):
rating = 3;
break;
case ratingClass.includes("Four"):
rating = 4;
break;
case ratingClass.includes("Five"):
rating = 5;
break;
default:
rating = null;
}
const priceElement = await bookElement.locator(
".product_price .price_color"
);
const price = (await priceElement.textContent()).trim();
const availabilityElement = await bookElement.locator(".availability");
const availability = (await availabilityElement.textContent()).trim();위의 코드 조각은 getAttribute() 및 textContent() Playwright 함수를 사용하여 각각 HTML 노드에서 특정 HTML 속성과 텍스트를 추출합니다. 평점 점수를 가져오는 사용자 정의 로직에 유의하십시오.
또한 페이지의 URL이 상대 경로이므로 다음 사용자 정의 함수를 사용하여 절대 URL로 변환할 수 있습니다:
function makeAbsoluteURL(url, baseURL) {
// 정규 표현식을 사용하여 ../ 또는 ../../ 패턴 제거
const cleanURL = url.replace(/(../)+/, "");
// 기본 URL과 정리된 상대 URL 결합
return baseURL + cleanURL;
}다음으로, 스크랩한 데이터로 새 객체를 채우고 books 배열에 추가합니다:
const book = {
"url": url,
"title": title,
"image": image,
"rating": rating,
"price": price,
"availability": availability,
};
books.push(book);완벽합니다! Playwright 스크래핑 로직이 이제 완성되었습니다.
4단계: 크롤링 로직 구현
대상 사이트를 살펴보면 일부 페이지 하단에 “다음” 버튼이 있음을 알 수 있습니다:
이 버튼을 클릭하면 다음 페이지가 로드됩니다. 마지막 페이지네이션 페이지에는 당연히 해당 버튼이 없습니다.
따라서 while (true) 루프를 사용해 웹 크롤링 로직을 구현할 수 있습니다:
- 현재 페이지의 데이터를 스크래핑하고
- “다음” 버튼이 존재할 경우 클릭하고 새 페이지 로딩을 기다림
- “다음” 버튼이 더 이상 존재하지 않을 때까지 이 과정을 반복합니다
구현 방법은 다음과 같습니다:
while (true) {
// 책 요소 선택 ...
// "다음" 버튼 선택 및 페이지 존재 여부 확인
const nextElement = await page.locator("li.next a");
if ((await nextElement.count()) !== 0) {
// "다음" 버튼 클릭 후 다음 페이지로 이동
await nextElement.click();
// 페이지 로드 완료 대기
await page.waitForLoadState("domcontentloaded")
} else {
break;
}
}훌륭합니다! 크롤링 로직 구현 완료.
5단계: CSV로 내보내기
마지막 단계는 스크랩한 데이터를 CSV 파일로 내보내는 것입니다. 기본 Node.js로도 가능하지만, fast-csv 같은 전용 라이브러리를 사용하면 훨씬 쉽습니다.
다음 명령어로 fast-csv 패키지를 설치하세요:
npm install fast-csvscraping.js 파일 시작 부분에서 필요한 모듈을 임포트하세요:
const { writeToPath } = require("fast-csv");다음으로, 스크랩한 데이터를 CSV 파일에 기록하려면 다음 코드 조각을 사용하세요:
writeToPath("books.csv", books, { headers: true });자, 이제 Playwright 웹 스크래핑 스크립트가 준비되었습니다.
6단계: 모든 것을 통합하기
script.js 파일에는 다음 내용이 포함되어야 합니다:
const { chromium } = require("playwright");
const { writeToPath } = require("fast-csv");
(async () => {
// 크로미움 브라우저 초기화
const browser = await chromium.launch({
headless: false, // 실제 운영 시 주석 처리
});
// 브라우저에 새 페이지 초기화
const page = await browser.newPage();
// 대상 페이지 방문
await page.goto(
"https://books.toscrape.com/catalogue/category/books/fantasy_19/index.html"
);
// 스크래핑된 데이터 저장 위치
books = [];
while (true) {
// 책 요소 선택
const bookElements = await page.locator(".product_pod").all();
// 데이터 추출을 위해 반복 처리
for (const bookElement of bookElements) {
// 데이터 추출 로직
const urlElement = await bookElement.locator("a").first();
const url = makeAbsoluteURL(
await urlElement.getAttribute("href"),
"https://books.toscrape.com/catalogue/"
);
const titleElement = await bookElement.locator("h3 a");
const title = await titleElement.getAttribute("title");
const imageElement = await bookElement.locator(".thumbnail");
const image = makeAbsoluteURL(
await imageElement.getAttribute("src"),
"https://books.toscrape.com/"
);
const ratingElement = await bookElement.locator(".star-rating");
const ratingClass = await ratingElement.getAttribute("class");
let rating;
switch (true) {
case ratingClass.includes("One"):
rating = 1;
break;
case ratingClass.includes("Two"):
rating = 2;
break;
case ratingClass.includes("Three"):
rating = 3;
break;
case ratingClass.includes("Four"):
rating = 4;
break;
case ratingClass.includes("Five"):
rating = 5;
break;
default:
rating = null;
}
const priceElement = await bookElement.locator(
".product_price .price_color"
);
const price = (await priceElement.textContent()).trim();
const availabilityElement = await bookElement.locator(".availability");
const availability = (await availabilityElement.textContent()).trim();
// 스크랩한 데이터로 새 책 항목을 생성하고
// 배열에 추가
const book = {
"url": url,
"title": title,
"image": image,
"rating": rating,
"price": price,
"availability": availability,
};
books.push(book);
}
// "다음" 버튼 선택 및 페이지 존재 여부 확인
const nextElement = await page.locator("li.next a");
if ((await nextElement.count()) !== 0) {
// "다음" 버튼 클릭 후 다음 페이지로 이동
await nextElement.click();
// 페이지 로드 완료 대기
await page.waitForLoadState("domcontentloaded");
} else {
break;
}
}
// 추출한 데이터를 CSV로 내보내기
writeToPath("books.csv", books, { headers: true });
// 브라우저 닫기 및 리소스 해제
await browser.close();
})();
function makeAbsoluteURL(url, baseURL) {
// 정규 표현식으로 ../ 또는 ../../ 패턴 제거
const cleanURL = url.replace(/(../)+/, "");
// 기본 URL과 정리된 상대 URL 결합
return baseURL + cleanURL;
}다음 Node.js 명령어로 실행하세요:
node script.js결과는 다음과 같은 books.csv 파일이 생성됩니다:
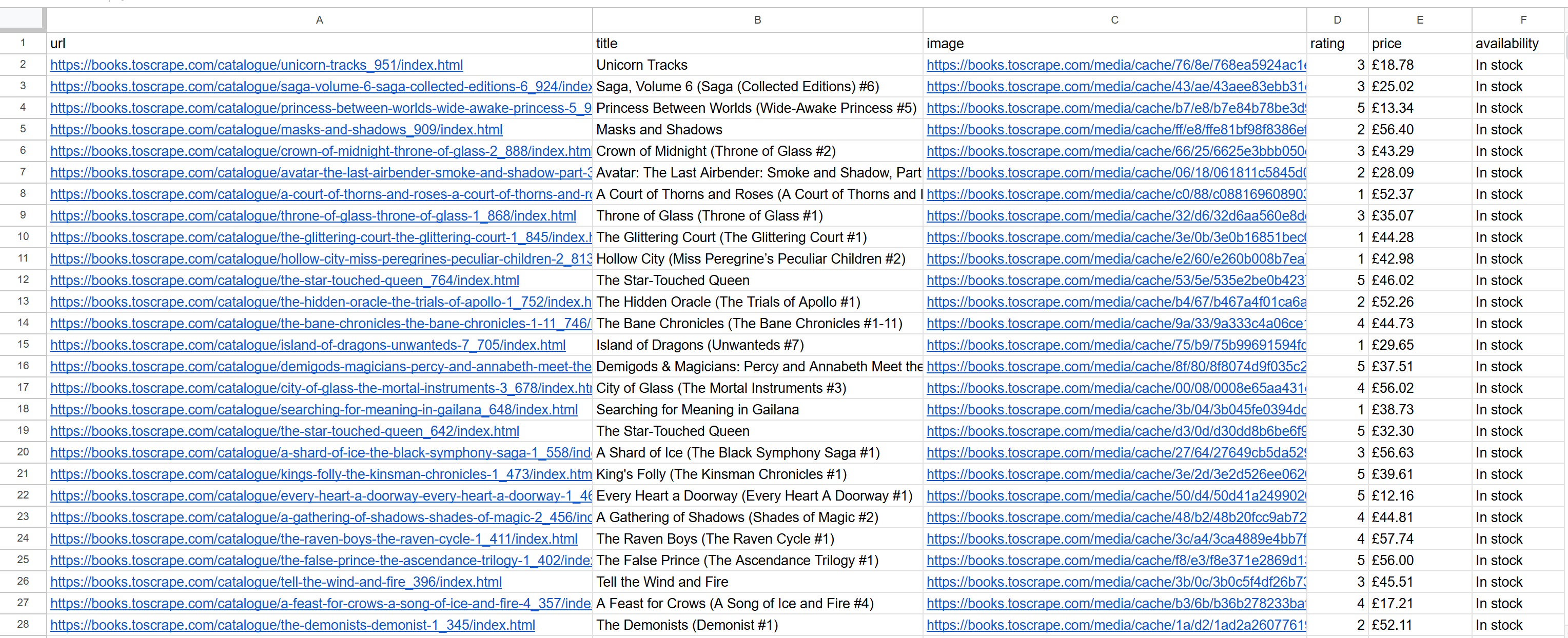
미션 완료! 이제 Scrapy로 동일한 결과를 얻는 방법을 살펴볼 차례입니다.
Scrapy를 이용한 웹 스크래핑 방법
아래 단계를 따라 Scrapy로 간단한 웹 스크레이퍼를 구축하는 방법을 알아보세요. 더 자세한 안내는 Scrapy 웹 스크래핑 튜토리얼을 참고하세요.
1단계: 프로젝트 설정
시작하기 전에 로컬에 Python 3이 설치되어 있는지 확인하세요. 설치되어 있지 않다면 공식 사이트에서 다운로드하여 설치하세요.
프로젝트용 폴더를 생성하고 그 안에 가상 환경을 초기화하세요:
mkdir scrapy-scraper
cd scrapy-scraper
python -m venv venvWindows에서는 다음 명령어를 실행하여 환경을 활성화하세요:
venvScriptsactivateUnix 또는 macOS에서는 동일하게 다음을 실행하세요:
source venv/bin/activate활성화된 환경에서 Scrapy를 설치하려면 다음을 실행하세요:
pip install scrapy다음으로, “books_scraper”라는 Scrapy 프로젝트를 생성하려면 아래 명령어를 실행하세요:
scrapy startproject books_scraper좋아요! 이제 Scrapy로 웹 스크래핑을 할 준비가 되었습니다.
2단계: Scrapy 스파이더 생성
Scrapy 프로젝트 폴더로 이동하여 대상 사이트용 새 스파이더를 생성합니다:
cd books_scraper
scrapy genspider books books.toscrape.comScrapy가 필요한 모든 파일을 자동으로 생성해 줍니다. 구체적으로 books_scraper 디렉토리는 이제 다음과 같은 파일 구조를 가져야 합니다:
books_scraper/
│── __init__.py
│── items.py
│── middlewares.py
│── pipelines.py
│── settings.py
└── spiders/
│── __init__.py
└── books.py원하는 스크래핑 로직을 구현하려면 books_scraper/spiders/books. py의 내용을 다음 코드로 대체하세요:
import scrapy
class BooksSpider(scrapy.Spider):
name = "books"
allowed_domains = ["books.toscrape.com"]
start_urls = ["https://books.toscrape.com/catalogue/page-1.html"]
def parse(self, response):
# 책 정보 추출
for book in response.css(".product_pod"):
yield {
"title": book.css("h3 a::attr(title)").get(),
"url": response.urljoin(book.css("h3 a::attr(href)").get()),
"image": response.urljoin(book.css(".thumbnail::attr(src)").get()),
"rating": book.css(".star-rating::attr(class)").get().split()[-1],
"price": book.css(".product_price .price_color::text").get(),
"availability": book.css(".availability::text").get().strip(),
}
# 페이지네이션 처리
next_page = response.css("li.next a::attr(href)").get()
if next_page:
yield response.follow(next_page, callback=self.parse)단계 #3: 스파이더 실행
books_scraper 폴더에서 활성화된 가상 환경에서 다음 명령어를 실행하여 Scrapy 스파이더를 실행하고 스크랩된 데이터를 CSV 파일로 내보냅니다:
scrapy crawl books -o books.csv이렇게 하면 Playwright 스크립트로 생성된 것과 동일한 books.csv 파일이 생성됩니다. 다시 한번, 미션 완료!
Scrapy vs Playwright: 어떤 것을 사용할까?
Playwright 스크래핑 스크립트는 6단계의 긴 절차가 필요한 반면, Scrapy는 단 3단계만 필요했습니다. 이는 놀라운 일이 아닙니다. Scrapy는 웹 스크래핑을 위해 설계된 반면, Playwright는 테스트와 스크래핑 모두에 사용되는 일반적인 브라우저 자동화 도구이기 때문입니다.
특히 핵심 차이는 웹 크롤링 로직에 있었습니다. Playwright는 페이지네이션을 위해 수동 상호작용과 맞춤형 로직이 필요한 반면, Scrapy는 몇 줄의 코드로 처리할 수 있습니다.
요약하자면, 다음과 같은 상황에서는 Playwright보다 Scrapy를 선택하세요:
- 대규모 데이터 추출이 필요하며 내장된 크롤링 지원이 요구되는 경우
- 성능과 속도가 최우선 과제인 경우(Scrapy는 빠른 병렬 요청에 최적화됨).
- 페이지네이션, 재시도, 다양한 형식의 데이터 추출, 병렬 스크래핑을 자동으로 처리해주는 프레임워크를 선호하는 경우.
반대로, 다음과 같은 경우에는 Scrapy보다 Playwright를 선호하십시오:
- 브라우저 렌더링이 필요한 자바스크립트 중심 웹사이트에서 데이터를 추출해야 할 때.
- 무한 스크롤링과 같은 동적 상호작용이 필요한 경우.
- 사용자 상호작용에 대한 더 많은 제어권(예: 복잡한 웹 스크래핑 탐색 패턴)이 필요한 경우.
Scrapy와 Playwright 비교의 마지막 단계로 아래 요약표를 참조하세요:
| 기능 | Scrapy | Playwright |
|---|---|---|
| 개발사 | Zyte + 커뮤니티 | Microsoft + 커뮤니티 |
| GitHub 스타 | 54k+ | 69k+ |
| 다운로드 | 380k+, 주간 | 1,200만 이상, 주간 |
| 프로그래밍 언어 | Python | 파이썬, 자바스크립트, 타입스크립트, C# |
| 주요 목표 | 웹 스크래핑 및 크롤링 | 브라우저 자동화, 테스트 및 웹 스크래핑 |
| 자바스크립트 렌더링 | ❌ (일부 플러그인으로 가능) | ✔️ |
| 브라우저 상호작용 | ❌ (일부 플러그인으로 가능) | ✔️ |
| 자동 크롤링 | ✔️ | ❌ (수동 처리 필요) |
| 프록시 통합 | 지원됨 | 지원됨 |
| 병렬 요청 | 효율적이고 쉽게 구성 가능 | 제한적이지만 가능 |
| 데이터 내보내기 | CSV, JSON, XML 등 | 사용자 정의 로직 필요 |
Playwright와 Scrapy의 한계
Scrapy와 Playwright는 모두 웹 스크래핑을 위한 강력한 도구이지만, 각각 특정 한계가 있습니다.
예를 들어, Scrapy는 렌더링이나 데이터 검색에 자바스크립트를 사용하는 사이트의 동적 콘텐츠를 스크래핑하는 데 어려움을 겪습니다. 현대 웹사이트 대부분이 자바스크립트를 필요로 하기 때문에, Scrapy는 일반적인 스크래핑 방지 조치에 더 취약합니다. 물론 Playwright는 자바스크립트 중심 사이트를 처리할 수 있지만, IP 차단과 같은 문제에 직면합니다.
많은 요청을 수행할 때 속도 제한 장치(rate limiter)를 작동시켜 요청 거부나 IP 차단까지 발생할 수 있습니다. 이를 완화하기 위해 프록시 서버를 통합하여 IP를 회전시킬 수 있습니다.
신뢰할 수 있는 프록시 서버가 필요하다면, Bright Data의 프록시 네트워크는 포춘 500대 기업과 전 세계 20,000명 이상의 고객이 신뢰합니다. 그들의 네트워크에는 다음이 포함됩니다:
- 데이터센터 프록시: 77만 개 이상의 데이터센터 IP.
- 주거용 프록시: 195개국 이상에 걸쳐 7,200만 개 이상의 주거용 IP.
- ISP 프록시: 70만 개 이상의 ISP IP 주소.
Playwright의 또 다른 과제는 CAPTCHA입니다. 이는 브라우저에서 작동하는 자동 스크래핑 봇을 차단하기 위해 설계되었습니다. 이를 극복하기 위해 Playwright에서 CAPTCHA 우회 솔루션을 탐색할 수 있습니다.
결론
이 Playwright 대 Scrapy 비교 블로그 글에서는 웹 스크래핑에서 두 라이브러리의 역할을 알아보았습니다. 데이터 추출 기능을 살펴보고 실제 페이지네이션 시나리오에서의 성능을 비교했습니다.
Scrapy는 데이터 파싱과 웹사이트 크롤링에 필요한 모든 것을 제공하는 반면, Playwright는 사용자 상호작용 시뮬레이션에 더 중점을 둡니다.
또한 IP 차단 및 CAPTCHA와 같은 한계점도 확인했습니다. 다행히 이러한 문제들은 프록시나 Bright Data의 CAPTCHA Solver 같은 전용 안티봇 솔루션을 통해 극복할 수 있습니다.
Bright Data의 프록시 및 스크래핑 솔루션을 경험해 보려면 지금 바로 무료 계정을 생성하세요!




