

상상해 보세요: 웹 스크레이퍼를 완성하는 데 몇 주를 투자했습니다. CSS 선택기는 정교하게 조정되었고 데이터는 원활하게 흐르는데, 아마존이 레이아웃을 변경합니다. 정성껏 다듬은 선택기가 하룻밤 사이에 무너집니다. 익숙한 이야기죠?
모델 컨텍스트 프로토콜(MCP)이 등장합니다. 웹 데이터 추출 방식을 바꿀 새로운 접근법이죠. 취약한 CSS 선택자를 작성하는 대신, AI에 평이한 영어 지시를 전달하면 AI가 복잡한 작업을 처리합니다. 하지만 이 AI 기반 접근법이 검증된 기존 방법보다 정말 더 나을까요?
두 접근법을 깊이 있게 분석하고, 실제 스크레이퍼를 구축하며, 2026년 승자는 어느 방법인지 알아봅시다.
간단 비교: 기존 방식 vs MCP 스크래핑
자세한 내용에 들어가기 전에, 두 접근법의 차이점을 살펴보겠습니다:
| 측면 | 전통적 스크래핑 | MCP 기반 스크래핑 |
|---|---|---|
| 설정 시간 | 몇 시간에서 며칠 | 분에서 시간 |
| 유지 관리 | 높음 – 레이아웃 변경 시 중단됨 | 낮음 – AI가 사소한 변경에 적응 |
| 비용 | 요청당 낮음 | 요청당 비용 증가 |
| 제어 | 논리에 대한 완전한 제어 | AI 해석에 의존 |
| 학습 곡선 | 가파름 – 코딩 기술 필요 | 완만함 – 자연어 프롬프트 |
| 최적 적용 분야 | 대량 트래픽, 안정적인 사이트 | 신속한 프로토타이핑, 변경이 잦은 사이트 |
전통적인 웹 스크래핑: 기초
수십 년간 데이터 추출을 주도해 온 전통적인 웹 스크래핑. 핵심은 데이터 추출 방식을 완전히 통제할 수 있는 간단한 4단계 프로세스입니다.
전통적인 워크플로
- HTTP 요청 전송: HTTP 클라이언트로 웹 페이지 가져오기 시작. Python의
requests라이브러리가 기본 요구사항을 처리하지만, 본격적인 성능을 원한다면 다음을 고려하세요:- 비동기 작업을 위한httpx 또는 aiohttp
- 병렬 요청을 위한requests-futures
- 웹 스크래핑 속도 향상 가이드에서 최적화 팁을 확인하세요
HTML 파싱: 파서를 사용하여 원시 HTML을 활용 가능한 데이터로 변환합니다. BeautifulSoup은 여전히 가장 선호되는 선택지이며, 속도를 위해 lxml로 구동되는 경우
- HTML 파싱: 파서를 사용하여 원시 HTML을 활용 가능한 데이터로 변환하세요. BeautifulSoup은 여전히 가장 많이 사용되는 선택지이며, 속도를 위해 lxml로 구동되는 경우가 많습니다. 이러한 파서들은 정적 콘텐츠 추출에 탁월합니다.
- 데이터 추출: 다음을 사용하여 특정 요소를 타겟팅하세요:
- CSS 선택자: 클래스, ID 또는 속성으로 간편하게 선택
- 복잡한 탐색 및 텍스트 일치에는 XPath 사용
- 어떤 것을 사용할지 모르시겠나요? 저희의 XPath 대 CSS 선택기 가이드에서 자세히 설명해 드립니다.
4. 동적 콘텐츠 처리: 자바스크립트 중심 사이트의 경우 브라우저 자동화가 필요합니다:
- Selenium: 광범위한 언어 지원을 제공하는 베테랑 선택지
- Playwright: 현대적이고 빠르며 안정적인 선택
- 퍼펫티어: Node.js 워크플로우에 최적화
- Bright Data의 스크래핑 브라우저: 내장형 봇 방지 기능 및 프록시 관리
인기 있는 기존 스크래핑 스택
정적 사이트용:
복잡한 크롤링용:
- 파이썬: Scrapy 프레임워크
자바스크립트 중심 사이트용:
- Playwright + Playwright Stealth
- 퍼피티어 + 퍼피티어-엑스트라-플러그인-스텔스
- SeleniumBase
모델 컨텍스트 프로토콜: AI 기반 스크래핑
2024년 11월 25일 Anthropic에서 출시한 모델 컨텍스트 프로토콜(MCP) 은 대규모 언어 모델(LLM)이 함수를 호출하는 것처럼 쉽게 외부 도구를 호출할 수 있게 하는 개방형 표준입니다. AI 애플리케이션을 위한 USB-C라고 생각하면 됩니다.
HTTP 요청이나 CSS 선택자를 하드코딩하는 대신, 단순히 결과물(“이 URL에서 제품 제목, 가격, 평점을 가져오세요”)을 설명하기만 하면 LLM이 백그라운드에서 적절한 도구(예: scrape_product())를 선택합니다.
웹 스크래핑 팀에게 이 변화는 취약한 파싱 로직을 탄력적인 프롬프트 기반 워크플로로 전환합니다.
MCP의 작동 방식
모든 메시지는 JSON-RPC 2.0을 통해 전송되므로 모든 호출이 언어에 구애받지 않고 스트림 친화적입니다.
- 호스트 — 대화를 시작하는 LLM 애플리케이션(예: Claude Desktop)
- 클라이언트 — 호스트에 내장된 프로토콜 핸들러
- 서버 — 하나 이상의 도구를 노출하는 서비스
- 도구 — JSON이나 CSV 같은 구조화된 결과를 반환하는 명명된 함수
마법은 상호작용 흐름에서 일어납니다:
- 작업 설명. “이 나이키 신발의 가격 이력을 가져와.”
- LLM이 도구를 선택합니다. 요청을 ` scrape_product_history(url)`로 매핑합니다.
- 서버가 실행합니다. 헤드리스 브라우징, 프록시 로테이션, CAPTCHA 해결 — 도구의 구성 방식에 따라 수행됩니다.
- 구조화된 출력. LLM은 정제된 JSON을 수신하여 반환하거나 다음 단계로 전달합니다.
💡 참고: MCP는 웹 추출뿐만 아니라 모든 도구 호출을 관리합니다. SQL 쿼리, git 작업, 파일 I/O 등을 조정할 수 있습니다. 하지만 도구는 여전히 누군가가 작성해야 합니다. AI는 구현되지 않은 로직을 발명할 수 없습니다.
MCP가 웹 스크래핑 워크플로를 어떻게 혁신하는지 자세히 살펴보세요.
공식 MCP SDK
Model Context Protocol 조직은 주요 언어용 SDK를 제공합니다:
- TypeScript SDK – 기본 구현
- Python SDK – AI/ML 워크플로를 위한 완전한 기능 지원
- Java SDK – Spring AI와 함께 유지 관리
- C# SDK – Microsoft 파트너십 (미리 보기)
- Ruby SDK – Shopify 협업
- Rust SDK – 고성능 구현
- Kotlin SDK – JVM 기반, Android에 적합
직접 비교: 두 가지 방식으로 아마존 스크레이퍼 구축하기
두 가지 접근 방식을 모두 사용하여 동일한 Amazon 제품 스크레이퍼를 구축해 보겠습니다. 이 실용적인 비교를 통해 기존 방식과 MCP 기반 스크래핑의 실제 차이점을 확인할 수 있습니다.
전통적인 접근 방식
먼저 Playwright와 BeautifulSoup을 사용한 전통적인 스크레이퍼를 구축해 보겠습니다:
import asyncio
from playwright.async_api import async_playwright
from bs4 import BeautifulSoup
async def scrape_amazon_product(url):
async with async_playwright() as p:
browser = await p.chromium.launch(headless=True)
page = await browser.new_page()
await page.goto(url)
await page.wait_for_selector("#productTitle", timeout=10000)
soup = BeautifulSoup(await page.content(), "html.parser")
await browser.close()
def extract(selector, default="N/A", attr=None, clean=lambda x: x.strip()):
element = soup.select_one(selector)
if not element:
return default
value = element.get(attr) if attr else element.text
return clean(value) if value else default
return {
"title": extract("#productTitle"),
"current_price": extract(".a-price-whole"),
"original_price": extract(".a-price.a-text-price span"),
"rating": extract("#acrPopover", attr="title"),
"reviews": extract("#acrCustomerReviewText"),
"availability": extract(
"#availability span", clean=lambda x: x.strip().split("n")[0].strip()
),
}
async def main():
product = await scrape_amazon_product("https://www.amazon.in/dp/B0BTDDVB67")
print("n제품 정보:")
print("-------------------")
print("n".join(f"{k.replace('_', ' ').title()}: {v}" for k, v in product.items()))
if __name__ == "__main__":
asyncio.run(main())문제점: CSS 선택자(#productTitle, .a-price-whole)가 하드코딩되어 있습니다. 아마존이 HTML을 수정하는 순간 스크래퍼가 작동하지 않게 됩니다. 데이터 분석보다 고장난 선택자를 고치는 데 더 많은 시간을 소비하게 될 것입니다.
아마존의 봇 방지 기능을 우회해야 하나요? 아마존 CAPTCHA 우회 방법에 대한 전체 가이드를 확인해 보세요.
MCP 접근법
이제 MCP를 사용해 동일한 스크레이퍼를 구축해 보겠습니다.
from mcp.server.fastmcp import FastMCP
from playwright.async_api import async_playwright
from markdownify import markdownify as md
from bs4 import BeautifulSoup
# FastMCP 인스턴스 초기화
mcp = FastMCP("Amazon Scraper")
@mcp.tool()
async def scrape_product(url: str) -> str:
"""
아마존 상품 페이지를 가져와 주요 상품 섹션을 추출하고
Markdown 형식으로 반환합니다.
"""
browser = None
try:
async with async_playwright() as playwright:
# 헤드리스 브라우저 실행
browser = await playwright.chromium.launch(headless=True)
page = await browser.new_page()
# 이동 후 상품 제목 대기
await page.goto(url, timeout=90000)
await page.wait_for_selector("span#productTitle", timeout=30000)
# HTML 추출 및 파싱
html_content = await page.content()
soup = BeautifulSoup(html_content, "lxml")
product_section = soup.find("div", id="dp") or soup.body
return md(str(product_section)).strip()
except Exception as e:
return f"Error: {e}"
finally:
if browser is not None:
await browser.close()
if __name__ == "__main__":
mcp.run(transport="stdio")차이점: 빠진 부분이 보이시나요? 가격, 평점, 재고 상태에 대한 특정 선택자가 없습니다. MCP 서버는 단순히 콘텐츠를 제공하며, AI가 사용자의 자연어 요청을 기반으로 추출할 내용을 파악합니다.
Cursor로 MCP 설정하기
직접 시도해보고 싶으신가요? MCP 서버를 커서와 통합하는 방법은 다음과 같습니다:
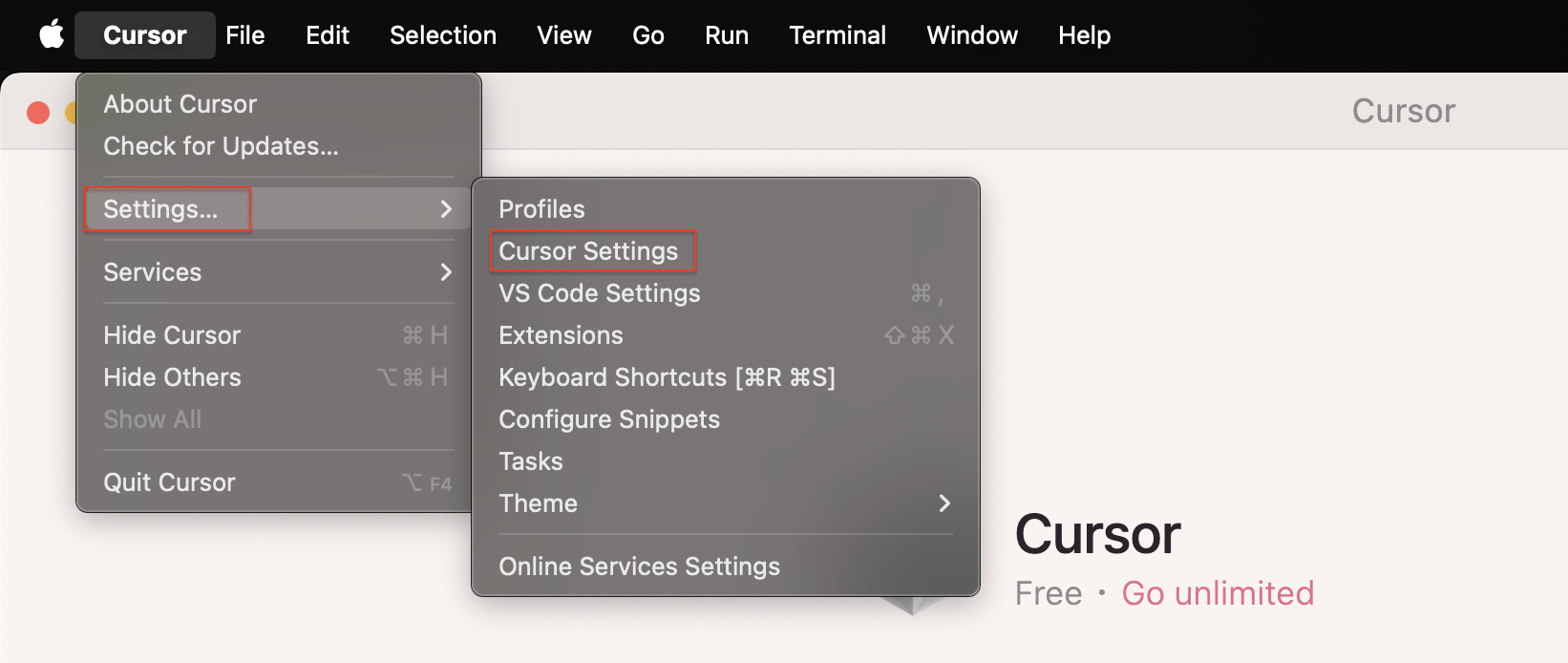
1단계: 커서를 열고 설정 → 커서 설정으로 이동
2단계: 사이드바에서 MCP 선택
3단계: + 새 글로벌 MCP 서버 추가 클릭
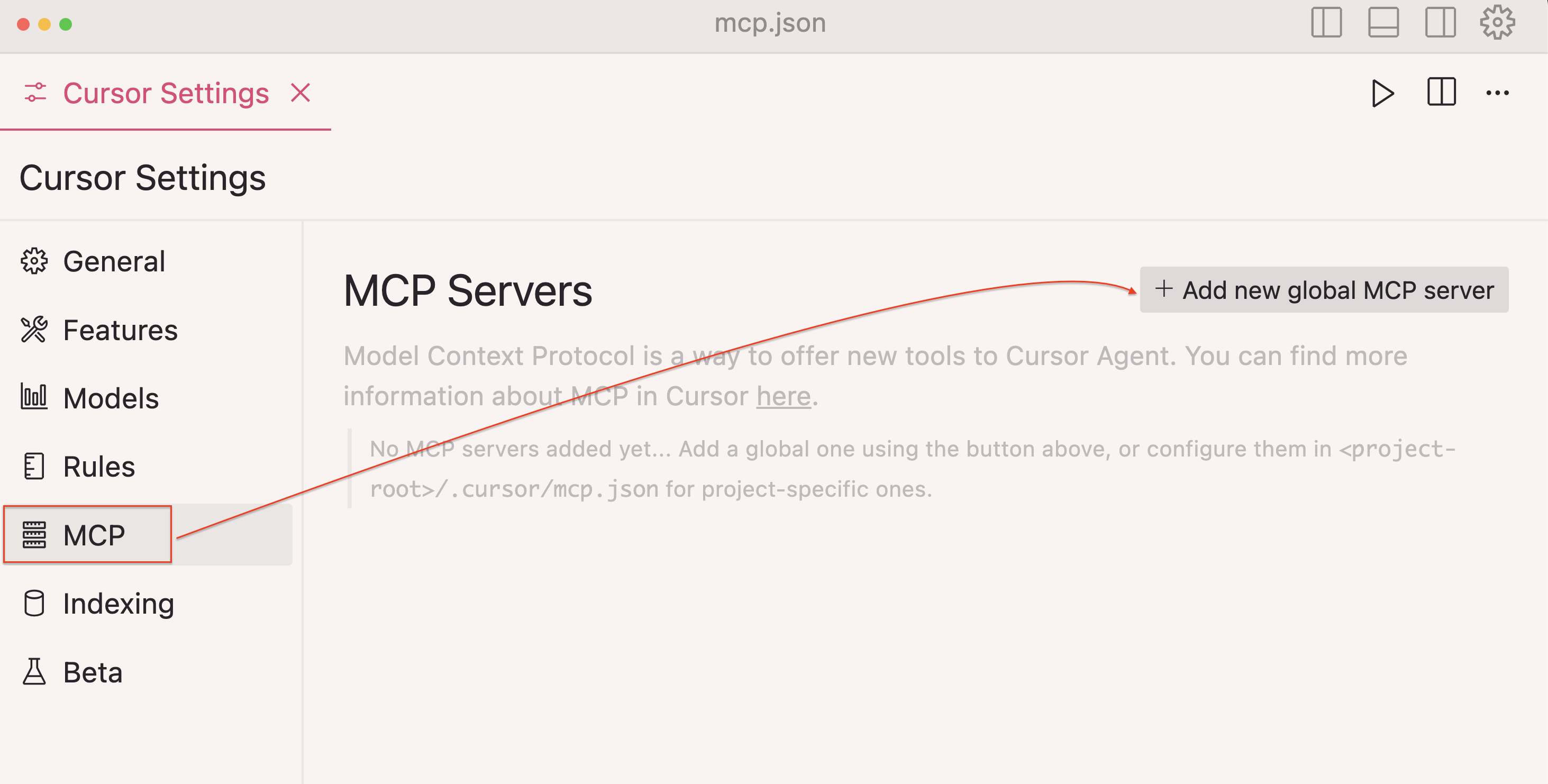
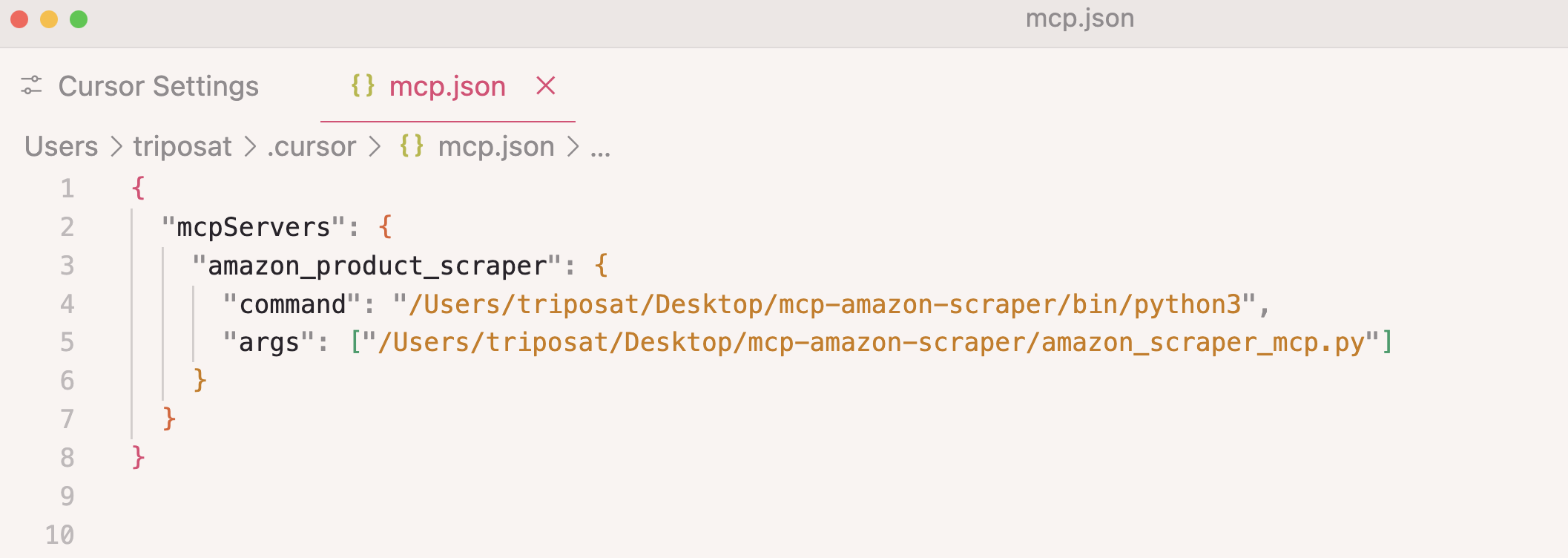
4단계: 서버 구성을 추가하세요:
{
"mcpServers": {
"amazon_product_scraper": {
"command": "/path/to/python",
"args": ["/path/to/amazon_scraper_mcp.py"]
}
}
}
단계 5: 저장하고 연결 상태가 녹색으로 표시되는지 확인
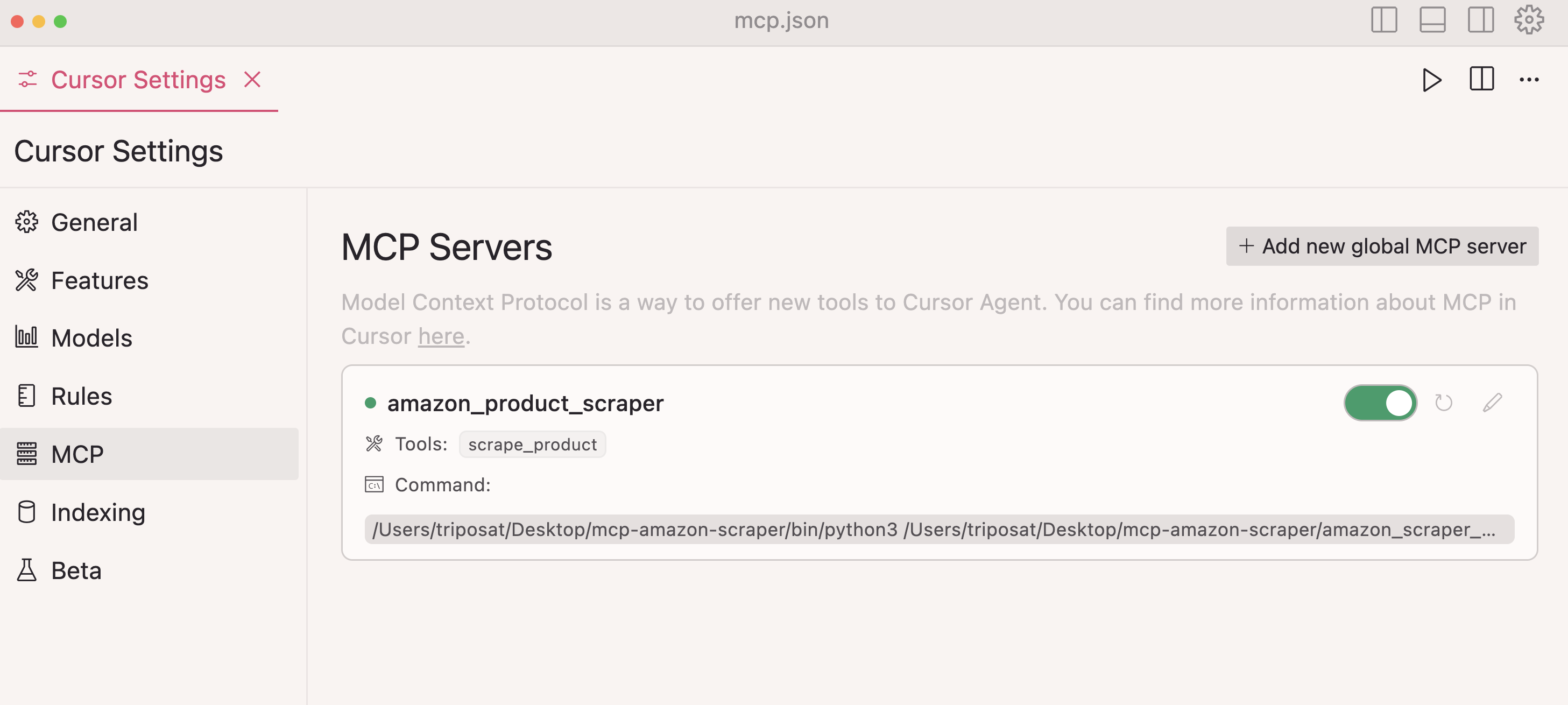
6단계: 이제 커서 채팅에서 자연어 명령을 사용할 수 있습니다:
https://www.amazon.in/dp/B0BTDDVB67에서 제품 제목, 현재 가격, 원래 가격, 별점, 리뷰 수, 주요 기능 3가지, 재고 상태를 추출하여 JSON으로 반환하세요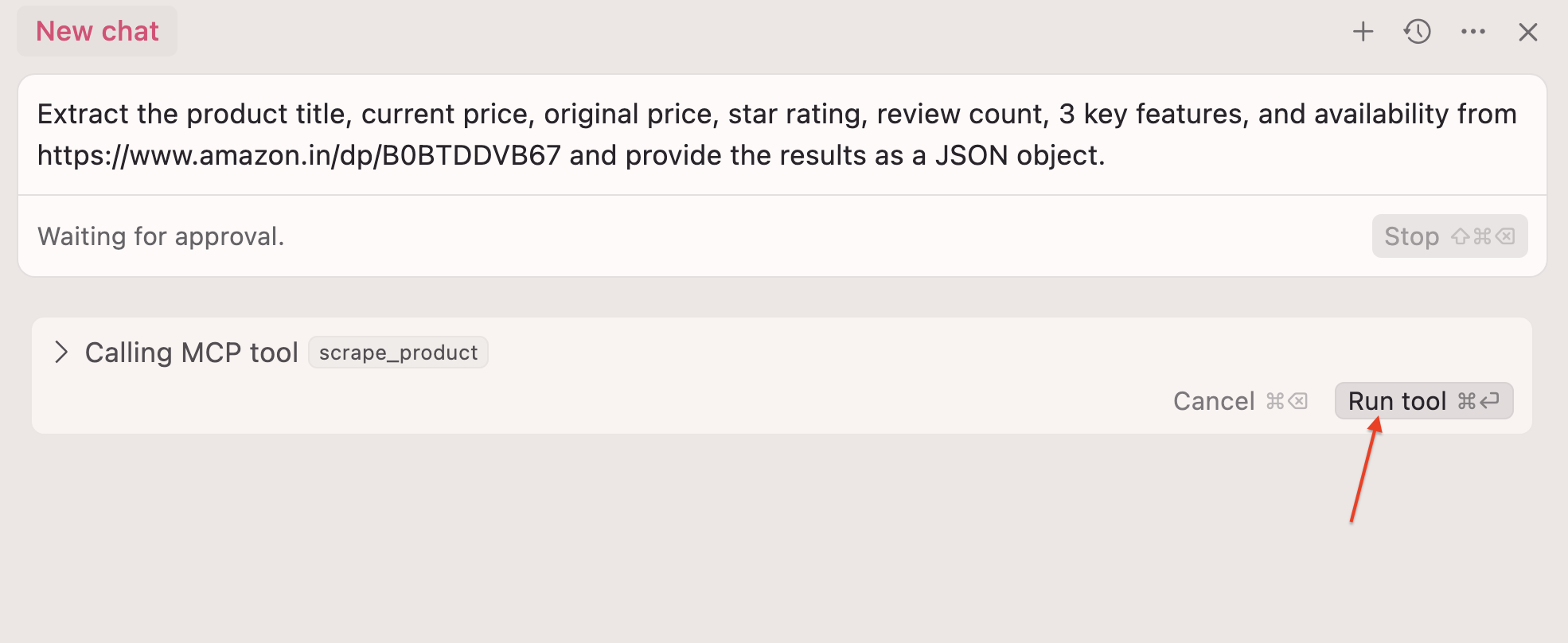
7단계: 실행 도구 ⏎ 클릭
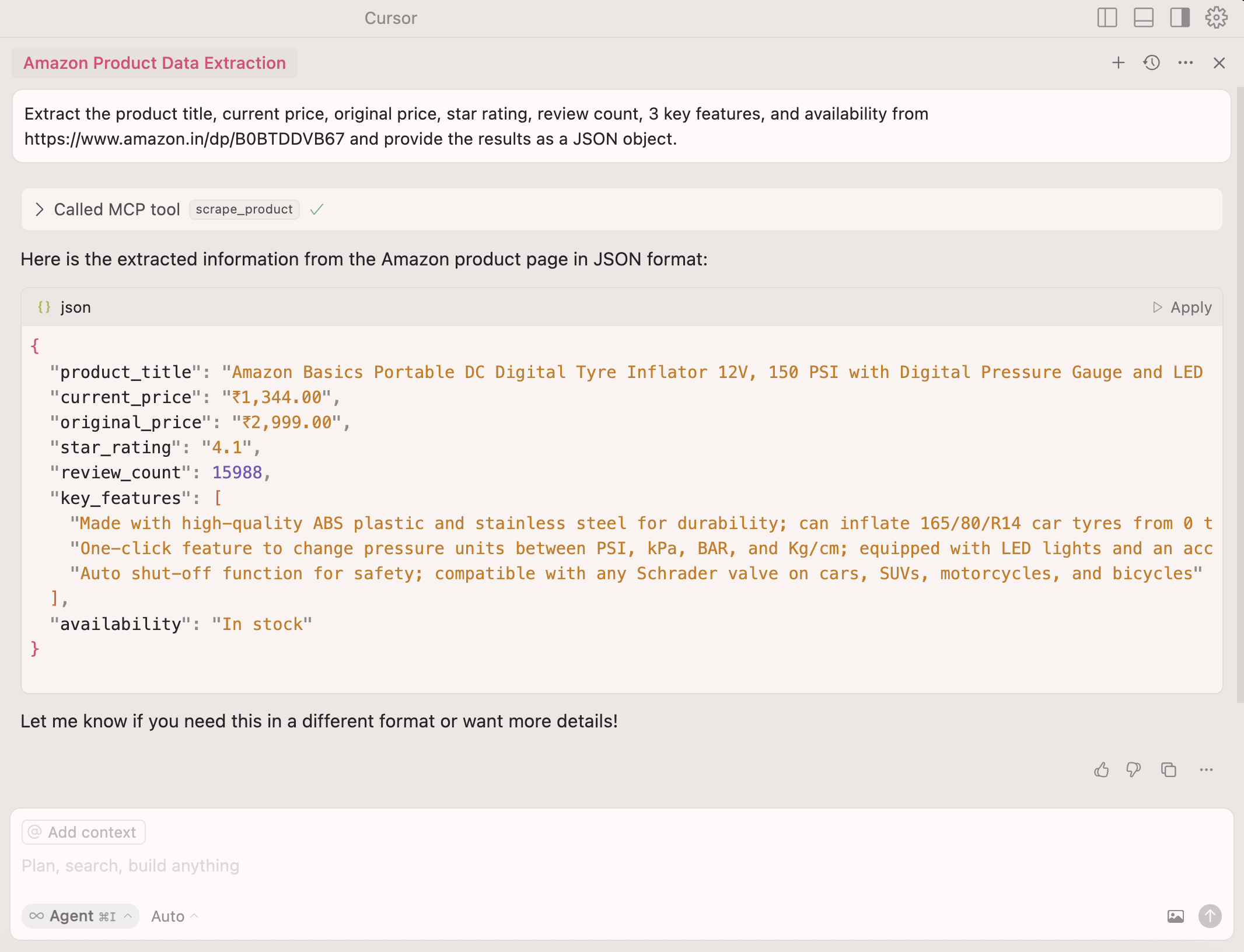
AI가 모든 추출 로직을 처리합니다—선택자(selector)가 필요 없습니다!
👉 실시간 AI 활용 웹 데이터 접근을 위한 Bright Data MCP 서버 통합 방법을 확인하세요.
각 접근 방식의 사용 시점
두 스크레이퍼를 모두 구축한 후에는 장단점이 명확해집니다.
모든 요청, 선택기 및 프록시를 종단 간 제어해야 할 때는 기존 스크래핑 방식을 선택하세요.
- 대량, 반복 가능한 작업
- 변화가 거의 없는 명확하게 정의된 사이트
- 모든 밀리초와 종속성이 중요한 파이프라인
💡 팁: 전통적 스크래핑의 경우:
- IP 로테이션 및 지역 제한 처리를 위해 Bright Data의 프록시 서비스를 활용하세요
- 120개 이상의 인기 도메인에서 미리 구축된 추출을 위한 웹 스크레이퍼 API를 사용해 보세요
- 즉시 사용 가능한 데이터를 위해 데이터셋 마켓플레이스를 둘러보세요
반면, 제품이 이미 LLM 중심이거나 에이전트가 실시간 데이터를 요청 시 가져오도록 하려면 MCP 기반 워크플로를 채택하세요.
- 선택자 작성으로 속도가 느려지는 경우 신속한 프로토타입 제작
- 자주 변경되거나 도메인마다 다른 사이트
- 기술에 익숙하지 않은 팀원도 프롬프트를 사용하여 데이터 수집을 트리거할 수 있습니다
- LLM 추론이 유용한 복잡한 흐름(예: 검색 → 페이지 분할 → 추출)
- 추가 지연 시간이나 도구 호출 비용을 감수할 수 있는 대화형 앱
💡 팁: MCP 통합을 위해:
- 커뮤니티 MCP 서버를 확인해 보세요
- 공식 MCP 참조 구현체로 실험해 보세요
- 기업급 안정성을 위한 Bright Data의 MCP 통합을 테스트하세요.
Bright Data의 MCP 서버는 단일 JSON-RPC 엔드포인트 뒤에 Web Unlocker, Crawl API, Browser API 또는 SERP API를 통합합니다. 에이전트는 search_engine과 같은 사용 가능한 도구를 호출하기만 하면 서버가 자동으로 스텔스 브라우징, CAPTCHA 해결 및 프록시 로테이션을 처리합니다.
미래는 하이브리드입니다
어느 접근 방식도 만능 해결책은 아니므로, 현명한 팀은 두 가지를 결합합니다.
- 발견을 위해 MCP를 사용하세요. 프롬프트 기반 스크레이퍼를 실행하여 몇 분 안에 새로운 데이터 소스를 검증하세요.
- 기존 코드로 최적화하세요. 대상과 스키마가 안정되면 속도와 비용 효율성을 위해 수동으로 튜닝된 선택기로 전환하세요.
- 성숙한 스크레이퍼를 MCP 도구로 노출하세요. 기존 Python 또는 Node.js 크롤러를 경량 MCP 서버로 감싸 에이전트가 단일 함수 호출로 실행할 수 있게 합니다.
현대적인 플랫폼은 이미 이 모델을 따르고 있습니다. 예를 들어, Bright Data의 MCP 서버를 사용하면 AI 주도 탐색과 프로덕션 등급의 스크래핑 인프라를 결합할 수 있습니다.
결론
기존 웹 스크래핑은 사라지지 않을 것입니다. 여전히 대부분의 대규모 데이터 작업을 수행합니다. 한편 MCP는 새로운 수준의 유연성과 LLM 지원 지능을 제공합니다.
미래는 하이브리드입니다. 작업 요구에 따라 두 가지를 모두 사용하고 전환하세요.
AI 기반 추출을 위한 확장 가능하고 규정 준수 인프라가 필요하다면, Bright Data의 AI 지원 웹 데이터 인프라를 확인하세요. 주거용 프록시부터 사전 구축된 API, 완전 관리형 MCP 서버까지 제공합니다.
이미 에이전트 워크플로를 구축 중이신가요? Google ADK와 Bright Data MCP 통합 가이드를 확인해 보세요.





